تحديد قانون مور باستخدام بيانات حقيقية في NumPy
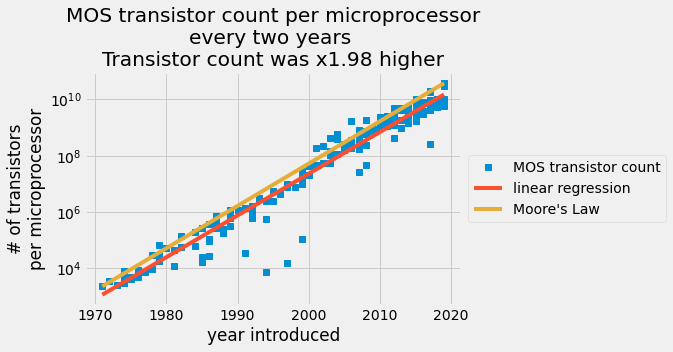
عدد الترانزستورات المسجلة لكل شريحة معينة مرسوماً بمقياس لوغاريتمي على المحور y مع تاريخ الإصدار على المحور x الخطي. نقاط البيانات الزرقاء مأخوذة من جدول عدد الترانزستورات. الخط الأحمر هو تنبؤ المربعات الصغرى العادية والخط البرتقالي هو قانون مور.
ما ستفعله
في عام 1965، تنبأ المهندس جوردون مور (Gordon Moore) بأن الترانزستورات (Transistors) الموجودة على الشريحة ستتضاعف كل عامين في العقد القادم [1]. ستقوم بمقارنة تنبؤ مور مع الأعداد الفعلية للترانزستورات في الـ 53 عاماً التي تلت تنبؤه. ستحدد الثوابت الأنسب لوصف النمو الأسي (Exponential Growth) للترانزستورات على أشباه الموصلات مقارنة بقانون مور (Moore's Law).
المهارات التي ستتعلمها
- تحميل البيانات من ملف *.csv
- إجراء الانحدار الخطي (Linear Regression) والتنبؤ بالنمو الأسي باستخدام المربعات الصغرى العادية (Ordinary Least Squares)
- ستقارن ثوابت النمو الأسي بين النماذج
- مشاركة تحليلك في ملف:
- كملفات NumPy مضغوطة
*.npz - كملف
*.csv
- كملفات NumPy مضغوطة
- تقييم التقدم المذهل الذي أحرزه مصنعو أشباه الموصلات في العقود الخمسة الماضية
ما ستحتاجه
1. هذه الحزم (Packages):
- NumPy
- Matplotlib
المستوردة بالأوامر التالية:
import matplotlib.pyplot as plt
import numpy as np
2. بما أن هذا قانون نمو أسي، فأنت بحاجة إلى خلفية بسيطة في الرياضيات المتعلقة بـ اللوغاريتمات الطبيعية (Natural Logs) و الدوال الأسية (Exponentials).
ستستخدم دوال NumPy و Matplotlib التالية:
np.loadtxt: تقوم هذه الدالة (Function) بتحميل النص في مصفوفة (Array) NumPy.np.log: تأخذ هذه الدالة اللوغاريتم الطبيعي لجميع العناصر في Array لـ NumPy.np.exp: تأخذ هذه الدالة القيمة الأسية لجميع العناصر في Array لـ NumPy.lambda: هذا تعريف دالة بسيط لإنشاء نموذج دالة.plt.semilogy: تقوم هذه الدالة برسم بيانات x-y على شكل بياني بمحور x خطي ومحور y بمقياس $\log_{10}$.plt.plot: تقوم هذه الدالة برسم بيانات x-y على محاور خطية.- تقطيع المصفوفات (Slicing Arrays): عرض أجزاء من البيانات المحملة في مساحة العمل، مثل
x[:10]لأول 10 قيم في المصفوفةx. - الفهرسة البولينية للمصفوفات (Boolean Array Indexing): لعرض أجزاء البيانات التي تطابق شرطاً معيناً باستخدام العمليات البولينية لفهرسة مصفوفة.
np.block: لدمج المصفوفات في مصفوفات ثنائية الأبعاد (2D Arrays).np.newaxis: لتغيير متجه (Vector) أحادي الأبعاد إلى متجه صف أو عمود.np.savezوnp.savetxt: هاتان الدالتان ستحفظان مصفوفاتك بتنسيق مصفوفة مضغوط ونصي، على التوالي.
+++
بناء قانون مور كدالة أسية (Building Moore's law as an exponential function)
يفترض نموذجك التجريبي أن عدد الترانزستورات لكل شبه موصل يتبع نمواً أسياً،
$\log(\text{transistor_count})= f(\text{year}) = A\cdot \text{year}+B$,
حيث $A$ و $B$ هما ثوابت الملاءمة. تستخدم بيانات مصنعي أشباه الموصلات للعثور على ثوابت الملاءمة.
