لغة برمجة Rust
بقلم ستيف كلابنيك، كارول نيكولز، وكريس كرايشو، بمساهمات من مجتمع Rust
تفترض هذه النسخة من النص أنك تستخدم Rust 1.90.0 (الإصدار 1.90.0) الصادر في 2025-09-18 أو إصدارًا أحدث مع تعيين edition = "2024" في ملف Cargo.toml الخاص بجميع المشاريع لتكوينها لاستخدام أساليب برمجية (Idioms) إصدار Rust 2024. راجع قسم التثبيت (Installation) في الفصل 1 للحصول على تعليمات حول تثبيت Rust أو تحديثه، وراجع الملحق هـ (Appendix E) لمعلومات عن الإصدارات.
يتوفر التنسيق HTML عبر الإنترنت على https://doc.rust-lang.org/stable/book/ وبشكل غير متصل مع تثبيتات Rust التي تمت باستخدام rustup؛ شغّل الأمر rustup doc --book لفتحه.
تتوفر أيضًا عدة [ترجمات] من المجتمع.
يتوفر هذا النص في صيغة كتاب ورقي وكتاب إلكتروني من دار No Starch Press.
🚨 هل تريد تجربة تعلم أكثر تفاعلية؟ جرّب إصدارًا مختلفًا من كتاب Rust، يتضمن: اختبارات، تمييز، تصورات، والمزيد: https://rust-book.cs.brown.edu
مقدمة
لقد قطعَت لغة البرمجة Rust شوطًا طويلًا في سنوات قليلة فقط، بدءًا من إنشائها واحتضانها من قِبل مجتمع صغير وناشئ من المهتمين، إلى أن أصبحت واحدة من أكثر لغات البرمجة حبًا وطلبًا في العالم. بالنظر إلى الوراء، كان من المُتوقّع أن تجذب قوة ووعد Rust الانتباه وتكتسب موطئ قدم في برمجة الأنظمة (Systems Programming). إلا أن النمو العالمي في الاهتمام والابتكار الذي انتشر عبر مجتمعات المصادر المفتوحة وحفز التبني الواسع عبر الصناعات لم يكن أمرًا محتمًا.
في هذه المرحلة، من السهل الإشارة إلى الميزات الرائعة التي تقدمها Rust لشرح هذا الانفجار في الاهتمام والتبني. من لا يريد سلامة الذاكرة (Memory Safety)، وأداء (Performance) سريع، ومترجم (compiler) ودود، وأدوات (Tooling) رائعة، إلى جانب مجموعة أخرى من الميزات المذهلة؟ لغة Rust التي تراها اليوم تجمع بين سنوات من البحث في برمجة الأنظمة مع الحكمة العملية لمجتمع حيوي وشغوف. تم تصميم هذه اللغة بهدف واضح وصُنعت بعناية، مقدمة للمطورين أداة تسهل كتابة كود آمن، سريع وموثوق.
لكن ما يجعل Rust مميزة حقًا هو جذورها في تمكينك، المستخدم، من تحقيق أهدافك. هذه لغة تريد لك النجاح، ومبدأ التمكين يتغلغل في جوهر المجتمع الذي يبني ويحافظ ويدافع عن هذه اللغة. منذ الإصدار السابق لهذا النص الحاسم، تطورت Rust بشكل أكبر لتصبح لغة عالمية وموثوقة بحق. مشروع Rust مدعوم الآن بقوة من قبل مؤسسة Rust Foundation، التي تستثمر أيضًا في مبادرات رئيسية لضمان أن تكون Rust آمنة، مستقرة، ومستدامة.
يعد هذا الإصدار من The Rust Programming Language تحديثًا شاملًا، يعكس تطور اللغة على مر السنين ويوفر معلومات جديدة قيّمة. لكنه ليس مجرد دليل للنحو والمكتبات—بل دعوة للانضمام إلى مجتمع يُقدّر الجودة، الأداء، والتصميم المدروس. سواء كنت مطورًا متمرسًا يتطلع لاستكشاف Rust لأول مرة أو Rustacean ذو خبرة يريد صقل مهاراته، يقدم هذا الإصدار شيئًا للجميع.
كانت رحلة Rust رحلة تعاونية، مليئة بالتعلم والتطوير التدريجي. نمو اللغة ونظامها البيئي هو انعكاس مباشر للمجتمع الحيوي والمتنوع الذي يقف وراءها. مساهمات آلاف المطورين، من مصممي اللغة الأساسيين إلى المساهمين العرضيين، هي ما تجعل من Rust أداة فريدة وقوية. بقراءة هذا الكتاب، أنت لا تتعلم لغة برمجة جديدة فقط—بل تنضم إلى حركة تهدف لجعل البرمجيات أفضل، أكثر أمانًا، وأكثر متعة في العمل بها.
مرحبًا بك في مجتمع Rust!
- بيك رامبول، المدير التنفيذي لمؤسسة Rust Foundation
مقدمة (Introduction)
ملاحظة: هذه الطبعة من الكتاب هي نفسها طبعة لغة البرمجة رست (The Rust Programming Language) المتوفرة في شكل مطبوع وكتاب إلكتروني من No Starch Press.
مرحباً بكم في كتاب لغة البرمجة رست، وهو كتاب تمهيدي حول Rust. تساعدك لغة البرمجة Rust على كتابة برمجيات أسرع وأكثر موثوقية. غالباً ما تتعارض بيئة العمل عالية المستوى (High-level ergonomics) والتحكم منخفض المستوى (low-level control) في تصميم لغات البرمجة؛ وتتحدى Rust هذا الصراع. من خلال الموازنة بين القدرة التقنية القوية وتجربة المطور الرائعة، تمنحك Rust خيار التحكم في التفاصيل منخفضة المستوى (مثل استخدام الذاكرة (memory usage)) دون كل العناء المرتبط تقليدياً بهذا التحكم.
لمن صُممت Rust
تعد Rust مثالية للعديد من الأشخاص لمجموعة متنوعة من الأسباب. دعونا نلقي نظرة على عدد قليل من أهم المجموعات.
فرق المطورين (Teams of Developers)
تثبت Rust أنها أداة إنتاجية للتعاون بين فرق كبيرة من المطورين الذين لديهم مستويات متفاوتة من المعرفة ببرمجة الأنظمة (systems programming). الكود منخفض المستوى عرضة للعديد من الأخطاء البرمجية (bugs) الدقيقة، والتي لا يمكن اكتشافها في معظم اللغات الأخرى إلا من خلال الاختبار المكثف ومراجعة الكود (code review) الدقيقة من قبل مطورين ذوي خبرة. في Rust، يلعب المصرف (compiler) دور الحارس من خلال رفض تصريف (compile) الكود الذي يحتوي على هذه الأخطاء المراوغة، بما في ذلك أخطاء التزامن (concurrency bugs). من خلال العمل جنباً إلى جنب مع compiler، يمكن للفريق قضاء وقته في التركيز على منطق البرنامج بدلاً من مطاردة bugs.
تجلب Rust أيضاً أدوات مطورين معاصرة إلى عالم برمجة الأنظمة:
- Cargo، وهو مدير الاعتمادات (dependency manager) وأداة البناء (build tool) المضمنة، يجعل إضافة الاعتمادات (dependencies) وتصريفها وإدارتها أمراً سهلاً ومتسقاً عبر نظام Rust البيئي (ecosystem).
- أداة التنسيق
rustfmtتضمن أسلوب ترميز (coding style) متسقاً بين المطورين. - خادم لغة رست (Rust Language Server) يدعم تكامل بيئة التطوير المتكاملة (IDE) لإكمال الكود ورسائل الخطأ المضمنة.
باستخدام هذه الأدوات وغيرها في نظام Rust البيئي، يمكن للمطورين أن يكونوا منتجين أثناء كتابة كود على مستوى الأنظمة.
الطلاب (Students)
Rust مخصصة للطلاب وأولئك المهتمين بالتعرف على مفاهيم الأنظمة. باستخدام Rust، تعلم الكثير من الناس مواضيع مثل تطوير أنظمة التشغيل. المجتمع مضياف للغاية ويسعده الإجابة على أسئلة الطلاب. من خلال جهود مثل هذا الكتاب، تريد فرق Rust جعل مفاهيم الأنظمة أكثر سهولة لمزيد من الناس، وخاصة الجدد في البرمجة.
الشركات (Companies)
تستخدم مئات الشركات، الكبيرة والصغيرة، Rust في الإنتاج لمجموعة متنوعة من المهام، بما في ذلك أدوات سطر الأوامر (command line tools)، وخدمات الويب، وأدوات العمليات البرمجية (DevOps tooling)، والأجهزة المدمجة (embedded devices)، وتحليل وترميز الصوت والفيديو، والعملات المشفرة، والمعلوماتية الحيوية، ومحركات البحث، وتطبيقات إنترنت الأشياء (Internet of Things)، والتعلم الآلي (machine learning)، وحتى أجزاء رئيسية من متصفح الويب Firefox.
مطورو البرمجيات مفتوحة المصدر (Open Source Developers)
Rust مخصصة للأشخاص الذين يرغبون في بناء لغة البرمجة Rust، والمجتمع، وأدوات المطورين، والمكتبات (libraries). يسعدنا أن تساهم في لغة Rust.
الأشخاص الذين يقدرون السرعة والاستقرار
Rust مخصصة للأشخاص الذين يتوقون إلى السرعة والاستقرار في اللغة. بالسرعة، نعني كلاً من مدى سرعة تشغيل كود Rust والسرعة التي تتيح لك بها Rust كتابة البرامج. تضمن فحوصات compiler في Rust الاستقرار من خلال إضافات الميزات وإعادة هيكلة الكود (refactoring). هذا على عكس الكود القديم الهش في اللغات التي لا تحتوي على هذه الفحوصات، والتي غالباً ما يخشى المطورون تعديلها. من خلال السعي وراء التجريدات صفرية التكلفة (zero-cost abstractions) — وهي ميزات عالية المستوى يتم تصريفها إلى كود منخفض المستوى بنفس سرعة الكود المكتوب يدوياً — تسعى Rust لجعل الكود الآمن كوداً سريعاً أيضاً.
تأمل لغة Rust في دعم العديد من المستخدمين الآخرين أيضاً؛ المذكورون هنا هم مجرد بعض من أكبر أصحاب المصلحة. بشكل عام، طموح Rust الأكبر هو القضاء على المقايضات التي قبلها المبرمجون لعقود من خلال توفير الأمان و الإنتاجية، والسرعة و سهولة الاستخدام. جرب Rust، وانظر ما إذا كانت خياراتها تناسبك.
لمن صُمم هذا الكتاب
يفترض هذا الكتاب أنك كتبت كوداً بلغة برمجة أخرى، لكنه لا يضع أي افتراضات حول أي لغة. لقد حاولنا جعل المادة متاحة على نطاق واسع لأولئك الذين ينتمون إلى مجموعة متنوعة من الخلفيات البرمجية. نحن لا نقضي الكثير من الوقت في التحدث عما تكون عليه البرمجة أو كيفية التفكير فيها. إذا كنت جديداً تماماً على البرمجة، فمن الأفضل لك قراءة كتاب يقدم خصيصاً مقدمة للبرمجة.
كيفية استخدام هذا الكتاب
بشكل عام، يفترض هذا الكتاب أنك تقرأه بالتسلسل من البداية إلى النهاية. تبني الفصول اللاحقة على المفاهيم الواردة في الفصول السابقة، وقد لا تتعمق الفصول السابقة في تفاصيل موضوع معين ولكنها ستعيد زيارة الموضوع في فصل لاحق.
ستجد نوعين من الفصول في هذا الكتاب: فصول المفاهيم وفصول المشاريع. في فصول المفاهيم، ستتعلم عن جانب من جوانب Rust. في فصول المشاريع، سنبني برامج صغيرة معاً، ونطبق ما تعلمته حتى الآن. الفصل 2 والفصل 12 والفصل 21 هي فصول مشاريع؛ والباقي فصول مفاهيم.
يشرح الفصل 1 كيفية تثبيت Rust، وكيفية كتابة برنامج “Hello, world!”، وكيفية استخدام Cargo، وهو مدير الحزم (package manager) وأداة البناء في Rust. الفصل 2 هو مقدمة عملية لكتابة برنامج في Rust، حيث يجعلك تبني لعبة تخمين الأرقام. هنا، نغطي المفاهيم على مستوى عالٍ، وستوفر الفصول اللاحقة تفاصيل إضافية. إذا كنت ترغب في البدء بالتطبيق العملي على الفور، فإن الفصل 2 هو المكان المناسب لذلك. إذا كنت متعلماً دقيقاً بشكل خاص وتفضل تعلم كل التفاصيل قبل الانتقال إلى الخطوة التالية، فقد ترغب في تخطي الفصل 2 والانتقال مباشرة إلى الفصل 3، الذي يغطي ميزات Rust المشابهة لميزات لغات البرمجة الأخرى؛ ثم يمكنك العودة إلى الفصل 2 عندما ترغب في العمل على مشروع يطبق التفاصيل التي تعلمتها.
في الفصل 4، ستتعلم عن نظام الملكية (ownership system) في Rust. يناقش الفصل 5 الهياكل (structs) والدوال (methods). يغطي الفصل 6 التعدادات (enums)، وتعبيرات match ، وبنيات تدفق التحكم if let و let...else. ستستخدم structs و enums لإنشاء أنواع مخصصة.
في الفصل 7، ستتعلم عن نظام الوحدات (module system) في Rust وعن قواعد الخصوصية لتنظيم الكود الخاص بك وواجهة برمجة التطبيقات (API) العامة الخاصة به. يناقش الفصل 8 بعض هياكل بيانات المجموعات (collection data structures) الشائعة التي توفرها المكتبة القياسية (standard library): المتجهات (vectors)، والسلاسل النصية (strings)، وخرائط التجزئة (hash maps). يستكشف الفصل 9 فلسفة وتقنيات معالجة الأخطاء (error-handling) في Rust.
يتعمق الفصل 10 في الأنواع العامة (generics)، والسمات (traits)، وفترات الحياة (lifetimes)، والتي تمنحك القدرة على تعريف كود ينطبق على أنواع متعددة. الفصل 11 يدور حول الاختبار (testing)، والذي حتى مع ضمانات الأمان في Rust يعد ضرورياً لضمان صحة منطق برنامجك. في الفصل 12، سنبني تنفيذنا الخاص لمجموعة فرعية من الوظائف من أداة سطر الأوامر grep التي تبحث عن نص داخل الملفات. لهذا، سنستخدم العديد من المفاهيم التي ناقشناها في الفصول السابقة.
يستكشف الفصل 13 الإغلاقات (closures) والمكررات (iterators): ميزات Rust التي تأتي من لغات البرمجة الوظيفية (functional programming languages). في الفصل 14، سنفحص Cargo بمزيد من العمق ونتحدث عن أفضل الممارسات لمشاركة مكتباتك مع الآخرين. يناقش الفصل 15 المؤشرات الذكية (smart pointers) التي توفرها standard library والسمات التي تمكن وظائفها.
في الفصل 16، سنستعرض نماذج مختلفة من البرمجة المتزامنة (concurrent programming) ونتحدث عن كيفية مساعدة Rust لك في البرمجة في خيوط معالجة (threads) متعددة دون خوف. في الفصل 17، نبني على ذلك من خلال استكشاف بناء جملة async و await في Rust، جنباً إلى جنب مع المهام (tasks)، والمستقبليات (futures)، والمجاري (streams)، ونموذج التزامن خفيف الوزن الذي تمكنه.
ينظر الفصل 18 في كيفية مقارنة اصطلاحات (idioms) Rust بمبادئ البرمجة كائنية التوجه التي قد تكون مألوفاً بها. الفصل 19 هو مرجع حول الأنماط (patterns) ومطابقة الأنماط (pattern matching)، وهي طرق قوية للتعبير عن الأفكار عبر برامج Rust. يحتوي الفصل 20 على مجموعة متنوعة من المواضيع المتقدمة ذات الأهمية، بما في ذلك Rust غير الآمنة (unsafe Rust)، والماكرو (macros)، والمزيد حول lifetimes و traits والأنواع والدوال و closures.
في الفصل 21، سنكمل مشروعاً سنقوم فيه بتنفيذ خادم ويب متعدد الخيوط منخفض المستوى!
أخيراً، تحتوي بعض الملاحق على معلومات مفيدة حول اللغة في شكل مرجعي أكثر. يغطي الملحق أ الكلمات المفتاحية (keywords) في Rust، ويغطي الملحق ب العمليات والرموز، ويغطي الملحق ج السمات القابلة للاشتقاق (derivable traits) التي توفرها standard library، ويغطي الملحق د بعض أدوات التطوير المفيدة، ويشرح الملحق هـ إصدارات (editions) Rust. في الملحق و، يمكنك العثور على ترجمات للكتاب، وفي الملحق ز سنغطي كيفية صنع Rust وما هي نسخة nightly من Rust.
لا توجد طريقة خاطئة لقراءة هذا الكتاب: إذا كنت تريد التخطي للأمام، فافعل ذلك! قد تضطر إلى العودة إلى الفصول السابقة إذا واجهت أي ارتباك. لكن افعل ما يناسبك.
جزء مهم من عملية تعلم Rust هو تعلم كيفية قراءة رسائل الخطأ التي يعرضها compiler: ستوجهك هذه الرسائل نحو الكود الذي يعمل. على هذا النحو، سنقدم العديد من الأمثلة التي لا يتم تصريفها جنباً إلى جنب مع رسالة الخطأ التي سيظهرها لك compiler في كل موقف. اعلم أنك إذا أدخلت وشغلت مثالاً عشوائياً، فقد لا يتم تصريفه! تأكد من قراءة النص المحيط لمعرفة ما إذا كان المثال الذي تحاول تشغيله يهدف إلى إظهار خطأ. في معظم الحالات، سنقودك إلى النسخة الصحيحة من أي كود لا يتم تصريفه. سيساعدك Ferris أيضاً في تمييز الكود الذي لا يُقصد منه العمل:
| Ferris | المعنى |
|---|---|
 | هذا الكود لا يتم تصريفه! |
 | هذا الكود يسبب هلعاً (panics)! |
 | هذا الكود لا ينتج السلوك المطلوب. |
في معظم الحالات، سنقودك إلى النسخة الصحيحة من أي كود لا يتم تصريفه.
الكود المصدري (Source Code)
يمكن العثور على الملفات المصدرية التي تم إنشاء هذا الكتاب منها على GitHub.
Getting Started
لنبدأ رحلتك في عالم Rust! هناك الكثير لتتعلمه، لكن كل رحلة تبدأ من مكان ما.
في هذا الفصل، سنتناول ما يلي:
-
تثبيت Rust على أنظمة Linux و macOS و Windows
-
كتابة برنامج يطبع عبارة
Hello, world! -
استخدام
Cargo، مدير الحزم ونظام البناء الخاص بـ Rust
التثبيت (Installation)
التثبيت (Installation)
الخطوة الأولى هي تثبيت Rust. سنقوم بتنزيل Rust من خلال rustup، وهي أداة سطر أوامر (command line tool) لإدارة إصدارات Rust والأدوات المرتبطة بها. ستحتاج إلى اتصال بالإنترنت لعملية التنزيل.
ملاحظة: إذا كنت تفضل عدم استخدام
rustupلسبب ما، فيرجى الاطلاع على صفحة طرق تثبيت Rust الأخرى للحصول على المزيد من الخيارات.
تثبت الخطوات التالية أحدث إصدار مستقر من مترجم لغة Rust (Rust compiler). تضمن ضمانات استقرار Rust أن جميع الأمثلة في الكتاب التي يتم تجميعها (compile) ستستمر في التجميع مع إصدارات Rust الأحدث. قد يختلف الإخراج قليلاً بين الإصدارات لأن Rust غالبًا ما تحسن رسائل الخطأ والتحذيرات. بعبارة أخرى، يجب أن يعمل أي إصدار مستقر أحدث من Rust تقوم بتثبيته باستخدام هذه الخطوات كما هو متوقع مع محتوى هذا الكتاب.
ترميز سطر الأوامر (Command Line Notation)
في هذا الفصل وطوال الكتاب، سنعرض بعض الأوامر المستخدمة في الطرفية (terminal). تبدأ جميع الأسطر التي يجب عليك إدخالها في
terminalبالرمز$. لا تحتاج إلى كتابة الحرف$. إنه موجه سطر الأوامر (command line prompt) الذي يظهر للإشارة إلى بداية كل أمر. الأسطر التي لا تبدأ بـ$ $عادةً ما تعرض إخراج الأمر السابق. بالإضافة إلى ذلك، ستستخدم الأمثلة الخاصة بـ PowerShell الرمز>بدلاً من$.
تثبيت rustup على Linux أو macOS
إذا كنت تستخدم Linux أو macOS، فافتح terminal وأدخل الأمر التالي:
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
يقوم الأمر بتنزيل سكريبت (script) وبدء تثبيت أداة rustup، والتي تثبت أحدث إصدار مستقر من Rust. قد يُطلب منك إدخال كلمة المرور الخاصة بك. إذا نجح التثبيت، فسيظهر السطر التالي:
Rust is installed now. Great!
ستحتاج أيضًا إلى رابط (linker)، وهو برنامج تستخدمه Rust لضم مخرجاتها المجمعة في ملف واحد. من المحتمل أن يكون لديك واحد بالفعل. إذا تلقيت أخطاء linker، فيجب عليك تثبيت مترجم لغة C (C compiler)، والذي سيتضمن عادةً linker. يعد C compiler مفيدًا أيضًا لأن بعض حزم Rust الشائعة تعتمد على كود C وستحتاج إلى C compiler.
على macOS، يمكنك الحصول على C compiler عن طريق تشغيل:
$ xcode-select --install
يجب على مستخدمي Linux عمومًا تثبيت GCC أو Clang، وفقًا لوثائق التوزيعة (distribution) الخاصة بهم. على سبيل المثال، إذا كنت تستخدم Ubuntu، يمكنك تثبيت حزمة build-essential.
تثبيت rustup على Windows
على Windows، انتقل إلى https://www.rust-lang.org/tools/install واتبع التعليمات لتثبيت Rust. في مرحلة ما من التثبيت، سيُطلب منك تثبيت Visual Studio. يوفر هذا linker والمكتبات الأصلية (native libraries) اللازمة لتجميع البرامج. إذا كنت بحاجة إلى مزيد من المساعدة في هذه الخطوة، فراجع https://rust-lang.github.io/rustup/installation/windows-msvc.html.
يستخدم باقي هذا الكتاب أوامر تعمل في كل من cmd.exe و PowerShell. إذا كانت هناك اختلافات محددة، فسنشرح أيها يجب استخدامه.
استكشاف الأخطاء وإصلاحها (Troubleshooting)
للتحقق مما إذا كنت قد قمت بتثبيت Rust بشكل صحيح، افتح shell وأدخل هذا السطر:
$ rustc --version
يجب أن ترى رقم الإصدار (version number)، ورمز التثبيت (commit hash)، وتاريخ التثبيت (commit date) لأحدث إصدار مستقر تم إصداره، بالتنسيق التالي:
rustc x.y.z (abcabcabc yyyy-mm-dd)
إذا رأيت هذه المعلومات، فقد قمت بتثبيت Rust بنجاح! إذا لم تر هذه المعلومات، فتحقق من أن Rust موجود في متغير النظام %PATH% الخاص بك على النحو التالي.
في Windows CMD، استخدم:
> echo %PATH%
في PowerShell، استخدم:
> echo $env:Path
في Linux و macOS، استخدم:
$ echo $PATH
إذا كان كل هذا صحيحًا ولا تزال Rust لا تعمل، فهناك عدد من الأماكن التي يمكنك الحصول على المساعدة منها. اكتشف كيفية التواصل مع Rustaceans الآخرين (لقب سخيف نطلق به على أنفسنا) على صفحة المجتمع.
التحديث وإلغاء التثبيت (Updating and Uninstalling)
بمجرد تثبيت Rust عبر rustup، يصبح التحديث إلى إصدار تم إصداره حديثًا أمرًا سهلاً. من shell الخاص بك، قم بتشغيل سكريبت التحديث التالي:
$ rustup update
لإلغاء تثبيت Rust و rustup، قم بتشغيل سكريبت إلغاء التثبيت التالي من shell الخاص بك:
$ rustup self uninstall
قراءة الوثائق المحلية (Reading the Local Documentation)
يتضمن تثبيت Rust أيضًا نسخة محلية من الوثائق حتى تتمكن من قراءتها دون اتصال بالإنترنت. قم بتشغيل rustup doc لفتح الوثائق المحلية في متصفحك.
في أي وقت يتم فيه توفير نوع (type) أو دالة (function) بواسطة المكتبة القياسية (standard library) ولست متأكدًا مما تفعله أو كيفية استخدامها، استخدم وثائق واجهة برمجة التطبيقات (API) لمعرفة ذلك!
استخدام محررات النصوص وبيئات التطوير المتكاملة (Using Text Editors and IDEs)
لا يفترض هذا الكتاب أي شيء حول الأدوات التي تستخدمها لكتابة كود Rust. أي محرر نصوص تقريبًا سيقوم بالمهمة! ومع ذلك، فإن العديد من محررات النصوص و IDEs لديها دعم مدمج لـ Rust. يمكنك دائمًا العثور على قائمة حديثة إلى حد ما للعديد من المحررات و IDEs على صفحة الأدوات على موقع Rust على الويب.
العمل دون اتصال بالإنترنت مع هذا الكتاب (Working Offline with This Book)
في العديد من الأمثلة، سنستخدم حزم Rust تتجاوز standard library. للعمل من خلال تلك الأمثلة، ستحتاج إما إلى اتصال بالإنترنت أو إلى تنزيل تلك التبعيات (dependencies) مسبقًا. لتنزيل dependencies مسبقًا، يمكنك تشغيل الأوامر التالية. (سنشرح ما هو cargo وما يفعله كل من هذه الأوامر بالتفصيل لاحقًا.)
$ cargo new get-dependencies
$ cd get-dependencies
$ cargo add rand@0.8.5 trpl@0.2.0
سيؤدي هذا إلى تخزين التنزيلات لهذه الحزم مؤقتًا (cache) بحيث لن تحتاج إلى تنزيلها لاحقًا. بمجرد تشغيل هذا الأمر، لا تحتاج إلى الاحتفاظ بمجلد get-dependencies. إذا قمت بتشغيل هذا الأمر، يمكنك استخدام العلامة --offline مع جميع أوامر cargo في بقية الكتاب لاستخدام هذه الإصدارات المخزنة مؤقتًا بدلاً من محاولة استخدام الشبكة.
أهلاً بالعالم! (Hello, World!)
مرحباً أيها العالم! (Hello, World!)
الآن بعد أن قمت بتثبيت Rust، حان الوقت لكتابة أول برنامج Rust لك. من التقليدي عند تعلم لغة جديدة كتابة برنامج صغير يطبع النص Hello, world! على الشاشة، لذلك سنفعل الشيء نفسه هنا!
ملاحظة: يفترض هذا الكتاب إلمامًا أساسيًا بسطر الأوامر (command line). لا تفرض Rust متطلبات محددة حول التحرير أو الأدوات الخاصة بك أو مكان وجود الكود الخاص بك، لذلك إذا كنت تفضل استخدام بيئة التطوير المتكاملة (IDE) بدلاً من
command line، فلا تتردد في استخدامIDEالمفضل لديك. تحتوي العديد منIDEsالآن على درجة معينة من دعم Rust؛ تحقق من وثائقIDEللحصول على التفاصيل. يركز فريق Rust على تمكين دعم رائع لـIDEعبر محلل لغة Rust (rust-analyzer). راجع الملحق د لمزيد من التفاصيل.
إعداد دليل المشروع (Project Directory Setup)
ستبدأ بإنشاء دليل (directory) لتخزين كود Rust الخاص بك. لا يهم Rust مكان وجود الكود الخاص بك، ولكن بالنسبة للتمارين والمشاريع في هذا الكتاب، نقترح إنشاء دليل المشاريع (projects directory) في دليلك الرئيسي والاحتفاظ بجميع مشاريعك هناك.
افتح الطرفية (terminal) وأدخل الأوامر التالية لإنشاء projects directory ودليل لمشروع “Hello, world!” داخل projects directory.
بالنسبة لنظامي Linux و macOS و PowerShell على Windows، أدخل ما يلي:
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
بالنسبة لـ Windows CMD، أدخل ما يلي:
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
أساسيات برنامج Rust (Rust Program Basics)
بعد ذلك، قم بإنشاء ملف مصدر (source file) جديد وسمه main.rs. تنتهي ملفات Rust دائمًا بامتداد .rs (extension). إذا كنت تستخدم أكثر من كلمة في اسم ملفك، فإن الاصطلاح (convention) هو استخدام شرطة سفلية (underscore) للفصل بينها. على سبيل المثال، استخدم hello_world.rs بدلاً من helloworld.rs.
الآن افتح ملف main.rs الذي أنشأته للتو وأدخل الكود في القائمة 1-1.
fn main() {
println!("Hello, world!");
}احفظ الملف وعد إلى نافذة terminal الخاصة بك في دليل ~/projects/hello_world. على Linux أو macOS، أدخل الأوامر التالية لتجميع (compile) وتشغيل (run) الملف:
$ rustc main.rs
$ ./main
Hello, world!
على Windows، أدخل الأمر .\main بدلاً من ./main:
> rustc main.rs
> .\main
Hello, world!
بغض النظر عن نظام التشغيل (operating system) الخاص بك، يجب أن تتم طباعة السلسلة النصية (string) Hello, world! على terminal. إذا لم تر هذا الإخراج، فارجع إلى جزء “استكشاف الأخطاء وإصلاحها” من قسم التثبيت للحصول على طرق للمساعدة.
إذا تمت طباعة Hello, world!، فتهانينا! لقد كتبت رسميًا برنامج Rust. هذا يجعلك مبرمج Rust - مرحبًا بك!
تشريح برنامج Rust (The Anatomy of a Rust Program)
دعنا نراجع برنامج “Hello, world!” هذا بالتفصيل. إليك الجزء الأول من اللغز:
fn main() {
}تحدد هذه الأسطر دالة (function) تسمى main. الدالة الرئيسية (main function) خاصة: إنها دائمًا أول كود يتم تشغيله في كل برنامج Rust قابل للتنفيذ (executable). هنا، يعلن السطر الأول عن function تسمى main ليس لها معاملات (parameters) ولا تُرجع شيئًا. إذا كانت هناك parameters، فستكون داخل الأقواس (()).
جسم الدالة (function body) مغلف بأقواس معقوفة (curly brackets) {}. تتطلب Rust curly brackets حول جميع أجسام الدوال. من الأسلوب الجيد وضع القوس المعقوف الافتتاحي في نفس السطر مثل إعلان function، مع إضافة مسافة واحدة بينهما.
ملاحظة: إذا كنت ترغب في الالتزام بأسلوب قياسي عبر مشاريع Rust، يمكنك استخدام أداة منسق الكود (rustfmt) التلقائية لتنسيق الكود الخاص بك بأسلوب معين (المزيد حول
rustfmtفي الملحق د). قام فريق Rust بتضمين هذه الأداة مع توزيع Rust القياسي، مثلrustc، لذلك يجب أن تكون مثبتة بالفعل على جهاز الكمبيوتر الخاص بك!
يحتوي function body لـ main على الكود التالي:
#![allow(unused)]
fn main() {
println!("Hello, world!");
}يقوم هذا السطر بكل العمل في هذا البرنامج الصغير: إنه يطبع نصًا على الشاشة. هناك ثلاث تفاصيل مهمة يجب ملاحظتها هنا.
أولاً، println! يستدعي ماكرو (macro) Rust. إذا كان قد استدعى function بدلاً من ذلك، فسيتم إدخاله كـ println (بدون !). macros Rust هي طريقة لكتابة كود يولد كودًا لتوسيع بناء جملة Rust، وسنناقشها بمزيد من التفصيل في الفصل 20. في الوقت الحالي، تحتاج فقط إلى معرفة أن استخدام ! يعني أنك تستدعي macro بدلاً من function عادية وأن macros لا تتبع دائمًا نفس قواعد functions.
ثانيًا، ترى string "Hello, world!". نمرر هذه string كوسيط (argument) إلى println!، ويتم طباعة string على الشاشة.
ثالثًا، ننهي السطر بفاصلة منقوطة (semicolon) (;)، مما يشير إلى أن هذا التعبير (expression) قد انتهى، والتعبير التالي جاهز للبدء. تنتهي معظم أسطر كود Rust بـ semicolon.
التجميع والتنفيذ (Compilation and Execution)
لقد قمت للتو بتشغيل برنامج تم إنشاؤه حديثًا، لذا دعنا نفحص كل خطوة في العملية.
قبل تشغيل برنامج Rust، يجب عليك تجميعه باستخدام مترجم Rust (Rust compiler) عن طريق إدخال الأمر rustc وتمرير اسم ملف المصدر (source file) الخاص بك إليه، مثل هذا:
$ rustc main.rs
إذا كانت لديك خلفية في C أو C++، فستلاحظ أن هذا مشابه لـ gcc أو clang. بعد التجميع بنجاح، يخرج Rust ملف ثنائي قابل للتنفيذ (binary executable).
على Linux و macOS و PowerShell على Windows، يمكنك رؤية executable عن طريق إدخال الأمر ls في shell الخاص بك:
$ ls
main main.rs
على Linux و macOS، سترى ملفين. باستخدام PowerShell على Windows، سترى نفس الملفات الثلاثة التي تراها باستخدام CMD. باستخدام CMD على Windows، ستدخل ما يلي:
> dir /B %= the /B option says to only show the file names =%
main.exe
main.pdb
main.rs
يعرض هذا source file بامتداد .rs، و executable (main.exe على Windows، ولكن main على جميع operating systems الأخرى)، وعند استخدام Windows، ملف يحتوي على معلومات تصحيح الأخطاء (debugging information) بامتداد .pdb. من هنا، تقوم بتشغيل ملف main أو main.exe، مثل هذا:
$ ./main # or .\main on Windows
إذا كان main.rs هو برنامج “Hello, world!” الخاص بك، فإن هذا السطر يطبع Hello, world! على terminal الخاص بك.
إذا كنت أكثر دراية بلغة ديناميكية (dynamic language)، مثل Ruby أو Python أو JavaScript، فقد لا تكون معتادًا على تجميع وتشغيل برنامج كخطوات منفصلة. Rust هي لغة مجمعة مسبقاً (ahead-of-time compiled language)، مما يعني أنه يمكنك تجميع برنامج وإعطاء executable لشخص آخر، ويمكنه تشغيله حتى بدون تثبيت Rust. إذا أعطيت شخصًا ملف .rb أو .py أو .js، فإنه يحتاج إلى تثبيت تطبيق Ruby أو Python أو JavaScript (على التوالي). ولكن في تلك اللغات، تحتاج فقط إلى أمر واحد لتجميع وتشغيل برنامجك. كل شيء هو مقايضة في تصميم اللغة.
التجميع باستخدام rustc فقط جيد للبرامج البسيطة، ولكن مع نمو مشروعك، سترغب في إدارة جميع الخيارات وتسهيل مشاركة الكود الخاص بك. بعد ذلك، سنقدم لك أداة كارغو (Cargo)، والتي ستساعدك في كتابة برامج Rust واقعية.
أهلاً كارغو! (Hello, Cargo!)
مرحبًا، Cargo!
إن Cargo هو نظام البناء (build system) ومدير الحزم (package manager) الخاص بلغة Rust. يستخدم معظم مبرمجي Rust (Rustaceans) هذه الأداة لإدارة مشاريعهم لأن Cargo يتولى الكثير من المهام نيابة عنك، مثل بناء الكود الخاص بك، وتنزيل المكتبات التي يعتمد عليها الكود، وبناء تلك المكتبات. (نسمي المكتبات التي يحتاجها الكود الخاص بك بالتبعيات (dependencies)).
أبسط برامج Rust، مثل البرنامج الذي كتبناه حتى الآن، لا تحتوي على أي dependencies. إذا قمنا ببناء مشروع “Hello, world!” باستخدام Cargo، فسيستخدم فقط الجزء من Cargo الذي يتعامل مع بناء الكود الخاص بك. بينما تكتب برامج Rust أكثر تعقيدًا، ستضيف dependencies، وإذا بدأت مشروعًا باستخدام Cargo، فستكون إضافة dependencies أسهل بكثير.
نظرًا لأن الغالبية العظمى من مشاريع Rust تستخدم Cargo، فإن بقية هذا الكتاب تفترض أنك تستخدم Cargo أيضًا. يأتي Cargo مثبتًا مع Rust إذا استخدمت المثبتات الرسمية التي تمت مناقشتها في قسم “Installation”. إذا قمت بتثبيت Rust بوسائل أخرى، فتحقق مما إذا كان Cargo مثبتًا عن طريق إدخال ما يلي في الطرفية (terminal):
$ cargo --version
إذا رأيت رقم إصدار، فأنت تمتلكه! إذا رأيت خطأ، مثل command not found (الأمر غير موجود)، فراجع وثائق طريقة التثبيت الخاصة بك لتحديد كيفية تثبيت Cargo بشكل منفصل.
إنشاء مشروع باستخدام Cargo
دعنا ننشئ مشروعًا جديدًا باستخدام Cargo ونرى كيف يختلف عن مشروع “Hello, world!” الأصلي الخاص بنا. انتقل مرة أخرى إلى دليل المشاريع (projects directory) الخاص بك (أو أي مكان قررت تخزين الكود فيه). ثم، على أي نظام تشغيل، قم بتشغيل ما يلي:
$ cargo new hello_cargo
$ cd hello_cargo
يؤدي الأمر الأول إلى إنشاء دليل ومشروع جديد يسمى hello_cargo. لقد أطلقنا على مشروعنا اسم hello_cargo، ويقوم Cargo بإنشاء ملفاته في دليل يحمل نفس الاسم.
ادخل إلى دليل hello_cargo واعرض قائمة الملفات. سترى أن Cargo قد أنشأ ملفين ودليلاً واحدًا لنا: ملف Cargo.toml ودليل src وبداخله ملف main.rs.
لقد قام أيضًا بتهيئة مستودع Git جديد مع ملف .gitignore. لن يتم إنشاء ملفات Git إذا قمت بتشغيل cargo new داخل مستودع Git موجود؛ يمكنك تجاوز هذا السلوك باستخدام cargo new --vcs=git.
ملاحظة: Git هو نظام شائع للتحكم في الإصدارات (version control system). يمكنك تغيير
cargo newلاستخدام نظام تحكم في الإصدارات مختلف أو عدم استخدام نظام تحكم في الإصدارات على الإطلاق باستخدام علم (flag)--vcs. قم بتشغيلcargo new --helpلرؤية الخيارات المتاحة.
افتح Cargo.toml في محرر النصوص الذي تختاره. يجب أن يبدو مشابهًا للكود الموجود في القائمة 1-2.
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2024"
[dependencies]
هذا الملف بتنسيق TOML (Tom’s Obvious, Minimal Language)، وهو تنسيق التكوين (configuration format) الخاص بـ Cargo.
السطر الأول، [package]، هو عنوان قسم يشير إلى أن العبارات التالية تقوم بتكوين حزمة (package). بينما نضيف المزيد من المعلومات إلى هذا الملف، سنضيف أقسامًا أخرى.
تحدد الأسطر الثلاثة التالية معلومات التكوين التي يحتاجها Cargo لتجميع (compile) برنامجك: الاسم، والإصدار، وإصدار Rust (edition) المراد استخدامه. سنتحدث عن مفتاح edition في Appendix E.
السطر الأخير، [dependencies]، هو بداية قسم لتدرج فيه أيًا من dependencies الخاصة بمشروعك. في Rust، يشار إلى حزم الكود باسم الصناديق (crates). لن نحتاج إلى أي crates أخرى لهذا المشروع، لكننا سنحتاج إليها في المشروع الأول في الفصل 2، لذا سنستخدم قسم dependencies هذا حينها.
الآن افتح src/main.rs وألقِ نظرة:
Filename: src/main.rs
fn main() {
println!("Hello, world!");
}لقد أنشأ Cargo برنامج “Hello, world!” لك، تمامًا مثل البرنامج الذي كتبناه في القائمة 1-1! حتى الآن، الاختلافات بين مشروعنا والمشروع الذي أنشأه Cargo هي أن Cargo وضع الكود في دليل src، ولدينا ملف تكوين Cargo.toml في الدليل العلوي.
يتوقع Cargo أن تعيش ملفات المصدر (source files) الخاصة بك داخل دليل src. دليل المشروع ذو المستوى الأعلى مخصص فقط لملفات README، ومعلومات الترخيص، وملفات التكوين، وأي شيء آخر غير متعلق بالكود الخاص بك. يساعدك استخدام Cargo في تنظيم مشاريعك. هناك مكان لكل شيء، وكل شيء في مكانه.
إذا بدأت مشروعًا لا يستخدم Cargo، كما فعلنا مع مشروع “Hello, world!”، يمكنك تحويله إلى مشروع يستخدم Cargo. انقل كود المشروع إلى دليل src وأنشئ ملف Cargo.toml مناسبًا. إحدى الطرق السهلة للحصول على ملف Cargo.toml هذا هي تشغيل cargo init الذي سيقوم بإنشائه لك تلقائيًا.
بناء وتشغيل مشروع Cargo
الآن دعنا نرى ما هو المختلف عندما نقوم ببناء وتشغيل برنامج “Hello, world!” باستخدام Cargo! من دليل hello_cargo الخاص بك، قم ببناء مشروعك عن طريق إدخال الأمر التالي:
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
يؤدي هذا الأمر إلى إنشاء ملف قابل للتنفيذ (executable file) في target/debug/hello_cargo (أو target\debug\hello_cargo.exe على Windows) بدلاً من دليلك الحالي. نظرًا لأن البناء الافتراضي هو بناء تصحيح أخطاء (debug build)، يضع Cargo الملف الثنائي (binary) في دليل يسمى debug. يمكنك تشغيل الملف القابل للتنفيذ بهذا الأمر:
$ ./target/debug/hello_cargo # or .\target\debug\hello_cargo.exe on Windows
Hello, world!
إذا سارت الأمور على ما يرام، يجب طباعة Hello, world! في terminal. يؤدي تشغيل cargo build لأول مرة أيضًا إلى قيام Cargo بإنشاء ملف جديد في المستوى الأعلى: Cargo.lock. يتتبع هذا الملف الإصدارات الدقيقة لـ dependencies في مشروعك. لا يحتوي هذا المشروع على dependencies، لذا فإن الملف فارغ قليلاً. لن تحتاج أبدًا إلى تغيير هذا الملف يدويًا؛ يتولى Cargo إدارة محتوياته نيابة عنك.
لقد قمنا للتو ببناء مشروع باستخدام cargo build وتشغيله باستخدام ./target/debug/hello_cargo ولكن يمكننا أيضًا استخدام cargo run لتجميع الكود ثم تشغيل الملف القابل للتنفيذ الناتج في أمر واحد:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
يعد استخدام cargo run أكثر ملاءمة من الاضطرار إلى تذكر تشغيل cargo build ثم استخدام المسار الكامل للملف الثنائي، لذا يستخدم معظم المطورين cargo run.
لاحظ أننا هذه المرة لم نرَ مخرجات تشير إلى أن Cargo كان يقوم بتجميع hello_cargo. أدرك Cargo أن الملفات لم تتغير، لذا لم يقم بإعادة البناء بل قام فقط بتشغيل binary. إذا قمت بتعديل كود المصدر الخاص بك، فسيقوم Cargo بإعادة بناء المشروع قبل تشغيله، وسترى هذا المخرج:
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
يوفر Cargo أيضًا أمرًا يسمى cargo check. يقوم هذا الأمر بفحص الكود الخاص بك بسرعة للتأكد من أنه يتم تجميعه ولكنه لا ينتج ملفًا قابلاً للتنفيذ:
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
لماذا قد لا ترغب في ملف قابل للتنفيذ؟ غالبًا ما يكون cargo check أسرع بكثير من cargo build لأنه يتخطى خطوة إنتاج ملف قابل للتنفيذ. إذا كنت تتحقق باستمرار من عملك أثناء كتابة الكود، فإن استخدام cargo check سيسرع عملية إخبارك إذا كان مشروعك لا يزال يتم تجميعه! على هذا النحو، يقوم العديد من مبرمجي Rust بتشغيل cargo check بشكل دوري أثناء كتابة برنامجهم للتأكد من أنه يتم تجميعه. ثم يقومون بتشغيل cargo build عندما يكونون مستعدين لاستخدام الملف القابل للتنفيذ.
دعنا نلخص ما تعلمناه حتى الآن عن Cargo:
- يمكننا إنشاء مشروع باستخدام
cargo new. - يمكننا بناء مشروع باستخدام
cargo build. - يمكننا بناء وتشغيل مشروع في خطوة واحدة باستخدام
cargo run. - يمكننا بناء مشروع دون إنتاج binary للتحقق من الأخطاء باستخدام
cargo check. - بدلاً من حفظ نتيجة البناء في نفس دليل الكود الخاص بنا، يقوم Cargo بتخزينها في دليل target/debug.
ميزة إضافية لاستخدام Cargo هي أن الأوامر هي نفسها بغض النظر عن نظام التشغيل الذي تعمل عليه. لذا، في هذه المرحلة، لن نقدم تعليمات محددة لنظامي التشغيل Linux و macOS مقابل Windows.
البناء للإصدار (Building for Release)
عندما يكون مشروعك جاهزًا أخيرًا للإصدار، يمكنك استخدام cargo build --release لتجميعه مع التحسينات (optimizations). سيؤدي هذا الأمر إلى إنشاء ملف قابل للتنفيذ في target/release بدلاً من target/debug. تجعل optimizations كود Rust الخاص بك يعمل بشكل أسرع، ولكن تشغيلها يطيل الوقت الذي يستغرقه برنامجك للتجميع. هذا هو السبب في وجود ملفي تعريف (profiles) مختلفين: أحدهما للتطوير، عندما تريد إعادة البناء بسرعة وبشكل متكرر، والآخر لبناء البرنامج النهائي الذي ستعطيه للمستخدم والذي لن يتم إعادة بنائه بشكل متكرر وسيعمل بأسرع ما يمكن. إذا كنت تقوم بقياس أداء (benchmarking) وقت تشغيل الكود الخاص بك، فتأكد من تشغيل cargo build --release والقياس باستخدام الملف القابل للتنفيذ في target/release.
الاستفادة من اتفاقيات Cargo
مع المشاريع البسيطة، لا يوفر Cargo الكثير من القيمة مقارنة بمجرد استخدام rustc ولكنه سيثبت جدارته عندما تصبح برامجك أكثر تعقيدًا. بمجرد أن تنمو البرامج لتشمل ملفات متعددة أو تحتاج إلى dependency، يكون من الأسهل بكثير ترك Cargo ينسق عملية البناء.
على الرغم من أن مشروع hello_cargo بسيط، إلا أنه يستخدم الآن الكثير من الأدوات الحقيقية التي ستستخدمها في بقية حياتك المهنية مع Rust. في الواقع، للعمل في أي مشاريع موجودة، يمكنك استخدام الأوامر التالية لسحب الكود باستخدام Git، والانتقال إلى دليل ذلك المشروع، والبناء:
$ git clone example.org/someproject
$ cd someproject
$ cargo build
لمزيد من المعلومات حول Cargo، راجع وثائقه.
ملخص
لقد بدأت بالفعل بداية رائعة في رحلتك مع Rust! في هذا الفصل، تعلمت كيفية:
- تثبيت أحدث إصدار مستقر من Rust باستخدام
rustup. - التحديث إلى إصدار Rust أحدث.
- فتح الوثائق المثبتة محليًا.
- كتابة وتشغيل برنامج “Hello, world!” باستخدام
rustcمباشرة. - إنشاء وتشغيل مشروع جديد باستخدام اتفاقيات Cargo.
هذا وقت رائع لبناء برنامج أكثر جوهرية للتعود على قراءة وكتابة كود Rust. لذا، في الفصل 2، سنبني برنامج لعبة التخمين. إذا كنت تفضل البدء بتعلم كيفية عمل مفاهيم البرمجة الشائعة في Rust، فراجع الفصل 3 ثم عد إلى الفصل 2.
برمجة لعبة التخمين
دعونا نبدأ رحلتنا مع لغة Rust من خلال العمل على مشروع عملي معاً! يقدم لك هذا الفصل بعض مفاهيم Rust الشائعة من خلال توضيح كيفية استخدامها في برنامج حقيقي. ستتعلم عن let و match والدوال (methods) والدوال المرتبطة (associated functions) والصناديق الخارجية (external crates) والمزيد! في الفصول التالية، سنستكشف هذه الأفكار بمزيد من التفصيل. في هذا الفصل، ستتدرب فقط على الأساسيات.
سنقوم بتنفيذ مشكلة برمجية كلاسيكية للمبتدئين: لعبة التخمين. وإليك آلية عملها: سيقوم البرنامج بتوليد رقم صحيح عشوائي بين 1 و 100، ثم يطلب من اللاعب إدخال تخمين. بعد إدخال التخمين، سيوضح البرنامج ما إذا كان التخمين منخفضاً جداً أم مرتفعاً جداً. إذا كان التخمين صحيحاً، فسيقوم البرنامج بطباعة رسالة تهنئة ويخرج من اللعبة.
إعداد مشروع جديد
لإعداد مشروع جديد، انتقل إلى دليل projects الذي أنشأته في الفصل الأول وأنشئ مشروعاً جديداً باستخدام Cargo، كما يلي:
$ cargo new guessing_game
$ cd guessing_game
الأمر الأول، cargo new يأخذ اسم المشروع (guessing_game) كمعامل أول. الأمر الثاني يغير المسار إلى دليل المشروع الجديد.
ألقِ نظرة على ملف Cargo.toml الذي تم إنشاؤه:
اسم الملف: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2021"
[dependencies]
كما رأيت في الفصل الأول، يقوم cargo new بإنشاء برنامج “Hello, world!” لك. تحقق من ملف src/main.rs:
اسم الملف: src/main.rs
fn main() {
println!("Hello, world!");
}الآن دعونا نقوم بتجميع برنامج “Hello, world!” هذا وتشغيله في نفس الخطوة باستخدام أمر cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/guessing_game`
Hello, world!
يعد أمر run مفيداً عندما تحتاج إلى تكرار العمل على مشروع بسرعة، كما سنفعل في هذه اللعبة، حيث نختبر كل تكرار بسرعة قبل الانتقال إلى التكرار التالي.
أعد فتح ملف src/main.rs. ستكتب كل الكود في هذا الملف.
معالجة التخمين
الجزء الأول من برنامج لعبة التخمين سيطلب مدخلات من المستخدم، ويعالج تلك المدخلات، ويتحقق من أن المدخلات في الشكل المتوقع. للبدء، سنسمح للاعب بإدخال تخمين. أدخل الكود الموجود في القائمة 2-1 في ملف src/main.rs.
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}يحتوي هذا الكود على الكثير من المعلومات، لذا دعونا نمر عليه سطراً بسطر. للحصول على مدخلات المستخدم ثم طباعة النتيجة كمخرجات، نحتاج إلى جلب مكتبة الإدخال/الإخراج io إلى النطاق (scope). تأتي مكتبة io من المكتبة القياسية، المعروفة باسم std:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}بشكل افتراضي، تمتلك Rust مجموعة من العناصر المحددة في المكتبة القياسية والتي تجلبها إلى نطاق كل برنامج. تسمى هذه المجموعة بـ prelude، ويمكنك رؤية كل شيء فيها في توثيق المكتبة القياسية.
إذا كان النوع الذي تريد استخدامه ليس في الـ prelude، فيجب عليك جلب ذلك النوع إلى النطاق صراحةً باستخدام عبارة use. يوفر لك استخدام مكتبة std::io عدداً من الميزات المفيدة، بما في ذلك القدرة على قبول مدخلات المستخدم.
كما رأيت في الفصل الأول، فإن دالة main هي نقطة الدخول إلى البرنامج:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}تعلن صيغة fn عن دالة جديدة؛ وتشير الأقواس () إلى عدم وجود معاملات؛ ويبدأ القوس المتعرج { جسم الدالة.
كما تعلمت أيضاً في الفصل الأول، فإن println! هو ماكرو (macro) يطبع سلسلة نصية على الشاشة:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}يقوم هذا الكود بطباعة مطالبة توضح ماهية اللعبة وتطلب مدخلات من المستخدم.
تخزين القيم باستخدام المتغيرات
بعد ذلك، سننشئ متغيراً لتخزين مدخلات المستخدم، كما يلي:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}الآن أصبح البرنامج مثيراً للاهتمام! هناك الكثير مما يحدث في هذا السطر الصغير. نستخدم عبارة let لإنشاء المتغير. إليك مثالاً آخر:
let apples = 5;ينشئ هذا السطر متغيراً جديداً باسم apples ويربطه بالقيمة 5. في Rust، تكون المتغيرات غير قابلة للتغيير (immutable) افتراضياً، مما يعني أنه بمجرد إعطاء المتغير قيمة، فلن تتغير القيمة. سنناقش هذا المفهوم بالتفصيل في قسم “المتغيرات وقابلية التغيير” في الفصل الثالث. لجعل المتغير قابلاً للتغيير، نضيف mut قبل اسم المتغير:
let apples = 5; // غير قابل للتغيير
let mut bananas = 5; // قابل للتغييرملاحظة: تبدأ صيغة
//تعليقاً يستمر حتى نهاية السطر. تتجاهل Rust كل شيء في التعليقات. سنناقش التعليقات بمزيد من التفصيل في الفصل الثالث.
بالعودة إلى برنامج لعبة التخمين، تعلم الآن أن let mut guess ستقدم متغيراً قابلاً للتغيير باسم guess. تخبر علامة التساوي (=) لغة Rust أننا نريد ربط شيء ما بالمتغير الآن. على يمين علامة التساوي توجد القيمة التي يرتبط بها guess وهي نتيجة استدعاء String::new وهي دالة تعيد نسخة جديدة من String. النوع String هو نوع سلسلة نصية توفره المكتبة القياسية وهو عبارة عن نص بتنسيق UTF-8 وقابل للنمو.
تشير صيغة :: في سطر ::new إلى أن new هي دالة مرتبطة (associated function) بنوع String. الدالة المرتبطة هي دالة يتم تنفيذها على نوع معين، في هذه الحالة String. تنشئ دالة new هذه سلسلة نصية جديدة وفارغة. ستجد دالة new في العديد من الأنواع لأنها اسم شائع لدالة تنشئ قيمة جديدة من نوع ما.
بشكل كامل، قام سطر let mut guess = String::new(); بإنشاء متغير قابل للتغيير مرتبط حالياً بنسخة جديدة وفارغة من String. يا للهول!
استقبال مدخلات المستخدم
تذكر أننا قمنا بتضمين وظائف الإدخال/الإخراج من المكتبة القياسية باستخدام use std::io; في السطر الأول من البرنامج. الآن سنستدعي دالة stdin من وحدة io والتي ستسمح لنا بالتعامل مع مدخلات المستخدم:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}إذا لم نكن قد استوردنا وحدة io باستخدام use std::io; في بداية البرنامج، كان بإمكاننا استدعاء الدالة بكتابتها كـ std::io::stdin. تعيد دالة stdin نسخة من std::io::Stdin وهو نوع يمثل مقبضاً (handle) للإدخال القياسي لمحطتك الطرفية (terminal).
بعد ذلك، يستدعي السطر .read_line(&mut guess) دالة read_line على مقبض الإدخال القياسي للحصول على مدخلات من المستخدم. نقوم أيضاً بتمرير &mut guess كمعامل لـ read_line لإخبارها بالسلسلة النصية التي يجب تخزين مدخلات المستخدم فيها. الوظيفة الكاملة لـ read_line هي أخذ كل ما يكتبه المستخدم في الإدخال القياسي وإلحاقه بسلسلة نصية (دون الكتابة فوق محتوياتها)، لذا نقوم بتمرير تلك السلسلة كمعامل. يجب أن يكون معامل السلسلة النصية قابلاً للتغيير حتى تتمكن الدالة من تغيير محتوى السلسلة.
تشير علامة & إلى أن هذا المعامل هو مرجع (reference)، مما يوفر لك طريقة للسماح لأجزاء متعددة من الكود بالوصول إلى قطعة واحدة من البيانات دون الحاجة إلى نسخ تلك البيانات في الذاكرة عدة مرات. المراجع ميزة معقدة، وإحدى المزايا الرئيسية لـ Rust هي مدى أمان وسهولة استخدام المراجع. لا تحتاج إلى معرفة الكثير من تلك التفاصيل لإنهاء هذا البرنامج. في الوقت الحالي، كل ما تحتاج إلى معرفته هو أن المراجع، مثل المتغيرات، غير قابلة للتغيير افتراضياً. ومن ثم، تحتاج إلى كتابة &mut guess بدلاً من &guess لجعلها قابلة للتغيير. (سيشرح الفصل الرابع المراجع بشكل أكثر تعمقاً).
التعامل مع الفشل المحتمل باستخدام Result
ما زلنا نعمل على هذا السطر من الكود. نحن نناقش الآن السطر الثالث من النص، ولكن لاحظ أنه لا يزال جزءاً من سطر منطقي واحد من الكود. الجزء التالي هو هذه الدالة:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}كان بإمكاننا كتابة هذا الكود كـ:
io::stdin().read_line(&mut guess).expect("فشل في قراءة السطر");ومع ذلك، يصعب قراءة سطر واحد طويل، لذا فمن الأفضل تقسيمه. غالباً ما يكون من الحكمة إدخال سطر جديد ومسافات بيضاء أخرى للمساعدة في تقسيم السطور الطويلة عند استدعاء دالة باستخدام صيغة .method_name(). الآن دعونا نناقش ما يفعله هذا السطر.
كما ذكرنا سابقاً، تضع read_line كل ما يدخله المستخدم في السلسلة النصية التي نمررها إليها، ولكنها تعيد أيضاً قيمة من نوع Result. النوع Result هو تعداد (enumeration)، وغالباً ما يسمى enum، وهو نوع يمكن أن يكون في حالة واحدة من عدة حالات ممكنة. نسمي كل حالة ممكنة بـ variant.
سيغطي الفصل السادس التعدادات بمزيد من التفصيل. الغرض من أنواع Result هذه هو تشفير معلومات معالجة الأخطاء.
حالات Result هي Ok و Err. تشير حالة Ok إلى أن العملية كانت ناجحة، وتحتوي على القيمة التي تم إنشاؤها بنجاح. تعني حالة Err أن العملية فشلت، وتحتوي على معلومات حول كيفية أو سبب فشل العملية.
القيم من نوع Result مثل القيم من أي نوع، لها دوال محددة عليها. نسخة Result لها دالة expect يمكنك استدعاؤها. إذا كانت نسخة Result هذه هي قيمة Err فستتسبب expect في تعطل البرنامج وعرض الرسالة التي مررتها كمعامل لـ expect. إذا أعادت دالة read_line قيمة Err فمن المحتمل أن يكون ذلك نتيجة لخطأ قادم من نظام التشغيل الأساسي. إذا كانت نسخة Result هذه هي قيمة Ok فستأخذ expect القيمة المرتجعة التي يحملها Ok وتعيد تلك القيمة إليك لتتمكن من استخدامها. في هذه الحالة، تلك القيمة هي عدد البايتات في مدخلات المستخدم.
إذا لم تستدعِ expect فسيتم تجميع البرنامج ولكنك ستحصل على تحذير:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut guess);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut guess);
| +++++++
warning: `guessing_game` (bin "guessing_game") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.59s
تحذر Rust من أنك لم تستخدم قيمة Result المرتجعة من read_line مما يشير إلى أن البرنامج لم يعالج خطأً محتملاً.
الطريقة الصحيحة لقمع التحذير هي كتابة معالجة الأخطاء فعلياً، ولكن في حالتنا نريد فقط تعطل البرنامج عند حدوث مشكلة، لذا يمكننا استخدام expect. ستتعلم عن التعافي من الأخطاء في الفصل التاسع.
طباعة القيم باستخدام نائبات println!
بصرف النظر عن القوس المتعرج الختامي، هناك سطر واحد فقط متبقٍ في الكود الذي أضفناه حتى الآن:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}يطبع هذا السطر السلسلة النصية التي تحتوي الآن على مدخلات المستخدم. مجموعة الأقواس المتعرجة {} هي نائبة (placeholder): فكر في {} كأطراف كماشة صغيرة تثبت القيمة في مكانها. عند طباعة قيمة متغير، يمكن أن يوضع اسم المتغير داخل الأقواس المتعرجة. عند طباعة نتيجة تعبير، ضع أقواس متعرجة فارغة في سلسلة التنسيق، ثم اتبع سلسلة التنسيق بقائمة من التعبيرات مفصولة بفاصلة لطباعتها في كل نائبة من الأقواس المتعرجة الفارغة بالترتيب. طباعة متغير ونتيجة تعبير في استدعاء واحد لـ println! ستبدو كما يلي:
#![allow(unused)]
fn main() {
let x = 5;
let y = 10;
println!("x = {x} and y + 2 = {}", y + 2);
}سيطبع هذا الكود x = 5 and y + 2 = 12.
اختبار الجزء الأول
دعونا نختبر الجزء الأول من لعبة التخمين. قم بتشغيله باستخدام cargo run:
{{#include ../listings/ch02-guessing-game-tutorial/listing-02-01/output.txt}}
في هذه المرحلة، الجزء الأول من اللعبة قد انتهى: نحن نحصل على مدخلات من لوحة المفاتيح ثم نطبعها.
توليد رقم سري
بعد ذلك، نحتاج إلى توليد رقم سري سيحاول المستخدم تخمينه. يجب أن يكون الرقم السري مختلفاً في كل مرة حتى تكون اللعبة ممتعة لإعادة اللعب؛ سنستخدم رقماً عشوائياً بين 1 و 100 حتى لا تكون اللعبة صعبة للغاية. لا تتضمن Rust وظائف أرقام عشوائية في مكتبتها القياسية بعد. ومع ذلك، يوفر فريق Rust صندوق rand (rand crate) بهذه الوظيفة.
استخدام صندوق للحصول على المزيد من الوظائف
تذكر أن الصندوق (crate) هو مجموعة من ملفات كود Rust. المشروع الذي نقوم ببنائه هو صندوق ثنائي (binary crate)، وهو ملف قابل للتنفيذ. صندوق rand هو صندوق مكتبة (library crate)، والذي يحتوي على كود مخصص لاستخدامه في برامج أخرى ولا يمكن تشغيله بمفرده.
استخدام Cargo للصناديق الخارجية هو المكان الذي يتألق فيه Cargo حقاً. قبل أن نتمكن من كتابة كود يستخدم rand نحتاج إلى تعديل ملف Cargo.toml لتضمين صندوق rand كاعتمادية (dependency). افتح ذلك الملف الآن وأضف السطر التالي في الأسفل، تحت عنوان القسم [dependencies] الذي أنشأه Cargo لك. تأكد من تحديد rand تماماً كما فعلنا هنا، مع رقم الإصدار هذا، وإلا فقد لا تعمل أمثلة الكود في هذا البرنامج التعليمي (في وقت كتابة هذا، كان rand بالإصدار 0.8.5):
اسم الملف: Cargo.toml
[dependencies]
rand = "0.8.5"
في ملف Cargo.toml كل ما يأتي بعد العنوان هو جزء من ذلك القسم الذي يستمر حتى يبدأ قسم آخر. في [dependencies] تخبر Cargo بالصناديق الخارجية التي يعتمد عليها مشروعك وأي إصدارات من تلك الصناديق تحتاجها. في هذه الحالة، نحدد صندوق rand مع محدد الإصدار الدلالي (Semantic Versioning) 0.8.5. يفهم Cargo الإصدار الدلالي (يسمى أحياناً SemVer)، وهو معيار لكتابة أرقام الإصدارات. الرقم 0.8.5 هو في الواقع اختصار لـ ^0.8.5 مما يعني أي إصدار يتوافق مع الإصدار 0.8.5 على الأقل ولكن أقل من 0.9.0.
يعتبر Cargo أن هذه الإصدارات لها واجهات برمجية (APIs) متوافقة مع الإصدار 0.8.5 ويضمن هذا التحديد أنك ستحصل على أحدث إصدار تصحيحي (patch release) سيظل يجمع مع الكود في هذا الفصل. لا يمكن ضمان توافق أي إصدار 0.9.0 أو أعلى مع الواجهة البرمجية التي تستخدمها الأمثلة التالية.
الآن، دون تغيير أي كود، دعونا نبني المشروع، كما هو موضح في القائمة 2-2.
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
Downloaded libc v0.2.143
Downloaded rand_chacha v0.3.1
Downloaded rand_core v0.6.4
Compiling libc v0.2.143
Compiling rand_core v0.6.4
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 2.53s
القائمة 2-2: المخرجات بعد إضافة صندوق rand كاعتمادية وتشغيل cargo build
قد ترى أرقام إصدارات مختلفة (ولكنها ستكون جميعاً متوافقة مع الكود، بفضل SemVer!) وخطوطاً مختلفة (اعتماداً على نظام التشغيل) وقد تكون السطور بترتيب مختلف.
عندما نقوم بتضمين اعتمادية خارجية، يجلب Cargo أحدث الإصدارات من كل ما تحتاجه تلك الاعتمادية من Crates.io وهو المكان الذي ينشر فيه الأشخاص في نظام Rust البيئي مشاريع Rust مفتوحة المصدر الخاصة بهم ليستخدمها الآخرون.
بعد تحديث الفهرس، يتحقق Cargo من قسم [dependencies] وينزل أي صناديق مدرجة لم يتم تنزيلها بعد. في هذه الحالة، على الرغم من أننا أدرجنا rand فقط كاعتمادية، فقد جلب Cargo أيضاً صناديق أخرى يعتمد عليها rand ليعمل. بعد تنزيل الصناديق، تقوم Rust بتجميعها ثم تجميع المشروع بالاعتماديات المتاحة.
إذا قمت بتشغيل cargo build مرة أخرى فوراً دون إجراء أي تغييرات، فلن تحصل على أي مخرجات سوى سطر Finished. يعرف Cargo أنه قد قام بالفعل بتنزيل وتجميع الاعتماديات، ولم تقم بتغيير أي شيء عنها في ملف Cargo.toml. يعرف Cargo أيضاً أنك لم تغير أي شيء في الكود الخاص بك، لذا فهو لا يعيد تجميعه أيضاً. مع عدم وجود شيء للقيام به، فإنه يخرج ببساطة.
إذا فتحت ملف src/main.rs وأجريت تغييراً تافهاً، ثم حفظته، وقمت بالبناء مرة أخرى، فسترى مخرجات سطرين فقط:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 2.53s
توضح هذه السطور أن Cargo يقوم فقط بتحديث البناء بتغييرك الصغير في ملف src/main.rs. لم تتغير اعتمادياتك، لذا يعرف Cargo أنه يمكنه إعادة استخدام ما قام بتنزيله وتجميعه بالفعل.
ضمان عمليات بناء قابلة للتكرار باستخدام ملف Cargo.lock
يحتوي Cargo على آلية تضمن إمكانية إعادة بناء نفس الملف الثنائي في كل مرة تقوم فيها أنت أو أي شخص آخر ببناء الكود الخاص بك: سيستخدم Cargo فقط إصدارات الاعتماديات التي حددتها حتى تشير إلى خلاف ذلك. على سبيل المثال، لنفترض أن الأسبوع القادم سيصدر الإصدار 0.8.6 من صندوق rand ويحتوي هذا الإصدار على إصلاح لخلل مهم، ولكنه يحتوي أيضاً على تراجع (regression) سيؤدي إلى كسر الكود الخاص بك. للتعامل مع هذا، تنشئ Rust ملف Cargo.lock في المرة الأولى التي تقوم فيها بتشغيل cargo build لذا لدينا الآن هذا الملف في دليل guessing_game.
عندما تبني مشروعاً لأول مرة، يكتشف Cargo جميع إصدارات الاعتماديات التي تناسب المعايير ثم يكتبها في ملف Cargo.lock. عندما تبني مشروعك في المستقبل، سيرى Cargo وجود ملف Cargo.lock وسيستخدم الإصدارات المحددة هناك بدلاً من القيام بكل العمل لمعرفة الإصدارات مرة أخرى. يتيح لك هذا الحصول على بناء قابل للتكرار تلقائياً. بمعنى آخر، سيظل مشروعك يستخدم الإصدار 0.8.5 حتى تقوم بالترقية صراحةً، بفضل ملف Cargo.lock. نظرًا لأن ملف Cargo.lock مهم لاستقرار عمليات البناء، فغالباً ما يتم تضمينه في نظام التحكم في الإصدارات (مثل Git) مع بقية الكود في مشروعك.
تحديث صندوق للحصول على إصدار جديد
عندما تريد تحديث صندوق، يوفر Cargo أمر update والذي سيتجاهل ملف Cargo.lock ويكتشف جميع أحدث الإصدارات التي تناسب مواصفاتك في Cargo.toml. سيقوم Cargo بعد ذلك بكتابة تلك الإصدارات في ملف Cargo.lock. وبخلاف ذلك، سيبحث Cargo افتراضياً فقط عن الإصدارات الأكبر من 0.8.5 وأقل من 0.9.0. إذا أصدر صندوق rand إصدارين جديدين 0.8.6 و 0.9.0 فسترى ما يلي إذا قمت بتشغيل cargo update:
$ cargo update
Updating crates.io index
Updating rand v0.8.5 -> v0.8.6
يتجاهل Cargo الإصدار 0.9.0. في هذه المرحلة، ستلاحظ أيضاً تغييراً في ملف Cargo.lock يشير إلى أن إصدار صندوق rand الذي تستخدمه الآن هو 0.8.6. لاستخدام الإصدار 0.9.0 من rand أو أي إصدار في سلسلة 0.9.x يجب عليك تحديث ملف Cargo.toml ليبدو كما يلي بدلاً من ذلك (أو الإصدار المناسب إذا كنت تستخدم rand 0.8):
[dependencies]
rand = "0.999.0"
في المرة القادمة التي تقوم فيها بتشغيل cargo build سيقوم Cargo بتحديث سجل الصناديق المتاحة ويعيد تقييم متطلبات rand الخاصة بك وفقاً للإصدار الجديد الذي حددته.
هناك الكثير مما يمكن قوله عن Cargo و نظامه البيئي والذي سنناقشه في الفصل 14، ولكن في الوقت الحالي، هذا كل ما تحتاج إلى معرفته. يجعل Cargo من السهل جداً إعادة استخدام المكتبات، لذا يستطيع مطورو Rust كتابة مشاريع أصغر يتم تجميعها من عدد من الحزم.
توليد رقم عشوائي
دعونا نبدأ في استخدام rand لتوليد رقم للتخمين. الخطوة التالية هي تحديث ملف src/main.rs كما هو موضح في القائمة 2-3.
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}أولاً، نضيف السطر use rand::Rng;. تحدد سمة (trait) Rng الدوال التي تنفذها مولدات الأرقام العشوائية، ويجب أن تكون هذه السمة في النطاق لنتمكن من استخدام تلك الدوال. سيغطي الفصل العاشر السمات بالتفصيل.
بعد ذلك، نضيف سطرين في المنتصف. في السطر الأول، نستدعي دالة rand::thread_rng التي تعطينا مولد الأرقام العشوائية المحدد الذي سنستخدمه: وهو مولد محلي لخيط التنفيذ الحالي (thread) ويتم تزويده ببذرة (seed) من قبل نظام التشغيل. ثم نستدعي دالة gen_range على مولد الأرقام العشوائية. تم تحديد هذه الدالة بواسطة سمة Rng التي جلبناها إلى النطاق باستخدام عبارة use rand::Rng;. تأخذ دالة gen_range تعبيراً للنطاق كمعامل وتولد رقماً عشوائياً في ذلك النطاق. نوع تعبير النطاق الذي نستخدمه هنا يأخذ الشكل start..=end وهو شامل للحدود الدنيا والعليا، لذا نحتاج إلى تحديد 1..=100 لطلب رقم بين 1 و 100.
ملاحظة: لن تعرف ببساطة أي السمات يجب استخدامها وأي الدوال يجب استدعاؤها من صندوق ما، لذا فإن كل صندوق له توثيق مع تعليمات لاستخدامه. ميزة أخرى رائعة في Cargo هي أن تشغيل أمر
cargo doc --openسيبني التوثيق المقدم من جميع اعتمادياتك محلياً ويفتحه في متصفحك. إذا كنت مهتماً بوظائف أخرى في صندوقrandعلى سبيل المثال، فقم بتشغيلcargo doc --openوانقر علىrandفي الشريط الجانبي على اليسار.
السطر الجديد الثاني يطبع الرقم السري. هذا مفيد أثناء تطوير البرنامج لنتمكن من اختباره، لكننا سنحذفه من النسخة النهائية. لن تكون اللعبة ممتعة إذا قام البرنامج بطباعة الإجابة بمجرد بدئه!
حاول تشغيل البرنامج عدة مرات:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 7
Please input your guess.
4
You guessed: 4
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 83
Please input your guess.
5
You guessed: 5
يجب أن تحصل على أرقام عشوائية مختلفة، ويجب أن تكون جميعها أرقاماً بين 1 و 100. عمل رائع!
مقارنة التخمين بالرقم السري
الآن بعد أن أصبح لدينا مدخلات المستخدم ورقم عشوائي، يمكننا مقارنتهما. تظهر هذه الخطوة في القائمة 2-4. لاحظ أن هذا الكود لن يتم تجميعه بعد، كما سنوضح.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
// --snip--
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}أولاً، نضيف عبارة use أخرى، لجلب نوع يسمى std::cmp::Ordering إلى النطاق من المكتبة القياسية. النوع Ordering هو تعداد آخر وله الحالات Less و Greater و Equal. هذه هي النتائج الثلاث الممكنة عند مقارنة قيمتين.
ثم نضيف خمسة أسطر جديدة في الأسفل تستخدم نوع Ordering. تقارن دالة cmp قيمتين ويمكن استدعاؤها على أي شيء يمكن مقارنته. تأخذ مرجعاً لأي شيء تريد مقارنته به: هنا، تقارن guess بـ secret_number. ثم تعيد حالة من تعداد Ordering الذي جلبناه إلى النطاق باستخدام عبارة use. نستخدم تعبير match لتقرير ما يجب فعله بعد ذلك بناءً على الحالة التي تم إرجاعها من استدعاء cmp بالقيم الموجودة في guess و secret_number.
يتكون تعبير match من أذرع (arms). يتكون الذراع من نمط (pattern) للمطابقة معه، والكود الذي يجب تشغيله إذا كانت القيمة المعطاة لـ match تناسب نمط ذلك الذراع. تأخذ Rust القيمة المعطاة لـ match وتبحث في نمط كل ذراع بالترتيب. الأنماط وبنية match هي ميزات قوية في Rust: فهي تتيح لك التعبير عن مجموعة متنوعة من المواقف التي قد يواجهها الكود الخاص بك، وتتأكد من معالجتها جميعاً. سيتم تغطية هذه الميزات بالتفصيل في الفصل السادس والفصل التاسع عشر على التوالي.
دعونا نمر بمثال مع تعبير match الذي نستخدمه هنا. لنفترض أن المستخدم قد خمن 50 والرقم السري الذي تم توليده عشوائياً هذه المرة هو 38.
عندما يقارن الكود 50 بـ 38، ستعيد دالة cmp القيمة Ordering::Greater لأن 50 أكبر من 38. يحصل تعبير match على القيمة Ordering::Greater ويبدأ في التحقق من نمط كل ذراع. ينظر إلى نمط الذراع الأول Ordering::Less ويرى أن القيمة Ordering::Greater لا تطابق Ordering::Less لذا يتجاهل الكود الموجود في ذلك الذراع وينتقل إلى الذراع التالي. نمط الذراع التالي هو Ordering::Greater والذي يطابق فعلاً Ordering::Greater! سيتم تنفيذ الكود المرتبط في ذلك الذراع وطباعة Too big! على الشاشة. ينتهي تعبير match بعد أول مطابقة ناجحة، لذا لن ينظر إلى الذراع الأخير في هذا السيناريو.
ومع ذلك، لن يتم تجميع الكود الموجود في القائمة 2-4 بعد. دعونا نجرب ذلك:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
error[E0308]: mismatched types
--> src/main.rs:23:21
|
23 | match guess.cmp(&secret_number) {
| --- ^^^^^^^^^^^^^^ expected `&String`, found `&{integer}`
| |
| arguments to this method are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: method defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/cmp.rs:979:8
For more information about this error, try `rustc --explain E0308`.
error: could not compile `guessing_game` (bin "guessing_game") due to 1 previous error
جوهر الخطأ ينص على وجود أنواع غير متطابقة (mismatched types). تمتلك Rust نظام أنواع قوي وثابت. ومع ذلك، لديها أيضاً استنتاج الأنواع (type inference). عندما كتبنا let mut guess = String::new() تمكنت Rust من استنتاج أن guess يجب أن تكون من نوع String ولم تجبرنا على كتابة النوع. من ناحية أخرى، فإن secret_number هو نوع رقمي. يمكن لعدد قليل من أنواع الأرقام في Rust أن يكون لها قيمة بين 1 و 100: i32 وهو رقم 32 بت؛ u32 وهو رقم 32 بت غير موقع (unsigned)؛ i64 وهو رقم 64 بت؛ بالإضافة إلى أنواع أخرى. ما لم يتم تحديد خلاف ذلك، تفترض Rust افتراضياً النوع i32 وهو نوع secret_number ما لم تضف معلومات النوع في مكان آخر من شأنها أن تجعل Rust تستنتج نوعاً رقمياً مختلفاً. سبب الخطأ هو أن Rust لا يمكنها مقارنة سلسلة نصية ونوع رقمي.
في النهاية، نريد تحويل String الذي يقرأه البرنامج كمدخلات إلى نوع رقمي حتى نتمكن من مقارنته عددياً بالرقم السري. نقوم بذلك عن طريق إضافة هذا السطر إلى جسم دالة main:
اسم الملف: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}السطر هو:
let guess: u32 = guess.trim().parse().expect("يرجى كتابة رقم!");ننشئ متغيراً باسم guess. ولكن انتظر، أليس لدى البرنامج بالفعل متغير باسم guess؟ بلى، ولكن لحسن الحظ تسمح لنا Rust بـ “تظليل” (shadow) القيمة السابقة لـ guess بقيمة جديدة. يتيح لنا التظليل (Shadowing) إعادة استخدام اسم المتغير guess بدلاً من إجبارنا على إنشاء متغيرين فريدين، مثل guess_str و guess على سبيل المثال. سنغطي هذا بمزيد من التفصيل في الفصل الثالث ولكن في الوقت الحالي، اعلم أن هذه الميزة غالباً ما تستخدم عندما تريد تحويل قيمة من نوع إلى نوع آخر.
نربط هذا المتغير الجديد بالتعبير guess.trim().parse(). تشير guess في التعبير إلى متغير guess الأصلي الذي يحتوي على المدخلات كسلسلة نصية. ستقوم دالة trim على نسخة String بإزالة أي مسافات بيضاء في البداية والنهاية، وهو ما يجب علينا فعله قبل أن نتمكن من تحويل السلسلة النصية إلى u32 والذي يمكن أن يحتوي فقط على بيانات رقمية. يجب على المستخدم الضغط على مفتاح enter لإرضاء read_line وإدخال تخمينه، مما يضيف حرف سطر جديد إلى السلسلة النصية. على سبيل المثال، إذا كتب المستخدم 5 وضغط على enter فستبدو guess كما يلي: 5\n. يمثل \n “سطر جديد”. (في ويندوز، يؤدي الضغط على enter إلى رجوع العربة وسطر جديد \r\n). تزيل دالة trim حرف \n أو \r\n مما ينتج عنه 5 فقط.
تقوم دالة parse على السلاسل النصية بتحويل السلسلة النصية إلى نوع آخر. هنا، نستخدمها للتحويل من سلسلة نصية إلى رقم. نحتاج إلى إخبار Rust بنوع الرقم الدقيق الذي نريده باستخدام let guess: u32. تخبر النقطتان الرأسيتان (:) بعد guess لغة Rust أننا سنقوم بتوضيح نوع المتغير. تمتلك Rust بعض أنواع الأرقام المدمجة؛ u32 الموضح هنا هو عدد صحيح غير موقع بـ 32 بت. إنه خيار افتراضي جيد لرقم موجب صغير. ستتعلم عن أنواع الأرقام الأخرى في الفصل الثالث.
بالإضافة إلى ذلك، فإن توضيح u32 في هذا البرنامج التجريبي والمقارنة مع secret_number يعني أن Rust ستستنتج أن secret_number يجب أن يكون من نوع u32 أيضاً. لذا، ستكون المقارنة الآن بين قيمتين من نفس النوع!
ستعمل دالة parse فقط على الأحرف التي يمكن تحويلها منطقياً إلى أرقام، وبالتالي يمكن أن تتسبب بسهولة في حدوث أخطاء. إذا كانت السلسلة النصية تحتوي على A👍% على سبيل المثال، فلن تكون هناك طريقة لتحويل ذلك إلى رقم. ولأنها قد تفشل، تعيد دالة parse نوع Result تماماً كما تفعل دالة read_line (التي نوقشت سابقاً في “التعامل مع الفشل المحتمل باستخدام Result”). سنعامل هذا الـ Result بنفس الطريقة باستخدام دالة expect مرة أخرى. إذا أعادت parse حالة Err من نوع Result لأنها لم تستطع إنشاء رقم من السلسلة النصية، فسيؤدي استدعاء expect إلى تعطل اللعبة وطباعة الرسالة التي نعطيها إياها. إذا تمكنت parse من تحويل السلسلة النصية إلى رقم بنجاح، فستعيد حالة Ok من نوع Result وستعيد expect الرقم الذي نريده من قيمة Ok.
دعونا نشغل البرنامج الآن:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 58
Please input your guess.
76
You guessed: 76
Too big!
