التعلم العميق على مجموعة بيانات MNIST (Deep learning on MNIST)
يوضح هذا الدليل التعليمي (Tutorial) كيفية بناء شبكة عصبية أمامية التغذية (Feedforward Neural Network) بسيطة (بطبقة مخفية واحدة) وتدريبها من الصفر باستخدام NumPy للتعرف على صور الأرقام المكتوبة بخط اليد.
سيتعلم نموذج التعلم العميق (Deep Learning) الخاص بك — وهو أحد أبسط الشبكات العصبية الاصطناعية (Artificial Neural Networks) التي تشبه المدرك متعدد الطبقات (Multi-layer Perceptron) الأصلي — كيفية تصنيف الأرقام من 0 إلى 9 من مجموعة بيانات MNIST. تحتوي مجموعة البيانات (Dataset) على 60,000 صورة للتدريب و 10,000 صورة للاختبار مع التسميات (Labels) المقابلة لها. يبلغ حجم كل صورة تدريب واختبار 784 (أو 28×28 بكسل) — سيكون هذا هو المدخل (Input) للشبكة العصبية.
بناءً على مدخلات الصور وتسمياتها (التعلم الخاضع للإشراف - Supervised Learning)، سيتم تدريب شبكتك العصبية لتعلم ميزاتها (Features) باستخدام الانتشار الأمامي (Forward Propagation) والانتشار العكسي (Backpropagation) (التفاضل في الوضع العكسي - Reverse-mode Differentiation). المخرج (Output) النهائي للشبكة هو متجه (Vector) مكون من 10 درجات — درجة واحدة لكل صورة رقم مكتوب بخط اليد. ستقوم أيضاً بتقييم مدى جودة نموذجك في تصنيف الصور على مجموعة الاختبار (Test Set).
تم اقتباس هذا الـ Tutorial من عمل أندرو تراسك (بإذن من المؤلف).
المتطلبات المسبقة (Prerequisites)
يجب أن يكون لدى القارئ بعض المعرفة بلغة Python، ومعالجة مصفوفات (Arrays) NumPy، والجبر الخطي (Linear Algebra). بالإضافة إلى ذلك، يجب أن تكون على دراية بالمفاهيم الرئيسية لـ Deep Learning.
لتنشيط الذاكرة، يمكنك الاطلاع على أدلة Python و الجبر الخطي على المصفوفات n-dimensional.
يُنصح بقراءة ورقة Deep Learning المنشورة في عام 2015 من قبل يان ليكون، ويوشوا بنجيو، وجيفري هينتون، الذين يعتبرون من رواد هذا المجال. يجب عليك أيضاً التفكير في قراءة كتاب أندرو تراسك Grokking Deep Learning، الذي يعلم Deep Learning باستخدام NumPy.
بالإضافة إلى NumPy، ستستخدم وحدات Python القياسية (Modules) التالية لتحميل البيانات ومعالجتها:
- urllib للتعامل مع روابط URL
- request لفتح روابط URL
- gzip لفك ضغط ملفات gzip
- pickle للعمل مع تنسيق ملفات pickle
وكذلك: - Matplotlib لتصور البيانات (Data Visualization)
يمكن تشغيل هذا الـ Tutorial محلياً في بيئة معزولة (Isolated Environment)، مثل Virtualenv أو conda. يمكنك استخدام Jupyter Notebook أو JupyterLab لتشغيل كل خلية (Cell) في المفكرة. لا تنسَ إعداد NumPy و Matplotlib.
جدول المحتويات
- تحميل مجموعة بيانات MNIST
- معالجة مجموعة البيانات مسبقاً
- بناء وتدريب شبكة عصبية صغيرة من الصفر
- الخطوات التالية
1. تحميل مجموعة بيانات MNIST (Load the MNIST dataset)
في هذا القسم، ستقوم بتنزيل ملفات Dataset لـ MNIST المضغوطة التي طورها فريق بحث يان ليكون في الأصل. (يتوفر المزيد من التفاصيل حول MNIST Dataset على Kaggle.) بعد ذلك، ستقوم بتحويلها إلى 4 ملفات من نوع NumPy Array باستخدام Modules لغة Python المدمجة. أخيراً، ستقوم بتقسيم الـ Arrays إلى مجموعات تدريب واختبار.
