تحليل تأثير الإغلاق على جودة الهواء في دلهي، الهند (Analyzing the impact of the lockdown on air quality in Delhi, India)

ما ستقوم به (What you'll do)
حساب مؤشرات جودة الهواء (Air Quality Indices - AQI) وإجراء اختبار t لستودنت المقترن (paired Student's t-test) عليها.
ما ستتعلمه (What you'll learn)
-
ستتعلم مفهوم المتوسطات المتحركة (moving averages)
-
ستتعلم كيفية حساب مؤشر جودة الهواء (Air Quality Index - AQI)
-
ستتعلم كيفية إجراء paired Student's t-test وإيجاد قيم
tوp -
ستتعلم كيفية تفسير هذه القيم
ما ستحتاجه (What you'll need)
-
تثبيت SciPy في بيئتك
-
فهم أساسي للمصطلحات الإحصائية مثل المجتمع (population)، والعينة (sample)، والمتوسط (mean)، والانحراف المعياري (standard deviation) وما إلى ذلك.
+++
مشكلة تلوث الهواء (The problem of air pollution)
يعد تلوث الهواء أحد أبرز أنواع التلوث التي نواجهها والتي لها تأثير مباشر على حياتنا اليومية. أدت جائحة كوفيد-19 (COVID-19) إلى عمليات إغلاق (lockdowns) في أجزاء مختلفة من العالم؛ مما وفر فرصة نادرة لدراسة تأثير النشاط البشري (أو انعدامه) على تلوث الهواء. في هذا البرنامج التعليمي، سندرس جودة الهواء في دلهي، وهي واحدة من أكثر المدن تضرراً من تلوث الهواء، قبل وأثناء الإغلاق من مارس إلى يونيو 2020. لهذا الغرض، سنقوم أولاً بحساب AQI لكل ساعة من قياسات الملوثات التي تم جمعها. بعد ذلك، سنأخذ عينات من هذه المؤشرات ونجري عليها paired Student's t-test. سيوضح لنا ذلك إحصائياً أن جودة الهواء تحسنت بسبب الإغلاق، مما يدعم حدسنا.
لنبدأ باستيراد المكتبات اللازمة في بيئتنا.
```{code-cell} ipython3 import numpy as np from numpy.random import default_rng from scipy import stats
## بناء مجموعة البيانات (Building the dataset)
سنستخدم نسخة مكثفة من مجموعة بيانات [بيانات جودة الهواء في الهند (Air Quality Data in India)](https://www.kaggle.com/rohanrao/air-quality-data-in-india). تحتوي مجموعة البيانات هذه على بيانات جودة الهواء و AQI على المستوى الساعي واليومي لمحطات مختلفة عبر مدن متعددة في الهند. تحتوي النسخة المكثفة المتاحة مع هذا البرنامج التعليمي على قياسات الملوثات الساعية لدلهي من 31 مايو 2019 إلى 30 يونيو 2020. وهي تتضمن قياسات للملوثات القياسية المطلوبة لحساب AQI وبعض الملوثات المهمة الأخرى:
الجسيمات المعلقة (Particulate Matter - PM 2.5 و PM 10)، وثاني أكسيد النيتروجين (NO2)، والأمونيا (NH3)، وثاني أكسيد الكبريت (SO2)، وأول أكسيد الكربون (CO)، والأوزون (O3)، وأكاسيد النيتروجين (NOx)، وأكسيد النيتريك (NO)، والبنزين، والتولوين، والزيلين.
لنقم بطباعة الصفوف القليلة الأولى لإلقاء نظرة على مجموعة البيانات الخاصة بنا.
```{code-cell} ipython3
! head air-quality-data.csv
لأغراض هذا البرنامج التعليمي، نحن مهتمون فقط بالملوثات القياسية المطلوبة لحساب AQI، وهي PM 2.5 و PM 10 و NO2 و NH3 و SO2 و CO و O3. لذا، سنقوم فقط باستيراد هذه الأعمدة المحددة باستخدام np.loadtxt. سنقوم بعد ذلك بـ التقطيع (slice) وإنشاء مجموعتين: pollutants_A التي تحتوي على PM 2.5 و PM 10 و NO2 و NH3 و SO2، و pollutants_B التي تحتوي على CO و O3. سيتم معالجة المجموعتين بشكل مختلف قليلاً، كما سنرى لاحقاً.