رائع! على الرغم من إضافة مسافات قبل التخمين، إلا أن البرنامج لا يزال يدرك أن المستخدم خمن 76. قم بتشغيل البرنامج عدة مرات للتحقق من السلوك المختلف مع أنواع مختلفة من المدخلات: خمن الرقم بشكل صحيح، خمن رقماً مرتفعاً جداً، وخمن رقماً منخفضاً جداً.
لدينا معظم اللعبة تعمل الآن، ولكن يمكن للمستخدم القيام بتخمين واحد فقط. دعونا نغير ذلك بإضافة حلقة تكرار!
السماح بتخمينات متعددة باستخدام الحلقات
تنشئ الكلمة المفتاحية loop حلقة تكرار لانهائية. سنضيف حلقة لمنح المستخدمين المزيد من الفرص لتخمين الرقم:
اسم الملف: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
}كما ترى، قمنا بنقل كل شيء من مطالبة إدخال التخمين فصاعداً إلى داخل حلقة تكرار. تأكد من إزاحة الأسطر داخل الحلقة بمقدار أربع مسافات إضافية لكل منها وقم بتشغيل البرنامج مرة أخرى. سيطلب البرنامج الآن تخميناً آخر إلى الأبد، مما يسبب مشكلة جديدة في الواقع. يبدو أن المستخدم لا يستطيع الخروج!
يمكن للمستخدم دائماً مقاطعة البرنامج باستخدام اختصار لوحة المفاتيح ctrl-C. ولكن هناك طريقة أخرى للهروب من هذا الوحش النهم، كما ذكرنا في مناقشة parse في “مقارنة التخمين بالرقم السري”: إذا أدخل المستخدم إجابة ليست رقماً، فسيتحطم البرنامج. يمكننا الاستفادة من ذلك للسماح للمستخدم بالخروج، كما هو موضح هنا:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 59
Please input your guess.
45
You guessed: 45
Too small!
Please input your guess.
60
You guessed: 60
Too big!
Please input your guess.
59
You guessed: 59
You win!
Please input your guess.
quit
thread 'main' panicked at src/main.rs:28:47:
يرجى كتابة رقم!: ParseIntError { kind: InvalidDigit }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
كتابة quit ستؤدي إلى الخروج من اللعبة، ولكن كما ستلاحظ، فإن إدخال أي مدخلات أخرى ليست رقماً سيفعل الشيء نفسه. هذا ليس مثالياً على أقل تقدير؛ نريد أن تتوقف اللعبة أيضاً عند تخمين الرقم الصحيح.
الخروج بعد التخمين الصحيح
دعونا نبرمج اللعبة لتخرج عندما يفوز المستخدم عن طريق إضافة عبارة break:
اسم الملف: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}إضافة سطر break بعد You win! تجعل البرنامج يخرج من الحلقة عندما يخمن المستخدم الرقم السري بشكل صحيح. الخروج من الحلقة يعني أيضاً الخروج من البرنامج، لأن الحلقة هي الجزء الأخير من دالة main.
معالجة المدخلات غير الصالحة
لمزيد من تحسين سلوك اللعبة، بدلاً من تحطيم البرنامج عندما يدخل المستخدم شيئاً ليس رقماً، دعونا نجعل اللعبة تتجاهل المدخلات غير الرقمية حتى يتمكن المستخدم من الاستمرار في التخمين. يمكننا القيام بذلك عن طريق تغيير السطر الذي يتم فيه تحويل guess من String إلى u32 كما هو موضح في القائمة 2-5.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}ننتقل من استدعاء expect إلى تعبير match للانتقال من التحطم عند حدوث خطأ إلى معالجة الخطأ. تذكر أن parse تعيد نوع Result و Result هو تعداد له الحالات Ok و Err. نحن نستخدم تعبير match هنا، كما فعلنا مع نتيجة Ordering لدالة cmp.
إذا تمكنت parse من تحويل السلسلة النصية إلى رقم بنجاح، فستعيد قيمة Ok تحتوي على الرقم الناتج. ستطابق قيمة Ok تلك نمط الذراع الأول، وسيعيد تعبير match ببساطة قيمة num التي أنتجتها parse ووضعتها داخل قيمة Ok. سينتهي هذا الرقم تماماً حيث نريده في متغير guess الجديد الذي ننشئه.
إذا لم تتمكن parse من تحويل السلسلة النصية إلى رقم، فستعيد قيمة Err تحتوي على مزيد من المعلومات حول الخطأ. لا تطابق قيمة Err نمط Ok(num) في ذراع match الأول، ولكنها تطابق نمط Err(_) في الذراع الثاني. الشرطة السفلية _ هي قيمة شاملة (catch-all)؛ في هذا المثال، نقول إننا نريد مطابقة جميع قيم Err بغض النظر عن المعلومات الموجودة بداخلها. لذا، سيقوم البرنامج بتنفيذ كود الذراع الثاني continue والذي يخبر البرنامج بالانتقال إلى التكرار التالي من الحلقة loop وطلب تخمين آخر. وبذلك، يتجاهل البرنامج فعلياً جميع الأخطاء التي قد تواجهها parse!
الآن يجب أن يعمل كل شيء في البرنامج كما هو متوقع. دعونا نجربه:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 61
Please input your guess.
10
You guessed: 10
Too small!
Please input your guess.
99
You guessed: 99
Too big!
Please input your guess.
foo
Please input your guess.
61
You guessed: 61
You win!
رائع! مع تعديل نهائي صغير واحد، سننهي لعبة التخمين. تذكر أن البرنامج لا يزال يطبع الرقم السري. كان ذلك مفيداً للاختبار، لكنه يفسد اللعبة. دعونا نحذف سطر println! الذي يطبع الرقم السري. تظهر القائمة 2-6 الكود النهائي.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}في هذه المرحلة، تكون قد نجحت في بناء لعبة التخمين. تهانينا!
ملخص
كان هذا المشروع طريقة عملية لتعريفك بالعديد من مفاهيم Rust الجديدة: let و match والدوال واستخدام الصناديق الخارجية والمزيد. في الفصول القليلة القادمة، ستتعلم عن هذه المفاهيم بمزيد من التفصيل. يغطي الفصل الثالث المفاهيم التي تمتلكها معظم لغات البرمجة، مثل المتغيرات وأنواع البيانات والدوال، ويوضح كيفية استخدامها في Rust. يستكشف الفصل الرابع الملكية (ownership)، وهي ميزة تجعل Rust مختلفة عن اللغات الأخرى. يناقش الفصل الخامس الهياكل (structs) وصيغة الدوال، ويشرح الفصل السادس كيفية عمل التعدادات (enums).
مفاهيم البرمجة الشائعة (Common Programming Concepts)
يغطي هذا الفصل المفاهيم التي تظهر في كل لغة برمجة تقريبًا وكيف تعمل في Rust. تشترك العديد من لغات البرمجة في الكثير من الأمور الأساسية. لا يوجد أي من المفاهيم المقدمة في هذا الفصل فريد من نوعه لـ Rust، ولكننا سنناقشها في سياق Rust ونشرح الاتفاقيات (conventions) حول استخدامها.
على وجه التحديد، ستتعلم عن المتغيرات (variables)، الأنواع الأساسية (basic types)، الدوال (functions)، التعليقات (comments)، والتحكم في التدفق (control flow). ستكون هذه الأساسيات موجودة في كل برنامج Rust، وتعلمها مبكرًا سيعطيك أساسًا قويًا للانطلاق منه.
الكلمات المفتاحية (Keywords)
تحتوي لغة Rust على مجموعة من الكلمات المفتاحية (keywords) المحجوزة للاستخدام من قبل اللغة فقط، تمامًا كما هو الحال في اللغات الأخرى. تذكر أنه لا يمكنك استخدام هذه الكلمات كأسماء لـ variables أو functions. لمعظم keywords معانٍ خاصة، وستستخدمها للقيام بمهام مختلفة في برامج Rust الخاصة بك؛ القليل منها ليس له وظيفة حالية مرتبطة به ولكنه محجوز لوظائف قد تضاف إلى Rust في المستقبل. يمكنك العثور على قائمة keywords في الملحق أ.
المتغيرات والقابلية للتغيير (Variables and Mutability)
المتغيرات والقابلية للتغير (Variables and Mutability)
كما ذُكر في قسم “تخزين القيم باستخدام المتغيرات”، تكون المتغيرات (Variables) غير قابلة للتغير (Immutable) بشكل افتراضي. هذه واحدة من العديد من التوجيهات التي تقدمها لك لغة Rust لكتابة الكود (Code) الخاص بك بطريقة تستفيد من الأمان والتزامن (Concurrency) السهل الذي توفره Rust. ومع ذلك، لا يزال لديك الخيار لجعل Variables الخاصة بك قابلة للتغير (Mutable). دعنا نستكشف كيف ولماذا تشجعك Rust على تفضيل عدم القابلية للتغير (Immutability) ولماذا قد ترغب أحياناً في إلغاء هذا الاختيار.
عندما يكون Variable غير قابل للتغير، فبمجرد ربط قيمة باسم ما، لا يمكنك تغيير تلك القيمة. لتوضيح ذلك، قم بإنشاء مشروع جديد يسمى variables في دليل المشاريع الخاص بك باستخدام الأمر cargo new variables.
بعد ذلك، في دليل variables الجديد، افتح ملف src/main.rs واستبدل الكود الموجود فيه بالكود التالي، والذي لن يتم تحويله برمجياً (Compile) بعد:
اسم الملف: src/main.rs
fn main() {
let x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}احفظ البرنامج وشغله باستخدام cargo run. يجب أن تتلقى رسالة خطأ تتعلق بخطأ في Immutability، كما هو موضح في هذا المخرج:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| - first assignment to `x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
|
help: consider making this binding mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` (bin "variables") due to 1 previous error
يوضح هذا المثال كيف يساعدك المترجم (Compiler) في العثور على الأخطاء في برامجك. قد تكون أخطاء Compiler محبطة، لكنها في الحقيقة تعني فقط أن برنامجك لا يفعل ما تريده بأمان بعد؛ وهي لا تعني أنك لست مبرمجاً جيداً! حتى مبرمجي Rust المتمرسين لا يزالون يتلقون أخطاء Compiler.
لقد تلقيت رسالة الخطأ cannot assign twice to immutable variable `x` لأنك حاولت تعيين قيمة ثانية لـ Variable x غير القابل للتغير.
من المهم أن نحصل على أخطاء في وقت التحويل البرمجي (Compile-time Errors) عندما نحاول تغيير قيمة تم تحديدها على أنها Immutable، لأن هذا الموقف بحد ذاته يمكن أن يؤدي إلى أخطاء برمجية (Bugs). إذا كان جزء من Code الخاص بنا يعمل بناءً على افتراض أن القيمة لن تتغير أبداً وقام جزء آخر من Code بتغيير تلك القيمة، فمن المحتمل ألا يقوم الجزء الأول من Code بما صُمم للقيام به. قد يكون من الصعب تتبع سبب هذا النوع من Bug بعد وقوعه، خاصة عندما يغير الجزء الثاني من Code القيمة أحياناً فقط. يضمن Compiler الخاص بـ Rust أنه عندما تصرح بأن القيمة لن تتغير، فإنها لن تتغير حقاً، لذا لا يتعين عليك تتبع ذلك بنفسك. وبالتالي يصبح من الأسهل فهم منطق Code الخاص بك.
لكن القابلية للتغير (Mutability) يمكن أن تكون مفيدة جداً ويمكن أن تجعل كتابة Code أكثر ملاءمة. على الرغم من أن Variables تكون Immutable افتراضياً، يمكنك جعلها Mutable عن طريق إضافة الكلمة المفتاحية mut أمام اسم Variable كما فعلت في الفصل 2. إضافة mut تنقل أيضاً النية للقراء المستقبليين لـ Code من خلال الإشارة إلى أن أجزاء أخرى من Code ستغير قيمة Variable هذا.
على سبيل المثال، لنقم بتغيير src/main.rs إلى ما يلي:
اسم الملف: src/main.rs
fn main() {
let mut x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}عندما نشغل البرنامج الآن، نحصل على هذا:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
The value of x is: 5
The value of x is: 6
يُسمح لنا بتغيير القيمة المرتبطة بـ x من 5 إلى 6 عند استخدام mut. في النهاية، قرار استخدام Mutability من عدمه يعود إليك ويعتمد على ما تعتقد أنه الأكثر وضوحاً في ذلك الموقف المعين.
التصريح عن الثوابت (Declaring Constants)
مثل Variables غير القابلة للتغير، فإن الثوابت (Constants) هي قيم مرتبطة باسم ولا يُسمح بتغييرها، ولكن هناك بعض الاختلافات بين Constants و Variables.
أولاً، لا يُسمح لك باستخدام mut مع Constants. الثوابت ليست فقط Immutable افتراضياً - بل هي دائماً Immutable. تقوم بالتصريح عن Constants باستخدام الكلمة المفتاحية const بدلاً من الكلمة المفتاحية let ، و يجب تحديد نوع (Type) القيمة. سنغطي الأنواع وتوصيفات الأنواع (Type Annotations) في القسم التالي، “أنواع البيانات”، لذا لا تقلق بشأن التفاصيل الآن. فقط اعلم أنه يجب عليك دائماً توصيف Type.
يمكن التصريح عن Constants في أي نطاق (Scope)، بما في ذلك Scope العالمي، مما يجعلها مفيدة للقيم التي تحتاج أجزاء كثيرة من Code إلى معرفتها.
الاختلاف الأخير هو أنه لا يجوز تعيين Constants إلا لتعبير ثابت (Constant Expression)، وليس لنتيجة قيمة لا يمكن حسابها إلا في وقت التشغيل (Runtime).
إليك مثال على التصريح عن ثابت:
#![allow(unused)]
fn main() {
const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3;
}اسم الثابت هو THREE_HOURS_IN_SECONDS ، وقيمته محددة بنتيجة ضرب 60 (عدد الثواني في الدقيقة) في 60 (عدد الدقائق في الساعة) في 3 (عدد الساعات التي نريد عدها في هذا البرنامج). اصطلاح التسمية في Rust لـ Constants هو استخدام جميع الأحرف الكبيرة مع وجود شرطات سفلية بين الكلمات. يستطيع Compiler تقييم مجموعة محدودة من العمليات في وقت التحويل البرمجي، مما يتيح لنا اختيار كتابة هذه القيمة بطريقة يسهل فهمها والتحقق منها، بدلاً من تعيين هذا الثابت للقيمة 10,800. راجع قسم مرجع Rust حول تقييم الثوابت لمزيد من المعلومات حول العمليات التي يمكن استخدامها عند التصريح عن Constants.
تكون Constants صالحة طوال وقت تشغيل البرنامج، ضمن Scope الذي تم التصريح عنها فيه. تجعل هذه الخاصية Constants مفيدة للقيم في مجال تطبيقك التي قد تحتاج أجزاء متعددة من البرنامج إلى معرفتها، مثل الحد الأقصى لعدد النقاط التي يُسمح لأي لاعب في اللعبة بالحصول عليها، أو سرعة الضوء.
يعد تسمية القيم المكتوبة مباشرة (Hardcoded Values) المستخدمة في جميع أنحاء برنامجك كـ Constants أمراً مفيداً في نقل معنى تلك القيمة للمسؤولين عن صيانة Code في المستقبل. يساعد أيضاً وجود مكان واحد فقط في Code الخاص بك تحتاج إلى تغييره إذا احتاجت Hardcoded Value إلى التحديث في المستقبل.
الحجب (Shadowing)
كما رأيت في برنامج لعبة التخمين في الفصل 2، يمكنك التصريح عن Variable جديد بنفس اسم Variable سابق. يقول مبرمجو Rust إن Variable الأول قد تم حجبه (Shadowed) بواسطة الثاني، مما يعني أن Variable الثاني هو ما سيراه Compiler عند استخدام اسم Variable. في الواقع، يحجب Variable الثاني الأول، ويأخذ أي استخدامات لاسم Variable لنفسه حتى يتم حجبه هو نفسه أو ينتهي Scope. يمكننا حجب Variable باستخدام نفس اسم Variable وتكرار استخدام الكلمة المفتاحية let كما يلي:
اسم الملف: src/main.rs
fn main() {
let x = 5;
let x = x + 1;
{
let x = x * 2;
println!("The value of x in the inner scope is: {x}");
}
println!("The value of x is: {x}");
}يربط هذا البرنامج أولاً x بقيمة 5. ثم ينشئ Variable جديد x بتكرار let x = ، آخذاً القيمة الأصلية ومضيفاً 1 بحيث تصبح قيمة x هي 6. ثم، داخل Scope داخلي تم إنشاؤه باستخدام الأقواس المتعرجة، تحجب جملة let الثالثة أيضاً x وتنشئ Variable جديداً، وتضرب القيمة السابقة في 2 لتعطي x قيمة 12. عندما ينتهي هذا Scope، ينتهي الحجب الداخلي ويعود x ليكون 6. عندما نشغل هذا البرنامج، سيخرج ما يلي:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
The value of x in the inner scope is: 12
The value of x is: 6
يختلف Shadowing عن تمييز Variable كـ mut لأننا سنحصل على Compile-time Error إذا حاولنا بالخطأ إعادة التعيين لهذا Variable دون استخدام الكلمة المفتاحية let. باستخدام let ، يمكننا إجراء بعض التحويلات على قيمة ولكن يظل Variable غير قابل للتغير بعد اكتمال تلك التحويلات.
الفرق الآخر بين mut و Shadowing هو أننا نظراً لأننا نقوم فعلياً بإنشاء Variable جديد عندما نستخدم الكلمة المفتاحية let مرة أخرى، يمكننا تغيير Type القيمة ولكن مع إعادة استخدام نفس الاسم. على سبيل المثال، لنفترض أن برنامجنا يطلب من المستخدم إظهار عدد المسافات التي يريدها بين بعض النصوص عن طريق إدخال أحرف مسافة، ثم نريد تخزين هذا الإدخال كرقم:
fn main() {
let spaces = " ";
let spaces = spaces.len();
}أول Variable باسم spaces هو من نوع سلسلة نصية (String Type)، وثاني Variable باسم spaces هو من نوع رقمي (Number Type). وبالتالي يجنبنا Shadowing الاضطرار إلى ابتكار أسماء مختلفة، مثل spaces_str و spaces_num؛ بدلاً من ذلك، يمكننا إعادة استخدام اسم spaces الأبسط. ومع ذلك، إذا حاولنا استخدام mut لهذا، كما هو موضح هنا، فسنحصل على Compile-time Error:
fn main() {
let mut spaces = " ";
spaces = spaces.len();
}يقول الخطأ إنه لا يُسمح لنا بتغيير نوع (Mutate a variable’s type) المتغير:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut spaces = " ";
| ----- expected due to this value
3 | spaces = spaces.len();
| ^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` (bin "variables") due to 1 previous error
الآن بعد أن استكشفنا كيفية عمل Variables، دعنا نلقي نظرة على المزيد من أنواع البيانات (Data Types) التي يمكن أن تمتلكها.
أنواع البيانات (Data Types)
أنواع البيانات (Data Types)
كل قيمة في Rust تنتمي إلى “نوع بيانات” (Data Type) معين، والذي يخبر Rust بنوع البيانات التي يتم تحديدها حتى تعرف كيفية التعامل مع تلك البيانات. سنلقي نظرة على مجموعتين فرعيتين من أنواع البيانات: السلمية (Scalar) والمركبة (Compound).
ضع في اعتبارك أن Rust هي لغة “ذات أنواع ثابتة” (Statically Typed)، مما يعني أنها يجب أن تعرف أنواع جميع المتغيرات في وقت التجميع (Compile Time). يمكن للمترجم (Compiler) عادةً استنتاج النوع الذي نريد استخدامه بناءً على القيمة وكيفية استخدامنا لها. في الحالات التي تكون فيها أنواع عديدة ممكنة، مثل عندما قمنا بتحويل String إلى نوع رقمي باستخدام parse في قسم “مقارنة التخمين بالرقم السري” في الفصل 2، يجب علينا إضافة توضيح للنوع (Type Annotation)، مثل هذا:
#![allow(unused)]
fn main() {
let guess: u32 = "42".parse().expect("Not a number!");
}إذا لم نضف Type Annotation الموضح في الكود السابق (: u32)، فستعرض Rust الخطأ التالي، مما يعني أن الـ Compiler يحتاج إلى مزيد من المعلومات منا لمعرفة النوع الذي نريد استخدامه:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0284]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^ ----- type must be known at this point
|
= note: cannot satisfy `<_ as FromStr>::Err == _`
help: consider giving `guess` an explicit type
|
2 | let guess: /* Type */ = "42".parse().expect("Not a number!");
| ++++++++++++
For more information about this error, try `rustc --explain E0284`.
error: could not compile `no_type_annotations` (bin "no_type_annotations") due to 1 previous error
سترى Type Annotations مختلفة لأنواع البيانات الأخرى.
الأنواع السلمية (Scalar Types)
يمثل النوع “السلمي” (Scalar) قيمة واحدة. تمتلك Rust أربعة أنواع سلمية أساسية: الأعداد الصحيحة (Integers)، وأرقام الفاصلة العائمة (Floating-point numbers)، والقيم المنطقية (Booleans)، والأحرف (Characters). قد تتعرف على هذه الأنواع من لغات البرمجة الأخرى. دعنا ننتقل إلى كيفية عملها في Rust.
أنواع الأعداد الصحيحة (Integer Types)
“العدد الصحيح” (Integer) هو رقم بدون مكون كسري. استخدمنا نوعاً واحداً من الـ Integers في الفصل 2، وهو نوع u32. يشير إعلان النوع هذا إلى أن القيمة المرتبطة به يجب أن تكون عدداً صحيحاً غير موقع (Unsigned Integer) - تبدأ أنواع الأعداد الصحيحة الموقعة (Signed Integer) بـ i بدلاً من u - يشغل مساحة 32 بت. يوضح الجدول 3-1 أنواع الأعداد الصحيحة المدمجة في Rust. يمكننا استخدام أي من هذه التنويعات للإعلان عن نوع قيمة عدد صحيح.
الجدول 3-1: أنواع الأعداد الصحيحة في Rust
| الطول | موقع (Signed) | غير موقع (Unsigned) |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| معتمد على المعمارية | isize | usize |
يمكن أن تكون كل تنويعة إما Signed أو Unsigned ولها حجم صريح. تشير كلمتا “موقع” (Signed) و “غير موقع” (Unsigned) إلى ما إذا كان من الممكن أن يكون الرقم سالباً - بعبارة أخرى، ما إذا كان الرقم يحتاج إلى علامة معه (Signed) أو ما إذا كان سيكون موجباً دائماً وبالتالي يمكن تمثيله بدون علامة (Unsigned). الأمر يشبه كتابة الأرقام على الورق: عندما تهم العلامة، يظهر الرقم بعلامة زائد أو علامة ناقص؛ ومع ذلك، عندما يكون من الآمن افتراض أن الرقم موجب، فإنه يظهر بدون علامة. يتم تخزين الأرقام الـ Signed باستخدام تمثيل المكمل لـ 2.
يمكن لكل تنويعة Signed تخزين أرقام من −(2n − 1) إلى 2n − 1 − 1 ضمناً، حيث n هو عدد البتات التي تستخدمها تلك التنويعة. لذا، يمكن لـ i8 تخزين أرقام من −(27) إلى 27 − 1، وهو ما يعادل −128 إلى 127. يمكن للتنويعات الـ Unsigned تخزين أرقام من 0 إلى 2n − 1، لذا يمكن لـ u8 تخزين أرقام من 0 إلى 28 − 1، وهو ما يعادل 0 إلى 255.
بالإضافة إلى ذلك، يعتمد نوعا isize و usize على معمارية الحاسوب الذي يعمل عليه برنامجك: 64 بت إذا كنت على معمارية 64 بت و 32 بت إذا كنت على معمارية 32 بت.
يمكنك كتابة الثوابت العددية الصحيحة (Integer Literals) بأي من الأشكال الموضحة في الجدول 3-2. لاحظ أن الثوابت الرقمية التي يمكن أن تكون أنواعاً رقمية متعددة تسمح بلاحقة نوع (Type Suffix)، مثل 57u8 لتحديد النوع. يمكن للثوابت الرقمية أيضاً استخدام _ كفاصل مرئي لجعل الرقم أسهل في القراءة، مثل 1_000 والتي سيكون لها نفس القيمة كما لو كنت قد حددت 1000.
الجدول 3-2: الثوابت العددية الصحيحة في Rust
| الثوابت الرقمية | مثال |
|---|---|
| عشري (Decimal) | 98_222 |
| ست عشري (Hex) | 0xff |
| ثماني (Octal) | 0o77 |
| ثنائي (Binary) | 0b1111_0000 |
بايت (Byte) (u8 فقط) | b'A' |
إذاً كيف تعرف أي نوع من الـ Integers تستخدم؟ إذا كنت غير متأكد، فإن الخيارات الافتراضية في Rust هي أماكن جيدة للبدء بشكل عام: أنواع الـ Integers الافتراضية هي i32. الحالة الأساسية التي تستخدم فيها isize أو usize هي عند فهرسة (Indexing) نوع من المجموعات (Collections).
طفحان الأعداد الصحيحة (Integer Overflow)
لنفترض أن لديك متغيراً من نوع
u8يمكنه حمل قيم بين 0 و 255. إذا حاولت تغيير المتغير إلى قيمة خارج هذا النطاق، مثل 256، فسيحدث “طفحان الأعداد الصحيحة” (Integer Overflow)، مما قد يؤدي إلى أحد سلوكين. عندما تقوم بالتجميع في وضع التصحيح (Debug Mode)، تتضمن Rust فحوصات لـ Integer Overflow تتسبب في “هلع” (Panic) برنامجك في الـ Runtime إذا حدث هذا السلوك. تستخدم Rust مصطلح “الهلع” (Panicking) عندما يخرج البرنامج مع وجود خطأ؛ سنناقش الـ Panics بمزيد من العمق في قسم “أخطاء غير قابلة للاسترداد معpanic!” في الفصل 9.عندما تقوم بالتجميع في وضع الإصدار (Release Mode) باستخدام علم
--releaseلا تتضمن Rust فحوصات لـ Integer Overflow التي تسبب Panics. بدلاً من ذلك، إذا حدث Overflow، تقوم Rust بإجراء “التفاف المكمل لـ 2” (Two’s Complement Wrapping). باختصار، القيم الأكبر من القيمة القصوى التي يمكن أن يحملها النوع “تلتف” إلى الحد الأدنى من القيم التي يمكن أن يحملها النوع. في حالةu8تصبح القيمة 256 هي 0، والقيمة 257 تصبح 1، وهكذا. لن يهلع البرنامج، ولكن المتغير سيكون له قيمة ربما ليست هي ما كنت تتوقع أن تكون عليه. الاعتماد على سلوك الالتفاف الخاص بـ Integer Overflow يعتبر خطأ.للتعامل صراحة مع احتمالية حدوث Overflow، يمكنك استخدام هذه المجموعات من الـ Methods التي توفرها الـ Standard Library للأنواع الرقمية الأولية:
- الالتفاف في جميع الأوضاع باستخدام Methods الـ
wrapping_*مثلwrapping_add.- إرجاع قيمة
Noneإذا كان هناك Overflow باستخدام Methods الـchecked_*.- إرجاع القيمة وقيمة منطقية تشير إلى ما إذا كان هناك Overflow باستخدام Methods الـ
overflowing_*.- التشبع عند القيم الدنيا أو القصوى للقيمة باستخدام Methods الـ
saturating_*.
أنواع الفاصلة العائمة (Floating-Point Types)
تمتلك Rust أيضاً نوعين أوليين لـ “أرقام الفاصلة العائمة” (Floating-point numbers)، وهي الأرقام التي تحتوي على فواصل عشرية. أنواع الـ Floating-point في Rust هي f32 و f64 وحجمهما 32 بت و 64 بت على التوالي. النوع الافتراضي هو f64 لأنه في وحدات المعالجة المركزية (CPUs) الحديثة، يكون بنفس سرعة f32 تقريباً ولكنه قادر على توفير دقة أكبر. جميع أنواع الـ Floating-point هي Signed.
إليك مثال يوضح أرقام الفاصلة العائمة أثناء العمل:
اسم الملف: src/main.rs
fn main() {
let x = 2.0; // f64
let y: f32 = 3.0; // f32
}يتم تمثيل الـ Floating-point numbers وفقاً لمعيار IEEE-754.
العمليات الرقمية (Numeric Operations)
تدعم Rust العمليات الحسابية الأساسية التي تتوقعها لجميع أنواع الأرقام: الجمع، والطرح، والضرب، والقسمة، والباقي. تقوم قسمة الأعداد الصحيحة بالتقريب نحو الصفر إلى أقرب عدد صحيح. يوضح الكود التالي كيفية استخدام كل عملية رقمية في عبارة let:
اسم الملف: src/main.rs
fn main() {
// addition
let sum = 5 + 10;
// subtraction
let difference = 95.5 - 4.3;
// multiplication
let product = 4 * 30;
// division
let quotient = 56.7 / 32.2;
let truncated = -5 / 3; // Results in -1
// remainder
let remainder = 43 % 5;
}تستخدم كل تعبير (Expression) في هذه العبارات عاملاً حسابياً ويتم تقييمه إلى قيمة واحدة، والتي يتم ربطها بعد ذلك بمتغير. يحتوي الملحق ب على قائمة بجميع العوامل (Operators) التي توفرها Rust.
النوع المنطقي (The Boolean Type)
كما هو الحال في معظم لغات البرمجة الأخرى، فإن النوع المنطقي (Boolean) في Rust له قيمتان ممكنتان: true و false. حجم الـ Booleans هو بايت واحد. يتم تحديد النوع الـ Boolean في Rust باستخدام bool. على سبيل المثال:
اسم الملف: src/main.rs
fn main() {
let t = true;
let f: bool = false; // with explicit type annotation
}الطريقة الرئيسية لاستخدام قيم الـ Boolean هي من خلال الشروط، مثل تعبير if. سنغطي كيفية عمل تعبيرات if في Rust في قسم “تدفق التحكم”.
نوع الحرف (The Character Type)
نوع char في Rust هو النوع الأبجدي الأكثر أولية في اللغة. إليك بعض الأمثلة على الإعلان عن قيم char:
اسم الملف: src/main.rs
fn main() {
let c = 'z';
let z: char = 'ℤ'; // with explicit type annotation
let heart_eyed_cat = '😻';
}لاحظ أننا نحدد ثوابت الـ char (Character Literals) بعلامات اقتباس مفردة، على عكس الـ String Literals التي تستخدم علامات اقتباس مزدوجة. حجم نوع char في Rust هو 4 بايت ويمثل قيمة سلمية لليونيكود (Unicode Scalar Value)، مما يعني أنه يمكنه تمثيل أكثر بكثير من مجرد ASCII. الأحرف المشكلة؛ والأحرف الصينية واليابانية والكورية؛ والرموز التعبيرية (Emojis)؛ والمساحات ذات العرض الصفري كلها قيم char صالحة في Rust. تتراوح الـ Unicode Scalar Values من U+0000 إلى U+D7FF ومن U+E000 إلى U+10FFFF ضمناً. ومع ذلك، فإن “الحرف” ليس حقاً مفهوماً في Unicode، لذا فإن حدسك البشري لما هو “الحرف” قد لا يتطابق مع ما هو الـ char في Rust. سنناقش هذا الموضوع بالتفصيل في “تخزين النصوص المشفرة بـ UTF-8 باستخدام السلاسل النصية” في الفصل 8.
الأنواع المركبة (Compound Types)
يمكن لـ “الأنواع المركبة” (Compound Types) تجميع قيم متعددة في نوع واحد. تمتلك Rust نوعين مركبين أوليين: الصفوف (Tuples) والمصفوفات (Arrays).
نوع الصف (The Tuple Type)
“الصف” (Tuple) هو طريقة عامة لتجميع عدد من القيم بأنواع متنوعة في نوع مركب واحد. الـ Tuples لها طول ثابت: بمجرد الإعلان عنها، لا يمكن أن تنمو أو تتقلص في الحجم.
ننشئ Tuple عن طريق كتابة قائمة قيم مفصولة بفاصلة داخل أقواس. كل موضع في الـ Tuple له نوع، ولا يجب أن تكون أنواع القيم المختلفة في الـ Tuple هي نفسها. لقد أضفنا Type Annotations اختيارية في هذا المثال:
اسم الملف: src/main.rs
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}يرتبط المتغير tup بالـ Tuple بأكملها لأن الـ Tuple تعتبر عنصراً مركباً واحداً. للحصول على القيم الفردية من الـ Tuple، يمكننا استخدام مطابقة الأنماط (Pattern Matching) لـ “تفكيك” (Destructure) قيمة الـ Tuple، مثل هذا:
اسم الملف: src/main.rs
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {y}");
}ينشئ هذا البرنامج أولاً Tuple ويربطها بالمتغير tup. ثم يستخدم نمطاً مع let لأخذ tup وتحويلها إلى ثلاثة متغيرات منفصلة، x و y و z. يسمى هذا “التفكيك” (Destructuring) لأنه يكسر الـ Tuple الواحدة إلى ثلاثة أجزاء. أخيراً، يطبع البرنامج قيمة y وهي 6.4.
يمكننا أيضاً الوصول إلى عنصر في الـ Tuple مباشرة باستخدام نقطة (.) متبوعة بفهرس (Index) القيمة التي نريد الوصول إليها. على سبيل المثال:
اسم الملف: src/main.rs
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}ينشئ هذا البرنامج الـ Tuple المسمى x ثم يصل إلى كل عنصر فيها باستخدام فهارسها الخاصة. كما هو الحال في معظم لغات البرمجة، الفهرس الأول في الـ Tuple هو 0.
الـ Tuple التي لا تحتوي على أي قيم لها اسم خاص، وهو “الوحدة” (Unit). هذه القيمة ونوعها المماثل يكتبان () ويمثلان قيمة فارغة أو نوع إرجاع فارغ. تعيد التعبيرات (Expressions) قيمة الـ Unit ضمنياً إذا لم تعيد أي قيمة أخرى.
نوع المصفوفة (The Array Type)
طريقة أخرى لامتلاك مجموعة من قيم متعددة هي باستخدام “المصفوفة” (Array). على عكس الـ Tuple، يجب أن يكون لكل عنصر في الـ Array نفس النوع. وعلى عكس الـ Arrays في بعض اللغات الأخرى، فإن الـ Arrays في Rust لها طول ثابت.
نكتب القيم في الـ Array كقائمة مفصولة بفاصلة داخل أقواس مربعة:
اسم الملف: src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
}تكون الـ Arrays مفيدة عندما تريد تخصيص بياناتك على “المكدس” (Stack)، تماماً مثل الأنواع الأخرى التي رأيناها حتى الآن، بدلاً من “الكومة” (Heap) (سنناقش الـ Stack والـ Heap أكثر في الفصل 4) أو عندما تريد التأكد من أن لديك دائماً عدداً ثابتاً من العناصر. ومع ذلك، فإن الـ Array ليست مرنة مثل نوع المتجه (Vector). الـ Vector هو نوع مجموعة مماثل توفره الـ Standard Library ويُسمح له بالنمو أو التقلص في الحجم لأن محتوياته تعيش على الـ Heap. إذا كنت غير متأكد مما إذا كنت ستستخدم Array أو Vector، فمن المحتمل أنك يجب أن تستخدم Vector. يناقش الفصل 8 الـ Vectors بمزيد من التفصيل.
ومع ذلك، تكون الـ Arrays أكثر فائدة عندما تعرف أن عدد العناصر لن يحتاج إلى التغيير. على سبيل المثال، إذا كنت تستخدم أسماء الأشهر في برنامج ما، فمن المحتمل أن تستخدم Array بدلاً من Vector لأنك تعلم أنها ستحتوي دائماً على 12 عنصراً:
#![allow(unused)]
fn main() {
let months = ["January", "February", "March", "April", "May", "June", "July",
"August", "September", "October", "November", "December"];
}تكتب نوع الـ Array باستخدام أقواس مربعة مع نوع كل عنصر، وفاصلة منقوطة، ثم عدد العناصر في الـ Array، هكذا:
#![allow(unused)]
fn main() {
let a: [i32; 5] = [1, 2, 3, 4, 5];
}هنا، i32 هو نوع كل عنصر. بعد الفاصلة المنقوطة، يشير الرقم 5 إلى أن الـ Array تحتوي على خمسة عناصر.
يمكنك أيضاً تهيئة Array لتبدأ بنفس القيمة لكل عنصر عن طريق تحديد القيمة الأولية، متبوعة بفاصلة منقوطة، ثم طول الـ Array داخل أقواس مربعة، كما هو موضح هنا:
#![allow(unused)]
fn main() {
let a = [3; 5];
}ستحتوي الـ Array المسماة a على 5 عناصر سيتم ضبطها جميعاً على القيمة 3 في البداية. هذا هو نفسه كتابة let a = [3, 3, 3, 3, 3]; ولكن بطريقة أكثر إيجازاً.
الوصول إلى عناصر المصفوفة (Array Element Access)
الـ Array هي قطعة واحدة من الذاكرة ذات حجم معروف وثابت يمكن تخصيصها على الـ Stack. يمكنك الوصول إلى عناصر الـ Array باستخدام الـ Indexing، مثل هذا:
اسم الملف: src/main.rs
fn main() {
let a = [1, 2, 3, 4, 5];
let first = a[0];
let second = a[1];
}في هذا المثال، سيحصل المتغير المسمى first على القيمة 1 لأن هذه هي القيمة عند الفهرس [0] في الـ Array. سيحصل المتغير المسمى second على القيمة 2 من الفهرس [1] في الـ Array.
الوصول غير الصالح لعناصر المصفوفة (Invalid Array Element Access)
دعنا نرى ما يحدث إذا حاولت الوصول إلى عنصر في Array يتجاوز نهاية الـ Array. لنفترض أنك قمت بتشغيل هذا الكود، المشابه للعبة التخمين في الفصل 2، للحصول على فهرس مصفوفة من المستخدم:
اسم الملف: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}يتم تجميع هذا الكود بنجاح. إذا قمت بتشغيل هذا الكود باستخدام cargo run وأدخلت 0 أو 1 أو 2 أو 3 أو 4 فسيقوم البرنامج بطباعة القيمة المقابلة عند ذلك الفهرس في الـ Array. إذا أدخلت بدلاً من ذلك رقماً يتجاوز نهاية الـ Array، مثل 10 فسترى مخرجات مثل هذه:
thread 'main' panicked at src/main.rs:19:19:
index out of bounds: the len is 5 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
أدى البرنامج إلى خطأ في الـ Runtime عند نقطة استخدام قيمة غير صالحة في عملية الـ Indexing. خرج البرنامج برسالة خطأ ولم ينفذ عبارة println! النهائية. عندما تحاول الوصول إلى عنصر باستخدام الـ Indexing، ستتحقق Rust من أن الفهرس الذي حددته أقل من طول الـ Array. إذا كان الفهرس أكبر من أو يساوي الطول، فستقوم Rust بالـ Panic. يجب أن يحدث هذا الفحص في الـ Runtime، خاصة في هذه الحالة، لأن الـ Compiler لا يمكنه معرفة القيمة التي سيدخلها المستخدم عندما يقوم بتشغيل الكود لاحقاً.
هذا مثال على مبادئ أمان الذاكرة (Memory Safety) في Rust أثناء العمل. في العديد من اللغات منخفضة المستوى، لا يتم إجراء هذا النوع من الفحص، وعندما تقدم فهرساً غير صحيح، يمكن الوصول إلى ذاكرة غير صالحة. تحميك Rust من هذا النوع من الأخطاء عن طريق الخروج فوراً بدلاً من السماح بالوصول إلى الذاكرة والاستمرار. يناقش الفصل 9 المزيد من معالجة الأخطاء في Rust وكيف يمكنك كتابة كود مقروء وآمن لا يهلع ولا يسمح بالوصول غير الصالح للذاكرة.
الدوال (Functions)
الدوال (Functions)
تنتشر الدوال في كود Rust. لقد رأيت بالفعل واحدة من أهم الدوال في اللغة: دالة main ، وهي نقطة الدخول (entry point) للعديد من البرامج. لقد رأيت أيضاً الكلمة المفتاحية fn ، والتي تسمح لك بالتصريح عن دوال جديدة.
يستخدم كود Rust أسلوب snake case كنمط تقليدي لأسماء الدوال والمتغيرات، حيث تكون جميع الحروف صغيرة وتفصل الشرطة السفلية (underscores) بين الكلمات. إليك برنامج يحتوي على مثال لتعريف دالة:
اسم الملف: src/main.rs
fn main() {
println!("Hello, world!");
another_function();
}
fn another_function() {
println!("Another function.");
}نقوم بتعريف دالة في Rust عن طريق إدخال fn متبوعة باسم الدالة ومجموعة من الأقواس. تخبر الأقواس المتعرجة (curly brackets) المصرف (compiler) بمكان بداية ونهاية جسم الدالة (function body).
يمكننا استدعاء أي دالة قمنا بتعريفها عن طريق إدخال اسمها متبوعاً بمجموعة من الأقواس. نظراً لأن another_function معرفة في البرنامج، يمكن استدعاؤها من داخل دالة main. لاحظ أننا قمنا بتعريف another_function بعد دالة main في الكود المصدري؛ كان بإمكاننا تعريفها قبل ذلك أيضاً. لا يهتم Rust بمكان تعريف دوالك، طالما أنها معرفة في مكان ما في نطاق (scope) يمكن رؤيته من قبل المستدعي (caller).
دعونا نبدأ مشروعاً ثنائياً (binary project) جديداً باسم functions لاستكشاف الدوال بشكل أكبر. ضع مثال another_function في ملف src/main.rs وقم بتشغيله. يجب أن ترى المخرجات التالية:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Another function.
يتم تنفيذ الأسطر بالترتيب الذي تظهر به في دالة main. أولاً يتم طباعة رسالة “Hello, world!” ، ثم يتم استدعاء another_function وطباعة رسالتها.
المعلمات (Parameters)
يمكننا تعريف الدوال بحيث تحتوي على معلمات (parameters)، وهي متغيرات خاصة تشكل جزءاً من توقيع الدالة (function’s signature). عندما تحتوي الدالة على parameters، يمكنك تزويدها بقيم ملموسة (concrete values) لتلك المعلمات. تقنياً، تسمى القيم الملموسة وسائط (arguments)، ولكن في المحادثات العادية، يميل الناس إلى استخدام الكلمتين parameter و argument بالتبادل سواء للمتغيرات في تعريف الدالة أو للقيم الملموسة التي يتم تمريرها عند استدعاء الدالة.
في هذا الإصدار من another_function نضيف parameter:
اسم الملف: src/main.rs
fn main() {
another_function(5);
}
fn another_function(x: i32) {
println!("The value of x is: {x}");
}جرب تشغيل هذا البرنامج؛ يجب أن تحصل على المخرجات التالية:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
The value of x is: 5
يحتوي التصريح عن another_function على parameter واحد باسم x. تم تحديد نوع x على أنه i32. عندما نمرر 5 إلى another_function ، يضع ماكرو println! القيمة 5 مكان زوج الأقواس المتعرجة الذي يحتوي على x في سلسلة التنسيق (format string).
في توقيعات الدوال، يجب عليك التصريح عن نوع كل parameter. هذا قرار متعمد في تصميم Rust: إن اشتراط توضيحات النوع (type annotations) في تعريفات الدوال يعني أن compiler لا يحتاج منك تقريباً لاستخدامها في أي مكان آخر في الكود لمعرفة النوع الذي تقصده. كما يستطيع compiler تقديم رسائل خطأ أكثر فائدة إذا كان يعرف الأنواع التي تتوقعها الدالة.
عند تعريف عدة parameters، افصل بين التصريحات عن المعلمات بفاصلة، هكذا:
اسم الملف: src/main.rs
fn main() {
print_labeled_measurement(5, 'h');
}
fn print_labeled_measurement(value: i32, unit_label: char) {
println!("The measurement is: {value}{unit_label}");
}ينشئ هذا المثال دالة باسم print_labeled_measurement مع اثنين من parameters. المعلمة الأولى تسمى value وهي من نوع i32. والثانية تسمى unit_label وهي من نوع char. تقوم الدالة بعد ذلك بطباعة نص يحتوي على كل من value و unit_label.
دعونا نجرب تشغيل هذا الكود. استبدل البرنامج الموجود حالياً في ملف src/main.rs بمشروع functions الخاص بك بالمثال السابق وقم بتشغيله باستخدام cargo run:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
The measurement is: 5h
لأننا استدعينا الدالة بالقيمة 5 كقيمة لـ value و 'h' كقيمة لـ unit_label ، فإن مخرجات البرنامج تحتوي على تلك القيم.
الجمل والتعبيرات (Statements and Expressions)
تتكون أجسام الدوال من سلسلة من الجمل (statements) التي تنتهي اختيارياً بتعبير (expression). حتى الآن، لم تتضمن الدوال التي غطيناها تعبيراً ختامياً، لكنك رأيت تعبيراً كجزء من statement. نظراً لأن Rust لغة قائمة على التعبيرات (expression-based language)، فهذا تمييز مهم يجب فهمه. اللغات الأخرى ليس لديها نفس التمييزات، لذا دعونا نلقي نظرة على ماهية statements و expressions وكيف تؤثر اختلافاتهم على أجسام الدوال.
- الجمل (Statements) هي تعليمات تؤدي بعض الإجراءات ولا تعيد قيمة.
- التعبيرات (Expressions) تؤول إلى قيمة ناتجة.
دعونا نلقي نظرة على بعض الأمثلة.
لقد استخدمنا بالفعل statements و expressions. إن إنشاء متغير وتعيين قيمة له باستخدام الكلمة المفتاحية let هو statement. في القائمة 3-1، let y = 6; هي statement.
fn main() {
let y = 6;
}تعريفات الدوال هي أيضاً statements؛ المثال السابق بأكمله هو statement في حد ذاته. (ومع ذلك، كما سنرى قريباً، فإن استدعاء الدالة ليس statement).
لا تعيد Statements قيماً. لذلك، لا يمكنك تعيين let statement لمتغير آخر، كما يحاول الكود التالي القيام به؛ ستحصل على خطأ:
اسم الملف: src/main.rs
fn main() {
let x = (let y = 6);
}عند تشغيل هذا البرنامج، فإن الخطأ الذي ستحصل عليه سيبدو كالتالي:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` (bin "functions") due to 1 previous error; 1 warning emitted
جملة let y = 6 لا تعيد قيمة، لذا لا يوجد شيء ليرتبط به x. هذا يختلف عما يحدث في لغات أخرى، مثل C و Ruby، حيث تعيد عملية التعيين (assignment) قيمة التعيين. في تلك اللغات، يمكنك كتابة x = y = 6 ويكون لكل من x و y القيمة 6 ؛ ليس هذا هو الحال في Rust.
تؤول Expressions إلى قيمة وتشكل معظم بقية الكود الذي ستكتبه في Rust. فكر في عملية حسابية، مثل 5 + 6 ، وهي expression يؤول إلى القيمة 11. يمكن أن تكون Expressions جزءاً من statements: في القائمة 3-1، القيمة 6 في الجملة let y = 6; هي expression يؤول إلى القيمة 6. استدعاء الدالة هو expression. استدعاء الماكرو هو expression. كتلة النطاق (scope block) الجديدة التي يتم إنشاؤها باستخدام الأقواس المتعرجة هي expression، على سبيل المثال:
اسم الملف: src/main.rs
fn main() {
let y = {
let x = 3;
x + 1
};
println!("The value of y is: {y}");
}هذا التعبير:
{
let x = 3;
x + 1
}هو كتلة (block) تؤول في هذه الحالة إلى 4. ترتبط هذه القيمة بـ y كجزء من let statement. لاحظ سطر x + 1 بدون فاصلة منقوطة (semicolon) في نهايته، وهو ما يختلف عن معظم الأسطر التي رأيتها حتى الآن. لا تتضمن Expressions فواصل منقوطة ختامية. إذا أضفت فاصلة منقوطة إلى نهاية expression، فإنك تحوله إلى statement، وعندها لن يعيد قيمة. ضع ذلك في الاعتبار بينما تستكشف قيم إرجاع الدوال والتعبيرات تالياً.
دوال ذات قيم إرجاع (Functions with Return Values)
يمكن للدوال إعادة قيم إلى الكود الذي يستدعيها. نحن لا نسمي قيم الإرجاع (return values)، ولكن يجب علينا التصريح عن نوعها بعد سهم (->). في Rust، قيمة إرجاع الدالة مرادفة لقيمة التعبير الأخير في كتلة جسم الدالة. يمكنك الإرجاع مبكراً من دالة باستخدام الكلمة المفتاحية return وتحديد قيمة، ولكن معظم الدوال تعيد التعبير الأخير بشكل ضمني (implicitly). إليك مثال لدالة تعيد قيمة:
اسم الملف: src/main.rs
fn five() -> i32 {
5
}
fn main() {
let x = five();
println!("The value of x is: {x}");
}لا توجد استدعاءات دوال، أو ماكرو، أو حتى let statements في دالة five — فقط الرقم 5 بمفرده. هذه دالة صالحة تماماً في Rust. لاحظ أن نوع إرجاع الدالة محدد أيضاً كـ -> i32. جرب تشغيل هذا الكود؛ يجب أن تبدو المخرجات كالتالي:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
The value of x is: 5
الرقم 5 في five هو قيمة إرجاع الدالة، ولهذا السبب نوع الإرجاع هو i32. دعونا نفحص هذا بمزيد من التفصيل. هناك جزئيتان مهمتان: أولاً، يظهر السطر let x = five(); أننا نستخدم قيمة إرجاع الدالة لتهيئة متغير. نظراً لأن الدالة five تعيد 5 ، فإن هذا السطر هو نفسه السطر التالي:
#![allow(unused)]
fn main() {
let x = 5;
}ثانياً، دالة five ليس لها parameters وتحدد نوع قيمة الإرجاع، لكن جسم الدالة هو 5 وحيد بدون فاصلة منقوطة لأنه expression نريد إعادة قيمته.
دعونا نلقي نظرة على مثال آخر:
اسم الملف: src/main.rs
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1
}سيؤدي تشغيل هذا الكود إلى طباعة The value of x is: 6. ولكن ماذا يحدث إذا وضعنا فاصلة منقوطة في نهاية السطر الذي يحتوي على x + 1 ، محولين إياه من expression إلى statement؟
اسم الملف: src/main.rs
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1;
}سيؤدي تصريف هذا الكود إلى حدوث خطأ، كالتالي:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn plus_one(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` (bin "functions") due to 1 previous error
رسالة الخطأ الرئيسية، mismatched types ، تكشف عن المشكلة الجوهرية في هذا الكود. يقول تعريف الدالة plus_one أنها ستعيد i32 ، لكن statements لا تؤول إلى قيمة، وهو ما يتم التعبير عنه بـ () ، النوع الوحدوي (unit type). لذلك، لا يتم إرجاع أي شيء، مما يتعارض مع تعريف الدالة ويؤدي إلى حدوث خطأ. في هذه المخرجات، يقدم Rust رسالة للمساعدة في تصحيح هذه المشكلة: يقترح إزالة الفاصلة المنقوطة، مما سيصلح الخطأ.
التعليقات (Comments)
التعليقات (Comments)
يسعى جميع المبرمجين لجعل code الخاص بهم سهل الفهم، ولكن في بعض الأحيان يكون هناك ما يبرر وجود شرح إضافي. في هذه الحالات، يترك المبرمجون تعليقات (comments) في شفرة المصدر (source code) الخاصة بهم والتي سيتجاهلها المُصرِّف (compiler) ولكن قد يجدها الأشخاص الذين يقرؤون source code مفيدة.
إليك comment بسيط:
#![allow(unused)]
fn main() {
// hello, world
}في Rust، يبدأ أسلوب comment الاصطلاحي بشرطتين مائلتين، ويستمر comment حتى نهاية السطر. بالنسبة لـ comments التي تمتد إلى ما بعد سطر واحد، ستحتاج إلى تضمين // في كل سطر، مثل هذا:
#![allow(unused)]
fn main() {
// So we're doing something complicated here, long enough that we need
// multiple lines of comments to do it! Whew! Hopefully, this comment will
// explain what's going on.
}يمكن أيضًا وضع comments في نهاية الأسطر التي تحتوي على code:
Filename: src/main.rs
fn main() {
let lucky_number = 7; // I'm feeling lucky today
}ولكن غالبًا ما ستراها مستخدمة بهذا التنسيق، مع comment على سطر منفصل فوق code الذي تشرحه:
Filename: src/main.rs
fn main() {
// I'm feeling lucky today
let lucky_number = 7;
}لدى Rust أيضًا نوع آخر من comments، وهو تعليقات التوثيق (documentation comments)، والتي سنناقشها في قسم “نشر حزمة (Crate) إلى Crates.io” من الفصل 14.
تدفق التحكم (Control Flow)
تدفق التحكم (Control Flow)
تعد القدرة على تشغيل بعض الأكواد بناءً على ما إذا كان الشرط true والقدرة على تشغيل بعض الأكواد بشكل متكرر بينما يكون الشرط true من اللبنات الأساسية في معظم لغات البرمجة. أكثر البنيات شيوعاً التي تتيح لك التحكم في تدفق تنفيذ كود Rust هي تعبيرات if والحلقات (loops).
تعبيرات if (if Expressions)
يسمح لك تعبير if بتفريع الكود الخاص بك بناءً على الشروط. أنت تقدم شرطاً ثم تنص على: “إذا تم استيفاء هذا الشرط، فقم بتشغيل كتلة الكود هذه. وإذا لم يتم استيفاء الشرط، فلا تقم بتشغيل كتلة الكود هذه”.
أنشئ مشروعاً جديداً يسمى branches في دليل projects الخاص بك لاستكشاف تعبير if. في ملف src/main.rs ، أدخل ما يلي:
اسم الملف: src/main.rs
fn main() {
let number = 3;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}تبدأ جميع تعبيرات if بالكلمة المفتاحية if ، متبوعة بشرط. في هذه الحالة، يتحقق الشرط مما إذا كان المتغير number يحتوي على قيمة أقل من 5 أم لا. نضع كتلة الكود المراد تنفيذها إذا كان الشرط true مباشرة بعد الشرط داخل أقواس متعرجة. تسمى كتل الكود المرتبطة بالشروط في تعبيرات if أحياناً بالأذرع (arms)، تماماً مثل arms في تعبيرات match التي ناقشناها في قسم “مقارنة التخمين بالرقم السري” من الفصل الثاني.
اختيارياً، يمكننا أيضاً تضمين تعبير else ، وهو ما اخترنا القيام به هنا، لمنح البرنامج كتلة كود بديلة لتنفيذها في حالة تقييم الشرط إلى false. إذا لم تقدم تعبير else وكان الشرط false ، فسيقوم البرنامج ببساطة بتخطي كتلة if والانتقال إلى الجزء التالي من الكود.
حاول تشغيل هذا الكود؛ يجب أن ترى المخرجات التالية:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was true
دعونا نحاول تغيير قيمة number إلى قيمة تجعل الشرط false لنرى ما سيحدث:
fn main() {
let number = 7;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}قم بتشغيل البرنامج مرة أخرى، وانظر إلى المخرجات:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was false
من الجدير بالذكر أيضاً أن الشرط في هذا الكود يجب أن يكون من النوع المنطقي (bool). إذا لم يكن الشرط bool ، فسنحصل على خطأ. على سبيل المثال، حاول تشغيل الكود التالي:
اسم الملف: src/main.rs
fn main() {
let number = 3;
if number {
println!("number was three");
}
}يتم تقييم شرط if إلى قيمة 3 هذه المرة، ويقوم Rust بإصدار خطأ:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if number {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
يشير الخطأ إلى أن Rust توقع bool ولكنه حصل على عدد صحيح (integer). على عكس لغات مثل Ruby و JavaScript، لن يحاول Rust تلقائياً تحويل الأنواع غير المنطقية إلى Boolean. يجب أن تكون صريحاً وتزود if دائماً بقيمة Boolean كشرط لها. إذا أردنا تشغيل كتلة كود if فقط عندما لا يساوي الرقم 0 ، على سبيل المثال، يمكننا تغيير تعبير if إلى ما يلي:
اسم الملف: src/main.rs
fn main() {
let number = 3;
if number != 0 {
println!("number was something other than zero");
}
}سيؤدي تشغيل هذا الكود إلى طباعة number was something other than zero.
التعامل مع شروط متعددة باستخدام else if
يمكنك استخدام شروط متعددة من خلال الجمع بين if و else في تعبير else if. على سبيل المثال:
اسم الملف: src/main.rs
fn main() {
let number = 6;
if number % 4 == 0 {
println!("number is divisible by 4");
} else if number % 3 == 0 {
println!("number is divisible by 3");
} else if number % 2 == 0 {
println!("number is divisible by 2");
} else {
println!("number is not divisible by 4, 3, or 2");
}
}يحتوي هذا البرنامج على أربعة مسارات محتملة يمكنه اتخاذها. بعد تشغيله، يجب أن ترى المخرجات التالية:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
number is divisible by 3
عندما يتم تنفيذ هذا البرنامج، فإنه يتحقق من كل تعبير if بالترتيب وينفذ أول جسم يتم تقييم شرطه إلى true. لاحظ أنه على الرغم من أن 6 يقبل القسمة على 2، إلا أننا لا نرى المخرجات number is divisible by 2 ، ولا نرى نص number is not divisible by 4, 3, or 2 من كتلة else. وذلك لأن Rust ينفذ فقط الكتلة الخاصة بأول شرط true ، وبمجرد العثور على واحد، فإنه لا يتحقق حتى من الباقي.
يمكن أن يؤدي استخدام الكثير من تعبيرات else if إلى جعل الكود الخاص بك مزدحماً، لذا إذا كان لديك أكثر من واحد، فقد ترغب في إعادة هيكلة (refactor) الكود الخاص بك. يصف الفصل السادس بنية تفريع قوية في Rust تسمى match لهذه الحالات.
استخدام if في عبارة let
نظراً لأن if هو تعبير (expression)، يمكننا استخدامه على الجانب الأيمن من عبارة let لتعيين النتيجة لمتغير، كما في القائمة 3-2.
fn main() {
let condition = true;
let number = if condition { 5 } else { 6 };
println!("The value of number is: {number}");
}سيتم ربط المتغير number بقيمة بناءً على نتيجة تعبير if. قم بتشغيل هذا الكود لترى ما سيحدث:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
The value of number is: 5
تذكر أن كتل الكود يتم تقييمها إلى آخر تعبير فيها، والأرقام بحد ذاتها هي أيضاً تعبيرات. في هذه الحالة، تعتمد قيمة تعبير if بالكامل على كتلة الكود التي يتم تنفيذها. هذا يعني أن القيم التي لديها القدرة على أن تكون نتائج من كل ذراع من أذرع if يجب أن تكون من نفس النوع؛ في القائمة 3-2، كانت نتائج كل من ذراع if وذراع else أعداداً صحيحة من نوع i32. إذا كانت الأنواع غير متطابقة، كما في المثال التالي، فسنحصل على خطأ:
اسم الملف: src/main.rs
fn main() {
let condition = true;
let number = if condition { 5 } else { "six" };
println!("The value of number is: {number}");
}عندما نحاول تصريف (compile) هذا الكود، سنحصل على خطأ. أذرع if و else لها أنواع قيم غير متوافقة، ويشير Rust بالضبط إلى مكان العثور على المشكلة في البرنامج:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let number = if condition { 5 } else { "six" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
يتم تقييم التعبير في كتلة if إلى عدد صحيح، ويتم تقييم التعبير في كتلة else إلى سلسلة نصية (string). لن يعمل هذا، لأن المتغيرات يجب أن يكون لها نوع واحد، ويحتاج Rust إلى معرفة نوع المتغير number بشكل قاطع في وقت التصريف (compile time). تتيح معرفة نوع number للمصرف (compiler) التحقق من أن النوع صالح في كل مكان نستخدم فيه number. لن يتمكن Rust من القيام بذلك إذا تم تحديد نوع number فقط في وقت التشغيل (runtime)؛ سيكون المصرف أكثر تعقيداً وسيقدم ضمانات أقل حول الكود إذا كان عليه تتبع أنواع افتراضية متعددة لأي متغير.
التكرار باستخدام الحلقات (Repetition with Loops)
غالباً ما يكون من المفيد تنفيذ كتلة من الكود أكثر من مرة. لهذه المهمة، يوفر Rust عدة حلقات (loops)، والتي ستعمل من خلال الكود الموجود داخل جسم الحلقة حتى النهاية ثم تبدأ فوراً من البداية. لتجربة الحلقات، دعونا ننشئ مشروعاً جديداً يسمى loops.
يحتوي Rust على ثلاثة أنواع من الحلقات: loop و while و for. دعونا نجرب كل واحدة منها.
تكرار الكود باستخدام loop
تخبر الكلمة المفتاحية loop لغة Rust بتنفيذ كتلة من الكود مراراً وتكراراً إما إلى الأبد أو حتى تخبرها صراحة بالتوقف.
كمثال، قم بتغيير ملف src/main.rs في دليل loops الخاص بك ليبدو كالتالي:
اسم الملف: src/main.rs
fn main() {
loop {
println!("again!");
}
}عندما نشغل هذا البرنامج، سنرى كلمة again! تُطبع مراراً وتكراراً بشكل مستمر حتى نوقف البرنامج يدوياً. تدعم معظم واجهات الأوامر (terminals) اختصار لوحة المفاتيح ctrl-C لمقاطعة برنامج عالق في حلقة مستمرة. جرب ذلك:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/loops`
again!
again!
again!
again!
^Cagain!
يمثل الرمز ^C المكان الذي ضغطت فيه على ctrl-C.
قد ترى أو لا ترى كلمة again! مطبوعة بعد ^C ، اعتماداً على مكان الكود في الحلقة عندما تلقى إشارة المقاطعة.
لحسن الحظ، يوفر Rust أيضاً طريقة للخروج من الحلقة باستخدام الكود. يمكنك وضع الكلمة المفتاحية break داخل الحلقة لإخبار البرنامج متى يتوقف عن تنفيذ الحلقة. تذكر أننا فعلنا ذلك في لعبة التخمين في قسم “الخروج بعد التخمين الصحيح” من الفصل الثاني للخروج من البرنامج عندما فاز المستخدم باللعبة من خلال تخمين الرقم الصحيح.
استخدمنا أيضاً continue في لعبة التخمين، والتي تخبر البرنامج في الحلقة بتخطي أي كود متبقٍ في هذه الدورة (iteration) من الحلقة والانتقال إلى الدورة التالية.
إرجاع القيم من الحلقات
أحد استخدامات loop هو إعادة محاولة عملية تعرف أنها قد تفشل، مثل التحقق مما إذا كان الخيط (thread) قد أكمل مهمته. قد تحتاج أيضاً إلى تمرير نتيجة تلك العملية خارج الحلقة إلى بقية الكود الخاص بك. للقيام بذلك، يمكنك إضافة القيمة التي تريد إرجاعها بعد تعبير break الذي تستخدمه لإيقاف الحلقة؛ سيتم إرجاع تلك القيمة خارج الحلقة حتى تتمكن من استخدامها، كما هو موضح هنا:
fn main() {
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2;
}
};
println!("The result is {result}");
}قبل الحلقة، نعلن عن متغير باسم counter ونقوم بتهيئته بالقيمة 0. ثم نعلن عن متغير باسم result للاحتفاظ بالقيمة المرجعة من الحلقة. في كل دورة من دورات الحلقة، نضيف 1 إلى المتغير counter ، ثم نتحقق مما إذا كان counter يساوي 10. عندما يكون كذلك، نستخدم الكلمة المفتاحية break مع القيمة counter * 2. بعد الحلقة، نستخدم فاصلة منقوطة لإنهاء العبارة التي تعين القيمة لـ result. أخيراً، نطبع القيمة في result ، وهي في هذه الحالة 20.
يمكنك أيضاً استخدام return من داخل الحلقة. بينما يخرج break فقط من الحلقة الحالية، فإن return يخرج دائماً من الدالة الحالية.
إزالة الغموض باستخدام تسميات الحلقات (Loop Labels)
إذا كان لديك حلقات داخل حلقات، فإن break و continue ينطبقان على الحلقة الداخلية في تلك النقطة. يمكنك اختيارياً تحديد تسمية للحلقة (loop label) على حلقة يمكنك استخدامها بعد ذلك مع break أو continue لتحديد أن تلك الكلمات المفتاحية تنطبق على الحلقة المسماة بدلاً من الحلقة الداخلية. يجب أن تبدأ تسميات الحلقات بفاصلة علوية واحدة. إليك مثال مع حلقتين متداخلتين:
fn main() {
let mut count = 0;
'counting_up: loop {
println!("count = {count}");
let mut remaining = 10;
loop {
println!("remaining = {remaining}");
if remaining == 9 {
break;
}
if count == 2 {
break 'counting_up;
}
remaining -= 1;
}
count += 1;
}
println!("End count = {count}");
}تقوم الحلقة الداخلية بدون تسمية بالعد التنازلي من 10 إلى 9. أول break لا يحدد تسمية سيخرج من الحلقة الداخلية فقط. أما عبارة break 'counting_up; فستخرج من الحلقة الخارجية. يطبع هذا الكود:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
count = 0
remaining = 10
remaining = 9
count = 1
remaining = 10
remaining = 9
count = 2
remaining = 10
End count = 2
تبسيط الحلقات الشرطية باستخدام while
غالباً ما يحتاج البرنامج إلى تقييم شرط داخل حلقة. طالما أن الشرط true ، تعمل الحلقة. عندما يتوقف الشرط عن كونه true ، يستدعي البرنامج break ، مما يوقف الحلقة. من الممكن تنفيذ سلوك مثل هذا باستخدام مزيج من loop و if و else و break ؛ يمكنك تجربة ذلك الآن في برنامج، إذا أردت. ومع ذلك، فإن هذا النمط شائع جداً لدرجة أن Rust لديها بنية لغة مدمجة له، تسمى حلقة while. في القائمة 3-3، نستخدم while لتدوير البرنامج ثلاث مرات، والعد التنازلي في كل مرة، ثم بعد الحلقة، لطباعة رسالة والخروج.
fn main() {
let mut number = 3;
while number != 0 {
println!("{number}!");
number -= 1;
}
println!("LIFTOFF!!!");
}تزيل هذه البنية الكثير من التداخل (nesting) الذي سيكون ضرورياً إذا استخدمت loop و if و else و break ، وهي أكثر وضوحاً. طالما يتم تقييم الشرط إلى true ، يتم تشغيل الكود؛ وإلا، فإنه يخرج من الحلقة.
التكرار عبر مجموعة باستخدام for
يمكنك اختيار استخدام بنية while للتكرار عبر عناصر مجموعة (collection)، مثل المصفوفة (array). على سبيل المثال، تقوم الحلقة في القائمة 3-4 بطباعة كل عنصر في المصفوفة a.
fn main() {
let a = [10, 20, 30, 40, 50];
let mut index = 0;
while index < 5 {
println!("the value is: {}", a[index]);
index += 1;
}
}هنا، يقوم الكود بالعد التصاعدي عبر العناصر في المصفوفة. يبدأ من الفهرس (index) 0 ثم يدور حتى يصل إلى الفهرس النهائي في المصفوفة (أي عندما لا يعود index < 5 صحيحاً). سيؤدي تشغيل هذا الكود إلى طباعة كل عنصر في المصفوفة:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/loops`
the value is: 10
the value is: 20
the value is: 30
the value is: 40
the value is: 50
تظهر جميع قيم المصفوفة الخمس في واجهة الأوامر، كما هو متوقع. على الرغم من أن index سيصل إلى قيمة 5 في مرحلة ما، إلا أن الحلقة تتوقف عن التنفيذ قبل محاولة جلب قيمة سادسة من المصفوفة.
ومع ذلك، فإن هذا النهج عرضة للأخطاء؛ فقد نتسبب في توقف البرنامج بشكل مفاجئ (panic) إذا كانت قيمة الفهرس أو شرط الاختبار غير صحيحين. على سبيل المثال، إذا قمت بتغيير تعريف المصفوفة a لتتكون من أربعة عناصر ولكنك نسيت تحديث الشرط إلى while index < 4 ، فسيحدث panic للكود. كما أنه بطيء، لأن المصرف يضيف كوداً في وقت التشغيل لإجراء الفحص الشرطي لما إذا كان الفهرس ضمن حدود المصفوفة في كل دورة عبر الحلقة.
كبديل أكثر إيجازاً، يمكنك استخدام حلقة for وتنفيذ بعض الأكواد لكل عنصر في المجموعة. تبدو حلقة for مثل الكود الموجود في القائمة 3-5.
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("the value is: {element}");
}
}عندما نشغل هذا الكود، سنرى نفس المخرجات كما في القائمة 3-4. والأهم من ذلك، أننا زدنا الآن من سلامة الكود وقضينا على فرصة حدوث أخطاء برمجية قد تنتج عن تجاوز نهاية المصفوفة أو عدم الذهاب بعيداً بما يكفي وفقدان بعض العناصر. يمكن أن يكون كود الآلة (machine code) الناتج عن حلقات for أكثر كفاءة أيضاً لأن الفهرس لا يحتاج إلى مقارنته بطول المصفوفة في كل دورة.
باستخدام حلقة for ، لن تحتاج إلى تذكر تغيير أي كود آخر إذا قمت بتغيير عدد القيم في المصفوفة، كما تفعل مع الطريقة المستخدمة في القائمة 3-4.
إن سلامة وإيجاز حلقات for تجعلها بنية الحلقات الأكثر استخداماً في Rust. حتى في المواقف التي تريد فيها تشغيل بعض الأكواد عدداً معيناً من المرات، كما في مثال العد التنازلي الذي استخدم حلقة while في القائمة 3-3، فإن معظم مبرمجي رست (Rustaceans) سيستخدمون حلقة for. الطريقة للقيام بذلك هي استخدام النطاق (Range)، الذي توفره المكتبة القياسية، والذي يولد جميع الأرقام بالتسلسل بدءاً من رقم واحد وانتهاءً قبل رقم آخر.
إليك كيف سيبدو العد التنازلي باستخدام حلقة for وطريقة أخرى لم نتحدث عنها بعد، وهي rev ، لعكس النطاق:
اسم الملف: src/main.rs
fn main() {
for number in (1..4).rev() {
println!("{number}!");
}
println!("LIFTOFF!!!");
}هذا الكود أجمل قليلاً، أليس كذلك؟
ملخص (Summary)
لقد فعلتها! كان هذا فصلاً كبيراً: لقد تعلمت عن المتغيرات، وأنواع البيانات البسيطة والمركبة، والدوال، والتعليقات، وتعبيرات if ، والحلقات! للتدرب على المفاهيم التي تمت مناقشتها في هذا الفصل، حاول بناء برامج للقيام بما يلي:
- تحويل درجات الحرارة بين فهرنهايت وسيلسيوس.
- توليد رقم فيبوناتشي ذو الترتيب n.
- طباعة كلمات أغنية عيد الميلاد “The Twelve Days of Christmas” ، مع الاستفادة من التكرار في الأغنية.
عندما تكون مستعداً للمضي قدماً، سنتحدث عن مفهوم في Rust لا يوجد عادةً في لغات البرمجة الأخرى: الملكية (ownership).
فهم Ownership
تُعدّ Ownership (الملكية) الميزة الأبرز في لغة Rust، ولها آثار عميقة على بقية مكونات اللغة.
فهي تُمكّن Rust من ضمان سلامة الذاكرة دون الحاجة إلى جامع قمامة، لذا من المهم فهم كيفية عمل Ownership .
في هذا الفصل، سنتناول Ownership بالإضافة إلى العديد من الميزات ذات الصلة:
borrowing (الاستعارة) ، slices (الشرائح) ، وكيفية تنظيم Rust للبيانات في الذاكرة.
ما هي الملكية؟ (What is Ownership?)
ما هي الملكية (Ownership)؟
الملكية (Ownership) هي مجموعة من القواعد التي تحكم كيفية إدارة برنامج Rust للذاكرة. يجب على جميع البرامج إدارة الطريقة التي تستخدم بها ذاكرة الكمبيوتر أثناء التشغيل. تحتوي بعض اللغات على تجميع البيانات المهملة (Garbage Collection - GC) الذي يبحث بانتظام عن الذاكرة التي لم تعد مستخدمة أثناء تشغيل البرنامج؛ وفي لغات أخرى، يجب على المبرمج تخصيص الذاكرة وتحريرها (allocate and free) بشكل صريح. تستخدم Rust نهجًا ثالثًا: تتم إدارة الذاكرة من خلال نظام Ownership مع مجموعة من القواعد التي يتحقق منها المترجم (compiler). إذا تم انتهاك أي من القواعد، فلن يتم تجميع البرنامج. لا توجد أي من ميزات Ownership تبطئ برنامجك أثناء تشغيله.
نظرًا لأن Ownership مفهوم جديد للعديد من المبرمجين، فإنه يستغرق بعض الوقت للاعتياد عليه. الخبر السار هو أنه كلما أصبحت أكثر خبرة في Rust وقواعد نظام Ownership، كلما وجدت أنه من الأسهل تطوير كود آمن وفعال بشكل طبيعي. استمر في المحاولة!
عندما تفهم Ownership، سيكون لديك أساس متين لفهم الميزات التي تجعل Rust فريدة من نوعها. في هذا الفصل، ستتعلم Ownership من خلال العمل على بعض الأمثلة التي تركز على بنية بيانات شائعة جدًا: السلاسل النصية (strings).
المكدس (Stack) والكومة (Heap)
لا تتطلب منك العديد من لغات البرمجة التفكير في الـ Stack والـ Heap في كثير من الأحيان. ولكن في لغة برمجة أنظمة مثل Rust، يؤثر ما إذا كانت القيمة موجودة على الـ Stack أو الـ Heap على كيفية تصرف اللغة ولماذا يجب عليك اتخاذ قرارات معينة. سيتم وصف أجزاء من Ownership فيما يتعلق بالـ Stack والـ Heap لاحقًا في هذا الفصل، لذا إليك شرح موجز كتحضير.
كل من الـ Stack والـ Heap هما جزءان من الذاكرة المتاحة للكود الخاص بك لاستخدامها في وقت التشغيل (runtime)، ولكنهما منظمان بطرق مختلفة. يخزن الـ Stack القيم بالترتيب الذي يحصل عليها به ويزيل القيم بالترتيب المعاكس. يشار إلى هذا باسم آخر ما يدخل، أول ما يخرج (Last In, First Out - LIFO). فكر في كومة من الأطباق: عندما تضيف المزيد من الأطباق، تضعها فوق الكومة، وعندما تحتاج إلى طبق، تأخذ واحدًا من الأعلى. لن ينجح إضافة أو إزالة الأطباق من المنتصف أو الأسفل! تسمى إضافة البيانات الدفع إلى الـ Stack (pushing onto the Stack)، وتسمى إزالة البيانات السحب من الـ Stack (popping off the Stack). يجب أن يكون لجميع البيانات المخزنة على الـ Stack حجم معروف وثابت. يجب تخزين البيانات ذات الحجم غير المعروف في وقت التجميع (compile time) أو الحجم الذي قد يتغير على الـ Heap بدلاً من ذلك.
الـ Heap أقل تنظيمًا: عندما تضع بيانات على الـ Heap، فإنك تطلب قدرًا معينًا من المساحة. يجد مخصص الذاكرة (memory allocator) بقعة فارغة في الـ Heap تكون كبيرة بما يكفي، ويضع علامة عليها بأنها قيد الاستخدام، ويعيد مؤشر (pointer)، وهو عنوان ذلك الموقع. تسمى هذه العملية التخصيص على الـ Heap (allocating on the Heap) ويتم اختصارها أحيانًا على أنها مجرد تخصيص (allocating) (لا يعتبر دفع القيم إلى الـ Stack تخصيصًا). نظرًا لأن الـ pointer إلى الـ Heap له حجم معروف وثابت، يمكنك تخزين الـ pointer على الـ Stack، ولكن عندما تريد البيانات الفعلية، يجب عليك اتباع الـ pointer. فكر في الجلوس في مطعم. عندما تدخل، تذكر عدد الأشخاص في مجموعتك، ويجد المضيف طاولة فارغة تناسب الجميع ويقودك إليها. إذا تأخر شخص ما في مجموعتك، يمكنه أن يسأل عن مكان جلوسك للعثور عليك.
الدفع إلى الـ Stack أسرع من الـ allocating على الـ Heap لأن الـ allocator لا يضطر أبدًا إلى البحث عن مكان لتخزين البيانات الجديدة؛ هذا الموقع دائمًا في الجزء العلوي من الـ Stack. بالمقارنة، يتطلب تخصيص مساحة على الـ Heap مزيدًا من العمل لأن الـ allocator يجب أن يجد أولاً مساحة كبيرة بما يكفي لاحتواء البيانات ثم يقوم بحفظ السجلات للتحضير للتخصيص التالي.
يعد الوصول إلى البيانات في الـ Heap أبطأ بشكل عام من الوصول إلى البيانات على الـ Stack لأنه يجب عليك اتباع pointer للوصول إليها. تكون المعالجات (processors) المعاصرة أسرع إذا قفزت حول الذاكرة بشكل أقل. استمرارًا للتشبيه، فكر في خادم في مطعم يأخذ طلبات من العديد من الطاولات. الأكثر كفاءة هو الحصول على جميع الطلبات على طاولة واحدة قبل الانتقال إلى الطاولة التالية. إن أخذ طلب من الطاولة A، ثم طلب من الطاولة B، ثم واحد من A مرة أخرى، ثم واحد من B مرة أخرى سيكون عملية أبطأ بكثير. بنفس الطريقة، يمكن للمعالج عادةً القيام بعمله بشكل أفضل إذا كان يعمل على بيانات قريبة من البيانات الأخرى (كما هو الحال في الـ Stack) بدلاً من أن تكون بعيدة (كما يمكن أن تكون في الـ Heap).
عندما يستدعي الكود الخاص بك دالة، يتم دفع القيم التي تم تمريرها إلى الدالة (بما في ذلك، من المحتمل، pointers إلى البيانات على الـ Heap) والمتغيرات المحلية للدالة إلى الـ Stack. عندما تنتهي الدالة، يتم سحب تلك القيم من الـ Stack.
تتبع الأجزاء التي تستخدم أي بيانات على الـ Heap، وتقليل كمية البيانات المكررة على الـ Heap، وتنظيف البيانات غير المستخدمة على الـ Heap حتى لا تنفد المساحة، كلها مشاكل يعالجها Ownership. بمجرد أن تفهم Ownership، لن تحتاج إلى التفكير في الـ Stack والـ Heap في كثير من الأحيان. ولكن معرفة أن الغرض الرئيسي من Ownership هو إدارة بيانات الـ Heap يمكن أن يساعد في تفسير سبب عمله بالطريقة التي يعمل بها.
قواعد الملكية (Ownership Rules)
أولاً، دعونا نلقي نظرة على قواعد Ownership. ضع هذه القواعد في الاعتبار بينما نعمل على الأمثلة التي توضحها:
- كل قيمة في Rust لها مالك (owner).
- يمكن أن يكون هناك owner واحد فقط في كل مرة.
- عندما يخرج الـ owner من النطاق (scope)، سيتم إسقاط (dropped) القيمة.
نطاق المتغير (Variable Scope)
الآن بعد أن تجاوزنا بناء جملة Rust الأساسي، لن ندرج كل كود fn main() { في الأمثلة، لذا إذا كنت تتابع، فتأكد من وضع الأمثلة التالية داخل دالة main يدويًا. ونتيجة لذلك، ستكون أمثلتنا أكثر إيجازًا، مما يسمح لنا بالتركيز على التفاصيل الفعلية بدلاً من الكود النمطي (boilerplate code).
كمثال أول على Ownership، سننظر إلى الـ scope لبعض المتغيرات. الـ scope هو النطاق داخل برنامج يكون فيه العنصر صالحًا. خذ المتغير التالي:
#![allow(unused)]
fn main() {
let s = "hello";
}يشير المتغير s إلى حرفي السلسلة النصية (string literal)، حيث يتم ترميز قيمة الـ string مباشرة في نص برنامجنا. يكون المتغير صالحًا من النقطة التي يتم فيها الإعلان عنه حتى نهاية الـ scope الحالي. تُظهر القائمة 4-1 برنامجًا يحتوي على تعليقات توضيحية تشير إلى المكان الذي سيكون فيه المتغير s صالحًا.
fn main() {
{ // s is not valid here, since it's not yet declared
let s = "hello"; // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no longer valid
}بمعنى آخر، هناك نقطتان زمنيتان مهمتان هنا:
- عندما يدخل
sإلى الـ scope، يكون صالحًا. - يظل صالحًا حتى يخرج من الـ scope.
في هذه المرحلة، العلاقة بين الـ scopes ومتى تكون المتغيرات صالحة تشبه تلك الموجودة في لغات البرمجة الأخرى. الآن سنبني على هذا الفهم من خلال تقديم النوع String.
النوع String
لتوضيح قواعد Ownership، نحتاج إلى نوع بيانات أكثر تعقيدًا من تلك التي تناولناها في قسم “أنواع البيانات” من الفصل 3. الأنواع التي تم تناولها سابقًا ذات حجم معروف، ويمكن تخزينها على الـ Stack وسحبها من الـ Stack عند انتهاء الـ scope الخاص بها، ويمكن نسخها بسرعة وبشكل بسيط لإنشاء مثيل (instance) جديد ومستقل إذا احتاج جزء آخر من الكود إلى استخدام نفس القيمة في scope مختلف. لكننا نريد أن ننظر إلى البيانات المخزنة على الـ Heap ونستكشف كيف تعرف Rust متى يجب تنظيف تلك البيانات، ويعد النوع String مثالًا رائعًا.
سنركز على أجزاء String المتعلقة بـ Ownership. تنطبق هذه الجوانب أيضًا على أنواع البيانات المعقدة الأخرى، سواء تم توفيرها بواسطة المكتبة القياسية (standard library) أو تم إنشاؤها بواسطتك. سنناقش جوانب String غير المتعلقة بـ Ownership في الفصل 8.