1. قم بتعريف متغير (Variable) لتخزين أسماء صور/تسميات التدريب/الاختبار لـ MNIST Dataset في قائمة:
data_sources = {
"training_images": "train-images-idx3-ubyte.gz", # 60,000 training images.
"test_images": "t10k-images-idx3-ubyte.gz", # 10,000 test images.
"training_labels": "train-labels-idx1-ubyte.gz", # 60,000 training labels.
"test_labels": "t10k-labels-idx1-ubyte.gz", # 10,000 test labels.
}
2. تحميل البيانات. تحقق أولاً مما إذا كانت البيانات مخزنة محلياً؛ إذا لم تكن كذلك، فقم بتنزيلها.
:tags: [remove-cell]
# Use responsibly! When running notebooks locally, be sure to keep local
# copies of the datasets to prevent unnecessary server requests
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:10.0) Gecko/20100101 Firefox/10.0"
}
request_opts = {
"headers": headers,
"params": {"raw": "true"},
}
import requests
import os
data_dir = "../_data"
os.makedirs(data_dir, exist_ok=True)
base_url = "https://ossci-datasets.s3.amazonaws.com/mnist/"
for fname in data_sources.values():
fpath = os.path.join(data_dir, fname)
if not os.path.exists(fpath):
print("Downloading file: " + fname)
resp = requests.get(base_url + fname, stream=True, **request_opts)
resp.raise_for_status() # Ensure download was succesful
with open(fpath, "wb") as fh:
for chunk in resp.iter_content(chunk_size=128):
fh.write(chunk)
3. فك ضغط الملفات الأربعة وإنشاء 4 ndarrays، وحفظها في قاموس (Dictionary). يبلغ حجم كل صورة أصلية 28×28 وتتوقع الشبكات العصبية عادةً مدخلاً من نوع Vector أحادي الأبعاد؛ لذلك، تحتاج أيضاً إلى إعادة تشكيل (Reshape) الصور عن طريق ضرب 28 في 28 (784).
import gzip
import numpy as np
mnist_dataset = {}
# Images
for key in ("training_images", "test_images"):
with gzip.open(os.path.join(data_dir, data_sources[key]), "rb") as mnist_file:
mnist_dataset[key] = np.frombuffer(
mnist_file.read(), np.uint8, offset=16
).reshape(-1, 28 * 28)
# Labels
for key in ("training_labels", "test_labels"):
with gzip.open(os.path.join(data_dir, data_sources[key]), "rb") as mnist_file:
mnist_dataset[key] = np.frombuffer(mnist_file.read(), np.uint8, offset=8)
4. تقسيم البيانات إلى مجموعات تدريب واختبار باستخدام التدوين القياسي x للبيانات و y للتسميات، وتسمية صور مجموعات التدريب والاختبار بـ x_train و x_test ، والتسميات بـ y_train و y_test:
x_train, y_train, x_test, y_test = (
mnist_dataset["training_images"],
mnist_dataset["training_labels"],
mnist_dataset["test_images"],
mnist_dataset["test_labels"],
)
5. يمكنك التأكد من أن شكل (Shape) مصفوفات الصور هو (60000, 784) و (10000, 784) لمجموعات التدريب والاختبار على التوالي، والتسميات — (60000,) و (10000,):
print(
"The shape of training images: {} and training labels: {}".format(
x_train.shape, y_train.shape
)
)
print(
"The shape of test images: {} and test labels: {}".format(
x_test.shape, y_test.shape
)
)
6. ويمكنك فحص بعض الصور باستخدام Matplotlib:
import matplotlib.pyplot as plt
# Take the 60,000th image (indexed at 59,999) from the training set,
# reshape from (784, ) to (28, 28) to have a valid shape for displaying purposes.
mnist_image = x_train[59999, :].reshape(28, 28)
# Set the color mapping to grayscale to have a black background.
plt.imshow(mnist_image, cmap="gray")
# Display the image.
plt.show()
# Display 5 random images from the training set.
num_examples = 5
seed = 147197952744
rng = np.random.default_rng(seed)
fig, axes = plt.subplots(1, num_examples)
for sample, ax in zip(rng.choice(x_train, size=num_examples, replace=False), axes):
ax.imshow(sample.reshape(28, 28), cmap="gray")
أعلاه توجد خمس صور مأخوذة من مجموعة تدريب MNIST. تظهر أرقام عربية مرسومة يدوياً متنوعة، مع اختيار القيم الدقيقة عشوائياً مع كل تشغيل لـ Code.