تحدد هذه الثوابت لقانون مور عن طريق تحديد معدل الترانزستورات المضافة، 2، وإعطاء عدد أولي من الترانزستورات لسنة معينة.
تضع قانون مور في شكل أسي كما يلي،
$\text{transistor_count}= e^{A_M\cdot \text{year} +B_M}.$
حيث $A_M$ و $B_M$ هما ثابتان يضاعفان عدد الترانزستورات كل عامين ويبدآن بـ 2250 ترانزستور في عام 1971،
-
$\dfrac{\text{transistor_count}(\text{year} +2)}{\text{transistor_count}(\text{year})} = 2 = \dfrac{e^{B_M}e^{A_M \text{year} + 2A_M}}{e^{B_M}e^{A_M \text{year}}} = e^{2A_M} \rightarrow $A_M = \frac{\log(2)}{2}$
-
$\log(2250) = \frac{\log(2)}{2}\cdot 1971 + B_M \rightarrow B_M = \log(2250)-\frac{\log(2)}{2}\cdot 1971$
لذا فإن قانون مور المصاغ كدالة أسية هو
$\log(\text{transistor_count})= A_M\cdot \text{year}+B_M,$
حيث
$A_M=0.3466$
$B_M=-675.4$
بما أن الدالة تمثل Moore's Law، فقم بتعريفها كدالة Python باستخدام lambda:
A_M = np.log(2) / 2
B_M = np.log(2250) - A_M * 1971
Moores_law = lambda year: np.exp(B_M) * np.exp(A_M * year)
في عام 1971، كان هناك 2250 ترانزستور على شريحة Intel 4004. استخدم Moores_law للتحقق من عدد أشباه الموصلات التي كان جوردون مور يتوقعها في عام 1973.
ML_1971 = Moores_law(1971)
ML_1973 = Moores_law(1973)
print("In 1973, G. Moore expects {:.0f} transistors on Intels chips".format(ML_1973))
print("This is x{:.2f} more transistors than 1971".format(ML_1973 / ML_1971))
تحميل بيانات التصنيع التاريخية إلى مساحة العمل الخاصة بك (Loading historical manufacturing data to your workspace)
الآن، قم بإجراء تنبؤ بناءً على البيانات التاريخية لأشباه الموصلات لكل شريحة. يوجد عدد الترانزستورات [3] لكل عام في ملف transistor_data.csv. قبل تحميل ملف *.csv في مصفوفة NumPy، من الجيد فحص بنية الملف أولاً. ثم حدد الأعمدة ذات الأهمية واحفظها في متغير. احفظ عمودين من الملف في المصفوفة data.
هنا، اطبع أول 10 صفوف من transistor_data.csv. الأعمدة هي:
| المعالج (Processor) | عدد ترانزستورات MOS | تاريخ الإصدار | المصمم (Designer) | عملية MOS | المساحة |
|---|---|---|---|---|---|
| Intel 4004 (4-bit 16-pin) | 2250 | 1971 | Intel | "10,000 nm" | 12 mm² |
| ... | ... | ... | ... | ... | ... |
! head transistor_data.csv
لا تحتاج إلى الأعمدة التي تحدد Processor أو Designer أو MOSprocess أو Area. يترك ذلك العمودين الثاني والثالث، MOS transistor count و Date of Introduction ، على التوالي.
بعد ذلك، تقوم بتحميل هذين العمودين في مصفوفة NumPy باستخدام np.loadtxt. ستضع الخيارات الإضافية أدناه البيانات بالتنسيق المطلوب:
delimiter = ',': تحديد الفاصل كفاصلة (هذا هو السلوك الافتراضي)usecols = [1,2]: استيراد العمودين الثاني والثالث من ملف csvskiprows = 1: عدم استخدام الصف الأول، لأنه صف رأس (Header Row)
data = np.loadtxt("transistor_data.csv", delimiter=",", usecols=[1, 2], skiprows=1)
لقد قمت بتحميل التاريخ الكامل لأشباه الموصلات في مصفوفة NumPy تسمى data. العمود الأول هو MOS transistor count والعمود الثاني هو Date of Introduction كسنة مكونة من أربعة أرقام.