لقد رأينا بالفعل string literals، حيث يتم ترميز قيمة string مباشرة في برنامجنا. تعد string literals مريحة، لكنها ليست مناسبة لكل موقف قد نرغب في استخدام نص فيه. أحد الأسباب هو أنها غير قابلة للتغيير (immutable). سبب آخر هو أنه لا يمكن معرفة كل قيمة string عندما نكتب الكود الخاص بنا: على سبيل المثال، ماذا لو أردنا أخذ مدخلات المستخدم (user input) وتخزينها؟ لهذه المواقف، لدى Rust النوع String. يدير هذا النوع البيانات المخصصة على الـ Heap وعلى هذا النحو يمكنه تخزين كمية من النص غير معروفة لنا في compile time. يمكنك إنشاء String من string literal باستخدام الدالة from، على النحو التالي:
#![allow(unused)]
fn main() {
let s = String::from("hello");
}يسمح لنا عامل التشغيل النقطتين المزدوجتين :: بتسمية هذه الدالة from المعينة تحت النوع String بدلاً من استخدام نوع من الأسماء مثل string_from. سنناقش بناء الجملة هذا أكثر في قسم “الدوال” من الفصل 5، وعندما نتحدث عن التسمية باستخدام الوحدات (modules) في “المسارات للإشارة إلى عنصر في شجرة الوحدة” في الفصل 7.
هذا النوع من الـ string يمكن أن يكون قابلاً للتغيير (mutable):
fn main() {
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() appends a literal to a String
println!("{s}"); // this will print `hello, world!`
}إذن، ما هو الفرق هنا؟ لماذا يمكن تغيير String ولكن string literals لا يمكن تغييرها؟ يكمن الاختلاف في كيفية تعامل هذين النوعين مع الذاكرة.
الذاكرة والتخصيص (Memory and Allocation)
في حالة string literal، نعرف المحتويات في compile time، لذلك يتم ترميز النص مباشرة في الملف التنفيذي النهائي. هذا هو السبب في أن string literals سريعة وفعالة. لكن هذه الخصائص تأتي فقط من عدم قابلية تغيير string literal. لسوء الحظ، لا يمكننا وضع كتلة من الذاكرة في الملف الثنائي (binary) لكل جزء من النص يكون حجمه غير معروف في compile time وقد يتغير حجمه أثناء تشغيل البرنامج.
باستخدام النوع String، لدعم جزء نصي قابل للتغيير والنمو، نحتاج إلى تخصيص (allocate) قدر من الذاكرة على الـ Heap، غير معروف في compile time، لاحتواء المحتويات. هذا يعني:
- يجب طلب الذاكرة من memory allocator في وقت التشغيل (runtime).
- نحتاج إلى طريقة لإعادة هذه الذاكرة إلى الـ allocator عندما ننتهي من
Stringالخاص بنا.
يتم تنفيذ الجزء الأول بواسطتنا: عندما نستدعي String::from، يطلب تطبيقه الذاكرة التي يحتاجها. هذا عالمي إلى حد كبير في لغات البرمجة.
ومع ذلك، فإن الجزء الثاني مختلف. في اللغات التي تحتوي على GC (Garbage Collector)، يتتبع الـ GC وينظف الذاكرة التي لم تعد مستخدمة، ولا نحتاج إلى التفكير في الأمر. في معظم اللغات التي لا تحتوي على GC، تقع على عاتقنا مسؤولية تحديد متى لم تعد الذاكرة مستخدمة واستدعاء الكود لتحريرها (free) بشكل صريح، تمامًا كما فعلنا لطلبها. لطالما كانت القيام بذلك بشكل صحيح مشكلة برمجة صعبة تاريخيًا. إذا نسينا، فسنهدر الذاكرة. إذا فعلنا ذلك في وقت مبكر جدًا، فسيكون لدينا متغير غير صالح. إذا فعلنا ذلك مرتين، فهذا bug أيضًا. نحتاج إلى إقران allocate واحد بالضبط مع free واحد بالضبط.
تأخذ Rust نهجًا مختلفًا: الـ owner. دعونا نعود إلى مثال string من القائمة 4-1 باستخدام String بدلاً من string literal:
fn main() {
{
let s = String::from("hello"); // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no
// longer valid
}هناك نقطة طبيعية يمكننا عندها إعادة الذاكرة التي يحتاجها String الخاص بنا إلى الـ allocator: عندما يخرج s من الـ scope. عندما يخرج متغير من الـ scope، تستدعي Rust دالة خاصة لنا. تسمى هذه الدالة drop، وهي المكان الذي يمكن لمؤلف String أن يضع فيه الكود لإعادة الذاكرة. تستدعي Rust الدالة drop تلقائيًا عند القوس المتعرج الختامي.
ملاحظة: في C++، يسمى هذا النمط من إلغاء تخصيص الموارد في نهاية عمر العنصر أحيانًا اكتساب الموارد هو تهيئة (Resource Acquisition Is Initialization - RAII). ستكون الدالة
dropفي Rust مألوفة لك إذا كنت قد استخدمت أنماط RAII.
لهذا النمط تأثير عميق على طريقة كتابة كود Rust. قد يبدو بسيطًا الآن، ولكن سلوك الكود يمكن أن يكون غير متوقع في مواقف أكثر تعقيدًا عندما نريد أن تستخدم متغيرات متعددة البيانات التي خصصناها على الـ Heap. دعونا نستكشف بعضًا من هذه المواقف الآن.
تفاعل المتغيرات والبيانات مع النقل (Move)
يمكن أن تتفاعل المتغيرات المتعددة مع نفس البيانات بطرق مختلفة في Rust. تُظهر القائمة 4-2 مثالًا باستخدام عدد صحيح (integer).
fn main() {
let x = 5;
let y = x;
}يمكننا على الأرجح تخمين ما يفعله هذا: “ربط القيمة 5 بـ x؛ ثم، عمل نسخة من القيمة في x وربطها بـ y.” لدينا الآن متغيران، x و y، وكلاهما يساوي 5. هذا هو بالفعل ما يحدث، لأن integers هي قيم بسيطة ذات حجم معروف وثابت، ويتم دفع هاتين القيمتين 5 إلى الـ Stack.
الآن دعونا نلقي نظرة على نسخة String:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
}يبدو هذا مشابهًا جدًا، لذلك قد نفترض أن طريقة عمله ستكون هي نفسها: أي أن السطر الثاني سيقوم بعمل نسخة من القيمة في s1 وربطها بـ s2. لكن هذا ليس ما يحدث تمامًا.
ألق نظرة على الشكل 4-1 لترى ما يحدث لـ String تحت الغطاء. يتكون String من ثلاثة أجزاء، موضحة على اليسار: pointer إلى الذاكرة التي تحتوي على محتويات الـ string، وطول (length)، وسعة (capacity). يتم تخزين هذه المجموعة من البيانات على الـ Stack. على اليمين توجد الذاكرة على الـ Heap التي تحتوي على المحتويات.

الشكل 4-1: تمثيل String في الذاكرة الذي يحمل القيمة "hello" المرتبطة بـ s1
الـ length هو مقدار الذاكرة، بالبايت، التي تستخدمها محتويات String حاليًا. الـ capacity هي إجمالي كمية الذاكرة، بالبايت، التي تلقاها String من الـ allocator. الفرق بين الـ length والـ capacity مهم، ولكن ليس في هذا السياق، لذلك في الوقت الحالي، لا بأس بتجاهل الـ capacity.
عندما نخصص s1 لـ s2، يتم نسخ بيانات String، مما يعني أننا ننسخ الـ pointer والـ length والـ capacity الموجودة على الـ Stack. نحن لا ننسخ البيانات الموجودة على الـ Heap التي يشير إليها الـ pointer. بمعنى آخر، يبدو تمثيل البيانات في الذاكرة كما في الشكل 4-2.

الشكل 4-2: تمثيل المتغير s2 في الذاكرة الذي يحتوي على نسخة من الـ pointer والـ length والـ capacity لـ s1
التمثيل لا يبدو مثل الشكل 4-3، وهو ما ستبدو عليه الذاكرة إذا نسخت Rust بيانات الـ Heap أيضًا. إذا فعلت Rust ذلك، فقد تكون عملية s2 = s1 مكلفة للغاية من حيث أداء وقت التشغيل إذا كانت البيانات الموجودة على الـ Heap كبيرة.

الشكل 4-3: احتمال آخر لما قد تفعله s2 = s1 إذا نسخت Rust بيانات الـ Heap أيضًا
في وقت سابق، قلنا أنه عندما يخرج متغير من الـ scope، تستدعي Rust تلقائيًا الدالة drop وتنظف ذاكرة الـ Heap لذلك المتغير. لكن الشكل 4-2 يظهر أن كلا الـ pointers يشيران إلى نفس الموقع. هذه مشكلة: عندما يخرج s2 و s1 من الـ scope، سيحاول كلاهما تحرير نفس الذاكرة. يُعرف هذا باسم خطأ التحرير المزدوج (double free) وهو أحد أخطاء سلامة الذاكرة (memory safety bugs) التي ذكرناها سابقًا. يمكن أن يؤدي تحرير الذاكرة مرتين إلى تلف الذاكرة (memory corruption)، مما قد يؤدي إلى ثغرات أمنية (security vulnerabilities).
لضمان memory safety، بعد السطر let s2 = s1;، تعتبر Rust أن s1 لم يعد صالحًا. لذلك، لا تحتاج Rust إلى تحرير أي شيء عندما يخرج s1 من الـ scope. تحقق مما يحدث عندما تحاول استخدام s1 بعد إنشاء s2؛ لن ينجح:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{s1}, world!");
}ستحصل على خطأ مثل هذا لأن Rust تمنعك من استخدام المرجع (reference) الذي تم إبطاله:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:16
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{s1}, world!");
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
إذا كنت قد سمعت مصطلحي النسخ السطحي (shallow copy) و النسخ العميق (deep copy) أثناء العمل مع لغات أخرى، فمن المحتمل أن يبدو مفهوم نسخ الـ pointer والـ length والـ capacity دون نسخ البيانات وكأنه عمل shallow copy. ولكن نظرًا لأن Rust تبطل أيضًا المتغير الأول، فبدلاً من تسميته shallow copy، فإنه يُعرف باسم النقل (move). في هذا المثال، نقول إن s1 تم نقله إلى s2. لذا، فإن ما يحدث بالفعل موضح في الشكل 4-4.

الشكل 4-4: تمثيل الذاكرة بعد إبطال s1
هذا يحل مشكلتنا! مع صلاحية s2 فقط، عندما يخرج من الـ scope، سيقوم وحده بتحرير الذاكرة، ونكون قد انتهينا.
بالإضافة إلى ذلك، هناك خيار تصميم ضمني بهذا: لن تقوم Rust أبدًا بإنشاء نسخ “deep” لبياناتك تلقائيًا. لذلك، يمكن افتراض أن أي نسخ تلقائي غير مكلف من حيث أداء وقت التشغيل.
النطاق والتعيين (Scope and Assignment)
العكس صحيح بالنسبة للعلاقة بين الـ scoping و Ownership والذاكرة التي يتم تحريرها عبر الدالة drop أيضًا. عندما تقوم بتعيين قيمة جديدة تمامًا لمتغير موجود، ستستدعي Rust الدالة drop وتحرر ذاكرة القيمة الأصلية على الفور. ضع في اعتبارك هذا الكود، على سبيل المثال:
fn main() {
let mut s = String::from("hello");
s = String::from("ahoy");
println!("{s}, world!");
}نعلن في البداية عن متغير s ونربطه بـ String بالقيمة "hello". ثم، نقوم على الفور بإنشاء String جديد بالقيمة "ahoy" ونعينه لـ s. في هذه المرحلة، لا يوجد شيء يشير إلى القيمة الأصلية على الـ Heap على الإطلاق. يوضح الشكل 4-5 بيانات الـ Stack والـ Heap الآن:

الشكل 4-5: تمثيل الذاكرة بعد استبدال القيمة الأولية بالكامل
وبالتالي، تخرج الـ string الأصلية من الـ scope على الفور. ستقوم Rust بتشغيل الدالة drop عليها وسيتم تحرير ذاكرتها على الفور. عندما نطبع القيمة في النهاية، ستكون "ahoy, world!".
تفاعل المتغيرات والبيانات مع الاستنساخ (Clone)
إذا أردنا عمل deep copy لبيانات الـ Heap لـ String، وليس فقط بيانات الـ Stack، فيمكننا استخدام دالة شائعة تسمى clone. سنناقش بناء جملة الـ methods في الفصل 5، ولكن نظرًا لأن الـ methods هي ميزة شائعة في العديد من لغات البرمجة، فمن المحتمل أنك رأيتها من قبل.
إليك مثال على دالة clone قيد التنفيذ:
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {s1}, s2 = {s2}");
}يعمل هذا بشكل جيد وينتج صراحة السلوك الموضح في الشكل 4-3، حيث يتم نسخ بيانات الـ Heap.
عندما ترى استدعاء لـ clone، فأنت تعلم أنه يتم تنفيذ بعض الكود التعسفي وأن هذا الكود قد يكون مكلفًا. إنه مؤشر مرئي على أن شيئًا مختلفًا يحدث.
بيانات الـ Stack فقط: النسخ (Copy)
هناك تجعيدة أخرى لم نتحدث عنها بعد. هذا الكود الذي يستخدم integers - والذي تم عرض جزء منه في القائمة 4-2 - يعمل وصالح:
fn main() {
let x = 5;
let y = x;
println!("x = {x}, y = {y}");
}لكن هذا الكود يبدو وكأنه يتناقض مع ما تعلمناه للتو: ليس لدينا استدعاء لـ clone، لكن x لا يزال صالحًا ولم يتم نقله إلى y.
السبب هو أن الأنواع مثل integers التي لها حجم معروف في compile time يتم تخزينها بالكامل على الـ Stack، لذا فإن نسخ القيم الفعلية سريعة التنفيذ. هذا يعني أنه لا يوجد سبب يدعونا إلى منع x من أن يكون صالحًا بعد إنشاء المتغير y. بمعنى آخر، لا يوجد فرق بين deep copy و shallow copy هنا، لذا فإن استدعاء clone لن يفعل أي شيء مختلف عن الـ shallow copy المعتاد، ويمكننا حذفه.
لدى Rust تعليق توضيحي خاص يسمى سمة النسخ (Copy trait) يمكننا وضعه على الأنواع المخزنة على الـ Stack، كما هو الحال مع integers (سنتحدث أكثر عن الـ traits في الفصل 10). إذا طبق نوع ما الـ Copy trait، فإن المتغيرات التي تستخدمه لا يتم نقلها (move)، بل يتم نسخها بشكل بسيط، مما يجعلها لا تزال صالحة بعد التعيين لمتغير آخر.
لن تسمح لنا Rust بتعليق نوع بـ Copy إذا كان النوع، أو أي من أجزائه، قد طبق الـ Drop trait. إذا كان النوع يحتاج إلى حدوث شيء خاص عندما تخرج القيمة من الـ scope وأضفنا التعليق التوضيحي Copy إلى هذا النوع، فسنحصل على خطأ في compile time. لمعرفة كيفية إضافة التعليق التوضيحي Copy إلى نوعك لتطبيق الـ trait، راجع “السمات القابلة للاشتقاق” في الملحق ج.
إذن، ما هي الأنواع التي تطبق الـ Copy trait؟ يمكنك التحقق من توثيق النوع المحدد للتأكد، ولكن كقاعدة عامة، يمكن لأي مجموعة من القيم العددية (scalar values) البسيطة تطبيق Copy، ولا يمكن لأي شيء يتطلب تخصيصًا (allocation) أو هو شكل من أشكال المورد (resource) تطبيق Copy. فيما يلي بعض الأنواع التي تطبق Copy:
- جميع أنواع integers، مثل
u32. - النوع المنطقي (Boolean)،
bool، بالقيمتينtrueوfalse. - جميع أنواع الفاصلة العائمة (floating-point)، مثل
f64. - نوع الحرف (character)،
char. - الصفوف (Tuples)، إذا كانت تحتوي فقط على أنواع تطبق
Copyأيضًا. على سبيل المثال، يطبق(i32, i32)الـCopy، لكن(i32, String)لا يطبقه.
الملكية والدوال (Ownership and Functions)
آلية تمرير قيمة إلى دالة تشبه تلك الخاصة بتعيين قيمة لمتغير. سيؤدي تمرير متغير إلى دالة إلى move أو copy، تمامًا كما يفعل التعيين. تحتوي القائمة 4-3 على مثال مع بعض التعليقات التوضيحية التي توضح أين تدخل المتغيرات وتخرج من الـ scope.
fn main() {
let s = String::from("hello"); // s comes into scope
takes_ownership(s); // s's value moves into the function...
// ... and so is no longer valid here
let x = 5; // x comes into scope
makes_copy(x); // Because i32 implements the Copy trait,
// x does NOT move into the function,
// so it's okay to use x afterward.
} // Here, x goes out of scope, then s. However, because s's value was moved,
// nothing special happens.
fn takes_ownership(some_string: String) { // some_string comes into scope
println!("{some_string}");
} // Here, some_string goes out of scope and `drop` is called. The backing
// memory is freed.
fn makes_copy(some_integer: i32) { // some_integer comes into scope
println!("{some_integer}");
} // Here, some_integer goes out of scope. Nothing special happens.إذا حاولنا استخدام s بعد الاستدعاء لـ takes_ownership، فستقوم Rust بإلقاء خطأ في compile time. تحمينا هذه الفحوصات الثابتة (static checks) من الأخطاء. حاول إضافة كود إلى main يستخدم s و x لترى أين يمكنك استخدامهما وأين تمنعك قواعد Ownership من القيام بذلك.
قيم الإرجاع والنطاق (Return Values and Scope)
يمكن أن تؤدي قيم الإرجاع أيضًا إلى نقل Ownership. تُظهر القائمة 4-4 مثالًا لدالة تُرجع بعض القيم، مع تعليقات توضيحية مماثلة لتلك الموجودة في القائمة 4-3.
fn main() {
let s1 = gives_ownership(); // gives_ownership moves its return
// value into s1
let s2 = String::from("hello"); // s2 comes into scope
let s3 = takes_and_gives_back(s2); // s2 is moved into
// takes_and_gives_back, which also
// moves its return value into s3
} // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing
// happens. s1 goes out of scope and is dropped.
fn gives_ownership() -> String { // gives_ownership will move its
// return value into the function
// that calls it
let some_string = String::from("yours"); // some_string comes into scope
some_string // some_string is returned and
// moves out to the calling
// function
}
// This function takes a String and returns a String.
fn takes_and_gives_back(a_string: String) -> String {
// a_string comes into
// scope
a_string // a_string is returned and moves out to the calling function
}يتبع Ownership لمتغير نفس النمط في كل مرة: تعيين قيمة لمتغير آخر ينقلها (moves it). عندما يخرج متغير يتضمن بيانات على الـ Heap من الـ scope، سيتم تنظيف القيمة بواسطة drop ما لم يتم نقل Ownership للبيانات إلى متغير آخر.
بينما يعمل هذا، فإن أخذ Ownership ثم إرجاع Ownership مع كل دالة أمر ممل بعض الشيء. ماذا لو أردنا السماح لدالة باستخدام قيمة ولكن لا تأخذ Ownership؟ إنه أمر مزعج للغاية أن أي شيء نمرره يحتاج أيضًا إلى إعادته إذا أردنا استخدامه مرة أخرى، بالإضافة إلى أي بيانات ناتجة عن نص الدالة قد نرغب في إرجاعها أيضًا.
تسمح لنا Rust بإرجاع قيم متعددة باستخدام tuple، كما هو موضح في القائمة 4-5.
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{s2}' is {len}.");
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() returns the length of a String
(s, length)
}لكن هذا كثير جدًا من الإجراءات والكثير من العمل لمفهوم يجب أن يكون شائعًا. لحسن حظنا، لدى Rust ميزة لاستخدام قيمة دون نقل Ownership: الـ references.
المراجع والاستعارة (References and Borrowing)
المراجع والاستعارة (References and Borrowing)
المشكلة في كود الصفوف (tuple) في القائمة 4-5 هي أننا نضطر إلى إعادة String إلى الدالة المستدعية حتى نتمكن من الاستمرار في استخدام String بعد استدعاء calculate_length ، لأن String تم نقله (moved) إلى calculate_length. بدلاً من ذلك، يمكننا تقديم مرجع (reference) لقيمة String. المرجع يشبه المؤشر (pointer) في أنه عنوان يمكننا اتباعه للوصول إلى البيانات المخزنة في ذلك العنوان؛ تلك البيانات مملوكة لمتغير آخر. على عكس pointer، يضمن المرجع أن يشير إلى قيمة صالحة من نوع معين طوال فترة حياة ذلك المرجع.
إليك كيف يمكنك تعريف واستخدام دالة calculate_length التي تحتوي على مرجع لكائن كمعلمة (parameter) بدلاً من أخذ ملكية القيمة:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize {
s.len()
}أولاً، لاحظ أن كل كود tuple في تصريح المتغير وقيمة إرجاع الدالة قد اختفى. ثانياً، لاحظ أننا نمرر &s1 إلى calculate_length وفي تعريفها، نأخذ &String بدلاً من String. تمثل علامات الاند (ampersands) هذه المراجع، وهي تسمح لك بالإشارة إلى قيمة ما دون أخذ ملكيتها. يوضح الشكل 4-6 هذا المفهوم.

الشكل 4-6: مخطط لـ &String s يشير إلى String s1
ملاحظة: عكس عملية الإسناد المرجعي (referencing) باستخدام
&هو إلغاء المرجعية (dereferencing)، والذي يتم تحقيقه باستخدام عامل إلغاء المرجعية (dereference operator)*. سنرى بعض استخدامات dereference operator في الفصل 8 ونناقش تفاصيل dereferencing في الفصل 15.
دعونا نلقي نظرة فاحصة على استدعاء الدالة هنا:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize {
s.len()
}يسمح لنا بناء جملة &s1 بإنشاء مرجع يشير إلى قيمة s1 ولكنه لا يملكها. ولأن المرجع لا يملكها، فإن القيمة التي يشير إليها لن يتم حذفها (dropped) عندما يتوقف استخدام المرجع.
وبالمثل، يستخدم توقيع الدالة & للإشارة إلى أن نوع parameter s هو مرجع. دعونا نضيف بعض التوضيحات الشارحة:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize { // s is a reference to a String
s.len()
} // Here, s goes out of scope. But because s does not have ownership of what
// it refers to, the String is not dropped.النطاق (scope) الذي يكون فيه المتغير s صالحاً هو نفس نطاق أي parameter للدالة، ولكن القيمة التي يشير إليها المرجع لا يتم حذفها عندما يتوقف استخدام s ، لأن s لا يملك الملكية. عندما تحتوي الدوال على مراجع كمعلمات بدلاً من القيم الفعلية، فلن نحتاج إلى إعادة القيم من أجل إعادة الملكية، لأننا لم نمتلك الملكية أبداً.
نسمي عملية إنشاء مرجع استعارة (borrowing). كما هو الحال في الحياة الواقعية، إذا كان شخص ما يملك شيئاً ما، يمكنك استعارته منه. عندما تنتهي، عليك إعادته. أنت لا تملكه.
لذا، ماذا يحدث إذا حاولنا تعديل شيء نستعيره؟ جرب الكود في القائمة 4-6. تنبيه: إنه لا يعمل!
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}إليك الخطأ:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | some_string.push_str(", world");
| ^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn change(some_string: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
تماماً كما أن المتغيرات غير قابلة للتغيير (immutable) بشكل افتراضي، كذلك المراجع. لا يُسمح لنا بتعديل شيء لدينا مرجع له.
المراجع القابلة للتغيير (Mutable References)
يمكننا إصلاح الكود من القائمة 4-6 للسماح لنا بتعديل قيمة مستعارة ببعض التعديلات الصغيرة التي تستخدم، بدلاً من ذلك، مرجعاً قابلاً للتغيير (mutable reference):
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}أولاً، نقوم بتغيير s ليكون mut. بعد ذلك، ننشئ mutable reference باستخدام &mut s حيث نستدعي دالة change ونقوم بتحديث توقيع الدالة لقبول mutable reference باستخدام some_string: &mut String. هذا يجعل من الواضح جداً أن دالة change ستقوم بتغيير (mutate) القيمة التي تستعيرها.
المراجع القابلة للتغيير لها قيد واحد كبير: إذا كان لديك mutable reference لقيمة ما، فلا يمكن أن يكون لديك مراجع أخرى لتلك القيمة. هذا الكود الذي يحاول إنشاء اثنين من mutable references لـ s سيفشل:
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{r1}, {r2}");
}إليك الخطأ:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{r1}, {r2}");
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
يقول هذا الخطأ أن هذا الكود غير صالح لأننا لا نستطيع استعارة s كـ mutable أكثر من مرة في كل مرة. الاستعارة القابلة للتغيير الأولى موجودة في r1 ويجب أن تستمر حتى يتم استخدامها في println! ، ولكن بين إنشاء ذلك المرجع القابل للتغيير واستخدامه، حاولنا إنشاء mutable reference آخر في r2 يستعير نفس البيانات مثل r1.
القيد الذي يمنع وجود مراجع متعددة قابلة للتغيير لنفس البيانات في نفس الوقت يسمح بالتغيير ولكن بطريقة محكومة للغاية. إنه شيء يعاني منه الـ Rustaceans الجدد لأن معظم اللغات تسمح لك بالتغيير وقتما تشاء. الفائدة من وجود هذا القيد هي أن Rust يمكنها منع سباقات البيانات (data races) في وقت التصريف (compile time). سباق البيانات يشبه حالة السباق (race condition) ويحدث عند وقوع هذه السلوكيات الثلاثة:
- وصول اثنين أو أكثر من pointers إلى نفس البيانات في نفس الوقت.
- استخدام واحد على الأقل من pointers للكتابة في البيانات.
- عدم وجود آلية مستخدمة لمزامنة الوصول إلى البيانات.
تسبب سباقات البيانات سلوكاً غير محدد (undefined behavior) ويمكن أن يكون من الصعب تشخيصها وإصلاحها عندما تحاول تعقبها في وقت التشغيل (runtime)؛ تمنع Rust هذه المشكلة برفض تصريف الكود الذي يحتوي على data races!
كما هو الحال دائماً، يمكننا استخدام الأقواس المتعرجة لإنشاء scope جديد، مما يسمح بوجود مراجع متعددة قابلة للتغيير، ولكن ليس مراجع متزامنة (simultaneous):
fn main() {
let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1 goes out of scope here, so we can make a new reference with no problems.
let r2 = &mut s;
}تفرض Rust قاعدة مماثلة للجمع بين المراجع القابلة للتغيير وغير القابلة للتغيير. يؤدي هذا الكود إلى حدوث خطأ:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
let r3 = &mut s; // BIG PROBLEM
println!("{r1}, {r2}, and {r3}");
}إليك الخطأ:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{r1}, {r2}, and {r3}");
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
يا للهول! لا يمكننا أيضاً الحصول على mutable reference بينما لدينا مرجع غير قابل للتغيير لنفس القيمة.
لا يتوقع مستخدمو المرجع غير القابل للتغيير أن تتغير القيمة فجأة من تحتهم! ومع ذلك، يُسمح بوجود مراجع متعددة غير قابلة للتغيير لأن لا أحد يقرأ البيانات فقط لديه القدرة على التأثير على قراءة أي شخص آخر للبيانات.
لاحظ أن scope المرجع يبدأ من حيث يتم تقديمه ويستمر حتى آخر مرة يتم فيها استخدام ذلك المرجع. على سبيل المثال، سيتم تصريف هذا الكود لأن آخر استخدام للمراجع غير القابلة للتغيير هو في println! ، قبل تقديم mutable reference:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
println!("{r1} and {r2}");
// Variables r1 and r2 will not be used after this point.
let r3 = &mut s; // no problem
println!("{r3}");
}تنتهي نطاقات المراجع غير القابلة للتغيير r1 و r2 بعد println! حيث تم استخدامهما لآخر مرة، وهو ما يحدث قبل إنشاء mutable reference r3. هذه النطاقات لا تتداخل، لذا فإن هذا الكود مسموح به: يمكن لـ compiler معرفة أن المرجع لم يعد مستخدماً عند نقطة قبل نهاية scope.
على الرغم من أن أخطاء borrowing قد تكون محبطة في بعض الأحيان، تذكر أن compiler في Rust هو من يشير إلى خطأ محتمل في وقت مبكر (في compile time بدلاً من runtime) ويوضح لك بالضبط مكان المشكلة. عندها، لن تضطر إلى تعقب سبب عدم كون بياناتك كما كنت تعتقد.
المراجع المعلقة (Dangling References)
في اللغات التي تحتوي على pointers، من السهل إنشاء مؤشر معلق (dangling pointer) عن طريق الخطأ — وهو مؤشر يشير إلى موقع في الذاكرة ربما تم إعطاؤه لشخص آخر — عن طريق تحرير بعض الذاكرة مع الاحتفاظ بمؤشر لتلك الذاكرة. في Rust، على النقيض من ذلك، يضمن compiler أن المراجع لن تكون أبداً مراجع معلقة (dangling references): إذا كان لديك مرجع لبعض البيانات، فسيضمن compiler أن البيانات لن تخرج عن النطاق قبل أن يخرج المرجع للبيانات عن النطاق.
دعونا نحاول إنشاء dangling reference لنرى كيف تمنعها Rust بخطأ في وقت التصريف:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}إليك الخطأ:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
5 | fn dangle() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn dangle() -> &String {
5 + fn dangle() -> String {
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
تشير رسالة الخطأ هذه إلى ميزة لم نغطها بعد: فترات الحياة (lifetimes). سنناقش lifetimes بالتفصيل في الفصل 10. ولكن، إذا تجاهلت الأجزاء المتعلقة بـ lifetimes، فإن الرسالة تحتوي بالفعل على المفتاح لسبب كون هذا الكود مشكلة:
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
دعونا نلقي نظرة فاحصة على ما يحدث بالضبط في كل مرحلة من مراحل كود dangle الخاص بنا:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle returns a reference to a String
let s = String::from("hello"); // s is a new String
&s // we return a reference to the String, s
} // Here, s goes out of scope and is dropped, so its memory goes away.
// Danger!لأن s تم إنشاؤه داخل dangle ، فعند انتهاء كود dangle ، سيتم إلغاء تخصيص (deallocated) s. لكننا حاولنا إعادة مرجع له. هذا يعني أن هذا المرجع سيشير إلى String غير صالح. هذا ليس جيداً! لن تسمح لنا Rust بالقيام بذلك.
الحل هنا هو إعادة String مباشرة:
fn main() {
let string = no_dangle();
}
fn no_dangle() -> String {
let s = String::from("hello");
s
}هذا يعمل دون أي مشاكل. يتم نقل الملكية للخارج، ولا يتم إلغاء تخصيص أي شيء.
قواعد المراجع (The Rules of References)
دعونا نلخص ما ناقشناه حول المراجع:
- في أي وقت معين، يمكنك الحصول على إما مرجع واحد قابل للتغيير أو أي عدد من المراجع غير القابلة للتغيير.
- يجب أن تكون المراجع صالحة دائماً.
بعد ذلك، سننظر في نوع مختلف من المراجع: الشرائح (slices).
نوع الشريحة (The Slice Type)
نوع الشريحة (The Slice Type)
تتيح لك الـ شرائح (slices) الإشارة إلى تسلسل متصل من العناصر في مجموعة. الشريحة هي نوع من المراجع (references)، لذا فهي لا تمتلك ملكية (ownership).
إليك مشكلة برمجية صغيرة: اكتب دالة تأخذ سلسلة نصية (string) من الكلمات المفصولة بمسافات وتعيد الكلمة الأولى التي تجدها في تلك السلسلة. إذا لم تجد الدالة مسافة في السلسلة، فيجب اعتبار السلسلة بأكملها كلمة واحدة، وبالتالي يجب إعادة السلسلة كاملة.
ملاحظة: لأغراض تقديم الـ slices، نفترض استخدام ASCII فقط في هذا القسم؛ يوجد نقاش أكثر تفصيلاً حول التعامل مع UTF-8 في قسم “تخزين النصوص المشفرة بـ UTF-8 باستخدام السلاسل النصية” في الفصل 8.
دعنا نستعرض كيف سنكتب توقيع (signature) هذه الدالة دون استخدام الـ slices، لفهم المشكلة التي ستحلها الـ slices:
fn first_word(s: &String) -> ?تمتلك دالة first_word معاملًا (parameter) من نوع &String. نحن لا نحتاج إلى الـ ownership، لذا هذا جيد. (في لغة Rust الاصطلاحية، لا تأخذ الدوال ملكية وسائطها (arguments) إلا إذا كانت بحاجة لذلك، وستتضح أسباب ذلك مع تقدمنا). ولكن ماذا يجب أن نعيد؟ ليس لدينا حقًا طريقة للتحدث عن جزء من السلسلة النصية. ومع ذلك، يمكننا إعادة فهرس (index) نهاية الكلمة، والذي تشير إليه المسافة. لنحاول ذلك، كما هو موضح في القائمة 4-7.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}لأننا بحاجة إلى المرور عبر الـ String عنصرًا تلو الآخر والتحقق مما إذا كانت القيمة مسافة، سنقوم بتحويل الـ String الخاص بنا إلى مصفوفة من البايتات (array of bytes) باستخدام دالة as_bytes.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}بعد ذلك، ننشئ مكررًا (iterator) فوق مصفوفة البايتات باستخدام دالة iter:
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}سنناقش الـ iterators بمزيد من التفصيل في الفصل 13. في الوقت الحالي، اعلم أن iter هي دالة تعيد كل عنصر في المجموعة، وأن enumerate تغلف نتيجة iter وتعيد كل عنصر كجزء من صف (tuple) بدلاً من ذلك. العنصر الأول في الـ tuple المعاد من enumerate هو الـ index، والعنصر الثاني هو مرجع للعنصر. هذا أكثر ملاءمة قليلاً من حساب الـ index بأنفسنا.
لأن دالة enumerate تعيد tuple، يمكننا استخدام الأنماط (patterns) لتفكيك ذلك الـ tuple. سنناقش الـ patterns أكثر في الفصل 6. في حلقة for نحدد نمطًا يحتوي على i للـ index في الـ tuple و &item للبايت الواحد في الـ tuple. ولأننا نحصل على مرجع للعنصر من .iter().enumerate() نستخدم & في النمط.
داخل حلقة for نبحث عن البايت الذي يمثل المسافة باستخدام بناء جملة البايت الحرفي (byte literal syntax). إذا وجدنا مسافة، نعيد الموضع. خلاف ذلك، نعيد طول السلسلة باستخدام s.len().
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}لدينا الآن طريقة لمعرفة فهرس نهاية الكلمة الأولى في السلسلة، ولكن هناك مشكلة. نحن نعيد نوع usize بمفرده، لكنه لا يكون ذا معنى إلا في سياق الـ &String. بعبارة أخرى، لأنه قيمة منفصلة عن الـ String فلا يوجد ضمان بأنه سيظل صالحًا في المستقبل. فكر في البرنامج في القائمة 4-8 الذي يستخدم دالة first_word من القائمة 4-7.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s); // word will get the value 5
s.clear(); // this empties the String, making it equal to ""
// word still has the value 5 here, but s no longer has any content that we
// could meaningfully use with the value 5, so word is now totally invalid!
}يترجم هذا البرنامج دون أي أخطاء، وسيفعل ذلك أيضًا إذا استخدمنا word بعد استدعاء s.clear(). ولأن word غير متصل بحالة s على الإطلاق، فإن word لا يزال يحتوي على القيمة 5. يمكننا استخدام تلك القيمة 5 مع المتغير s لمحاولة استخراج الكلمة الأولى، ولكن هذا سيكون خطأً برمجياً (bug) لأن محتويات s قد تغيرت منذ أن حفظنا 5 في word.
الاضطرار للقلق بشأن خروج الـ index في word عن المزامنة مع البيانات في s هو أمر ممل وعرضة للخطأ! إدارة هذه الفهارس تكون أكثر هشاشة إذا كتبنا دالة second_word. سيضطر توقيعها ليكون هكذا:
fn second_word(s: &String) -> (usize, usize) {الآن نحن نتتبع فهرس بداية ونهاية، ولدينا المزيد من القيم التي تم حسابها من بيانات في حالة معينة ولكنها ليست مرتبطة بتلك الحالة على الإطلاق. لدينا ثلاثة متغيرات غير مرتبطة تطفو حولنا وتحتاج إلى الحفاظ على مزامنتها.
لحسن الحظ، لدى Rust حل لهذه المشكلة: شرائح السلاسل النصية (string slices).
شرائح السلاسل النصية (String Slices)
الـ string slice هي مرجع لتسلسل متصل من عناصر الـ String وتبدو هكذا:
fn main() {
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
}بدلاً من مرجع للـ String بالكامل، فإن hello هو مرجع لجزء من الـ String محدد في الجزء الإضافي [0..5]. ننشئ الـ slices باستخدام نطاق (range) داخل أقواس مربعة عن طريق تحديد [starting_index..ending_index] حيث يكون starting_index هو الموضع الأول في الشريحة و ending_index هو أكثر بواحد من الموضع الأخير في الشريحة. داخليًا، يخزن هيكل بيانات الشريحة موضع البداية وطول الشريحة، والذي يتوافق مع ending_index ناقص starting_index. لذا، في حالة let world = &s[6..11]; سيكون world عبارة عن شريحة تحتوي على مؤشر (pointer) للبايت عند الفهرس 6 من s مع قيمة طول قدرها 5.
يوضح الشكل 4-7 هذا في رسم تخطيطي.

الشكل 4-7: شريحة سلسلة نصية تشير إلى جزء من String
مع بناء جملة النطاق .. في Rust، إذا كنت تريد البدء من الفهرس 0، يمكنك حذف القيمة قبل النقطتين. بعبارة أخرى، هذه متساوية:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];
}وبنفس المنطق، إذا كانت شريحتك تتضمن البايت الأخير من الـ String يمكنك حذف الرقم اللاحق. وهذا يعني أن هذه متساوية:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let len = s.len();
let slice = &s[3..len];
let slice = &s[3..];
}يمكنك أيضًا حذف كلتا القيمتين لأخذ شريحة من السلسلة بأكملها. لذا، هذه متساوية:
#![allow(unused)]
fn main() {
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];
}ملاحظة: يجب أن تقع فهارس نطاق الـ string slice عند حدود أحرف UTF-8 صالحة. إذا حاولت إنشاء شريحة سلسلة نصية في منتصف حرف متعدد البايتات، فسيخرج برنامجك بخطأ.
مع وضع كل هذه المعلومات في الاعتبار، دعنا نعيد كتابة first_word لتعيد شريحة. النوع الذي يشير إلى “شريحة سلسلة نصية” يكتب كـ &str:
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {}نحصل على الفهرس لنهاية الكلمة بنفس الطريقة التي فعلناها في القائمة 4-7، من خلال البحث عن أول ظهور للمسافة. عندما نجد مسافة، نعيد شريحة سلسلة نصية باستخدام بداية السلسلة وفهرس المسافة كفهارس البداية والنهاية.
الآن عندما نستدعي first_word نحصل على قيمة واحدة مرتبطة بالبيانات الأساسية. تتكون القيمة من مرجع لنقطة بداية الشريحة وعدد العناصر في الشريحة.
إعادة شريحة سيعمل أيضًا مع دالة second_word:
fn second_word(s: &String) -> &str {لدينا الآن واجهة برمجة تطبيقات (API) مباشرة يصعب العبث بها لأن المترجم سيضمن بقاء المراجع داخل الـ String صالحة. تذكر الـ bug في البرنامج في القائمة 4-8، عندما حصلنا على الفهرس لنهاية الكلمة الأولى ثم مسحنا السلسلة فصار الفهرس غير صالح؟ كان ذلك الكود غير صحيح منطقيًا ولكنه لم يظهر أي أخطاء فورية. كانت المشاكل ستظهر لاحقًا إذا واصلنا محاولة استخدام فهرس الكلمة الأولى مع سلسلة فارغة. تجعل الـ slices هذا الـ bug مستحيلاً وتخبرنا في وقت أبكر بكثير أن لدينا مشكلة في كودنا. استخدام نسخة الـ slice من first_word سيؤدي إلى خطأ في وقت الترجمة (compile-time error):
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {word}");
}إليك خطأ المترجم:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {word}");
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
تذكر من قواعد الاستعارة (borrowing rules) أنه إذا كان لدينا مرجع غير قابل للتغيير (immutable reference) لشيء ما، فلا يمكننا أيضًا أخذ مرجع قابل للتغيير (mutable reference). ولأن clear تحتاج إلى تقليص الـ String فهي بحاجة للحصول على mutable reference. الـ println! بعد استدعاء clear تستخدم المرجع في word لذا يجب أن يظل الـ immutable reference نشطًا عند تلك النقطة. يمنع Rust وجود الـ mutable reference في clear والـ immutable reference في word في نفس الوقت، ويفشل الترجمة. لم يجعل Rust الـ API الخاص بنا أسهل في الاستخدام فحسب، بل قضى أيضًا على فئة كاملة من الأخطاء في وقت الترجمة!
السلاسل النصية الحرفية كشرائح (String Literals as Slices)
تذكر أننا تحدثنا عن تخزين السلاسل النصية الحرفية (string literals) داخل الملف الثنائي (binary). الآن بعد أن عرفنا عن الـ slices، يمكننا فهم السلاسل النصية الحرفية بشكل صحيح:
#![allow(unused)]
fn main() {
let s = "Hello, world!";
}نوع s هنا هو &str: إنه شريحة تشير إلى تلك النقطة المحددة من الـ binary. وهذا أيضًا هو السبب في أن السلاسل النصية الحرفية غير قابلة للتغيير؛ &str هو immutable reference.
شرائح السلاسل النصية كمعاملات (String Slices as Parameters)
معرفة أنه يمكنك أخذ شرائح من الحرفيات وقيم الـ String يقودنا إلى تحسين آخر على first_word وهو توقيعها:
fn first_word(s: &String) -> &str {سيكتب مبرمج Rust الأكثر خبرة (Rustacean) التوقيع الموضح في القائمة 4-9 بدلاً من ذلك لأنه يسمح لنا باستخدام نفس الدالة على كل من قيم &String وقيم &str.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or
// whole.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}إذا كان لدينا string slice، يمكننا تمريرها مباشرة. إذا كان لدينا String يمكننا تمرير شريحة من الـ String أو مرجع للـ String. تستفيد هذه المرونة من تحويلات فك المراجع (deref coercions)، وهي ميزة سنغطيها في قسم “استخدام تحويلات فك المراجع في الدوال والـ methods” في الفصل 15.
تعريف دالة لتأخذ string slice بدلاً من مرجع لـ String يجعل الـ API الخاص بنا أكثر عمومية وفائدة دون فقدان أي وظائف:
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or
// whole.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}شرائح أخرى (Other Slices)
شرائح السلاسل النصية، كما قد تتخيل، خاصة بالسلاسل النصية. ولكن هناك نوع شريحة أكثر عمومية أيضًا. فكر في هذه المصفوفة:
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
}تمامًا كما قد نرغب في الإشارة إلى جزء من سلسلة نصية، قد نرغب في الإشارة إلى جزء من مصفوفة. سنفعل ذلك هكذا:
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
}هذه الشريحة لها النوع &[i32]. وهي تعمل بنفس الطريقة التي تعمل بها شرائح السلاسل النصية، من خلال تخزين مرجع للعنصر الأول وطول. ستستخدم هذا النوع من الشرائح لجميع أنواع المجموعات الأخرى. سنناقش هذه المجموعات بالتفصيل عندما نتحدث عن المتجهات (vectors) في الفصل 8.
ملخص (Summary)
تضمن مفاهيم الملكية (ownership)، والاستعارة (borrowing)، والشرائح (slices) سلامة الذاكرة (memory safety) في برامج Rust في وقت الترجمة. تمنحك لغة Rust التحكم في استخدام الذاكرة بنفس الطريقة التي تمنحك إياها لغات برمجة الأنظمة الأخرى. ولكن وجود مالك للبيانات يقوم تلقائيًا بتنظيف تلك البيانات عندما يخرج المالك عن النطاق يعني أنك لست مضطرًا لكتابة وتصحيح كود إضافي للحصول على هذا التحكم.
تؤثر الـ Ownership على كيفية عمل الكثير من الأجزاء الأخرى في Rust، لذا سنتحدث عن هذه المفاهيم بشكل أكبر في بقية الكتاب. دعنا ننتقل إلى الفصل 5 وننظر في تجميع قطع البيانات معًا في هيكل struct.
استخدام الهياكل لتنظيم البيانات ذات الصلة (Using Structs to Structure Related Data)
الـ هيكل (struct)، أو البنية (structure)، هو نوع بيانات مخصص يتيح لك تجميع وتسمية قيم متعددة ذات صلة تشكل مجموعة ذات معنى. إذا كنت معتاداً على لغة كائنية التوجه (object-oriented language)، فإن struct يشبه سمات البيانات (data attributes) الخاصة بالكائن. في هذا الفصل، سنقوم بمقارنة وتباين الصفوف (tuples) مع structs للبناء على ما تعرفه بالفعل وتوضيح متى تكون structs طريقة أفضل لتجميع البيانات.
سنوضح كيفية تعريف وإنشاء مثيلات (instantiate) من structs. سنناقش كيفية تعريف الدوال المرتبطة (associated functions)، وخاصة نوع associated functions الذي يسمى الدوال (methods)، لتحديد السلوك المرتبط بنوع struct. تعد structs والتعدادات (enums) (التي تمت مناقشتها في الفصل السادس) هي اللبنات الأساسية لإنشاء أنواع جديدة في مجال برنامجك للاستفادة الكاملة من فحص النوع في وقت التصريف (compile-time type checking) في Rust.
تعريف وإنشاء الهياكل (Defining and Instantiating Structs)
تعريف الهياكل وإنشاؤها (Defining and Instantiating Structs)
تتشابه الهياكل (structs) مع الصفوف (tuples)، التي نوقشت في قسم “نوع الصف (Tuple)” ، في أن كليهما يحمل عدة قيم مرتبطة. ومثل tuples، يمكن أن تكون أجزاء الـ struct من أنواع مختلفة. وبخلاف tuples، ستقوم في الـ struct بتسمية كل قطعة من البيانات بحيث يكون واضحاً ما تعنيه القيم. إضافة هذه الأسماء تعني أن structs أكثر مرونة من tuples: لست مضطراً للاعتماد على ترتيب البيانات لتحديد قيم مثيل (instance) أو الوصول إليها.
لتعريف struct، ندخل الكلمة المفتاحية struct ونسمي الـ struct بالكامل. يجب أن يصف اسم الـ struct أهمية قطع البيانات التي يتم تجميعها معاً. ثم، داخل أقواس متعرجة، نعرف أسماء وأنواع قطع البيانات، والتي نسميها حقولاً (fields). على سبيل المثال، توضح القائمة 5-1 struct يخزن معلومات حول حساب مستخدم.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {}لاستخدام struct بعد تعريفه، ننشئ مثيلاً (instance) من ذلك الـ struct عن طريق تحديد قيم ملموسة لكل من الـ fields. ننشئ instance بذكر اسم الـ struct ثم نضيف أقواس متعرجة تحتوي على أزواج key: value ، حيث المفاتيح هي أسماء الـ fields والقيم هي البيانات التي نريد تخزينها في تلك الـ fields. ليس علينا تحديد الـ fields بنفس الترتيب الذي صرحنا به عنها في الـ struct. بمعنى آخر، تعريف الـ struct يشبه قالباً عاماً للنوع، وتقوم الـ instances بملء ذلك القالب ببيانات محددة لإنشاء قيم من ذلك النوع. على سبيل المثال، يمكننا التصريح عن مستخدم معين كما هو موضح في القائمة 5-2.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
}للحصول على قيمة محددة من struct، نستخدم ترميز النقطة (dot notation). على سبيل المثال، للوصول إلى عنوان البريد الإلكتروني لهذا المستخدم، نستخدم user1.email. إذا كان الـ instance قابلاً للتغيير (mutable)، فيمكننا تغيير قيمة باستخدام dot notation والتعيين في field معين. توضح القائمة 5-3 كيفية تغيير القيمة في حقل email لمثيل User قابل للتغيير.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let mut user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");
}لاحظ أن الـ instance بالكامل يجب أن يكون mutable؛ لا تسمح لنا Rust بتمييز حقول معينة فقط كـ mutable. وكما هو الحال مع أي تعبير، يمكننا بناء instance جديد من الـ struct كآخر تعبير في جسم الدالة (function body) لإرجاع ذلك الـ instance الجديد ضمناً.
توضح القائمة 5-4 دالة build_user تعيد instance من User بالبريد الإلكتروني واسم المستخدم المعطيين. يحصل حقل active على القيمة true ، ويحصل sign_in_count على قيمة 1.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
active: true,
username: username,
email: email,
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(
String::from("someone@example.com"),
String::from("someusername123"),
);
}من المنطقي تسمية معاملات الدالة (function parameters) بنفس اسم struct fields ، ولكن الاضطرار إلى تكرار أسماء الحقول والمتغيرات email و username أمر ممل بعض الشيء. إذا كان للـ struct حقول أكثر، فإن تكرار كل اسم سيصبح أكثر إزعاجاً. لحسن الحظ، هناك اختصار مريح!
استخدام اختصار تهيئة الحقول (Using the Field Init Shorthand)
لأن أسماء الـ parameters وأسماء struct fields متطابقة تماماً في القائمة 5-4، يمكننا استخدام صيغة (syntax) اختصار تهيئة الحقول (field init shorthand) لإعادة كتابة build_user بحيث تتصرف تماماً بنفس الطريقة ولكن بدون تكرار username و email ، كما هو موضح في القائمة 5-5.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
active: true,
username,
email,
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(
String::from("someone@example.com"),
String::from("someusername123"),
);
}هنا، نقوم بإنشاء instance جديد من الـ User struct، والذي يحتوي على field باسم email. نريد تعيين قيمة حقل email إلى القيمة الموجودة في parameter الـ email لدالة build_user. ولأن حقل email و parameter الـ email لهما نفس الاسم، نحتاج فقط إلى كتابة email بدلاً من email: email.
إنشاء مثيلات باستخدام صيغة تحديث الهيكل (Creating Instances with Struct Update Syntax)
غالباً ما يكون من المفيد إنشاء instance جديد من struct يتضمن معظم القيم من instance آخر من نفس النوع، ولكن يغير بعضها. يمكنك القيام بذلك باستخدام صيغة تحديث الهيكل (struct update syntax).
أولاً، في القائمة 5-6 نوضح كيفية إنشاء instance جديد من User في user2 بالطريقة العادية، بدون update syntax. نقوم بتعيين قيمة جديدة لـ email ولكن بخلاف ذلك نستخدم نفس القيم من user1 الذي أنشأناه في القائمة 5-2.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
// --snip--
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
}باستخدام struct update syntax، يمكننا تحقيق نفس التأثير بكود أقل، كما هو موضح في القائمة 5-7. تحدد الصيغة .. أن الـ fields المتبقية التي لم يتم تعيينها صراحة يجب أن يكون لها نفس قيمة الـ fields في الـ instance المعطى.
يُنشئ الكود في القائمة 5-7 أيضاً instance في `user2` له قيمة مختلفة لـ `email` ولكن له نفس القيم لحقول `username` و `active` و `sign_in_count` من `user1`. يجب أن تأتي `..user1` في النهاية لتحديد أن أي حقول متبقية يجب أن تحصل على قيمها من الحقول المقابلة في `user1` ، ولكن يمكننا اختيار تحديد قيم لعدد الحقول الذي نريده وبأي ترتيب، بغض النظر عن ترتيب الحقول في تعريف الـ struct.
لاحظ أن struct update syntax يستخدم `=` مثل التعيين؛ هذا لأنه ينقل البيانات، تماماً كما رأينا في قسم ["تفاعل المتغيرات والبيانات مع النقل (Move)"][move]. في هذا المثال، لم يعد بإمكاننا استخدام `user1` بعد إنشاء `user2` لأن الـ `String` في حقل `username` لـ `user1` قد نُقل إلى `user2`. إذا أعطينا `user2` قيم `String` جديدة لكل من `email` و `username` ، وبالتالي استخدمنا فقط قيم `active` و `sign_in_count` من `user1` ، فسيظل `user1` صالحاً بعد إنشاء `user2`. كل من `active` و `sign_in_count` هما أنواع تنفذ سمة (trait) الـ `Copy` ، لذا فإن السلوك الذي ناقشناه في قسم ["بيانات المكدس فقط: النسخ (Copy)"][copy] سينطبق. يمكننا أيضاً الاستمرار في استخدام `user1.email` في هذا المثال، لأن قيمته لم تُنقل خارج `user1`.
<!-- Old headings. Do not remove or links may break. -->
<a id="using-tuple-structs-without-named-fields-to-create-different-types"></a>
### إنشاء أنواع مختلفة باستخدام هياكل الصفوف (Creating Different Types with Tuple Structs)
تدعم Rust أيضاً structs تشبه tuples، وتسمى _هياكل الصفوف_ (tuple structs). تمتلك tuple structs المعنى الإضافي الذي يوفره اسم الـ struct ولكن ليس لها أسماء مرتبطة بحقولها؛ بدلاً من ذلك، لديها فقط أنواع الحقول. تكون tuple structs مفيدة عندما تريد إعطاء الـ tuple بالكامل اسماً وجعل الـ tuple نوعاً مختلفاً عن tuples الأخرى، وعندما يكون تسمية كل حقل كما هو الحال في الـ struct العادي أمراً مطولاً أو زائداً عن الحاجة.
لتعريف tuple struct، ابدأ بالكلمة المفتاحية `struct` واسم الـ struct متبوعاً بالأنواع الموجودة في الـ tuple. على سبيل المثال، هنا نعرف ونستخدم اثنين من tuple structs باسم `Color` و `Point`:
<Listing file-name="src/main.rs">
```rust
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
}
لاحظ أن قيم black و origin هي أنواع مختلفة لأنها instances من tuple structs مختلفة. كل struct تعرفه هو نوع خاص به، على الرغم من أن الحقول داخل الـ struct قد يكون لها نفس الأنواع. على سبيل المثال، الدالة التي تأخذ parameter من نوع Color لا يمكنها أخذ Point كـ argument، على الرغم من أن كلا النوعين يتكونان من ثلاث قيم i32. بخلاف ذلك، تتشابه instances الـ tuple struct مع tuples في أنه يمكنك تفكيكها (destructure) إلى قطعها الفردية، ويمكنك استخدام . متبوعة بالفهرس (index) للوصول إلى قيمة فردية. وبخلاف tuples، تتطلب منك tuple structs تسمية نوع الـ struct عند القيام بـ destructure لها. على سبيل المثال، سنكتب let Point(x, y, z) = origin; لتفكيك القيم في نقطة الـ origin إلى متغيرات تسمى x و y و z.
تعريف الهياكل الشبيهة بالوحدة (Defining Unit-Like Structs)
يمكنك أيضاً تعريف structs لا تحتوي على أي حقول! تسمى هذه الهياكل الشبيهة بالوحدة (unit-like structs) لأنها تتصرف بشكل مشابه لـ () ، وهو نوع الوحدة (unit type) الذي ذكرناه في قسم “نوع الصف (Tuple)”. يمكن أن تكون unit-like structs مفيدة عندما تحتاج إلى تنفيذ trait على نوع ما ولكن ليس لديك أي بيانات تريد تخزينها في النوع نفسه. سنناقش الـ traits في الفصل العاشر. إليك مثال على التصريح عن struct وحدة باسم AlwaysEqual وإنشائه:
struct AlwaysEqual;
fn main() {
let subject = AlwaysEqual;
}لتعريف AlwaysEqual ، نستخدم الكلمة المفتاحية struct ، والاسم الذي نريده، ثم فاصلة منقوطة. لا حاجة لأقواس متعرجة أو أقواس عادية! بعد ذلك، يمكننا الحصول على instance من AlwaysEqual في متغير subject بطريقة مماثلة: باستخدام الاسم الذي عرفناه، بدون أي أقواس متعرجة أو عادية. تخيل أننا سنقوم لاحقاً بتنفيذ سلوك لهذا النوع بحيث يكون كل instance من AlwaysEqual مساوياً دائماً لكل instance من أي نوع آخر، ربما للحصول على نتيجة معروفة لأغراض الاختبار. لن نحتاج إلى أي بيانات لتنفيذ هذا السلوك! سترى في الفصل العاشر كيفية تعريف traits وتنفيذها على أي نوع، بما في ذلك unit-like structs.
ملكية بيانات الهيكل (Ownership of Struct Data)
في تعريف
Userstruct في القائمة 5-1، استخدمنا نوع الـStringالمملوك بدلاً من نوع شريحة السلسلة (string slice)&str. هذا اختيار متعمد لأننا نريد أن يمتلك كل instance من هذا الـ struct جميع بياناته وأن تكون تلك البيانات صالحة طالما أن الـ struct بالكامل صالح.من الممكن أيضاً للـ structs تخزين مراجع (references) لبيانات مملوكة لشيء آخر، ولكن القيام بذلك يتطلب استخدام فترات الحياة (lifetimes)، وهي ميزة في Rust سنناقشها في الفصل العاشر. تضمن lifetimes أن البيانات المشار إليها بواسطة struct صالحة طالما أن الـ struct صالح. لنفترض أنك حاولت تخزين reference في struct دون تحديد lifetimes، مثل ما يلي في src/main.rs؛ هذا لن يعمل:
struct User { active: bool, username: &str, email: &str, sign_in_count: u64, } fn main() { let user1 = User { active: true, username: "someusername123", email: "someone@example.com", sign_in_count: 1, }; }سيشتكي المترجم (compiler) من أنه يحتاج إلى محددات فترات الحياة (lifetime specifiers):
$ cargo run Compiling structs v0.1.0 (file:///projects/structs) error[E0106]: missing lifetime specifier --> src/main.rs:3:15 | 3 | username: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 ~ username: &'a str, | error[E0106]: missing lifetime specifier --> src/main.rs:4:12 | 4 | email: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 | username: &str, 4 ~ email: &'a str, | For more information about this error, try `rustc --explain E0106`. error: could not compile `structs` (bin "structs") due to 2 previous errorsفي الفصل العاشر، سنناقش كيفية إصلاح هذه الأخطاء بحيث يمكنك تخزين references في structs، ولكن في الوقت الحالي، سنصلح أخطاء مثل هذه باستخدام الأنواع المملوكة مثل
Stringبدلاً من references مثل&str.
برنامج مثال باستخدام Structs
برنامج مثال يستخدم التركيبات (Structs)
لفهم متى قد نرغب في استخدام Structs، دعنا نكتب برنامجًا يحسب مساحة مستطيل. سنبدأ باستخدام متغيرات مفردة ثم نقوم بـ إعادة الهيكلة (Refactoring) للبرنامج حتى نستخدم Structs بدلاً من ذلك.
دعنا ننشئ مشروعًا ثنائيًا جديدًا باستخدام Cargo يسمى rectangles والذي سيأخذ العرض والارتفاع لمستطيل محدد بالبكسل ويحسب مساحة المستطيل. توضح القائمة 5-8 برنامجًا قصيرًا بإحدى طرق القيام بذلك بالضبط في ملف src/main.rs الخاص بمشروعنا.
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}الآن، قم بتشغيل هذا البرنامج باستخدام cargo run:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
The area of the rectangle is 1500 square pixels.
ينجح هذا الكود في معرفة مساحة المستطيل عن طريق استدعاء الدالة area بكل بُعد، ولكن يمكننا فعل المزيد لجعل هذا الكود واضحًا وقابلًا للقراءة.
تظهر المشكلة في هذا الكود واضحة في توقيع area:
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}من المفترض أن تحسب الدالة area مساحة مستطيل واحد، لكن الدالة التي كتبناها تحتوي على معاملين، وليس من الواضح في أي مكان في برنامجنا أن المعاملين مرتبطان. سيكون تجميع width و height معًا أكثر قابلية للقراءة وأسهل في الإدارة. لقد ناقشنا بالفعل إحدى الطرق التي قد نفعل بها ذلك في قسم “The Tuple Type” من الفصل 3: باستخدام الصفوف (Tuples).
Refactoring باستخدام Tuples
توضح القائمة 5-9 إصدارًا آخر من برنامجنا يستخدم Tuples.
fn main() {
let rect1 = (30, 50);
println!(
"The area of the rectangle is {} square pixels.",
area(rect1)
);
}
fn area(dimensions: (u32, u32)) -> u32 {
dimensions.0 * dimensions.1
}بطريقة ما، هذا البرنامج أفضل. تسمح لنا Tuples بإضافة القليل من الهيكلة، ونحن الآن نمرر وسيطًا واحدًا فقط. ولكن بطريقة أخرى، هذا الإصدار أقل وضوحًا: لا تسمي Tuples عناصرها، لذلك يجب علينا الفهرسة في أجزاء Tuple، مما يجعل حسابنا أقل وضوحًا.
لن يهم خلط width و height في حساب المساحة، ولكن إذا أردنا رسم المستطيل على الشاشة، فسيكون الأمر مهمًا! سيتعين علينا أن نضع في اعتبارنا أن width هو فهرس Tuple رقم 0 وأن height هو فهرس Tuple رقم 1. سيكون هذا أصعب على شخص آخر اكتشافه ووضعه في الاعتبار إذا كان سيستخدم الكود الخاص بنا. نظرًا لأننا لم ننقل معنى بياناتنا في الكود الخاص بنا، فقد أصبح من الأسهل الآن إدخال أخطاء.
Refactoring باستخدام Structs
نستخدم Structs لإضافة معنى عن طريق تسمية البيانات. يمكننا تحويل Tuple الذي نستخدمه إلى Struct باسم للكل بالإضافة إلى أسماء للأجزاء، كما هو موضح في القائمة 5-10.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!(
"The area of the rectangle is {} square pixels.",
area(&rect1)
);
}
fn area(rectangle: &Rectangle) -> u32 {
rectangle.width * rectangle.height
}هنا، قمنا بتعريف Struct وسميناها Rectangle. داخل الأقواس المعقوفة، قمنا بتعريف الحقول (Fields) كـ width و height، وكلاهما من النوع u32. بعد ذلك، في main، أنشأنا مثيلًا (instance) معينًا من Rectangle بعرض 30 وارتفاع 50.
تم تعريف الدالة area الآن بمعامل واحد، سميناه rectangle، ونوعه هو استعارة غير قابلة للتغيير (immutable borrow) لمثيل Struct Rectangle. كما ذكرنا في الفصل 4، نريد استعارة (Borrow) Struct بدلاً من أخذ الملكية (Ownership) لها. بهذه الطريقة، تحتفظ main بـ Ownership الخاصة بها ويمكنها الاستمرار في استخدام rect1، وهذا هو السبب في أننا نستخدم & في توقيع الدالة وعندما نستدعي الدالة.
تصل الدالة area إلى Fields width و height لمثيل Rectangle (لاحظ أن الوصول إلى Fields لمثيل Struct مستعار لا ينقل قيم Field، ولهذا السبب ترى غالبًا عمليات Borrow لـ Structs). يقول توقيع الدالة area الآن بالضبط ما نعنيه: احسب مساحة Rectangle، باستخدام Fields width و height الخاصة بها. هذا ينقل أن width و height مرتبطان ببعضهما البعض، ويعطي أسماء وصفية للقيم بدلاً من استخدام قيم فهرس Tuple 0 و 1. هذا مكسب للوضوح.
إضافة وظائف باستخدام السمات المشتقة (Derived Traits)
سيكون من المفيد أن نتمكن من طباعة مثيل Rectangle أثناء تصحيح الأخطاء (Debug) في برنامجنا ورؤية القيم لجميع Fields الخاصة به. تحاول القائمة 5-11 استخدام الماكرو println! كما استخدمناه في الفصول السابقة. ومع ذلك، لن ينجح هذا.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {rect1}");
}عندما نقوم بتجميع هذا الكود، نحصل على خطأ بهذه الرسالة الأساسية:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
يمكن لـ ماكرو println! القيام بالعديد من أنواع التنسيق، وبشكل افتراضي، تخبر الأقواس المعقوفة println! باستخدام تنسيق يُعرف باسم Display: إخراج مخصص للاستهلاك المباشر للمستخدم النهائي. تطبق الأنواع البدائية (primitive types) التي رأيناها حتى الآن Display افتراضيًا لأنه لا توجد سوى طريقة واحدة تريد بها إظهار 1 أو أي نوع بدائي آخر للمستخدم. ولكن مع Structs، فإن الطريقة التي يجب أن يقوم بها println! بتنسيق الإخراج أقل وضوحًا لأن هناك المزيد من إمكانيات العرض: هل تريد فواصل أم لا؟ هل تريد طباعة الأقواس المعقوفة؟ هل يجب عرض جميع Fields؟ بسبب هذا الغموض، لا يحاول Rust تخمين ما نريده، ولا تحتوي Structs على تطبيق متوفر لـ Display لاستخدامه مع println! والعنصر النائب {}.
إذا واصلنا قراءة الأخطاء، فسنجد هذه الملاحظة المفيدة:
| |`Rectangle` cannot be formatted with the default formatter
| required by this formatting parameter
دعنا نجربها! سيبدو استدعاء ماكرو println! الآن كما يلي: println!("rect1 is {rect1:?}");. وضع المحدد :? داخل الأقواس المعقوفة يخبر println! أننا نريد استخدام تنسيق إخراج يسمى Debug. تُمكّننا السمة (Trait) Debug من طباعة Struct الخاص بنا بطريقة مفيدة للمطورين حتى نتمكن من رؤية قيمتها أثناء قيامنا بـ Debug الكود الخاص بنا.
قم بتجميع الكود بهذا التغيير. يا للأسف! ما زلنا نحصل على خطأ:
error[E0277]: `Rectangle` doesn't implement `Debug`
ولكن مرة أخرى، يعطينا المترجم ملاحظة مفيدة:
| required by this formatting parameter
|
يتضمن Rust وظيفة لطباعة معلومات Debug، ولكن يجب علينا الاشتراك صراحةً لجعل هذه الوظيفة متاحة لـ Struct الخاص بنا. للقيام بذلك، نضيف السمة الخارجية (Attribute) #[derive(Debug)] قبل تعريف Struct مباشرةً، كما هو موضح في القائمة 5-12.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {rect1:?}");
}الآن عندما نقوم بتشغيل البرنامج، لن نحصل على أي أخطاء، وسنرى الإخراج التالي:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle { width: 30, height: 50 }
جيد! إنه ليس أجمل إخراج، ولكنه يظهر قيم جميع Fields لهذا المثيل، مما سيساعد بالتأكيد أثناء Debug. عندما يكون لدينا Structs أكبر، من المفيد أن يكون لدينا إخراج أسهل قليلاً في القراءة؛ في هذه الحالات، يمكننا استخدام {:#?} بدلاً من {:?} في سلسلة println!. في هذا المثال، سيؤدي استخدام نمط {:#?} إلى إخراج ما يلي:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle {
width: 30,
height: 50,
}
هناك طريقة أخرى لطباعة قيمة باستخدام تنسيق Debug وهي استخدام الماكرو dbg!، الذي يأخذ Ownership لتعبير (على عكس println!، الذي يأخذ reference)، ويطبع الملف ورقم السطر الذي يحدث فيه استدعاء ماكرو dbg! في الكود الخاص بك جنبًا إلى جنب مع القيمة الناتجة لهذا التعبير، ويعيد Ownership للقيمة.
ملاحظة: يطبع استدعاء ماكرو
dbg!إلى مجرى وحدة التحكم للخطأ القياسي (stderr)، على عكسprintln!، الذي يطبع إلى مجرى وحدة التحكم للإخراج القياسي (stdout). سنتحدث أكثر عنstderrوstdoutفي قسم “Redirecting Errors to Standard Error” section in Chapter 12.
إليك مثال حيث نهتم بالقيمة التي يتم تعيينها لـ Field width، بالإضافة إلى قيمة Struct بأكمله في rect1:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let scale = 2;
let rect1 = Rectangle {
width: dbg!(30 * scale),
height: 50,
};
dbg!(&rect1);
}يمكننا وضع dbg! حول التعبير 30 * scale، ولأن dbg! يعيد Ownership لقيمة التعبير، سيحصل Field width على نفس القيمة كما لو لم يكن لدينا استدعاء dbg! هناك. لا نريد أن يأخذ dbg! Ownership لـ rect1، لذلك نستخدم reference لـ rect1 في الاستدعاء التالي. إليك كيف يبدو إخراج هذا المثال:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10:16] 30 * scale = 60
[src/main.rs:14:5] &rect1 = Rectangle {
width: 60,
height: 50,
}
يمكننا أن نرى أن الجزء الأول من الإخراج جاء من السطر 10 في src/main.rs حيث نقوم بـ Debug التعبير 30 * scale، وقيمته الناتجة هي 60 (تنسيق Debug المطبق للأعداد الصحيحة هو طباعة قيمتها فقط). يخرج استدعاء dbg! في السطر 14 من src/main.rs قيمة &rect1، وهي Struct Rectangle. يستخدم هذا الإخراج تنسيق Debug الجميل لنوع Rectangle. يمكن أن يكون ماكرو dbg! مفيدًا حقًا عندما تحاول معرفة ما يفعله الكود الخاص بك!
بالإضافة إلى Trait Debug، وفر Rust عددًا من Traits لنا لاستخدامها مع Attribute derive والتي يمكن أن تضيف سلوكًا مفيدًا لأنواعنا المخصصة. يتم سرد هذه Traits وسلوكياتها في Appendix C. سنغطي كيفية تطبيق هذه Traits بسلوك مخصص بالإضافة إلى كيفية إنشاء Traits الخاصة بك في الفصل 10. هناك أيضًا العديد من Attributes بخلاف derive؛ لمزيد من المعلومات، راجع the “Attributes” section of the Rust Reference.
الدالة area الخاصة بنا محددة للغاية: إنها تحسب مساحة المستطيلات فقط. سيكون من المفيد ربط هذا السلوك بشكل أوثق بـ Struct Rectangle الخاص بنا لأنه لن يعمل مع أي نوع آخر. دعنا نلقي نظرة على كيف يمكننا الاستمرار في Refactoring هذا الكود عن طريق تحويل الدالة area إلى دالة عضو (Method) area معرفة على نوع Rectangle الخاص بنا.
دوال الكائنات (Methods)
الـ Methods
الـ Methods تشبه الـ functions: نعلن عنها باستخدام الكلمة المفتاحية fn واسم، يمكن أن تحتوي على parameters وقيمة إرجاع (return value)، وتحتوي على بعض الكود الذي يتم تشغيله عند استدعاء الـ method من مكان آخر. على عكس الـ functions، يتم تعريف الـ methods ضمن سياق struct (أو enum أو trait object، والتي نغطيها في الفصل 6 و الفصل 18، على التوالي)، ويكون الـ parameter الأول لها دائمًا self، والذي يمثل مثيل الـ struct الذي يتم استدعاء الـ method عليه.
بناء جملة الـ Method (Method Syntax)
دعنا نغير دالة area التي تحتوي على مثيل Rectangle كـ parameter ونجعلها بدلاً من ذلك method area معرفًا على struct Rectangle، كما هو موضح في القائمة 5-13.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!(
"The area of the rectangle is {} square pixels.",
rect1.area()
);
}لتعريف الـ function ضمن سياق Rectangle، نبدأ كتلة impl (تنفيذ (implementation)) لـ Rectangle. كل شيء داخل كتلة impl هذه سيتم ربطه بنوع Rectangle. بعد ذلك، ننقل دالة area داخل الأقواس المعقوفة لـ impl ونغير الـ parameter الأول (والوحيد في هذه الحالة) ليكون self في الـ signature وفي كل مكان داخل الـ body. في main، حيث استدعينا دالة area ومررنا rect1 كوسيط (argument)، يمكننا بدلاً من ذلك استخدام بناء جملة الـ method (method syntax) لاستدعاء method area على مثيل Rectangle الخاص بنا. يأتي الـ method syntax بعد مثيل: نضيف نقطة متبوعة باسم الـ method، والأقواس، وأي arguments.
في الـ signature لـ area، نستخدم &self بدلاً من rectangle: &Rectangle. الـ &self هو في الواقع اختصار لـ self: &Self. ضمن كتلة impl، النوع Self هو اسم مستعار (alias) للنوع الذي تنطبق عليه كتلة impl. يجب أن تحتوي الـ methods على parameter يسمى self من النوع Self لـ parameter الأول، لذا تسمح لك Rust باختصار ذلك باستخدام الاسم self فقط في موضع الـ parameter الأول. لاحظ أننا ما زلنا بحاجة إلى استخدام & أمام اختصار self للإشارة إلى أن هذا الـ method يقترض (borrows) مثيل Self، تمامًا كما فعلنا في rectangle: &Rectangle. يمكن أن تأخذ الـ methods ملكية (ownership) الـ self، أو تقترض الـ self بشكل غير قابل للتغيير (immutably)، كما فعلنا هنا، أو تقترض الـ self بشكل قابل للتغيير (mutably)، تمامًا كما يمكنها أي parameter آخر.
اخترنا &self هنا لنفس السبب الذي استخدمنا به &Rectangle في إصدار الـ function: لا نريد أن نأخذ الـ ownership، ونريد فقط قراءة الـ data في الـ struct، وليس الكتابة عليها. إذا أردنا تغيير المثيل الذي استدعينا الـ method عليه كجزء مما يفعله الـ method، فسنستخدم &mut self كـ parameter الأول. من النادر أن يكون هناك method يأخذ الـ ownership للمثيل باستخدام self فقط كـ parameter الأول؛ تُستخدم هذه التقنية عادةً عندما يحول الـ method الـ self إلى شيء آخر وتريد منع الـ caller من استخدام المثيل الأصلي بعد التحويل.
السبب الرئيسي لاستخدام الـ methods بدلاً من الـ functions، بالإضافة إلى توفير method syntax وعدم الاضطرار إلى تكرار نوع self في الـ signature لكل method، هو التنظيم. لقد وضعنا كل الأشياء التي يمكننا القيام بها باستخدام مثيل نوع ما في كتلة impl واحدة بدلاً من جعل المستخدمين المستقبليين للكود الخاص بنا يبحثون عن إمكانيات Rectangle في أماكن مختلفة في الـ library التي نقدمها.
لاحظ أنه يمكننا اختيار إعطاء الـ method نفس اسم أحد حقول الـ struct. على سبيل المثال، يمكننا تعريف method على Rectangle يسمى أيضًا width:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn width(&self) -> bool {
self.width > 0
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
if rect1.width() {
println!("The rectangle has a nonzero width; it is {}", rect1.width);
}
}هنا، نختار جعل method width يُرجع true إذا كانت القيمة في حقل width للمثيل أكبر من 0 و false إذا كانت القيمة 0: يمكننا استخدام حقل داخل method يحمل نفس الاسم لأي غرض. في main، عندما نتبع rect1.width بأقواس، تعرف Rust أننا نعني method width. عندما لا نستخدم الأقواس، تعرف Rust أننا نعني حقل width.
في كثير من الأحيان، ولكن ليس دائمًا، عندما نعطي الـ method نفس اسم الحقل، فإننا نريده فقط أن يُرجع القيمة في الحقل ولا يفعل أي شيء آخر. تسمى الـ methods مثل هذه الـ Getters، ولا تطبقها Rust تلقائيًا لحقول الـ struct كما تفعل بعض اللغات الأخرى. الـ Getters مفيدة لأنه يمكنك جعل الحقل خاصًا (private) ولكن الـ method عامًا (public)، وبالتالي تمكين الوصول للقراءة فقط إلى هذا الحقل كجزء من واجهة برمجة التطبيقات العامة (public API) للنوع. سنناقش ما هو public و private وكيفية تعيين حقل أو method كـ public أو private في الفصل 7.
أين عامل التشغيل
->؟في C و C++، يتم استخدام عاملي تشغيل مختلفين لاستدعاء الـ methods: تستخدم
.إذا كنت تستدعي method على الـ object مباشرة وتستخدم->إذا كنت تستدعي الـ method على مؤشر (pointer) إلى الـ object وتحتاج إلى dereference الـ pointer أولاً. بعبارة أخرى، إذا كانobjectمؤشرًا، فإنobject->something()يشبه(*object).something().لا تحتوي Rust على ما يعادل عامل التشغيل
->؛ بدلاً من ذلك، تحتوي Rust على ميزة تسمى الإشارة وإلغاء الإشارة التلقائي (automatic referencing and dereferencing). يعد استدعاء الـ methods أحد الأماكن القليلة في Rust التي تتمتع بهذا السلوك.إليك كيفية عملها: عندما تستدعي method باستخدام
object.something()، تضيف Rust تلقائيًا&أو&mutأو*بحيث يتطابقobjectمع الـ signature للـ method. بعبارة أخرى، ما يلي متماثل:#![allow(unused)] fn main() { #[derive(Debug,Copy,Clone)] struct Point { x: f64, y: f64, } impl Point { fn distance(&self, other: &Point) -> f64 { let x_squared = f64::powi(other.x - self.x, 2); let y_squared = f64::powi(other.y - self.y, 2); f64::sqrt(x_squared + y_squared) } } let p1 = Point { x: 0.0, y: 0.0 }; let p2 = Point { x: 5.0, y: 6.5 }; p1.distance(&p2); (&p1).distance(&p2); }يبدو الأول أكثر نظافة. يعمل سلوك الـ referencing التلقائي هذا لأن الـ methods لها مستقبل واضح - نوع
self. بالنظر إلى مستقبل واسم الـ method، يمكن لـ Rust أن تحدد بشكل قاطع ما إذا كان الـ method يقرأ (&self)، أو يغير (&mut self)، أو يستهلك (self). حقيقة أن Rust تجعل الـ borrowing ضمنيًا لمستقبلات الـ method هي جزء كبير من جعل الـ ownership مريحًا (ergonomic) في الممارسة العملية.
الـ Methods ذات الـ Parameters الإضافية
دعنا نتدرب على استخدام الـ methods من خلال تطبيق method ثانٍ على struct Rectangle. هذه المرة نريد أن يأخذ مثيل Rectangle مثيلًا آخر من Rectangle ويُرجع true إذا كان Rectangle الثاني يمكن أن يتناسب تمامًا داخل self (الـ Rectangle الأول)؛ وإلا، يجب أن يُرجع false. أي، بمجرد أن نحدد method can_hold، نريد أن نكون قادرين على كتابة البرنامج الموضح في القائمة 5-14.
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}سيبدو الإخراج المتوقع كما يلي لأن كلا بعدي rect2 أصغر من أبعاد rect1، لكن rect3 أوسع من rect1:
Can rect1 hold rect2? true
Can rect1 hold rect3? false
نعلم أننا نريد تعريف method، لذلك سيكون ضمن كتلة impl Rectangle. سيكون اسم الـ method هو can_hold، وسيأخذ اقتراضًا غير قابل للتغيير (immutable borrow) لـ Rectangle آخر كـ parameter. يمكننا معرفة نوع الـ parameter من خلال النظر إلى الكود الذي يستدعي الـ method: rect1.can_hold(&rect2) يمرر &rect2، وهو immutable borrow لـ rect2، وهو مثيل لـ Rectangle. هذا منطقي لأننا نحتاج فقط إلى قراءة rect2 (بدلاً من الكتابة، مما يعني أننا سنحتاج إلى mutable borrow)، ونريد أن يحتفظ main بـ ownership لـ rect2 حتى نتمكن من استخدامه مرة أخرى بعد استدعاء method can_hold. ستكون القيمة المرجعة لـ can_hold عبارة عن Boolean، وسيقوم الـ implementation بالتحقق مما إذا كان عرض وارتفاع self أكبر من عرض وارتفاع الـ Rectangle الآخر، على التوالي. دعنا نضيف method can_hold الجديد إلى كتلة impl من القائمة 5-13، الموضحة في القائمة 5-15.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}عندما نقوم بتشغيل هذا الكود باستخدام دالة main في القائمة 5-14، سنحصل على الإخراج المطلوب. يمكن أن تأخذ الـ methods parameters متعددة نضيفها إلى الـ signature بعد parameter self، وتعمل هذه الـ parameters تمامًا مثل الـ parameters في الـ functions.
الـ Functions المرتبطة (Associated Functions)
تسمى جميع الـ functions المعرفة داخل كتلة impl الـ functions المرتبطة (associated functions) لأنها مرتبطة بالنوع المسمى بعد impl. يمكننا تعريف associated functions لا تحتوي على self كـ parameter الأول لها (وبالتالي فهي ليست methods) لأنها لا تحتاج إلى مثيل من النوع للعمل معه. لقد استخدمنا بالفعل function واحدًا من هذا القبيل: دالة String::from المعرفة على نوع String.
غالبًا ما تُستخدم الـ associated functions التي ليست methods لـ الـ constructors التي ستُرجع مثيلًا جديدًا من الـ struct. غالبًا ما تسمى هذه new، ولكن new ليس اسمًا خاصًا ولم يتم بناؤه في اللغة. على سبيل المثال، يمكننا اختيار توفير associated function يسمى square والذي سيكون له parameter بعد واحد ويستخدم ذلك كـ عرض وارتفاع، مما يسهل إنشاء Rectangle مربع بدلاً من الاضطرار إلى تحديد نفس القيمة مرتين:
Filename: src/main.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn square(size: u32) -> Self {
Self {
width: size,
height: size,
}
}
}
fn main() {
let sq = Rectangle::square(3);
}الكلمات المفتاحية Self في نوع الإرجاع وفي نص الـ function هي aliases للنوع الذي يظهر بعد الكلمة المفتاحية impl، وهو في هذه الحالة Rectangle.