ملاحظة: يمكنك أيضاً تصور صورة عينة كـ Array عن طريق طباعة
x_train[59999]. هنا،59999هي عينة صورة التدريب رقم 60,000 (0ستكون الأولى). سيكون مخرجك طويلاً جداً ويجب أن يحتوي على Array من الأعداد الصحيحة ذات 8 بت (8-bit Integers):
... 0, 0, 38, 48, 48, 22, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 62, 97, 198, 243, 254, 254, 212, 27, 0, 0, 0, 0, ...
# Display the label of the 60,000th image (indexed at 59,999) from the training set.
y_train[59999]
2. معالجة البيانات مسبقاً (Preprocess the data)
يمكن للشبكات العصبية العمل مع مدخلات تكون في شكل موترات (Tensors) (مصفوفات متعددة الأبعاد) من نوع الفاصلة العائمة (Floating-point). عند معالجة البيانات مسبقاً، يجب عليك مراعاة العمليات التالية: التحويل إلى متجهات (Vectorization) و التحويل إلى تنسيق الفاصلة العائمة (Conversion to a Floating-point Format).
نظراً لأن بيانات MNIST محولة بالفعل إلى Vector والـ Arrays من نوع dtype uint8 ، فإن التحدي التالي هو تحويلها إلى تنسيق Floating-point، مثل float64 (دقة مزدوجة - Double-precision):
- تطبيع (Normalizing) بيانات الصور: إجراء تغيير حجم الميزات (Feature Scaling) الذي يمكن أن يسرع عملية تدريب الشبكة العصبية من خلال توحيد توزيع بيانات الإدخال.
- ترميز الفئة الواحدة/الترميز الفئوي (One-hot/Categorical Encoding) لتسميات الصور.
# Data normalization
x_train, x_test = x_train / 255.0, x_test / 255.0
# One-hot encoding
def one_hot_encode(labels, num_classes=10):
return np.eye(num_classes)[labels]
y_train = one_hot_encode(y_train)