```{code-cell} ipython3 pollutant_data = np.loadtxt("air-quality-data.csv", dtype=float, delimiter=",", skiprows=1, usecols=range(1, 8)) pollutants_A = pollutant_data[:, 0:5] pollutants_B = pollutant_data[:, 5:]
print(pollutants_A.shape) print(pollutants_B.shape)
قد تحتوي مجموعة البيانات الخاصة بنا على قيم مفقودة، يرمز لها بـ `NaN` ، لذا لنقم بإجراء فحص سريع باستخدام [np.isfinite](https://numpy.org/devdocs/reference/generated/numpy.isfinite.html).
```{code-cell} ipython3
np.all(np.isfinite(pollutant_data))
بهذا، نكون قد نجحنا في استيراد البيانات وتأكدنا من اكتمالها. لننتقل إلى حسابات AQI!
+++
حساب مؤشر جودة الهواء (Calculating the Air Quality Index)
سنقوم بحساب AQI باستخدام الطريقة (the method) المعتمدة من قبل المجلس المركزي لمكافحة التلوث (Central Pollution Control Board) في الهند. لتلخيص الخطوات:
-
جمع قيم متوسط التركيز على مدار 24 ساعة للملوثات القياسية؛ و8 ساعات في حالة CO و O3.
-
حساب المؤشرات الفرعية (sub-indices) لهذه الملوثات باستخدام الصيغة:
$$ Ip = \dfrac{\text{IHi – ILo}}{\text{BPHi – BPLo}}\cdot{\text{Cp – BPLo}} + \text{ILo} $$
حيث:
Ip= المؤشر الفرعي للملوثp\Cp= التركيز المتوسط للملوثp\BPHi= نقطة انقطاع التركيز (concentration breakpoint) أي أكبر من أو تساويCp\BPLo= نقطة انقطاع التركيز أي أقل من أو تساويCp\IHi= قيمة AQI المقابلة لـBPHi\ILo= قيمة AQI المقابلة لـBPLo -
الحد الأقصى للمؤشر الفرعي في أي وقت معين هو Air Quality Index.
يتم حساب Air Quality Index بمساعدة نطاقات نقاط الانقطاع (breakpoint ranges) كما هو موضح في المخطط أدناه.
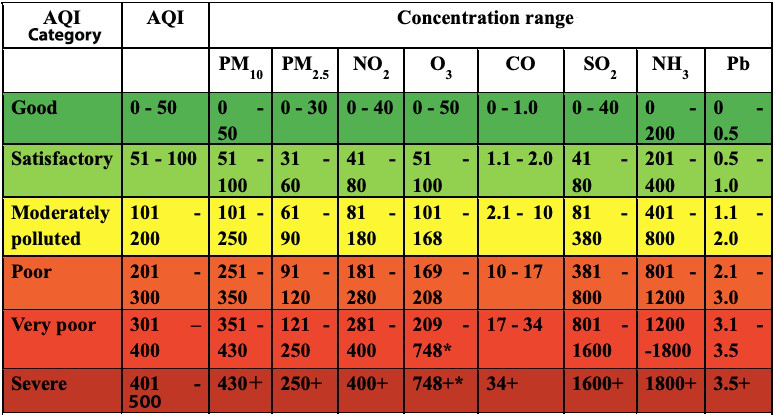
لنقم بإنشاء مصفوفتين لتخزين نطاقات AQI ونقاط الانقطاع حتى نتمكن من استخدامهما لاحقاً في حساباتنا.
```{code-cell} ipython3 AQI = np.array([0, 51, 101, 201, 301, 401, 501])
breakpoints = { 'PM2.5': np.array([0, 31, 61, 91, 121, 251]), 'PM10': np.array([0, 51, 101, 251, 351, 431]), 'NO2': np.array([0, 41, 81, 181, 281, 401]), 'NH3': np.array([0, 201, 401, 801, 1201, 1801]), 'SO2': np.array([0, 41, 81, 381, 801, 1601]), 'CO': np.array([0, 1.1, 2.1, 10.1, 17.1, 35]), 'O3': np.array([0, 51, 101, 169, 209, 749]) }
### المتوسطات المتحركة (Moving averages)
للخطوة الأولى، يتعين علينا حساب moving averages لـ `pollutants_A` عبر نافذة مدتها 24 ساعة ولـ `pollutants_B` عبر نافذة مدتها 8 ساعات. سنكتب دالة بسيطة `moving_mean` باستخدام [np.cumsum](https://numpy.org/devdocs/reference/generated/numpy.cumsum.html) و [الفهرسة المقطعة (sliced indexing)](https://numpy.org/devdocs/user/basics.indexing.html#slicing-and-striding) لتحقيق ذلك.