لاستدعاء هذا الـ associated function، نستخدم بناء جملة :: مع اسم الـ struct؛ let sq = Rectangle::square(3); هو مثال. هذا الـ function يتم تسميته بواسطة الـ struct: يتم استخدام بناء جملة :: لكل من الـ associated functions والـ namespaces التي تم إنشاؤها بواسطة الـ modules. سنناقش الـ modules في الفصل 7.
كتل impl المتعددة
يُسمح لكل struct أن يكون له كتل impl متعددة. على سبيل المثال، القائمة 5-15 مكافئة للكود الموضح في القائمة 5-16، والذي يحتوي على كل method في كتلة impl خاصة به.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}لا يوجد سبب لفصل هذه الـ methods إلى كتل impl متعددة هنا، ولكن هذا بناء جملة صالح. سنرى حالة تكون فيها كتل impl المتعددة مفيدة في الفصل 10، حيث نناقش الـ generic types والـ traits.
ملخص
تتيح لك الـ Structs إنشاء أنواع مخصصة (custom types) ذات مغزى لـ domain الخاص بك. باستخدام الـ structs، يمكنك الاحتفاظ بأجزاء الـ data المرتبطة متصلة ببعضها البعض وتسمية كل جزء لجعل الكود الخاص بك واضحًا. في كتل impl، يمكنك تعريف الـ functions المرتبطة بنوعك، والـ methods هي نوع من الـ associated function التي تتيح لك تحديد السلوك الذي تتمتع به مثيلات الـ structs الخاصة بك.
لكن الـ structs ليست الطريقة الوحيدة التي يمكنك من خلالها إنشاء custom types: دعنا ننتقل إلى ميزة enum في Rust لإضافة أداة أخرى إلى صندوق أدواتك.
التعدادات ومطابقة الأنماط (Enums and Pattern Matching)
في هذا الفصل، سننظر في التعدادات (Enums)، والتي يشار إليها أيضاً باسم enums.
تسمح لك الـ Enums بتعريف نوع من خلال تعداد المتغيرات (variants) الممكنة له. أولاً، سنقوم بتعريف واستخدام enum لإظهار كيف يمكن لـ enum أن يشفر المعنى جنباً إلى جنب مع البيانات. بعد ذلك، سنستكشف enum مفيداً بشكل خاص، يسمى الخيار (Option)، والذي يعبر عن أن القيمة يمكن أن تكون إما شيئاً أو لا شيء. ثم، سننظر في كيفية جعل مطابقة الأنماط (pattern matching) في تعبير match من السهل تشغيل كود مختلف لقيم مختلفة من enum. أخيراً، سنغطي كيف أن بنية if let هي أسلوب برمجي (idiom) آخر مريح وموجز متاح للتعامل مع enums في الكود الخاص بك.
تعريف التعداد (Defining an Enum)
تعريف التعداد (Defining an Enum)
بينما تمنحك الهياكل (structs) طريقة لتجميع الحقول والبيانات ذات الصلة معاً، مثل Rectangle مع width و height الخاصين به، تمنحك التعدادات (enums) طريقة لقول أن القيمة هي واحدة من مجموعة محتملة من القيم. على سبيل المثال، قد نرغب في القول أن Rectangle هو واحد من مجموعة من الأشكال الممكنة التي تتضمن أيضاً Circle و Triangle. للقيام بذلك، يسمح لنا Rust بترميز هذه الاحتمالات كـ enum.
دعونا نلقي نظرة على موقف قد نرغب في التعبير عنه في الكود ونرى لماذا تعد enums مفيدة وأكثر ملاءمة من structs في هذه الحالة. لنفترض أننا بحاجة إلى العمل مع عناوين IP. حالياً، يتم استخدام معيارين رئيسيين لعناوين IP: الإصدار الرابع والإصدار السادس. نظراً لأن هذه هي الاحتمالات الوحيدة لعنوان IP التي سيواجهها برنامجنا، يمكننا تعداد (enumerate) جميع المتغيرات (variants) الممكنة، ومن هنا حصل التعداد على اسمه.
يمكن أن يكون أي عنوان IP إما عنواناً من الإصدار الرابع أو الإصدار السادس، ولكن ليس كلاهما في نفس الوقت. تجعل هذه الخاصية لعناوين IP هيكل بيانات enum مناسباً لأن قيمة enum لا يمكن أن تكون إلا واحدة من variants الخاصة بها. لا تزال عناوين الإصدار الرابع والإصدار السادس في الأساس عناوين IP، لذا يجب معاملتها على أنها من نفس النوع عندما يتعامل الكود مع المواقف التي تنطبق على أي نوع من عناوين IP.
يمكننا التعبير عن هذا المفهوم في الكود من خلال تعريف تعداد IpAddrKind وإدراج الأنواع الممكنة التي يمكن أن يكون عليها عنوان IP، وهي V4 و V6. هذه هي variants الخاصة بالتعداد:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}أصبح IpAddrKind الآن نوع بيانات مخصصاً يمكننا استخدامه في مكان آخر في الكود الخاص بنا.
قيم التعداد (Enum Values)
يمكننا إنشاء مثيلات (instances) لكل من المتغيرين في IpAddrKind كالتالي:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}لاحظ أن variants الخاصة بالتعداد تقع تحت مساحة الاسم (namespaced) الخاصة بمعرفه، ونستخدم نقطتين مزدوجتين للفصل بينهما. هذا مفيد لأن كلا القيمتين IpAddrKind::V4 و IpAddrKind::V6 هما الآن من نفس النوع: IpAddrKind. يمكننا بعد ذلك، على سبيل المثال، تعريف دالة تأخذ أي IpAddrKind:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}ويمكننا استدعاء هذه الدالة بأي من المتغيرين:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}استخدام enums له مزايا أكثر. بالتفكير أكثر في نوع عنوان IP الخاص بنا، في الوقت الحالي ليس لدينا طريقة لتخزين بيانات (data) عنوان IP الفعلية؛ نحن نعرف فقط نوعه. بالنظر إلى أنك تعلمت للتو عن structs في الفصل الخامس، فقد تميل إلى معالجة هذه المشكلة باستخدام structs كما هو موضح في القائمة 6-1.
fn main() {
enum IpAddrKind {
V4,
V6,
}
struct IpAddr {
kind: IpAddrKind,
address: String,
}
let home = IpAddr {
kind: IpAddrKind::V4,
address: String::from("127.0.0.1"),
};
let loopback = IpAddr {
kind: IpAddrKind::V6,
address: String::from("::1"),
};
}هنا، قمنا بتعريف struct باسم IpAddr يحتوي على حقلين: حقل kind من نوع IpAddrKind (التعداد الذي عرفناه سابقاً) وحقل address من نوع String. لدينا مثيلان من هذا struct. الأول هو home ، وله القيمة IpAddrKind::V4 كـ kind مع بيانات العنوان المرتبطة 127.0.0.1. المثيل الثاني هو loopback. وله المتغير الآخر من IpAddrKind كقيمة لـ kind ، وهو V6 ، وله العنوان ::1 مرتبطاً به. لقد استخدمنا struct لربط قيم kind و address معاً، لذا أصبح المتغير الآن مرتبطاً بالقيمة.
ومع ذلك، فإن تمثيل نفس المفهوم باستخدام enum فقط هو أكثر إيجازاً: بدلاً من enum داخل struct، يمكننا وضع البيانات مباشرة في كل enum variant. يقول هذا التعريف الجديد لتعداد IpAddr أن كلا المتغيرين V4 و V6 سيكون لهما قيم String مرتبطة:
fn main() {
enum IpAddr {
V4(String),
V6(String),
}
let home = IpAddr::V4(String::from("127.0.0.1"));
let loopback = IpAddr::V6(String::from("::1"));
}نحن نرفق البيانات بكل variant من التعداد مباشرة، لذا لا داعي لـ struct إضافي. هنا، من الأسهل أيضاً رؤية تفصيل آخر لكيفية عمل enums: يصبح اسم كل enum variant نقوم بتعريفه أيضاً دالة تنشئ instance من التعداد. أي أن IpAddr::V4() هو استدعاء دالة يأخذ وسيطاً (argument) من نوع String ويعيد instance من نوع IpAddr. نحصل تلقائياً على دالة البناء (constructor function) هذه نتيجة لتعريف التعداد.
هناك ميزة أخرى لاستخدام enum بدلاً من struct: يمكن أن يكون لكل variant أنواع وكميات مختلفة من البيانات المرتبطة. ستتكون عناوين IP من الإصدار الرابع دائماً من أربعة مكونات رقمية ستكون قيمها بين 0 و 255. إذا أردنا تخزين عناوين V4 كأربع قيم u8 ولكننا لا نزال نريد التعبير عن عناوين V6 كقيمة String واحدة، فلن نتمكن من ذلك باستخدام struct. تتعامل التعدادات مع هذه الحالة بسهولة:
fn main() {
enum IpAddr {
V4(u8, u8, u8, u8),
V6(String),
}
let home = IpAddr::V4(127, 0, 0, 1);
let loopback = IpAddr::V6(String::from("::1"));
}لقد عرضنا عدة طرق مختلفة لتعريف هياكل البيانات لتخزين عناوين IP من الإصدار الرابع والسادس. ومع ذلك، كما اتضح، فإن الرغبة في تخزين عناوين IP وترميز نوعها أمر شائع جداً لدرجة أن المكتبة القياسية لديها تعريف يمكننا استخدامه! دعونا نلقي نظرة على كيفية تعريف المكتبة القياسية لـ IpAddr. لديها نفس التعداد والمتغيرات التي عرفناها واستخدمناها، ولكنها تدمج بيانات العنوان داخل variants في شكل اثنين من structs المختلفين، واللذين يتم تعريفهما بشكل مختلف لكل variant:
#![allow(unused)]
fn main() {
struct Ipv4Addr {
// --snip--
}
struct Ipv6Addr {
// --snip--
}
enum IpAddr {
V4(Ipv4Addr),
V6(Ipv6Addr),
}
}يوضح هذا الكود أنه يمكنك وضع أي نوع من البيانات داخل enum variant: سلاسل نصية، أو أنواع رقمية، أو structs، على سبيل المثال. يمكنك حتى تضمين enum آخر! أيضاً، غالباً ما لا تكون أنواع المكتبة القياسية أكثر تعقيداً بكثير مما قد تبتكره أنت.
لاحظ أنه على الرغم من أن المكتبة القياسية تحتوي على تعريف لـ IpAddr ، إلا أنه لا يزال بإمكاننا إنشاء واستخدام تعريفنا الخاص دون تعارض لأننا لم نجلب تعريف المكتبة القياسية إلى نطاقنا (scope). سنتحدث أكثر عن جلب الأنواع إلى النطاق في الفصل السابع.
دعونا نلقي نظرة على مثال آخر لـ enum في القائمة 6-2: هذا المثال يحتوي على مجموعة واسعة من الأنواع المدمجة في variants الخاصة به.
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {}يحتوي هذا التعداد على أربعة variants بأنواع مختلفة:
Quit: ليس لديه أي بيانات مرتبطة به على الإطلاقMove: يحتوي على حقول مسمى، تماماً كما يفعل structWrite: يتضمنStringواحدةChangeColor: يتضمن ثلاث قيمi32
تعريف enum مع variants مثل تلك الموجودة في القائمة 6-2 يشبه تعريف أنواع مختلفة من تعريفات struct، باستثناء أن التعداد لا يستخدم الكلمة المفتاحية struct ويتم تجميع جميع variants معاً تحت نوع Message. يمكن لـ structs التالية الاحتفاظ بنفس البيانات التي تحتفظ بها enum variants السابقة:
struct QuitMessage; // unit struct
struct MoveMessage {
x: i32,
y: i32,
}
struct WriteMessage(String); // tuple struct
struct ChangeColorMessage(i32, i32, i32); // tuple struct
fn main() {}ولكن إذا استخدمنا structs المختلفة، والتي لكل منها نوعها الخاص، فلن نتمكن بسهولة من تعريف دالة لتأخذ أي نوع من هذه الرسائل كما فعلنا مع تعداد Message المعرف في القائمة 6-2، والذي هو نوع واحد.
هناك تشابه آخر بين enums و structs: تماماً كما يمكننا تعريف دوال (methods) على structs باستخدام impl ، يمكننا أيضاً تعريف methods على enums. إليك method يسمى call يمكننا تعريفه على تعداد Message الخاص بنا:
fn main() {
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
impl Message {
fn call(&self) {
// method body would be defined here
}
}
let m = Message::Write(String::from("hello"));
m.call();
}سيستخدم جسم الـ method الكلمة self للحصول على القيمة التي استدعينا الـ method عليها. في هذا المثال، أنشأنا متغيراً m له القيمة Message::Write(String::from("hello")) ، وهذا ما ستكون عليه self في جسم الـ method call عندما يتم تشغيل m.call().
دعونا نلقي نظرة على enum آخر في المكتبة القياسية شائع جداً ومفيد: Option.
تعداد Option (The Option Enum)
يستكشف هذا القسم دراسة حالة لـ Option ، وهو enum آخر معرف بواسطة المكتبة القياسية. يرمز النوع Option للسيناريو الشائع جداً الذي يمكن أن تكون فيه القيمة شيئاً ما، أو قد لا تكون شيئاً (nothing).
على سبيل المثال، إذا طلبت العنصر الأول في قائمة غير فارغة، فستحصل على قيمة. إذا طلبت العنصر الأول في قائمة فارغة، فلن تحصل على شيء. التعبير عن هذا المفهوم من حيث نظام الأنواع (type system) يعني أن المصرف (compiler) يمكنه التحقق مما إذا كنت قد تعاملت مع جميع الحالات التي يجب عليك التعامل معها؛ يمكن لهذه الوظيفة منع الأخطاء البرمجية الشائعة للغاية في لغات البرمجة الأخرى.
غالباً ما يتم التفكير في تصميم لغة البرمجة من حيث الميزات التي تضمنها، ولكن الميزات التي تستبعدها مهمة أيضاً. لا يحتوي Rust على ميزة القيمة الفارغة (null) الموجودة في العديد من اللغات الأخرى. Null هي قيمة تعني عدم وجود قيمة هناك. في اللغات التي تحتوي على null، يمكن أن تكون المتغيرات دائماً في واحدة من حالتين: null أو ليست null.
في عرضه التقديمي لعام 2009 بعنوان “مراجع Null: خطأ المليار دولار” ، قال توني هور، مخترع null، ما يلي:
أسميه خطأ المليار دولار الخاص بي. في ذلك الوقت، كنت أصمم أول نظام أنواع شامل للمراجع في لغة كائنية التوجه. كان هدفي هو ضمان أن يكون كل استخدام للمراجع آمناً تماماً، مع إجراء الفحص تلقائياً بواسطة المصرف. لكنني لم أستطع مقاومة إغراء وضع مرجع null، ببساطة لأنه كان من السهل جداً تنفيذه. أدى هذا إلى عدد لا يحصى من الأخطاء والثغرات الأمنية وانهيارات النظام، والتي تسببت على الأرجح في ألم وأضرار بقيمة مليار دولار في الأربعين سنة الماضية.
المشكلة في قيم null هي أنك إذا حاولت استخدام قيمة null كقيمة ليست null، فستحصل على خطأ من نوع ما. ولأن خاصية null أو ليست null هذه منتشرة، فمن السهل جداً ارتكاب هذا النوع من الخطأ.
ومع ذلك، فإن المفهوم الذي تحاول null التعبير عنه لا يزال مفهوماً مفيداً: null هي قيمة غير صالحة حالياً أو غائبة لسبب ما.
المشكلة ليست حقاً في المفهوم ولكن في التنفيذ المحدد. على هذا النحو، لا يحتوي Rust على nulls، ولكنه يحتوي على enum يمكنه ترميز مفهوم وجود القيمة أو غيابها. هذا التعداد هو Option<T> ، وهو معرف بواسطة المكتبة القياسية كما يلي:
#![allow(unused)]
fn main() {
enum Option<T> {
None,
Some(T),
}
}تعداد Option<T> مفيد جداً لدرجة أنه مضمن في التمهيد (prelude)؛ لست بحاجة إلى جلبه إلى النطاق صراحة. كما أن variants الخاصة به مضمنة في prelude: يمكنك استخدام Some و None مباشرة بدون بادئة Option::. لا يزال تعداد Option<T> مجرد enum عادي، ولا تزال Some(T) و None عبارة عن variants من نوع Option<T>.
بناء الجملة <T> هو ميزة في Rust لم نتحدث عنها بعد. إنه معلمة نوع عام (generic type parameter)، وسنغطي الأنواع العامة (generics) بمزيد من التفصيل في الفصل العاشر. في الوقت الحالي، كل ما تحتاج إلى معرفته هو أن <T> تعني أن المتغير Some من تعداد Option يمكنه الاحتفاظ بقطعة واحدة من البيانات من أي نوع، وأن كل نوع ملموس يتم استخدامه بدلاً من T يجعل نوع Option<T> الإجمالي نوعاً مختلفاً. إليك بعض الأمثلة على استخدام قيم Option للاحتفاظ بأنواع الأرقام وأنواع الأحرف:
#![allow(unused)]
fn main() {
(Content truncated due to size limit. Use line ranges to read remaining content)
}نوع some_number هو Option<i32>. ونوع some_char هو Option<char> ، وهو نوع مختلف. يمكن لـ Rust استنتاج (infer) هذه الأنواع لأننا حددنا قيمة داخل المتغير Some. بالنسبة لـ absent_number ، يتطلب Rust منا توضيح نوع Option الإجمالي: لا يمكن للمصرف استنتاج النوع الذي سيحتفظ به المتغير Some المقابل من خلال النظر فقط إلى قيمة None. هنا، نخبر Rust أننا نقصد أن يكون absent_number من نوع Option<i32>.
عندما يكون لدينا قيمة Some ، فإننا نعلم أن القيمة موجودة، وأن القيمة محتفظ بها داخل Some. عندما يكون لدينا قيمة None ، فإنها تعني بمعنى ما نفس الشيء مثل null: ليس لدينا قيمة صالحة. إذاً، لماذا يعد وجود Option<T> أفضل من وجود null؟
باختصار، لأن Option<T> و T (حيث يمكن أن يكون T أي نوع) هما نوعان مختلفان، فلن يسمح لنا المصرف باستخدام قيمة Option<T> كما لو كانت بالتأكيد قيمة صالحة. على سبيل المثال، لن يتم تصريف هذا الكود، لأنه يحاول إضافة i8 إلى Option<i8>:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
}إذا قمنا بتشغيل هذا الكود، فسنحصل على رسالة خطأ مثل هذه:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:5:17
|
5 | let sum = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
`&i8` implements `Add<i8>`
`&i8` implements `Add`
`i8` implements `Add<&i8>`
`i8` implements `Add`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` (bin "enums") due to 1 previous error
مثير للاهتمام! في الواقع، تعني رسالة الخطأ هذه أن Rust لا يفهم كيفية إضافة i8 و Option<i8> ، لأنهما نوعان مختلفان. عندما يكون لدينا قيمة من نوع مثل i8 في Rust، سيضمن المصرف أن لدينا دائماً قيمة صالحة. يمكننا المضي قدماً بثقة دون الحاجة إلى التحقق من null قبل استخدام تلك القيمة. فقط عندما يكون لدينا Option<i8> (أو أي نوع من القيم التي نعمل معها) يتعين علينا القلق بشأن احتمال عدم وجود قيمة، وسيضمن المصرف أننا نتعامل مع هذه الحالة قبل استخدام القيمة.
بمعنى آخر، يجب عليك تحويل Option<T> إلى T قبل أن تتمكن من إجراء عمليات T عليها. بشكل عام، يساعد هذا في اكتشاف واحدة من أكثر المشكلات شيوعاً مع null: افتراض أن شيئاً ما ليس null بينما هو كذلك في الواقع.
يساعدك القضاء على خطر الافتراض الخاطئ لقيمة ليست null على أن تكون أكثر ثقة في الكود الخاص بك. لكي يكون لديك قيمة يمكن أن تكون null، يجب عليك اختيار ذلك صراحة بجعل نوع تلك القيمة Option<T>. بعد ذلك، عندما تستخدم تلك القيمة، يطلب منك صراحة التعامل مع الحالة التي تكون فيها القيمة null. في كل مكان يكون فيه للقيمة نوع ليس Option<T> ، يمكنك بأمان افتراض أن القيمة ليست null. كان هذا قراراً تصميمياً متعمداً لـ Rust للحد من انتشار null وزيادة سلامة كود Rust.
إذاً، كيف تحصل على قيمة T من متغير Some عندما يكون لديك قيمة من نوع Option<T> حتى تتمكن من استخدام تلك القيمة؟ يحتوي تعداد Option<T> على عدد كبير من الدوال (methods) المفيدة في مجموعة متنوعة من المواقف؛ يمكنك الاطلاع عليها في توثيقها. سيصبح التعرف على methods الموجودة في Option<T> مفيداً للغاية في رحلتك مع Rust.
بشكل عام، من أجل استخدام قيمة Option<T> ، فأنت تريد كوداً يتعامل مع كل variant. تريد بعض الكود الذي سيتم تشغيله فقط عندما يكون لديك قيمة Some(T) ، ويسمح لهذا الكود باستخدام T الداخلية. وتريد تشغيل كود آخر فقط إذا كان لديك قيمة None ، وهذا الكود ليس لديه قيمة T متاحة. تعبير match هو بنية تدفق تحكم تقوم بذلك بالضبط عند استخدامها مع enums: سيقوم بتشغيل كود مختلف اعتماداً على variant التعداد الذي لديه، ويمكن لهذا الكود استخدام البيانات الموجودة داخل القيمة المطابقة.
بنية تدفق التحكم match
بنية التحكم في التدفق match (The match Control Flow Construct)
تمتلك Rust بنية تحكم في التدفق (control flow construct) قوية للغاية تسمى match تسمح لك بمقارنة قيمة مقابل سلسلة من الأنماط (patterns) ثم تنفيذ الكود بناءً على النمط الذي يتطابق. يمكن أن تتكون الأنماط من قيم حرفية (literal values)، وأسماء متغيرات، وعلامات بديلة (wildcards)، وأشياء أخرى كثيرة؛ يغطي الفصل 19 جميع الأنواع المختلفة من الأنماط وما تفعله. تأتي قوة match من التعبيرية في الأنماط وحقيقة أن المترجم (compiler) يؤكد أن جميع الحالات الممكنة قد تمت معالجتها.
فكر في تعبير match كما لو كان آلة لفرز العملات المعدنية: تنزلق العملات المعدنية على مسار به ثقوب ذات أحجام مختلفة، وتسقط كل عملة في أول ثقب تصادفه وتناسب حجمه. وبنفس الطريقة، تمر القيم عبر كل نمط في match وعند أول نمط “تناسبه” القيمة، تسقط القيمة في كتلة الكود المرتبطة بها لاستخدامها أثناء التنفيذ.
وبالحديث عن العملات المعدنية، دعنا نستخدمها كمثال باستخدام match! يمكننا كتابة دالة تأخذ عملة أمريكية غير معروفة، وبطريقة مماثلة لآلة العد، تحدد نوع العملة وترجع قيمتها بالسنتات، كما هو موضح في القائمة 6-3.
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
fn main() {}دعنا نحلل match في دالة value_in_cents. أولاً، ندرج الكلمة المفتاحية match متبوعة بتعبير، وهو في هذه الحالة القيمة coin. يبدو هذا مشابهًا جدًا للتعبير الشرطي المستخدم مع if ولكن هناك فرق كبير: مع if يجب أن يتم تقييم الشرط إلى قيمة منطقية (Boolean)، ولكن هنا يمكن أن يكون من أي نوع. نوع coin في هذا المثال هو التعداد Coin (enum) الذي عرفناه في السطر الأول.
بعد ذلك تأتي أذرع الـ match (match arms). يتكون الذراع (arm) من جزأين: نمط وكود. الذراع الأول هنا يحتوي على نمط هو القيمة Coin::Penny ثم عامل التشغيل => الذي يفصل بين النمط والكود المراد تشغيله. الكود في هذه الحالة هو مجرد القيمة 1. يتم فصل كل ذراع عن التالي بفاصلة.
عندما يتم تنفيذ تعبير match فإنه يقارن القيمة الناتجة مقابل نمط كل ذراع، بالترتيب. إذا تطابق النمط مع القيمة، يتم تنفيذ الكود المرتبط بهذا النمط. إذا لم يتطابق هذا النمط مع القيمة، يستمر التنفيذ إلى الذراع التالي، تمامًا كما هو الحال في آلة فرز العملات. يمكننا الحصول على عدد الأذرع الذي نحتاجه: في القائمة 6-3، يحتوي الـ match الخاص بنا على أربعة أذرع.
الكود المرتبط بكل ذراع هو تعبير (expression)، والقيمة الناتجة عن التعبير في الذراع المطابق هي القيمة التي يتم إرجاعها لتعبير match بالكامل.
عادة لا نستخدم الأقواس المتعرجة (curly brackets) إذا كان كود ذراع المطابقة قصيرًا، كما هو الحال في القائمة 6-3 حيث يرجع كل ذراع قيمة فقط. إذا كنت تريد تشغيل عدة أسطر من الكود في ذراع مطابقة، فيجب عليك استخدام الأقواس المتعرجة، وتكون الفاصلة التي تلي الذراع اختيارية حينها. على سبيل المثال، يقوم الكود التالي بطباعة “Lucky penny!” في كل مرة يتم فيها استدعاء الدالة بـ Coin::Penny ولكنه لا يزال يرجع القيمة الأخيرة في الكتلة، وهي 1:
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => {
println!("Lucky penny!");
1
}
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
fn main() {}الأنماط التي ترتبط بالقيم (Patterns That Bind to Values)
ميزة أخرى مفيدة لأذرع المطابقة هي أنها يمكن أن ترتبط بأجزاء القيم التي تطابق النمط. هذه هي الطريقة التي يمكننا بها استخراج القيم من متغيرات التعداد (enum variants).
كمثال، دعنا نغير أحد متغيرات التعداد لدينا ليحمل بيانات بداخله. من عام 1999 إلى عام 2008، سكّت الولايات المتحدة أرباع دولارات (quarters) بتصميمات مختلفة لكل ولاية من الولايات الخمسين على أحد الجانبين. لم تحصل أي عملات معدنية أخرى على تصميمات الولايات، لذا فإن أرباع الدولارات فقط هي التي تمتلك هذه القيمة الإضافية. يمكننا إضافة هذه المعلومات إلى الـ enum الخاص بنا عن طريق تغيير متغير Quarter ليشمل قيمة UsState مخزنة بداخله، وهو ما فعلناه في القائمة 6-4.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {}دعنا نتخيل أن صديقًا يحاول جمع كل أرباع الدولارات الخاصة بالولايات الخمسين. بينما نقوم بفرز فكتنا حسب نوع العملة، سننادي أيضًا باسم الولاية المرتبطة بكل ربع دولار بحيث إذا كانت ولاية لا يملكها صديقنا، فيمكنه إضافتها إلى مجموعته.
في تعبير المطابقة لهذا الكود، نضيف متغيرًا يسمى state إلى النمط الذي يطابق قيم المتغير Coin::Quarter. عندما يتطابق Coin::Quarter سيرتبط متغير state بقيمة ولاية ذلك الربع. بعد ذلك، يمكننا استخدام state في الكود الخاص بهذا الذراع، هكذا:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter(state) => {
println!("State quarter from {state:?}!");
25
}
}
}
fn main() {
value_in_cents(Coin::Quarter(UsState::Alaska));
}إذا استدعينا value_in_cents(Coin::Quarter(UsState::Alaska)) فستكون coin هي Coin::Quarter(UsState::Alaska). عندما نقارن تلك القيمة مع كل من أذرع المطابقة، لا يتطابق أي منها حتى نصل إلى Coin::Quarter(state). عند تلك النقطة، سيكون الارتباط لـ state هو القيمة UsState::Alaska. يمكننا بعد ذلك استخدام ذلك الارتباط في تعبير println! وبالتالي استخراج قيمة الولاية الداخلية من متغير تعداد Coin لـ Quarter.
نمط match مع Option<T> (The Option<T> match Pattern)
في القسم السابق، أردنا الحصول على قيمة T الداخلية من حالة Some عند استخدام Option<T>؛ يمكننا أيضًا التعامل مع Option<T> باستخدام match كما فعلنا مع تعداد Coin! بدلاً من مقارنة العملات، سنقارن متغيرات Option<T> ولكن تظل الطريقة التي يعمل بها تعبير match كما هي.
لنفترض أننا نريد كتابة دالة تأخذ Option<i32> وإذا كانت هناك قيمة بداخلها، تضيف 1 إلى تلك القيمة. إذا لم تكن هناك قيمة بداخلها، يجب أن ترجع الدالة القيمة None ولا تحاول إجراء أي عمليات.
هذه الدالة سهلة الكتابة للغاية بفضل match وستبدو مثل القائمة 6-5.
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}دعنا نفحص التنفيذ الأول لـ plus_one بمزيد من التفصيل. عندما نستدعي plus_one(five) سيكون للمتغير x في جسم plus_one القيمة Some(5). ثم نقارن ذلك مقابل كل ذراع مطابقة:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}القيمة Some(5) لا تطابق النمط None لذا نستمر إلى الذراع التالي:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}هل تطابق Some(5) النمط Some(i)؟ نعم! لدينا نفس المتغير. يرتبط i بالقيمة الموجودة في Some لذا يأخذ i القيمة 5. يتم بعد ذلك تنفيذ الكود في ذراع المطابقة، لذا نضيف 1 إلى قيمة i وننشئ قيمة Some جديدة مع مجموعنا 6 بداخلها.
الآن دعنا نفكر في الاستدعاء الثاني لـ plus_one في القائمة 6-5، حيث تكون x هي None. ندخل الـ match ونقارن بالذراع الأول:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}إنه يتطابق! لا توجد قيمة للإضافة إليها، لذا يتوقف البرنامج ويرجع القيمة None على الجانب الأيمن من =>. ولأن الذراع الأول تطابق، لا يتم مقارنة أي أذرع أخرى.
يعد الجمع بين match والتعدادات مفيدًا في العديد من المواقف. سترى هذا النمط كثيرًا في كود Rust: match مقابل تعداد، وربط متغير بالبيانات الموجودة بداخله، ثم تنفيذ الكود بناءً عليه. إنه أمر صعب قليلاً في البداية، ولكن بمجرد أن تعتاد عليه، ستتمنى لو كان لديك في جميع اللغات. إنه المفضل لدى المستخدمين باستمرار.
المطابقات شاملة (Matches Are Exhaustive)
هناك جانب آخر لـ match نحتاج إلى مناقشته: يجب أن تغطي أنماط الأذرع جميع الاحتمالات. فكر في هذا الإصدار من دالة plus_one الذي يحتوي على خطأ (bug) ولن يترجم:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}لم نعالج حالة None لذا سيتسبب هذا الكود في حدوث خطأ. لحسن الحظ، إنه خطأ تعرف Rust كيفية اكتشافه. إذا حاولنا ترجمة هذا الكود، فسنحصل على هذا الخطأ:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:593:1
::: /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:597:5
|
= note: not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` (bin "enums") due to 1 previous error
تعرف Rust أننا لم نغطِ كل حالة ممكنة بل وتعرف النمط الذي نسيناه! المطابقات في Rust شاملة (exhaustive): يجب أن نستنفد كل الاحتمالات الأخيرة لكي يكون الكود صالحًا. خاصة في حالة Option<T> عندما تمنعنا Rust من نسيان التعامل صراحة مع حالة None فإنها تحمينا من افتراض أن لدينا قيمة بينما قد يكون لدينا null، مما يجعل “خطأ المليار دولار” الذي نوقش سابقًا مستحيلاً.
أنماط الالتقاط الشامل والعلامة البديلة _ (Catch-All Patterns and the _ Placeholder)
باستخدام التعدادات، يمكننا أيضًا اتخاذ إجراءات خاصة لعدد قليل من القيم المعينة، ولكن لجميع القيم الأخرى نتخذ إجراءً افتراضيًا واحدًا. تخيل أننا ننفذ لعبة حيث إذا حصلت على 3 في رمية نرد، فلا يتحرك لاعبك ولكنه يحصل بدلاً من ذلك على قبعة جديدة فاخرة. إذا حصلت على 7، يفقد لاعبك قبعة فاخرة. لجميع القيم الأخرى، يتحرك لاعبك بهذا العدد من المساحات على لوحة اللعبة. إليك match ينفذ هذا المنطق، مع كتابة نتيجة رمية النرد بشكل ثابت بدلاً من قيمة عشوائية، وتمثيل كل المنطق الآخر بدوال بدون أجسام لأن تنفيذها الفعلي خارج نطاق هذا المثال:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
other => move_player(other),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn move_player(num_spaces: u8) {}
}بالنسبة لأول ذراعين، الأنماط هي القيم الحرفية 3 و 7. بالنسبة للذراع الأخير الذي يغطي كل قيمة ممكنة أخرى، النمط هو المتغير الذي اخترنا تسميته other. الكود الذي يعمل لذراع other يستخدم المتغير عن طريق تمريره إلى دالة move_player.
يترجم هذا الكود، على الرغم من أننا لم ندرج جميع القيم الممكنة التي يمكن أن يمتلكها u8 لأن النمط الأخير سيطابق جميع القيم غير المدرجة بشكل محدد. يلبي نمط الالتقاط الشامل (catch-all pattern) هذا متطلب أن يكون match شاملاً. لاحظ أنه يجب علينا وضع ذراع الالتقاط الشامل في النهاية لأن الأنماط يتم تقييمها بالترتيب. إذا وضعنا ذراع الالتقاط الشامل في وقت سابق، فلن تعمل الأذرع الأخرى أبدًا، لذا ستحذرنا Rust إذا أضفنا أذرعًا بعد الالتقاط الشامل!
تمتلك Rust أيضًا نمطًا يمكننا استخدامه عندما نريد التقاطًا شاملاً ولكن لا نريد استخدام القيمة في نمط الالتقاط الشامل: _ هو نمط خاص يطابق أي قيمة ولا يرتبط بتلك القيمة. هذا يخبر Rust أننا لن نستخدم القيمة، لذا لن تحذرنا Rust بشأن متغير غير مستخدم.
دعنا نغير قواعد اللعبة: الآن، إذا حصلت على أي شيء آخر غير 3 أو 7، يجب عليك الرمي مرة أخرى. لم نعد بحاجة إلى استخدام قيمة الالتقاط الشامل، لذا يمكننا تغيير كودنا لاستخدام _ بدلاً من المتغير المسمى other:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => reroll(),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn reroll() {}
}يلبي هذا المثال أيضًا متطلب الشمولية لأننا نتجاهل صراحة جميع القيم الأخرى في الذراع الأخير؛ لم ننسَ أي شيء.
أخيرًا، سنغير قواعد اللعبة مرة أخرى بحيث لا يحدث أي شيء آخر في دورك إذا حصلت على أي شيء آخر غير 3 أو 7. يمكننا التعبير عن ذلك باستخدام قيمة الوحدة (unit value) (نوع المجموعة الفارغة الذي ذكرناه في قسم “نوع المجموعة”) ككود يتماشى مع ذراع _:
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => (),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
}هنا، نخبر Rust صراحة أننا لن نستخدم أي قيمة أخرى لا تطابق نمطًا في ذراع سابق، ولا نريد تشغيل أي كود في هذه الحالة.
هناك المزيد حول الأنماط والمطابقة سنغطيه في الفصل 19. في الوقت الحالي، سننتقل إلى بناء جملة if let والذي يمكن أن يكون مفيدًا في المواقف التي يكون فيها تعبير match مطولاً قليلاً.
تدفق التحكم الموجز باستخدام if let و let...else
التحكم في التدفق المختصر باستخدام if let و let...else
تتيح لك صياغة if let دمج if و let في طريقة أقل إسهابًا للتعامل مع القيم التي تطابق نمطًا واحدًا (pattern) مع تجاهل الباقي. لننظر إلى البرنامج في القائمة 6-6 الذي يطابق قيمة Option<u8> في المتغير config_max ولكنه يريد فقط تنفيذ الكود إذا كانت القيمة هي البديل (variant) Some.
fn main() {
let config_max = Some(3u8);
match config_max {
Some(max) => println!("The maximum is configured to be {max}"),
_ => (),
}
}إذا كانت القيمة هي Some، فإننا نطبع القيمة في variant Some عن طريق ربط (binding) القيمة بالمتغير max في pattern. لا نريد أن نفعل أي شيء بقيمة None. لإرضاء تعبير المطابقة (match expression)، يجب علينا إضافة _ => () بعد معالجة variant واحد فقط، وهو كود نمطي مزعج (annoying boilerplate code) للإضافة.
بدلاً من ذلك، يمكننا كتابة هذا بطريقة أقصر باستخدام if let. يتصرف الكود التالي بنفس طريقة match في القائمة 6-6:
fn main() {
let config_max = Some(3u8);
if let Some(max) = config_max {
println!("The maximum is configured to be {max}");
}
}تأخذ صياغة if let نمطًا (pattern) وتعبيرًا (expression) مفصولين بعلامة يساوي. يعمل بنفس طريقة match، حيث يتم إعطاء expression إلى match و pattern هو ذراعه الأول (first arm). في هذه الحالة، pattern هو Some(max)، ويرتبط max بالقيمة داخل Some. يمكننا بعد ذلك استخدام max في جسم كتلة if let (if let block) بنفس الطريقة التي استخدمنا بها max في ذراع match المقابل. يتم تشغيل الكود في if let block فقط إذا كانت القيمة تطابق pattern.
استخدام if let يعني كتابة أقل، مسافة بادئة (indentation) أقل، و boilerplate code أقل. ومع ذلك، فإنك تفقد التحقق الشامل (exhaustive checking) الذي يفرضه match والذي يضمن أنك لا تنسى التعامل مع أي حالات. يعتمد الاختيار بين match و if let على ما تفعله في حالتك الخاصة وما إذا كانت اكتساب الإيجاز (conciseness) مقايضة مناسبة لفقدان exhaustive checking.
بمعنى آخر، يمكنك التفكير في if let على أنه سكر صياغي (syntax sugar) لـ match يقوم بتشغيل الكود عندما تطابق القيمة pattern واحدًا ثم تتجاهل جميع القيم الأخرى.
يمكننا تضمين else مع if let. كتلة الكود التي تأتي مع else هي نفسها كتلة الكود التي ستأتي مع حالة _ في match expression المكافئ لـ if let و else. تذكر تعريف التعداد (enum) Coin في القائمة 6-4، حيث احتوى البديل Quarter أيضًا على قيمة UsState. إذا أردنا عد جميع العملات غير الربعية التي نراها مع الإعلان أيضًا عن حالة الأرباع، يمكننا القيام بذلك باستخدام match expression، مثل هذا:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {
let coin = Coin::Penny;
let mut count = 0;
match coin {
Coin::Quarter(state) => println!("State quarter from {state:?}!"),
_ => count += 1,
}
}أو يمكننا استخدام تعبير if let و else، مثل هذا:
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {
let coin = Coin::Penny;
let mut count = 0;
if let Coin::Quarter(state) = coin {
println!("State quarter from {state:?}!");
} else {
count += 1;
}
}البقاء على “المسار السعيد” (Happy Path) باستخدام let...else
النمط الشائع هو إجراء بعض العمليات الحسابية عندما تكون القيمة موجودة وإرجاع قيمة افتراضية (default value) بخلاف ذلك. استمرارًا في مثالنا للعملات المعدنية بقيمة UsState، إذا أردنا أن نقول شيئًا مضحكًا اعتمادًا على عمر الولاية على الربع، فقد نقدم طريقة (method) على UsState للتحقق من عمر الولاية، مثل هذا:
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
if let Coin::Quarter(state) = coin {
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}بعد ذلك، قد نستخدم if let للمطابقة على نوع العملة، مع تقديم متغير state داخل جسم الشرط (condition)، كما في القائمة 6-7.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
if let Coin::Quarter(state) = coin {
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}هذا ينجز المهمة، ولكنه دفع العمل إلى جسم عبارة if let، وإذا كان العمل الذي يتعين القيام به أكثر تعقيدًا، فقد يكون من الصعب متابعة كيفية ارتباط الفروع (branches) ذات المستوى الأعلى بالضبط. يمكننا أيضًا الاستفادة من حقيقة أن التعبيرات (expressions) تنتج قيمة إما لإنتاج state من if let أو للعودة مبكرًا (return early)، كما في القائمة 6-8. (يمكنك القيام بشيء مشابه باستخدام match أيضًا.)
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
let state = if let Coin::Quarter(state) = coin {
state
} else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}هذا مزعج بعض الشيء للمتابعة بطريقته الخاصة، على الرغم من ذلك! ينتج أحد فروع if let قيمة، والآخر يعود من الدالة (function) بالكامل.
لجعل هذا النمط الشائع أسهل في التعبير، تحتوي Rust على let...else. تأخذ صياغة let...else نمطًا (pattern) على الجانب الأيسر وتعبيرًا (expression) على الجانب الأيمن، مشابهًا جدًا لـ if let، ولكن ليس لديها فرع if، بل فرع else فقط. إذا طابق pattern، فسيربط القيمة من pattern في النطاق الخارجي (outer scope). إذا لم يطابق pattern، فسيتدفق البرنامج إلى ذراع else، والذي يجب أن يعود من function.
في القائمة 6-9، يمكنك أن ترى كيف تبدو القائمة 6-8 عند استخدام let...else بدلاً من if let.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
let Coin::Quarter(state) = coin else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}لاحظ أنه يبقى على “المسار السعيد” (happy path) في الجسم الرئيسي لـ function بهذه الطريقة، دون أن يكون لديه تدفق تحكم (control flow) مختلف بشكل كبير لفرعين بالطريقة التي فعلها if let.
إذا كان لديك موقف يحتوي فيه برنامجك على منطق (logic) مطول جدًا للتعبير عنه باستخدام match، فتذكر أن if let و let...else موجودان في صندوق أدوات Rust الخاص بك أيضًا.
ملخص (Summary)
لقد غطينا الآن كيفية استخدام التعدادات (enums) لإنشاء أنواع مخصصة (custom types) يمكن أن تكون واحدة من مجموعة من القيم المعددة. لقد أوضحنا كيف يساعدك نوع Option<T> في المكتبة القياسية (standard library) على استخدام نظام الأنواع (type system) لمنع الأخطاء. عندما تحتوي قيم enum على بيانات بداخلها، يمكنك استخدام match أو if let لاستخراج واستخدام تلك القيم، اعتمادًا على عدد الحالات التي تحتاج إلى التعامل معها.
يمكن لبرامج Rust الخاصة بك الآن التعبير عن المفاهيم في مجالك باستخدام الهياكل (structs) و enums. يضمن إنشاء custom types لاستخدامها في واجهة برمجة التطبيقات (API) الخاصة بك سلامة الأنواع (type safety): سيضمن المترجم (compiler) أن الدوال (functions) الخاصة بك تحصل فقط على قيم من النوع الذي تتوقعه كل دالة.
من أجل توفير API جيد التنظيم لمستخدميك يكون سهل الاستخدام ولا يكشف إلا عما سيحتاجه المستخدمون بالضبط، دعنا ننتقل الآن إلى وحدات Rust (Rust’s modules).
الحزم، والـ Crates، والوحدات (Packages, Crates, and Modules)
بينما تكتب برامج كبيرة، سيصبح تنظيم الكود الخاص بك مهماً بشكل متزايد. من خلال تجميع الوظائف ذات الصلة وفصل الكود ذو الميزات المتميزة، ستوضح مكان العثور على الكود الذي ينفذ ميزة معينة ومكان الذهاب لتغيير كيفية عمل الميزة.
البرامج التي كتبناها حتى الآن كانت في “وحدة” (Module) واحدة في ملف واحد. مع نمو المشروع، يجب عليك تنظيم الكود عن طريق تقسيمه إلى عدة Modules ثم إلى عدة ملفات. يمكن أن تحتوي “الحزمة” (Package) على عدة “صناديق ثنائية” (Binary Crates) واختيارياً “صندوق مكتبة” (Library Crate) واحد. مع نمو الـ Package، يمكنك استخراج أجزاء في Crates منفصلة تصبح تبعيات خارجية. يغطي هذا الفصل كل هذه التقنيات. بالنسبة للمشاريع الكبيرة جداً التي تتكون من مجموعة من الـ Packages المترابطة التي تتطور معاً، يوفر Cargo “مساحات عمل” (Workspaces)، والتي سنغطيها في قسم “مساحات عمل Cargo” في الفصل 14.
سنناقش أيضاً تغليف تفاصيل التنفيذ، مما يتيح لك إعادة استخدام الكود على مستوى أعلى: بمجرد تنفيذ عملية ما، يمكن للكود الآخر استدعاء الكود الخاص بك عبر واجهته العامة دون الحاجة إلى معرفة كيفية عمل التنفيذ. تحدد الطريقة التي تكتب بها الكود الأجزاء العامة ليستخدمها الكود الآخر والأجزاء التي تعد تفاصيل تنفيذ خاصة تحتفظ بالحق في تغييرها. هذه طريقة أخرى للحد من كمية التفاصيل التي يجب أن تبقيها في ذهنك.
المفهوم ذو الصلة هو “النطاق” (Scope): السياق المتداخل الذي يتم فيه كتابة الكود يحتوي على مجموعة من الأسماء المعرفة على أنها “داخل النطاق” (In Scope). عند قراءة الكود وكتابته وتجميعه، يحتاج المبرمجون والمترجمون (Compilers) إلى معرفة ما إذا كان اسم معين في بقعة معينة يشير إلى متغير، أو دالة، أو هيكل (Struct)، أو تعداد (Enum)، أو Module، أو ثابت، أو عنصر آخر وماذا يعني ذلك العنصر. يمكنك إنشاء Scopes وتغيير الأسماء الموجودة داخل الـ Scope أو خارجه. لا يمكنك الحصول على عنصرين بنفس الاسم في نفس الـ Scope؛ تتوفر أدوات لحل تعارض الأسماء.
تمتلك Rust عدداً من الميزات التي تتيح لك إدارة تنظيم الكود الخاص بك، بما في ذلك التفاصيل التي يتم كشفها، والتفاصيل الخاصة، والأسماء الموجودة في كل Scope في برامجك. هذه الميزات، التي يشار إليها أحياناً مجتمعة باسم “نظام الوحدات” (Module System)، تشمل:
- الحزم (Packages): ميزة في Cargo تتيح لك بناء واختبار ومشاركة الـ Crates.
- الصناديق (Crates): شجرة من الـ Modules تنتج مكتبة أو ملفاً قابلاً للتنفيذ.
- الوحدات و use (Modules and use): تتيح لك التحكم في التنظيم، والـ Scope، وخصوصية المسارات.
- المسارات (Paths): طريقة لتسمية عنصر، مثل Struct، أو دالة، أو Module.
في هذا الفصل، سنغطي كل هذه الميزات، ونناقش كيفية تفاعلها، ونشرح كيفية استخدامها لإدارة الـ Scope. بنهاية الفصل، يجب أن يكون لديك فهم قوي للـ Module System وأن تكون قادراً على التعامل مع الـ Scopes كالمحترفين!
الحزم والكرات (Packages and Crates)
الحزم والصناديق (Packages and Crates)
الأجزاء الأولى من نظام الوحدات (Module System) التي سنغطيها هي الحزم (Packages) والصناديق (Crates).
الـ “صندوق” (Crate) هو أصغر كمية من الكود يأخذها مترجم Rust (Compiler) في الاعتبار في المرة الواحدة. حتى لو قمت بتشغيل rustc بدلاً من cargo ومررت ملف كود مصدري واحد (كما فعلنا سابقاً في قسم “أساسيات برنامج Rust” في الفصل 1)، فإن الـ Compiler يعتبر ذلك الملف بمثابة Crate. يمكن أن تحتوي الـ Crates على وحدات (Modules)، وقد يتم تعريف الـ Modules في ملفات أخرى يتم تجميعها مع الـ Crate، كما سنرى في الأقسام القادمة.
يمكن أن يأتي الـ Crate في أحد شكلين: “صندوق ثنائي” (Binary Crate) أو “صندوق مكتبة” (Library Crate). الـ “Binary Crates” هي برامج يمكنك تجميعها إلى ملف قابل للتنفيذ يمكنك تشغيله، مثل برنامج سطر أوامر أو خادم. يجب أن يحتوي كل منها على دالة تسمى main تحدد ما يحدث عند تشغيل الملف القابل للتنفيذ. جميع الـ Crates التي أنشأناها حتى الآن كانت Binary Crates.
الـ “Library Crates” لا تحتوي على دالة main ولا يتم تجميعها إلى ملف قابل للتنفيذ. بدلاً من ذلك، فهي تحدد وظائف مخصصة للمشاركة مع مشاريع متعددة. على سبيل المثال، يوفر Crate الـ rand الذي استخدمناه في الفصل 2 وظائف تولد أرقاماً عشوائية. في معظم الأوقات عندما يقول مبرمجو Rust (Rustaceans) كلمة “Crate”، فإنهم يقصدون Library Crate، ويستخدمون كلمة “Crate” بالتبادل مع المفهوم البرمجي العام لـ “المكتبة” (Library).
“جذر الصندوق” (Crate Root) هو ملف مصدري يبدأ منه الـ Compiler ويشكل الـ Module الجذر للـ Crate الخاصة بك (سنشرح الـ Modules بعمق في قسم “التحكم في النطاق والخصوصية باستخدام الوحدات”).
الـ “حزمة” (Package) هي حزمة من Crate واحد أو أكثر توفر مجموعة من الوظائف. تحتوي الـ Package على ملف Cargo.toml يصف كيفية بناء تلك الـ Crates. في الواقع، Cargo هو Package يحتوي على Binary Crate لأداة سطر الأوامر التي كنت تستخدمها لبناء الكود الخاص بك. تحتوي Package الـ Cargo أيضاً على Library Crate يعتمد عليه الـ Binary Crate. يمكن للمشاريع الأخرى الاعتماد على Library Crate الخاص بـ Cargo لاستخدام نفس المنطق الذي تستخدمه أداة سطر أوامر Cargo.
يمكن أن تحتوي الـ Package على أي عدد تريده من الـ Binary Crates، ولكن على الأكثر Library Crate واحد فقط. يجب أن تحتوي الـ Package على Crate واحد على الأقل، سواء كان ذلك Library Crate أو Binary Crate.
دعنا نستعرض ما يحدث عندما ننشئ Package. أولاً، ندخل الأمر cargo new my-project:
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
بعد تشغيل cargo new my-project نستخدم ls لنرى ما ينشئه Cargo. في دليل my-project يوجد ملف Cargo.toml مما يمنحنا Package. يوجد أيضاً دليل src يحتوي على main.rs. افتح Cargo.toml في محرر النصوص الخاص بك ولاحظ أنه لا يوجد ذكر لـ src/main.rs. يتبع Cargo اتفاقاً (Convention) مفاده أن src/main.rs هو الـ Crate Root لـ Binary Crate يحمل نفس اسم الـ Package. وبالمثل، يعرف Cargo أنه إذا كان دليل الـ Package يحتوي على src/lib.rs فإن الـ Package تحتوي على Library Crate بنفس اسم الـ Package، ويكون src/lib.rs هو الـ Crate Root الخاص به. يمرر Cargo ملفات الـ Crate Root إلى rustc لبناء المكتبة أو الملف الثنائي.
هنا، لدينا Package تحتوي فقط على src/main.rs مما يعني أنها تحتوي فقط على Binary Crate يسمى my-project. إذا كانت الـ Package تحتوي على src/main.rs و src/lib.rs فإنها تحتوي على صندوقين: Binary و Library، وكلاهما بنفس اسم الـ Package. يمكن أن تحتوي الـ Package على عدة Binary Crates عن طريق وضع الملفات في دليل src/bin: سيكون كل ملف عبارة عن Binary Crate منفصل.
التحكم في النطاق والخصوصية باستخدام الوحدات (Modules)
التحكم في النطاق والخصوصية باستخدام الوحدات البرمجية
في هذا القسم، سنتحدث عن الوحدات البرمجية (modules) وأجزاء أخرى من نظام الوحدات البرمجية (module system)، وتحديداً المسارات (paths)، التي تسمح لك بتسمية العناصر؛ والكلمة المفتاحية use التي تجلب المسار (path) إلى النطاق (scope)؛ والكلمة المفتاحية pub لجعل العناصر عامة (public). سنناقش أيضاً الكلمة المفتاحية as والطرود الخارجية (external packages) وعامل الشمول (glob operator).
ورقة غش الوحدات البرمجية
قبل أن ننتقل إلى تفاصيل modules و paths، نقدم هنا مرجعاً سريعاً حول كيفية عمل modules و paths والكلمة المفتاحية use والكلمة المفتاحية pub في المترجم (compiler)، وكيف ينظم معظم المطورين كودهم. سنمر بأمثلة على كل من هذه القواعد طوال هذا الفصل، ولكن هذا مكان رائع للرجوع إليه كتذكير بكيفية عمل modules.
- البدء من جذر الكريت (crate root): عند تصريف (compiling) كريت (crate)، يبحث compiler أولاً في ملف crate root (عادةً ما يكون src/lib.rs لكريت المكتبة و src/main.rs لكريت ثنائي) عن كود لتصريفه.
- التصريح عن الوحدات البرمجية (Declaring modules): في ملف crate root، يمكنك التصريح عن modules جديدة؛ لنفترض أنك صرحت عن وحدة “garden” باستخدام
mod garden;. سيبحث compiler عن كود الوحدة في هذه الأماكن:- مضمناً (Inline)، داخل أقواس متعرجة تحل محل الفاصلة المنقوطة التي تلي
mod garden - في الملف src/garden.rs
- في الملف src/garden/mod.rs
- مضمناً (Inline)، داخل أقواس متعرجة تحل محل الفاصلة المنقوطة التي تلي
- التصريح عن الوحدات الفرعية (Declaring submodules): في أي ملف آخر غير crate root، يمكنك التصريح عن وحدات فرعية (submodules). على سبيل المثال، قد تصرح عن
mod vegetables;في src/garden.rs. سيبحث compiler عن كود submodule داخل المجلد المسمى باسم الوحدة الأب (parent module) في هذه الأماكن:- مضمناً، مباشرة بعد
mod vegetablesداخل أقواس متعرجة بدلاً من الفاصلة المنقوطة - في الملف src/garden/vegetables.rs
- في الملف src/garden/vegetables/mod.rs
- مضمناً، مباشرة بعد
- المسارات إلى الكود في الوحدات البرمجية: بمجرد أن تصبح module جزءاً من crate الخاص بك، يمكنك الرجوع إلى الكود في تلك module من أي مكان آخر في نفس crate، طالما تسمح قواعد الخصوصية (privacy rules) بذلك، باستخدام path المؤدي إلى الكود. على سبيل المثال، سيتم العثور على النوع
Asparagusفي وحدة vegetables الخاصة بـ garden فيcrate::garden::vegetables::Asparagus. - خاص مقابل عام (Private vs. public): الكود داخل module يكون خاصاً (private) عن وحداته الأب بشكل افتراضي. لجعل module عامة (public)، صرح عنها باستخدام
pub modبدلاً منmod. لجعل العناصر داخل public module عامة أيضاً، استخدمpubقبل التصريح عنها. - الكلمة المفتاحية
use: داخل scope، تنشئ الكلمة المفتاحيةuseاختصارات للعناصر لتقليل تكرار paths الطويلة. في أي scope يمكنه الرجوع إلىcrate::garden::vegetables::Asparagusيمكنك إنشاء اختصار باستخدامuse crate::garden::vegetables::Asparagus;ومنذ ذلك الحين فصاعداً ستحتاج فقط إلى كتابةAsparagusلاستخدام ذلك النوع في scope.
هنا، ننشئ binary crate باسم backyard يوضح هذه القواعد. يحتوي مجلد crate، المسمى أيضاً backyard، على هذه الملفات والمجلدات:
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden
│ └── vegetables.rs
├── garden.rs
└── main.rs
ملف crate root في هذه الحالة هو src/main.rs، ويحتوي على:
use crate::garden::vegetables::Asparagus;
pub mod garden;
fn main() {
let plant = Asparagus {};
println!("I'm growing {plant:?}!");
}يخبر سطر pub mod garden; المترجم بتضمين الكود الذي يجده في src/garden.rs، وهو:
pub mod vegetables;هنا، تعني pub mod vegetables; أن الكود في src/garden/vegetables.rs مضمن أيضاً. هذا الكود هو:
#[derive(Debug)]
pub struct Asparagus {}الآن دعونا ندخل في تفاصيل هذه القواعد ونستعرضها عملياً!
تجميع الكود ذو الصلة في وحدات برمجية
تسمح لنا Modules بتنظيم الكود داخل crate لسهولة القراءة وإعادة الاستخدام. تسمح لنا modules أيضاً بالتحكم في خصوصية العناصر لأن الكود داخل module يكون private بشكل افتراضي. العناصر الخاصة هي تفاصيل تنفيذ داخلية (internal implementation details) غير متاحة للاستخدام الخارجي. يمكننا اختيار جعل modules والعناصر داخلها public، مما يكشفها للسماح للكود الخارجي باستخدامها والاعتماد عليها.
كمثال، لنكتب library crate يوفر وظائف مطعم. سنحدد تواقيع الدوال (function signatures) ولكن سنترك أجسامها فارغة للتركيز على تنظيم الكود بدلاً من تنفيذ (implementation) المطعم.
في صناعة المطاعم، يشار إلى بعض أجزاء المطعم باسم “واجهة المطعم” (front of house) وأجزاء أخرى باسم “خلفية المطعم” (back of house). Front of house هو المكان الذي يتواجد فيه الزبائن؛ وهذا يشمل المكان الذي يجلس فيه المضيفون الزبائن، ويأخذ فيه النادلون الطلبات والمدفوعات، ويقوم فيه السقاة بإعداد المشروبات. Back of house هو المكان الذي يعمل فيه الطهاة في المطبخ، ويقوم فيه غاسلو الأطباق بالتنظيف، ويقوم فيه المديرون بالعمل الإداري.
لهيكلة crate الخاص بنا بهذه الطريقة، يمكننا تنظيم دواله في modules متداخلة. أنشئ مكتبة جديدة باسم restaurant عن طريق تشغيل cargo new restaurant --lib. ثم أدخل الكود الموجود في القائمة 7-1 في src/lib.rs لتعريف بعض modules وتواقيع الدوال؛ هذا الكود هو قسم front of house.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}نحدد module باستخدام الكلمة المفتاحية mod متبوعة باسم module (في هذه الحالة، front_of_house). ثم يوضع جسم module داخل أقواس متعرجة. داخل modules، يمكننا وضع modules أخرى، كما في هذه الحالة مع الوحدتين hosting و serving. يمكن أن تحتوي modules أيضاً على تعريفات لعناصر أخرى، مثل الهياكل (structs) والتعدادات (enums) والثوابت (constants) والسمات (traits) وكما في القائمة 7-1، الدوال (functions).
باستخدام modules، يمكننا تجميع التعريفات ذات الصلة معاً وتسمية سبب ارتباطها. يمكن للمبرمجين الذين يستخدمون هذا الكود التنقل فيه بناءً على المجموعات بدلاً من الاضطرار إلى قراءة جميع التعريفات، مما يسهل العثور على التعريفات ذات الصلة بهم. سيعرف المبرمجون الذين يضيفون وظائف جديدة إلى هذا الكود مكان وضع الكود للحفاظ على تنظيم البرنامج.
ذكرنا سابقاً أن src/main.rs و src/lib.rs يسمى كل منهما crate roots. والسبب في تسميتهما هو أن محتويات أي من هذين الملفين تشكل module تسمى crate في جذر هيكل الوحدات البرمجية للكريت، والمعروف باسم شجرة الوحدات البرمجية (module tree).
توضح القائمة 7-2 module tree للهيكل الموجود في القائمة 7-1.
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
توضح هذه الشجرة كيف تتداخل بعض modules داخل modules أخرى؛ على سبيل المثال، hosting يتداخل داخل front_of_house. توضح الشجرة أيضاً أن بعض modules هي أشقاء (siblings)، مما يعني أنها معرفة في نفس module؛ hosting و serving هما siblings معرفان داخل front_of_house. إذا كانت الوحدة A محتواة داخل الوحدة B، فإننا نقول إن الوحدة A هي الابن (child) للوحدة B وأن الوحدة B هي الأب (parent) للوحدة A. لاحظ أن module tree بالكامل متجذرة تحت module الضمنية المسماة crate.
قد تذكرك module tree بشجرة مجلدات نظام الملفات على جهاز الكمبيوتر الخاص بك؛ هذا تشبيه دقيق للغاية! تماماً مثل المجلدات في نظام الملفات، تستخدم modules لتنظيم كودك. وتماماً مثل الملفات في المجلد، نحتاج إلى طريقة للعثور على modules الخاصة بنا.
المسارات للإشارة إلى عنصر في شجرة الوحدات (Module Tree)
المسارات (Paths) للإشارة إلى عنصر في شجرة الوحدات (Module Tree)
لإظهار لغة Rust أين تجد عنصرًا في شجرة الوحدات (module tree)، نستخدم مسارًا (path) بنفس الطريقة التي نستخدم بها مسارًا عند التنقل في نظام الملفات (filesystem). لاستدعاء دالة (function)، نحتاج إلى معرفة مسارها.
يمكن أن يتخذ المسار شكلين:
- المسار المطلق (Absolute path) هو المسار الكامل الذي يبدأ من جذر الصندوق (crate root)؛ بالنسبة للكود من صندوق خارجي (external crate)، يبدأ المسار المطلق باسم الـ crate، وبالنسبة للكود من الـ crate الحالي، يبدأ بالحرف
crate. - المسار النسبي (Relative path) يبدأ من الوحدة (module) الحالية ويستخدم
selfأوsuperأو معرفًا (identifier) في الـ module الحالي.
يتبع كل من الـ absolute paths والـ relative paths بمعرف واحد أو أكثر مفصول بعلامتي نقطتين مزدوجتين (::).
بالعودة إلى القائمة 7-1، لنفترض أننا نريد استدعاء الدالة add_to_waitlist. هذا هو نفس السؤال: ما هو مسار الدالة add_to_waitlist؟ تحتوي القائمة 7-3 على القائمة 7-1 مع إزالة بعض الـ modules والدوال.
سنعرض طريقتين لاستدعاء الدالة add_to_waitlist من دالة جديدة، eat_at_restaurant، محددة في الـ crate root. هذه المسارات صحيحة، ولكن هناك مشكلة أخرى متبقية ستمنع هذا المثال من الـ compile كما هو. سنشرح السبب بعد قليل.
تعد الدالة eat_at_restaurant جزءًا من واجهة برمجة التطبيقات العامة (public API) لـ library crate الخاص بنا، لذلك نضع علامة عليها بالكلمة المفتاحية pub. في قسم “كشف المسارات باستخدام الكلمة المفتاحية pub”، سنتعمق في تفاصيل أكثر حول pub.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}في المرة الأولى التي نستدعي فيها الدالة add_to_waitlist في eat_at_restaurant، نستخدم absolute path. تم تعريف الدالة add_to_waitlist في نفس الـ crate مثل eat_at_restaurant، مما يعني أنه يمكننا استخدام الكلمة المفتاحية crate لبدء absolute path. ثم نقوم بتضمين كل من الـ modules المتتالية حتى نصل إلى add_to_waitlist. يمكنك تخيل filesystem بنفس الهيكل: سنحدد المسار /front_of_house/hosting/add_to_waitlist لتشغيل برنامج add_to_waitlist؛ استخدام اسم الـ crate للبدء من الـ crate root يشبه استخدام / للبدء من جذر نظام الملفات في الـ shell الخاص بك.
في المرة الثانية التي نستدعي فيها add_to_waitlist في eat_at_restaurant، نستخدم relative path. يبدأ المسار بـ front_of_house، وهو اسم الـ module المحدد في نفس مستوى الـ module tree مثل eat_at_restaurant. هنا، سيكون مكافئ نظام الملفات هو استخدام المسار front_of_house/hosting/add_to_waitlist. البدء باسم module يعني أن المسار نسبي.
إن اختيار ما إذا كنت ستستخدم relative path أو absolute path هو قرار ستتخذه بناءً على مشروعك، ويعتمد على ما إذا كنت أكثر عرضة لنقل كود تعريف العنصر بشكل منفصل عن الكود الذي يستخدم العنصر أو معه. على سبيل المثال، إذا نقلنا الـ module front_of_house والدالة eat_at_restaurant إلى module يسمى customer_experience، فسنحتاج إلى تحديث الـ absolute path إلى add_to_waitlist، لكن الـ relative path سيظل صالحًا. ومع ذلك، إذا نقلنا الدالة eat_at_restaurant بشكل منفصل إلى module يسمى dining، فسيظل الـ absolute path إلى استدعاء add_to_waitlist كما هو، ولكن سيحتاج الـ relative path إلى التحديث. تفضيلنا بشكل عام هو تحديد absolute paths لأنه من المرجح أننا سنرغب في نقل تعريفات الكود واستدعاءات العناصر بشكل مستقل عن بعضها البعض.
دعنا نحاول compile القائمة 7-3 ونكتشف سبب عدم الـ compile بعد! تظهر الأخطاء التي نحصل عليها في القائمة 7-4.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `hosting` is private
--> src/lib.rs:9:28
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
error[E0603]: module `hosting` is private
--> src/lib.rs:12:21
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
تقول رسائل الخطأ أن الـ module hosting خاص (private). بعبارة أخرى، لدينا المسارات الصحيحة لـ module hosting والدالة add_to_waitlist، لكن Rust لن تسمح لنا باستخدامها لأنه ليس لديها وصول إلى الأقسام الـ private. في Rust، تكون جميع العناصر (الدوال، الـ methods، الـ structs، الـ enums، الـ modules، والثوابت) خاصة بـ parent modules افتراضيًا. إذا كنت تريد جعل عنصر مثل function أو struct خاصًا، فستضعه في module.
لا يمكن للعناصر الموجودة في parent module استخدام العناصر الـ private داخل child modules، ولكن يمكن للعناصر الموجودة في child modules استخدام العناصر الموجودة في ancestor modules الخاصة بها. هذا لأن الـ child modules تغلف وتخفي تفاصيل التطبيق الخاصة بها، ولكن يمكن لـ child modules رؤية السياق الذي تم تعريفها فيه. لمواصلة استعارتنا، فكر في قواعد الخصوصية على أنها مثل المكتب الخلفي للمطعم: ما يحدث هناك خاص لعملاء المطعم، ولكن يمكن لمديري المكاتب رؤية والقيام بكل شيء في المطعم الذي يديرونه.
اختارت Rust أن يعمل نظام الـ module بهذه الطريقة بحيث يكون إخفاء تفاصيل التطبيق الداخلية هو الافتراضي. بهذه الطريقة، تعرف أي أجزاء من الكود الداخلي يمكنك تغييرها دون كسر الكود الخارجي. ومع ذلك، تمنحك Rust خيار كشف الأجزاء الداخلية من كود الـ child modules لـ ancestor modules الخارجية باستخدام الكلمة المفتاحية pub لجعل العنصر عامًا (public).
كشف المسارات باستخدام الكلمة المفتاحية pub
دعنا نعود إلى الخطأ في القائمة 7-4 الذي أخبرنا أن الـ module hosting خاص. نريد أن يكون للدالة eat_at_restaurant في الـ parent module وصول إلى الدالة add_to_waitlist في الـ child module، لذلك نضع علامة على الـ module hosting بالكلمة المفتاحية pub، كما هو موضح في القائمة 7-5.
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}لسوء الحظ، لا يزال الكود في القائمة 7-5 يؤدي إلى أخطاء في الـ compiler، كما هو موضح في القائمة 7-6.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:10:37
|
10 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:13:30
|
13 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
ماذا حدث؟ إضافة الكلمة المفتاحية pub أمام mod hosting تجعل الـ module عامًا. مع هذا التغيير، إذا تمكنا من الوصول إلى front_of_house، فيمكننا الوصول إلى hosting. لكن محتويات hosting لا تزال خاصة؛ جعل الـ module عامًا لا يجعل محتوياته عامة. تسمح الكلمة المفتاحية pub على module فقط للكود الموجود في ancestor modules بالإشارة إليه، وليس الوصول إلى الكود الداخلي الخاص به. نظرًا لأن الـ modules هي حاويات، فلا يمكننا فعل الكثير بمجرد جعل الـ module عامًا؛ نحتاج إلى المضي قدمًا واختيار جعل عنصر واحد أو أكثر داخل الـ module عامًا أيضًا.
تقول الأخطاء في القائمة 7-6 أن الدالة add_to_waitlist خاصة. تنطبق قواعد الخصوصية على الـ structs، الـ enums، الـ functions، والـ methods بالإضافة إلى الـ modules.
دعنا نجعل الدالة add_to_waitlist عامة أيضًا عن طريق إضافة الكلمة المفتاحية pub قبل تعريفها، كما في القائمة 7-7.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}الآن سيتم الـ compile للكود! لمعرفة سبب سماح إضافة الكلمة المفتاحية pub لنا باستخدام هذه المسارات في eat_at_restaurant فيما يتعلق بقواعد الخصوصية، دعنا ننظر إلى الـ absolute paths والـ relative paths.
في الـ absolute path، نبدأ بـ crate، وهو جذر الـ module tree لـ crate الخاص بنا. تم تعريف الـ module front_of_house في الـ crate root. على الرغم من أن front_of_house ليس عامًا، نظرًا لأن الدالة eat_at_restaurant محددة في نفس الـ module مثل front_of_house (أي أن eat_at_restaurant و front_of_house هما شقيقان)، يمكننا الإشارة إلى front_of_house من eat_at_restaurant. التالي هو الـ module hosting الذي تم وضع علامة عليه بـ pub. يمكننا الوصول إلى الـ parent module لـ hosting، لذلك يمكننا الوصول إلى hosting. أخيرًا، تم وضع علامة على الدالة add_to_waitlist بـ pub، ويمكننا الوصول إلى الـ parent module الخاص بها، لذا فإن استدعاء الدالة هذا يعمل!
في الـ relative path، يكون المنطق هو نفسه الـ absolute path باستثناء الخطوة الأولى: بدلاً من البدء من الـ crate root، يبدأ المسار من front_of_house. تم تعريف الـ module front_of_house داخل نفس الـ module مثل eat_at_restaurant، لذا فإن الـ relative path الذي يبدأ من الـ module الذي تم تعريف eat_at_restaurant فيه يعمل. بعد ذلك، نظرًا لأن hosting و add_to_waitlist تم وضع علامة عليهما بـ pub، فإن بقية المسار يعمل، واستدعاء الدالة هذا صالح!
إذا كنت تخطط لمشاركة library crate الخاص بك بحيث يمكن للمشاريع الأخرى استخدام الكود الخاص بك، فإن الـ public API الخاص بك هو عقدك مع مستخدمي الـ crate الخاص بك الذي يحدد كيفية تفاعلهم مع الكود الخاص بك. هناك العديد من الاعتبارات حول إدارة التغييرات على الـ public API الخاص بك لتسهيل اعتماد الأشخاص على الـ crate الخاص بك. هذه الاعتبارات تتجاوز نطاق هذا الكتاب؛ إذا كنت مهتمًا بهذا الموضوع، فراجع إرشادات Rust API.
أفضل الممارسات للحزم التي تحتوي على ثنائي ومكتبة (Binary and a Library)
ذكرنا أن الحزمة يمكن أن تحتوي على كل من جذر الـ binary crate
src/main.rsبالإضافة إلى جذر الـ library cratesrc/lib.rs، وسيكون لكلا الـ crates اسم الحزمة افتراضيًا. عادةً، تحتوي الحزم التي تحتوي على هذا النمط من احتواء كل من library crate و binary crate على كود كافٍ فقط في الـ binary crate لبدء ملف تنفيذي يستدعي الكود المحدد في الـ library crate. يتيح ذلك للمشاريع الأخرى الاستفادة من معظم الوظائف التي توفرها الحزمة لأنه يمكن مشاركة كود الـ library crate.يجب تعريف الـ module tree في
src/lib.rs. بعد ذلك، يمكن استخدام أي عناصر عامة في الـ binary crate عن طريق بدء المسارات باسم الحزمة. يصبح الـ binary crate مستخدمًا لـ library crate تمامًا مثلما يستخدم الـ external crate بالكامل الـ library crate: يمكنه فقط استخدام الـ public API. يساعدك هذا في تصميم API جيد؛ لست أنت المؤلف فحسب، بل أنت أيضًا عميل!في الفصل 12، سنوضح هذه الممارسة التنظيمية باستخدام برنامج سطر أوامر سيحتوي على كل من binary crate و library crate.
بدء الـ Relative Paths بـ super
يمكننا إنشاء relative paths تبدأ في الـ parent module، بدلاً من الـ module الحالي أو الـ crate root، باستخدام super في بداية المسار. هذا يشبه بدء مسار filesystem ببناء جملة .. الذي يعني الانتقال إلى الدليل الأصل (parent directory). يسمح لنا استخدام super بالإشارة إلى عنصر نعرف أنه موجود في الـ parent module، مما قد يجعل إعادة ترتيب الـ module tree أسهل عندما يكون الـ module مرتبطًا ارتباطًا وثيقًا بالـ parent ولكن قد يتم نقل الـ parent إلى مكان آخر في الـ module tree في يوم من الأيام.
ضع في اعتبارك الكود في القائمة 7-8 الذي يصمم الموقف الذي يقوم فيه طاهٍ بإصلاح طلب غير صحيح ويحضره شخصيًا إلى العميل. تستدعي الدالة fix_incorrect_order المحددة في الـ module back_of_house الدالة deliver_order المحددة في الـ parent module عن طريق تحديد المسار إلى deliver_order، بدءًا من super.
fn deliver_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::deliver_order();
}
fn cook_order() {}
}توجد الدالة fix_incorrect_order في الـ module back_of_house، لذلك يمكننا استخدام super للانتقال إلى الـ parent module لـ back_of_house، وهو في هذه الحالة crate، الجذر. من هناك، نبحث عن deliver_order ونجده. نجاح! نعتقد أن الـ module back_of_house والدالة deliver_order من المرجح أن يظلا في نفس العلاقة مع بعضهما البعض ويتم نقلهما معًا إذا قررنا إعادة تنظيم الـ module tree لـ crate. لذلك، استخدمنا super حتى يكون لدينا عدد أقل من الأماكن لتحديث الكود فيها في المستقبل إذا تم نقل هذا الكود إلى module مختلف.
جعل الـ Structs والـ Enums عامة
يمكننا أيضًا استخدام pub لتعيين الـ structs والـ enums كـ public، ولكن هناك بعض الاختلافات. إذا وضعنا pub قبل تعريف struct، فإننا نجعل الـ struct عامًا، لكن الـ fields الخاصة بالـ struct ستظل خاصة. يمكننا جعل كل field عامًا أو لا على أساس كل حالة على حدة. في القائمة 7-9، قمنا بتعريف struct عام back_of_house::Breakfast مع field عام toast ولكن field خاص seasonal_fruit. يصمم هذا الحالة في مطعم حيث يمكن للعميل اختيار نوع الخبز الذي يأتي مع الوجبة، لكن الطاهي يقرر الفاكهة التي تصاحب الوجبة بناءً على ما هو موسمي ومتوفر. تتغير الفاكهة المتاحة بسرعة، لذلك لا يمكن للعملاء اختيار الفاكهة أو حتى رؤية الفاكهة التي سيحصلون عليها.
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// Order a breakfast in the summer with Rye toast.
let mut meal = back_of_house::Breakfast::summer("Rye");
// Change our mind about what bread we'd like.
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
// The next line won't compile if we uncomment it; we're not allowed
// to see or modify the seasonal fruit that comes with the meal.
// meal.seasonal_fruit = String::from("blueberries");
}نظرًا لأن الـ field toast في struct back_of_house::Breakfast عام، في eat_at_restaurant يمكننا الكتابة والقراءة إلى الـ field toast باستخدام تدوين النقطة (dot notation). لاحظ أنه لا يمكننا استخدام الـ field seasonal_fruit في eat_at_restaurant، لأن seasonal_fruit خاص. حاول إلغاء التعليق على السطر الذي يعدل قيمة الـ field seasonal_fruit لترى الخطأ الذي تحصل عليه!
لاحظ أيضًا أنه نظرًا لأن back_of_house::Breakfast يحتوي على field خاص، يحتاج الـ struct إلى توفير دالة مرتبطة عامة تنشئ مثيلًا لـ Breakfast (لقد أطلقنا عليها اسم summer هنا). إذا لم يكن لدى Breakfast مثل هذه الدالة، فلن نتمكن من إنشاء مثيل لـ Breakfast في eat_at_restaurant، لأننا لا يمكننا تعيين قيمة الـ field الخاص seasonal_fruit في eat_at_restaurant.
في المقابل، إذا جعلنا enum عامًا، فإن جميع متغيراته (variants) تكون عامة. نحتاج فقط إلى pub قبل الكلمة المفتاحية enum، كما هو موضح في القائمة 7-10.
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}نظرًا لأننا جعلنا الـ enum Appetizer عامًا، يمكننا استخدام الـ variants Soup و Salad في eat_at_restaurant.
الـ Enums ليست مفيدة جدًا ما لم تكن متغيراتها عامة؛ سيكون من المزعج الاضطرار إلى إضافة تعليق توضيحي لجميع enum variants بـ pub في كل حالة، لذا فإن الإعداد الافتراضي لـ enum variants هو أن تكون عامة. غالبًا ما تكون الـ Structs مفيدة دون أن تكون الـ fields الخاصة بها عامة، لذا تتبع الـ struct fields القاعدة العامة المتمثلة في أن كل شيء خاص افتراضيًا ما لم يتم وضع علامة عليه بـ pub.
هناك موقف آخر يتعلق بـ pub لم نقم بتغطيته، وهو آخر ميزة لنظام الـ module: الكلمة المفتاحية use. سنغطي use بمفردها أولاً، ثم سنوضح كيفية دمج pub و use.
جلب المسارات إلى النطاق باستخدام الكلمة المفتاحية use
جلب المسارات إلى النطاق باستخدام الكلمة المفتاحية use (Bringing Paths into Scope with the use Keyword)
قد يكون الاضطرار إلى كتابة (المسارات) paths بالكامل لاستدعاء الدوال أمراً غير مريح ومتكرراً. في القائمة 7-7، سواء اخترنا المسار المطلق أو النسبي لدالة add_to_waitlist ، كان علينا في كل مرة نريد فيها استدعاء add_to_waitlist تحديد front_of_house و hosting أيضاً. لحسن الحظ، هناك طريقة لتبسيط هذه العملية: يمكننا إنشاء اختصار لمسار باستخدام الكلمة المفتاحية use مرة واحدة، ثم استخدام الاسم الأقصر في أي مكان آخر في (النطاق) scope.
في القائمة 7-11، نقوم بجلب (الوحدة) module المسماة crate::front_of_house::hosting إلى نطاق دالة eat_at_restaurant بحيث نضطر فقط إلى تحديد hosting::add_to_waitlist لاستدعاء دالة add_to_waitlist في eat_at_restaurant.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}إضافة use ومسار في نطاق ما يشبه إنشاء (رابط رمزي) symbolic link في نظام الملفات. من خلال إضافة use crate::front_of_house::hosting في جذر الصندوق، أصبح hosting الآن اسماً صالحاً في ذلك النطاق، تماماً كما لو تم تعريف وحدة hosting في جذر الصندوق. المسارات التي يتم جلبها إلى النطاق باستخدام use تخضع أيضاً لفحص (الخصوصية) privacy ، مثل أي مسارات أخرى.
لاحظ أن use تنشئ الاختصار فقط للنطاق المحدد الذي تظهر فيه use. تقوم القائمة 7-12 بنقل دالة eat_at_restaurant إلى وحدة فرعية جديدة تسمى customer ، والتي تعد نطاقاً مختلفاً عن عبارة use ، لذا لن يتم تجميع جسم الدالة.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
mod customer {
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
}يظهر خطأ المترجم أن الاختصار لم يعد ينطبق داخل وحدة customer:
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0433]: failed to resolve: use of unresolved module or unlinked crate `hosting`
--> src/lib.rs:11:9
|
11 | hosting::add_to_waitlist();
| ^^^^^^^ use of unresolved module or unlinked crate `hosting`
|
= help: if you wanted to use a crate named `hosting`, use `cargo add hosting` to add it to your `Cargo.toml`
help: consider importing this module through its public re-export
|
10 + use crate::hosting;
|
warning: unused import: `crate::front_of_house::hosting`
--> src/lib.rs:7:5
|
7 | use crate::front_of_house::hosting;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` (lib) due to 1 previous error; 1 warning emitted
لاحظ أن هناك أيضاً تحذيراً بأن use لم تعد مستخدمة في نطاقها! لإصلاح هذه المشكلة، انقل use داخل وحدة customer أيضاً، أو أشر إلى الاختصار في الوحدة الأب باستخدام super::hosting داخل الوحدة الفرعية customer.
إنشاء مسارات use اصطلاحية (Creating Idiomatic use Paths)
في القائمة 7-11، ربما تساءلت لماذا حددنا use crate::front_of_house::hosting ثم استدعينا hosting::add_to_waitlist في eat_at_restaurant ، بدلاً من تحديد مسار use بالكامل وصولاً إلى دالة add_to_waitlist لتحقيق نفس النتيجة، كما في القائمة 7-13.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist();
}على الرغم من أن كلاً من القائمة 7-11 والقائمة 7-13 تنجزان نفس المهمة، إلا أن القائمة 7-11 هي الطريقة (الاصطلاحية) idiomatic لجلب دالة إلى النطاق باستخدام use. جلب الوحدة الأب للدالة إلى النطاق باستخدام use يعني أنه يجب علينا تحديد الوحدة الأب عند استدعاء الدالة. تحديد الوحدة الأب عند استدعاء الدالة يجعل من الواضح أن الدالة ليست معرفة محلياً مع تقليل تكرار المسار الكامل. الكود في القائمة 7-13 غير واضح فيما يتعلق بمكان تعريف add_to_waitlist.