y_test = one_hot_encode(y_test)
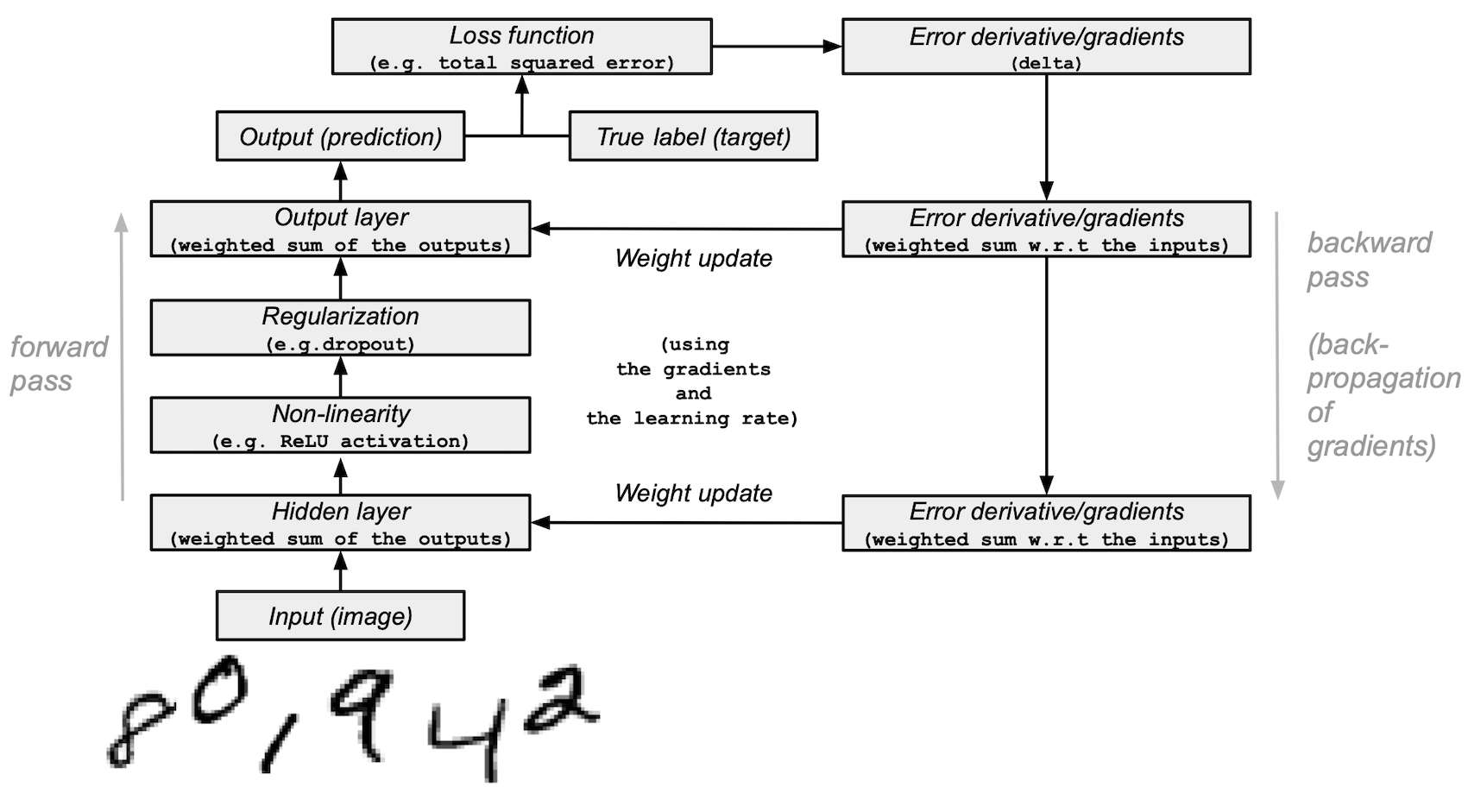
3. بناء وتدريب شبكة عصبية صغيرة من الصفر (Build and train a small neural network from scratch)
في هذا القسم، ستنفذ خوارزمية الانتشار الأمامي و Backpropagation من الصفر باستخدام NumPy.
1. ابدأ بتحديد دالة التنشيط (Activation Function) "وحدة خطية مصححة" (Rectified Linear Unit - ReLU) ومشتقها (Derivative). ستستخدم ReLU في الطبقة المخفية لإدخال اللاخطية (Non-linearity) في النموذج.
def relu(x):
return np.maximum(0, x)
def relu2deriv(output):
return output > 0
2. حدد معلمات التدريب (Training Parameters) مثل معدل التعلم (Learning Rate)، وعدد حقبات التدريب (Epochs)، وحجم الطبقة المخفية، وحجم الإدخال، وعدد الفئات (Classes):
learning_rate = 0.005
epochs = 100
hidden_size = 40
input_size = 784
num_labels = 10
3. تهيئة الأوزان (Initialize Weights) عشوائياً. ستقوم بتهيئة الأوزان بين طبقة الإدخال والطبقة المخفية (weights_1) وبين الطبقة المخفية وطبقة الإخراج (weights_2).
# Seed for reproducibility
seed = 42
rng = np.random.default_rng(seed)
weights_1 = 0.2 * rng.random((input_size, hidden_size)) - 0.1
weights_2 = 0.2 * rng.random((hidden_size, num_labels)) - 0.1
4. تنفيذ حلقة التدريب (Training Loop). في كل Epoch ، ستقوم بالتالي: 1. إجراء Forward Propagation لحساب التنبؤات. 2. حساب الخسارة (Loss) (خطأ المربع المتوسط - Mean Squared Error). 3. إجراء Backpropagation لحساب التدرجات (Gradients). 4. تحديث الأوزان باستخدام نزول التدرج العشوائي (Stochastic Gradient Descent).