للتأكد من أن كلتا المجموعتين لهما نفس الطول، سنقوم باقتطاع `pollutants_B_8hr_avg` وفقاً لطول `pollutants_A_24hr_avg`. سيضمن ذلك أيضاً أن لدينا تركيزات لجميع الملوثات خلال نفس الفترة الزمنية.
```{code-cell} ipython3
def moving_mean(a, n):
ret = np.cumsum(a, dtype=float, axis=0)
ret[n:] = ret[n:] - ret[:-n]
return ret[n - 1:] / n
pollutants_A_24hr_avg = moving_mean(pollutants_A, 24)
pollutants_B_8hr_avg = moving_mean(pollutants_B, 8)[-(pollutants_A_24hr_avg.shape[0]):]
الآن، يمكننا دمج المجموعتين باستخدام np.concatenate لتشكيل مجموعة بيانات واحدة لجميع التركيزات المتوسطة. لاحظ أنه يتعين علينا دمج مصفوفاتنا على مستوى الأعمدة، لذا نمرر المعامل axis=1.
```{code-cell} ipython3 pollutants = np.concatenate((pollutants_A_24hr_avg, pollutants_B_8hr_avg), axis=1)
### المؤشرات الفرعية (Sub-indices)
يتم حساب sub-indices لكل ملوث وفقاً للعلاقة الخطية بين AQI ونطاقات نقاط الانقطاع القياسية باستخدام الصيغة المذكورة أعلاه:
$$
Ip = \dfrac{\text{IHi – ILo}}{\text{BPHi – BPLo}}\cdot{\text{Cp – BPLo}} + \text{ILo}
$$
تقوم دالة `compute_indices` أولاً بجلب الحدود العليا والدنيا الصحيحة لفئات AQI وتركيزات نقاط الانقطاع للتركيز والملوث المدخلين بمساعدة مصفوفات `AQI` و `breakpoints` التي أنشأناها أعلاه. ثم تقوم بتغذية هذه القيم في الصيغة لحساب المؤشر الفرعي.
```{code-cell} ipython3
def compute_indices(pol, con):
bp = breakpoints[pol]
if pol == 'CO':
inc = 0.1
else:
inc = 1
if bp[0] <= con < bp[1]:
Bl = bp[0]
Bh = bp[1] - inc
Ih = AQI[1] - inc
Il = AQI[0]
elif bp[1] <= con < bp[2]:
Bl = bp[1]
Bh = bp[2] - inc
Ih = AQI[2] - inc
Il = AQI[1]
elif bp[2] <= con < bp[3]:
Bl = bp[2]
Bh = bp[3] - inc
Ih = AQI[3] - inc
Il = AQI[2]
elif bp[3] <= con < bp[4]:
Bl = bp[3]
Bh = bp[4] - inc
Ih = AQI[4] - inc
Il = AQI[3]
elif bp[4] <= con < bp[5]:
Bl = bp[4]
Bh = bp[5] - inc
Ih = AQI[5] - inc
Il = AQI[4]
elif bp[5] <= con:
Bl = bp[5]
Bh = bp[5] + bp[4] - (2 * inc)
Ih = AQI[6]
Il = AQI[5]
else:
print("Concentration out of range!")
return ((Ih - Il) / (Bh - Bl)) * (con - Bl) + Il
سنستخدم np.vectorize للاستفادة من مفهوم الاتجاهية (vectorization). وهذا يعني ببساطة أننا لا نحتاج إلى المرور عبر كل عنصر في مصفوفة الملوثات بأنفسنا. تعد Vectorization واحدة من المزايا الرئيسية لـ NumPy.
```{code-cell} ipython3 vcompute_indices = np.vectorize(compute_indices)
من خلال استدعاء دالتنا الموجهة `vcompute_indices` لكل ملوث، نحصل على المؤشرات الفرعية. للعودة إلى مصفوفة بالشكل الأصلي، نستخدم [np.stack](https://numpy.org/devdocs/reference/generated/numpy.stack.html).