من ناحية أخرى، عند جلب (الهياكل) structs و (التعدادات) enums والعناصر الأخرى باستخدام use ، فمن الاصطلاحي تحديد المسار الكامل. تعرض القائمة 7-14 الطريقة الاصطلاحية لجلب هيكل HashMap من المكتبة القياسية إلى نطاق صندوق ثنائي.
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
map.insert(1, 2);
}لا يوجد سبب قوي وراء هذا الاصطلاح: إنه مجرد العرف الذي ظهر، واعتاد الناس على قراءة وكتابة كود Rust بهذه الطريقة.
الاستثناء من هذا الاصطلاح هو إذا كنا نجلب عنصرين بنفس الاسم إلى النطاق باستخدام عبارات use ، لأن Rust لا تسمح بذلك. تعرض القائمة 7-15 كيفية جلب نوعين من Result إلى النطاق لهما نفس الاسم ولكن وحدات أب مختلفة، وكيفية الإشارة إليهما.
use std::fmt;
use std::io;
fn function1() -> fmt::Result {
// --snip--
Ok(())
}
fn function2() -> io::Result<()> {
// --snip--
Ok(())
}كما ترى، فإن استخدام الوحدات الأب يميز بين نوعي Result. إذا حددنا بدلاً من ذلك use std::fmt::Result و use std::io::Result ، فسيكون لدينا نوعان من Result في نفس النطاق، ولن تعرف Rust أيهما نقصد عندما نستخدم Result.
توفير أسماء جديدة باستخدام الكلمة المفتاحية as (Providing New Names with the as Keyword)
هناك حل آخر لمشكلة جلب نوعين من نفس الاسم إلى نفس النطاق باستخدام use: بعد المسار، يمكننا تحديد as واسم محلي جديد، أو (اسم مستعار) alias ، للنوع. تعرض القائمة 7-16 طريقة أخرى لكتابة الكود في القائمة 7-15 عن طريق إعادة تسمية أحد نوعي Result باستخدام as.
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
Ok(())
}
fn function2() -> IoResult<()> {
// --snip--
Ok(())
}في عبارة use الثانية، اخترنا الاسم الجديد IoResult لنوع std::io::Result ، والذي لن يتعارض مع Result من std::fmt الذي جلبناه أيضاً إلى النطاق. تعتبر كل من القائمة 7-15 والقائمة 7-16 اصطلاحية، لذا فالخيار متروك لك!
إعادة تصدير الأسماء باستخدام pub use (Re-exporting Names with pub use)
عندما نجلب اسماً إلى النطاق باستخدام الكلمة المفتاحية use ، يكون الاسم خاصاً بالنطاق الذي استوردناه إليه. لتمكين الكود خارج ذلك النطاق من الإشارة إلى ذلك الاسم كما لو كان قد تم تعريفه في ذلك النطاق، يمكننا الجمع بين pub و use. تسمى هذه التقنية (إعادة التصدير) re-exporting لأننا نجلب عنصراً إلى النطاق ولكننا نجعله متاحاً أيضاً للآخرين لجلبه إلى نطاقهم.
تعرض القائمة 7-17 الكود في القائمة 7-11 مع تغيير use في الوحدة الجذرية إلى pub use.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}قبل هذا التغيير، كان على الكود الخارجي استدعاء دالة add_to_waitlist باستخدام المسار restaurant::front_of_house::hosting::add_to_waitlist() ، والذي كان سيتطلب أيضاً وضع علامة pub على وحدة front_of_house. الآن بعد أن قامت pub use بإعادة تصدير وحدة hosting من الوحدة الجذرية، يمكن للكود الخارجي استخدام المسار restaurant::hosting::add_to_waitlist() بدلاً من ذلك.
تعد إعادة التصدير مفيدة عندما يكون الهيكل الداخلي لكودك مختلفاً عن الطريقة التي يفكر بها المبرمجون الذين يستدعون كودك حول المجال. على سبيل المثال، في استعارة المطعم هذه، يفكر الأشخاص الذين يديرون المطعم في “واجهة المطعم” و “خلفية المطعم”. لكن الزبائن الذين يزورون المطعم ربما لن يفكروا في أجزاء المطعم بهذه المصطلحات. باستخدام pub use ، يمكننا كتابة كودنا بهيكل واحد ولكن كشف هيكل مختلف. القيام بذلك يجعل مكتبتنا منظمة بشكل جيد للمبرمجين الذين يعملون على المكتبة والمبرمجين الذين يستدعون المكتبة. سنلقي نظرة على مثال آخر لـ pub use وكيف تؤثر على توثيق صندوقك في “تصدير واجهة برمجة تطبيقات عامة مريحة” في الفصل 14.
استخدام الحزم الخارجية (Using External Packages)
في الفصل الثاني، قمنا ببرمجة مشروع لعبة تخمين استخدم حزمة خارجية تسمى rand للحصول على أرقام عشوائية. لاستخدام rand في مشروعنا، أضفنا هذا السطر إلى Cargo.toml:
rand = "0.8.5"
إضافة rand كـ dependency في Cargo.toml يخبر Cargo بتنزيل حزمة rand وأي تبعيات من crates.io وجعل rand متاحاً لمشروعنا.
بعد ذلك، لجلب تعريفات rand إلى نطاق حزمتنا، أضفنا سطر use يبدأ باسم الصندوق، rand ، ودرجنا العناصر التي أردنا جلبها إلى النطاق. تذكر أنه في “توليد رقم عشوائي” في الفصل الثاني، جلبنا (سمة) trait المسماة Rng إلى النطاق واستدعينا دالة rand::thread_rng:
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}قام أعضاء مجتمع Rust بتوفير العديد من الحزم في crates.io ، ويتضمن سحب أي منها إلى حزمتك نفس هذه الخطوات: إدراجها في ملف Cargo.toml الخاص بحزمتك واستخدام use لجلب العناصر من صناديقها إلى النطاق.
لاحظ أن المكتبة القياسية std هي أيضاً صندوق خارجي لحزمتنا. نظراً لأن المكتبة القياسية يتم شحنها مع لغة Rust، فلا نحتاج إلى تغيير Cargo.toml لتضمين std. لكننا نحتاج إلى الإشارة إليها باستخدام use لجلب العناصر من هناك إلى نطاق حزمتنا. على سبيل المثال، مع HashMap سنستخدم هذا السطر:
#![allow(unused)]
fn main() {
use std::collections::HashMap;
}هذا مسار مطلق يبدأ بـ std ، وهو اسم صندوق المكتبة القياسية.
استخدام المسارات المتداخلة لتنظيف قوائم use الكبيرة (Using Nested Paths to Clean Up use Lists)
إذا كنا نستخدم عناصر متعددة معرفة في نفس الصندوق أو نفس الوحدة، فإن إدراج كل عنصر في سطر خاص به يمكن أن يشغل مساحة رأسية كبيرة في ملفاتنا. على سبيل المثال، هاتان العبارتان use اللتان كانتا لدينا في لعبة التخمين في القائمة 2-4 تجلبان عناصر من std إلى النطاق:
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}بدلاً من ذلك، يمكننا استخدام (المسارات المتداخلة) nested paths لجلب نفس العناصر إلى النطاق في سطر واحد. نقوم بذلك عن طريق تحديد الجزء المشترك من المسار، متبوعاً بنقطتين مزدوجتين، ثم أقواس معقوفة حول قائمة أجزاء المسارات التي تختلف، كما هو موضح في القائمة 7-18.
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}في البرامج الأكبر، يمكن أن يؤدي جلب العديد من العناصر إلى النطاق من نفس الصندوق أو الوحدة باستخدام المسارات المتداخلة إلى تقليل عدد عبارات use المنفصلة المطلوبة بشكل كبير!
يمكننا استخدام مسار متداخل في أي مستوى في المسار، وهو أمر مفيد عند دمج عبارني use تشتركان في مسار فرعي. على سبيل المثال، تعرض القائمة 7-19 عبارني use: واحدة تجلب std::io إلى النطاق وأخرى تجلب std::io::Write إلى النطاق.
use std::io;
use std::io::Write;الجزء المشترك من هذين المسارين هو std::io ، وهذا هو المسار الأول الكامل. لدمج هذين المسارين في عبارة use واحدة، يمكننا استخدام self في المسار المتداخل، كما هو موضح في القائمة 7-20.
use std::io::{self, Write};يجلب هذا السطر std::io و std::io::Write إلى النطاق.
استيراد العناصر باستخدام عامل النجمة (Importing Items with the Glob Operator)
إذا أردنا جلب جميع العناصر العامة المعرفة في مسار ما إلى النطاق، فيمكننا تحديد ذلك المسار متبوعاً بـ (عامل النجمة) glob operator وهو *:
#![allow(unused)]
fn main() {
use std::collections::*;
}تجلب عبارة use هذه جميع العناصر العامة المعرفة في std::collections إلى النطاق الحالي. كن حذراً عند استخدام عامل النجمة! يمكن أن يجعل glob من الصعب معرفة الأسماء الموجودة في النطاق ومكان تعريف الاسم المستخدم في برنامجك. بالإضافة إلى ذلك، إذا قامت التبعية بتغيير تعريفاتها، فإن ما استوردته يتغير أيضاً، مما قد يؤدي إلى أخطاء في المترجم عند ترقية التبعية إذا أضافت التبعية تعريفاً بنفس اسم تعريف خاص بك في نفس النطاق، على سبيل المثال.
غالباً ما يُستخدم عامل النجمة عند الاختبار لجلب كل شيء تحت الاختبار إلى وحدة tests ؛ سنتحدث عن ذلك في “كيفية كتابة الاختبارات” في الفصل 11. يُستخدم عامل النجمة أيضاً أحياناً كجزء من نمط (التمهيد) prelude : راجع توثيق المكتبة القياسية لمزيد من المعلومات حول هذا النمط.
فصل الوحدات في ملفات مختلفة
فصل الوحدات البرمجية في ملفات مختلفة
حتى الآن، كانت جميع الأمثلة في هذا الفصل تعرف وحدات برمجية (modules) متعددة في ملف واحد. عندما تصبح modules كبيرة، قد ترغب في نقل تعريفاتها إلى ملف منفصل لتسهيل تصفح الكود.
على سبيل المثال، لنبدأ من الكود الموجود في القائمة 7-17 الذي كان يحتوي على عدة modules للمطعم. سنقوم باستخراج modules إلى ملفات بدلاً من وجود جميع modules معرفة في ملف جذر الكريت (crate root). في هذه الحالة، ملف crate root هو src/lib.rs، ولكن هذا الإجراء يعمل أيضاً مع الكريتات الثنائية (binary crates) التي يكون ملف crate root الخاص بها هو src/main.rs.
أولاً، سنقوم باستخراج وحدة front_of_house إلى ملفها الخاص. قم بإزالة الكود الموجود داخل الأقواس المتعرجة لوحدة front_of_house مع ترك التصريح mod front_of_house; فقط، بحيث يحتوي src/lib.rs على الكود الموضح في القائمة 7-21. لاحظ أن هذا لن يتم تصريفه (compile) حتى ننشئ ملف src/front_of_house.rs في القائمة 7-22.
mod front_of_house;
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}بعد ذلك، ضع الكود الذي كان داخل الأقواس المتعرجة في ملف جديد باسم src/front_of_house.rs، كما هو موضح في القائمة 7-22. يعرف المترجم (compiler) أنه يجب البحث في هذا الملف لأنه صادف تصريح الوحدة في crate root باسم front_of_house.
pub mod hosting {
pub fn add_to_waitlist() {}
}لاحظ أنك تحتاج فقط إلى تحميل ملف باستخدام تصريح mod مرة واحدة في شجرة الوحدات البرمجية (module tree). بمجرد أن يعرف compiler أن الملف جزء من المشروع (ويعرف مكان وجود الكود في module tree بسبب المكان الذي وضعت فيه عبارة mod)، يجب أن تشير الملفات الأخرى في مشروعك إلى كود الملف المحمل باستخدام مسار (path) إلى مكان التصريح عنه، كما هو مغطى في قسم “مسارات الإشارة إلى عنصر في شجرة الوحدات البرمجية”. بعبارة أخرى، mod ليست عملية “تضمين” (include) كما قد تكون رأيتها في لغات برمجة أخرى.
بعد ذلك، سنقوم باستخراج وحدة hosting إلى ملفها الخاص. العملية مختلفة قليلاً لأن hosting هي وحدة فرعية (child module) لـ front_of_house وليست للوحدة الجذرية. سنضع ملف hosting في مجلد جديد سيتم تسميته باسم أسلافه في module tree، وفي هذه الحالة هو src/front_of_house.
لبدء نقل hosting نقوم بتغيير src/front_of_house.rs ليحتوي فقط على تصريح وحدة hosting:
pub mod hosting;ثم ننشئ مجلد src/front_of_house وملف hosting.rs ليحتويا على التعريفات الموجودة في وحدة hosting:
pub fn add_to_waitlist() {}إذا وضعنا hosting.rs في مجلد src بدلاً من ذلك، فسيوقع compiler أن يكون كود hosting.rs في وحدة hosting مصرح عنها في crate root وليس مصرحاً عنها كابن لوحدة front_of_house. تعني قواعد compiler الخاصة بالملفات التي يجب فحصها بحثاً عن كود modules أن المجلدات والملفات تتطابق بشكل أوثق مع module tree.
مسارات ملفات بديلة (Alternate File Paths)
حتى الآن قمنا بتغطية مسارات الملفات الأكثر شيوعاً (idiomatic) التي يستخدمها مترجم Rust، ولكن Rust يدعم أيضاً أسلوباً قديماً لمسارات الملفات. بالنسبة لوحدة تسمى
front_of_houseمصرح عنها في crate root، سيبحث compiler عن كود الوحدة في:
- src/front_of_house.rs (ما قمنا بتغطيته)
- src/front_of_house/mod.rs (أسلوب قديم، مسار لا يزال مدعوماً)
بالنسبة لوحدة تسمى
hostingوهي وحدة فرعية (submodule) لـfront_of_houseسيبحث compiler عن كود الوحدة في:
- src/front_of_house/hosting.rs (ما قمنا بتغطيته)
- src/front_of_house/hosting/mod.rs (أسلوب قديم، مسار لا يزال مدعوماً)
إذا استخدمت كلا الأسلوبين لنفس الوحدة، فستحصل على خطأ من المترجم (compiler error). يسمح باستخدام مزيج من كلا الأسلوبين لوحدات مختلفة في نفس المشروع ولكن قد يكون ذلك مربكاً للأشخاص الذين يتصفحون مشروعك.
العيب الرئيسي للأسلوب الذي يستخدم ملفات تسمى mod.rs هو أن مشروعك قد ينتهي به الأمر بالعديد من الملفات المسماة mod.rs، مما قد يصبح مربكاً عندما تكون مفتوحة في المحرر الخاص بك في نفس الوقت.
لقد نقلنا كود كل وحدة إلى ملف منفصل، وظلت module tree كما هي. ستعمل استدعاءات الدوال في eat_at_restaurant دون أي تعديل، على الرغم من أن التعريفات تعيش في ملفات مختلفة. تتيح لك هذه التقنية نقل modules إلى ملفات جديدة مع زيادة حجمها.
لاحظ أن عبارة pub use crate::front_of_house::hosting في src/lib.rs لم تتغير أيضاً، كما أن use ليس لها أي تأثير على الملفات التي يتم تصريفها كجزء من crate. تقوم الكلمة المفتاحية mod بالتصريح عن modules، ويبحث Rust في ملف له نفس اسم الوحدة عن الكود الذي يوضع في تلك الوحدة.
ملخص
تسمح لك Rust بتقسيم طرد (package) إلى عدة كريتات (crates) والكريت إلى وحدات برمجية (modules) بحيث يمكنك الرجوع إلى العناصر المعرفة في وحدة من وحدة أخرى. يمكنك القيام بذلك عن طريق تحديد مسارات (paths) مطلقة أو نسبية. يمكن جلب هذه paths إلى النطاق (scope) باستخدام عبارة use بحيث يمكنك استخدام مسار أقصر لاستخدامات متعددة للعنصر في ذلك scope. كود الوحدة يكون خاصاً (private) بشكل افتراضي، ولكن يمكنك جعل التعريفات عامة (public) بإضافة الكلمة المفتاحية pub.
في الفصل القادم، سنلقي نظرة على بعض هياكل بيانات المجموعات (collection data structures) في المكتبة القياسية (standard library) التي يمكنك استخدامها في كودك المنظم بدقة.
المجموعات الشائعة (Common Collections)
تتضمن مكتبة Rust القياسية (Standard Library) عدداً من هياكل البيانات المفيدة جداً والتي تسمى “المجموعات” (Collections). تمثل معظم أنواع البيانات الأخرى قيمة واحدة محددة، ولكن يمكن للـ Collections أن تحتوي على قيم متعددة. على عكس أنواع المصفوفات (Arrays) والصفوف (Tuples) المدمجة، يتم تخزين البيانات التي تشير إليها هذه الـ Collections على “الكومة” (Heap)، مما يعني أن كمية البيانات لا يلزم معرفتها في “وقت التجميع” (Compile Time) ويمكن أن تنمو أو تتقلص أثناء تشغيل البرنامج. تمتلك كل نوع من الـ Collections قدرات وتكاليف مختلفة، واختيار النوع المناسب لموقفك الحالي هو مهارة ستطورها بمرور الوقت. في هذا الفصل، سنناقش ثلاث مجموعات تُستخدم بكثرة في برامج Rust:
- “المتجه” (Vector) يتيح لك تخزين عدد متغير من القيم بجانب بعضها البعض.
- “السلسلة النصية” (String) هي مجموعة من الأحرف. لقد ذكرنا نوع
Stringسابقاً، ولكن في هذا الفصل، سنتحدث عنه بعمق. - “جدول التجزئة” (Hash Map) يتيح لك ربط قيمة بمفتاح (Key) معين. إنه تنفيذ محدد لهيكل البيانات الأكثر عمومية والذي يسمى “الخريطة” (Map).
للتعرف على الأنواع الأخرى من الـ Collections التي توفرها الـ Standard Library، راجع التوثيق.
سنناقش كيفية إنشاء وتحديث الـ Vectors، والـ Strings، والـ Hash Maps، بالإضافة إلى ما يجعل كل منها مميزاً.
تخزين قوائم القيم باستخدام المتجهات (Vectors)
تخزين قوائم من القيم باستخدام الـ Vectors
أول نوع تجميع (collection type) سننظر إليه هو Vec<T>، المعروف أيضًا باسم الـ vector. تسمح لك الـ Vectors بتخزين أكثر من قيمة في بنية بيانات واحدة تضع جميع القيم بجوار بعضها البعض في الذاكرة. يمكن للـ Vectors تخزين قيم من نفس النوع فقط. وهي مفيدة عندما يكون لديك قائمة من العناصر، مثل أسطر النص في ملف أو أسعار العناصر في عربة تسوق.
إنشاء Vector جديد
لإنشاء vector جديد وفارغ، نستدعي دالة Vec::new، كما هو موضح في القائمة 8-1.
fn main() {
let v: Vec<i32> = Vec::new();
}لاحظ أننا أضفنا تذييل نوع (type annotation) هنا. نظرًا لأننا لا ندخل أي قيم في هذا الـ vector، فإن Rust لا تعرف نوع العناصر التي ننوي تخزينها. هذه نقطة مهمة. يتم تطبيق الـ Vectors باستخدام الأنواع العامة (generics)؛ سنغطي كيفية استخدام الـ generics مع أنواعك الخاصة في الفصل 10. في الوقت الحالي، اعلم أن نوع Vec<T> الذي توفره الـ standard library يمكن أن يحتوي على أي نوع. عندما ننشئ vector لاحتواء نوع معين، يمكننا تحديد النوع داخل الأقواس الزاوية (angle brackets). في القائمة 8-1، أخبرنا Rust أن Vec<T> في v سيحتوي على عناصر من نوع i32.
في كثير من الأحيان، ستقوم بإنشاء Vec<T> بقيم أولية، وستستنتج Rust نوع القيمة التي تريد تخزينها، لذلك نادرًا ما تحتاج إلى إجراء type annotation هذا. توفر Rust بشكل ملائم الماكرو (macro) vec!، والذي سيقوم بإنشاء vector جديد يحتوي على القيم التي تقدمها له. تنشئ القائمة 8-2 Vec<i32> جديدًا يحتوي على القيم 1 و 2 و 3. نوع الـ integer هو i32 لأنه نوع الـ integer الافتراضي، كما ناقشنا في قسم “أنواع البيانات” (Data Types) في الفصل 3.
fn main() {
let v = vec![1, 2, 3];
}نظرًا لأننا قدمنا قيم i32 أولية، يمكن لـ Rust استنتاج أن نوع v هو Vec<i32>، و type annotation ليس ضروريًا. بعد ذلك، سننظر في كيفية تعديل الـ vector.
تحديث Vector
لإنشاء vector ثم إضافة عناصر إليه، يمكننا استخدام الـ method push، كما هو موضح في القائمة 8-3.
fn main() {
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
}كما هو الحال مع أي متغير، إذا أردنا أن نكون قادرين على تغيير قيمته، فنحن بحاجة إلى جعله قابلاً للتغيير (mutable) باستخدام الكلمة المفتاحية mut، كما نوقش في الفصل 3. الأرقام التي نضعها بالداخل كلها من نوع i32، وتستنتج Rust ذلك من الـ data، لذلك لا نحتاج إلى type annotation Vec<i32>.
قراءة عناصر الـ Vectors
هناك طريقتان للإشارة إلى قيمة مخزنة في vector: عبر الفهرسة (indexing) أو باستخدام الـ method get. في الأمثلة التالية، قمنا بتذييل أنواع القيم التي يتم إرجاعها من هذه الـ functions لمزيد من الوضوح.
توضح القائمة 8-4 كلتا طريقتي الوصول إلى قيمة في vector، باستخدام بناء جملة الـ indexing و method get.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2];
println!("The third element is {third}");
let third: Option<&i32> = v.get(2);
match third {
Some(third) => println!("The third element is {third}"),
None => println!("There is no third element."),
}
}لاحظ بعض التفاصيل هنا. نستخدم قيمة الـ index 2 للحصول على العنصر الثالث لأن الـ vectors مفهرسة بالرقم، بدءًا من الصفر. يمنحنا استخدام & و [] مرجعًا (reference) إلى العنصر الموجود في قيمة الـ index. عندما نستخدم method get مع تمرير الـ index كوسيط، نحصل على Option<&T> يمكننا استخدامه مع match.
توفر Rust هاتين الطريقتين للإشارة إلى عنصر حتى تتمكن من اختيار كيفية تصرف البرنامج عندما تحاول استخدام قيمة index خارج نطاق العناصر الموجودة. كمثال، دعنا نرى ما يحدث عندما يكون لدينا vector من خمسة عناصر ثم نحاول الوصول إلى عنصر في الـ index 100 بكل تقنية، كما هو موضح في القائمة 8-5.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let does_not_exist = &v[100];
let does_not_exist = v.get(100);
}عندما نقوم بتشغيل هذا الكود، ستتسبب طريقة [] الأولى في ذعر (panic) البرنامج لأنها تشير إلى عنصر غير موجود. من الأفضل استخدام هذه الطريقة عندما تريد أن يتعطل برنامجك إذا كانت هناك محاولة للوصول إلى عنصر يتجاوز نهاية الـ vector.
عندما يتم تمرير index إلى method get يكون خارج نطاق الـ vector، فإنه يُرجع None دون panic. ستستخدم هذا الـ method إذا كان الوصول إلى عنصر يتجاوز نطاق الـ vector قد يحدث أحيانًا في ظل الظروف العادية. سيحتوي الكود الخاص بك بعد ذلك على منطق للتعامل مع وجود إما Some(&element) أو None، كما نوقش في الفصل 6. على سبيل المثال، يمكن أن يأتي الـ index من شخص يدخل رقمًا. إذا أدخلوا عن طريق الخطأ رقمًا كبيرًا جدًا وحصل البرنامج على قيمة None، فيمكنك إخبار المستخدم بعدد العناصر الموجودة في الـ vector الحالي ومنحهم فرصة أخرى لإدخال قيمة صالحة. سيكون هذا أكثر سهولة في الاستخدام من تعطل البرنامج بسبب خطأ مطبعي!
عندما يكون للبرنامج reference صالح، يفرض مدقق الاقتراض (borrow checker) قواعد الـ ownership والـ borrowing (المغطاة في الفصل 4) لضمان أن هذا الـ reference وأي references أخرى لمحتويات الـ vector تظل صالحة. تذكر القاعدة التي تنص على أنه لا يمكنك الحصول على references قابلة للتغيير وغير قابلة للتغيير في نفس النطاق (scope). تنطبق هذه القاعدة في القائمة 8-6، حيث نحتفظ بـ immutable reference للعنصر الأول في vector ونحاول إضافة عنصر إلى النهاية. لن يعمل هذا البرنامج إذا حاولنا أيضًا الإشارة إلى هذا العنصر لاحقًا في الـ function.
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {first}");
}سيؤدي تجميع هذا الكود إلى هذا الخطأ:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("The first element is: {first}");
| ----- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` (bin "collections") due to 1 previous error
قد يبدو الكود في القائمة 8-6 وكأنه يجب أن يعمل: لماذا يجب أن يهتم الـ reference إلى العنصر الأول بالتغييرات في نهاية الـ vector؟ يرجع هذا الخطأ إلى طريقة عمل الـ vectors: نظرًا لأن الـ vectors تضع القيم بجوار بعضها البعض في الذاكرة، فإن إضافة عنصر جديد إلى نهاية الـ vector قد يتطلب تخصيص (allocating) ذاكرة جديدة ونسخ العناصر القديمة إلى المساحة الجديدة، إذا لم تكن هناك مساحة كافية لوضع جميع العناصر بجوار بعضها البعض حيث يتم تخزين الـ vector حاليًا. في هذه الحالة، سيشير الـ reference إلى العنصر الأول إلى ذاكرة تم إلغاء تخصيصها (deallocated memory). تمنع قواعد الـ borrowing البرامج من الانتهاء في هذا الموقف.
ملاحظة: لمزيد من التفاصيل حول تفاصيل تطبيق نوع
Vec<T>، راجع “The Rustonomicon”.
التكرار (Iterating) على القيم في Vector
للوصول إلى كل عنصر في vector بدوره، سنقوم بـ التكرار (iterate) عبر جميع العناصر بدلاً من استخدام الـ indices للوصول إلى عنصر واحد في كل مرة. توضح القائمة 8-7 كيفية استخدام حلقة for للحصول على immutable references لكل عنصر في vector من قيم i32 وطباعتها.
fn main() {
let v = vec![100, 32, 57];
for i in &v {
println!("{i}");
}
}يمكننا أيضًا iterate على mutable references لكل عنصر في mutable vector من أجل إجراء تغييرات على جميع العناصر. ستضيف حلقة for في القائمة 8-8 50 إلى كل عنصر.
fn main() {
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}
}لتغيير القيمة التي يشير إليها الـ mutable reference، يجب علينا استخدام عامل إلغاء الإشارة (dereference operator) * للوصول إلى القيمة في i قبل أن نتمكن من استخدام عامل التشغيل +=. سنتحدث أكثر عن dereference operator في قسم “متابعة الـ Reference إلى القيمة” (Following the Reference to the Value) في الفصل 15.
يعد الـ Iterating على vector، سواء كان immutably أو mutably، آمنًا بسبب قواعد borrow checker. إذا حاولنا إدراج أو إزالة عناصر في نصوص حلقات for في القائمة 8-7 والقائمة 8-8، فسنحصل على خطأ compiler مشابه للخطأ الذي حصلنا عليه مع الكود في القائمة 8-6. يمنع الـ reference إلى الـ vector الذي تحتفظ به حلقة for التعديل المتزامن للـ vector بأكمله.
استخدام Enum لتخزين أنواع متعددة
يمكن للـ Vectors تخزين قيم من نفس النوع فقط. قد يكون هذا غير مريح؛ هناك بالتأكيد حالات استخدام تتطلب تخزين قائمة من العناصر من أنواع مختلفة. لحسن الحظ، يتم تعريف متغيرات (variants) الـ enum ضمن نفس نوع الـ enum، لذلك عندما نحتاج إلى نوع واحد لتمثيل عناصر من أنواع مختلفة، يمكننا تعريف واستخدام enum!
على سبيل المثال، لنفترض أننا نريد الحصول على قيم من صف في جدول بيانات يحتوي فيه بعض الأعمدة في الصف على integers، وبعضها على أرقام فاصلة عائمة (floating-point numbers)، وبعضها على strings. يمكننا تعريف enum تحتوي متغيراته على أنواع القيم المختلفة، وستعتبر جميع متغيرات الـ enum من نفس النوع: نوع الـ enum. بعد ذلك، يمكننا إنشاء vector لاحتواء هذا الـ enum، وبالتالي، في النهاية، الاحتفاظ بأنواع مختلفة. لقد أوضحنا ذلك في القائمة 8-9.
fn main() {
enum SpreadsheetCell {
Int(i32),
Float(f64),
Text(String),
}
let row = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Text(String::from("blue")),
SpreadsheetCell::Float(10.12),
];
}تحتاج Rust إلى معرفة الأنواع التي ستكون في الـ vector في وقت التجميع (compile time) حتى تعرف بالضبط مقدار الذاكرة على الكومة (heap) التي ستكون مطلوبة لتخزين كل عنصر. يجب أن نكون صريحين أيضًا بشأن الأنواع المسموح بها في هذا الـ vector. إذا سمحت Rust لـ vector بالاحتفاظ بأي نوع، فستكون هناك فرصة لأن يتسبب نوع واحد أو أكثر من الأنواع في حدوث أخطاء في العمليات التي يتم إجراؤها على عناصر الـ vector. يعني استخدام enum بالإضافة إلى تعبير match أن Rust ستضمن في compile time التعامل مع كل حالة ممكنة، كما نوقش في الفصل 6.
إذا كنت لا تعرف المجموعة الشاملة من الأنواع التي سيحصل عليها البرنامج في وقت التشغيل (runtime) لتخزينها في vector، فلن تنجح تقنية الـ enum. بدلاً من ذلك، يمكنك استخدام كائن سمة (trait object)، والذي سنغطيه في الفصل 18.
الآن بعد أن ناقشنا بعضًا من أكثر الطرق شيوعًا لاستخدام الـ vectors، تأكد من مراجعة وثائق API لجميع الـ methods المفيدة العديدة المعرفة على Vec<T> بواسطة الـ standard library. على سبيل المثال، بالإضافة إلى push، يزيل method pop العنصر الأخير ويُرجعه.
إسقاط Vector يسقط عناصره
مثل أي struct آخر، يتم تحرير (freed) الـ vector عندما يخرج من النطاق (scope)، كما هو موضح في القائمة 8-10.
fn main() {
{
let v = vec![1, 2, 3, 4];
// do stuff with v
} // <- v goes out of scope and is freed here
}عندما يتم إسقاط الـ vector، يتم أيضًا إسقاط جميع محتوياته، مما يعني أنه سيتم تنظيف الـ integers التي يحتوي عليها. يضمن borrow checker أن أي references لمحتويات vector تُستخدم فقط بينما يكون الـ vector نفسه صالحًا.
دعنا ننتقل إلى نوع التجميع التالي: String!
تخزين النصوص المشفرة بـ UTF-8 باستخدام السلاسل النصية (Strings)
تخزين النصوص المشفرة بـ UTF-8 باستخدام السلاسل النصية (Strings)
تحدثنا عن السلاسل النصية (Strings) في الفصل 4، لكننا سنلقي نظرة عليها بعمق أكبر الآن. عادةً ما يواجه المبرمجون الجدد في Rust (Rustaceans) صعوبة في التعامل مع الـ Strings لثلاثة أسباب مجتمعة: ميل Rust لإظهار الأخطاء المحتملة، وكون الـ Strings هيكل بيانات أكثر تعقيداً مما يعتقده الكثير من المبرمجين، و UTF-8. تجتمع هذه العوامل بطريقة قد تبدو صعبة عندما تأتي من لغات برمجة أخرى.
نناقش الـ Strings في سياق المجموعات (Collections) لأن الـ Strings يتم تنفيذها كمجموعة من البايتات (Bytes)، بالإضافة إلى بعض الدوال المرتبطة (Methods) لتوفير وظائف مفيدة عندما يتم تفسير تلك الـ Bytes كنص. في هذا القسم، سنتحدث عن العمليات على String التي تمتلكها كل أنواع الـ Collections، مثل الإنشاء والتحديث والقراءة. سنناقش أيضاً الطرق التي تختلف بها String عن الـ Collections الأخرى، وتحديداً كيف أن الفهرسة (Indexing) في String معقدة بسبب الاختلافات بين كيفية تفسير البشر والحواسيب لبيانات الـ String.
تعريف السلاسل النصية (Defining Strings)
سنعرف أولاً ما نعنيه بمصطلح String. تمتلك Rust نوعاً واحداً فقط من السلاسل النصية في لغتها الأساسية (Core Language)، وهو شريحة السلسلة النصية (String Slice) str والتي تُرى عادةً في شكلها المستعار &str. في الفصل 4، تحدثنا عن الـ String Slices، وهي مراجع (References) لبعض بيانات النصوص المشفرة بـ UTF-8 والمخزنة في مكان آخر. السلاسل النصية الثابتة (String Literals)، على سبيل المثال، يتم تخزينها في الملف الثنائي (Binary) للبرنامج وبالتالي فهي String Slices.
نوع String الذي توفره مكتبة Rust القياسية (Standard Library) بدلاً من كونه مدمجاً في الـ Core Language، هو نوع سلسلة نصية قابل للنمو، وقابل للتغيير (Mutable)، ومملوك (Owned)، ومشفر بـ UTF-8. عندما يشير الـ Rustaceans إلى “Strings” في Rust، فقد يقصدون إما نوع String أو نوع الـ String Slice &str وليس أحدهما فقط. على الرغم من أن هذا القسم يدور بشكل كبير حول String إلا أن كلا النوعين يستخدمان بكثافة في الـ Standard Library، وكلاهما مشفر بـ UTF-8.
إنشاء سلسلة نصية جديدة (Creating a New String)
تتوفر العديد من العمليات المتاحة مع Vec<T> لـ String أيضاً لأن String يتم تنفيذها فعلياً كغلاف حول متجه من البايتات (Vector of Bytes) مع بعض الضمانات والقيود والقدرات الإضافية. مثال على دالة تعمل بنفس الطريقة مع Vec<T> و String هي دالة new لإنشاء نسخة (Instance)، كما هو موضح في القائمة 8-11.
fn main() {
let mut s = String::new();
}يُنشئ هذا السطر سلسلة نصية جديدة فارغة تسمى s والتي يمكننا لاحقاً تحميل البيانات فيها. غالباً ما يكون لدينا بعض البيانات الأولية التي نريد بدء السلسلة النصية بها. لذلك، نستخدم Method تسمى to_string والمتاحة لأي نوع ينفذ سمة Display (Trait) كما تفعل الـ String Literals. توضح القائمة 8-12 مثالين.
fn main() {
let data = "initial contents";
let s = data.to_string();
// The method also works on a literal directly:
let s = "initial contents".to_string();
}ينشئ هذا الكود سلسلة نصية تحتوي على initial contents.
يمكننا أيضاً استخدام الدالة String::from لإنشاء String من String Literal. الكود في القائمة 8-13 يعادل الكود في القائمة 8-12 الذي يستخدم to_string.
fn main() {
let s = String::from("initial contents");
}لأن الـ Strings تستخدم لأشياء كثيرة، يمكننا استخدام العديد من الواجهات البرمجية العامة (Generic APIs) المختلفة لها، مما يوفر لنا الكثير من الخيارات. قد يبدو بعضها زائداً عن الحاجة، لكن لكل منها مكانه! في هذه الحالة، تقوم String::from و to_string بنفس الشيء، لذا فإن اختيار أحدهما هو مسألة أسلوب ووضوح للقراءة.
تذكر أن الـ Strings مشفرة بـ UTF-8، لذا يمكننا تضمين أي بيانات مشفرة بشكل صحيح فيها، كما هو موضح في القائمة 8-14.
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}كل هذه قيم String صالحة.
تحديث سلسلة نصية (Updating a String)
يمكن لـ String أن تنمو في الحجم ويمكن أن تتغير محتوياتها، تماماً مثل محتويات Vec<T> إذا قمت بدفع (Push) المزيد من البيانات إليها. بالإضافة إلى ذلك، يمكنك استخدام عامل + أو ماكرو format! لدمج (Concatenate) قيم String بسهولة.
الإلحاق باستخدام push_str أو push
يمكننا زيادة حجم String باستخدام push_str لإلحاق String Slice، كما هو موضح في القائمة 8-15.
fn main() {
let mut s = String::from("foo");
s.push_str("bar");
}بعد هذين السطرين، ستحتوي s على foobar. تأخذ push_str شريحة نصية لأننا لا نريد بالضرورة أخذ ملكية (Ownership) المعامل. على سبيل المثال، في الكود في القائمة 8-16، نريد أن نكون قادرين على استخدام s2 بعد إلحاق محتوياتها بـ s1.
fn main() {
let mut s1 = String::from("foo");
let s2 = "bar";
s1.push_str(s2);
println!("s2 is {s2}");
}إذا كانت push_str تأخذ Ownership لـ s2 فلن نتمكن من طباعة قيمتها في السطر الأخير. ومع ذلك، يعمل هذا الكود كما نتوقع!
تأخذ Method الـ push حرفاً واحداً كمعامل وتضيفه إلى الـ String. تضيف القائمة 8-17 الحرف l إلى String باستخدام push.
fn main() {
let mut s = String::from("lo");
s.push('l');
}نتيجة لذلك، ستحتوي s على lol.
الدمج باستخدام + أو format!
غالباً ما ستحتاج إلى دمج سلسلتين نصيتين موجودتين. إحدى الطرق للقيام بذلك هي استخدام عامل + كما هو موضح في القائمة 8-18.
fn main() {
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used
}ستحتوي السلسلة s3 على Hello, world!. السبب في أن s1 لم تعد صالحة بعد الإضافة، والسبب في استخدامنا لمرجع لـ s2 يتعلق بتوقيع (Signature) الـ Method التي يتم استدعاؤها عند استخدام عامل +. يستخدم عامل + دالة add التي يبدو توقيعها كالتالي:
fn add(self, s: &str) -> String {في الـ Standard Library، سترى add معرفة باستخدام الأنواع العامة (Generics) والأنواع المرتبطة (Associated Types). هنا، قمنا باستبدالها بأنواع ملموسة (Concrete Types)، وهو ما يحدث عندما نستدعي هذه الـ Method بقيم String. سنناقش الـ Generics في الفصل 10. يعطينا هذا الـ Signature الأدلة التي نحتاجها لفهم الأجزاء المعقدة في عامل +.
أولاً، تمتلك s2 علامة & مما يعني أننا نضيف Reference للسلسلة الثانية إلى السلسلة الأولى. هذا بسبب معامل s في دالة add: يمكننا فقط إضافة String Slice إلى String؛ لا يمكننا إضافة قيمتي String معاً. ولكن انتظر—نوع &s2 هو &String وليس &str كما هو محدد في المعامل الثاني لـ add. إذاً، لماذا يتم تجميع القائمة 8-18؟
السبب في قدرتنا على استخدام &s2 في استدعاء add هو أن المترجم (Compiler) يمكنه إجبار (Coerce) معامل الـ &String ليصبح &str. عندما نستدعي add تستخدم Rust “إجبار إلغاء الإسناد” (Deref Coercion)، والذي يحول هنا &s2 إلى &s2[..]. سنناقش الـ Deref Coercion بعمق أكبر في الفصل 15. ولأن add لا تأخذ Ownership لمعامل s ستظل s2 قيمة String صالحة بعد هذه العملية.
ثانياً، يمكننا أن نرى في الـ Signature أن add تأخذ Ownership لـ self لأن self لا تمتلك علامة &. هذا يعني أن s1 في القائمة 8-18 سيتم نقلها (Moved) إلى استدعاء add ولن تعد صالحة بعد ذلك. لذا، على الرغم من أن let s3 = s1 + &s2; تبدو وكأنها ستنسخ كلتا السلسلتين وتنشئ واحدة جديدة، إلا أن هذه العبارة تأخذ في الواقع Ownership لـ s1 وتلحق بها نسخة من محتويات s2 ثم تعيد Ownership للنتيجة. بعبارة أخرى، يبدو الأمر وكأنه يتم إجراء الكثير من النسخ، لكنه ليس كذلك؛ التنفيذ أكثر كفاءة من النسخ.
إذا احتجنا لدمج سلاسل نصية متعددة، يصبح سلوك عامل + غير مريح:
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = s1 + "-" + &s2 + "-" + &s3;
}عند هذه النقطة، ستكون s هي tic-tac-toe. مع كل علامات + و " يصبح من الصعب رؤية ما يحدث. لدمج السلاسل النصية بطرق أكثر تعقيداً، يمكننا بدلاً من ذلك استخدام ماكرو format!:
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{s1}-{s2}-{s3}");
}يضبط هذا الكود أيضاً s لتكون tic-tac-toe. يعمل ماكرو format! مثل println! ولكن بدلاً من طباعة المخرجات على الشاشة، فإنه يعيد String بالمحتويات. نسخة الكود التي تستخدم format! أسهل بكثير في القراءة، والكود الناتج عن ماكرو format! يستخدم مراجع (References) بحيث لا يأخذ هذا الاستدعاء Ownership لأي من معاملاته.
الفهرسة في السلاسل النصية (Indexing into Strings)
في العديد من لغات البرمجة الأخرى، يعد الوصول إلى أحرف فردية في سلسلة نصية عن طريق الإشارة إليها بالفهرس (Index) عملية صالحة وشائعة. ومع ذلك، إذا حاولت الوصول إلى أجزاء من String باستخدام صيغة الفهرسة في Rust، فستحصل على خطأ. فكر في الكود غير الصالح في القائمة 8-19.
fn main() {
let s1 = String::from("hi");
let h = s1[0];
}سيؤدي هذا الكود إلى الخطأ التالي:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:3:16
|
3 | let h = s1[0];
| ^ string indices are ranges of `usize`
|
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= help: the following other types implement trait `SliceIndex<T>`:
`usize` implements `SliceIndex<ByteStr>`
`usize` implements `SliceIndex<[T]>`
= note: required for `String` to implement `Index<{integer}>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` (bin "collections") due to 1 previous error
الخطأ يوضح القصة: الـ Strings في Rust لا تدعم الـ Indexing. ولكن لماذا لا؟ للإجابة على هذا السؤال، نحتاج إلى مناقشة كيفية تخزين Rust للـ Strings في الذاكرة.
التمثيل الداخلي (Internal Representation)
الـ String هي غلاف فوق Vec<u8>. دعنا ننظر في بعض أمثلة السلاسل النصية المشفرة بـ UTF-8 من القائمة 8-14. أولاً، هذه:
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}في هذه الحالة، سيكون len هو 4 مما يعني أن الـ Vector الذي يخزن السلسلة "Hola" طوله 4 بايتات. كل حرف من هذه الأحرف يأخذ 1 بايت عند تشفيره بـ UTF-8. ماذا عن السطر التالي؟
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}إذا سُئلت عن طول السلسلة، فقد تقول 12. في الواقع، إجابة Rust هي 24: هذا هو عدد البايتات التي يتطلبها تشفير “Здравствуйте” بـ UTF-8، لأن كل قيمة سلمية لليونيكود (Unicode Scalar Value) في تلك السلسلة تأخذ 2 بايت من التخزين. لذلك، فإن الفهرس في بايتات السلسلة لن يرتبط دائماً بـ Unicode Scalar Value صالحة. للتوضيح، فكر في كود Rust غير الصالح هذا:
let hello = "Здравствуйте";
let answer = &hello[0];أنت تعلم بالفعل أن answer لن تكون З (الحرف الأول). عند التشفير بـ UTF-8، يكون البايت الأول من З هو 208 والثاني هو 151 لذا يبدو أن answer يجب أن تكون في الواقع 208 لكن 208 ليس حرفاً صالحاً بمفرده. من المحتمل ألا يكون إرجاع 208 هو ما يريده المستخدم إذا طلب الحرف الأول من هذه السلسلة؛ ومع ذلك، فهذه هي البيانات الوحيدة التي تمتلكها Rust عند فهرس البايت 0. لا يريد المستخدمون عموماً إرجاع قيمة البايت، حتى لو كانت السلسلة تحتوي فقط على أحرف لاتينية: إذا كان &"hi"[0] كوداً صالحاً يعيد قيمة البايت، فإنه سيعيد 104 وليس h.
الإجابة إذاً هي أنه لتجنب إرجاع قيمة غير متوقعة والتسبب في أخطاء قد لا يتم اكتشافها على الفور، لا تقوم Rust بتجميع هذا الكود على الإطلاق وتمنع سوء الفهم في وقت مبكر من عملية التطوير.
البايتات، والقيم السلمية، وعناقيد الرموز (Bytes, Scalar Values, and Grapheme Clusters)
نقطة أخرى حول UTF-8 هي أن هناك في الواقع ثلاث طرق ذات صلة للنظر في الـ Strings من منظور Rust: كبايتات (Bytes)، وقيم سلمية (Scalar Values)، وعناقيد رموز (Grapheme Clusters) - وهي أقرب شيء لما نسميه أحرفاً.
إذا نظرنا إلى الكلمة الهندية “नमस्ते” المكتوبة بخط الديفاناغاري، فسيتم تخزينها كمتجه من قيم u8 يبدو كالتالي:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
هذا يمثل 18 بايت وهو الكيفية التي تخزن بها الحواسيب هذه البيانات في النهاية. إذا نظرنا إليها كـ Unicode Scalar Values، وهي ما يمثله نوع char في Rust، فستبدو تلك البايتات كالتالي:
['न', 'م', 'س', '्', 'ت', 'े']
هناك ست قيم char هنا، لكن الرابعة والسادسة ليست أحرفاً: إنها علامات تشكيل لا معنى لها بمفردها. أخيراً، إذا نظرنا إليها كـ Grapheme Clusters، فسنحصل على ما يسميه الشخص الأحرف الأربعة التي تشكل الكلمة الهندية:
["न", "م", "स्", "ته"]
توفر Rust طرقاً مختلفة لتفسير بيانات السلسلة الخام التي تخزنها الحواسيب بحيث يمكن لكل برنامج اختيار التفسير الذي يحتاجه، بغض النظر عن اللغة البشرية التي كتبت بها البيانات.
السبب الأخير الذي يجعل Rust لا تسمح لنا بالفهرسة في String للحصول على حرف هو أن عمليات الفهرسة يُتوقع منها دائماً أن تأخذ وقتاً ثابتاً (O(1)). ولكن ليس من الممكن ضمان هذا الأداء مع String لأن Rust ستضطر إلى المرور عبر المحتويات من البداية إلى الفهرس لتحديد عدد الأحرف الصالحة الموجودة.
تشريح السلاسل النصية (Slicing Strings)
غالباً ما تكون الفهرسة في سلسلة نصية فكرة سيئة لأنه ليس من الواضح ما يجب أن يكون عليه النوع المرتجع لعملية فهرسة السلسلة: قيمة بايت، أو حرف، أو عنقود رموز، أو شريحة سلسلة نصية. إذا كنت بحاجة حقاً لاستخدام الفهارس لإنشاء String Slices، فإن Rust تطلب منك أن تكون أكثر تحديداً.
بدلاً من الفهرسة باستخدام [] مع رقم واحد، يمكنك استخدام [] مع نطاق (Range) لإنشاء String Slice يحتوي على بايتات معينة:
#![allow(unused)]
fn main() {
let hello = "Здравствуйте";
let s = &hello[0..4];
}هنا، ستكون s عبارة عن &str تحتوي على أول 4 بايتات من السلسلة. ذكرنا سابقاً أن كل حرف من هذه الأحرف كان 2 بايت، مما يعني أن s ستكون Зд.
إذا حاولنا تشريح جزء فقط من بايتات حرف ما باستخدام شيء مثل &hello[0..1] فستقوم Rust بالهلع (Panic) في وقت التشغيل بنفس الطريقة التي يحدث بها الوصول إلى فهرس غير صالح في متجه:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at src/main.rs:4:19:
byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
يجب عليك توخي الحذر عند إنشاء String Slices باستخدام النطاقات، لأن القيام بذلك قد يؤدي إلى تعطل برنامجك.
التكرار عبر السلاسل النصية (Iterating Over Strings)
أفضل طريقة للتعامل مع أجزاء من السلاسل النصية هي أن تكون صريحاً بشأن ما إذا كنت تريد أحرفاً أم بايتات. بالنسبة لـ Unicode Scalar Values الفردية، استخدم Method الـ chars. استدعاء chars على “Зд” يفصل ويعيد قيمتين من نوع char ويمكنك التكرار (Iterate) عبر النتيجة للوصول إلى كل عنصر:
#![allow(unused)]
fn main() {
for c in "Зд".chars() {
println!("{c}");
}
}سيطبع هذا الكود ما يلي:
З
д
بدلاً من ذلك، تعيد Method الـ bytes كل بايت خام، وهو ما قد يكون مناسباً لمجالك:
#![allow(unused)]
fn main() {
for b in "Зд".bytes() {
println!("{b}");
}
}سيطبع هذا الكود الـ 4 بايتات التي تشكل هذه السلسلة:
208
151
208
180
لكن تأكد من تذكر أن Unicode Scalar Values الصالحة قد تتكون من أكثر من 1 بايت.
الحصول على Grapheme Clusters من السلاسل النصية، كما هو الحال مع خط الديفاناغاري، أمر معقد، لذا لا توفر المكتبة القياسية هذه الوظيفة. تتوفر حزم (Crates) على crates.io إذا كانت هذه هي الوظيفة التي تحتاجها.
التعامل مع تعقيدات السلاسل النصية (Handling the Complexities of Strings)
باختصار، السلاسل النصية معقدة. تتخذ لغات البرمجة المختلفة خيارات مختلفة حول كيفية تقديم هذا التعقيد للمبرمج. اختارت Rust جعل التعامل الصحيح مع بيانات String هو السلوك الافتراضي لجميع برامج Rust، مما يعني أن المبرمجين يضطرون إلى التفكير أكثر في التعامل مع بيانات UTF-8 مسبقاً. تكشف هذه المقايضة عن المزيد من تعقيد السلاسل النصية عما هو ظاهر في لغات البرمجة الأخرى، ولكنها تمنعك من الاضطرار إلى التعامل مع الأخطاء التي تتضمن أحرفاً غير تابعة لـ ASCII لاحقاً في دورة حياة التطوير الخاصة بك.
الخبر السار هو أن الـ Standard Library تقدم الكثير من الوظائف المبنية على نوعي String و &str للمساعدة في التعامل مع هذه المواقف المعقدة بشكل صحيح. تأكد من مراجعة التوثيق للتعرف على Methods مفيدة مثل contains للبحث في سلسلة نصية و replace لاستبدال أجزاء من سلسلة نصية بسلسلة أخرى.
دعنا ننتقل إلى شيء أقل تعقيداً قليلاً: جداول التجزئة (Hash Maps)!
تخزين المفاتيح مع القيم المرتبطة في خرائط التجزئة (Hash Maps)
تخزين المفاتيح مع القيم المرتبطة في الخرائط الهاشية (Hash Maps)
الخريطة الهاشية (Hash Map) هي آخر مجموعة شائعة لدينا. يخزن النوع HashMap<K, V> تعيينًا للمفاتيح (keys) من النوع K إلى القيم (values) من النوع V باستخدام دالة تجزئة (hashing function)، والتي تحدد كيفية وضع هذه keys و values في الذاكرة. تدعم العديد من لغات البرمجة هذا النوع من هياكل البيانات، ولكنها غالبًا ما تستخدم اسمًا مختلفًا، مثل hash، map، object، hash table، dictionary، أو associative array، على سبيل المثال لا الحصر.
تعد Hash Maps مفيدة عندما تريد البحث عن البيانات ليس باستخدام فهرس، كما يمكنك أن تفعل مع المتجهات (vectors)، ولكن باستخدام key يمكن أن يكون من أي نوع. على سبيل المثال، في لعبة ما، يمكنك تتبع نتيجة كل فريق في Hash Map يكون فيها كل key هو اسم الفريق و values هي نتيجة كل فريق. بالنظر إلى اسم الفريق، يمكنك استرداد نتيجته.
سنتناول واجهة برمجة التطبيقات (API) الأساسية لـ Hash Maps في هذا القسم، ولكن هناك المزيد من الميزات مخبأة في الدوال المعرفة على HashMap<K, V> بواسطة المكتبة القياسية (standard library). كما هو الحال دائمًا، تحقق من وثائق standard library لمزيد من المعلومات.
إنشاء Hash Map جديدة
إحدى طرق إنشاء Hash Map فارغة هي استخدام new وإضافة العناصر باستخدام insert. في القائمة 8-20، نتتبع نتائج فريقين هما الأزرق و_الأصفر_. يبدأ الفريق الأزرق بـ 10 نقاط، والفريق الأصفر بـ 50.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
}لاحظ أننا نحتاج أولاً إلى use لـ HashMap من جزء المجموعات في standard library. من بين مجموعاتنا الشائعة الثلاث، هذه هي الأقل استخدامًا، لذا فهي غير مدرجة في الميزات التي يتم جلبها تلقائيًا إلى النطاق (scope) في المقدمة (prelude). تحظى Hash Maps أيضًا بدعم أقل من standard library؛ لا يوجد ماكرو (macro) مدمج لإنشائها، على سبيل المثال.
تمامًا مثل vectors، تخزن Hash Maps بياناتها على الكومة (heap). تحتوي HashMap هذه على keys من النوع سلسلة نصية (String) و values من النوع عدد صحيح 32 بت (i32). مثل vectors، فإن Hash Maps متجانسة (homogeneous): يجب أن تكون جميع keys من نفس النوع، ويجب أن تكون جميع values من نفس النوع.
الوصول إلى القيم في Hash Map
يمكننا الحصول على value من Hash Map عن طريق توفير key الخاص بها لدالة get، كما هو موضح في القائمة 8-21.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
let team_name = String::from("Blue");
let score = scores.get(&team_name).copied().unwrap_or(0);
}هنا، سيكون لـ score القيمة المرتبطة بالفريق الأزرق، وستكون النتيجة 10. تُرجع دالة get خيارًا (Option<&V>)؛ إذا لم تكن هناك value لهذا key في Hash Map، فستُرجع get لا شيء (None). يتعامل هذا البرنامج مع Option عن طريق استدعاء copied للحصول على Option<i32> بدلاً من Option<&i32>، ثم unwrap_or لتعيين score إلى صفر إذا لم يكن لدى scores إدخال (entry) لـ key.
يمكننا التكرار (iterate) على كل زوج key-value في Hash Map بطريقة مماثلة لما نفعله مع vectors، باستخدام حلقة for:
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
for (key, value) in &scores {
println!("{key}: {value}");
}
}سيقوم هذا الكود بطباعة كل زوج بترتيب عشوائي:
Yellow: 50
Blue: 10
إدارة الملكية (Ownership) في Hash Maps
بالنسبة للأنواع التي تطبق سمة النسخ (Copy trait)، مثل i32، يتم نسخ values إلى Hash Map. بالنسبة للقيم المملوكة (owned values) مثل String، سيتم نقل values وستكون Hash Map هي مالك (owner) تلك values، كما هو موضح في القائمة 8-22.
fn main() {
use std::collections::HashMap;
let field_name = String::from("Favorite color");
let field_value = String::from("Blue");
let mut map = HashMap::new();
map.insert(field_name, field_value);
// field_name and field_value are invalid at this point, try using them and
// see what compiler error you get!
}لا يمكننا استخدام المتغيرين field_name و field_value بعد نقلهما إلى Hash Map باستدعاء insert.
إذا قمنا بإدراج مراجع (references) إلى values في Hash Map، فلن يتم نقل values إلى Hash Map. يجب أن تكون values التي تشير إليها references صالحة على الأقل طالما أن Hash Map صالحة. سنتحدث أكثر عن هذه المشكلات في “Validating References with Lifetimes” في الفصل 10.
تحديث Hash Map
على الرغم من أن عدد أزواج key و value قابل للنمو، إلا أن كل key فريد يمكن أن يكون له value واحدة فقط مرتبطة به في كل مرة (ولكن ليس العكس: على سبيل المثال، يمكن أن يكون لكل من الفريق الأزرق والفريق الأصفر القيمة 10 مخزنة في Hash Map scores).
عندما تريد تغيير البيانات في Hash Map، عليك أن تقرر كيفية التعامل مع الحالة التي يكون فيها لـ key قيمة معينة بالفعل. يمكنك استبدال value القديمة بـ value الجديدة، متجاهلاً value القديمة تمامًا. يمكنك الاحتفاظ بـ value القديمة وتجاهل value الجديدة، وإضافة value الجديدة فقط إذا لم يكن لـ key قيمة بالفعل. أو يمكنك دمج value القديمة و value الجديدة. دعونا نرى كيف نفعل كل واحدة من هذه!
الكتابة فوق قيمة (Overwriting a Value)
إذا قمنا بإدراج key و value في Hash Map ثم قمنا بإدراج نفس key بـ value مختلفة، فسيتم استبدال value المرتبطة بهذا key. على الرغم من أن الكود في القائمة 8-23 يستدعي insert مرتين، إلا أن Hash Map ستحتوي على زوج key-value واحد فقط لأننا نقوم بإدراج value لـ key الفريق الأزرق في كلتا المرتين.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Blue"), 25);
println!("{scores:?}");
}سيقوم هذا الكود بطباعة {"Blue": 25}. تم الكتابة فوق (overwritten) القيمة الأصلية 10.
إضافة Key و Value فقط إذا لم يكن Key موجودًا
من الشائع التحقق مما إذا كان key معين موجودًا بالفعل في Hash Map بقيمة، ثم اتخاذ الإجراءات التالية: إذا كان key موجودًا في Hash Map، فيجب أن تظل value الحالية كما هي؛ إذا لم يكن key موجودًا، فقم بإدراجه و value له.
تحتوي Hash Maps على واجهة API خاصة لذلك تسمى entry والتي تأخذ key الذي تريد التحقق منه كمعامل. القيمة المرجعة لدالة entry هي تعداد (enum) يسمى Entry يمثل value قد تكون موجودة أو لا تكون موجودة. لنفترض أننا نريد التحقق مما إذا كان key للفريق الأصفر له value مرتبطة به. إذا لم يكن كذلك، فنريد إدراج value 50، ونفس الشيء للفريق الأزرق. باستخدام واجهة API لـ entry، يبدو الكود كما في القائمة 8-24.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.entry(String::from("Yellow")).or_insert(50);
scores.entry(String::from("Blue")).or_insert(50);
println!("{scores:?}");
}تم تعريف دالة or_insert على Entry لإرجاع مرجع قابل للتغيير (mutable reference) إلى value لـ key الخاص بـ Entry المقابل إذا كان هذا key موجودًا، وإذا لم يكن كذلك، فإنه يدرج المعامل كـ value الجديدة لهذا key ويعيد mutable reference إلى value الجديدة. هذه التقنية أنظف بكثير من كتابة المنطق بأنفسنا، وبالإضافة إلى ذلك، تتوافق بشكل أفضل مع مدقق الاستعارة (borrow checker).
سيؤدي تشغيل الكود في القائمة 8-24 إلى طباعة {"Yellow": 50, "Blue": 10}. سيقوم الاستدعاء الأول لـ entry بإدراج key للفريق الأصفر بـ value 50 لأن الفريق الأصفر ليس لديه value بالفعل. لن يغير الاستدعاء الثاني لـ entry Hash Map، لأن الفريق الأزرق لديه value 10 بالفعل.
تحديث قيمة بناءً على القيمة القديمة
حالة استخدام شائعة أخرى لـ Hash Maps هي البحث عن value لـ key ثم تحديثها بناءً على value القديمة. على سبيل المثال، تعرض القائمة 8-25 كودًا يحسب عدد مرات ظهور كل كلمة في نص ما. نستخدم Hash Map مع الكلمات كـ keys ونزيد value لتتبع عدد المرات التي رأينا فيها تلك الكلمة. إذا كانت هذه هي المرة الأولى التي نرى فيها كلمة، فسنقوم أولاً بإدراج value 0.
fn main() {
use std::collections::HashMap;
let text = "hello world wonderful world";
let mut map = HashMap::new();
for word in text.split_whitespace() {
let count = map.entry(word).or_insert(0);
*count += 1;
}
println!("{map:?}");
}سيقوم هذا الكود بطباعة {"world": 2, "hello": 1, "wonderful": 1}. قد ترى أزواج key-value نفسها مطبوعة بترتيب مختلف: تذكر من “Accessing Values in a Hash Map” أن التكرار على Hash Map يحدث بترتيب عشوائي.
تُرجع دالة split_whitespace مكررًا (iterator) على الشرائح الفرعية (subslices)، مفصولة بمسافات بيضاء، لـ value في text. تُرجع دالة or_insert مرجعًا قابلًا للتغيير (&mut V) إلى value لـ key المحدد. هنا، نقوم بتخزين هذا mutable reference في المتغير count، لذلك من أجل التعيين لتلك value، يجب علينا أولاً فك الإشارة (dereference) لـ count باستخدام النجمة (*). يخرج mutable reference من النطاق في نهاية حلقة for، لذا فإن كل هذه التغييرات آمنة ومسموح بها بواسطة قواعد الاستعارة (borrowing rules).
دوال التجزئة (Hashing Functions)
بشكل افتراضي، تستخدم HashMap دالة تجزئة تسمى سيبهاش (SipHash) يمكن أن توفر مقاومة لهجمات حجب الخدمة (denial-of-service (DoS) attacks) التي تتضمن جداول التجزئة (hash tables)1. هذه ليست أسرع خوارزمية تجزئة متاحة، ولكن المقايضة بين الأمان الأفضل الذي يأتي مع انخفاض الأداء تستحق العناء. إذا قمت بتحليل الكود الخاص بك ووجدت أن دالة hash الافتراضية بطيئة جدًا لأغراضك، فيمكنك التبديل إلى دالة أخرى عن طريق تحديد مجزئ (hasher) مختلف. الـ hasher هو نوع يطبق سمة BuildHasher (BuildHasher trait). سنتحدث عن traits وكيفية تطبيقها في Chapter 10. ليس عليك بالضرورة تطبيق hasher الخاص بك من البداية؛ يحتوي crates.io على مكتبات يشاركها مستخدمو Rust الآخرون توفر hashers تطبق العديد من خوارزميات hash الشائعة.
ملخص
ستوفر vectors و strings و Hash Maps قدرًا كبيرًا من الوظائف الضرورية في البرامج عندما تحتاج إلى تخزين البيانات والوصول إليها وتعديلها. فيما يلي بعض التمارين التي يجب أن تكون الآن مجهزًا لحلها:
- بالنظر إلى قائمة من الأعداد الصحيحة، استخدم vector وأرجع الوسيط (median) (عندما يتم فرزها، القيمة في الموضع الأوسط) والمنوال (mode) (القيمة التي تحدث في أغلب الأحيان؛ ستكون Hash Map مفيدة هنا) للقائمة.
- قم بتحويل strings إلى اللاتينية الخنزيرية (Pig Latin). يتم نقل الحرف الساكن الأول من كل كلمة إلى نهاية الكلمة ويتم إضافة ay، لذا تصبح first هي irst-fay. الكلمات التي تبدأ بحرف متحرك يتم إضافة hay إلى نهايتها بدلاً من ذلك (apple تصبح apple-hay). ضع في اعتبارك التفاصيل المتعلقة بترميز UTF-8 (
UTF-8 encoding)! - باستخدام Hash Map و vectors، قم بإنشاء واجهة نصية للسماح للمستخدم بإضافة أسماء الموظفين إلى قسم في شركة؛ على سبيل المثال، “Add Sally to Engineering” أو “Add Amir to Sales”. بعد ذلك، اسمح للمستخدم باسترداد قائمة بجميع الأشخاص في قسم أو جميع الأشخاص في الشركة حسب القسم، مرتبة أبجديًا.
تصف وثائق API لـ standard library الدوال التي تحتوي عليها vectors و strings و Hash Maps والتي ستكون مفيدة لهذه التمارين!
نحن ندخل في برامج أكثر تعقيدًا حيث يمكن أن تفشل العمليات، لذا فقد حان الوقت المثالي لمناقشة معالجة الأخطاء. سنفعل ذلك لاحقًا!
معالجة الأخطاء (Error Handling)
الأخطاء هي حقيقة واقعة في البرمجيات، لذا تمتلك Rust عدداً من الميزات للتعامل مع المواقف التي يحدث فيها خطأ ما. في كثير من الحالات، تطلب منك Rust الإقرار باحتمالية حدوث خطأ واتخاذ إجراء ما قبل أن يتم تجميع الكود الخاص بك. هذا المتطلب يجعل برنامجك أكثر قوة من خلال ضمان اكتشافك للأخطاء ومعالجتها بشكل مناسب قبل نشر الكود الخاص بك في بيئة الإنتاج!
تقسم Rust الأخطاء إلى فئتين رئيسيتين: أخطاء قابلة للاسترداد (Recoverable) وأخطاء غير قابلة للاسترداد (Unrecoverable). بالنسبة لـ “الخطأ القابل للاسترداد” (Recoverable Error)، مثل خطأ “الملف غير موجود”، فمن المرجح أننا نريد فقط إبلاغ المستخدم بالمشكلة وإعادة محاولة العملية. أما “الأخطاء غير القابلة للاسترداد” (Unrecoverable Errors) فهي دائماً أعراض لوجود أخطاء برمجية (Bugs)، مثل محاولة الوصول إلى موقع يتجاوز نهاية المصفوفة، ولذا نريد إيقاف البرنامج على الفور.
لا تفرق معظم اللغات بين هذين النوعين من الأخطاء وتتعامل مع كليهما بنفس الطريقة، باستخدام آليات مثل “الاستثناءات” (Exceptions). لا تمتلك Rust استثناءات؛ بدلاً من ذلك، لديها النوع Result<T, E> للأخطاء الـ Recoverable، وماكرو panic! الذي يوقف التنفيذ عندما يواجه البرنامج خطأ Unrecoverable. يغطي هذا الفصل استدعاء panic! أولاً ثم يتحدث عن إرجاع قيم Result<T, E>. بالإضافة إلى ذلك، سنستكشف الاعتبارات عند تحديد ما إذا كنت ستحاول الاسترداد من خطأ ما أو إيقاف التنفيذ.
الأخطاء غير القابلة للاسترداد باستخدام panic!
الأخطاء غير القابلة للاسترداد باستخدام panic! (Unrecoverable Errors with panic!)
أحيانًا تحدث أشياء سيئة في الكود الخاص بك، ولا يوجد شيء يمكنك القيام به حيال ذلك. في هذه الحالات، تمتلك Rust ماكرو (macro) panic!. هناك طريقتان للتسبب في حدوث ذعر (panic) في الممارسة العملية: عن طريق اتخاذ إجراء يتسبب في ذعر الكود الخاص بنا (مثل الوصول إلى مصفوفة بعد نهايتها) أو عن طريق استدعاء ماكرو panic! صراحةً. في كلتا الحالتين، نتسبب في حدوث ذعر في برنامجنا. بشكل افتراضي، ستقوم حالات الذعر هذه بطباعة رسالة فشل، وفك المكدس (unwind)، وتنظيف المكدس (stack)، ثم الخروج. عبر متغير بيئة (environment variable)، يمكنك أيضًا جعل Rust تعرض مكدس الاستدعاءات (call stack) عند حدوث ذعر لتسهيل تتبع مصدر الذعر.
فك المكدس أو الإجهاض استجابةً للذعر (Unwinding the Stack or Aborting in Response to a Panic)
بشكل افتراضي، عندما يحدث ذعر، يبدأ البرنامج في فك المكدس (unwinding)، مما يعني أن Rust تعود إلى الوراء في المكدس وتنظف البيانات من كل دالة تصادفها. ومع ذلك، فإن العودة للخلف والتنظيف يتطلب الكثير من العمل. لذلك تسمح لك Rust باختيار البديل وهو الإجهاض (aborting) الفوري، والذي ينهي البرنامج دون تنظيف.
ستحتاج الذاكرة التي كان البرنامج يستخدمها بعد ذلك إلى التنظيف بواسطة نظام التشغيل. إذا كنت بحاجة في مشروعك إلى جعل الملف الثنائي الناتج أصغر ما يمكن، فيمكنك التبديل من فك المكدس إلى الإجهاض عند حدوث ذعر عن طريق إضافة
panic = 'abort'إلى أقسام[profile]المناسبة في ملف Cargo.toml الخاص بك. على سبيل المثال، إذا كنت تريد الإجهاض عند حدوث ذعر في وضع الإصدار (release mode)، فأضف هذا:[profile.release] panic = 'abort'
دعنا نحاول استدعاء panic! في برنامج بسيط:
fn main() {
panic!("crash and burn");
}عند تشغيل البرنامج، سترى شيئًا كهذا:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:2:5:
crash and burn
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
يتسبب استدعاء panic! في رسالة الخطأ الواردة في السطرين الأخيرين. يوضح السطر الأول رسالة الذعر الخاصة بنا والمكان في كود المصدر الخاص بنا حيث حدث الذعر: يشير src/main.rs:2:5 إلى أنه السطر الثاني، الحرف الخامس من ملف src/main.rs الخاص بنا.
في هذه الحالة، السطر المشار إليه هو جزء من الكود الخاص بنا، وإذا ذهبنا إلى ذلك السطر، فسنرى استدعاء ماكرو panic!. في حالات أخرى، قد يكون استدعاء panic! في كود يستدعيه الكود الخاص بنا، وسيكون اسم الملف ورقم السطر الوارد في رسالة الخطأ هما كود شخص آخر حيث يتم استدعاء ماكرو panic! وليس سطر الكود الخاص بنا الذي أدى في النهاية إلى استدعاء panic!.
يمكننا استخدام تتبع الخلفية (backtrace) للدوال التي جاء منها استدعاء panic! لمعرفة جزء الكود الخاص بنا الذي يسبب المشكلة. لفهم كيفية استخدام تتبع الخلفية لـ panic! دعنا ننظر إلى مثال آخر ونرى كيف يبدو الأمر عندما يأتي استدعاء panic! من مكتبة بسبب خطأ في الكود الخاص بنا بدلاً من استدعاء الكود الخاص بنا للماكرو مباشرةً. تحتوي القائمة 9-1 على بعض الكود الذي يحاول الوصول إلى فهرس (index) في متجه (vector) يتجاوز نطاق الفهارس الصالحة.
fn main() {
let v = vec![1, 2, 3];
v[99];
}هنا، نحاول الوصول إلى العنصر رقم 100 في المتجه الخاص بنا (الموجود في الفهرس 99 لأن الفهرسة تبدأ من الصفر)، لكن المتجه يحتوي على ثلاثة عناصر فقط. في هذه الحالة، ستصاب Rust بالذعر. من المفترض أن يؤدي استخدام [] إلى إرجاع عنصر، ولكن إذا مررت فهرسًا غير صالح، فلا يوجد عنصر يمكن لـ Rust إرجاعه هنا ويكون صحيحًا.
في لغة C، تعد محاولة القراءة بعد نهاية هيكل البيانات سلوكًا غير محدد (undefined behavior). قد تحصل على أي شيء موجود في موقع الذاكرة الذي يتوافق مع ذلك العنصر في هيكل البيانات، على الرغم من أن الذاكرة لا تنتمي إلى ذلك الهيكل. يسمى هذا قراءة زائدة للمخزن المؤقت (buffer overread) ويمكن أن يؤدي إلى ثغرات أمنية إذا تمكن المهاجم من التلاعب بالفهرس بطريقة تمكنه من قراءة بيانات لا ينبغي السماح له بها والمخزنة بعد هيكل البيانات.
لحماية برنامجك من هذا النوع من الثغرات، إذا حاولت قراءة عنصر في فهرس غير موجود، فستوقف Rust التنفيذ وترفض الاستمرار. دعنا نجرب ذلك ونرى:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
يشير هذا الخطأ إلى السطر 4 من ملف main.rs الخاص بنا حيث نحاول الوصول إلى الفهرس 99 للمتجه في v.
يخبرنا سطر note: أنه يمكننا تعيين متغير البيئة RUST_BACKTRACE للحصول على تتبع خلفية (backtrace) لما حدث بالضبط وتسبب في الخطأ. تتبع الخلفية هو قائمة بجميع الدوال التي تم استدعاؤها للوصول إلى هذه النقطة. تعمل تتبعات الخلفية في Rust كما تفعل في اللغات الأخرى: المفتاح لقراءة تتبع الخلفية هو البدء من الأعلى والقراءة حتى ترى الملفات التي كتبتها. هذه هي النقطة التي نشأت منها المشكلة. الأسطر الموجودة فوق تلك النقطة هي كود استدعاه الكود الخاص بك؛ الأسطر الموجودة أسفلها هي كود استدعى الكود الخاص بك. قد تتضمن هذه الأسطر السابقة واللاحقة كود Rust الأساسي (core)، أو كود المكتبة القياسية (standard library)، أو الصناديق (crates) التي تستخدمها. دعنا نحاول الحصول على تتبع خلفية عن طريق تعيين متغير البيئة RUST_BACKTRACE إلى أي قيمة باستثناء 0. تعرض القائمة 9-2 مخرجات مشابهة لما ستراه.
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: rust_begin_unwind
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/std/src/panicking.rs:692:5
1: core::panicking::panic_fmt
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:273:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:16:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs:3361:9
6: panic::main
at ./src/main.rs:4:6
7: core::ops::function::FnOnce::call_once
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
هذا الكثير من المخرجات! قد تختلف المخرجات الدقيقة التي تراها اعتمادًا على نظام التشغيل وإصدار Rust الخاص بك. من أجل الحصول على تتبعات خلفية بهذه المعلومات، يجب تمكين رموز التصحيح (debug symbols). يتم تمكين رموز التصحيح افتراضيًا عند استخدام cargo build أو cargo run بدون علم --release كما فعلنا هنا.
في المخرجات في القائمة 9-2، يشير السطر 6 من تتبع الخلفية إلى السطر في مشروعنا الذي يسبب المشكلة: السطر 4 من src/main.rs. إذا كنا لا نريد أن يصاب برنامجنا بالذعر، فيجب أن نبدأ تحقيقنا في الموقع الذي يشير إليه السطر الأول الذي يذكر ملفًا كتبناه. في القائمة 9-1، حيث كتبنا عمدًا كودًا من شأنه أن يسبب ذعرًا، فإن طريقة إصلاح الذعر هي عدم طلب عنصر يتجاوز نطاق فهارس المتجه. عندما يصاب الكود الخاص بك بالذعر في المستقبل، ستحتاج إلى معرفة الإجراء الذي يتخذه الكود مع أي قيم للتسبب في الذعر وما يجب أن يفعله الكود بدلاً من ذلك.
سنعود إلى panic! ومتى يجب ولا يجب استخدام panic! للتعامل مع ظروف الخطأ في قسم “استخدام panic! أو عدم استخدامه” لاحقًا في هذا الفصل. بعد ذلك، سننظر في كيفية الاسترداد من خطأ باستخدام Result.
الأخطاء القابلة للاسترداد باستخدام Result
الأخطاء القابلة للاسترداد باستخدام Result (Recoverable Errors with Result)
معظم الأخطاء ليست خطيرة بما يكفي لتتطلب إيقاف البرنامج بالكامل. أحياناً عندما تفشل دالة (function)، يكون ذلك لسبب يمكنك تفسيره والاستجابة له بسهولة. على سبيل المثال، إذا حاولت فتح ملف وفشلت تلك العملية لأن الملف غير موجود، فقد ترغب في إنشاء الملف بدلاً من إنهاء العملية (process).
تذكر من قسم “معالجة الفشل المحتمل باستخدام Result” في الفصل الثاني أن تعداد (enum) الـ Result مُعرف بأنه يحتوي على متغيرين (variants)، هما Ok و Err ، كما يلي:
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}الـ T والـ E هما معاملات أنواع عامة (generic type parameters): سنناقش الأنواع العامة (generics) بمزيد من التفصيل في الفصل العاشر. ما تحتاج لمعرفته الآن هو أن T يمثل نوع القيمة التي سيتم إرجاعها في حالة النجاح داخل variant الـ Ok ، و E يمثل نوع الخطأ الذي سيتم إرجاعه في حالة الفشل داخل variant الـ Err. ولأن Result يحتوي على معاملات الأنواع العامة هذه، يمكننا استخدام نوع Result والدوال المعرفة عليه في العديد من المواقف المختلفة حيث قد تختلف قيمة النجاح وقيمة الخطأ التي نريد إرجاعها.
دعونا نستدعي function تعيد قيمة Result لأن الـ function قد تفشل. في القائمة 9-3، نحاول فتح ملف.
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
}نوع الإرجاع لـ File::open هو Result<T, E>. تم ملء المعامل العام T بواسطة تطبيق File::open بنوع قيمة النجاح، std::fs::File ، وهو مقبض ملف (file handle). نوع E المستخدم في قيمة الخطأ هو std::io::Error. نوع الإرجاع هذا يعني أن استدعاء File::open قد ينجح ويعيد file handle يمكننا القراءة منه أو الكتابة إليه. قد يفشل استدعاء الـ function أيضاً: على سبيل المثال، قد لا يكون الملف موجوداً، أو قد لا نمتلك الإذن للوصول إلى الملف. تحتاج function الـ File::open إلى طريقة لإخبارنا ما إذا كانت قد نجحت أو فشلت وفي نفس الوقت تعطينا إما الـ file handle أو معلومات الخطأ. هذه المعلومات هي بالضبط ما ينقله enum الـ Result.
في الحالة التي ينجح فيها File::open ، ستكون القيمة في المتغير greeting_file_result مثيلاً (instance) من Ok يحتوي على file handle. وفي الحالة التي يفشل فيها، ستكون القيمة في greeting_file_result instance من Err يحتوي على مزيد من المعلومات حول نوع الخطأ الذي حدث.
نحتاج إلى الإضافة على الكود في القائمة 9-3 لاتخاذ إجراءات مختلفة اعتماداً على القيمة التي يعيدها File::open. توضح القائمة 9-4 إحدى طرق معالجة Result باستخدام أداة أساسية، وهي تعبير المطابقة (match expression) الذي ناقشناه في الفصل السادس.
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => panic!("Problem opening the file: {error:?}"),
};
}لاحظ أنه، مثل enum الـ Option ، تم جلب enum الـ Result ومتغيراته إلى النطاق (scope) بواسطة التمهيد (prelude)، لذا لا نحتاج إلى تحديد Result:: قبل متغيرات Ok و Err في أذرع (arms) الـ match.
عندما تكون النتيجة Ok ، سيعيد هذا الكود قيمة file الداخلية من variant الـ Ok ، ثم نقوم بتعيين قيمة file handle تلك للمتغير greeting_file. بعد الـ match ، يمكننا استخدام الـ file handle للقراءة أو الكتابة.
الذراع الآخر للـ match يعالج الحالة التي نحصل فيها على قيمة Err من File::open. في هذا المثال، اخترنا استدعاء ماكرو (macro) panic!. إذا لم يكن هناك ملف باسم hello.txt في دليلنا الحالي وقمنا بتشغيل هذا الكود، فسنرى المخرجات التالية من macro الـ panic!:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at src/main.rs:8:23:
Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
كالعادة، تخبرنا هذه المخرجات بالضبط بما حدث من خطأ.
المطابقة على أخطاء مختلفة (Matching on Different Errors)
الكود في القائمة 9-4 سيقوم بـ panic! بغض النظر عن سبب فشل File::open. ومع ذلك، نريد اتخاذ إجراءات مختلفة لأسباب فشل مختلفة. إذا فشل File::open لأن الملف غير موجود، نريد إنشاء الملف وإرجاع الـ handle للملف الجديد. إذا فشل File::open لأي سبب آخر - على سبيل المثال، لأننا لم نمتلك الإذن لفتح الملف - فلا نزال نريد أن يقوم الكود بـ panic! بنفس الطريقة التي فعلها في القائمة 9-4. لهذا، نضيف match expression داخلياً، كما هو موضح في القائمة 9-5.
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {e:?}"),
},
_ => {
panic!("Problem opening the file: {error:?}");
}
},
};
}نوع القيمة التي يعيدها File::open داخل variant الـ Err هو io::Error ، وهو هيكل (struct) توفره المكتبة القياسية (standard library). هذا الـ struct لديه method تسمى kind ، يمكننا استدعاؤها للحصول على قيمة io::ErrorKind. يتم توفير enum الـ io::ErrorKind بواسطة الـ standard library ويحتوي على variants تمثل الأنواع المختلفة من الأخطاء التي قد تنتج عن عملية io. الـ variant الذي نريد استخدامه هو ErrorKind::NotFound ، والذي يشير إلى أن الملف الذي نحاول فتحه غير موجود بعد. لذا، نقوم بالمطابقة على greeting_file_result ، ولكن لدينا أيضاً مطابقة داخلية على error.kind().
الشرط الذي نريد التحقق منه في الـ match الداخلي هو ما إذا كانت القيمة التي تعيدها error.kind() هي variant الـ NotFound من enum الـ ErrorKind. إذا كانت كذلك، نحاول إنشاء الملف باستخدام File::create. ومع ذلك، ولأن File::create قد يفشل أيضاً، نحتاج إلى ذراع ثانٍ في الـ match expression الداخلي. عندما لا يمكن إنشاء الملف، يتم طباعة رسالة خطأ مختلفة. يبقى الذراع الثاني للـ match الخارجي كما هو، بحيث يصاب البرنامج بالذعر عند حدوث أي خطأ بخلاف خطأ فقدان الملف.