# For simplicity, we will use a subset of the data
training_images = x_train[:1000]
training_labels = y_train[:1000]
test_images = x_test
test_labels = y_test
store_training_loss = []
store_training_accurate_pred = []
store_test_loss = []
store_test_accurate_pred = []
for j in range(epochs):
training_loss = 0.0
training_accurate_predictions = 0
for i in range(len(training_images)):
# 1. Forward propagation
layer_0 = training_images[i : i + 1]
layer_1 = relu(np.dot(layer_0, weights_1))
# Optional: apply dropout
dropout_mask = rng.integers(low=0, high=2, size=layer_1.shape)
layer_1 *= dropout_mask * 2
layer_2 = np.dot(layer_1, weights_2)
# 2. Calculate loss
training_loss += np.sum((training_labels[i : i + 1] - layer_2) ** 2)
training_accurate_predictions += int(
np.argmax(layer_2) == np.argmax(training_labels[i])
)
# 3. Differentiate the loss function/error.
layer_2_delta = training_labels[i : i + 1] - layer_2
# 4. Propagate the gradients of the loss function back through the hidden layer.
layer_1_delta = np.dot(layer_2_delta, weights_2.T) * relu2deriv(layer_1)
# 5. Apply the dropout to the gradients.
layer_1_delta *= dropout_mask
# 6. Update the weights for the middle and input layers
# by multiplying them by the learning rate and the gradients.
weights_1 += learning_rate * np.dot(layer_0.T, layer_1_delta)
weights_2 += learning_rate * np.dot(layer_1.T, layer_2_delta)
# Store training set losses and accurate predictions.
store_training_loss.append(training_loss)
store_training_accurate_pred.append(training_accurate_predictions)
###################
# Evaluation step #
###################
# Evaluate model performance on the test set at each epoch.
# Unlike the training step, the weights are not modified for each image
# (or batch). Therefore the model can be applied to the test images in a
# vectorized manner, eliminating the need to loop over each image
# individually:
results = relu(test_images @ weights_1) @ weights_2
# Measure the error between the actual label (truth) and prediction values.
test_loss = np.sum((test_labels - results) ** 2)
# Measure prediction accuracy on test set
test_accurate_predictions = np.sum(
np.argmax(results, axis=1) == np.argmax(test_labels, axis=1)
)
# Store test set losses and accurate predictions.
store_test_loss.append(test_loss)
store_test_accurate_pred.append(test_accurate_predictions)
# Summarize error and accuracy metrics at each epoch
if j % 10 == 0 or j == epochs - 1:
print(
(
f"Epoch: {j}\n"
f" Training set error: {training_loss / len(training_images):.3f}\n"
f" Training set accuracy: {training_accurate_predictions / len(training_images)}\n"
f" Test set error: {test_loss / len(test_images):.3f}\n"
f" Test set accuracy: {test_accurate_predictions / len(test_images)}"
)
)
قد تستغرق عملية التدريب عدة دقائق، اعتماداً على عدد من العوامل، مثل قوة معالجة الجهاز الذي تقوم بتشغيل التجربة عليه وعدد الـ Epochs. لتقليل وقت الانتظار، يمكنك تغيير متغير Epoch (التكرار) من 100 إلى رقم أقل، وإعادة ضبط وقت التشغيل (مما سيؤدي إلى إعادة ضبط الأوزان)، وتشغيل Cells المفكرة مرة أخرى.
+++
بعد تنفيذ الخلية أعلاه، يمكنك تصور أخطاء ودقة مجموعات التدريب والاختبار لمثيل من عملية التدريب هذه.
epoch_range = np.arange(epochs) + 1 # Starting from 1
# The training set metrics.
training_metrics = {
"accuracy": np.asarray(store_training_accurate_pred) / len(training_images),
"error": np.asarray(store_training_loss) / len(training_images),
}
# The test set metrics.
test_metrics = {
"accuracy": np.asarray(store_test_accurate_pred) / len(test_images),
"error": np.asarray(store_test_loss) / len(test_images),
}
# Display the plots.
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 5))
for ax, metrics, title in zip(
axes, (training_metrics, test_metrics), ("Training set", "Test set")
):
# Plot the metrics
for metric, values in metrics.items():
ax.plot(epoch_range, values, label=metric.capitalize())
ax.set_title(title)
ax.set_xlabel("Epochs")
ax.legend()
plt.show()
يظهر خطأ التدريب والاختبار أعلاه في المخططين الأيسر والأيمن على التوالي. مع زيادة عدد الـ Epochs ، ينخفض إجمالي الخطأ وتزداد الدقة.