```{code-cell} ipython3
sub_indices = np.stack((vcompute_indices('PM2.5', pollutants[..., 0]),
vcompute_indices('PM10', pollutants[..., 1]),
vcompute_indices('NO2', pollutants[..., 2]),
vcompute_indices('NH3', pollutants[..., 3]),
vcompute_indices('SO2', pollutants[..., 4]),
vcompute_indices('CO', pollutants[..., 5]),
vcompute_indices('O3', pollutants[..., 6])), axis=1)
مؤشرات جودة الهواء (Air quality indices)
باستخدام np.max، نجد الحد الأقصى للمؤشر الفرعي لكل فترة، وهو Air Quality Index الخاص بنا!
```{code-cell} ipython3 aqi_array = np.max(sub_indices, axis=1)
بهذا، أصبح لدينا AQI لكل ساعة من 1 يونيو 2019 إلى 30 يونيو 2020. لاحظ أنه على الرغم من أننا بدأنا بالبيانات من 31 مايو، إلا أننا قمنا باقتطاعها خلال خطوة moving averages.
+++
## اختبار t لستودنت المقترن على قيم AQI (Paired Student's t-test on the AQIs)
اختبار الفرضيات (Hypothesis testing) هو شكل من أشكال الإحصاء الوصفي المستخدم لمساعدتنا في اتخاذ القرارات بناءً على البيانات. من بيانات AQI المحسوبة، نريد معرفة ما إذا كان هناك فرق ذو دلالة إحصائية في متوسط AQI قبل وبعد فرض الإغلاق. سنستخدم [paired Student's t-test](https://en.wikipedia.org/wiki/Student%27s_t-test#Dependent_t-test_for_paired_samples) ذو الطرف الأيسر لحساب إحصائيتين للاختبار - [`إحصائية t` (t statistic)](https://en.wikipedia.org/wiki/T-statistic) و [`قيمة p` (p value)](https://en.wikipedia.org/wiki/P-value). سنقوم بعد ذلك بمقارنة هذه القيم مع القيم الحرجة المقابلة لاتخاذ القرار.

### أخذ العينات (Sampling)
```{code-cell} ipython3
datetime = np.loadtxt("air-quality-data.csv", dtype='M8[h]', delimiter=",",
skiprows=1, usecols=(0, ))[-(pollutants_A_24hr_avg.shape[0]):]
بما أن الإغلاق التام بدأ في دلهي من 24 مارس 2020، فإن المجموعة الفرعية لما بعد الإغلاق هي للفترة من 24 مارس 2020 إلى 30 يونيو 2020. المجموعة الفرعية لما قبل الإغلاق هي لنفس الفترة الزمنية قبل 24 مارس.
```{code-cell} ipython3 after_lock = aqi_array[np.where(datetime >= np.datetime64('2020-03-24T00'))]
before_lock = aqi_array[np.where(datetime <= np.datetime64('2020-03-21T00'))][-(after_lock.shape[0]):]
print(after_lock.shape) print(before_lock.shape)
للتأكد من أن عيناتنا موزعة توزيعاً طبيعياً *تقريباً*، نأخذ عينات بحجم `n = 30`. `before_sample` و `after_sample` هما مجموعة الملاحظات العشوائية المسحوبة قبل وبعد الإغلاق التام. نستخدم [random.Generator.choice](https://numpy.org/devdocs/reference/random/generated/numpy.random.Generator.choice.html) لتوليد العينات.
```{code-cell} ipython3
rng = default_rng()
before_sample = rng.choice(before_lock, size=30, replace=False)
after_sample = rng.choice(after_lock, size=30, replace=False)
تعريف الفرضية (Defining the hypothesis)
دعونا نفترض أنه لا يوجد فرق جوهري بين متوسطات العينات قبل وبعد الإغلاق. ستكون هذه هي الفرضية الصفرية (null hypothesis). الفرضية البديلة (alternative hypothesis) ستكون أن هناك فرقاً جوهرياً بين المتوسطات وأن AQI قد تحسن. رياضياً:
$H_{0}: \mu_\text{after-before} = 0$ \ $H_{a}: \mu_\text{after-before} < 0$
+++
حساب إحصائيات الاختبار (Calculating the test statistics)
سنستخدم إحصائية t لتقييم فرضيتنا وحتى حساب p value منها. صيغة إحصائية t هي:
$$ t = \frac{\mu_\text{after-before}}{\sqrt{\sigma^{2}/n}} $$
حيث:
$\mu_\text{after-before}$ = متوسط فروق العينات \ $\sigma^{2}$ = تباين متوسط الفروق \ $n$ = حجم العينة
```{code-cell} ipython3 def t_test(x, y): diff = y - x var = np.var(diff, ddof=1) num = np.mean(diff) denom = np.sqrt(var / len(x)) return np.divide(num, denom)
t_value = t_test(before_sample, after_sample)
بالنسبة لـ `p value` ، سنستخدم دالة `stats.distributions.t.cdf()` من SciPy. وهي تأخذ وسيطين - `t statistic` ودرجات الحرية (`dof`). صيغة `dof` هي `n - 1`.