بدائل لاستخدام
matchمعResult<T, E>هذا الكثير من الـ
match! تعبيرmatchمفيد جداً ولكنه أيضاً بدائي (primitive) للغاية. في الفصل الثالث عشر، ستتعلم عن الإغلاقات (closures)، والتي تُستخدم مع العديد من الـ methods المعرفة علىResult<T, E>. يمكن أن تكون هذه الـ methods أكثر إيجازاً من استخدامmatchعند التعامل مع قيمResult<T, E>في الكود الخاص بك.على سبيل المثال، إليك طريقة أخرى لكتابة نفس المنطق الموضح في القائمة 9-5، هذه المرة باستخدام closures و method الـ
unwrap_or_else:use std::fs::File; use std::io::ErrorKind; fn main() { let greeting_file = File::open("hello.txt").unwrap_or_else(|error| { if error.kind() == ErrorKind::NotFound { File::create("hello.txt").unwrap_or_else(|error| { panic!("Problem creating the file: {error:?}"); }) } else { panic!("Problem opening the file: {error:?}"); } }); }على الرغم من أن هذا الكود له نفس سلوك القائمة 9-5، إلا أنه لا يحتوي على أي
match expressionsوهو أكثر نظافة في القراءة. عد إلى هذا المثال بعد قراءة الفصل الثالث عشر وابحث عن method الـunwrap_or_elseفي توثيق الـ standard library. العديد من هذه الـ methods يمكنها تنظيفmatch expressionsالضخمة والمتداخلة عند التعامل مع الأخطاء.
اختصارات للذعر عند حدوث خطأ (Shortcuts for Panic on Error)
استخدام match يعمل بشكل جيد بما فيه الكفاية، ولكنه قد يكون مطولاً بعض الشيء ولا يوصل النية (intent) دائماً بشكل جيد. نوع Result<T, E> لديه العديد من الدوال المساعدة (helper methods) المعرفة عليه للقيام بمهام متنوعة وأكثر تحديداً. الـ method المسمى unwrap هو طريقة اختصار مطبقة تماماً مثل match expression الذي كتبناه في القائمة 9-4. إذا كانت قيمة Result هي variant الـ Ok ، سيعيد unwrap القيمة الموجودة داخل Ok. وإذا كان Result هو variant الـ Err ، سيقوم unwrap باستدعاء macro الـ panic! نيابة عنا. إليك مثال على unwrap قيد العمل:
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt").unwrap();
}إذا قمنا بتشغيل هذا الكود بدون ملف hello.txt ، فسنرى رسالة خطأ من استدعاء panic! الذي تقوم به method الـ unwrap:
thread 'main' panicked at src/main.rs:4:49:
called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
وبالمثل، تتيح لنا method الـ expect اختيار رسالة خطأ الـ panic!. استخدام expect بدلاً من unwrap وتقديم رسائل خطأ جيدة يمكن أن يوصل intent الخاص بك ويجعل تتبع مصدر الـ panic أسهل. صيغة (syntax) الـ expect تبدو هكذا:
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")
.expect("hello.txt should be included in this project");
}نستخدم expect بنفس طريقة unwrap: لإرجاع file handle أو استدعاء macro الـ panic!. رسالة الخطأ المستخدمة بواسطة expect في استدعائها لـ panic! ستكون المعامل (parameter) الذي نمرره لـ expect ، بدلاً من رسالة panic! الافتراضية التي يستخدمها unwrap. إليك كيف يبدو الأمر:
thread 'main' panicked at src/main.rs:5:10:
hello.txt should be included in this project: Os { code: 2, kind: NotFound, message: "No such file or directory" }
في الكود ذو جودة الإنتاج، يختار معظم مبرمجي Rust (Rustaceans) استخدام expect بدلاً من unwrap ويعطون سياقاً أكبر حول سبب توقع نجاح العملية دائماً. بهذه الطريقة، إذا ثبت خطأ افتراضاتك يوماً ما، فستمتلك المزيد من المعلومات لاستخدامها في تصحيح الأخطاء (debugging).
نشر الأخطاء (Propagating Errors)
عندما يستدعي تطبيق function شيئاً قد يفشل، بدلاً من معالجة الخطأ داخل الـ function نفسها، يمكنك إرجاع الخطأ إلى الكود المستدعي حتى يتمكن من تحديد ما يجب فعله. يُعرف هذا باسم نشر (propagating) الخطأ ويعطي تحكماً أكبر للكود المستدعي، حيث قد تتوفر معلومات أو منطق أكثر يملي كيفية معالجة الخطأ مما هو متاح لديك في سياق الكود الخاص بك.
على سبيل المثال، توضح القائمة 9-6 function تقرأ اسم مستخدم من ملف. إذا لم يكن الملف موجوداً أو لم يمكن قراءته، فستعيد هذه الـ function تلك الأخطاء إلى الكود الذي استدعى الـ function.
<Listing number="9-6" file-name="src/main.rs" caption="A function that returns errors to the calling code using `match` ">
```rust
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let username_file_result = File::open("hello.txt");
let mut username_file = match username_file_result {
Ok(file) => file,
Err(e) => return Err(e),
};
let mut username = String::new();
match username_file.read_to_string(&mut username) {
Ok(_) => Ok(username),
Err(e) => Err(e),
}
}
يمكن كتابة هذه الـ function بطريقة أقصر بكثير، لكننا سنبدأ بالقيام بالكثير منها يدوياً لاستكشاف معالجة الأخطاء؛ وفي النهاية، سنعرض الطريقة الأقصر. دعونا ننظر إلى نوع الإرجاع للـ function أولاً: Result<String, io::Error>. هذا يعني أن الـ function تعيد قيمة من النوع Result<T, E> ، حيث تم ملء المعامل العام T بالنوع الملموس String وتم ملء المعامل العام E بالنوع الملموس io::Error.
إذا نجحت هذه الـ function دون أي مشاكل، فسيستلم الكود الذي يستدعي هذه الـ function قيمة Ok تحمل String - وهو username الذي قرأته هذه الـ function من الملف. وإذا واجهت هذه الـ function أي مشاكل، فسيستلم الكود المستدعي قيمة Err تحمل instance من io::Error يحتوي على مزيد من المعلومات حول ماهية المشاكل. لقد اخترنا io::Error كنوع إرجاع لهذه الـ function لأن هذا هو نوع قيمة الخطأ التي تعيدها كلتا العمليتين اللتين نستدعيهما في جسم (body) هذه الـ function واللتين قد تفشلان: function الـ File::open و method الـ read_to_string.
يبدأ body الـ function باستدعاء function الـ File::open. ثم نعالج قيمة Result باستخدام match مشابه للـ match في القائمة 9-4. إذا نجح File::open ، يصبح file handle الموجود في متغير النمط (pattern variable) المسمى file هو القيمة في المتغير القابل للتغيير username_file وتستمر الـ function. وفي حالة الـ Err ، بدلاً من استدعاء panic! ، نستخدم الكلمة المفتاحية return للخروج مبكراً من الـ function بالكامل وتمرير قيمة الخطأ من File::open ، الموجودة الآن في pattern variable المسمى e ، مرة أخرى إلى الكود المستدعي كقيمة خطأ لهذه الـ function.
لذا، إذا كان لدينا file handle في username_file ، تقوم الـ function بعد ذلك بإنشاء String جديد في المتغير username وتستدعي method الـ read_to_string على file handle الموجود في username_file لقراءة محتويات الملف إلى username. يعيد method الـ read_to_string أيضاً Result لأنه قد يفشل، حتى لو نجح File::open. لذا، نحتاج إلى match آخر لمعالجة ذلك الـ Result: إذا نجح read_to_string ، فقد نجحت الـ function الخاصة بنا، ونعيد اسم المستخدم من الملف الموجود الآن في username مغلفاً بـ Ok. وإذا فشل read_to_string ، فإننا نعيد قيمة الخطأ بنفس الطريقة التي أعدنا بها قيمة الخطأ في الـ match الذي عالج قيمة إرجاع File::open. ومع ذلك، لا نحتاج إلى قول return صراحة، لأن هذا هو التعبير الأخير في الـ function.
سيتعامل الكود الذي يستدعي هذا الكود بعد ذلك مع الحصول على إما قيمة Ok تحتوي على اسم مستخدم أو قيمة Err تحتوي على io::Error. الأمر متروك للكود المستدعي ليقرر ما سيفعله بتلك القيم. إذا حصل الكود المستدعي على قيمة Err ، فيمكنه استدعاء panic! وإيقاف البرنامج، أو استخدام اسم مستخدم افتراضي، أو البحث عن اسم المستخدم من مكان آخر غير الملف، على سبيل المثال. ليس لدينا معلومات كافية عما يحاول الكود المستدعي فعله حقاً، لذا فنحن ننشر جميع معلومات النجاح أو الخطأ للأعلى ليتعامل معها بشكل مناسب.
هذا النمط من نشر الأخطاء شائع جداً في Rust لدرجة أن Rust توفر عامل علامة الاستفهام (question mark operator) ? لجعل ذلك أسهل.
اختصار عامل الـ ? (The ? Operator Shortcut)
توضح القائمة 9-7 تطبيقاً لـ read_username_from_file له نفس وظيفة القائمة 9-6، ولكن هذا التطبيق يستخدم عامل الـ ?.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username_file = File::open("hello.txt")?;
let mut username = String::new();
username_file.read_to_string(&mut username)?;
Ok(username)
}
}عامل الـ ? الموضوع بعد قيمة Result مُعرف ليعمل بنفس الطريقة تقريباً مثل match expressions التي عرفناها لمعالجة قيم Result في القائمة 9-6. إذا كانت قيمة الـ Result هي Ok ، فسيتم إرجاع القيمة الموجودة داخل الـ Ok من هذا التعبير، وسيستمر البرنامج. وإذا كانت القيمة هي Err ، فسيتم إرجاع الـ Err من الـ function بالكامل كما لو كنا قد استخدمنا الكلمة المفتاحية return بحيث يتم نشر قيمة الخطأ إلى الكود المستدعي.
هناك فرق بين ما يفعله match expression من القائمة 9-6 وما يفعله عامل الـ ?: قيم الخطأ التي يتم استدعاء عامل الـ ? عليها تمر عبر function الـ from ، المعرفة في سمة (trait) الـ From في الـ standard library، والتي تُستخدم لتحويل القيم من نوع إلى آخر. عندما يستدعي عامل الـ ? الـ function المسمى from ، يتم تحويل نوع الخطأ المستلم إلى نوع الخطأ المعرف في نوع إرجاع الـ function الحالية. هذا مفيد عندما تعيد function نوع خطأ واحداً لتمثيل جميع الطرق التي قد تفشل بها الـ function، حتى لو كانت الأجزاء قد تفشل لأسباب عديدة ومختلفة.
على سبيل المثال، يمكننا تغيير function الـ read_username_from_file في القائمة 9-7 لتعيد نوع خطأ مخصصاً باسم OurError نقوم بتعريفه. إذا قمنا أيضاً بتعريف impl From<io::Error> for OurError لإنشاء instance من OurError من io::Error ، فإن استدعاءات عامل الـ ? في body الـ read_username_from_file ستستدعي from وتحول أنواع الأخطاء دون الحاجة إلى إضافة أي كود آخر إلى الـ function.
في سياق القائمة 9-7، فإن الـ ? في نهاية استدعاء File::open سيعيد القيمة الموجودة داخل Ok إلى المتغير username_file. وإذا حدث خطأ، فسيقوم عامل الـ ? بالعودة مبكراً من الـ function بالكامل ويعطي أي قيمة Err للكود المستدعي. وينطبق الشيء نفسه على الـ ? في نهاية استدعاء read_to_string.
يزيل عامل الـ ? الكثير من الكود المتكرر (boilerplate) ويجعل تطبيق هذه الـ function أبسط. يمكننا حتى تقصير هذا الكود أكثر عن طريق ربط (chaining) استدعاءات الـ methods مباشرة بعد الـ ? ، كما هو موضح في القائمة 9-8.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username = String::new();
File::open("hello.txt")?.read_to_string(&mut username)?;
Ok(username)
}
}لقد نقلنا إنشاء الـ String الجديد في username إلى بداية الـ function؛ هذا الجزء لم يتغير. وبدلاً من إنشاء متغير username_file ، قمنا بربط استدعاء read_to_string مباشرة بنتيجة File::open("hello.txt")?. لا يزال لدينا ? في نهاية استدعاء read_to_string ، ولا نزال نعيد قيمة Ok تحتوي على username عندما ينجح كل من File::open و read_to_string بدلاً من إرجاع الأخطاء. الوظيفة هي نفسها مرة أخرى كما في القائمة 9-6 والقائمة 9-7؛ هذه مجرد طريقة مختلفة وأكثر راحة (ergonomic) لكتابتها.
توضح القائمة 9-9 طريقة لجعل هذا أقصر باستخدام fs::read_to_string.
#![allow(unused)]
fn main() {
use std::fs;
use std::io;
fn read_username_from_file() -> Result<String, io::Error> {
fs::read_to_string("hello.txt")
}
}قراءة ملف إلى سلسلة نصية هي عملية شائعة إلى حد ما، لذا توفر الـ standard library الـ function المريح fs::read_to_string الذي يفتح الملف، وينشئ String جديداً، ويقرأ محتويات الملف، ويضع المحتويات في ذلك الـ String ، ويعيده. بالطبع، استخدام fs::read_to_string لا يعطينا الفرصة لشرح كل معالجة الأخطاء، لذا قمنا بذلك بالطريقة الأطول أولاً.
أين يمكن استخدام عامل الـ ? (Where to Use the ? Operator)
لا يمكن استخدام عامل الـ ? إلا في الـ functions التي يكون نوع إرجاعها متوافقاً مع القيمة التي يُستخدم عليها الـ ?. وذلك لأن عامل الـ ? مُعرف للقيام بعودة مبكرة لقيمة خارج الـ function، بنفس الطريقة التي يعمل بها match expression الذي عرفناه في القائمة 9-6. في القائمة 9-6، كان الـ match يستخدم قيمة Result ، وكان ذراع العودة المبكرة يعيد قيمة Err(e). يجب أن يكون نوع إرجاع الـ function هو Result بحيث يكون متوافقاً مع هذا الـ return.
في القائمة 9-10، دعونا ننظر إلى الخطأ الذي سنحصل عليه إذا استخدمنا عامل الـ ? في function الـ main بنوع إرجاع غير متوافق مع نوع القيمة التي نستخدم الـ ? عليها.
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")?;
}يفتح هذا الكود ملفاً، وهو ما قد يفشل. يتبع عامل الـ ? قيمة الـ Result التي تعيدها File::open ، ولكن function الـ main هذه لها نوع إرجاع () ، وليس Result. عندما نقوم بتجميع هذا الكود، نحصل على رسالة الخطأ التالية:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let greeting_file = File::open("hello.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
help: consider adding return type
|
3 ~ fn main() -> Result<(), Box<dyn std::error::Error>> {
4 | let greeting_file = File::open("hello.txt")?;
5 + Ok(())
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` (bin "error-handling") due to 1 previous error
يشير هذا الخطأ إلى أنه مسموح لنا فقط باستخدام عامل الـ ? في function تعيد Result أو Option أو نوعاً آخر يطبق FromResidual.
لإصلاح الخطأ، لديك خياران. أحد الخيارات هو تغيير نوع إرجاع الـ function الخاصة بك ليكون متوافقاً مع القيمة التي تستخدم عامل الـ ? عليها طالما لم يكن لديك قيود تمنع ذلك. الخيار الآخر هو استخدام match أو إحدى methods الـ Result<T, E> لمعالجة الـ Result<T, E> بأي طريقة مناسبة.
ذكرت رسالة الخطأ أيضاً أنه يمكن استخدام الـ ? مع قيم Option<T> أيضاً. كما هو الحال مع استخدام ? على Result ، يمكنك فقط استخدام ? على Option في function تعيد Option. سلوك عامل الـ ? عند استدعائه على Option<T> مشابه لسلوكه عند استدعائه على Result<T, E>: إذا كانت القيمة هي None ، فسيتم إرجاع الـ None مبكراً من الـ function عند تلك النقطة. وإذا كانت القيمة هي Some ، فإن القيمة الموجودة داخل الـ Some هي القيمة الناتجة عن التعبير، وتستمر الـ function. تحتوي القائمة 9-11 على مثال لـ function تجد الحرف الأخير من السطر الأول في النص المعطى.
fn last_char_of_first_line(text: &str) -> Option<char> {
text.lines().next()?.chars().last()
}
fn main() {
assert_eq!(
last_char_of_first_line("Hello, world\nHow are you today?"),
Some('d')
);
assert_eq!(last_char_of_first_line(""), None);
assert_eq!(last_char_of_first_line("\nhi"), None);
}تعيد هذه الـ function القيمة Option<char> لأنه من المحتمل وجود حرف هناك، ولكن من المحتمل أيضاً عدم وجوده. يأخذ هذا الكود وسيط (argument) شريحة السلسلة النصية (string slice) المسمى text ويستدعي method الـ lines عليه، والذي يعيد مكرراً (iterator) على الأسطر في السلسلة النصية. ولأن هذه الـ function تريد فحص السطر الأول، فإنها تستدعي next على الـ iterator للحصول على القيمة الأولى منه. إذا كان text سلسلة نصية فارغة، فسيؤدي استدعاء next هذا إلى إرجاع None ، وفي هذه الحالة نستخدم ? للتوقف وإرجاع None من last_char_of_first_line. وإذا لم يكن text سلسلة نصية فارغة، فسيقوم next بإرجاع قيمة Some تحتوي على string slice للسطر الأول في text.
يقوم الـ ? باستخراج الـ string slice، ويمكننا استدعاء chars على ذلك الـ string slice للحصول على iterator لحروفه. نحن مهتمون بالحرف الأخير في هذا السطر الأول، لذا نستدعي last لإرجاع العنصر الأخير في الـ iterator. هذا هو Option لأنه من المحتمل أن يكون السطر الأول سلسلة نصية فارغة؛ على سبيل المثال، إذا بدأ text بسطر فارغ ولكن لديه حروف في أسطر أخرى، كما في "\nhi". ومع ذلك، إذا كان هناك حرف أخير في السطر الأول، فسيتم إرجاعه في variant الـ Some. يعطينا عامل الـ ? في المنتصف طريقة موجزة للتعبير عن هذا المنطق، مما يسمح لنا بتطبيق الـ function في سطر واحد. إذا لم نتمكن من استخدام عامل الـ ? على Option ، فسنضطر إلى تطبيق هذا المنطق باستخدام المزيد من استدعاءات الـ methods أو match expression.
لاحظ أنه يمكنك استخدام عامل الـ ? على Result في function تعيد Result ، ويمكنك استخدام عامل الـ ? على Option في function تعيد Option ، ولكن لا يمكنك الخلط والمطابقة. لن يقوم عامل الـ ? تلقائياً بتحويل Result إلى Option أو العكس؛ في تلك الحالات، يمكنك استخدام methods مثل method الـ ok على Result أو method الـ ok_or على Option للقيام بالتحويل صراحة.
حتى الآن، جميع الـ functions المسمى main التي استخدمناها تعيد (). الـ function المسمى main خاص لأنه نقطة الدخول ونقطة الخروج لبرنامج قابل للتنفيذ،
وهناك قيود على ما يمكن أن يكون عليه نوع إرجاعها لكي يتصرف البرنامج كما هو متوقع.
لحسن الحظ، يمكن لـ `main` أيضاً إرجاع `Result<(), E>`. تحتوي القائمة 9-12 على الكود من القائمة 9-10، لكننا قمنا بتغيير نوع إرجاع `main` ليكون `Result<(), Box<dyn Error>>` وأضفنا قيمة إرجاع `Ok(())` إلى النهاية. سيتم تجميع هذا الكود الآن.
<Listing number="9-12" file-name="src/main.rs" caption="Changing `main` to return `Result<(), E>` allows the use of the `?` operator on `Result` values.">
```rust,ignore
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello.txt")?;
Ok(())
}
النوع Box<dyn Error> هو كائن سمة (trait object)، والذي سنتحدث عنه في قسم “استخدام كائنات السمات للتجريد فوق السلوك المشترك” في الفصل الثامن عشر. في الوقت الحالي، يمكنك قراءة Box<dyn Error> لتعني “أي نوع من الأخطاء”. يُسمح باستخدام ? على قيمة Result في function الـ main مع نوع الخطأ Box<dyn Error> لأنه يسمح بإرجاع أي قيمة Err مبكراً. على الرغم من أن body الـ main هذا سيعيد فقط أخطاء من النوع std::io::Error ، إلا أنه من خلال تحديد Box<dyn Error> ، سيبقى هذا التوقيع (signature) صحيحاً حتى لو تمت إضافة المزيد من الكود الذي يعيد أخطاء أخرى إلى body الـ main.
عندما تعيد function الـ main القيمة Result<(), E> ، سيخرج الملف القابل للتنفيذ بقيمة 0 إذا أعادت main القيمة Ok(()) وسيخرج بقيمة غير صفرية إذا أعادت main قيمة Err. تعيد الملفات القابلة للتنفيذ المكتوبة بلغة C أعداداً صحيحة (integers) عند خروجها: البرامج التي تخرج بنجاح تعيد الـ integer 0 ، والبرامج التي تخطئ تعيد عدداً صحيحاً آخر غير 0. تعيد Rust أيضاً integers من الملفات القابلة للتنفيذ لتكون متوافقة مع هذا العرف.
قد تعيد function الـ main أي أنواع تطبق سمة std::process::Termination ، والتي تحتوي على function تسمى report تعيد ExitCode. راجع توثيق الـ standard library لمزيد من المعلومات حول تطبيق سمة Termination لأنواعك الخاصة.
الآن بعد أن ناقشنا تفاصيل استدعاء panic! أو إرجاع Result ، دعونا نعود إلى موضوع كيفية تحديد أيهما مناسب للاستخدام في أي حالات.
استخدام panic! أو عدم استخدامه
استخدام panic! أو عدم استخدامه (To panic! or Not to panic!)
إذاً، كيف تقرر متى يجب عليك استدعاء panic! ومتى يجب عليك إعادة Result؟ عندما يصاب الكود بـ (الذعر) panic ، لا توجد طريقة للاسترداد. يمكنك استدعاء panic! في أي حالة خطأ، سواء كانت هناك طريقة ممكنة للاسترداد أم لا، ولكنك بذلك تتخذ القرار نيابة عن الكود المستدعي بأن الموقف غير قابل للاسترداد. عندما تختار إعادة قيمة Result ، فإنك تمنح الكود المستدعي خيارات؛ حيث يمكن للكود المستدعي اختيار محاولة الاسترداد بطريقة مناسبة لموقفه، أو يمكنه تقرير أن قيمة Err في هذه الحالة غير قابلة للاسترداد، وبالتالي يمكنه استدعاء panic! وتحويل خطئك القابل للاسترداد إلى خطأ غير قابل للاسترداد. لذلك، تعد إعادة Result خياراً افتراضياً جيداً عند تعريف دالة قد تفشل.
في حالات مثل الأمثلة، وكود النماذج الأولية، والاختبارات، يكون من الأنسب كتابة كود يصاب بالذعر بدلاً من إعادة Result. دعنا نستكشف السبب، ثم نناقش الحالات التي لا يستطيع فيها المترجم معرفة أن الفشل مستحيل، ولكن يمكنك أنت كبشر معرفة ذلك. سينتهي الفصل ببعض الإرشادات العامة حول كيفية تقرير ما إذا كان يجب استخدام panic! في كود المكتبة.
الأمثلة، وكود النماذج الأولية، والاختبارات (Examples, Prototype Code, and Tests)
عندما تكتب مثالاً لتوضيح مفهوم ما، فإن تضمين كود قوي للتعامل مع الأخطاء يمكن أن يجعل المثال أقل وضوحاً. في الأمثلة، من المفهوم أن استدعاء (منهج) method مثل unwrap الذي قد يؤدي إلى panic هو بمثابة مكان محجوز للطريقة التي تريد أن يتعامل بها تطبيقك مع الأخطاء، والتي يمكن أن تختلف بناءً على ما يفعله باقي الكود الخاص بك.
وبالمثل، فإن منهجي unwrap و expect مفيدان جداً عندما تقوم ببناء (نموذج أولي) prototyping ولم تكن مستعداً بعد لتقرير كيفية التعامل مع الأخطاء؛ فهما يتركان علامات واضحة في كودك للموعد الذي ستكون فيه مستعداً لجعل برنامجك أكثر قوة.
إذا فشل استدعاء منهج في اختبار ما، فستحتاج إلى فشل الاختبار بأكمله، حتى لو لم يكن هذا المنهج هو الوظيفة قيد الاختبار. ولأن panic! هي الطريقة التي يتم بها وضع علامة على الاختبار كفاشل، فإن استدعاء unwrap أو expect هو بالضبط ما يجب أن يحدث.
عندما تمتلك معلومات أكثر من المترجم (When You Have More Information Than the Compiler)
سيكون من المناسب أيضاً استدعاء expect عندما يكون لديك منطق آخر يضمن أن Result ستحتوي على قيمة Ok ، ولكن هذا المنطق ليس شيئاً يفهمه المترجم. ستظل لديك قيمة Result تحتاج إلى التعامل معها: فأي عملية تستدعيها لا تزال لديها إمكانية الفشل بشكل عام، على الرغم من أنها مستحيلة منطقياً في حالتك الخاصة. إذا كان بإمكانك التأكد من خلال فحص الكود يدوياً أنك لن تحصل أبداً على (متغير) variant من نوع Err ، فمن المقبول تماماً استدعاء expect وتوثيق السبب الذي يجعلك تعتقد أنك لن تحصل أبداً على Err في نص الوسيطة. إليك مثالاً:
fn main() {
use std::net::IpAddr;
let home: IpAddr = "127.0.0.1"
.parse()
.expect("Hardcoded IP address should be valid");
}نحن نقوم بإنشاء (نموذج) instance من IpAddr عن طريق تحليل سلسلة نصية مكتوبة برمجياً (Hardcoded). يمكننا أن نرى أن 127.0.0.1 هو عنوان IP صالح، لذا فمن المقبول استخدام expect هنا. ومع ذلك، فإن وجود سلسلة نصية صالحة ومكتوبة برمجياً لا يغير نوع الإرجاع لمنهج parse: فنحن لا نزال نحصل على قيمة Result ، وسيظل المترجم يجبرنا على التعامل مع Result كما لو كان متغير Err ممكناً لأن المترجم ليس ذكياً بما يكفي ليرى أن هذه السلسلة هي دائماً عنوان IP صالح. إذا جاءت سلسلة عنوان IP من مستخدم بدلاً من كونها مكتوبة برمجياً في البرنامج وبالتالي كانت لديها إمكانية الفشل، فسنرغب بالتأكيد في التعامل مع Result بطريقة أكثر قوة بدلاً من ذلك. إن ذكر الافتراض بأن عنوان IP هذا مكتوب برمجياً سيحثنا على تغيير expect إلى كود أفضل للتعامل مع الأخطاء إذا احتجنا في المستقبل إلى الحصول على عنوان IP من مصدر آخر بدلاً من ذلك.
إرشادات للتعامل مع الأخطاء (Guidelines for Error Handling)
يُنصح بجعل كودك يصاب بالذعر عندما يكون من الممكن أن ينتهي به المطاف في (حالة سيئة) bad state. في هذا السياق، تكون الحالة السيئة عندما يتم كسر بعض الافتراضات أو الضمانات أو العقود أو (الثوابت) invariants ، مثل تمرير قيم غير صالحة أو قيم متناقضة أو قيم مفقودة إلى كودك - بالإضافة إلى واحد أو أكثر مما يلي:
- الحالة السيئة هي شيء غير متوقع، على عكس شيء من المحتمل أن يحدث أحياناً، مثل إدخال المستخدم لبيانات بتنسيق خاطئ.
- يحتاج كودك بعد هذه النقطة إلى الاعتماد على عدم وجوده في هذه الحالة السيئة، بدلاً من التحقق من المشكلة في كل خطوة.
- لا توجد طريقة جيدة لترميز هذه المعلومات في الأنواع التي تستخدمها. سنعمل من خلال مثال لما نعنيه في “ترميز الحالات والسلوك كأنواع” في الفصل 18.
إذا قام شخص ما باستدعاء كودك ومرر قيماً غير منطقية، فمن الأفضل إعادة خطأ إذا استطعت حتى يتمكن مستخدم المكتبة من تقرير ما يريد فعله في هذه الحالة. ومع ذلك، في الحالات التي قد يكون فيها الاستمرار غير آمن أو ضاراً، قد يكون الخيار الأفضل هو استدعاء panic! وتنبيه الشخص الذي يستخدم مكتبتك إلى وجود (خطأ برمجى) bug في كوده حتى يتمكن من إصلاحه أثناء التطوير. وبالمثل، غالباً ما يكون panic! مناسباً إذا كنت تستدعي كوداً خارجياً خارجاً عن سيطرتك ويعيد حالة غير صالحة ليس لديك طريقة لإصلاحها.
ومع ذلك، عندما يكون الفشل متوقعاً، فمن الأنسب إعادة Result بدلاً من إجراء استدعاء panic!. تشمل الأمثلة إعطاء (محلل) parser بيانات مشوهة أو إعادة طلب HTTP لحالة تشير إلى أنك وصلت إلى حد المعدل (Rate limit). في هذه الحالات، تشير إعادة Result إلى أن الفشل هو احتمال متوقع يجب على الكود المستدعي تقرير كيفية التعامل معه.
عندما يؤدي كودك عملية قد تعرض المستخدم للخطر إذا تم استدعاؤها باستخدام قيم غير صالحة، يجب أن يتحقق كودك من صحة القيم أولاً ويصاب بالذعر إذا لم تكن القيم صالحة. هذا في الغالب لأسباب تتعلق بالسلامة: فمحاولة العمل على بيانات غير صالحة يمكن أن تعرض كودك لثغرات أمنية. هذا هو السبب الرئيسي الذي يجعل المكتبة القياسية تستدعي panic! إذا حاولت الوصول إلى ذاكرة خارج الحدود: فمحاولة الوصول إلى ذاكرة لا تنتمي إلى هيكل البيانات الحالي هي مشكلة أمنية شائعة. غالباً ما يكون للدوال (عقود) contracts: حيث يكون سلوكها مضموناً فقط إذا كانت المدخلات تلبي متطلبات معينة. إن الإصابة بالذعر عند انتهاك العقد أمر منطقي لأن انتهاك العقد يشير دائماً إلى خطأ من جانب المستدعي، وليس نوعاً من الأخطاء التي تريد أن يضطر الكود المستدعي للتعامل معها صراحة. في الواقع، لا توجد طريقة معقولة للكود المستدعي للاسترداد؛ بل يحتاج المبرمجون المستدعون إلى إصلاح الكود. يجب شرح عقود الدالة، خاصة عندما يتسبب الانتهاك في حدوث ذعر، في توثيق API للدالة.
ومع ذلك، فإن وجود الكثير من عمليات التحقق من الأخطاء في جميع دوالك سيكون مطولاً ومزعجاً. لحسن الحظ، يمكنك استخدام (نظام الأنواع) type system في Rust (وبالتالي فحص الأنواع الذي يقوم به المترجم) للقيام بالعديد من عمليات التحقق نيابة عنك. إذا كانت دالتك تحتوي على نوع معين كمعلمة، فيمكنك المضي قدماً في منطق كودك مع العلم أن المترجم قد تأكد بالفعل من أن لديك قيمة صالحة. على سبيل المثال، إذا كان لديك نوع بدلاً من Option ، فإن برنامجك يتوقع الحصول على شيء ما بدلاً من لا شيء. لا يتعين على كودك بعد ذلك التعامل مع حالتين لمتغيري Some و None: سيكون لديه حالة واحدة فقط للحصول على قيمة بالتأكيد. الكود الذي يحاول تمرير “لا شيء” إلى دالتك لن يتم تجميعه حتى، لذا لا يتعين على دالتك التحقق من هذه الحالة في وقت التشغيل. مثال آخر هو استخدام نوع صحيح غير موقع مثل u32 ، والذي يضمن أن المعلمة ليست سالبة أبداً.
أنواع مخصصة للتحقق من الصحة (Custom Types for Validation)
دعنا نأخذ فكرة استخدام نظام الأنواع في Rust لضمان حصولنا على قيمة صالحة خطوة إلى الأمام وننظر في إنشاء نوع مخصص للتحقق من الصحة. تذكر لعبة التخمين في الفصل الثاني التي طلب فيها كودنا من المستخدم تخمين رقم بين 1 و 100. لم نقم أبداً بالتحقق من أن تخمين المستخدم كان بين تلك الأرقام قبل التحقق منه مقابل رقمنا السري؛ لقد تحققنا فقط من أن التخمين كان موجباً. في هذه الحالة، لم تكن العواقب وخيمة للغاية: فمخرجاتنا “عالية جداً” أو “منخفضة جداً” ستظل صحيحة. ولكن سيكون من التحسينات المفيدة توجيه المستخدم نحو التخمينات الصالحة ويكون له سلوك مختلف عندما يخمن المستخدم رقماً خارج النطاق مقابل عندما يكتب المستخدم، على سبيل المثال، حروفاً بدلاً من ذلك.
إحدى الطرق للقيام بذلك هي تحليل التخمين كـ i32 بدلاً من u32 فقط للسماح بالأرقام السالبة المحتملة، ثم إضافة فحص لكون الرقم في النطاق، هكذا:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: i32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if guess < 1 || guess > 100 {
println!("The secret number will be between 1 and 100.");
continue;
}
match guess.cmp(&secret_number) {
// --snip--
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}يتحقق تعبير if مما إذا كانت قيمتنا خارج النطاق، ويخبر المستخدم بالمشكلة، ويستدعي continue لبدء التكرار التالي للحلقة وطلب تخمين آخر. بعد تعبير if ، يمكننا المضي قدماً في المقارنات بين guess والرقم السري مع العلم أن guess بين 1 و 100.
ومع ذلك، هذا ليس حلاً مثالياً: فإذا كان من الضروري تماماً أن يعمل البرنامج فقط على القيم بين 1 و 100، وكان لديه العديد من الدوال بهذا المتطلب، فإن وجود فحص مثل هذا في كل دالة سيكون مملاً (وقد يؤثر على الأداء).
بدلاً من ذلك، يمكننا إنشاء نوع جديد في وحدة مخصصة ووضع عمليات التحقق من الصحة في دالة لإنشاء نموذج من النوع بدلاً من تكرار عمليات التحقق في كل مكان. بهذه الطريقة، يكون من الآمن للدوال استخدام النوع الجديد في (توقيعاتها) signatures واستخدام القيم التي تتلقاها بثقة. تعرض القائمة 9-13 إحدى الطرق لتعريف نوع Guess الذي سيقوم فقط بإنشاء نموذج من Guess إذا تلقت دالة new قيمة بين 1 و 100.
#![allow(unused)]
fn main() {
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
pub fn value(&self) -> i32 {
self.value
}
}
}لاحظ أن هذا الكود في src/guessing_game.rs يعتمد على إضافة إعلان وحدة mod guessing_game; في src/lib.rs لم نعرضه هنا. داخل ملف هذه الوحدة الجديدة، نعرف هيكلاً يسمى Guess يحتوي على حقل يسمى value يحمل i32. هذا هو المكان الذي سيتم فيه تخزين الرقم.
بعد ذلك، نقوم بتنفيذ دالة مرتبطة تسمى new على Guess تقوم بإنشاء نماذج من قيم Guess. تم تعريف دالة new لتكون لها معلمة واحدة تسمى value من نوع i32 وتعيد Guess. يختبر الكود الموجود في جسم دالة new القيمة value للتأكد من أنها بين 1 و 100. إذا لم تجتز value هذا الاختبار، فإننا نجري استدعاء panic! ، والذي سينبه المبرمج الذي يكتب الكود المستدعي بأن لديه خطأ برمجياً يحتاج إلى إصلاحه، لأن إنشاء Guess بقيمة value خارج هذا النطاق سينتهك العقد الذي تعتمد عليه Guess::new. يجب مناقشة الظروف التي قد تؤدي فيها Guess::new إلى حدوث ذعر في توثيق API العام الخاص بها؛ سنغطي اصطلاحات التوثيق التي تشير إلى إمكانية حدوث panic! في توثيق API الذي تنشئه في الفصل 14. إذا اجتازت value الاختبار، فإننا ننشئ Guess جديداً مع ضبط حقل value الخاص به على معلمة value ونعيد Guess.
بعد ذلك، نقوم بتنفيذ منهج يسمى value يستعير self ، وليس له أي معلمات أخرى، ويعيد i32. يسمى هذا النوع من المناهج أحياناً (جالب) getter لأن الغرض منه هو الحصول على بعض البيانات من حقوله وإعادتها. هذا المنهج العام ضروري لأن حقل value في هيكل Guess خاص. من المهم أن يكون حقل value خاصاً حتى لا يُسمح للكود الذي يستخدم هيكل Guess بضبط value مباشرة: يجب على الكود خارج وحدة guessing_game استخدام دالة Guess::new لإنشاء نموذج من Guess ، مما يضمن عدم وجود طريقة لـ Guess للحصول على value لم يتم فحصها بواسطة الشروط الموجودة في دالة Guess::new.
يمكن للدالة التي تحتوي على معلمة أو تعيد فقط أرقاماً بين 1 و 100 أن تعلن في توقيعها أنها تأخذ أو تعيد Guess بدلاً من i32 ولن تحتاج إلى إجراء أي فحوصات إضافية في جسمها.
ملخص (Summary)
تم تصميم ميزات التعامل مع الأخطاء في Rust لمساعدتك على كتابة كود أكثر قوة. يشير (ماكرو) macro المسمى panic! إلى أن برنامجك في حالة لا يمكنه التعامل معها ويسمح لك بإخبار العملية بالتوقف بدلاً من محاولة المضي قدماً بقيم غير صالحة أو غير صحيحة. يستخدم (تعداد) enum المسمى Result نظام الأنواع في Rust للإشارة إلى أن العمليات قد تفشل بطريقة يمكن لكودك الاسترداد منها. يمكنك استخدام Result لإخبار الكود الذي يستدعي كودك بأنه يحتاج إلى التعامل مع النجاح أو الفشل المحتمل أيضاً. إن استخدام panic! و Result في المواقف المناسبة سيجعل كودك أكثر موثوقية في مواجهة المشكلات الحتمية.
الآن بعد أن رأيت طرقاً مفيدة تستخدم بها المكتبة القياسية (الأنواع العامة) generics مع تعدادي Option و Result ، سنتحدث عن كيفية عمل الأنواع العامة وكيف يمكنك استخدامها في كودك.
الأنواع العامة والسمات وفترات الحياة
تمتلك كل لغة برمجة أدوات للتعامل بفعالية مع تكرار المفاهيم. في لغة Rust، إحدى هذه الأدوات هي الأنواع العامة (generics): وهي بدائل مجردة للأنواع الملموسة (concrete types) أو الخصائص الأخرى. يمكننا التعبير عن سلوك generics أو كيفية ارتباطها بـ generics أخرى دون معرفة ما سيحل محلها عند تصريف (compiling) وتشغيل الكود.
يمكن للدوال أن تأخذ معاملات من نوع عام (generic type)، بدلاً من نوع ملموس (concrete type) مثل i32 أو String بنفس الطريقة التي تأخذ بها معاملات بقيم غير معروفة لتشغيل نفس الكود على قيم ملموسة متعددة. في الواقع، لقد استخدمنا بالفعل generics في الفصل السادس مع Option<T>، وفي الفصل الثامن مع Vec<T> و HashMap<K, V>، وفي الفصل التاسع مع Result<T, E>. في هذا الفصل، ستستكشف كيفية تعريف الأنواع والدوال والطرق (methods) الخاصة بك باستخدام generics!
أولاً، سنراجع كيفية استخراج دالة لتقليل تكرار الكود. سنستخدم بعد ذلك نفس التقنية لإنشاء دالة عامة (generic function) من دالتين تختلفان فقط في أنواع معاملاتهما. سنشرح أيضاً كيفية استخدام generic types في تعريفات الهياكل (structs) والتعدادات (enums).
بعد ذلك، ستتعلم كيفية استخدام السمات (traits) لتعريف السلوك بطريقة عامة. يمكنك دمج traits مع generic types لتقييد generic type لقبول تلك الأنواع التي تمتلك سلوكاً معيناً فقط، بدلاً من قبول أي نوع فحسب.
أخيراً، سنناقش فترات الحياة (lifetimes): وهي نوع من generics تزود المترجم (compiler) بمعلومات حول كيفية ارتباط المراجع (references) ببعضها البعض. تسمح لنا lifetimes بإعطاء compiler معلومات كافية حول القيم المستعارة (borrowed values) حتى يتمكن من ضمان أن references ستكون صالحة في مواقف أكثر مما يمكنه فعله بدون مساعدتنا.
إزالة التكرار عن طريق استخراج دالة
تسمح لنا generics باستبدال أنواع محددة بعنصر نائب (placeholder) يمثل أنواعاً متعددة لإزالة تكرار الكود. قبل الغوص في بناء جملة (syntax) الـ generics، دعونا ننظر أولاً في كيفية إزالة التكرار بطريقة لا تتضمن generic types عن طريق استخراج دالة تستبدل قيمًا محددة بـ placeholder يمثل قيمًا متعددة. بعد ذلك، سنطبق نفس التقنية لاستخراج generic function! من خلال النظر في كيفية التعرف على الكود المكرر الذي يمكنك استخراجه إلى دالة، ستبدأ في التعرف على الكود المكرر الذي يمكنه استخدام generics.
سنبدأ بالبرنامج القصير في القائمة 10-1 الذي يجد أكبر رقم في قائمة.
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
assert_eq!(*largest, 100);
}نقوم بتخزين قائمة من الأعداد الصحيحة في المتغير number_list ونضع مرجعاً (reference) لأول رقم في القائمة في متغير يسمى largest. ثم نقوم بالتكرار (iterate) عبر جميع الأرقام في القائمة، وإذا كان الرقم الحالي أكبر من الرقم المخزن في largest نقوم باستبدال reference في ذلك المتغير. ومع ذلك، إذا كان الرقم الحالي أقل من أو يساوي أكبر رقم شوهد حتى الآن، فلا يتغير المتغير، وينتقل الكود إلى الرقم التالي في القائمة. بعد النظر في جميع الأرقام في القائمة، يجب أن يشير largest إلى أكبر رقم، وهو في هذه الحالة 100.
لقد كُلفنا الآن بالعثور على أكبر رقم في قائمتين مختلفتين من الأرقام. للقيام بذلك، يمكننا اختيار تكرار الكود الموجود في القائمة 10-1 واستخدام نفس المنطق في مكانين مختلفين في البرنامج، كما هو موضح في القائمة 10-2.
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
}على الرغم من أن هذا الكود يعمل، إلا أن تكرار الكود أمر ممل وعرضة للخطأ. كما يتعين علينا تذكر تحديث الكود في أماكن متعددة عندما نريد تغييره.
للقضاء على هذا التكرار، سننشئ تجريداً (abstraction) من خلال تعريف دالة تعمل على أي قائمة من الأعداد الصحيحة يتم تمريرها كمعامل (parameter). يجعل هذا الحل كودنا أكثر وضوحاً ويسمح لنا بالتعبير عن مفهوم العثور على أكبر رقم في قائمة بشكل مجرد.
في القائمة 10-3، نستخرج الكود الذي يجد أكبر رقم في دالة تسمى largest. ثم نستدعي الدالة للعثور على أكبر رقم في القائمتين من القائمة 10-2. يمكننا أيضاً استخدام الدالة على أي قائمة أخرى من قيم i32 قد تكون لدينا في المستقبل.
fn largest(list: &[i32]) -> &i32 {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 100);
let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let result = largest(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 6000);
}تمتلك الدالة largest معاملًا يسمى list يمثل أي شريحة (slice) ملموسة من قيم i32 قد نمررها إلى الدالة. ونتيجة لذلك، عندما نستدعي الدالة، يتم تشغيل الكود على القيم المحددة التي نمررها.
باختصار، إليك الخطوات التي اتخذناها لتغيير الكود من القائمة 10-2 إلى القائمة 10-3:
- تحديد الكود المكرر.
- استخراج الكود المكرر في جسم الدالة، وتحديد المدخلات وقيم الإرجاع (return values) لهذا الكود في توقيع الدالة (function signature).
- تحديث مثيلي الكود المكرر لاستدعاء الدالة بدلاً من ذلك.
بعد ذلك، سنستخدم هذه الخطوات نفسها مع generics لتقليل تكرار الكود. بنفس الطريقة التي يمكن بها لجسم الدالة أن يعمل على list مجردة بدلاً من قيم محددة، تسمح generics للكود بالعمل على أنواع مجردة.
على سبيل المثال، لنفترض أن لدينا دالتين: واحدة تجد أكبر عنصر في slice من قيم i32 وأخرى تجد أكبر عنصر في slice من قيم char. كيف سنزيل هذا التكرار؟ لنكتشف ذلك!
أنواع البيانات العامة (Generic Data Types)
أنواع البيانات العامة (Generic Data Types)
نستخدم الـ generics لإنشاء تعريفات لعناصر مثل توقيعات الدوال (function signatures) أو الـ structs، والتي يمكننا بعد ذلك استخدامها مع العديد من أنواع البيانات الملموسة (concrete data types) المختلفة. دعنا ننظر أولاً إلى كيفية تعريف الـ functions، الـ structs، الـ enums، والـ methods باستخدام الـ generics. بعد ذلك، سنناقش كيف تؤثر الـ generics على أداء الكود.
في تعريفات الدوال
عند تعريف function تستخدم الـ generics، نضع الـ generics في توقيع الـ function حيث نحدد عادةً أنواع البيانات (data types) للمعلمات (parameters) وقيمة الإرجاع (return value). يؤدي القيام بذلك إلى جعل الكود الخاص بنا أكثر مرونة ويوفر وظائف أكثر لمستدعي الـ function مع منع تكرار الكود.
بالاستمرار مع الـ function largest، تُظهر القائمة 10-4 دالتين تجدان أكبر قيمة في شريحة (slice). سنقوم بعد ذلك بدمج هاتين الدالتين في function واحدة تستخدم الـ generics.
fn largest_i32(list: &[i32]) -> &i32 {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn largest_char(list: &[char]) -> &char {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest_i32(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 100);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest_char(&char_list);
println!("The largest char is {result}");
assert_eq!(*result, 'y');
}الدالة largest_i32 هي الدالة التي استخرجناها في القائمة 10-3 والتي تجد أكبر i32 في slice. تجد الدالة largest_char أكبر char في slice. تحتوي نصوص الدوال على نفس الكود، لذا دعنا نتخلص من التكرار عن طريق إدخال معلمة نوع عام (generic type parameter) في function واحدة.
لتعيين الـ types كـ parameters في function واحدة جديدة، نحتاج إلى تسمية الـ type parameter، تمامًا كما نفعل لـ value parameters لـ function. يمكنك استخدام أي معرف (identifier) كاسم لـ type parameter. لكننا سنستخدم T لأنه، حسب الاصطلاح، تكون أسماء الـ type parameter في Rust قصيرة، وغالبًا ما تكون حرفًا واحدًا فقط، واصطلاح تسمية الـ type في Rust هو UpperCamelCase. T، اختصار لـ type، هو الخيار الافتراضي لمعظم مبرمجي Rust.
عندما نستخدم parameter في نص الـ function، يجب علينا الإعلان عن اسم الـ parameter في التوقيع حتى يعرف المترجم (compiler) ما يعنيه هذا الاسم. وبالمثل، عندما نستخدم اسم type parameter في توقيع function، يجب علينا الإعلان عن اسم الـ type parameter قبل استخدامه. لتعريف الـ generic function largest، نضع إعلانات اسم الـ type داخل أقواس زاوية، <>، بين اسم الـ function وقائمة الـ parameters، مثل هذا:
fn largest<T>(list: &[T]) -> &T {نقرأ هذا التعريف على أنه “الدالة largest عامة (generic) على نوع ما T.” تحتوي هذه الـ function على parameter واحد يسمى list، وهو slice من القيم من النوع T. ستُرجع الدالة largest مرجعًا (reference) إلى قيمة من نفس النوع T.
تُظهر القائمة 10-5 تعريف الـ function largest المدمج باستخدام نوع البيانات العام (generic data type) في توقيعها. تُظهر القائمة أيضًا كيف يمكننا استدعاء الـ function إما بـ slice من قيم i32 أو قيم char. لاحظ أن هذا الكود لن يتم تجميعه بعد.
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {result}");
}إذا قمنا بـ compile هذا الكود الآن، فسنحصل على هذا الخطأ:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
يذكر نص المساعدة std::cmp::PartialOrd، وهو سمة (trait)، وسنتحدث عن الـ traits في القسم التالي. في الوقت الحالي، اعلم أن هذا الخطأ ينص على أن نص largest لن يعمل لجميع الـ types الممكنة التي يمكن أن يكونها T. نظرًا لأننا نريد مقارنة قيم من النوع T في النص، يمكننا فقط استخدام الـ types التي يمكن ترتيب قيمها. لتمكين المقارنات، تحتوي المكتبة القياسية (standard library) على الـ trait std::cmp::PartialOrd الذي يمكنك تطبيقه على الـ types (راجع الملحق ج لمزيد من المعلومات حول هذا الـ trait). لإصلاح القائمة 10-5، يمكننا اتباع اقتراح نص المساعدة وتقييد الـ types الصالحة لـ T على تلك التي تطبق PartialOrd فقط. سيتم بعد ذلك تجميع القائمة، لأن الـ standard library تطبق PartialOrd على كل من i32 و char.
في تعريفات الـ Struct
يمكننا أيضًا تعريف الـ structs لاستخدام generic type parameter في حقل واحد أو أكثر باستخدام بناء جملة <>. تحدد القائمة 10-6 struct Point<T> للاحتفاظ بقيم إحداثيات x و y من أي نوع.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let integer = Point { x: 5, y: 10 };
let float = Point { x: 1.0, y: 4.0 };
}بناء الجملة لاستخدام الـ generics في تعريفات الـ struct مشابه لذلك المستخدم في تعريفات الـ function. أولاً، نعلن عن اسم الـ type parameter داخل أقواس زاوية مباشرة بعد اسم الـ struct. بعد ذلك، نستخدم الـ generic type في تعريف الـ struct حيث كنا سنحدد أنواع البيانات الملموسة.
لاحظ أنه نظرًا لأننا استخدمنا generic type واحدًا فقط لتعريف Point<T>، فإن هذا التعريف يقول إن struct Point<T> عام على نوع ما T، وأن الـ fields x و y هما كلاهما من نفس النوع، مهما كان هذا النوع. إذا أنشأنا مثيلًا لـ Point<T> يحتوي على قيم من أنواع مختلفة، كما في القائمة 10-7، فلن يتم تجميع الكود الخاص بنا.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}في هذا المثال، عندما نخصص القيمة الصحيحة 5 لـ x، فإننا نُعلم الـ compiler أن الـ generic type T سيكون عددًا صحيحًا لهذا المثيل من Point<T>. بعد ذلك، عندما نحدد 4.0 لـ y، والذي حددناه ليكون من نفس نوع x، سنحصل على خطأ عدم تطابق النوع (type mismatch) مثل هذا:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let wont_work = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
لتعريف struct Point حيث يكون x و y كلاهما generics ولكنهما يمكن أن يكونا من أنواع مختلفة، يمكننا استخدام multiple generic type parameters. على سبيل المثال، في القائمة 10-8، نغير تعريف Point ليكون عامًا على الـ types T و U حيث يكون x من النوع T و y من النوع U.
struct Point<T, U> {
x: T,
y: U,
}
fn main() {
let both_integer = Point { x: 5, y: 10 };
let both_float = Point { x: 1.0, y: 4.0 };
let integer_and_float = Point { x: 5, y: 4.0 };
}الآن جميع مثيلات Point الموضحة مسموح بها! يمكنك استخدام أي عدد تريده من generic type parameters في تعريف، ولكن استخدام أكثر من عدد قليل يجعل الكود الخاص بك صعب القراءة. إذا وجدت أنك بحاجة إلى الكثير من الـ generic types في الكود الخاص بك، فقد يشير ذلك إلى أن الكود الخاص بك يحتاج إلى إعادة هيكلة (restructuring) إلى أجزاء أصغر.
في تعريفات الـ Enum
كما فعلنا مع الـ structs، يمكننا تعريف الـ enums للاحتفاظ بـ generic data types في متغيراتها (variants). دعنا نلقي نظرة أخرى على الـ enum Option<T> الذي توفره الـ standard library، والذي استخدمناه في الفصل 6:
#![allow(unused)]
fn main() {
enum Option<T> {
Some(T),
None,
}
}يجب أن يكون هذا التعريف أكثر منطقية بالنسبة لك الآن. كما ترى، فإن الـ enum Option<T> عام على النوع T وله متغيران: Some، الذي يحتوي على قيمة واحدة من النوع T، ومتغير None الذي لا يحتوي على أي قيمة. باستخدام الـ enum Option<T>، يمكننا التعبير عن المفهوم المجرد للقيمة الاختيارية (optional value)، ولأن Option<T> عام، يمكننا استخدام هذا التجريد بغض النظر عن نوع القيمة الاختيارية.
يمكن أن تستخدم الـ Enums أنواعًا عامة متعددة أيضًا. تعريف الـ enum Result الذي استخدمناه في الفصل 9 هو أحد الأمثلة:
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}الـ enum Result عام على نوعين، T و E، وله متغيران: Ok، الذي يحتوي على قيمة من النوع T، و Err، الذي يحتوي على قيمة من النوع E. يجعل هذا التعريف من الملائم استخدام الـ enum Result في أي مكان لدينا عملية قد تنجح (تُرجع قيمة من نوع ما T) أو تفشل (تُرجع خطأ من نوع ما E). في الواقع، هذا ما استخدمناه لفتح ملف في القائمة 9-3، حيث تم ملء T بالنوع std::fs::File عندما تم فتح الملف بنجاح وتم ملء E بالنوع std::io::Error عندما كانت هناك مشاكل في فتح الملف.
عندما تدرك مواقف في الكود الخاص بك مع تعريفات struct أو enum متعددة تختلف فقط في أنواع القيم التي تحتفظ بها، يمكنك تجنب التكرار باستخدام generic types بدلاً من ذلك.
في تعريفات الـ Method
يمكننا تطبيق الـ methods على الـ structs والـ enums (كما فعلنا في الفصل 5) واستخدام generic types في تعريفاتها أيضًا. تُظهر القائمة 10-9 struct Point<T> الذي عرفناه في القائمة 10-6 مع method يسمى x مطبق عليه.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}هنا، قمنا بتعريف method يسمى x على Point<T> يُرجع reference إلى البيانات الموجودة في الـ field x.
لاحظ أنه يجب علينا الإعلان عن T مباشرة بعد impl حتى نتمكن من استخدام T لتحديد أننا نطبق الـ methods على النوع Point<T>. من خلال الإعلان عن T كـ generic type بعد impl، يمكن لـ Rust تحديد أن النوع الموجود في الأقواس الزاوية في Point هو generic type بدلاً من concrete type. كان بإمكاننا اختيار اسم مختلف لـ generic parameter هذا عن الـ generic parameter المعلن في تعريف الـ struct، ولكن استخدام نفس الاسم هو اصطلاح. إذا كتبت method داخل impl يعلن عن generic type، فسيتم تعريف هذا الـ method على أي مثيل من النوع، بغض النظر عن الـ concrete type الذي ينتهي به الأمر ليحل محل الـ generic type.
يمكننا أيضًا تحديد قيود (constraints) على الـ generic types عند تعريف الـ methods على النوع. يمكننا، على سبيل المثال، تطبيق الـ methods فقط على مثيلات Point<f32> بدلاً من مثيلات Point<T> بأي generic type. في القائمة 10-10، نستخدم الـ concrete type f32، مما يعني أننا لا نعلن عن أي types بعد impl.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
impl Point<f32> {
fn distance_from_origin(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}يعني هذا الكود أن النوع Point<f32> سيكون له method distance_from_origin؛ لن يكون لدى المثيلات الأخرى من Point<T> حيث T ليس من النوع f32 هذا الـ method المعرف. يقيس الـ method مدى بعد نقطتنا عن النقطة عند الإحداثيات (0.0، 0.0) ويستخدم العمليات الرياضية المتاحة فقط لـ floating-point types.
لا تكون generic type parameters في تعريف struct دائمًا هي نفسها التي تستخدمها في توقيعات الـ method لنفس الـ struct. تستخدم القائمة 10-11 الـ generic types X1 و Y1 لـ struct Point و X2 و Y2 لـ method signature mixup لجعل المثال أكثر وضوحًا. ينشئ الـ method مثيل Point جديدًا بقيمة x من self Point (من النوع X1) وقيمة y من Point الذي تم تمريره (من النوع Y2).
struct Point<X1, Y1> {
x: X1,
y: Y1,
}
impl<X1, Y1> Point<X1, Y1> {
fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> {
Point {
x: self.x,
y: other.y,
}
}
}
fn main() {
let p1 = Point { x: 5, y: 10.4 };
let p2 = Point { x: "Hello", y: 'c' };
let p3 = p1.mixup(p2);
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}في main، قمنا بتعريف Point يحتوي على i32 لـ x (بقيمة 5) و f64 لـ y (بقيمة 10.4). المتغير p2 هو struct Point يحتوي على string slice لـ x (بقيمة "Hello") و char لـ y (بقيمة c). استدعاء mixup على p1 بالوسيطة p2 يعطينا p3، وستطبع نتيجة الاستدعاء p3.x = 5, p3.y = c.
الغرض من هذا المثال هو إظهار موقف يتم فيه الإعلان عن بعض الـ generic parameters باستخدام impl ويتم الإعلان عن البعض الآخر باستخدام تعريف الـ method. هنا، يتم الإعلان عن الـ generic parameters X1 و Y1 بعد impl لأنهما يذهبان مع تعريف الـ struct. يتم الإعلان عن الـ generic parameters X2 و Y2 بعد fn mixup لأنهما لا يتعلقان إلا بالـ method.
أداء الكود الذي يستخدم الـ Generics
قد تتساءل عما إذا كانت هناك تكلفة في وقت التشغيل (runtime cost) عند استخدام generic type parameters. الخبر السار هو أن استخدام generic types لن يجعل برنامجك يعمل أبطأ مما لو كان بأنواع ملموسة (concrete types).
تحقق Rust ذلك عن طريق إجراء تنميط أحادي (monomorphization) للكود باستخدام الـ generics في الـ compile time. الـ Monomorphization هي عملية تحويل الـ generic code إلى كود محدد عن طريق ملء الـ concrete types التي يتم استخدامها عند الـ compile. في هذه العملية، يقوم الـ compiler بعكس الخطوات التي استخدمناها لإنشاء الـ generic function في القائمة 10-5: ينظر الـ compiler إلى جميع الأماكن التي يتم فيها استدعاء الـ generic code ويولد كودًا لـ concrete types التي يتم استدعاء الـ generic code بها.
دعنا ننظر إلى كيفية عمل ذلك باستخدام الـ generic enum Option<T> الخاص بالـ standard library:
#![allow(unused)]
fn main() {
let integer = Some(5);
let float = Some(5.0);
}عندما تقوم Rust بـ compile هذا الكود، فإنها تجري monomorphization. خلال هذه العملية، يقرأ الـ compiler القيم التي تم استخدامها في مثيلات Option<T> ويحدد نوعين من Option<T>: أحدهما i32 والآخر f64. على هذا النحو، فإنه يوسع التعريف العام لـ Option<T> إلى تعريفين متخصصين لـ i32 و f64، وبالتالي يحل محل التعريف العام بالتعريفات المحددة.
يبدو الإصدار الذي تم عمل monomorphization له من الكود مشابهًا لما يلي (يستخدم الـ compiler أسماء مختلفة عما نستخدمه هنا للتوضيح):
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let integer = Option_i32::Some(5);
let float = Option_f64::Some(5.0);
}يتم استبدال الـ generic Option<T> بالتعريفات المحددة التي أنشأها الـ compiler. نظرًا لأن Rust تقوم بـ compile الـ generic code إلى كود يحدد النوع في كل مثيل، فإننا لا ندفع أي runtime cost لاستخدام الـ generics. عندما يتم تشغيل الكود، فإنه يعمل تمامًا كما لو كنا قد كررنا كل تعريف يدويًا. عملية الـ monomorphization تجعل الـ generics في Rust فعالة للغاية في الـ runtime.
تعريف السلوك المشترك باستخدام السمات (Traits)
تعريف السلوك المشترك باستخدام السمات (Defining Shared Behavior with Traits)
تحدد الـ سمة (trait) الوظائف التي يمتلكها نوع معين ويمكنه مشاركتها مع أنواع أخرى. يمكننا استخدام الـ traits لتعريف السلوك المشترك بطريقة مجردة (abstract). كما يمكننا استخدام قيود السمات (trait bounds) لتحديد أن النوع العام (generic type) يمكن أن يكون أي نوع يمتلك سلوكًا معينًا.
ملاحظة: الـ traits تشبه ميزة تسمى غالبًا الواجهات (interfaces) في لغات أخرى، وإن كان مع بعض الاختلافات.
تعريف سمة (Defining a Trait)
يتكون سلوك النوع من الدوال (methods) التي يمكننا استدعاؤها على ذلك النوع. تتشارك الأنواع المختلفة في نفس السلوك إذا كان بإمكاننا استدعاء نفس الـ methods على كل تلك الأنواع. تعريفات الـ Trait هي وسيلة لتجميع تواقيع الدوال (method signatures) معًا لتعريف مجموعة من السلوكيات الضرورية لتحقيق غرض ما.
على سبيل المثال، لنفترض أن لدينا عدة هياكل (structs) تحمل أنواعًا وكميات مختلفة من النصوص: هيكل NewsArticle يحمل قصة إخبارية مسجلة في موقع معين، وهيكل SocialPost يمكن أن يحتوي على 280 حرفًا كحد أقصى مع بيانات وصفية (metadata) تشير إلى ما إذا كان منشورًا جديدًا، أو إعادة نشر، أو ردًا على منشور آخر.
نريد إنشاء حزمة مكتبة (library crate) لمجمع وسائط تسمى aggregator يمكنها عرض ملخصات للبيانات التي قد تكون مخزنة في مثيل (instance) من NewsArticle أو SocialPost. للقيام بذلك، نحتاج إلى ملخص من كل نوع، وسنطلب ذلك الملخص عن طريق استدعاء دالة summarize على الـ instance. توضح القائمة 10-12 تعريف سمة Summary عامة (public) تعبر عن هذا السلوك.
pub trait Summary {
fn summarize(&self) -> String;
}هنا، نعلن عن trait باستخدام الكلمة المفتاحية trait ثم اسم الـ trait، وهو Summary في هذه الحالة. نعلن أيضًا عن الـ trait كـ pub بحيث يمكن للـ crates التي تعتمد على هذه الـ crate استخدام هذه الـ trait أيضًا، كما سنرى في بضعة أمثلة. داخل الأقواس المتعرجة، نعلن عن الـ method signatures التي تصف سلوكيات الأنواع التي تنفذ (implement) هذه الـ trait، وهي في هذه الحالة fn summarize(&self) -> String.
بعد الـ method signature، وبدلاً من توفير تنفيذ (implementation) داخل أقواس متعرجة، نستخدم فاصلة منقوطة. يجب على كل نوع ينفذ هذه الـ trait توفير سلوكه المخصص لجسم الـ method. سيفرض المترجم (compiler) أن أي نوع يمتلك الـ Summary trait سيكون لديه الـ method المسمى summarize معرفًا بهذا التوقيع (signature) تمامًا.
يمكن أن يحتوي الـ trait على عدة methods في جسمه: يتم إدراج الـ method signatures واحدًا تلو الآخر في كل سطر، وينتهي كل سطر بفاصلة منقوطة.
تنفيذ سمة على نوع (Implementing a Trait on a Type)
الآن بعد أن حددنا التواقيع المطلوبة لـ methods سمة Summary يمكننا تنفيذها على الأنواع في مجمع الوسائط الخاص بنا. توضح القائمة 10-13 تنفيذًا لـ Summary trait على هيكل NewsArticle يستخدم العنوان الرئيسي، والمؤلف، والموقع لإنشاء القيمة المعادة من summarize. بالنسبة لهيكل SocialPost نحدد summarize كاسم المستخدم متبوعًا بالنص الكامل للمنشور، بافتراض أن محتوى المنشور محدود بالفعل بـ 280 حرفًا.
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}تنفيذ trait على نوع يشبه تنفيذ الـ methods العادية. الفرق هو أنه بعد impl نضع اسم الـ trait الذي نريد تنفيذه، ثم نستخدم الكلمة المفتاحية for ثم نحدد اسم النوع الذي نريد تنفيذ الـ trait له. داخل كتلة impl نضع الـ method signatures التي حددها تعريف الـ trait. وبدلاً من إضافة فاصلة منقوطة بعد كل signature، نستخدم الأقواس المتعرجة ونملأ جسم الـ method بالسلوك المحدد الذي نريده لـ methods الـ trait لهذا النوع المعين.
الآن بعد أن نفذت المكتبة الـ Summary trait على NewsArticle و SocialPost يمكن لمستخدمي الـ crate استدعاء الـ trait methods على instances من NewsArticle و SocialPost بنفس الطريقة التي نستدعي بها الـ methods العادية. الفرق الوحيد هو أنه يجب على المستخدم إحضار الـ trait إلى النطاق (scope) بالإضافة إلى الأنواع. إليك مثال على كيفية استخدام binary crate لمكتبة aggregator الخاصة بنا:
use aggregator::{SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}يطبع هذا الكود 1 new post: horse_ebooks: of course, as you probably already know, people.
يمكن للـ crates الأخرى التي تعتمد على aggregator crate أيضًا إحضار الـ Summary trait إلى الـ scope لتنفيذ Summary على أنواعها الخاصة. أحد القيود التي يجب ملاحظتها هو أنه يمكننا تنفيذ trait على نوع فقط إذا كان الـ trait أو النوع، أو كلاهما، محليًا (local) للـ crate الخاصة بنا. على سبيل المثال، يمكننا تنفيذ traits المكتبة القياسية (standard library) مثل Display على نوع مخصص مثل SocialPost كجزء من وظائف aggregator crate لأن النوع SocialPost محلي لـ aggregator crate الخاصة بنا. يمكننا أيضًا تنفيذ Summary على Vec<T> في aggregator crate لأن الـ trait المسمى Summary محلي لـ aggregator crate الخاصة بنا.
لكن لا يمكننا تنفيذ traits خارجية على أنواع خارجية. على سبيل المثال، لا يمكننا تنفيذ الـ Display trait على Vec<T> داخل aggregator crate الخاصة بنا، لأن Display و Vec<T> كلاهما معرفان في المكتبة القياسية وليسا محليين لـ aggregator crate الخاصة بنا. هذا القيد هو جزء من خاصية تسمى التماسك (coherence)، وبشكل أكثر تحديدًا قاعدة اليتيم (orphan rule)، وسميت بهذا الاسم لأن النوع الأب غير موجود. تضمن هذه القاعدة أن كود الأشخاص الآخرين لا يمكنه كسر كودك والعكس صحيح. بدون هذه القاعدة، يمكن لـ crates اثنتين تنفيذ نفس الـ trait لنفس النوع، ولن يعرف Rust أي تنفيذ يستخدم.
استخدام التنفيذات الافتراضية (Using Default Implementations)
أحيانًا يكون من المفيد الحصول على سلوك افتراضي (default behavior) لبعض أو كل الـ methods في trait بدلاً من طلب تنفيذات لجميع الـ methods على كل نوع. بعد ذلك، عندما ننفذ الـ trait على نوع معين، يمكننا الاحتفاظ بالسلوك الافتراضي لكل method أو تجاوزه (override).
في القائمة 10-14، نحدد سلسلة نصية افتراضية لدالة summarize في سمة Summary بدلاً من الاكتفاء بتعريف الـ method signature، كما فعلنا في القائمة 10-12.
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}لاستخدام تنفيذ افتراضي لتلخيص instances من NewsArticle نحدد كتلة impl فارغة باستخدام impl Summary for NewsArticle {}.
على الرغم من أننا لم نعد نعرف دالة summarize على NewsArticle مباشرة، فقد قدمنا تنفيذًا افتراضيًا وحددنا أن NewsArticle ينفذ الـ Summary trait. ونتيجة لذلك، لا يزال بإمكاننا استدعاء دالة summarize على instance من NewsArticle بهذا الشكل:
use aggregator::{self, NewsArticle, Summary};
fn main() {
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
};
println!("New article available! {}", article.summarize());
}يطبع هذا الكود New article available! (Read more...).
إنشاء تنفيذ افتراضي لا يتطلب منا تغيير أي شيء في تنفيذ Summary على SocialPost في القائمة 10-13. والسبب هو أن بناء الجملة (syntax) لتجاوز تنفيذ افتراضي هو نفسه الـ syntax لتنفيذ trait method ليس له تنفيذ افتراضي.
يمكن للتنفيذات الافتراضية استدعاء methods أخرى في نفس الـ trait، حتى لو لم يكن لتلك الـ methods الأخرى تنفيذ افتراضي. بهذه الطريقة، يمكن لـ trait توفير الكثير من الوظائف المفيدة وتتطلب فقط من المنفذين تحديد جزء صغير منها. على سبيل المثال، يمكننا تعريف الـ Summary trait ليكون له دالة summarize_author التي يكون تنفيذها مطلوبًا، ثم تعريف دالة summarize لها تنفيذ افتراضي يستدعي دالة summarize_author:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}لاستخدام هذه النسخة من Summary نحتاج فقط إلى تعريف summarize_author عندما ننفذ الـ trait على نوع ما:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}بعد تعريف summarize_author يمكننا استدعاء summarize على instances من هيكل SocialPost وسيقوم التنفيذ الافتراضي لـ summarize باستدعاء تعريف summarize_author الذي قدمناه. نظرًا لأننا نفذنا summarize_author فقد منحتنا الـ Summary trait سلوك دالة summarize دون مطالبتنا بكتابة أي كود إضافي. إليك كيف يبدو ذلك:
use aggregator::{self, SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}يطبع هذا الكود 1 new post: (Read more from @horse_ebooks...).
لاحظ أنه ليس من الممكن استدعاء التنفيذ الافتراضي من تنفيذ متجاوز (overriding implementation) لنفس الـ method.
استخدام السمات كمعاملات (Using Traits as Parameters)
الآن بعد أن عرفت كيفية تعريف وتنفيذ الـ traits، يمكننا استكشاف كيفية استخدام الـ traits لتعريف دوال تقبل العديد من الأنواع المختلفة. سنستخدم الـ Summary trait الذي نفذناه على نوعي NewsArticle و SocialPost في القائمة 10-13 لتعريف دالة notify تستدعي دالة summarize على معاملها (parameter) المسمى item وهو من نوع ما ينفذ الـ Summary trait. للقيام بذلك، نستخدم الـ impl Trait syntax بهذا الشكل:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}بدلاً من نوع ملموس (concrete type) للمعامل item نحدد الكلمة المفتاحية impl واسم الـ trait. يقبل هذا الـ parameter أي نوع ينفذ الـ trait المحدد. في جسم notify يمكننا استدعاء أي methods على item تأتي من الـ Summary trait، مثل summarize. يمكننا استدعاء notify وتمرير أي instance من NewsArticle أو SocialPost. الكود الذي يستدعي الدالة مع أي نوع آخر، مثل String أو i32 لن يترجم، لأن تلك الأنواع لا تنفذ Summary.
بناء جملة قيد السمة (Trait Bound Syntax)
يعمل الـ impl Trait syntax في الحالات المباشرة ولكنه في الواقع عبارة عن اختصار برمجي (syntax sugar) لشكل أطول يعرف باسم قيد السمة (trait bound)؛ ويبدو هكذا:
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}هذا الشكل الأطول مكافئ للمثال في القسم السابق ولكنه أكثر تفصيلاً. نضع الـ trait bounds مع الإعلان عن معامل النوع العام (generic type parameter) بعد نقطتين وداخل أقواس زاوية.
يعتبر الـ trait bound syntax مناسبًا للحالات الأكثر تعقيدًا. على سبيل المثال، يمكن أن يكون لدينا معاملان ينفذان Summary. القيام بذلك باستخدام الـ impl Trait syntax يبدو هكذا:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {استخدام impl Trait مناسب إذا أردنا أن تسمح هذه الدالة لـ item1 و item2 بأن يكون لهما نوعان مختلفان (طالما أن كلا النوعين ينفذان Summary). أما إذا أردنا إجبار كلا المعاملين على أن يكون لهما نفس النوع، فيجب علينا استخدام trait bound بهذا الشكل:
pub fn notify<T: Summary>(item1: &T, item2: &T) {النوع العام T المحدد كنوع للمعاملين item1 و item2 يقيد الدالة بحيث يجب أن يكون النوع الملموس للقيمة الممررة كوسيط (argument) لـ item1 و item2 هو نفسه.
قيود سمات متعددة باستخدام الـ + Syntax (Multiple Trait Bounds with the + Syntax)
يمكننا أيضًا تحديد أكثر من trait bound واحد. لنفترض أننا أردنا أن تستخدم notify تنسيق العرض (display formatting) بالإضافة إلى summarize على item: نحدد في تعريف notify أن item يجب أن ينفذ كلاً من Display و Summary. يمكننا القيام بذلك باستخدام الـ + syntax:
pub fn notify(item: &(impl Summary + Display)) {الـ + syntax صالح أيضًا مع الـ trait bounds على الأنواع العامة:
pub fn notify<T: Summary + Display>(item: &T) {مع تحديد قيدي السمة، يمكن لجسم notify استدعاء summarize واستخدام {} لتنسيق item.
قيود سمات أكثر وضوحًا باستخدام بنود where (Clearer Trait Bounds with where Clauses)
استخدام الكثير من الـ trait bounds له سلبياته. فكل نوع عام له الـ trait bounds الخاصة به، لذا فإن الدوال التي تحتوي على عدة معاملات أنواع عامة يمكن أن تحتوي على الكثير من معلومات الـ trait bound بين اسم الدالة وقائمة معاملاتها، مما يجعل توقيع الدالة (function signature) صعب القراءة. لهذا السبب، يمتلك Rust بناء جملة بديلاً لتحديد الـ trait bounds داخل بند where بعد function signature. لذا، بدلاً من كتابة هذا:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {يمكننا استخدام بند where بهذا الشكل:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}توقيع هذه الدالة أقل فوضى: اسم الدالة، وقائمة المعاملات، ونوع الإرجاع قريبة من بعضها البعض، بشكل مشابه لدالة لا تحتوي على الكثير من الـ trait bounds.
إرجاع الأنواع التي تنفذ السمات (Returning Types That Implement Traits)
يمكننا أيضًا استخدام الـ impl Trait syntax في موضع الإرجاع لإعادة قيمة من نوع ما ينفذ trait، كما هو موضح هنا:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable() -> impl Summary {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}باستخدام impl Summary لنوع الإرجاع، نحدد أن دالة returns_summarizable تعيد نوعًا ما ينفذ الـ Summary trait دون تسمية النوع الملموس. في هذه الحالة، تعيد returns_summarizable هيكل SocialPost ولكن الكود الذي يستدعي هذه الدالة لا يحتاج إلى معرفة ذلك.
القدرة على تحديد نوع الإرجاع فقط من خلال الـ trait الذي ينفذه مفيدة بشكل خاص في سياق الـ closures والـ iterators، والتي نغطيها في الفصل 13. تنشئ الـ closures والـ iterators أنواعًا لا يعرفها إلا المترجم أو أنواعًا طويلة جدًا في تحديدها. يتيح لك الـ impl Trait syntax تحديد أن الدالة تعيد نوعًا ما ينفذ الـ Iterator trait بإيجاز دون الحاجة إلى كتابة نوع طويل جدًا.
ومع ذلك، يمكنك فقط استخدام impl Trait إذا كنت تعيد نوعًا واحدًا فقط. على سبيل المثال، هذا الكود الذي يعيد إما NewsArticle أو SocialPost مع تحديد نوع الإرجاع كـ impl Summary لن يعمل:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}
}إرجاع إما NewsArticle أو SocialPost غير مسموح به بسبب قيود حول كيفية تنفيذ الـ impl Trait syntax في المترجم. سنغطي كيفية كتابة دالة بهذا السلوك في قسم “استخدام كائنات السمات للتجريد فوق السلوك المشترك” من الفصل 18.
استخدام قيود السمات لتنفيذ الدوال بشكل مشروط (Using Trait Bounds to Conditionally Implement Methods)
باستخدام trait bound مع كتلة impl تستخدم معاملات أنواع عامة، يمكننا تنفيذ الـ methods بشكل مشروط للأنواع التي تنفذ الـ traits المحددة. على سبيل المثال، النوع Pair<T> في القائمة 10-15 ينفذ دائمًا دالة new لإعادة instance جديد من Pair<T> (تذكر من قسم “بناء جملة الدالة” في الفصل 5 أن Self هو اسم مستعار لنوع كتلة impl وهو في هذه الحالة Pair<T>). ولكن في كتلة impl التالية، ينفذ Pair<T> دالة cmp_display فقط إذا كان نوعه الداخلي T ينفذ الـ PartialOrd trait الذي يتيح المقارنة و الـ Display trait الذي يتيح الطباعة.
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}يمكننا أيضًا تنفيذ trait بشكل مشروط لأي نوع ينفذ trait آخر. تسمى تنفيذات trait على أي نوع يستوفي الـ trait bounds بـ التنفيذات الشاملة (blanket implementations) وتستخدم على نطاق واسع في مكتبة Rust القياسية. على سبيل المثال، تنفذ المكتبة القياسية الـ ToString trait على أي نوع ينفذ الـ Display trait. تبدو كتلة impl في المكتبة القياسية مشابهة لهذا الكود:
impl<T: Display> ToString for T {
// --snip--
}نظرًا لأن المكتبة القياسية تمتلك هذا الـ blanket implementation، يمكننا استدعاء دالة to_string المعرفة بواسطة الـ ToString trait على أي نوع ينفذ الـ Display trait. على سبيل المثال، يمكننا تحويل الأعداد الصحيحة (integers) إلى قيم String المقابلة لها بهذا الشكل لأن الأعداد الصحيحة تنفذ Display:
#![allow(unused)]
fn main() {
let s = 3.to_string();
}تظهر الـ blanket implementations في التوثيق الخاص بالـ trait في قسم “المنفذون” (Implementors).
تتيح لنا الـ traits والـ trait bounds كتابة كود يستخدم معاملات أنواع عامة لتقليل التكرار ولكنها تحدد أيضًا للمترجم أننا نريد أن يمتلك النوع العام سلوكًا معينًا. يمكن للمترجم بعد ذلك استخدام معلومات الـ trait bound للتحقق من أن جميع الأنواع الملموسة المستخدمة مع كودنا توفر السلوك الصحيح. في اللغات ذات الأنواع الديناميكية (dynamically typed languages)، سنحصل على خطأ في وقت التشغيل (runtime) إذا استدعينا دالة على نوع لم يحدد تلك الدالة. لكن Rust ينقل هذه الأخطاء إلى وقت الترجمة (compile time) بحيث نضطر إلى إصلاح المشكلات قبل أن يتمكن كودنا من العمل. بالإضافة إلى ذلك، لا يتعين علينا كتابة كود يتحقق من السلوك في وقت التشغيل، لأننا تحققنا بالفعل في وقت الترجمة. القيام بذلك يحسن الأداء دون الحاجة إلى التخلي عن مرونة الأنواع العامة (generics).
التحقق من المراجع باستخدام الأعمار (Lifetimes)
التحقق من صحة المراجع باستخدام فترات الحياة (Lifetimes)
تعد فترات الحياة (Lifetimes) نوعاً آخر من الأنواع العامة (Generics) التي كنا نستخدمها بالفعل. بدلاً من التأكد من أن النوع يمتلك السلوك الذي نريده، تضمن الـ Lifetimes أن المراجع (References) تظل صالحة طالما احتجنا إليها.
أحد التفاصيل التي لم نناقشها في قسم “المراجع والاستعارة” في الفصل الرابع هو أن كل Reference في Rust له Lifetime، وهو النطاق (Scope) الذي يكون فيه هذا المرجع صالحاً. في معظم الأوقات، تكون الـ Lifetimes ضمنية ومستنتجة، تماماً كما يتم استنتاج الأنواع في معظم الأوقات. نحن مطالبون فقط بتوضيح (Annotate) الأنواع عندما يكون هناك عدة أنواع ممكنة. وبطريقة مماثلة، يجب علينا توضيح الـ Lifetimes عندما يمكن أن ترتبط فترات حياة المراجع ببعضها البعض بعدة طرق مختلفة. تتطلب Rust منا توضيح هذه العلاقات باستخدام معاملات فترات الحياة العامة (Generic Lifetime Parameters) لضمان أن المراجع الفعلية المستخدمة في وقت التشغيل ستكون صالحة بالتأكيد.
إن توضيح الـ Lifetimes ليس مفهوماً موجوداً في معظم لغات البرمجة الأخرى، لذا سيبدو هذا الأمر غير مألوف. على الرغم من أننا لن نغطي فترات الحياة بالكامل في هذا الفصل، إلا أننا سنناقش الطرق الشائعة التي قد تواجه فيها صيغة فترات الحياة (Lifetime Syntax) حتى تتمكن من التعود على هذا المفهوم.
المراجع المعلقة (Dangling References)
الهدف الرئيسي من الـ Lifetimes هو منع المراجع المعلقة (Dangling References)، والتي إذا سُمح بوجودها، فستتسبب في إشارة البرنامج إلى بيانات غير البيانات المقصود الإشارة إليها. فكر في البرنامج الموجود في القائمة 10-16، والذي يحتوي على نطاق خارجي (Outer Scope) ونطاق داخلي (Inner Scope).
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}ملاحظة: تعلن الأمثلة في القوائم 10-16 و10-17 و10-23 عن متغيرات دون إعطائها قيمة أولية، لذا فإن اسم المتغير موجود في الـ Outer Scope. للوهلة الأولى، قد يبدو هذا متعارضاً مع عدم وجود قيم فارغة (Null) في Rust. ومع ذلك، إذا حاولنا استخدام متغير قبل إعطائه قيمة، فسنحصل على خطأ في وقت التجميع (Compile-time Error)، مما يوضح أن Rust بالفعل لا تسمح بالقيم الـ Null.