بعد ذلك، اجعل البيانات أسهل في القراءة والإدارة عن طريق تعيين العمودين للمتغيرين year و transistor_count. اطبع أول 10 قيم عن طريق تقطيع (Slicing) مصفوفات year و transistor_count بـ [:10]. اطبع هذه القيم للتحقق من أنك قمت بحفظ البيانات في المتغيرات الصحيحة.
year = data[:, 1] # جلب العمود الثاني وتعيينه
transistor_count = data[:, 0] # جلب العمود الأول وتعيينه
print("year:\t\t", year[:10])
print("trans. cnt:\t", transistor_count[:10])
أنت تقوم بإنشاء دالة تتنبأ بعدد الترانزستورات بمعلومية السنة. لديك متغير مستقل (Independent Variable)، year ، و متغير تابع (Dependent Variable)، transistor_count. قم بتحويل المتغير التابع إلى مقياس لوغاريتمي،
$y_i = \log($ transistor_count[i] $),$
مما ينتج عنه معادلة خطية،
$y_i = A\cdot \text{year} +B$.
yi = np.log(transistor_count)
حساب منحنى النمو التاريخي للترانزستورات (Calculating the historical growth curve for transistors)
يفترض نموذجك أن yi هي دالة في year. الآن، ابحث عن نموذج الملاءمة الأفضل الذي يقلل الفرق بين $y_i$ و $A\cdot \text{year} +B, $ كما يلي:
$\min \sum|y_i - (A\cdot \text{year}_i + B)|^2.$
يمكن تمثيل خطأ مجموع المربعات هذا بإيجاز كمصفوفات كما يلي:
$\sum|\mathbf{y}-\mathbf{Z} [A,~B]^T|^2,$
حيث $\mathbf{y}$ هي ملاحظات لوغاريتم عدد الترانزستورات في مصفوفة أحادية الأبعاد و $\mathbf{Z}=[\text{year}_i^1,~\text{year}_i^0]$ هي حدود كثيرات الحدود لـ $\text{year}_i$ في العمودين الأول والثاني. من خلال إنشاء هذه المجموعة من المتغيرات المفسرة (Regressors) في مصفوفة $\mathbf{Z}-$ ، فإنك تقوم بإعداد نموذج إحصائي للمربعات الصغرى العادية.
Z هو نموذج خطي بمعلمتين، أي كثير حدود من الدرجة 1. لذلك يمكننا تمثيل النموذج بـ numpy.polynomial.Polynomial واستخدام وظيفة الملاءمة (Fitting) لتحديد معلمات النموذج:
model = np.polynomial.Polynomial.fit(year, yi, deg=1)
بشكل افتراضي، تقوم Polynomial.fit بإجراء الملاءمة في النطاق المحدد بواسطة المتغير المستقل (year في هذه الحالة). يمكن استعادة المعاملات للنموذج غير المقاس وغير المزاح باستخدام طريقة convert:
model = model.convert()
model
المعلمات الفردية $A$ و $B$ هي معاملات نموذجنا الخطي:
B, A = model
هل ضاعف المصنعون عدد الترانزستورات كل عامين؟ لديك الصيغة النهائية،
$\dfrac{\text{transistor_count}(\text{year} +2)}{\text{transistor_count}(\text{year})} = xFactor = \dfrac{e^{B}e^{A( \text{year} + 2)}}{e^{B}e^{A \text{year}}} = e^{2A}$
حيث الزيادة في عدد الترانزستورات هي $xFactor,$ وعدد السنوات هو 2، و $A$ هو ميل الملاءمة الأفضل على الدالة شبه اللوغاريتمية.
print(f"Rate of semiconductors added on a chip every 2 years: {np.exp(2 * A):.2f}")
(محتوى محذوف للاختصار...)
delimiter = ',': استخدم الفواصل لفصل الأعمدة في الملفheader = head: استخدم الرأسheadالمحدد أعلاه
np.savetxt("mooreslaw_regression.csv", X=output, delimiter=",", header=head)
! head mooreslaw_regression.csv
الختام (Wrapping up)
في الختام، قمت بمقارنة البيانات التاريخية لمصنعي أشباه الموصلات بقانون مور وأنشأت نموذج انحدار خطي للعثور على متوسط عدد الترانزستورات المضافة إلى كل معالج دقيق كل عامين. تنبأ جوردون مور بأن عدد الترانزستورات سيتضاعف كل عامين من عام 1965 حتى عام 1975، لكن متوسط النمو حافظ على زيادة ثابتة قدرها $\times 1.98 \pm 0.01$ كل عامين من عام 1971 حتى عام 2019. في عام 2015، راجع مور تنبؤه ليقول إن Moore's Law يجب أن يستمر حتى عام 2025 [2]. يمكنك مشاركة هذه النتائج كملف مصفوفة NumPy مضغوط، mooreslaw_regression.npz ، أو كملف csv آخر، mooreslaw_regression.csv. لقد مكن التقدم المذهل في تصنيع أشباه الموصلات صناعات جديدة وقوة حوسبة هائلة. يجب أن يعطيك هذا التحليل نظرة بسيطة حول مدى روعة هذا النمو على مدار نصف القرن الماضي.
+++