```{code-cell} ipython3
dof = len(before_sample) - 1
p_value = stats.distributions.t.cdf(t_value, dof)
print("The t value is {} and the p value is {}.".format(t_value, p_value))
ماذا تعني قيم t و p؟ (What do the t and p values mean?)
سنقوم الآن بمقارنة إحصائيات الاختبار المحسوبة مع إحصائيات الاختبار الحرجة. يتم حساب قيمة t الحرجة من خلال البحث في جدول توزيع t (t-distribution table).
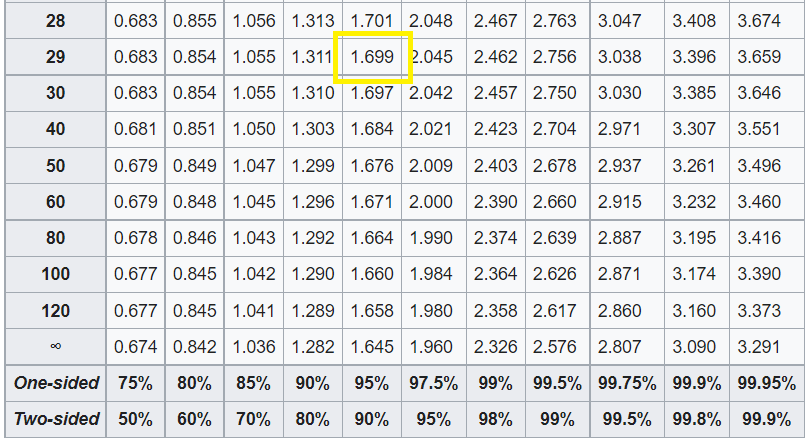
من الجدول أعلاه، القيمة الحرجة هي 1.699 لـ 29 dof عند مستوى ثقة 95%. بما أننا نستخدم اختبار الطرف الأيسر، فإن قيمتنا الحرجة هي -1.699. من الواضح أن قيمة t المحسوبة أقل من القيمة الحرجة، لذا يمكننا رفض null hypothesis بأمان.
قيمة p الحرجة، والتي يرمز لها بـ $\alpha$ ، عادة ما يتم اختيارها لتكون 0.05، وهو ما يقابل مستوى ثقة 95%. إذا كانت p value المحسوبة أقل من $\alpha$ ، فيمكن رفض null hypothesis بأمان. من الواضح أن p value لدينا أقل بكثير من $\alpha$ ، لذا يمكننا رفض null hypothesis.
لاحظ أن هذا لا يعني أنه يمكننا قبول alternative hypothesis. إنه يخبرنا فقط أنه لا يوجد دليل كافٍ لرفض $H_{a}$. بعبارة أخرى، فشلنا في رفض alternative hypothesis، لذا قد تكون صحيحة.
+++
في الممارسة العملية... (In practice...)
-
يفضل استخدام مكتبة pandas لتحليل بيانات السلاسل الزمنية (time-series data).
-
توفر وحدة SciPy stats دالة stats.ttest_rel والتي يمكن استخدامها للحصول على
t statisticوp value. -
في الحياة الواقعية، لا تكون البيانات عادةً موزعة توزيعاً طبيعياً. هناك اختبارات لمثل هذه البيانات غير الطبيعية مثل اختبار ويلكوكسون (Wilcoxon test).
قراءات إضافية (Further reading)
-
هناك مجموعة من الاختبارات الإحصائية التي يمكنك اختيارها وفقاً لخصائص البيانات المعطاة. اقرأ المزيد عنها في مقدمة لطيفة لتوزيعات البيانات الإحصائية (A Gentle Introduction to Statistical Data Distributions).
-
هناك إصدارات مختلفة من Student's t-test التي يمكنك اعتمادها وفقاً لاحتياجاتك.