يعلن الـ Outer Scope عن متغير باسم r بدون قيمة أولية، ويعلن الـ Inner Scope عن متغير باسم x بقيمة أولية قدرها 5. داخل الـ Inner Scope، نحاول تعيين قيمة r كمرجع لـ x. ثم ينتهي الـ Inner Scope، ونحاول طباعة القيمة الموجودة في r. لن يتم تجميع هذا الكود، لأن القيمة التي يشير إليها r قد خرجت عن الـ Scope قبل أن نحاول استخدامها. إليك رسالة الخطأ:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
تقول رسالة الخطأ أن المتغير x “لا يعيش لفترة كافية”. والسبب هو أن x سيخرج عن الـ Scope عندما ينتهي الـ Inner Scope في السطر 7. لكن r لا يزال صالحاً للـ Outer Scope؛ ولأن نطاقه أكبر، نقول إنه “يعيش لفترة أطول”. إذا سمحت Rust لهذا الكود بالعمل، فسيشير r إلى ذاكرة تم إلغاء تخصيصها عندما خرج x عن الـ Scope، وأي شيء نحاول القيام به باستخدام r لن يعمل بشكل صحيح. إذاً، كيف تحدد Rust أن هذا الكود غير صالح؟ إنها تستخدم مدقق الاستعارة (Borrow Checker).
مدقق الاستعارة (Borrow Checker)
يحتوي مترجم Rust على مدقق استعارة (Borrow Checker) يقارن النطاقات لتحديد ما إذا كانت جميع الاستعارات (Borrows) صالحة. توضح القائمة 10-17 نفس الكود الموجود في القائمة 10-16 ولكن مع توضيحات تظهر الـ Lifetimes للمتغيرات.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+هنا، قمنا بتوضيح الـ Lifetime لـ r بـ 'a والـ Lifetime لـ x بـ 'b. كما ترون، فإن كتلة 'b الداخلية أصغر بكثير من كتلة الـ Lifetime 'a الخارجية. في وقت التجميع، تقارن Rust حجم فترتي الحياة وترى أن r له Lifetime قدره 'a ولكنه يشير إلى ذاكرة بـ Lifetime قدره 'b. يتم رفض البرنامج لأن 'b أقصر من 'a: فصاحب المرجع لا يعيش طويلاً مثل المرجع نفسه.
تقوم القائمة 10-18 بإصلاح الكود بحيث لا يحتوي على Dangling Reference ويتم تجميعه دون أي أخطاء.
fn main() {
let x = 5; // ----------+-- 'b
// |
let r = &x; // --+-- 'a |
// | |
println!("r: {r}"); // | |
// --+ |
} // ----------+هنا، يمتلك x الـ Lifetime 'b والتي في هذه الحالة أكبر من 'a. هذا يعني أن r يمكنه الإشارة إلى x لأن Rust تعلم أن المرجع في r سيكون دائماً صالحاً طالما أن x صالح.
الآن بعد أن عرفت أين توجد الـ Lifetimes للمراجع وكيف تحلل Rust فترات الحياة لضمان أن المراجع ستكون دائماً صالحة، دعنا نستكشف الـ Generic Lifetimes في معاملات الدوال والقيم المرتجعة.
فترات الحياة العامة في الدوال (Generic Lifetimes in Functions)
سنكتب دالة تعيد السلسلة الأطول من بين شريحتين نصيتين (String Slices). ستأخذ هذه الدالة شريحتين نصيتين وتعيد شريحة نصية واحدة. بعد تنفيذ دالة longest يجب أن يطبع الكود في القائمة 10-19 عبارة The longest string is abcd.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}لاحظ أننا نريد أن تأخذ الدالة String Slices، وهي مراجع، بدلاً من سلاسل نصية (Strings)، لأننا لا نريد لدالة longest أن تأخذ ملكية (Ownership) معاملاتها. ارجع إلى قسم “شرائح النصوص كمعاملات” في الفصل الرابع لمزيد من النقاش حول سبب كون المعاملات التي نستخدمها في القائمة 10-19 هي التي نريدها.
إذا حاولنا تنفيذ دالة longest كما هو موضح في القائمة 10-20، فلن يتم تجميعها.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}بدلاً من ذلك، نحصل على خطأ يتحدث عن الـ Lifetimes:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
يكشف نص المساعدة أن النوع المرتجع يحتاج إلى Generic Lifetime Parameter عليه لأن Rust لا تستطيع تحديد ما إذا كان المرجع الذي يتم إرجاعه يشير إلى x أو y. في الواقع، نحن لا نعرف ذلك أيضاً، لأن كتلة if في جسم هذه الدالة تعيد مرجعاً لـ x وكتلة else تعيد مرجعاً لـ y!
عندما نقوم بتعريف هذه الدالة، فإننا لا نعرف القيم الملموسة (Concrete Values) التي سيتم تمريرها إليها، لذا لا نعرف ما إذا كانت حالة if أو حالة else هي التي ستنفذ. كما أننا لا نعرف الـ Concrete Lifetimes للمراجع التي سيتم تمريرها، لذا لا يمكننا النظر في النطاقات كما فعلنا في القوائم 10-17 و10-18 لتحديد ما إذا كان المرجع الذي نعيده سيكون دائماً صالحاً. لا يمكن للـ Borrow Checker تحديد ذلك أيضاً، لأنه لا يعرف كيف ترتبط فترات حياة x و y بـ Lifetime القيمة المرتجعة. لإصلاح هذا الخطأ، سنضيف Generic Lifetime Parameters تحدد العلاقة بين المراجع حتى يتمكن الـ Borrow Checker من إجراء تحليله.
صيغة توضيح فترة الحياة (Lifetime Annotation Syntax)
لا تغير توضيحات فترة الحياة (Lifetime Annotations) مدة بقاء أي من المراجع. بدلاً من ذلك، فهي تصف علاقات فترات حياة مراجع متعددة ببعضها البعض دون التأثير على فترات الحياة. تماماً كما يمكن للدوال قبول أي نوع عندما يحدد التوقيع (Signature) معامل نوع عام، يمكن للدوال قبول مراجع بأي Lifetime من خلال تحديد Generic Lifetime Parameter.
تمتلك الـ Lifetime Annotations صيغة غير معتادة قليلاً: يجب أن تبدأ أسماء معاملات فترة الحياة بفاصلة عليا (') وعادة ما تكون كلها أحرفاً صغيرة وقصيرة جداً، مثل الأنواع العامة. يستخدم معظم الناس الاسم 'a لأول Lifetime Annotation. نضع توضيحات معاملات فترة الحياة بعد علامة & للمرجع، مع استخدام مسافة لفصل التوضيح عن نوع المرجع.
إليك بعض الأمثلة: مرجع لـ i32 بدون معامل فترة حياة، ومرجع لـ i32 له معامل فترة حياة باسم 'a ومرجع قابل للتغيير (Mutable Reference) لـ i32 له أيضاً فترة الحياة 'a:
&i32 // مرجع
&'a i32 // مرجع مع فترة حياة صريحة
&'a mut i32 // مرجع قابل للتغيير مع فترة حياة صريحةتوضيح فترة حياة واحد بمفرده ليس له معنى كبير، لأن التوضيحات تهدف إلى إخبار Rust بكيفية ارتباط الـ Generic Lifetime Parameters لمراجع متعددة ببعضها البعض. دعنا نفحص كيف ترتبط الـ Lifetime Annotations ببعضها البعض في سياق دالة longest.
في تواقيع الدوال (Function Signatures)
لاستخدام الـ Lifetime Annotations في تواقيع الدوال، نحتاج إلى الإعلان عن الـ Generic Lifetime Parameters داخل أقواس زاوية بين اسم الدالة وقائمة المعاملات، تماماً كما فعلنا مع معاملات الأنواع العامة.
نريد أن يعبر الـ Signature عن القيد التالي: المرجع المرتجع سيكون صالحاً طالما أن كلا المعاملين صالحان. هذه هي العلاقة بين فترات حياة المعاملات والقيمة المرتجعة. سنسمي فترة الحياة 'a ثم نضيفها إلى كل مرجع، كما هو موضح في القائمة 10-21.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}يجب أن يتم تجميع هذا الكود وينتج النتيجة التي نريدها عندما نستخدمه مع دالة main في القائمة 10-19.
يخبر الـ Signature الآن Rust أنه لـ Lifetime ما 'a تأخذ الدالة معاملين، كلاهما String Slices يعيشان على الأقل طالما تعيش فترة الحياة 'a. يخبر الـ Signature أيضاً Rust أن الـ String Slice المرتجع من الدالة سيعيش على الأقل طالما تعيش فترة الحياة 'a. من الناحية العملية، هذا يعني أن فترة حياة المرجع الذي تعيده الدالة… (تم اختصار المحتوى بسبب حدود الحجم)
…
fn first_word<'a>(s: &'a str) -> &'a str {الآن تمتلك جميع المراجع في الـ Signature فترات حياة، ويمكن للمترجم مواصلة تحليله دون حاجة المبرمج لتوضيح فترات الحياة في هذا الـ Signature.
دعنا ننظر في مثال آخر، هذه المرة باستخدام دالة longest التي لم تكن تحتوي على معاملات فترة حياة عندما بدأنا العمل عليها في القائمة 10-20:
fn longest(x: &str, y: &str) -> &str {دعنا نطبق القاعدة الأولى: يحصل كل معامل على فترة حياة خاصة به. هذه المرة لدينا معاملان بدلاً من واحد، لذا لدينا فترتا حياة:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {يمكنك أن ترى أن القاعدة الثانية لا تنطبق، لأن هناك أكثر من فترة حياة مدخلة واحدة. القاعدة الثالثة لا تنطبق أيضاً، لأن longest هي دالة وليست دالة مرتبطة (Method)، لذا لا يوجد أي من المعاملات هو self. بعد المرور بجميع القواعد الثلاث، ما زلنا لم نكتشف ما هي فترة حياة النوع المرتجع. لهذا السبب حصلنا على خطأ عند محاولة تجميع الكود في القائمة 10-20: لقد مر المترجم عبر قواعد حذف فترة الحياة (Lifetime Elision Rules) ولكنه لم يتمكن بعد من اكتشاف جميع فترات حياة المراجع في الـ Signature.
ولأن القاعدة الثالثة تنطبق حقاً فقط في تواقيع الدوال المرتبطة (Method Signatures)، فسننظر في فترات الحياة في ذلك السياق تالياً لنرى لماذا تعني القاعدة الثالثة أننا لا نضطر لتوضيح فترات الحياة في الـ Method Signatures في كثير من الأحيان.
في تعريفات الدوال المرتبطة (Method Definitions)
عندما نقوم بتنفيذ Methods على هيكل (Struct) يحتوي على فترات حياة، نستخدم نفس الصيغة المستخدمة لمعاملات الأنواع العامة، كما هو موضح في القائمة 10-11. يعتمد مكان الإعلان عن معاملات فترات الحياة واستخدامها على ما إذا كانت مرتبطة بحقول الهيكل أو بمعاملات الـ Method والقيم المرتجعة.
يجب دائماً الإعلان عن أسماء فترات الحياة لحقول الهيكل بعد الكلمة المفتاحية impl ثم استخدامها بعد اسم الهيكل لأن فترات الحياة هذه جزء من نوع الهيكل.
في الـ Method Signatures داخل كتلة impl قد تكون المراجع مرتبطة بفترة حياة المراجع في حقول الهيكل، أو قد تكون مستقلة. بالإضافة إلى ذلك، غالباً ما تجعل الـ Lifetime Elision Rules توضيحات فترة الحياة غير ضرورية في الـ Method Signatures. دعنا ننظر في بعض الأمثلة باستخدام الهيكل المسمى ImportantExcerpt الذي عرفناه في القائمة 10-24.
أولاً، سنستخدم Method تسمى level معاملها الوحيد هو مرجع لـ self وقيمتها المرتجعة هي i32 وهو ليس مرجعاً لأي شيء:
struct ImportantExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
fn level(&self) -> i32 {
3
}
}
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {announcement}");
self.part
}
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}الإعلان عن معامل فترة الحياة بعد impl واستخدامه بعد اسم النوع مطلوبان، ولكن بسبب قاعدة الحذف الأولى، لسنا مطالبين بتوضيح فترة حياة المرجع لـ self.
إليك مثال تنطبق فيه الـ Lifetime Elision Rule الثالثة:
struct ImportantExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
fn level(&self) -> i32 {
3
}
}
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {announcement}");
self.part
}
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}هناك فترتا حياة مدخلتان، لذا تطبق Rust قاعدة حذف فترة الحياة الأولى وتعطي كلاً من &self و announcement فترات حياة خاصة بهما. ثم، ولأن أحد المعاملات هو &self يحصل النوع المرتجع على فترة حياة &self وبذلك تم حساب جميع فترات الحياة.
فترة الحياة الساكنة (Static Lifetime)
إحدى فترات الحياة الخاصة التي نحتاج لمناقشتها هي 'static والتي تشير إلى أن المرجع المتأثر يمكن أن يعيش طوال مدة البرنامج. جميع السلاسل النصية الثابتة (String Literals) لها فترة الحياة 'static والتي يمكننا توضيحها كما يلي:
#![allow(unused)]
fn main() {
let s: &'static str = "I have a static lifetime.";
}يتم تخزين نص هذه السلسلة مباشرة في الملف الثنائي للبرنامج، والذي يكون متاحاً دائماً. لذلك، فإن فترة حياة جميع الـ String Literals هي 'static.
قد ترى اقتراحات في رسائل الخطأ لاستخدام فترة الحياة 'static. ولكن قبل تحديد 'static كفترة حياة لمرجع ما، فكر فيما إذا كان المرجع الذي لديك يعيش بالفعل طوال فترة حياة برنامجك، وما إذا كنت تريد ذلك. في معظم الأوقات، تنتج رسالة الخطأ التي تقترح فترة الحياة 'static عن محاولة إنشاء Dangling Reference أو عدم تطابق في فترات الحياة المتاحة. في مثل هذه الحالات، الحل هو إصلاح تلك المشكلات، وليس تحديد فترة الحياة 'static.
معاملات الأنواع العامة، وقيود السمات، وفترات الحياة معاً
دعنا نلقي نظرة سريعة على صيغة تحديد معاملات الأنواع العامة، وقيود السمات (Trait Bounds)، وفترات الحياة جميعاً في دالة واحدة!
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest_with_an_announcement(
string1.as_str(),
string2,
"Today is someone's birthday!",
);
println!("The longest string is {result}");
}
use std::fmt::Display;
fn longest_with_an_announcement<'a, T>(
x: &'a str,
y: &'a str,
ann: T,
) -> &'a str
where
T: Display,
{
println!("Announcement! {ann}");
if x.len() > y.len() { x } else { y }
}هذه هي دالة longest من القائمة 10-21 التي تعيد الأطول بين شريحتين نصيتين. ولكن الآن لديها معامل إضافي باسم ann من النوع العام T والذي يمكن ملؤه بأي نوع ينفذ سمة Display كما هو محدد في بند where. سيتم طباعة هذا المعامل الإضافي باستخدام {} ولهذا السبب كان قيد سمة Display ضرورياً. ولأن فترات الحياة هي نوع من الأنواع العامة، فإن الإعلانات عن معامل فترة الحياة 'a ومعامل النوع العام T توضع في نفس القائمة داخل أقواس الزاوية بعد اسم الدالة.
ملخص
لقد غطينا الكثير في هذا الفصل! الآن بعد أن عرفت عن معاملات الأنواع العامة، والسمات وقيود السمات، ومعاملات فترات الحياة العامة، فأنت جاهز لكتابة كود بدون تكرار يعمل في العديد من المواقف المختلفة. تسمح لك معاملات الأنواع العامة بتطبيق الكود على أنواع مختلفة. تضمن السمات وقيود السمات أنه على الرغم من أن الأنواع عامة، إلا أنها ستمتلك السلوك الذي يحتاجه الكود. لقد تعلمت كيفية استخدام الـ Lifetime Annotations لضمان أن هذا الكود المرن لن يحتوي على أي Dangling References. وكل هذا التحليل يحدث في وقت التجميع، مما لا يؤثر على أداء وقت التشغيل!
صدق أو لا تصدق، هناك الكثير لتعلمه حول المواضيع التي ناقشناها في هذا الفصل: يناقش الفصل 18 كائنات السمات (Trait Objects)، وهي طريقة أخرى لاستخدام السمات. هناك أيضاً سيناريوهات أكثر تعقيداً تتضمن الـ Lifetime Annotations والتي ستحتاج إليها فقط في سيناريوهات متقدمة جداً؛ ولتلك الحالات، يجب عليك قراءة مرجع Rust. ولكن تالياً، ستتعلم كيفية كتابة الاختبارات في Rust حتى تتمكن من التأكد من أن الكود الخاص بك يعمل بالطريقة التي ينبغي أن يعمل بها.
كتابة الاختبارات المؤتمتة (Writing Automated Tests)
في مقاله الصادر عام 1972 بعنوان “المبرمج المتواضع” (The Humble Programmer)، قال إيدجر ديجكسترا (Edsger W. Dijkstra) إن “اختبار البرامج (program testing) يمكن أن يكون وسيلة فعالة للغاية لإظهار وجود الأخطاء البرمجية (bugs)، ولكنه غير كافٍ بشكل يائس لإظهار غيابها”. هذا لا يعني أنه لا ينبغي لنا محاولة الاختبار قدر استطاعتنا!
الصحة (Correctness) في برامجنا هي مدى قيام الكود الخاص بنا بما نعتزم القيام به. تم تصميم Rust مع درجة عالية من الاهتمام بصحة البرامج، لكن الصحة معقدة وليس من السهل إثباتها. يتحمل نظام الأنواع (type system) في Rust جزءاً كبيراً من هذا العبء، لكن type system لا يمكنه التقاط كل شيء. على هذا النحو، تتضمن Rust دعماً لكتابة اختبارات البرمجيات المؤتمتة (automated software tests).
لنفترض أننا كتبنا دالة add_two تضيف 2 إلى أي رقم يتم تمريره إليها. يقبل توقيع هذه الدالة (signature) عدداً صحيحاً كمعلمة (parameter) ويُرجع عدداً صحيحاً كنيتجة. عندما نقوم بتنفيذ وتصريف (compile) هذه الدالة، تقوم Rust بجميع عمليات التحقق من النوع (type checking) والتحقق من الاستعارة (borrow checking) التي تعلمتها حتى الآن للتأكد، على سبيل المثال، من أننا لا نمرر قيمة String أو مرجعاً (reference) غير صالح لهذه الدالة. لكن Rust لا يمكنها التحقق من أن هذه الدالة ستفعل بالضبط ما نعتزم القيام به، وهو إرجاع parameter مضافاً إليه 2 بدلاً من، لنقل، parameter مضافاً إليه 10 أو parameter مطروحاً منه 50! وهنا يأتي دور الاختبارات.
يمكننا كتابة اختبارات تؤكد (assert)، على سبيل المثال، أنه عندما نمرر 3 إلى دالة add_two ، فإن القيمة المرجعة هي 5. يمكننا تشغيل هذه الاختبارات كلما أجرينا تغييرات على الكود الخاص بنا للتأكد من أن أي سلوك صحيح موجود لم يتغير.
الاختبار مهارة معقدة: على الرغم من أننا لا نستطيع تغطية كل التفاصيل حول كيفية كتابة اختبارات جيدة في فصل واحد، إلا أننا سنناقش في هذا الفصل آليات مرافق الاختبار في Rust. سنتحدث عن التوضيحات الشارحة (annotations) والماكرو (macros) المتاحة لك عند كتابة اختباراتك، والسلوك الافتراضي والخيارات المقدمة لتشغيل اختباراتك، وكيفية تنظيم الاختبارات إلى اختبارات الوحدة (unit tests) واختبارات التكامل (integration tests).
كيفية كتابة الاختبارات (Tests)
كيفية كتابة الاختبارات
الاختبارات (Tests) هي دوال Rust (Rust functions) تتحقق من أن الكود غير الاختباري (non-test code) يعمل بالطريقة المتوقعة. عادةً ما تقوم نصوص دوال الاختبار (test functions) بتنفيذ هذه الإجراءات الثلاثة:
- إعداد أي بيانات أو حالة مطلوبة.
- تشغيل الكود الذي تريد اختباره.
- التأكيد (Assert) على أن النتائج هي ما تتوقعه.
دعونا نلقي نظرة على الميزات التي توفرها Rust خصيصًا لكتابة الاختبارات التي تتخذ هذه الإجراءات، والتي تشمل السمة test (test attribute)، وبعض الماكرو (macro)، والسمة should_panic (should_panic attribute).
هيكلة دوال الاختبار (Structuring Test Functions)
في أبسط صورها، الاختبار في Rust هو دالة مُعلّمة بالسمة test. السمات (attribute) هي بيانات وصفية (metadata) حول أجزاء من كود Rust؛ أحد الأمثلة هو السمة derive التي استخدمناها مع الهياكل (structs) في الفصل الخامس. لتحويل دالة إلى دالة اختبار، أضف #[test] على السطر الذي يسبق fn. عند تشغيل الاختبارات الخاصة بك باستخدام أمر cargo test (cargo test command)، تقوم Rust ببناء ملف تنفيذي لمشغل الاختبار (test runner binary) يقوم بتشغيل الدوال المُعلّمة ويُبلغ عما إذا كانت كل دالة اختبار تنجح (passes) أو تفشل (fails).
عندما نقوم بإنشاء مشروع مكتبة (library project) جديد باستخدام Cargo، يتم إنشاء وحدة (module) اختبار تحتوي على دالة اختبار تلقائيًا لنا. توفر لك هذه الوحدة قالبًا لكتابة الاختبارات الخاصة بك بحيث لا تضطر إلى البحث عن الهيكلة (structure) والبنية (syntax) الدقيقة في كل مرة تبدأ فيها مشروعًا جديدًا. يمكنك إضافة أي عدد تريده من دوال الاختبار الإضافية وأي عدد تريده من وحدات الاختبار!
سوف نستكشف بعض جوانب كيفية عمل الاختبارات من خلال تجربة قالب الاختبار قبل أن نختبر أي كود فعليًا. بعد ذلك، سنكتب بعض الاختبارات الواقعية التي تستدعي بعض الكود الذي كتبناه وتؤكد أن سلوكه صحيح.
لنقم بإنشاء مشروع مكتبة جديد يسمى adder سيقوم بجمع رقمين:
$ cargo new adder --lib
Created library `adder` project
$ cd adder
يجب أن يبدو محتوى ملف src/lib.rs في مكتبة adder الخاصة بك كما في القائمة 11-1.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}يبدأ الملف بدالة add مثال حتى يكون لدينا شيء لاختباره.
في الوقت الحالي، دعونا نركز فقط على الدالة it_works. لاحظ التعليق التوضيحي #[test]: تشير هذه السمة إلى أن هذه دالة اختبار، لذا فإن test runner يعرف أن يتعامل مع هذه الدالة على أنها اختبار. قد يكون لدينا أيضًا دوال non-test في وحدة tests للمساعدة في إعداد سيناريوهات شائعة أو تنفيذ عمليات شائعة، لذلك نحتاج دائمًا إلى الإشارة إلى الدوال التي هي tests.
يستخدم نص الدالة المثال الماكرو assert_eq! (assert_eq! macro) للتأكيد على أن result، الذي يحتوي على نتيجة استدعاء add بالرقمين 2 و 2، يساوي 4. يعمل هذا التأكيد كمثال على تنسيق الاختبار النموذجي. لنقم بتشغيله لنرى أن هذا test ينجح.
يقوم أمر cargo test بتشغيل جميع tests في مشروعنا، كما هو موضح في القائمة 11-2.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/adder-01ad14159ff659ab)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
قام Cargo بتجميع وتشغيل test. نرى السطر running 1 test. يُظهر السطر التالي اسم دالة test التي تم إنشاؤها، والتي تسمى tests::it_works، وأن نتيجة تشغيل هذا test هي ok. الملخص العام test result: ok. يعني أن جميع tests نجحت، والجزء الذي يقرأ 1 passed; 0 failed يجمع عدد tests التي نجحت أو فشلت.
من الممكن وضع علامة على test كـ “متجاهل” (ignored) بحيث لا يتم تشغيله في حالة معينة؛ سنتناول ذلك في قسم “تجاهل الاختبارات ما لم يُطلب ذلك تحديدًا” لاحقًا في هذا الفصل. نظرًا لأننا لم نفعل ذلك هنا، يُظهر الملخص 0 ignored. يمكننا أيضًا تمرير وسيطة إلى أمر cargo test لتشغيل tests فقط التي يتطابق اسمها مع سلسلة نصية؛ وهذا ما يسمى التصفية (filtering)، وسنتناوله في قسم “تشغيل مجموعة فرعية من الاختبارات بالاسم”. هنا، لم نقم بتصفية tests التي يتم تشغيلها، لذا فإن نهاية الملخص تُظهر 0 filtered out.
الإحصائية 0 measured مخصصة لاختبارات الأداء (benchmark tests) التي تقيس الأداء. اختبارات الأداء، حتى كتابة هذه السطور، متاحة فقط في Rust الليلية (nightly Rust). راجع التوثيق حول اختبارات الأداء لمعرفة المزيد.
الجزء التالي من خرج test الذي يبدأ بـ Doc-tests adder مخصص لنتائج أي اختبارات التوثيق (documentation tests). ليس لدينا أي documentation tests بعد، ولكن Rust يمكنها تجميع أي أمثلة كود تظهر في توثيق API (API documentation) الخاص بنا. تساعد هذه الميزة في الحفاظ على تزامن وثائقك وكودك! سنناقش كيفية كتابة documentation tests في قسم “تعليقات التوثيق كاختبارات” من الفصل 14. في الوقت الحالي، سنتجاهل خرج Doc-tests.
لنبدأ في تخصيص test ليناسب احتياجاتنا الخاصة. أولاً، قم بتغيير اسم الدالة it_works إلى اسم مختلف، مثل exploration، على النحو التالي:
اسم الملف: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}ثم، قم بتشغيل cargo test مرة أخرى. يُظهر الخرج الآن exploration بدلاً من it_works:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
الآن سنضيف test آخر، ولكن هذه المرة سنجعل test يفشل! تفشل Tests عندما يحدث panic لشيء ما في دالة test. يتم تشغيل كل test في خيط (thread) جديد، وعندما يرى الخيط الرئيسي (main thread) أن خيط test قد مات، يتم وضع علامة على test على أنه FAILED. في الفصل 9، تحدثنا عن أن أبسط طريقة لإحداث panic هي استدعاء الماكرو panic! (panic! macro). أدخل test الجديد كدالة مسماة another، بحيث يبدو ملف src/lib.rs الخاص بك كما في القائمة 11-3.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}قم بتشغيل tests مرة أخرى باستخدام cargo test. يجب أن يبدو الخرج كما في القائمة 11-4، والتي تُظهر أن test exploration الخاص بنا نجح و another فشل.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'tests::another' panicked at src/lib.rs:17:9:
Make this test fail
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
بدلاً من ok، يُظهر السطر test tests::another كلمة FAILED. يظهر قسمان جديدان بين النتائج الفردية والملخص: يعرض الأول السبب المفصل لفشل كل test. في هذه الحالة، نحصل على التفاصيل التي تفيد بأن tests::another فشل لأنه حدث له panic مع الرسالة Make this test fail في السطر 17 في ملف src/lib.rs. يسرد القسم التالي أسماء جميع tests الفاشلة فقط، وهو أمر مفيد عندما يكون هناك الكثير من tests والكثير من خرج test الفاشل المفصل. يمكننا استخدام اسم test فاشل لتشغيل هذا test فقط لتصحيحه بسهولة أكبر؛ سنتحدث أكثر عن طرق تشغيل tests في قسم “التحكم في كيفية تشغيل الاختبارات”.
يظهر سطر الملخص في النهاية: بشكل عام، نتيجة test الخاصة بنا هي FAILED. كان لدينا test واحد نجح و test واحد فشل.
الآن بعد أن رأيت كيف تبدو نتائج test في سيناريوهات مختلفة، دعنا نلقي نظرة على بعض macros الأخرى بخلاف panic! المفيدة في tests.
التحقق من النتائج باستخدام الماكرو assert!
الماكرو assert! (assert! macro)، الذي توفره المكتبة القياسية (standard library)، مفيد عندما تريد التأكد من أن بعض الشروط في test يتم تقييمها إلى قيمة منطقية (Boolean) true. نعطي الماكرو assert! وسيطة يتم تقييمها إلى Boolean. إذا كانت القيمة true، فلن يحدث شيء وينجح test. إذا كانت القيمة false، يستدعي الماكرو assert! الماكرو panic! للتسبب في فشل test. يساعدنا استخدام الماكرو assert! في التحقق من أن الكود الخاص بنا يعمل بالطريقة التي ننويها.
في الفصل 5، القائمة 5-15، استخدمنا هيكل Rectangle ودالة can_hold، والتي تتكرر هنا في القائمة 11-5. لنضع هذا الكود في ملف src/lib.rs، ثم نكتب بعض tests له باستخدام الماكرو assert!.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}تُرجع الدالة can_hold قيمة Boolean، مما يعني أنها حالة استخدام مثالية للماكرو assert!. في القائمة 11-6، نكتب test يمارس الدالة can_hold عن طريق إنشاء مثيل Rectangle بعرض 8 وارتفاع 7 والتأكيد على أنه يمكن أن يحتوي على مثيل Rectangle آخر بعرض 5 وارتفاع 1.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}لاحظ السطر use super::*; داخل وحدة tests. وحدة tests هي وحدة عادية تتبع قواعد الرؤية (visibility rules) المعتادة التي تناولناها في الفصل 7 في قسم “المسارات للإشارة إلى عنصر في شجرة الوحدة”. نظرًا لأن وحدة tests هي وحدة داخلية، نحتاج إلى جلب الكود قيد الاختبار في الوحدة الخارجية إلى نطاق (scope) الوحدة الداخلية. نستخدم glob هنا، لذا فإن أي شيء نحدده في الوحدة الخارجية متاح لوحدة tests هذه.
لقد أطلقنا على test الخاص بنا اسم larger_can_hold_smaller، وقمنا بإنشاء مثيلي Rectangle اللذين نحتاجهما. بعد ذلك، استدعينا الماكرو assert! ومررنا له نتيجة استدعاء larger.can_hold(&smaller). من المفترض أن تُرجع هذه العبارة true، لذا يجب أن ينجح test الخاص بنا. دعونا نكتشف ذلك!
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.80s
Running unittests (target/debug/deps/adder-92938fa227f3322b)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 filtered out; finished in 0.00s
لقد نجح! لنضف test آخر، هذه المرة نؤكد أن مستطيلاً أصغر لا يمكنه احتواء مستطيل أكبر:
اسم الملف: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
// --snip--
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}نظرًا لأن النتيجة الصحيحة لدالة can_hold في هذه الحالة هي false، نحتاج إلى نفي تلك النتيجة قبل تمريرها إلى الماكرو assert!. ونتيجة لذلك، سينجح test الخاص بنا إذا أعادت can_hold القيمة false:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.80s
Running unittests (target/debug/deps/adder-92938fa227f3322b)
running 2 tests
test tests::smaller_cannot_hold_larger ... ok
test tests::larger_can_hold_smaller ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 filtered out; finished in 0.00s
اثنان tests ينجحان! الآن دعونا نرى ما سيحدث لنتائج test الخاصة بنا عندما نقدم خطأ (bug) في الكود الخاص بنا. سنقوم بتغيير تطبيق دالة can_hold عن طريق استبدال علامة أكبر من (>) بعلامة أقل من (<) عند مقارنة العروض:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// --snip--
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width < other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}تشغيل tests الآن ينتج ما يلي:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.80s
Running unittests (target/debug/deps/adder-92938fa227f3322b)
running 2 tests
test tests::smaller_cannot_hold_larger ... ok
test tests::larger_can_hold_smaller ... FAILED
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'tests::larger_can_hold_smaller' panicked at src/lib.rs:21:5:
assertion failed: larger.can_hold(&smaller)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 filtered out; finished in 0.00s
لقد اكتشفت tests الخاصة بنا الـ bug! نظرًا لأن larger.width هو 8 و smaller.width هو 5، فإن مقارنة العروض في can_hold تُرجع الآن false: 8 ليست أقل من 5.
اختبار المساواة باستخدام assert_eq! و assert_ne!
تتمثل إحدى الطرق الشائعة للتحقق من الوظائف في اختبار المساواة بين نتيجة الكود قيد الاختبار والقيمة التي تتوقع أن تُرجعها الكود. يمكنك القيام بذلك باستخدام الماكرو assert! وتمرير عبارة تستخدم عامل التشغيل ==. ومع ذلك، يعد هذا test شائعًا جدًا لدرجة أن المكتبة القياسية توفر زوجًا من macros - assert_eq! و assert_ne! (assert_ne! macro) - لإجراء هذا test بشكل أكثر ملاءمة. تقارن هذه macros وسيطتين للمساواة أو عدم المساواة، على التوالي. ستقوم أيضًا بطباعة القيمتين إذا فشل التأكيد، مما يسهل رؤية سبب فشل test؛ على العكس من ذلك، يشير الماكرو assert! فقط إلى أنه حصل على قيمة false لعبارة ==، دون طباعة القيم التي أدت إلى القيمة false.
في القائمة 11-7، نكتب دالة تسمى add_two تضيف 2 إلى معلمتها (parameter)، ثم نختبر هذه الدالة باستخدام الماكرو assert_eq!.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}دعونا نتحقق من نجاحه!
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.80s
Running unittests (target/debug/deps/adder-92938fa227f3322b)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 filtered out; finished in 0.00s
نقوم بإنشاء متغير يسمى result يحمل نتيجة استدعاء add_two(2). بعد ذلك، نمرر result و 4 كوسيطتين للماكرو assert_eq!. سطر الخرج لهذا test هو test tests::it_adds_two ... ok، ويشير نص ok إلى أن test الخاص بنا نجح!
لنقدم bug في الكود الخاص بنا لنرى كيف يبدو assert_eq! عندما يفشل. قم بتغيير تطبيق دالة add_two لإضافة 3 بدلاً من ذلك:
pub fn add_two(a: u64) -> u64 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}قم بتشغيل tests مرة أخرى:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.80s
Running unittests (target/debug/deps/adder-92938fa227f3322b)
running 1 test
test tests::it_adds_two ... FAILED
failures:
---- tests::it_adds_two stdout ----
thread 'tests::it_adds_two' panicked at src/lib.rs:11:5:
assertion `left == right` failed
left: `5`
right: `4`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_adds_two
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 filtered out; finished in 0.00s
لقد اكتشف test الخاص بنا الـ bug! فشل test tests::it_adds_two، وتخبرنا الرسالة أن التأكيد الذي فشل هو left == right وما هي قيمتا left و right. تساعدنا هذه الرسالة في بدء تصحيح الأخطاء (debugging): كانت الوسيطة left، حيث كانت لدينا نتيجة استدعاء add_two(2)، هي 5، لكن الوسيطة right كانت 4. يمكنك أن تتخيل أن هذا سيكون مفيدًا بشكل خاص عندما يكون لدينا الكثير من tests قيد التشغيل.
لاحظ أنه في بعض اللغات وأطر عمل الاختبار (test frameworks)، تسمى المعلمات (parameters) لدوال تأكيد المساواة expected و actual، ويعد الترتيب الذي نحدد به الوسيطات مهمًا. ومع ذلك، في Rust، تسمى left و right، ولا يهم الترتيب الذي نحدد به القيمة التي نتوقعها والقيمة التي ينتجها الكود. يمكننا كتابة التأكيد في هذا test على النحو التالي assert_eq!(4, result)، مما سيؤدي إلى نفس رسالة الفشل التي تعرض assertion `left == right` failed.
سينجح الماكرو assert_ne! إذا كانت القيمتان اللتان نعطيه إياهما غير متساويتين وسيفشل إذا كانتا متساويتين. يعد هذا الماكرو أكثر فائدة للحالات التي لا نكون فيها متأكدين مما ستكون عليه القيمة، ولكننا نعرف ما يجب ألا تكون عليه القيمة بالتأكيد. على سبيل المثال، إذا كنا نختبر دالة مضمونة لتغيير مدخلاتها (input) بطريقة ما، ولكن الطريقة التي يتم بها تغيير الـ input تعتمد على يوم الأسبوع الذي نشغل فيه tests الخاصة بنا، فقد يكون أفضل شيء للتأكيد هو أن خرج الدالة لا يساوي الـ input.
تحت السطح، يستخدم الماكرو assert_eq! و assert_ne! عاملي التشغيل == و !=، على التوالي. عندما تفشل التأكيدات، تطبع هذه macros وسيطاتها باستخدام تنسيق Debug، مما يعني أن القيم التي تتم مقارنتها يجب أن تطبق السمات (traits) PartialEq و Debug. تطبق جميع الأنواع البدائية (primitive types) ومعظم أنواع المكتبة القياسية هذه traits. بالنسبة للهياكل (structs) والتعدادات (enums) التي تحددها بنفسك، ستحتاج إلى تطبيق PartialEq للتأكيد على مساواة تلك الأنواع. ستحتاج أيضًا إلى تطبيق Debug لطباعة القيم عندما يفشل التأكيد. نظرًا لأن كلا الـ traits قابلان للاشتقاق (derivable traits)، كما ذكرنا في القائمة 5-12 في الفصل 5، فعادةً ما يكون الأمر بسيطًا مثل إضافة التعليق التوضيحي #[derive(PartialEq, Debug)] إلى تعريف struct أو enum الخاص بك. راجع الملحق ج، “السمات القابلة للاشتقاق”، لمزيد من التفاصيل حول هذه الـ traits القابلة للاشتقاق وغيرها.
إضافة رسائل فشل مخصصة (Custom Failure Messages)
يمكنك أيضًا إضافة رسالة مخصصة (Custom Failure Messages) ليتم طباعتها مع رسالة الفشل كوسيطات اختيارية للـ macros assert! و assert_eq! و assert_ne!. يتم تمرير أي وسيطات محددة بعد الوسيطات المطلوبة إلى الماكرو format! (format! macro) (الذي تمت مناقشته في “الربط باستخدام + أو format!” في الفصل 8)، بحيث يمكنك تمرير سلسلة تنسيق (format string) تحتوي على عناصر نائبة (placeholder) {} وقيم لوضعها في تلك الـ placeholders. تعد الـ Custom Failure Messages مفيدة لتوثيق ما يعنيه التأكيد؛ عندما يفشل test، سيكون لديك فكرة أفضل عن ماهية المشكلة في الكود.
على سبيل المثال، لنفترض أن لدينا دالة تحيي الأشخاص بالاسم ونريد اختبار أن الاسم الذي نمرره إلى الدالة يظهر في الخرج:
اسم الملف: src/lib.rs
pub fn greeting(name: &str) -> String {
format!("Hello {name}!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}لم يتم الاتفاق على متطلبات هذا البرنامج بعد، ونحن على يقين من أن نص Hello في بداية التحية سيتغير. قررنا أننا لا نريد الاضطرار إلى تحديث test عندما تتغير المتطلبات، لذلك بدلاً من التحقق من المساواة التامة للقيمة التي تم إرجاعها من دالة greeting، سنؤكد فقط أن الخرج يحتوي على نص الـ input parameter.
الآن لنقدم bug في هذا الكود عن طريق تغيير greeting لاستبعاد name لنرى كيف يبدو فشل test الافتراضي:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}تشغيل هذا test ينتج ما يلي:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.80s
Running unittests (target/debug/deps/adder-92938fa227f3322b)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:13:5:
assertion failed: greeting("Carol").contains("Carol")
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 filtered out; finished in 0.00s
تشير هذه النتيجة فقط إلى أن التأكيد فشل وعلى أي سطر يوجد التأكيد. ستطبع رسالة فشل أكثر فائدة القيمة من دالة greeting. لنضف Custom Failure Message تتكون من format string مع placeholder مملوءة بالقيمة الفعلية التي حصلنا عليها من دالة greeting:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{result}`"
);
}
}الآن عندما نشغل test، سنحصل على رسالة خطأ أكثر إفادة:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.80s
Running unittests (target/debug/deps/adder-92938fa227f3322b)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:13:5:
Greeting did not contain name, value was `Hello!`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 filtered out; finished in 0.00s
يمكننا رؤية القيمة التي حصلنا عليها بالفعل في خرج test، مما سيساعدنا في تصحيح الأخطاء (debug) لمعرفة ما حدث بدلاً مما كنا نتوقع حدوثه.
التحقق من الـ Panics باستخدام should_panic
بالإضافة إلى التحقق من قيم الإرجاع (return values)، من المهم التحقق من أن الكود الخاص بنا يتعامل مع حالات الخطأ (error conditions) كما نتوقع. على سبيل المثال، ضع في اعتبارك النوع Guess الذي أنشأناه في الفصل 9، القائمة 9-13. يعتمد الكود الآخر الذي يستخدم Guess على الضمان بأن مثيلات Guess ستحتوي فقط على قيم بين 1 و 100. يمكننا كتابة test يضمن أن محاولة إنشاء مثيل Guess بقيمة خارج هذا النطاق يحدث لها panic.
نقوم بذلك عن طريق إضافة السمة should_panic إلى دالة test الخاصة بنا. ينجح test إذا حدث panic للكود داخل الدالة؛ ويفشل test إذا لم يحدث panic للكود داخل الدالة.
تُظهر القائمة 11-8 test يتحقق من أن error conditions لـ Guess::new تحدث عندما نتوقعها.
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}نضع السمة #[should_panic] بعد السمة #[test] وقبل دالة test التي تنطبق عليها. لننظر إلى النتيجة عندما ينجح هذا test:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.80s
Running unittests (target/debug/deps/adder-92938fa227f3322b)
running 1 test
test tests::greater_than_100 ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 filtered out; finished in 0.00s
يبدو جيدًا! الآن لنقدم bug في الكود الخاص بنا عن طريق إزالة الشرط الذي سيحدث فيه panic للدالة new إذا كانت القيمة أكبر من 100:
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}عندما نشغل test في القائمة 11-8، سيفشل:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.80s
Running unittests (target/debug/deps/adder-92938fa227f3322b)
running 1 test
test tests::greater_than_100 ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'tests::greater_than_100' panicked at src/lib.rs:11:5:
test did not panic
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 filtered out; finished in 0.00s
لا نحصل على رسالة مفيدة جدًا في هذه الحالة، ولكن عندما ننظر إلى دالة test، نرى أنها مُعلّمة بـ #[should_panic]. الفشل الذي حصلنا عليه يعني أن الكود في دالة test لم يتسبب في panic.
يمكن أن تكون Tests التي تستخدم should_panic غير دقيقة. سينجح test should_panic حتى لو حدث panic لـ test لسبب مختلف عن السبب الذي كنا نتوقعه. لجعل tests should_panic أكثر دقة، يمكننا إضافة معلمة expected اختيارية إلى السمة should_panic. سيتأكد إطار عمل الاختبار (test harness) من أن رسالة الفشل تحتوي على النص المقدم. على سبيل المثال، ضع في اعتبارك الكود المعدل لـ Guess في القائمة 11-9 حيث يحدث panic للدالة new برسائل مختلفة اعتمادًا على ما إذا كانت القيمة صغيرة جدًا أو كبيرة جدًا.
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}سينجح هذا test لأن القيمة التي وضعناها في معلمة expected لسمة should_panic هي سلسلة فرعية (substring) من الرسالة التي يحدث بها panic لدالة Guess::new. كان بإمكاننا تحديد رسالة panic بأكملها التي نتوقعها، والتي ستكون في هذه الحالة Guess value must be less than or equal to 100, got 200. ما تختاره لتحديده يعتمد على مقدار رسالة panic الفريد أو الديناميكي ومدى دقة test الذي تريده. في هذه الحالة، تكفي سلسلة فرعية من رسالة panic لضمان أن الكود في test…
لنر ما يحدث عندما يفشل test should_panic مع رسالة expected، لنقدم مرة أخرى bug في الكود الخاص بنا عن طريق تبديل نصوص كتل if value < 1 و else if value > 100:
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}هذه المرة عندما نشغل test should_panic، سيفشل:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.80s
Running unittests (target/debug/deps/adder-92938fa227f3322b)
running 1 test
test tests::greater_than_100 ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'tests::greater_than_100' panicked at src/lib.rs:11:5:
panic message did not contain expected string `less than or equal to 100`
panic message: `Guess value must be greater than or equal to 1, got 200`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 filtered out; finished in 0.00s
تشير رسالة الفشل إلى أن هذا test قد حدث له panic بالفعل كما توقعنا، لكن رسالة panic لم تتضمن السلسلة المتوقعة less than or equal to 100. كانت رسالة panic التي حصلنا عليها في هذه الحالة هي Guess value must be greater than or equal to 1, got 200. الآن يمكننا البدء في معرفة مكان الـ bug الخاص بنا!
استخدام Result<T, E> في الاختبارات
جميع tests الخاصة بنا حتى الآن يحدث لها panic عندما تفشل. يمكننا أيضًا كتابة tests تستخدم النتيجة Result<T, E> (Result<T, E>) ! إليك test من القائمة 11-1، أعيدت كتابته لاستخدام Result<T, E> وإرجاع Err بدلاً من panic:
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() -> Result<(), String> {
let result = add(2, 2);
if result == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}تتمتع الدالة it_works الآن بنوع الإرجاع Result<(), String>. في نص الدالة، بدلاً من استدعاء الماكرو assert_eq!، نُرجع Ok(()) عندما ينجح test و Err مع String بالداخل عندما يفشل test.
تتيح لك كتابة tests بحيث تُرجع Result<T, E> استخدام عامل علامة الاستفهام (question mark operator) في نص tests، والتي يمكن أن تكون طريقة ملائمة لكتابة tests يجب أن تفشل إذا أرجعت أي عملية بداخلها متغير Err.
لا يمكنك استخدام التعليق التوضيحي #[should_panic] على tests التي تستخدم Result<T, E>. للتأكيد على أن عملية ما تُرجع متغير Err، لا تستخدم question mark operator على قيمة Result<T, E>. بدلاً من ذلك، استخدم assert!(value.is_err()).
الآن بعد أن عرفت عدة طرق لكتابة tests، دعنا نلقي نظرة على ما يحدث عندما نشغل tests الخاصة بنا ونستكشف الخيارات المختلفة التي يمكننا استخدامها مع cargo test.
التحكم في كيفية تشغيل الاختبارات
التحكم في كيفية تشغيل الاختبارات
تماماً كما يقوم الأمر cargo run بتصريف الكود الخاص بك ثم تشغيل الملف الثنائي (binary) الناتج، يقوم الأمر cargo test بتصريف الكود في وضع الاختبار (test mode) وتشغيل ملف الاختبار الثنائي الناتج. السلوك الافتراضي للملف الثنائي الناتج عن cargo test هو تشغيل جميع الاختبارات (tests) بالتوازي والتقاط المخرجات (output) الناتجة أثناء تشغيل الاختبارات، مما يمنع عرض المخرجات ويسهل قراءة المخرجات المتعلقة بنتائج الاختبار. ومع ذلك، يمكنك تحديد خيارات سطر الأوامر (command line options) لتغيير هذا السلوك الافتراضي.
تذهب بعض خيارات سطر الأوامر إلى cargo test وبعضها يذهب إلى ملف الاختبار الثنائي الناتج. لفصل هذين النوعين من الوسائط (arguments)، تسرد الوسائط التي تذهب إلى cargo test متبوعة بالفاصل -- ثم تلك التي تذهب إلى ملف الاختبار الثنائي. يعرض تشغيل cargo test --help الخيارات التي يمكنك استخدامها مع cargo test ويعرض تشغيل cargo test -- --help الخيارات التي يمكنك استخدامها بعد الفاصل. هذه الخيارات موثقة أيضاً في قسم “الاختبارات” في كتاب rustc.
تشغيل الاختبارات بالتوازي أو بالتتابع
عند تشغيل اختبارات متعددة، فإنها تعمل افتراضياً بالتوازي (in parallel) باستخدام الخيوط (threads)، مما يعني أنها تنتهي من العمل بسرعة أكبر وتحصل على التغذية الراجعة في وقت أقرب. نظراً لأن الاختبارات تعمل في نفس الوقت، يجب عليك التأكد من أن اختباراتك لا تعتمد على بعضها البعض أو على أي حالة مشتركة (shared state)، بما في ذلك البيئة المشتركة، مثل مجلد العمل الحالي أو متغيرات البيئة.
على سبيل المثال، لنفترض أن كل اختبار من اختباراتك يشغل كوداً ينشئ ملفاً على القرص باسم test-output.txt ويكتب بعض البيانات في ذلك الملف. ثم يقرأ كل اختبار البيانات الموجودة في ذلك الملف ويؤكد (asserts) أن الملف يحتوي على قيمة معينة، والتي تختلف في كل اختبار. نظراً لأن الاختبارات تعمل في نفس الوقت، فقد يقوم أحد الاختبارات بالكتابة فوق الملف في الوقت بين كتابة اختبار آخر للملف وقراءته له. سيفشل الاختبار الثاني حينها، ليس لأن الكود غير صحيح ولكن لأن الاختبارات تداخلت مع بعضها البعض أثناء تشغيلها بالتوازي. أحد الحلول هو التأكد من أن كل اختبار يكتب في ملف مختلف؛ وحل آخر هو تشغيل الاختبارات واحداً تلو الآخر.
إذا كنت لا ترغب في تشغيل الاختبارات بالتوازي أو إذا كنت تريد تحكماً أكثر دقة في عدد threads المستخدمة، يمكنك إرسال علم --test-threads وعدد threads التي تريد استخدامها إلى ملف الاختبار الثنائي. ألقِ نظرة على المثال التالي:
$ cargo test -- --test-threads=1
لقد قمنا بضبط عدد خيوط الاختبار (test threads) على 1 لإخبار البرنامج بعدم استخدام أي توازي (parallelism). سيستغرق تشغيل الاختبارات باستخدام خيط واحد وقتاً أطول من تشغيلها بالتوازي، لكن الاختبارات لن تتداخل مع بعضها البعض إذا كانت تشترك في الحالة.
إظهار مخرجات الدالة
افتراضياً، إذا نجح الاختبار، فإن مكتبة اختبار Rust تلتقط أي شيء يتم طباعته إلى المخرج القياسي (standard output). على سبيل المثال، إذا استدعينا println! في اختبار ونجح الاختبار، فلن نرى مخرجات println! في الطرفية (terminal)؛ سنرى فقط السطر الذي يشير إلى نجاح الاختبار. إذا فشل الاختبار، فسنرى كل ما تمت طباعته إلى standard output مع بقية رسالة الفشل.
كمثال، تحتوي القائمة 11-10 على دالة بسيطة تطبع قيمة معاملها وتعيد 10، بالإضافة إلى اختبار ينجح واختبار يفشل.
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {a}");
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(value, 10);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(value, 5);
}
}عندما نشغل هذه الاختبارات باستخدام cargo test فسنرى المخرجات التالية:
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
لاحظ أنه لا نرى في أي مكان في هذه المخرجات عبارة I got the value 4 التي تُطبع عند تشغيل الاختبار الذي ينجح. لقد تم التقاط تلك المخرجات. تظهر مخرجات الاختبار الذي فشل، I got the value 8 في قسم مخرجات ملخص الاختبار، والذي يوضح أيضاً سبب فشل الاختبار.
إذا أردنا رؤية القيم المطبوعة للاختبارات الناجحة أيضاً، يمكننا إخبار Rust بإظهار مخرجات الاختبارات الناجحة أيضاً باستخدام --show-output:
$ cargo test -- --show-output
عندما نشغل الاختبارات في القائمة 11-10 مرة أخرى باستخدام علم --show-output نرى المخرجات التالية:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
successes:
---- tests::this_test_will_pass stdout ----
I got the value 4
successes:
tests::this_test_will_pass
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
تشغيل مجموعة فرعية من الاختبارات بالاسم
قد يستغرق تشغيل مجموعة اختبارات (test suite) كاملة وقتاً طويلاً في بعض الأحيان. إذا كنت تعمل على كود في منطقة معينة، فقد ترغب في تشغيل الاختبارات المتعلقة بهذا الكود فقط. يمكنك اختيار الاختبارات التي تريد تشغيلها عن طريق تمرير اسم أو أسماء الاختبارات التي تريد تشغيلها كـ argument إلى cargo test.
لتوضيح كيفية تشغيل مجموعة فرعية من الاختبارات، سننشئ أولاً ثلاثة اختبارات لدالة add_two الخاصة بنا، كما هو موضح في القائمة 11-11، ونختار أي منها سنشغل.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
#[test]
fn add_three_and_two() {
let result = add_two(3);
assert_eq!(result, 5);
}
#[test]
fn one_hundred() {
let result = add_two(100);
assert_eq!(result, 102);
}
}إذا قمنا بتشغيل الاختبارات دون تمرير أي arguments كما رأينا سابقاً، فستعمل جميع الاختبارات بالتوازي:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
تشغيل اختبارات فردية
يمكننا تمرير اسم أي دالة اختبار إلى cargo test لتشغيل ذلك الاختبار فقط:
$ cargo test one_hundred
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::one_hundred ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
تم تشغيل الاختبار الذي يحمل الاسم one_hundred فقط؛ ولم يتطابق الاختباران الآخران مع هذا الاسم. تخبرنا مخرجات الاختبار أن لدينا المزيد من الاختبارات التي لم يتم تشغيلها من خلال عرض 2 filtered out في النهاية.
لا يمكننا تحديد أسماء اختبارات متعددة بهذه الطريقة؛ سيتم استخدام القيمة الأولى فقط المعطاة لـ cargo test. ولكن هناك طريقة لتشغيل اختبارات متعددة.
التصفية لتشغيل اختبارات متعددة
يمكننا تحديد جزء من اسم الاختبار، وسيتم تشغيل أي اختبار يتطابق اسمه مع تلك القيمة. على سبيل المثال، نظراً لأن اسمي اثنين من اختباراتنا يحتويان على add فيمكننا تشغيل هذين الاختبارين عن طريق تشغيل cargo test add:
$ cargo test add
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
قام هذا الأمر بتشغيل جميع الاختبارات التي تحتوي على add في الاسم وقام بتصفية الاختبار المسمى one_hundred. لاحظ أيضاً أن الوحدة (module) التي يظهر فيها الاختبار تصبح جزءاً من اسم الاختبار، لذا يمكننا تشغيل جميع الاختبارات في module عن طريق التصفية على اسم module.
تجاهل الاختبارات ما لم يطلب ذلك تحديداً
أحياناً قد يستغرق تنفيذ بعض الاختبارات المحددة وقتاً طويلاً جداً، لذا قد ترغب في استبعادها أثناء معظم عمليات تشغيل cargo test. بدلاً من إدراج جميع الاختبارات التي تريد تشغيلها كـ arguments، يمكنك بدلاً من ذلك تمييز الاختبارات التي تستغرق وقتاً طويلاً باستخدام سمة ignore لاستبعادها، كما هو موضح هنا:
اسم الملف: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// code that takes an hour to run
}
}بعد #[test] نضيف سطر #[ignore] إلى الاختبار الذي نريد استبعاده. الآن عندما نشغل اختباراتنا، سيعمل it_works ولكن لن يعمل expensive_test:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::expensive_test ... ignored
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
يتم إدراج الدالة expensive_test على أنها متجاهلة (ignored). إذا أردنا تشغيل الاختبارات المتجاهلة فقط، يمكننا استخدام cargo test -- --ignored:
$ cargo test -- --ignored
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::expensive_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
من خلال التحكم في الاختبارات التي يتم تشغيلها، يمكنك التأكد من عودة نتائج cargo test بسرعة. عندما تصل إلى نقطة يكون فيها من المنطقي التحقق من نتائج الاختبارات المتجاهلة (ignored) ويكون لديك وقت لانتظار النتائج، يمكنك تشغيل cargo test -- --ignored بدلاً من ذلك. إذا كنت تريد تشغيل جميع الاختبارات سواء كانت متجاهلة أم لا، يمكنك تشغيل cargo test -- --include-ignored.
تنظيم الاختبارات
تنظيم الاختبارات (Test Organization)
كما ذكرنا في بداية الفصل، فإن الاختبار (testing) هو تخصص معقد، ويستخدم أشخاص مختلفون مصطلحات وتنظيمات مختلفة. يفكر مجتمع Rust في الاختبارات من حيث فئتين رئيسيتين: اختبارات الوحدة (unit tests) واختبارات التكامل (integration tests). الـ unit tests صغيرة وأكثر تركيزًا، حيث تختبر وحدة واحدة (module) في عزلة في كل مرة، ويمكنها اختبار الواجهات الخاصة (private interfaces). أما الـ integration tests فهي خارجية تمامًا عن مكتبتك وتستخدم كودك بنفس الطريقة التي يستخدمه بها أي كود خارجي آخر، وذلك باستخدام الواجهة العامة (public interface) فقط، ومن المحتمل أن تختبر عدة وحدات في كل اختبار.
تعد كتابة كلا النوعين من الاختبارات أمرًا مهمًا لضمان أن أجزاء مكتبتك تقوم بما تتوقعه منها، بشكل منفصل ومعًا.
اختبارات الوحدة (Unit Tests)
الغرض من اختبارات الوحدة هو اختبار كل وحدة من الكود بمعزل عن بقية الكود لتحديد مكان عمل الكود وعدم عمله كما هو متوقع بسرعة. ستضع اختبارات الوحدة في دليل src في كل ملف مع الكود الذي تختبره. الاصطلاح المتبع هو إنشاء وحدة تسمى tests في كل ملف لاحتواء دوال الاختبار وتمييز الوحدة بـ cfg(test).
وحدة الـ tests و #[cfg(test)]
يخبر التعليق التوضيحي (annotation) المسمى #[cfg(test)] على وحدة tests لغة Rust بترجمة وتشغيل كود الاختبار فقط عندما تقوم بتشغيل cargo test وليس عند تشغيل cargo build. هذا يوفر وقت الترجمة عندما تريد فقط بناء المكتبة ويوفر مساحة في الأداة المترجمة الناتجة لأن الاختبارات لا يتم تضمينها. سترى أنه نظرًا لأن اختبارات التكامل تذهب إلى دليل مختلف، فهي لا تحتاج إلى تعليق #[cfg(test)]. ومع ذلك، نظرًا لأن اختبارات الوحدة تذهب في نفس الملفات مع الكود، فستستخدم #[cfg(test)] لتحديد أنه لا ينبغي تضمينها في النتيجة المترجمة.
تذكر أنه عندما أنشأنا مشروع adder الجديد في القسم الأول من هذا الفصل، قام Cargo بإنشاء هذا الكود لنا:
اسم الملف: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}في وحدة tests التي تم إنشاؤها تلقائيًا، ترمز السمة cfg إلى الإعداد (configuration) وتخبر Rust أن العنصر التالي يجب تضمينه فقط في حالة وجود خيار إعداد معين. في هذه الحالة، خيار الإعداد هو test والذي توفره Rust لترجمة وتشغيل الاختبارات. باستخدام سمة cfg يقوم Cargo بترجمة كود الاختبار الخاص بنا فقط إذا قمنا بتشغيل الاختبارات بنشاط باستخدام cargo test. يتضمن ذلك أي دوال مساعدة قد تكون داخل هذه الوحدة، بالإضافة إلى الدوال المميزة بـ #[test].
اختبار الدوال الخاصة (Private Function Tests)
هناك نقاش داخل مجتمع الاختبار حول ما إذا كان ينبغي اختبار الدوال الخاصة (private functions) مباشرة أم لا، وتجعل لغات أخرى من الصعب أو المستحيل اختبار الدوال الخاصة. بغض النظر عن أيديولوجية الاختبار التي تلتزم بها، فإن قواعد الخصوصية في Rust تسمح لك باختبار الدوال الخاصة. فكر في الكود في القائمة 11-12 مع الدالة الخاصة internal_adder.
pub fn add_two(a: u64) -> u64 {
internal_adder(a, 2)
}
fn internal_adder(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
let result = internal_adder(2, 2);
assert_eq!(result, 4);
}
}لاحظ أن دالة internal_adder غير مميزة بـ pub. الاختبارات هي مجرد كود Rust، ووحدة tests هي مجرد وحدة أخرى. كما ناقشنا في “مسارات الإشارة إلى عنصر في شجرة الوحدات”، يمكن للعناصر في الوحدات التابعة استخدام العناصر في الوحدات الأصلية. في هذا الاختبار، نقوم بإحضار جميع العناصر التي تنتمي إلى أصل وحدة tests إلى النطاق (scope) باستخدام use super::* ومن ثم يمكن للاختبار استدعاء internal_adder. إذا كنت لا تعتقد أنه يجب اختبار الدوال الخاصة، فلا يوجد شيء في Rust يجبرك على القيام بذلك.
اختبارات التكامل (Integration Tests)
في Rust، تكون اختبارات التكامل خارجية تمامًا عن مكتبتك. فهي تستخدم مكتبتك بنفس الطريقة التي يستخدمها بها أي كود آخر، مما يعني أنها لا يمكنها سوى استدعاء الدوال التي تعد جزءًا من واجهة برمجة التطبيقات العامة (public API) لمكتبتك. غرضها هو اختبار ما إذا كانت أجزاء كثيرة من مكتبتك تعمل معًا بشكل صحيح. وحدات الكود التي تعمل بشكل صحيح بمفردها قد تواجه مشاكل عند دمجها، لذا فإن تغطية الاختبار للكود المتكامل مهمة أيضًا. لإنشاء اختبارات التكامل، تحتاج أولاً إلى دليل tests.
دليل الـ tests
ننشئ دليل tests في المستوى الأعلى من دليل مشروعنا، بجانب src. يعرف Cargo أنه يجب البحث عن ملفات اختبار التكامل في هذا الدليل. يمكننا بعد ذلك إنشاء أي عدد نريده من ملفات الاختبار، وسيقوم Cargo بترجمة كل ملف كـ crate فردية.
لننشئ اختبار تكامل. مع بقاء الكود في القائمة 11-12 في ملف src/lib.rs أنشئ دليل tests وأنشئ ملفًا جديدًا يسمى tests/integration_test.rs. يجب أن تبدو بنية دليلك هكذا:
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
أدخل الكود الموجود في القائمة 11-13 في ملف tests/integration_test.rs.
use adder::add_two;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}كل ملف في دليل tests هو crate منفصلة، لذا نحتاج إلى إحضار مكتبتنا إلى نطاق كل test crate. لهذا السبب، نضيف use adder::add_two; في أعلى الكود، وهو ما لم نحتجه في اختبارات الوحدة.
لا نحتاج إلى تمييز أي كود في tests/integration_test.rs بـ #[cfg(test)]. يعامل Cargo دليل tests بشكل خاص ويقوم بترجمة الملفات في هذا الدليل فقط عندما نقوم بتشغيل cargo test. قم بتشغيل cargo test الآن:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/adder-1082c4b063a8fbe6)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-1082c4b063a8fbe6)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
تتضمن الأقسام الثلاثة للمخرجات اختبارات الوحدة، واختبار التكامل، واختبارات التوثيق (doc tests). لاحظ أنه إذا فشل أي اختبار في قسم ما، فلن يتم تشغيل الأقسام التالية. على سبيل المثال، إذا فشل اختبار وحدة، فلن يكون هناك أي مخرجات لاختبارات التكامل والتوثيق، لأن تلك الاختبارات لن يتم تشغيلها إلا إذا نجحت جميع اختبارات الوحدة.
القسم الأول لاختبارات الوحدة هو نفسه الذي كنا نراه: سطر واحد لكل اختبار وحدة (واحد يسمى internal أضفناه في القائمة 11-12) ثم سطر ملخص لاختبارات الوحدة.
يبدأ قسم اختبارات التكامل بالسطر Running tests/integration_test.rs. بعد ذلك، هناك سطر لكل دالة اختبار في اختبار التكامل هذا وسطر ملخص لنتائج اختبار التكامل قبل بدء قسم Doc-tests adder.
كل ملف اختبار تكامل له قسمه الخاص، لذا إذا أضفنا المزيد من الملفات في دليل tests فسيكون هناك المزيد من أقسام اختبار التكامل.
لا يزال بإمكاننا تشغيل دالة اختبار تكامل معينة عن طريق تحديد اسم دالة الاختبار كوسيط لـ cargo test. لتشغيل جميع الاختبارات في ملف اختبار تكامل معين، استخدم الوسيط --test لـ cargo test متبوعًا باسم الملف:
$ cargo test --test integration_test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
يقوم هذا الأمر بتشغيل الاختبارات الموجودة في ملف tests/integration_test.rs فقط.
الوحدات الفرعية في اختبارات التكامل (Submodules in Integration Tests)
بينما تضيف المزيد من اختبارات التكامل، قد ترغب في إنشاء المزيد من الملفات في دليل tests للمساعدة في تنظيمها؛ على سبيل المثال، يمكنك تجميع دوال الاختبار حسب الوظيفة التي تختبرها. كما ذكرنا سابقًا، يتم ترجمة كل ملف في دليل tests كـ crate منفصلة خاصة به، وهو أمر مفيد لإنشاء نطاقات منفصلة لتقليد الطريقة التي سيستخدم بها المستخدمون النهائيون حزمتك بشكل أوثق. ومع ذلك، هذا يعني أن الملفات في دليل tests لا تتشارك في نفس السلوك الذي تتشاركه الملفات في src كما تعلمت في الفصل 7 بخصوص كيفية فصل الكود إلى وحدات وملفات.
يكون السلوك المختلف لملفات دليل tests أكثر وضوحًا عندما يكون لديك مجموعة من الدوال المساعدة لاستخدامها في ملفات اختبار تكامل متعددة، وتحاول اتباع الخطوات الواردة في قسم “فصل الوحدات إلى ملفات مختلفة” في الفصل 7 لاستخراجها إلى وحدة مشتركة. على سبيل المثال، إذا أنشأنا tests/common.rs ووضعنا دالة تسمى setup فيه، فيمكننا إضافة بعض الكود إلى setup الذي نريد استدعاءه من دوال اختبار متعددة في ملفات اختبار متعددة:
اسم الملف: tests/common.rs
pub fn setup() {
// setup code specific to your library's tests would go here
}عندما نشغل الاختبارات مرة أخرى، سنرى قسمًا جديدًا في مخرجات الاختبار لملف common.rs على الرغم من أن هذا الملف لا يحتوي على أي دوال اختبار ولم نستدعِ دالة setup من أي مكان:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/common.rs (target/debug/deps/common-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
ظهور common في نتائج الاختبار مع عرض running 0 tests له ليس هو ما أردناه. أردنا فقط مشاركة بعض الكود مع ملفات اختبار التكامل الأخرى. لتجنب ظهور common في مخرجات الاختبار، بدلاً من إنشاء tests/common.rs سننشئ tests/common/mod.rs. يبدو دليل المشروع الآن هكذا:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
هذا هو اصطلاح التسمية القديم الذي تفهمه Rust أيضًا والذي ذكرناه في “مسارات الملفات البديلة” في الفصل 7. تسمية الملف بهذه الطريقة تخبر Rust بعدم معاملة وحدة common كملف اختبار تكامل. عندما ننقل كود دالة setup إلى tests/common/mod.rs ونحذف ملف tests/common.rs لن يظهر القسم في مخرجات الاختبار بعد الآن. الملفات الموجودة في الأدلة الفرعية لدليل tests لا يتم ترجمتها كـ crates منفصلة أو يكون لها أقسام في مخرجات الاختبار.
بعد أن أنشأنا tests/common/mod.rs يمكننا استخدامه من أي من ملفات اختبار التكامل كوحدة. إليك مثال على استدعاء دالة setup من اختبار it_adds_two في tests/integration_test.rs:
اسم الملف: tests/integration_test.rs
use adder::add_two;
mod common;
#[test]
fn it_adds_two() {
common::setup();
let result = add_two(2);
assert_eq!(result, 4);
}لاحظ أن إعلان mod common; هو نفسه إعلان الوحدة الذي عرضناه في القائمة 7-21. ثم، في دالة الاختبار، يمكننا استدعاء دالة common::setup().
اختبارات التكامل للحزم الثنائية (Integration Tests for Binary Crates)
إذا كان مشروعنا عبارة عن حزمة ثنائية (binary crate) تحتوي فقط على ملف src/main.rs ولا تحتوي على ملف src/lib.rs فلا يمكننا إنشاء اختبارات تكامل في دليل tests وإحضار الدوال المعرفة في ملف src/main.rs إلى النطاق باستخدام عبارة use. فقط حزم المكتبات (library crates) هي التي تعرض الدوال التي يمكن للحزم الأخرى استخدامها؛ الحزم الثنائية مخصصة للتشغيل بمفردها.
هذا هو أحد الأسباب التي تجعل مشاريع Rust التي توفر ملفًا ثنائيًا تمتلك ملف src/main.rs بسيطًا يستدعي المنطق الموجود في ملف src/lib.rs. باستخدام هذه البنية، يمكن لاختبارات التكامل اختبار حزمة المكتبة باستخدام use لجعل الوظائف المهمة متاحة. إذا كانت الوظائف المهمة تعمل، فإن الكمية الصغيرة من الكود في ملف src/main.rs ستعمل أيضًا، وهذه الكمية الصغيرة من الكود لا تحتاج إلى اختبار.
ملخص (Summary)
توفر ميزات الاختبار في Rust طريقة لتحديد كيفية عمل الكود لضمان استمراره في العمل كما تتوقع، حتى عند إجراء تغييرات. تختبر اختبارات الوحدة أجزاء مختلفة من المكتبة بشكل منفصل ويمكنها اختبار تفاصيل التنفيذ الخاصة. تتحقق اختبارات التكامل من أن أجزاء كثيرة من المكتبة تعمل معًا بشكل صحيح، وتستخدم واجهة برمجة التطبيقات العامة للمكتبة لاختبار الكود بنفس الطريقة التي سيستخدمه بها الكود الخارجي. على الرغم من أن نظام الأنواع وقواعد الملكية في Rust يساعدان في منع بعض أنواع الأخطاء، إلا أن الاختبارات لا تزال مهمة لتقليل الأخطاء المنطقية المتعلقة بكيفية توقع سلوك كودك.
دعنا نجمع المعرفة التي تعلمتها في هذا الفصل وفي الفصول السابقة للعمل على مشروع!
مشروع إدخال وإخراج (I/O Project): بناء برنامج واجهة أوامر (Command Line Program)
هذا الفصل هو مراجعة للعديد من المهارات التي تعلمتها حتى الآن واستكشاف لعدد قليل من ميزات المكتبة القياسية (standard library). سنقوم ببناء أداة واجهة أوامر (command line tool) تتفاعل مع مدخلات ومخرجات الملفات وواجهة الأوامر لممارسة بعض مفاهيم Rust التي أصبحت تتقنها الآن.
إن سرعة Rust وأمانها، وإنتاجها لملف ثنائي واحد (single binary)، ودعمها للمنصات المتعددة (cross-platform) يجعلها لغة مثالية لإنشاء أدوات واجهة الأوامر، لذا في مشروعنا، سنقوم بصنع نسختنا الخاصة من أداة البحث الكلاسيكية في واجهة الأوامر grep (البحث العالمي عن تعبير نمطي والطباعة - globally search a regular expression and print). في أبسط حالات الاستخدام، تبحث grep في ملف محدد عن سلسلة نصية (string) محددة. للقيام بذلك، تأخذ grep كوسطاء (arguments) لها مسار ملف وسلسلة نصية. بعد ذلك، تقرأ الملف، وتجد الأسطر في ذلك الملف التي تحتوي على argument السلسلة النصية، وتطبع تلك الأسطر.
على طول الطريق، سنوضح كيفية جعل أداة واجهة الأوامر الخاصة بنا تستخدم ميزات الطرفية (terminal) التي تستخدمها العديد من أدوات واجهة الأوامر الأخرى. سنقرأ قيمة متغير بيئة (environment variable) للسماح للمستخدم بتكوين سلوك أداتنا. سنقوم أيضاً بطباعة رسائل الخطأ إلى تدفق وحدة تحكم الخطأ القياسي (stderr) بدلاً من المخرجات القياسية (stdout) بحيث يمكن للمستخدم، على سبيل المثال، إعادة توجيه المخرجات الناجحة إلى ملف مع الاستمرار في رؤية رسائل الخطأ على الشاشة.
قام أحد أعضاء مجتمع Rust، وهو أندرو غالانت (Andrew Gallant)، بالفعل بإنشاء نسخة كاملة الميزات وسريعة جداً من grep تسمى ripgrep. وبالمقارنة، ستكون نسختنا بسيطة للغاية، ولكن هذا الفصل سيعطيك بعض المعرفة الخلفية التي تحتاجها لفهم مشروع واقعي مثل ripgrep.
سيجمع مشروع grep الخاص بنا عدداً من المفاهيم التي تعلمتها حتى الآن:
- تنظيم الكود (الفصل 7)
- استخدام المتجهات (vectors) والسلاسل النصية (الفصل 8)
- معالجة الأخطاء (Handling errors) (الفصل 9)
- استخدام السمات (traits) وفترات الحياة (lifetimes) حيثما كان ذلك مناسباً (الفصل 10)
- كتابة الاختبارات (Writing tests) (الفصل 11)
سنقدم أيضاً بإيجاز الإغلاقات (closures)، والمكررات (iterators)، وكائنات السمات (trait objects)، والتي سيغطيها الفصل 13 و الفصل 18 بالتفصيل.
قبول وسائط واجهة الأوامر (Command Line Arguments)
استقبال وسائط سطر الأوامر (Command Line Arguments)
لنقم بإنشاء مشروع جديد كالعادة باستخدام cargo new. سنطلق على مشروعنا اسم minigrep لتمييزه عن أداة grep التي قد تكون موجودة بالفعل على نظامك:
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
المهمة الأولى هي جعل minigrep يقبل وسيطي (Arguments) سطر الأوامر الخاصين به: مسار الملف وسلسلة نصية (String) للبحث عنها. أي أننا نريد أن نكون قادرين على تشغيل برنامجنا باستخدام cargo run متبوعاً بشرطتين للإشارة إلى أن الوسائط (Arguments) التالية مخصصة لبرنامجنا وليس لـ cargo نفسه، ثم السلسلة النصية المراد البحث عنها، ومسار الملف المراد البحث فيه، على النحو التالي:
$ cargo run -- searchstring example-filename.txt
في الوقت الحالي، لا يمكن للبرنامج الذي تم إنشاؤه بواسطة cargo new معالجة Arguments التي نمررها له. يمكن لبعض المكتبات (Libraries) الموجودة على crates.io المساعدة في كتابة برنامج يقبل Arguments سطر الأوامر، ولكن بما أنك تتعلم هذا المفهوم للتو، فلنقم بتنفيذ هذه الإمكانية بأنفسنا.
قراءة قيم الوسائط (Argument Values)
لتمكين minigrep من قراءة قيم Arguments سطر الأوامر التي نمررها إليه، سنحتاج إلى الدالة (Function) std::env::args المتوفرة في مكتبة Rust القياسية (Standard Library). تعيد هذه Function مكرراً (Iterator) لوسائط سطر الأوامر التي تم تمريرها إلى minigrep. سنغطي Iterators بالكامل في الفصل 13. في الوقت الحالي، تحتاج فقط إلى معرفة تفصيلين حول Iterators: تنتج Iterators سلسلة من القيم، ويمكننا استدعاء التابع (Method) collect على Iterator لتحويله إلى مجموعة (Collection)، مثل المتجه (Vector)، الذي يحتوي على جميع العناصر التي ينتجها Iterator.
تسمح الشفرة البرمجية (Code) في القائمة 12-1 لبرنامج minigrep الخاص بك بقراءة أي Arguments سطر أوامر يتم تمريرها إليه ثم جمع القيم في Vector.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
dbg!(args);
}أولاً، نقوم بجلب الوحدة (Module) std::env إلى النطاق (Scope) باستخدام عبارة (Statement) use حتى نتمكن من استخدام Function args الخاصة بها. لاحظ أن Function std::env::args متداخلة في مستويين من Modules. كما ناقشنا في الفصل 7، في الحالات التي تكون فيها Function المطلوبة متداخلة في أكثر من Module واحد، اخترنا جلب Module الأب إلى Scope بدلاً من Function نفسها. ومن خلال القيام بذلك، يمكننا بسهولة استخدام Functions أخرى من std::env. كما أنه أقل غموضاً من إضافة use std::env::args ثم استدعاء Function باستخدام args فقط، لأن args قد يتم الخلط بينها وبين Function معرفة في Module الحالي.
الدالة
argsوالترميز الموحد (Unicode) غير الصالحلاحظ أن
std::env::argsستتسبب في حالة ذعر (Panic) إذا كان أي Argument يحتوي على Unicode غير صالح. إذا كان برنامجك يحتاج إلى قبول Arguments تحتوي على Unicode غير صالح، فاستخدمstd::env::args_osبدلاً من ذلك. تعيد تلك Function مكرراً (Iterator) ينتج قيمOsStringبدلاً من قيمString. لقد اخترنا استخدامstd::env::argsهنا للتبسيط لأن قيمOsStringتختلف باختلاف نظام التشغيل (Platform) وهي أكثر تعقيداً في التعامل معها من قيمString.
في السطر الأول من main استدعينا env::args واستخدمنا collect على الفور لتحويل Iterator إلى Vector يحتوي على جميع القيم التي ينتجها Iterator. يمكننا استخدام Function collect لإنشاء أنواع عديدة من Collections، لذا قمنا بتحديد نوع (Type) args صراحة لنبين أننا نريد Vector من السلاسل النصية (Strings). على الرغم من أنك نادراً ما تحتاج إلى تحديد Types في Rust، إلا أن collect هي إحدى Functions التي غالباً ما تحتاج إلى تحديد نوعها لأن Rust لا يستطيع استنتاج نوع Collection الذي تريده.
أخيراً، نقوم بطباعة Vector باستخدام ماكرو التصحيح (Debug Macro). لنحاول تشغيل Code أولاً بدون Arguments ثم مع وسيطين:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
]
$ cargo run -- needle haystack
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep needle haystack`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
"needle",
"haystack",
]
لاحظ أن القيمة الأولى في Vector هي "target/debug/minigrep"، وهي اسم ملفنا الثنائي (Binary). هذا يطابق سلوك قائمة Arguments في لغة C، مما يسمح للبرامج باستخدام الاسم الذي تم استدعاؤها به أثناء تنفيذها. غالباً ما يكون من الملائم الوصول إلى اسم البرنامج في حال كنت ترغب في طباعته في الرسائل أو تغيير سلوك البرنامج بناءً على الاسم المستعار (Alias) لسطر الأوامر الذي تم استخدامه لاستدعاء البرنامج. ولكن لأغراض هذا الفصل، سنتجاهله ونحفظ فقط وسيطي (Arguments) اللذين نحتاجهما.
حفظ قيم الوسائط في متغيرات (Variables)
البرنامج قادر حالياً على الوصول إلى القيم المحددة كـ Arguments سطر الأوامر. نحتاج الآن إلى حفظ قيم وسيطي (Arguments) في متغيرات (Variables) حتى نتمكن من استخدام القيم في بقية البرنامج. نقوم بذلك في القائمة 12-2.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
}كما رأينا عندما قمنا بطباعة Vector، فإن اسم البرنامج يشغل القيمة الأولى في Vector عند args[0]، لذا سنبدأ Arguments عند الفهرس (Index) 1. أول Argument يأخذه minigrep هو السلسلة النصية التي نبحث عنها، لذا نضع مرجعاً (Reference) لـ Argument الأول في المتغير (Variable) query. سيكون Argument الثاني هو مسار الملف، لذا نضع Reference لـ Argument الثاني في Variable file_path.
نقوم بطباعة قيم هذه Variables مؤقتاً لإثبات أن Code يعمل كما نريد. لنقم بتشغيل هذا البرنامج مرة أخرى مع Arguments test و sample.txt:
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
Searching for test
In file sample.txt
رائع، البرنامج يعمل! يتم حفظ قيم Arguments التي نحتاجها في Variables الصحيحة. لاحقاً سنضيف بعض معالجة الأخطاء (Error Handling) للتعامل مع بعض المواقف الخاطئة المحتملة، مثل عندما لا يقدم المستخدم أي Arguments؛ في الوقت الحالي، سنتجاهل هذا الموقف ونعمل على إضافة إمكانيات قراءة الملفات بدلاً من ذلك.
قراءة ملف
قراءة ملف (Reading a File)
سنقوم الآن بإضافة وظيفة لقراءة الملف المحدد في وسيط (argument) file_path. أولاً، نحتاج إلى ملف عينة لاختباره: سنستخدم ملفاً يحتوي على كمية صغيرة من النص عبر عدة أسطر مع بعض الكلمات المتكررة. تحتوي القائمة 12-3 على قصيدة لإميلي ديكنسون (Emily Dickinson) ستعمل بشكل جيد! أنشئ ملفاً يسمى poem.txt في المستوى الجذر لمشروعك، وأدخل قصيدة “I’m Nobody! Who are you?”.
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
مع وجود النص في مكانه، قم بتحرير src/main.rs وأضف كوداً لقراءة الملف، كما هو موضح في القائمة 12-4.
use std::env;
use std::fs;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}أولاً، نقوم باستيراد جزء ذي صلة من المكتبة القياسية (standard library) باستخدام جملة use: نحتاج إلى std::fs للتعامل مع الملفات.
في main ، تأخذ الجملة الجديدة fs::read_to_string الـ file_path ، وتفتح ذلك الملف، وتُرجع قيمة من نوع std::io::Result<String> تحتوي على محتويات الملف.
بعد ذلك، نضيف مرة أخرى جملة println! مؤقتة تطبع قيمة contents بعد قراءة الملف حتى نتمكن من التحقق من أن البرنامج يعمل حتى الآن.