قد تكون معدلات الدقة التي يصل إليها نموذجك أثناء التدريب والاختبار معقولة إلى حد ما، ولكن قد تجد أيضاً أن معدلات الخطأ مرتفعة جداً.
لتقليل الخطأ أثناء التدريب والاختبار، يمكنك التفكير في تغيير دالة الخسارة البسيطة إلى، على سبيل المثال، الاعتلاج المتقاطع (Cross-entropy) الفئوي. يتم مناقشة الحلول الممكنة الأخرى أدناه.
الخطوات التالية (Next steps)
لقد تعلمت كيفية بناء وتدريب شبكة عصبية أمامية التغذية بسيطة من الصفر باستخدام NumPy فقط لتصنيف أرقام MNIST المكتوبة بخط اليد.
لمزيد من التعزيز والتحسين لنموذج الشبكة العصبية الخاص بك، يمكنك التفكير في واحد أو مزيج مما يلي: - زيادة حجم عينة التدريب من 1,000 إلى رقم أعلى (يصل إلى 60,000). - استخدام الدفعات الصغيرة وتقليل معدل التعلم (Mini-batches and reduce the Learning Rate). - تغيير المعمارية عن طريق إدخال المزيد من الطبقات المخفية لجعل الشبكة أعمق (Deeper). - دمج دالة خسارة Cross-entropy مع دالة تنشيط softmax في الطبقة الأخيرة. - إدخال طبقات تلافيفية: استبدال الشبكة أمامية التغذية بمعمارية شبكة عصبية تلافيفية (Convolutional Neural Network). - استخدام حجم Epoch أعلى للتدريب لفترة أطول وإضافة المزيد من تقنيات التنظيم (Regularization)، مثل التوقف المبكر (Early Stopping)، لمنع فرط التخصيص (Overfitting). - إدخال مجموعة تحقق (Validation Set) لتقييم غير متحيز لملاءمة النموذج. - تطبيق تطبيع الدفعة (Batch Normalization) لتدريب أسرع وأكثر استقراراً. - ضبط المعلمات الأخرى، مثل Learning Rate وحجم الطبقة المخفية.
يعد بناء شبكة عصبية من الصفر باستخدام NumPy طريقة رائعة لمعرفة المزيد عن NumPy وعن Deep Learning. ومع ذلك، بالنسبة للتطبيقات الواقعية، يجب عليك استخدام أطر عمل متخصصة — مثل PyTorch، أو JAX، أو TensorFlow، أو MXNet — التي توفر واجهات برمجة تطبيقات (APIs) تشبه NumPy، وتحتوي على تمايز تلقائي (Automatic Differentiation) مدمج ودعم لوحدات معالجة الرسومات (GPU)، وهي مصممة للحوسبة العددية عالية الأداء وتعلم الآلة.
أخيراً، عند تطوير نموذج تعلم آلة، يجب عليك التفكير في القضايا الأخلاقية المحتملة وتطبيق الممارسات لتجنبها أو التخفيف منها: - توثيق نموذج مدرب باستخدام بطاقة نموذج (Model Card) - انظر ورقة Model Cards for Model Reporting بقلم مارجريت ميتشل وآخرون. - توثيق Dataset باستخدام ورقة بيانات (Datasheet) - انظر ورقة Datasheets for Datasets بقلم تمنيت جيبرو وآخرون. - فكر في تأثير نموذجك - من يتأثر به، ومن يستفيد منه - انظر المقال و المحادثة بقلم براتيوشا كالوري. - لمزيد من الموارد، انظر هذه التدوينة بقلم راشيل توماس وبودكاست Radical AI.
(الشكر لـ hsjeong5 لتوضيح كيفية تنزيل MNIST دون استخدام مكتبات خارجية.)