دعونا نشغل هذا الكود مع أي سلسلة نصية (string) كأول وسيط لواجهة الأوامر (لأننا لم ننفذ جزء البحث بعد) وملف poem.txt كوسيط ثانٍ:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
رائع! قام الكود بقراءة محتويات الملف ثم طباعتها. لكن الكود به بعض العيوب. في الوقت الحالي، تمتلك دالة main مسؤوليات متعددة: بشكل عام، تكون الدوال أوضح وأسهل في الصيانة إذا كانت كل دالة مسؤولة عن فكرة واحدة فقط. المشكلة الأخرى هي أننا لا نعالج الأخطاء (handling errors) بشكل جيد كما يمكننا. لا يزال البرنامج صغيراً، لذا فإن هذه العيوب ليست مشكلة كبيرة، ولكن مع نمو البرنامج، سيكون من الصعب إصلاحها بشكل نظيف. من الممارسات الجيدة البدء في إعادة الهيكلة (refactoring) في وقت مبكر عند تطوير البرنامج لأنه من الأسهل بكثير إعادة هيكلة كميات أصغر من الكود. سنفعل ذلك بعد ذلك.
إعادة الهيكلة لتحسين الوحدات ومعالجة الأخطاء
إعادة الهيكلة (Refactoring) لتحسين النمطية (Modularity) ومعالجة الأخطاء (Error Handling)
لتحسين برنامجنا، سنقوم بإصلاح أربع مشكلات تتعلق بهيكلة البرنامج وكيفية معالجته للأخطاء المحتملة. أولاً، تقوم دالة main الخاصة بنا الآن بمهمتين: تحليل الوسائط (parse arguments) وقراءة الملفات (reads files). مع نمو برنامجنا، سيزداد عدد المهام المنفصلة التي تتعامل معها دالة main. عندما تكتسب الدالة مسؤوليات، يصبح من الصعب التفكير فيها، وأصعب في الاختبار، وأصعب في التغيير دون كسر أحد أجزائها. من الأفضل فصل الوظائف بحيث تكون كل دالة مسؤولة عن مهمة واحدة.
ترتبط هذه المشكلة أيضًا بالمشكلة الثانية: على الرغم من أن query و file_path هما متغيرات تهيئة (configuration variables) لبرنامجنا، فإن متغيرات مثل contents تُستخدم لأداء منطق (logic) البرنامج. كلما أصبحت main أطول، زاد عدد المتغيرات التي سنحتاج إلى إحضارها إلى النطاق (scope)؛ وكلما زاد عدد المتغيرات لدينا في الـ scope، زادت صعوبة تتبع الغرض من كل منها. من الأفضل تجميع الـ configuration variables في هيكل (structure) واحد لتوضيح الغرض منها.
المشكلة الثالثة هي أننا استخدمنا expect لطباعة رسالة خطأ عندما تفشل قراءة الملف، لكن رسالة الخطأ تطبع فقط Should have been able to read the file. يمكن أن تفشل قراءة الملف بعدة طرق: على سبيل المثال، قد يكون الملف مفقودًا، أو قد لا يكون لدينا إذن لفتحه. في الوقت الحالي، بغض النظر عن الموقف، سنطبع نفس رسالة الخطأ لكل شيء، والتي لن تعطي المستخدم أي معلومات!
رابعًا، نستخدم expect لمعالجة خطأ، وإذا قام المستخدم بتشغيل برنامجنا دون تحديد وسائط كافية، فسيحصل على خطأ تجاوز حدود الفهرس (index out of bounds) من Rust لا يشرح المشكلة بوضوح. سيكون من الأفضل لو كان كل كود Error Handling في مكان واحد بحيث يكون لدى القائمين على الصيانة في المستقبل مكان واحد فقط للرجوع إليه إذا احتاج منطق Error Handling إلى التغيير. سيضمن وجود كل كود Error Handling في مكان واحد أيضًا أننا نطبع رسائل ذات مغزى لمستخدمينا النهائيين.
دعونا نعالج هذه المشاكل الأربعة عن طريق إعادة هيكلة (refactoring) مشروعنا.
فصل الاهتمامات في المشاريع الثنائية (Binary Projects)
تعد مشكلة التنظيم المتمثلة في تخصيص المسؤولية عن مهام متعددة لدالة main شائعة في العديد من الـ binary projects. ونتيجة لذلك، يجد العديد من مبرمجي Rust أنه من المفيد تقسيم الاهتمامات المنفصلة لبرنامج ثنائي عندما تبدأ دالة main في أن تصبح كبيرة. تتضمن هذه العملية الخطوات التالية:
- تقسيم برنامجك إلى ملف
main.rsوملفlib.rsونقل منطق برنامجك إلىlib.rs. - طالما أن منطق تحليل سطر الأوامر (command line parsing) الخاص بك صغير، يمكن أن يظل في دالة
main. - عندما يبدأ منطق command line parsing في أن يصبح معقدًا، قم باستخراجه من دالة
mainإلى دوال أو أنواع أخرى.
يجب أن تقتصر المسؤوليات التي تظل في دالة main بعد هذه العملية على ما يلي:
- استدعاء منطق command line parsing بقيم الوسائط
- إعداد أي تهيئة أخرى
- استدعاء دالة
runفيlib.rs - معالجة الخطأ إذا أرجعت دالة
runخطأ
يدور هذا النمط حول فصل الاهتمامات: يتعامل main.rs مع تشغيل البرنامج ويتعامل lib.rs مع كل منطق المهمة قيد التنفيذ. نظرًا لأنه لا يمكنك اختبار دالة main مباشرة، فإن هذا الهيكل يسمح لك باختبار كل منطق برنامجك عن طريق نقله خارج دالة main. سيكون الكود الذي يظل في دالة main صغيرًا بما يكفي للتحقق من صحته عن طريق قراءته. دعونا نعيد صياغة برنامجنا باتباع هذه العملية.
استخراج محلل الوسائط (Argument Parser)
سنقوم باستخراج الوظيفة الخاصة بـ parse arguments إلى دالة ستستدعيها main. تُظهر القائمة 12-5 البداية الجديدة لدالة main التي تستدعي دالة جديدة parse_config، والتي سنقوم بتعريفها في src/main.rs.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (query, file_path) = parse_config(&args);
// --snip--
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
fn parse_config(args: &[String]) -> (&str, &str) {
let query = &args[1];
let file_path = &args[2];
(query, file_path)
}ما زلنا نجمع وسائط سطر الأوامر في متجه (vector)، ولكن بدلاً من تعيين قيمة الوسيطة في الـ index 1 للمتغير query وقيمة الوسيطة في الـ index 2 للمتغير file_path داخل دالة main، نمرر الـ vector بالكامل إلى دالة parse_config. تحتوي دالة parse_config بعد ذلك على المنطق الذي يحدد الوسيطة التي تذهب إلى أي متغير وتمرر القيم مرة أخرى إلى main. ما زلنا ننشئ المتغيرين query و file_path في main، لكن main لم تعد مسؤولة عن تحديد كيفية توافق وسائط سطر الأوامر والمتغيرات.
قد تبدو إعادة الصياغة هذه مبالغة بالنسبة لبرنامجنا الصغير، لكننا نقوم بـ refactoring في خطوات صغيرة ومتزايدة. بعد إجراء هذا التغيير، قم بتشغيل البرنامج مرة أخرى للتحقق من أن parse arguments لا يزال يعمل. من الجيد التحقق من تقدمك كثيرًا، للمساعدة في تحديد سبب المشاكل عند حدوثها.
تجميع قيم التهيئة (Configuration Values)
يمكننا اتخاذ خطوة صغيرة أخرى لتحسين دالة parse_config بشكل أكبر. في الوقت الحالي، نقوم بإرجاع صف (tuple)، ولكننا بعد ذلك نقوم على الفور بتقسيم هذا الـ tuple إلى أجزاء فردية مرة أخرى. هذه علامة على أنه ربما ليس لدينا التجريد (abstraction) الصحيح بعد.
مؤشر آخر يوضح أن هناك مجالًا للتحسين هو جزء config من parse_config، مما يعني أن القيمتين اللتين نرجعهما مرتبطتان وكلاهما جزء من قيمة تهيئة واحدة. نحن لا ننقل هذا المعنى حاليًا في هيكل البيانات بخلاف تجميع القيمتين في tuple؛ بدلاً من ذلك، سنضع القيمتين في هيكل (struct) واحد ونعطي كل حقل (field) من حقول الـ struct اسمًا ذا مغزى. سيؤدي القيام بذلك إلى تسهيل فهم القائمين على صيانة هذا الكود في المستقبل لكيفية ارتباط القيم المختلفة ببعضها البعض وما هو الغرض منها.
تُظهر القائمة 12-6 التحسينات التي تم إجراؤها على دالة parse_config.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = parse_config(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
// --snip--
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
fn parse_config(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}لقد أضفنا struct يسمى Config تم تعريفه ليحتوي على fields تسمى query و file_path. يشير توقيع parse_config الآن إلى أنه يُرجع قيمة Config. في نص parse_config، حيث اعتدنا على إرجاع شرائح string (string slices) تشير إلى قيم String في args، نقوم الآن بتعريف Config لاحتواء قيم String مملوكة. متغير args في main هو المالك لقيم الوسائط ويسمح فقط لدالة parse_config باستعارتها (borrow)، مما يعني أننا سننتهك قواعد الاستعارة (borrowing rules) الخاصة بـ Rust إذا حاول Config أخذ ملكية القيم في args.
هناك عدد من الطرق التي يمكننا من خلالها إدارة بيانات String؛ أسهل طريقة، على الرغم من أنها غير فعالة إلى حد ما، هي استدعاء دالة clone (clone method) على القيم. سيؤدي هذا إلى عمل نسخة كاملة من البيانات لمثيل Config لامتلاكها، الأمر الذي يستغرق وقتًا وذاكرة أكبر من تخزين مرجع لبيانات الـ string. ومع ذلك، فإن عمل clone للبيانات يجعل الكود الخاص بنا مباشرًا للغاية لأننا لسنا مضطرين لإدارة فترات الحياة (lifetimes) للمراجع؛ في هذه الظروف، يعد التخلي عن القليل من الأداء للحصول على البساطة مقايضة تستحق العناء.
المقايضات في استخدام
cloneهناك ميل بين العديد من مبرمجي Rust لتجنب استخدام
cloneلإصلاح مشاكل Ownership بسبب تكلفته في وقت التشغيل. في الفصل 13، ستتعلم كيفية استخدام methods أكثر كفاءة في هذا النوع من المواقف. ولكن في الوقت الحالي، لا بأس في نسخ بعض الـ strings لمواصلة إحراز التقدم لأنك ستقوم بهذه النسخ مرة واحدة فقط ومسار ملفك وسلسلة الاستعلام (query string) صغيران جدًا. من الأفضل أن يكون لديك برنامج يعمل ولكنه غير فعال بعض الشيء بدلاً من محاولة التحسين المفرط للكود في محاولتك الأولى. عندما تصبح أكثر خبرة في Rust، سيكون من الأسهل البدء بالحل الأكثر كفاءة، ولكن في الوقت الحالي، من المقبول تمامًا استدعاءclone.
لقد قمنا بتحديث main بحيث يضع مثيل Config الذي تم إرجاعه بواسطة parse_config في متغير يسمى config، وقمنا بتحديث الكود الذي كان يستخدم سابقًا المتغيرين المنفصلين query و file_path بحيث يستخدم الآن الـ fields الموجودة على struct Config بدلاً من ذلك.
الآن ينقل الكود الخاص بنا بشكل أكثر وضوحًا أن query و file_path مرتبطان وأن الغرض منهما هو تهيئة كيفية عمل البرنامج. أي كود يستخدم هذه القيم يعرف أنه يجب العثور عليها في مثيل config في الـ fields المسماة لغرضها.
إنشاء دالة بناء (Constructor) لـ Config
حتى الآن، قمنا باستخراج المنطق المسؤول عن parse arguments سطر الأوامر من main ووضعناه في دالة parse_config. ساعدنا القيام بذلك في رؤية أن قيم query و file_path مرتبطة، ويجب نقل هذه العلاقة في الكود الخاص بنا. ثم أضفنا struct Config لتسمية الغرض المرتبط بـ query و file_path ولتكون قادرًا على إرجاع أسماء قيم الـ fields كـ struct field names من دالة parse_config.
لذا، الآن بعد أن أصبح الغرض من دالة parse_config هو إنشاء مثيل Config، يمكننا تغيير parse_config من دالة عادية إلى دالة تسمى new مرتبطة بـ struct Config. سيؤدي إجراء هذا التغيير إلى جعل الكود أكثر اصطلاحية (idiomatic). يمكننا إنشاء مثيلات من الأنواع في المكتبة القياسية، مثل String، عن طريق استدعاء String::new. وبالمثل، عن طريق تغيير parse_config إلى دالة new مرتبطة بـ Config، سنتمكن من إنشاء مثيلات Config عن طريق استدعاء Config::new. تُظهر القائمة 12-7 التغييرات التي نحتاج إلى إجرائها.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
// --snip--
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}لقد قمنا بتحديث main حيث كنا نستدعي parse_config لاستدعاء Config::new بدلاً من ذلك. لقد قمنا بتغيير اسم parse_config إلى new ونقلناه داخل كتلة impl (impl block)، والتي تربط دالة new بـ Config. حاول تجميع هذا الكود مرة أخرى للتأكد من أنه يعمل.
إصلاح معالجة الأخطاء (Fixing the Error Handling)
الآن سنعمل على إصلاح Error Handling الخاص بنا. تذكر أن محاولة الوصول إلى القيم في الـ vector args في الـ index 1 أو الـ index 2 ستتسبب في ذعر (panic!) البرنامج إذا كان الـ vector يحتوي على أقل من ثلاثة عناصر. حاول تشغيل البرنامج بدون أي وسائط؛ سيبدو كالتالي:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:27:21:
index out of bounds: the len is 1 but the index is 1
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
السطر index out of bounds: the len is 1 but the index is 1 هو خطأ…
تحسين رسالة الخطأ (Improving the Error Message)
في القائمة 12-8، نضيف فحصًا في دالة new يتحقق من أن الشريحة (slice) طويلة بما يكفي قبل الوصول إلى الـ index 1 والـ index 2. إذا لم تكن الشريحة طويلة بما يكفي، يحدث panic! للبرنامج ويعرض رسالة خطأ أفضل.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
// --snip--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("not enough arguments");
}
// --snip--
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}يشبه هذا الكود دالة Guess::new التي كتبناها في القائمة 9-13، حيث استدعينا panic! عندما كانت وسيطة value خارج نطاق القيم الصالحة. بدلاً من التحقق من نطاق من القيم هنا، نتحقق من أن طول args هو 3 على الأقل ويمكن لبقية الدالة أن تعمل بافتراض أن هذا الشرط قد تم الوفاء به. إذا كان args يحتوي على أقل من ثلاثة عناصر، فسيكون هذا الشرط true، ونستدعي الماكرو panic! لإنهاء البرنامج على الفور.
باستخدام هذه الأسطر الإضافية القليلة من الكود في new، دعنا نشغل البرنامج بدون أي وسائط مرة أخرى لنرى كيف يبدو الخطأ الآن:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:26:13:
not enough arguments
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
هذا الخرج أفضل: لدينا الآن رسالة خطأ معقولة. ومع ذلك، لدينا أيضًا معلومات زائدة لا نريد إعطاءها لمستخدمينا. ربما التقنية التي استخدمناها في القائمة 9-13 ليست الأفضل للاستخدام هنا: استدعاء panic! أكثر ملاءمة لمشكلة برمجة من مشكلة استخدام، كما نوقش في الفصل 9. بدلاً من ذلك، سنستخدم التقنية الأخرى التي تعلمتها في الفصل 9 - إرجاع نتيجة (Result) تشير إما إلى النجاح أو الخطأ.
إرجاع Result بدلاً من استدعاء panic!
يمكننا بدلاً من ذلك إرجاع قيمة Result ستحتوي على مثيل Config في حالة النجاح وستصف المشكلة في حالة الخطأ. سنقوم أيضًا بتغيير اسم الدالة من new إلى build لأن العديد من المبرمجين يتوقعون ألا تفشل دوال new أبدًا. عندما تتواصل Config::build مع main، يمكننا استخدام النوع Result للإشارة إلى وجود مشكلة. بعد ذلك، يمكننا تغيير main لتحويل متغير Err إلى خطأ أكثر عملية لمستخدمينا دون النص المحيط حول thread 'main' و RUST_BACKTRACE الذي يسببه استدعاء panic!.
تُظهر القائمة 12-9 التغييرات التي نحتاج إلى إجرائها على قيمة الإرجاع للدالة التي نسميها الآن Config::build ونص الدالة اللازم لإرجاع Result. لاحظ أن هذا لن يتم تجميعه حتى نقوم بتحديث main أيضًا، وهو ما سنفعله في القائمة التالية.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}تُرجع دالة build الخاصة بنا Result مع مثيل Config في حالة النجاح وحرفي string في حالة الخطأ. ستكون قيم الخطأ الخاصة بنا دائمًا string literals لها فترة الحياة (lifetime) 'static.
لقد أجرينا تغييرين في نص الدالة: بدلاً من استدعاء panic! عندما لا يمرر المستخدم وسائط كافية، نُرجع الآن قيمة Err، وقمنا بتغليف قيمة إرجاع Config في Ok. هذه التغييرات تجعل الدالة تتوافق مع توقيع النوع الجديد الخاص بها.
يسمح إرجاع قيمة Err من Config::build لدالة main بمعالجة قيمة Result التي تم إرجاعها من دالة build وإنهاء العملية بشكل أنظف في حالة الخطأ.
استدعاء Config::build ومعالجة الأخطاء
لمعالجة حالة الخطأ وطباعة رسالة سهلة الاستخدام، نحتاج إلى تحديث main لمعالجة Result الذي يتم إرجاعه بواسطة Config::build، كما هو موضح في القائمة 12-10. سنتحمل أيضًا مسؤولية إنهاء أداة سطر الأوامر برمز خطأ غير صفري (nonzero error code) بعيدًا عن panic! وبدلاً من ذلك سنقوم بتطبيقه يدويًا. حالة الخروج غير الصفرية هي اصطلاح للإشارة إلى العملية التي استدعت برنامجنا بأن البرنامج خرج بحالة خطأ.
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}في هذه القائمة، استخدمنا دالة لم نقم بتغطيتها بالتفصيل بعد: unwrap_or_else (unwrap_or_else method)، والتي تم تعريفها على Result<T, E> بواسطة المكتبة القياسية. يسمح لنا استخدام unwrap_or_else بتعريف بعض Error Handling المخصص وغير panic!. إذا كانت Result قيمة Ok، فإن سلوك هذه الدالة يشبه unwrap: فإنه يُرجع القيمة الداخلية التي يغلفها Ok. ومع ذلك، إذا كانت القيمة قيمة Err، فإن هذه الدالة تستدعي الكود في الدالة المجهولة (closure)، وهي دالة مجهولة نقوم بتعريفها وتمريرها كوسيطة إلى unwrap_or_else. سنغطي الـ closures بمزيد من التفصيل في الفصل 13. في الوقت الحالي، تحتاج فقط إلى معرفة أن unwrap_or_else سيمرر القيمة الداخلية لـ Err، والتي في هذه الحالة هي الـ string الثابت "not enough arguments" الذي أضفناه في القائمة 12-9، إلى الـ closure الخاص بنا في الوسيطة err التي تظهر بين الأنابيب العمودية. يمكن للكود الموجود في الـ closure بعد ذلك استخدام قيمة err عند تشغيله.
لقد أضفنا سطر use جديدًا لإحضار process من المكتبة القياسية إلى الـ scope. الكود الموجود في الـ closure الذي سيتم تشغيله في حالة الخطأ هو سطران فقط: نطبع قيمة err ثم نستدعي process::exit. ستوقف دالة process::exit البرنامج على الفور وتُرجع الرقم الذي تم تمريره كرمز حالة الخروج. هذا مشابه لـ Error Handling القائم على panic! الذي استخدمناه في القائمة 12-8، لكننا لم نعد نحصل على كل الخرج الإضافي. لنجربها:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problem parsing arguments: not enough arguments
عظيم! هذا الخرج أكثر ودية لمستخدمينا.
استخراج المنطق من main
الآن بعد أن انتهينا من refactoring لـ parse arguments، دعنا ننتقل إلى منطق البرنامج. كما ذكرنا في “فصل الاهتمامات في المشاريع الثنائية”، سنقوم باستخراج دالة تسمى run ستحتوي على كل المنطق الموجود حاليًا في دالة main والذي لا يشارك في إعداد التهيئة أو Error Handling. عندما ننتهي، ستكون دالة main موجزة وسهلة التحقق عن طريق الفحص، وسنكون قادرين على كتابة اختبارات لكل المنطق الآخر.
تُظهر القائمة 12-11 التحسين الصغير والمتزايد لاستخراج دالة run.
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) {
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}تحتوي دالة run الآن على كل المنطق المتبقي من main، بدءًا من قراءة الملف. تأخذ دالة run مثيل Config كوسيطة.
إرجاع الأخطاء من run
مع فصل منطق البرنامج المتبقي في دالة run، يمكننا تحسين Error Handling، كما فعلنا مع Config::build في القائمة 12-9. بدلاً من السماح للبرنامج بـ panic! عن طريق استدعاء expect، ستُرجع دالة run قيمة Result<T, E> عندما يحدث خطأ ما. سيسمح لنا هذا بزيادة دمج المنطق حول Error Handling في main بطريقة سهلة الاستخدام. تُظهر القائمة 12-12 التغييرات التي نحتاج إلى إجرائها على توقيع ونص run.
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}لقد أجرينا ثلاثة تغييرات مهمة هنا. أولاً، قمنا بتغيير نوع الإرجاع لدالة run إلى Result<(), Box<dyn Error>>. كانت هذه الدالة تُرجع سابقًا نوع الوحدة (unit type)، ()، ونحتفظ بذلك كقيمة مُرجعة في حالة Ok.
بالنسبة لنوع الخطأ، استخدمنا كائن سمة (trait object) Box<dyn Error> (وأحضرنا std::error::Error إلى الـ scope باستخدام عبارة use في الأعلى). سنغطي الـ trait objects في الفصل 18. في الوقت الحالي، ما عليك سوى معرفة أن Box<dyn Error> يعني أن الدالة ستُرجع نوعًا يطبق السمة (trait) Error، ولكن ليس علينا تحديد النوع المعين الذي ستكون عليه قيمة الإرجاع. يمنحنا هذا المرونة لإرجاع قيم خطأ قد تكون من أنواع مختلفة في حالات خطأ مختلفة. الكلمة المفتاحية dyn هي اختصار لـ dynamic.
ثانيًا، قمنا بإزالة الاستدعاء لـ expect لصالح عامل التشغيل ؟ (? operator)، كما تحدثنا في الفصل 9. بدلاً من panic! عند حدوث خطأ، سيُرجع ؟ قيمة الخطأ من الدالة الحالية للمستدعي لمعالجتها.
ثالثًا، تُرجع دالة run الآن قيمة Ok في حالة النجاح. لقد أعلنا عن نوع نجاح دالة run على أنه () في التوقيع، مما يعني أننا بحاجة إلى تغليف قيمة unit type في قيمة Ok. قد يبدو بناء الجملة Ok(()) غريبًا بعض الشيء في البداية. لكن استخدام () بهذه الطريقة هو الطريقة الاصطلاحية للإشارة إلى أننا نستدعي run لآثارها الجانبية (side effects) فقط؛ فهي لا تُرجع قيمة نحتاجها.
عندما تقوم بتشغيل هذا الكود، سيتم تجميعه ولكنه سيعرض تحذيرًا:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
19 | let _ = run(config);
| +++++++
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
تخبرنا Rust أن الكود الخاص بنا تجاهل قيمة Result وقد تشير قيمة Result إلى حدوث خطأ. لكننا لا نتحقق مما إذا كان هناك خطأ أم لا، ويذكرنا المترجم (compiler) بأننا ربما قصدنا أن يكون لدينا بعض كود Error Handling هنا! دعونا نصحح هذه المشكلة الآن.
معالجة الأخطاء التي تم إرجاعها من run في main
سنتحقق من الأخطاء ونتعامل معها باستخدام تقنية مماثلة لتلك التي استخدمناها مع Config::build في القائمة 12-10، ولكن مع اختلاف طفيف:
اسم الملف: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}نستخدم if let بدلاً من unwrap_or_else للتحقق مما إذا كانت run تُرجع قيمة Err ولاستدعاء process::exit(1) إذا كانت كذلك. لا تُرجع دالة run قيمة نريد unwrap بنفس الطريقة التي تُرجع بها Config::build مثيل Config. نظرًا لأن run تُرجع () في حالة النجاح، فإننا نهتم فقط باكتشاف الخطأ، لذلك لا نحتاج إلى unwrap_or_else لإرجاع القيمة غير المغلفة، والتي ستكون () فقط.
نصوص if let و unwrap_or_else هي نفسها في كلتا الحالتين: نطبع الخطأ ونخرج.
تقسيم الكود إلى صندوق مكتبة (Library Crate)
يبدو مشروع minigrep الخاص بنا جيدًا حتى الآن! الآن سنقوم بتقسيم ملف src/main.rs ووضع بعض الكود في ملف src/lib.rs. بهذه الطريقة، يمكننا اختبار الكود والحصول على ملف src/main.rs بمسؤوليات أقل.
دعنا نحدد الكود المسؤول عن البحث عن النص في src/lib.rs بدلاً من src/main.rs، مما سيسمح لنا (أو لأي شخص آخر يستخدم صندوق المكتبة (library crate) minigrep الخاص بنا) باستدعاء دالة البحث من سياقات أكثر من صندوقنا الثنائي (binary crate) minigrep.
أولاً، دعنا نحدد توقيع دالة search في src/lib.rs كما هو موضح في القائمة 12-13، مع نص يستدعي الماكرو unimplemented!. سنشرح التوقيع بمزيد من التفصيل عندما نملأ التطبيق.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}… يمكننا استخدامها من الـ binary crate الخاص بنا ويمكننا اختبارها!
الآن نحتاج إلى إحضار الكود المحدد في src/lib.rs إلى الـ scope الخاص بالـ binary crate في src/main.rs واستدعائه، كما هو موضح في القائمة 12-14.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
// --snip--
use minigrep::search;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}نضيف سطر use minigrep::search لإحضار دالة search من الـ library crate إلى الـ scope الخاص بالـ binary crate. بعد ذلك، في دالة run، بدلاً من طباعة محتويات الملف، نستدعي دالة search ونمرر قيمة config.query و contents كوسيطتين. بعد ذلك، ستستخدم run حلقة for لطباعة كل سطر تم إرجاعه من search يتطابق مع الـ query. هذا أيضًا وقت مناسب لإزالة استدعاءات println! في دالة main التي عرضت الـ query ومسار الملف بحيث يطبع برنامجنا نتائج البحث فقط (إذا لم تحدث أخطاء).
لاحظ أن دالة البحث ستجمع كل النتائج في vector تُرجعه قبل حدوث أي طباعة. قد يكون هذا التطبيق بطيئًا في عرض النتائج عند البحث في ملفات كبيرة، لأن النتائج لا تتم طباعتها عند العثور عليها؛ سنناقش طريقة محتملة لإصلاح ذلك باستخدام المكررات (iterators) في الفصل 13.
يا له من عمل شاق! لقد كان هذا كثيرًا من العمل، لكننا أعددنا أنفسنا للنجاح في المستقبل. أصبح الآن من الأسهل بكثير معالجة الأخطاء، وجعلنا الكود أكثر نمطية (modular). سيتم تنفيذ كل عملنا تقريبًا في src/lib.rs من الآن فصاعدًا.
دعنا نستغل هذه الـ modularity المكتشفة حديثًا من خلال القيام بشيء كان سيكون صعبًا مع الكود القديم ولكنه سهل مع الكود الجديد: سنكتب بعض الاختبارات!
إضافة وظائف باستخدام التطوير المدفوع بالاختبار (Test Driven Development)
إضافة الوظائف باستخدام التطوير القائم على الاختبار (Adding Functionality with Test-Driven Development)
الآن بعد أن أصبح لدينا منطق البحث في src/lib.rs منفصلاً عن دالة main ، أصبح من الأسهل بكثير كتابة اختبارات (tests) للوظائف الأساسية لكودنا. يمكننا استدعاء الدوال مباشرة بـ معاملات (arguments) متنوعة والتحقق من قيم الإرجاع (return values) دون الحاجة إلى استدعاء ملفنا الثنائي (binary) من سطر الأوامر.
في هذا القسم، سنضيف منطق البحث إلى برنامج minigrep باستخدام عملية التطوير القائم على الاختبار (test-driven development - TDD) بالخطوات التالية:
- اكتب اختباراً يفشل وقم بتشغيله للتأكد من فشله للسبب الذي تتوقعه.
- اكتب أو عدل ما يكفي من الكود فقط لجعل الاختبار الجديد ينجح.
- قم بإعادة هيكلة (Refactor) الكود الذي أضفته أو غيرته للتو وتأكد من استمرار نجاح الاختبارات.
- كرر من الخطوة 1!
على الرغم من أنها مجرد واحدة من طرق عديدة لكتابة البرمجيات، إلا أن TDD يمكن أن يساعد في دفع تصميم الكود. كتابة الاختبار قبل كتابة الكود الذي يجعل الاختبار ينجح يساعد في الحفاظ على تغطية اختبار (test coverage) عالية طوال العملية.
سنقوم بتطوير الوظيفة التي ستقوم فعلياً بالبحث عن سلسلة الاستعلام (query string) في محتويات الملف وإنتاج قائمة بالأسطر التي تطابق الاستعلام. سنضيف هذه الوظيفة في دالة تسمى search.
كتابة اختبار فاشل (Writing a Failing Test)
في src/lib.rs ، سنضيف وحدة اختبارات (tests module) مع دالة اختبار، كما فعلنا في الفصل الحادي عشر. تحدد دالة الاختبار السلوك الذي نريده لدالة search: ستأخذ استعلاماً (query) والنص المراد البحث فيه، وستعيد فقط الأسطر من النص التي تحتوي على الاستعلام. توضح القائمة 12-15 هذا الاختبار.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}
// --snip--
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}يبحث هذا الاختبار عن السلسلة "duct". النص الذي نبحث فيه يتكون من ثلاثة أسطر، واحد منها فقط يحتوي على "duct" (لاحظ أن الشرطة المائلة العكسية بعد علامة الاقتباس المزدوجة الافتتاحية تخبر Rust بعدم وضع حرف سطر جديد في بداية محتويات سلسلة النص هذه). نحن نؤكد (assert) أن القيمة المعادة من دالة search تحتوي فقط على السطر الذي نتوقعه.
إذا قمنا بتشغيل هذا الاختبار، فسيفشل حالياً لأن ماكرو unimplemented! يسبب حالة ذعر (panics) مع الرسالة “not implemented”. وفقاً لمبادئ TDD، سنتخذ خطوة صغيرة بإضافة ما يكفي من الكود فقط لكي لا تسبب الدالة panic عند استدعائها عن طريق تعريف دالة search لتعيد دائماً متجهاً (vector) فارغاً، كما هو موضح في القائمة 12-16. بعد ذلك، يجب أن يتم تجميع (compile) الاختبار ويفشل لأن المتجه الفارغ لا يطابق متجراً يحتوي على السطر "safe, fast, productive.".
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}الآن دعونا نناقش سبب حاجتنا إلى تعريف عمر (lifetime) صريح 'a في توقيع (signature) دالة search واستخدام ذلك الـ lifetime مع argument الـ contents وقيمة الإرجاع. تذكر في الفصل العاشر أن معاملات العمر (lifetime parameters) تحدد أي عمر للمعاملات مرتبط بعمر قيمة الإرجاع. في هذه الحالة، نشير إلى أن الـ vector المعاد يجب أن يحتوي على شرائح نصية (string slices) تشير إلى شرائح من الـ argument الـ contents (بدلاً من الـ argument الـ query).
بعبارة أخرى، نحن نخبر Rust أن البيانات المعادة بواسطة دالة search ستعيش طالما عاشت البيانات الممرة إلى دالة search في الـ argument الـ contents. هذا أمر مهم! البيانات المشار إليها بواسطة شريحة (slice) يجب أن تكون صالحة لكي يكون المرجع (reference) صالحاً؛ إذا افترض المترجم (compiler) أننا ننشئ string slices من query بدلاً من contents ، فسيقوم بفحص الأمان بشكل غير صحيح.
إذا نسينا تعليقات العمر (lifetime annotations) وحاولنا تجميع هذه الدالة، فسنحصل على هذا الخطأ:
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:51
|
1 | pub fn search(query: &str, contents: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contents`
help: consider introducing a named lifetime parameter
|
1 | pub fn search<'a>(query: &'a str, contents: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to 1 previous error
لا يمكن لـ Rust معرفة أي من المعاملين نحتاجه للمخرجات، لذا نحتاج إلى إخباره صراحة. لاحظ أن نص المساعدة يقترح تحديد نفس lifetime parameter لجميع المعاملات ونوع المخرجات، وهذا غير صحيح! لأن contents هو المعامل الذي يحتوي على كل النص الخاص بنا ونريد إعادة أجزاء من ذلك النص التي تتطابق، فنحن نعلم أن contents هو المعامل الوحيد الذي يجب أن يكون مرتبطاً بقيمة الإرجاع باستخدام صيغة lifetime.
لا تتطلب لغات البرمجة الأخرى منك ربط المعاملات بقيم الإرجاع في الـ signature، ولكن هذه الممارسة ستصبح أسهل بمرور الوقت. قد ترغب في مقارنة هذا المثال بالأمثلة الموجودة في قسم “التحقق من المراجع باستخدام الأعمار” في الفصل العاشر.
كتابة الكود لإنجاح الاختبار (Writing Code to Pass the Test)
حالياً، يفشل اختبارنا لأننا نعيد دائماً vector فارغاً. لإصلاح ذلك وتنفيذ search ، يحتاج برنامجنا إلى اتباع هذه الخطوات:
- التكرار (Iterate) عبر كل سطر من المحتويات.
- التحقق مما إذا كان السطر يحتوي على سلسلة الاستعلام الخاصة بنا.
- إذا كان يحتوي عليها، أضفه إلى قائمة القيم التي نعيدها.
- إذا لم يكن يحتوي عليها، فلا تفعل شيئاً.
- أعد قائمة النتائج المتطابقة.
دعونا نعمل على كل خطوة، بدءاً من التكرار عبر الأسطر.
التكرار عبر الأسطر باستخدام طريقة lines (Iterating Through Lines with the lines Method)
تمتلك Rust طريقة مفيدة للتعامل مع التكرار سطراً بسطر للسلاسل النصية، تسمى بشكل ملائم lines ، والتي تعمل كما هو موضح في القائمة 12-17. لاحظ أن هذا لن يتم تجميعه بعد.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
// do something with line
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}تعيد طريقة lines مكرراً (iterator). سنتحدث عن الـ iterators بعمق في الفصل الثالث عشر. لكن تذكر أنك رأيت هذه الطريقة لاستخدام iterator في القائمة 3-5 ، حيث استخدمنا حلقة for مع iterator لتشغيل بعض الكود على كل عنصر في مجموعة (collection).
البحث في كل سطر عن الاستعلام (Searching Each Line for the Query)
بعد ذلك، سنتحقق مما إذا كان السطر الحالي يحتوي على سلسلة الاستعلام الخاصة بنا. لحسن الحظ، تمتلك السلاسل النصية طريقة مفيدة تسمى contains تقوم بذلك نيابة عنا! أضف استدعاءً لطريقة contains في دالة search ، كما هو موضح في القائمة 12-18. لاحظ أن هذا لا يزال لن يتم تجميعه بعد.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
if line.contains(query) {
// do something with line
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}في الوقت الحالي، نحن نبني الوظائف. لكي يتم تجميع الكود، نحتاج إلى إعادة قيمة من الجسم كما أشرنا في signature الدالة.
تخزين الأسطر المتطابقة (Storing Matching Lines)
لإنهاء هذه الدالة، نحتاج إلى طريقة لتخزين الأسطر المتطابقة التي نريد إعادتها. لذلك، يمكننا إنشاء vector قابل للتغيير (mutable vector) قبل حلقة for واستدعاء طريقة push لتخزين line في الـ vector. بعد حلقة for ، نعيد الـ vector، كما هو موضح في القائمة 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}الآن يجب أن تعيد دالة search فقط الأسطر التي تحتوي على query ، ويجب أن ينجح اختبارنا. دعونا نشغل الاختبار:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
لقد نجح اختبارنا، لذا نحن نعلم أنه يعمل!
في هذه المرحلة، يمكننا التفكير في فرص لإعادة هيكلة تنفيذ دالة البحث مع الحفاظ على نجاح الاختبارات للحفاظ على نفس الوظيفة. الكود في دالة البحث ليس سيئاً للغاية، لكنه لا يستفيد من بعض الميزات المفيدة للـ iterators. سنعود إلى هذا المثال في الفصل الثالث عشر ، حيث سنستكشف الـ iterators بالتفصيل، وننظر في كيفية تحسينه.
الآن يجب أن يعمل البرنامج بأكمله! دعونا نجربه، أولاً بكلمة يجب أن تعيد سطراً واحداً بالضبط من قصيدة إميلي ديكنسون: frog.
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
رائع! الآن دعونا نجرب كلمة ستطابق أسطراً متعددة، مثل body:
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
وأخيراً، دعونا نتأكد من أننا لا نحصل على أي أسطر عندما نبحث عن كلمة ليست موجودة في أي مكان في القصيدة، مثل monomorphization:
$ cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
ممتاز! لقد بنينا نسختنا المصغرة الخاصة من أداة كلاسيكية وتعلمنا الكثير عن كيفية هيكلة التطبيقات. لقد تعلمنا أيضاً القليل عن إدخال وإخراج الملفات، والأعمار، والاختبار، وتحليل سطر الأوامر.
لإكمال هذا المشروع، سنوضح بإيجاز كيفية التعامل مع متغيرات البيئة (environment variables) وكيفية الطباعة إلى الخطأ القياسي (standard error)، وكلاهما مفيد عندما تكتب برامج سطر الأوامر.
العمل مع متغيرات البيئة (Environment Variables)
العمل مع متغيرات البيئة (Environment Variables)
سنقوم بتحسين البرنامج الثنائي (Binary) لـ minigrep عن طريق إضافة ميزة إضافية: خيار للبحث غير الحساس لحالة الأحرف (Case-insensitive Searching) الذي يمكن للمستخدم تفعيله عبر متغير بيئة (Environment Variable). كان بإمكاننا جعل هذه الميزة خياراً لسطر الأوامر (Command Line Option) ومطالبة المستخدمين بإدخاله في كل مرة يريدون تطبيقه فيها، ولكن بجعله بدلاً من ذلك Environment Variable، فإننا نسمح لمستخدمينا بضبط Environment Variable مرة واحدة وجعل جميع عمليات البحث الخاصة بهم غير حساسة لحالة الأحرف في جلسة الطرفية (Terminal Session) تلك.
كتابة اختبار فاشل للبحث غير الحساس لحالة الأحرف
نضيف أولاً دالة (Function) جديدة باسم search_case_insensitive إلى مكتبة (Library) minigrep والتي سيتم استدعاؤها عندما يكون لـ Environment Variable قيمة. سنستمر في اتباع عملية التطوير القائم على الاختبار (TDD - Test-Driven Development)، لذا فإن الخطوة الأولى هي مرة أخرى كتابة اختبار فاشل (Failing Test). سنضيف اختباراً جديداً لـ Function الجديدة search_case_insensitive ونعيد تسمية اختبارنا القديم من one_result إلى case_sensitive لتوضيح الفروق بين الاختبارين، كما هو موضح في القائمة (Listing) 12-20.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}لاحظ أننا قمنا بتحرير محتويات (Contents) الاختبار القديم أيضاً. لقد أضفنا سطراً جديداً بالنص "Duct tape." باستخدام حرف D كبير لا ينبغي أن يطابق الاستعلام (Query) "duct" عندما نبحث بطريقة حساسة لحالة الأحرف (Case-sensitive). يساعد تغيير الاختبار القديم بهذه الطريقة في ضمان عدم كسر وظيفة البحث الحساس لحالة الأحرف التي قمنا بتنفيذها بالفعل عن طريق الخطأ. يجب أن ينجح هذا الاختبار الآن ويستمر في النجاح بينما نعمل على البحث غير الحساس لحالة الأحرف.
يستخدم الاختبار الجديد للبحث غير الحساس لحالة الأحرف "rUsT" كـ Query خاص به. في Function التي أوشكنا على إضافتها search_case_insensitive ، يجب أن يطابق Query "rUsT" السطر الذي يحتوي على "Rust:" بحرف R كبير ويطابق السطر "Trust me." على الرغم من أن كليهما لهما حالة أحرف مختلفة عن Query. هذا هو Failing Test الخاص بنا، وسيفشل في التحويل البرمجي (Compile) لأننا لم نقم بعد بتعريف Function search_case_insensitive. لا تتردد في إضافة تنفيذ هيكلي (Skeleton Implementation) يعيد دائماً متجهاً (Vector) فارغاً، على غرار الطريقة التي اتبعناها مع Function search في Listing 12-16 لرؤية الاختبار وهو Compile ويفشل.
تنفيذ دالة search_case_insensitive
ستكون Function search_case_insensitive الموضحة في Listing 12-21، هي نفسها تقريباً Function search. الفرق الوحيد هو أننا سنقوم بتحويل Query وكل سطر (Line) إلى أحرف صغيرة (Lowercase) بحيث أياً كانت حالة أحرف وسائط الإدخال (Input Arguments)، فإنها ستكون بنفس حالة الأحرف عندما نتحقق مما إذا كان Line يحتوي على Query.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}أولاً، نقوم بتحويل سلسلة (String) الـ Query إلى Lowercase ونخزنها في متغير (Variable) جديد بنفس الاسم، مما يحجب (Shadowing) الـ Query الأصلي. استدعاء to_lowercase على Query ضروري بحيث بغض النظر عما إذا كان Query الخاص بالمستخدم هو "rust" أو "RUST" أو "Rust" أو "rUsT"، فإننا سنعامل Query كما لو كان "rust" ونكون غير حساسين للحالة. بينما سيتعامل to_lowercase مع ترميز يونيكود (Unicode) الأساسي، إلا أنه لن يكون دقيقاً بنسبة 100 بالمائة. إذا كنا نكتب تطبيقاً حقيقياً، فسنرغب في القيام بمزيد من العمل هنا، ولكن هذا القسم يتعلق بـ Environment Variables وليس Unicode، لذا سنكتفي بذلك هنا.
لاحظ أن Query هو الآن String بدلاً من شريحة سلسلة (String Slice) لأن استدعاء to_lowercase ينشئ بيانات جديدة بدلاً من الإشارة إلى بيانات موجودة. لنفترض أن Query هو "rUsT" كمثال: String Slice تلك لا تحتوي على حرف u أو t صغير لنستخدمه، لذا يتعين علينا تخصيص (Allocate) String جديد يحتوي على "rust". عندما نمرر Query كـ Argument إلى طريقة (Method) contains الآن، نحتاج إلى إضافة علامة أند (Ampersand) لأن توقيع (Signature) contains مُعرف ليأخذ String Slice.
بعد ذلك، نضيف استدعاءً لـ to_lowercase على كل Line لتحويل جميع الأحرف إلى أحرف صغيرة. الآن بعد أن قمنا بتحويل Line و Query إلى Lowercase، سنجد التطابقات بغض النظر عن حالة أحرف Query.
دعونا نرى ما إذا كان هذا التنفيذ يجتاز الاختبارات:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
رائع! لقد اجتازت الاختبارات. الآن دعونا نستدعي Function الجديدة search_case_insensitive من Function run. أولاً، سنضيف خيار تكوين (Configuration Option) إلى هيكل (Struct) Config للتبديل بين البحث الحساس وغير الحساس لحالة الأحرف. ستؤدي إضافة هذا الحقل (Field) إلى حدوث أخطاء في المترجم (Compiler Errors) لأننا لم نقم بتهيئة (Initializing) هذا Field في أي مكان بعد:
اسم الملف: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}لقد أضفنا Field ignore_case الذي يحمل قيمة بولينية (Boolean). بعد ذلك، نحتاج إلى Function run للتحقق من قيمة Field ignore_case واستخدام ذلك لتقرير ما إذا كان سيتم استدعاء Function search أو Function search_case_insensitive كما هو موضح في Listing 12-22. هذا لا يزال لن يتم Compile بعد.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}أخيراً، نحتاج إلى التحقق من Environment Variable. الدوال المخصصة للعمل مع Environment Variables موجودة في وحدة (Module) env في المكتبة القياسية (Standard Library)، والتي هي موجودة بالفعل في النطاق (Scope) في أعلى ملف src/main.rs. سنستخدم Function var من Module env للتحقق مما إذا كان قد تم تعيين أي قيمة لـ Environment Variable يسمى IGNORE_CASE كما هو موضح في Listing 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}هنا، نقوم بإنشاء Variable جديد باسم ignore_case. لتعيين قيمته، نستدعي Function env::var ونمرر لها اسم Environment Variable IGNORE_CASE. تعيد Function env::var نتيجة (Result) ستكون متغير (Variant) النجاح Ok الذي يحتوي على قيمة Environment Variable إذا تم تعيين Environment Variable لأي قيمة. وستعيد Variant الخطأ Err إذا لم يتم تعيين Environment Variable.
نحن نستخدم Method is_ok على Result للتحقق مما إذا كان Environment Variable قد تم تعيينه، مما يعني أن البرنامج يجب أن يقوم ببحث غير حساس لحالة الأحرف. إذا لم يتم تعيين Environment Variable IGNORE_CASE لأي شيء، فإن is_ok ستعيد false وسيقوم البرنامج بإجراء بحث حساس لحالة الأحرف. نحن لا نهتم بـ قيمة Environment Variable، فقط ما إذا كان معيناً أو غير معين، لذا نتحقق من is_ok بدلاً من استخدام unwrap أو expect أو أي من الطرق الأخرى التي رأيناها في Result.
نمرر القيمة الموجودة في Variable ignore_case إلى مثيل (Instance) Config بحيث يمكن لـ Function run قراءة تلك القيمة وتقرير ما إذا كان سيتم استدعاء search_case_insensitive أو search كما نفذنا في Listing 12-22.
دعونا نجرب ذلك! أولاً، سنقوم بتشغيل برنامجنا دون تعيين Environment Variable ومع Query to ، والذي يجب أن يطابق أي Line يحتوي على كلمة to بجميع الأحرف الصغيرة:
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
يبدو أن هذا لا يزال يعمل! الآن دعونا نشغل البرنامج مع تعيين IGNORE_CASE إلى 1 ولكن بنفس Query to:
$ IGNORE_CASE=1 cargo run -- to poem.txt
إذا كنت تستخدم PowerShell، فستحتاج إلى تعيين Environment Variable وتشغيل البرنامج كأوامر منفصلة:
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
سيؤدي هذا إلى جعل IGNORE_CASE يستمر لبقية Terminal Session الخاصة بك. يمكن إلغاء تعيينه باستخدام الأمر (Cmdlet) Remove-Item:
PS> Remove-Item Env:IGNORE_CASE
يجب أن نحصل على Lines تحتوي على to والتي قد تحتوي على أحرف كبيرة:
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
ممتاز، لقد حصلنا أيضاً على Lines تحتوي على To! يمكن لبرنامج minigrep الخاص بنا الآن إجراء بحث غير حساس لحالة الأحرف يتم التحكم فيه بواسطة Environment Variable. الآن أنت تعرف كيفية إدارة الخيارات المحددة باستخدام إما وسائط سطر الأوامر (Command Line Arguments) أو Environment Variables.
تسمح بعض البرامج بـ Arguments و Environment Variables لنفس التكوين. في تلك الحالات، تقرر البرامج أن أحدهما له الأولوية. لتمرين آخر بمفردك، حاول التحكم في حساسية حالة الأحرف من خلال إما Command Line Argument أو Environment Variable. قرر ما إذا كان يجب أن تكون الأولوية لـ Command Line Argument أو Environment Variable إذا تم تشغيل البرنامج مع ضبط أحدهما على الحساسية لحالة الأحرف والآخر على تجاهل حالة الأحرف.
يحتوي Module std::env على العديد من الميزات المفيدة الأخرى للتعامل مع Environment Variables: راجع وثائقه (Documentation) لمعرفة ما هو متاح.
إعادة توجيه الأخطاء إلى الخطأ القياسي (Standard Error)
إعادة توجيه الأخطاء إلى الخطأ القياسي (Redirecting Errors to Standard Error)
في الوقت الحالي، نقوم بكتابة جميع مخرجاتنا إلى الطرفية (terminal) باستخدام ماكرو (macro) println!. في معظم الطرفيات، هناك نوعان من المخرجات: المخرجات القياسية (standard output) وتختصر بـ (stdout) للمعلومات العامة، و الخطأ القياسي (standard error) ويختصر بـ (stderr) لرسائل الخطأ. يتيح هذا التمييز للمستخدمين اختيار توجيه المخرجات الناجحة لبرنامج ما إلى ملف مع الاستمرار في طباعة رسائل الخطأ على الشاشة.
ماكرو println! قادر فقط على الطباعة إلى standard output، لذا يتعين علينا استخدام شيء آخر للطباعة إلى standard error.
التحقق من مكان كتابة الأخطاء (Checking Where Errors Are Written)
أولاً، دعونا نلاحظ كيف يتم حالياً كتابة المحتوى المطبوع بواسطة minigrep إلى standard output، بما في ذلك أي رسائل خطأ نريد كتابتها إلى standard error بدلاً من ذلك. سنفعل ذلك عن طريق إعادة توجيه تدفق standard output إلى ملف مع التسبب في حدوث خطأ عمداً. لن نقوم بإعادة توجيه تدفق standard error، لذا فإن أي محتوى يتم إرساله إلى standard error سيستمر في الظهور على الشاشة.
يُتوقع من برامج واجهة الأوامر (Command line programs) إرسال رسائل الخطأ إلى تدفق standard error حتى نتمكن من رؤية رسائل الخطأ على الشاشة حتى لو قمنا بإعادة توجيه تدفق standard output إلى ملف. برنامجنا حالياً لا يتصرف بشكل جيد: نحن على وشك أن نرى أنه يحفظ مخرجات رسالة الخطأ في ملف بدلاً من ذلك!
لإظهار هذا السلوك، سنقوم بتشغيل البرنامج باستخدام > ومسار الملف، output.txt، الذي نريد إعادة توجيه تدفق standard output إليه. لن نمرر أي وسائط (arguments)، مما قد يتسبب في حدوث خطأ:
$ cargo run > output.txt
تخبر صيغة > الغلاف (shell) بكتابة محتويات standard output إلى output.txt بدلاً من الشاشة. لم نرَ رسالة الخطأ التي كنا نتوقع طباعتها على الشاشة، وهذا يعني أنها لا بد وأن انتهت في الملف. وهذا ما يحتويه output.txt:
Problem parsing arguments: not enough arguments
نعم، تتم طباعة رسالة الخطأ الخاصة بنا إلى standard output. من المفيد أكثر بكثير طباعة رسائل خطأ كهذه إلى standard error بحيث تنتهي البيانات الناتجة عن تشغيل ناجح فقط في الملف. سنقوم بتغيير ذلك.
طباعة الأخطاء إلى الخطأ القياسي (Printing Errors to Standard Error)
سنستخدم الكود الموجود في القائمة 12-24 لتغيير كيفية طباعة رسائل الخطأ. بسبب إعادة الهيكلة (refactoring) التي قمنا بها سابقاً في هذا الفصل، فإن كل الكود الذي يطبع رسائل الخطأ موجود في دالة واحدة، وهي main. توفر المكتبة القياسية (standard library) ماكرو eprintln! الذي يطبع إلى تدفق standard error، لذا دعونا نغير المكانين اللذين كنا نستدعي فيهما println! لطباعة الأخطاء لاستخدام eprintln! بدلاً من ذلك.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}دعونا الآن نشغل البرنامج مرة أخرى بنفس الطريقة، بدون أي arguments ومع إعادة توجيه standard output باستخدام >:
$ cargo run > output.txt
Problem parsing arguments: not enough arguments
الآن نرى الخطأ على الشاشة ولا يحتوي output.txt على شيء، وهو السلوك الذي نتوقعه من Command line programs.
دعونا نشغل البرنامج مرة أخرى مع arguments لا تسبب خطأ ولكن مع الاستمرار في إعادة توجيه standard output إلى ملف، هكذا:
$ cargo run -- to poem.txt > output.txt
لن نرى أي مخرجات في terminal، وسوف يحتوي output.txt على نتائجنا:
اسم الملف: output.txt
Are you nobody, too?
How dreary to be somebody!
يوضح هذا أننا نستخدم الآن standard output للمخرجات الناجحة و standard error لمخرجات الخطأ حسب الاقتضاء.
ملخص (Summary)
لخص هذا الفصل بعض المفاهيم الرئيسية التي تعلمتها حتى الآن وغطى كيفية إجراء عمليات الإدخال والإخراج (I/O operations) الشائعة في Rust. باستخدام arguments واجهة الأوامر، والملفات، ومتغيرات البيئة (environment variables)، وماكرو eprintln! لطباعة الأخطاء، فأنت الآن مستعد لكتابة تطبيقات واجهة الأوامر. وبالجمع مع المفاهيم الواردة في الفصول السابقة، سيكون الكود الخاص بك منظماً جيداً، ويخزن البيانات بفعالية في هياكل البيانات (data structures) المناسبة، ويعالج الأخطاء بشكل جيد، ويكون مختبراً جيداً.
بعد ذلك، سنستكشف بعض ميزات Rust التي تأثرت باللغات الوظيفية (functional languages): الإغلاقات (closures) والمكررات (iterators).
ميزات اللغة الوظيفية: المكررات والإغلاقات (Functional Language Features: Iterators and Closures)
استلهم تصميم لغة Rust من العديد من اللغات والتقنيات الموجودة، وكان أحد التأثيرات الهامة هو البرمجة الوظيفية (functional programming). غالباً ما تتضمن البرمجة بالأسلوب الوظيفي استخدام الدوال كقيم من خلال تمريرها في معاملات (arguments)، وإرجاعها من دوال أخرى، وتعيينها لمتغيرات (variables) لتنفيذها لاحقاً، وما إلى ذلك.
في هذا الفصل، لن نناقش مسألة ماهية البرمجة الوظيفية أو ما ليست عليه، بل سنناقش بدلاً من ذلك بعض ميزات Rust التي تشبه الميزات الموجودة في العديد من اللغات التي يشار إليها غالباً بأنها وظيفية.
بشكل أكثر تحديداً، سنغطي ما يلي:
- الإغلاقات (Closures): وهي بنية تشبه الدالة يمكنك تخزينها في متغير.
- المكررات (Iterators): وهي طريقة لمعالجة سلسلة من العناصر.
- كيفية استخدام Closures و Iterators لتحسين مشروع الإدخال والإخراج (I/O project) في الفصل الثاني عشر.
- أداء Closures و Iterators (تنبيه: إنها أسرع مما قد تعتقد!).
لقد غطينا بالفعل بعض ميزات Rust الأخرى، مثل مطابقة الأنماط (pattern matching) والتعدادات (enums)، والتي تأثرت أيضاً بالأسلوب الوظيفي. ولأن إتقان Closures و Iterators يعد جزءاً مهماً من كتابة كود Rust سريع واحترافي (idiomatic)، فسنخصص هذا الفصل بالكامل لهما.
الإغلاقات (Closures)
الإغلاقات (Closures)
الإغلاقات (Closures) في Rust هي دوال مجهولة (anonymous functions) يمكنك حفظها في متغير (variable) أو تمريرها كوسائط (arguments) إلى دوال (functions) أخرى. يمكنك إنشاء الـ Closure في مكان واحد ثم استدعاء الـ Closure في مكان آخر لتقييمها في سياق مختلف. على عكس الـ functions، يمكن للـ Closures التقاط قيم من النطاق (scope) الذي تم تعريفها فيه. سنوضح كيف تسمح ميزات الـ Closure هذه بإعادة استخدام الكود (code reuse) وتخصيص السلوك (behavior customization).
التقاط البيئة (Capturing the Environment)
سنقوم أولاً بفحص كيف يمكننا استخدام Closures لالتقاط قيم من البيئة (environment) التي تم تعريفها فيها لاستخدامها لاحقًا. إليك السيناريو: بين الحين والآخر، تقوم شركة القمصان لدينا بإهداء قميص حصري ومحدود الإصدار (exclusive, limited-edition shirt) لشخص ما في قائمة البريد (mailing list) الخاصة بنا كعرض ترويجي. يمكن للأشخاص في الـ mailing list إضافة لونهم المفضل (favorite color) اختياريًا إلى ملفهم الشخصي (profile). إذا كان لدى الشخص الذي تم اختياره للحصول على قميص مجاني لون مفضل محدد، فسيحصل على قميص بهذا اللون. إذا لم يحدد الشخص لونًا مفضلاً، فسيحصل على أي لون تتوفر منه الشركة حاليًا على أكبر عدد.
هناك العديد من الطرق لتنفيذ ذلك. لهذا المثال، سنستخدم enum يسمى ShirtColor يحتوي على المتغيرات (variants) Red و Blue (لتبسيط عدد الألوان المتاحة). نمثل مخزون الشركة (inventory) باستخدام struct يسمى Inventory يحتوي على حقل باسم shirts يتضمن Vec<ShirtColor> يمثل ألوان القمصان المتوفرة حاليًا في المخزون. تقوم الدالة giveaway المعرفة على Inventory بالحصول على تفضيل لون القميص الاختياري للفائز بالقميص المجاني، وتعيد لون القميص الذي سيحصل عليه الشخص. يظهر هذا الإعداد في القائمة 13-1.
#[derive(Debug, PartialEq, Copy, Clone)]
enum ShirtColor {
Red,
Blue,
}
struct Inventory {
shirts: Vec<ShirtColor>,
}
impl Inventory {
fn giveaway(&self, user_preference: Option<ShirtColor>) -> ShirtColor {
user_preference.unwrap_or_else(|| self.most_stocked())
}
fn most_stocked(&self) -> ShirtColor {
let mut num_red = 0;
let mut num_blue = 0;
for color in &self.shirts {
match color {
ShirtColor::Red => num_red += 1,
ShirtColor::Blue => num_blue += 1,
}
}
if num_red > num_blue {
ShirtColor::Red
} else {
ShirtColor::Blue
}
}
}
fn main() {
let store = Inventory {
shirts: vec![ShirtColor::Blue, ShirtColor::Red, ShirtColor::Blue],
};
let user_pref1 = Some(ShirtColor::Red);
let giveaway1 = store.giveaway(user_pref1);
println!(
"The user with preference {:?} gets {:?}",
user_pref1, giveaway1
);
let user_pref2 = None;
let giveaway2 = store.giveaway(user_pref2);
println!(
"The user with preference {:?} gets {:?}",
user_pref2, giveaway2
);
}يحتوي الـ store المعرف في main على قميصين أزرق وقميص أحمر متبقيين لتوزيعهما لهذا العرض الترويجي محدود الإصدار. نستدعي الدالة giveaway لمستخدم يفضل قميصًا أحمر ومستخدم ليس لديه أي تفضيل.
مرة أخرى، يمكن تنفيذ هذا الكود بعدة طرق، وهنا، للتركيز على Closures، التزمنا بالمفاهيم التي تعلمتها بالفعل، باستثناء جسم الدالة giveaway الذي يستخدم Closure. في الدالة giveaway، نحصل على تفضيل المستخدم كـ parameter من نوع Option<ShirtColor> ونستدعي الدالة unwrap_or_else على user_preference. يتم تعريف الدالة unwrap_or_else على Option<T> بواسطة المكتبة القياسية (standard library). تأخذ وسيطًا واحدًا: Closure بدون أي وسائط تعيد قيمة T (نفس النوع المخزن في متغير Some من الـ Option<T>، وفي هذه الحالة ShirtColor). إذا كان الـ Option<T> هو متغير Some، فإن unwrap_or_else تعيد القيمة من داخل الـ Some. إذا كان الـ Option<T> هو متغير None، فإن unwrap_or_else تستدعي الـ Closure وتعيد القيمة التي أعادتها الـ Closure.
نحدد تعبير الـ Closure || self.most_stocked() كوسيط لـ unwrap_or_else. هذه Closure لا تأخذ أي parameters بنفسها (إذا كانت الـ Closure تحتوي على parameters، فستظهر بين علامتي الأنبوب العمودي). جسم الـ Closure يستدعي self.most_stocked(). نحن نعرّف الـ Closure هنا، وسيقوم تنفيذ unwrap_or_else بتقييم الـ Closure لاحقًا إذا كانت النتيجة مطلوبة.
تشغيل هذا الكود يطبع ما يلي:
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
The user with preference Some(Red) gets Red
The user with preference None gets Blue
أحد الجوانب المثيرة للاهتمام هنا هو أننا مررنا Closure تستدعي self.most_stocked() على مثيل Inventory الحالي. لم تكن المكتبة القياسية بحاجة إلى معرفة أي شيء عن أنواع Inventory أو ShirtColor التي عرفناها، أو المنطق الذي نريد استخدامه في هذا السيناريو. تلتقط الـ Closure مرجعًا غير قابل للتغيير (immutable reference) إلى مثيل self Inventory وتمرره مع الكود الذي نحدده إلى الدالة unwrap_or_else. الـ functions، من ناحية أخرى، غير قادرة على التقاط بيئتها بهذه الطريقة.
استنتاج أنواع Closures وتحديدها (Inferring and Annotating Closure Types)
هناك المزيد من الاختلافات بين الـ functions والـ Closures. لا تتطلب الـ Closures عادةً منك تحديد أنواع الـ parameters أو قيمة الإرجاع (return value) كما تفعل الـ fn functions. تحديد أنواع الـ parameters مطلوب في الـ functions لأن الأنواع هي جزء من واجهة صريحة (explicit interface) مكشوفة لمستخدميك. يعد تحديد هذه الواجهة بصرامة أمرًا مهمًا لضمان اتفاق الجميع على أنواع القيم التي تستخدمها الـ function وتعيدها. الـ Closures، من ناحية أخرى، لا تُستخدم في واجهة مكشوفة كهذه: يتم تخزينها في variables، وتُستخدم دون تسميتها وكشفها لمستخدمي مكتبتنا.
عادةً ما تكون الـ Closures قصيرة وذات صلة فقط ضمن سياق ضيق بدلاً من أي سيناريو عشوائي. ضمن هذه السياقات المحدودة، يمكن للمترجم (compiler) استنتاج أنواع الـ parameters ونوع الإرجاع، على غرار كيفية قدرته على استنتاج أنواع معظم الـ variables (هناك حالات نادرة يحتاج فيها الـ compiler أيضًا إلى تحديد أنواع الـ Closure).
كما هو الحال مع الـ variables، يمكننا إضافة تحديد أنواع (type annotations) إذا أردنا زيادة الوضوح والصراحة على حساب أن تكون أكثر إسهابًا مما هو ضروري تمامًا. سيبدو تحديد الأنواع لـ Closure كما هو موضح في القائمة 13-2. في هذا المثال، نقوم بتعريف Closure وتخزينها في variable بدلاً من تعريف الـ Closure في المكان الذي نمررها فيه كوسيط، كما فعلنا في القائمة 13-1.
use std::thread;
use std::time::Duration;
fn generate_workout(intensity: u32, random_number: u32) {
let expensive_closure = |num: u32| -> u32 {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
};
if intensity < 25 {
println!("Today, do {} pushups!", expensive_closure(intensity));
println!("Next, do {} situps!", expensive_closure(intensity));
} else {
if random_number == 3 {
println!("Take a break today! Remember to stay hydrated!");
} else {
println!(
"Today, run for {} minutes!",
expensive_closure(intensity)
);
}
}
}
fn main() {
let simulated_user_specified_value = 10;
let simulated_random_number = 7;
generate_workout(simulated_user_specified_value, simulated_random_number);
}مع إضافة الـ type annotations، يبدو بناء جملة الـ Closures أكثر تشابهًا مع بناء جملة الـ functions. هنا، نعرّف function تضيف 1 إلى الـ parameter الخاص بها و Closure لها نفس السلوك، للمقارنة. لقد أضفنا بعض المسافات لمواءمة الأجزاء ذات الصلة. يوضح هذا كيف أن بناء جملة الـ Closure يشبه بناء جملة الـ function باستثناء استخدام علامات الأنبوب العمودي وكمية بناء الجملة الاختيارية:
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;يُظهر السطر الأول تعريف function ويُظهر السطر الثاني تعريف Closure محدد بالكامل. في السطر الثالث، نزيل الـ type annotations من تعريف الـ Closure. في السطر الرابع، نزيل الأقواس المعقوفة، وهي اختيارية لأن جسم الـ Closure يحتوي على تعبير واحد فقط. كل هذه تعريفات صالحة ستنتج نفس السلوك عند استدعائها. تتطلب الأسطر add_one_v3 و add_one_v4 تقييم الـ Closures لتتمكن من الـ compile لأن الأنواع سيتم استنتاجها من استخدامها. هذا مشابه لـ let v = Vec::new(); التي تحتاج إما إلى type annotations أو قيم من نوع ما ليتم إدراجها في الـ Vec لكي يتمكن Rust من استنتاج النوع.
بالنسبة لتعريفات الـ Closure، سيستنتج الـ compiler نوعًا ملموسًا واحدًا لكل من الـ parameters الخاصة بها ولقيمة الإرجاع الخاصة بها. على سبيل المثال، تُظهر القائمة 13-3 تعريف Closure قصيرة تعيد فقط القيمة التي تتلقاها كـ parameter. هذه الـ Closure ليست مفيدة جدًا باستثناء أغراض هذا المثال. لاحظ أننا لم نضف أي type annotations إلى التعريف. نظرًا لعدم وجود type annotations، يمكننا استدعاء الـ Closure بأي نوع، وهو ما فعلناه هنا باستخدام String في المرة الأولى. إذا حاولنا بعد ذلك استدعاء example_closure بعدد صحيح (integer)، فسنحصل على خطأ.
fn main() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
}يعطينا الـ compiler هذا الخطأ:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = example_closure(5);
| --------------- ^ expected `String`, found integer
| |
| arguments to this function are incorrect
|
note: expected because the closure was earlier called with an argument of type `String`
--> src/main.rs:4:29
|
4 | let s = example_closure(String::from("hello"));
| --------------- ^^^^^^^^^^^^^^^^^^^^^ expected because this argument is of type `String`
| |
| in this closure call
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let example_closure = |x| x;
| ^
help: try using a conversion method
|
5 | let n = example_closure(5.to_string());
| ++++++++++++
For more information about this error, try `rustc --explain E0308`.
error: could not compile `closure-example` (bin "closure-example") due to 1 previous error
في المرة الأولى التي نستدعي فيها example_closure بقيمة String، يستنتج الـ compiler نوع x ونوع الإرجاع للـ Closure ليكون String. يتم بعد ذلك تثبيت هذه الأنواع في الـ Closure في example_closure، ونحصل على خطأ في النوع (type error) عندما نحاول بعد ذلك استخدام نوع مختلف مع نفس الـ Closure.
التقاط المراجع أو نقل الملكية (Capturing References or Moving Ownership)
يمكن للـ Closures التقاط قيم من بيئتها بثلاث طرق، تتوافق مباشرة مع الطرق الثلاث التي يمكن أن تأخذ بها الـ function parameter: الاقتراض غير القابل للتغيير (borrowing immutably)، الاقتراض القابل للتغيير (borrowing mutably)، وأخذ الملكية (taking ownership). ستقرر الـ Closure أيًا من هذه الطرق ستستخدم بناءً على ما يفعله جسم الـ function بالقيم الملتقطة.
في القائمة 13-4، نعرّف Closure تلتقط مرجعًا غير قابل للتغيير (immutable reference) إلى الـ vector المسمى list لأنها تحتاج فقط إلى immutable reference لطباعة القيمة.
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
let only_borrows = || println!("From closure: {list:?}");
println!("Before calling closure: {list:?}");
only_borrows();
println!("After calling closure: {list:?}");
}يوضح هذا المثال أيضًا أن الـ variable يمكن أن يرتبط بتعريف Closure، ويمكننا لاحقًا استدعاء الـ Closure باستخدام اسم الـ variable والأقواس كما لو كان اسم الـ variable اسم function.
نظرًا لأنه يمكن أن يكون لدينا مراجع متعددة غير قابلة للتغيير (immutable references) لـ list في نفس الوقت، يظل list متاحًا من الكود قبل تعريف الـ Closure، وبعد تعريف الـ Closure ولكن قبل استدعاء الـ Closure، وبعد استدعاء الـ Closure. هذا الكود يعمل ويطبع:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
Before calling closure: [1, 2, 3]
From closure: [1, 2, 3]
After calling closure: [1, 2, 3]
بعد ذلك، في القائمة 13-5، نغير جسم الـ Closure بحيث يضيف عنصرًا إلى الـ vector list. تلتقط الـ Closure الآن مرجعًا قابلاً للتغيير (mutable reference).
fn main() {
let mut list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
let mut borrows_mutably = || list.push(7);
borrows_mutably();
println!("After calling closure: {list:?}");
}هذا الكود يعمل ويطبع:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
After calling closure: [1, 2, 3, 7]
لاحظ أنه لم يعد هناك println! بين تعريف واستدعاء الـ Closure borrows_mutably: عندما يتم تعريف borrows_mutably، فإنه يلتقط mutable reference لـ list. لا نستخدم الـ Closure مرة أخرى بعد استدعاء الـ Closure، لذلك ينتهي الاقتراض القابل للتغيير (mutable borrow). بين تعريف الـ Closure واستدعاء الـ Closure، لا يُسمح بالاقتراض غير القابل للتغيير (immutable borrow) للطباعة، لأنه لا يُسمح بأي اقتراض آخر عندما يكون هناك mutable borrow. حاول إضافة println! هناك لترى رسالة الخطأ التي تحصل عليها!
إذا كنت تريد أن تجبر الـ Closure على أخذ ملكية (ownership) القيم التي تلتقطها من البيئة (environment) حتى لو لم يكن جسم الـ Closure يحتاج إلى الـ ownership بشكل صارم، يمكنك استخدام الكلمة المفتاحية move قبل قائمة الـ parameters.
هذه التقنية مفيدة في الغالب عند تمرير Closure إلى thread جديد لنقل البيانات بحيث يمتلكها الـ thread الجديد. سنناقش الـ threads ولماذا قد ترغب في استخدامها بالتفصيل في الفصل 16 عندما نتحدث عن التزامن (concurrency)، ولكن في الوقت الحالي، دعنا نستكشف بإيجاز إنشاء thread جديد باستخدام Closure تحتاج إلى الكلمة المفتاحية move. تُظهر القائمة 13-6 القائمة 13-4 معدلة لطباعة الـ vector في thread جديد بدلاً من الـ main thread.
use std::thread;
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
thread::spawn(move || println!("From thread: {list:?}"))
.join()
.unwrap();
}نقوم بإنشاء thread جديد، ونعطي الـ thread Closure لتشغيلها كوسيط. يطبع جسم الـ Closure الـ list. في القائمة 13-4، التقطت الـ Closure الـ list فقط باستخدام immutable reference لأن هذا هو أقل قدر من الوصول إلى list المطلوب لطباعته. في هذا المثال، على الرغم من أن جسم الـ Closure لا يزال يحتاج فقط إلى immutable reference، نحتاج إلى تحديد أنه يجب نقل list إلى الـ Closure عن طريق وضع الكلمة المفتاحية move في بداية تعريف الـ Closure. إذا أجرى الـ main thread المزيد من العمليات قبل استدعاء join على الـ thread الجديد، فقد ينتهي الـ thread الجديد قبل أن ينتهي باقي الـ main thread، أو قد ينتهي الـ main thread أولاً. إذا احتفظ الـ main thread بـ ownership لـ list ولكنه انتهى قبل الـ thread الجديد وأسقط list، فسيكون الـ immutable reference في الـ thread غير صالح. لذلك، يتطلب الـ compiler نقل list إلى الـ Closure المعطاة للـ thread الجديد بحيث يكون الـ reference صالحًا. حاول إزالة الكلمة المفتاحية move أو استخدام list في الـ main thread بعد تعريف الـ Closure لترى أخطاء الـ compiler التي تحصل عليها!
نقل القيم الملتقطة خارج Closures (Moving Captured Values Out of Closures)
بمجرد أن تلتقط الـ Closure مرجعًا أو تلتقط ownership لقيمة من البيئة التي تم تعريف الـ Closure فيها (وبالتالي تؤثر على ما يتم نقله إلى الـ Closure، إن وجد)، فإن الكود الموجود في جسم الـ Closure يحدد ما يحدث للمراجع أو القيم عند تقييم الـ Closure لاحقًا (وبالتالي يؤثر على ما يتم نقله خارج الـ Closure، إن وجد).
يمكن لجسم الـ Closure القيام بأي مما يلي: نقل قيمة ملتقطة خارج الـ Closure، تغيير القيمة الملتقطة (mutate the captured value)، لا نقل ولا تغيير للقيمة، أو عدم التقاط أي شيء من البيئة في البداية.
تؤثر الطريقة التي تلتقط بها الـ Closure القيم من البيئة وتتعامل معها على الـ traits التي تنفذها الـ Closure، والـ traits هي كيف يمكن للـ functions والـ structs تحديد أنواع الـ Closures التي يمكنها استخدامها. ستقوم الـ Closures تلقائيًا بتنفيذ واحد أو اثنين أو كل ثلاثة من الـ Fn traits هذه، بطريقة إضافية، اعتمادًا على كيفية تعامل جسم الـ Closure مع القيم:
FnOnceتنطبق على الـ Closures التي يمكن استدعاؤها مرة واحدة. تنفذ جميع الـ Closures هذا الـ trait على الأقل لأنه يمكن استدعاء جميع الـ Closures. الـ Closure التي تنقل القيم الملتقطة خارج جسمها ستنفذFnOnceفقط وليس أيًا من الـ Fn traits الأخرى لأنه لا يمكن استدعاؤها إلا مرة واحدة.FnMutتنطبق على الـ Closures التي لا تنقل القيم الملتقطة خارج جسمها ولكن قد تغير القيم الملتقطة. يمكن استدعاء هذه الـ Closures أكثر من مرة.Fnتنطبق على الـ Closures التي لا تنقل القيم الملتقطة خارج جسمها ولا تغير القيم الملتقطة، وكذلك الـ Closures التي لا تلتقط أي شيء من بيئتها. يمكن استدعاء هذه الـ Closures أكثر من مرة دون تغيير بيئتها، وهو أمر مهم في حالات مثل استدعاء Closure عدة مرات بالتزامن (concurrently).
دعنا نلقي نظرة على تعريف الدالة unwrap_or_else على Option<T> التي استخدمناها في القائمة 13-1:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}تذكر أن T هو النوع العام (generic type) الذي يمثل نوع القيمة في متغير Some من الـ Option. هذا النوع T هو أيضًا نوع الإرجاع لـ function unwrap_or_else: الكود الذي يستدعي unwrap_or_else على Option<String>، على سبيل المثال، سيحصل على String.
بعد ذلك، لاحظ أن function unwrap_or_else لديها الـ generic type parameter الإضافي F. النوع F هو نوع الـ parameter المسمى f، وهو الـ Closure الذي نوفره عند استدعاء unwrap_or_else.
الـ trait bound المحدد على الـ generic type F هو FnOnce() -> T، مما يعني أن F يجب أن تكون قادرة على الاستدعاء مرة واحدة، ولا تأخذ أي وسائط، وتعيد T. استخدام FnOnce في الـ trait bound يعبر عن القيد بأن unwrap_or_else لن تستدعي f أكثر من مرة. في جسم unwrap_or_else، يمكننا أن نرى أنه إذا كان الـ Option هو Some، فلن يتم استدعاء f. إذا كان الـ Option هو None، فسيتم استدعاء f مرة واحدة. نظرًا لأن جميع الـ Closures تنفذ FnOnce، فإن unwrap_or_else تقبل جميع الأنواع الثلاثة من الـ Closures وتكون مرنة قدر الإمكان.
ملاحظة: إذا كان ما نريد القيام به لا يتطلب التقاط قيمة من البيئة، يمكننا استخدام اسم function بدلاً من Closure حيث نحتاج إلى شيء ينفذ أحد الـ Fn traits. على سبيل المثال، على قيمة
Option<Vec<T>>، يمكننا استدعاءunwrap_or_else(Vec::new)للحصول على vector جديد وفارغ إذا كانت القيمةNone. يقوم الـ compiler تلقائيًا بتنفيذ أي من الـ Fn traits القابلة للتطبيق لتعريف function.
الآن دعنا نلقي نظرة على دالة المكتبة القياسية sort_by_key، المعرفة على slices، لنرى كيف تختلف عن unwrap_or_else ولماذا تستخدم sort_by_key الـ FnMut بدلاً من FnOnce لـ trait bound. تحصل الـ Closure على وسيط واحد في شكل مرجع (reference) إلى العنصر الحالي في الـ slice الذي يتم النظر فيه، وتعيد قيمة من نوع K يمكن ترتيبها. هذه الـ function مفيدة عندما تريد فرز slice حسب سمة معينة لكل عنصر. في القائمة 13-7، لدينا قائمة من مثيلات Rectangle، ونستخدم sort_by_key لترتيبها حسب سمة width من الأدنى إلى الأعلى.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
list.sort_by_key(|r| r.width);
println!("{list:#?}");
}هذا الكود يطبع:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/rectangles`
[
Rectangle {
width: 3,
height: 5,
},
Rectangle {
width: 7,
height: 12,
},
Rectangle {
width: 10,
height: 1,
},
]
السبب في تعريف sort_by_key لأخذ Closure من نوع FnMut هو أنها تستدعي الـ Closure عدة مرات: مرة واحدة لكل عنصر في الـ slice. الـ Closure |r| r.width لا تلتقط أو تغير أو تنقل أي شيء من بيئتها، لذلك فهي تفي بمتطلبات الـ trait bound.
في المقابل، تُظهر القائمة 13-8 مثالاً لـ Closure تنفذ فقط الـ trait FnOnce، لأنها تنقل قيمة خارج البيئة. لن يسمح لنا الـ compiler باستخدام هذه الـ Closure مع sort_by_key.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("closure called");
list.sort_by_key(|r| {
sort_operations.push(value);
r.width
});
println!("{list:#?}");
}هذه طريقة مصطنعة ومعقدة (لا تعمل) لمحاولة عد عدد المرات التي تستدعي فيها sort_by_key الـ Closure عند فرز list. يحاول هذا الكود القيام بهذا العد عن طريق دفع value—وهي String من بيئة الـ Closure—إلى الـ vector sort_operations. تلتقط الـ Closure الـ value ثم تنقل الـ value خارج الـ Closure عن طريق نقل ownership الـ value إلى الـ vector sort_operations. يمكن استدعاء هذه الـ Closure مرة واحدة؛ محاولة استدعائها مرة ثانية لن تنجح، لأن الـ value لن تكون موجودة في البيئة ليتم دفعها إلى sort_operations مرة أخرى! لذلك، تنفذ هذه الـ Closure الـ FnOnce فقط. عندما نحاول compile هذا الكود، نحصل على هذا الخطأ بأن الـ value لا يمكن نقلها خارج الـ Closure لأن الـ Closure يجب أن تنفذ FnMut:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
error[E0507]: cannot move out of `value`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let value = String::from("closure called");
| ----- ------------------------------ move occurs because `value` has type `String`, which does not implement the `Copy` trait
| |
| captured outer variable
16 |
17 | list.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | sort_operations.push(value);
| ^^^^^ `value` is moved here
|
help: consider cloning the value if the performance cost is acceptable
|
18 | sort_operations.push(value.clone());
| ++++++++
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rectangles` (bin "rectangles") due to 1 previous error
يشير الخطأ إلى السطر في جسم الـ Closure الذي ينقل الـ value خارج البيئة. لإصلاح ذلك، نحتاج إلى تغيير جسم الـ Closure بحيث لا ينقل القيم خارج البيئة. الاحتفاظ بعداد في البيئة وزيادة قيمته في جسم الـ Closure هو طريقة أكثر وضوحًا لعد عدد المرات التي يتم فيها استدعاء الـ Closure. الـ Closure في القائمة 13-9 تعمل مع sort_by_key لأنها تلتقط فقط mutable reference لعداد num_sort_operations وبالتالي يمكن استدعاؤها أكثر من مرة.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut num_sort_operations = 0;
list.sort_by_key(|r| {
num_sort_operations += 1;
r.width
});
println!("{list:#?}, sorted in {num_sort_operations} operations");
}الـ Fn traits مهمة عند تعريف أو استخدام functions أو أنواع تستخدم Closures. في القسم التالي، سنناقش iterators. تتطلب العديد من دوال الـ iterator وسائط Closures، لذا ضع تفاصيل الـ Closure هذه في الاعتبار بينما نواصل!
معالجة سلسلة من العناصر باستخدام المكررات (Iterators)
معالجة سلسلة من العناصر باستخدام المكررات (Processing a Series of Items with Iterators)
يسمح لك نمط المكرر (iterator pattern) بأداء بعض المهام على تسلسل من العناصر بالدور. المكرر (iterator) مسؤول عن منطق التكرار (iterating) عبر كل عنصر وتحديد متى ينتهي التسلسل. عندما تستخدم iterators، ليس عليك إعادة تنفيذ ذلك المنطق بنفسك.
في Rust، تكون الـ iterators كسولة (lazy)، مما يعني أنه ليس لها أي تأثير حتى تستدعي طرقاً (methods) تستهلك (consume) الـ iterator لاستخدامه بالكامل. على سبيل المثال، الكود في القائمة 13-10 ينشئ iterator عبر العناصر الموجودة في المتجه (vector) v1 عن طريق استدعاء طريقة iter المعرفة على Vec<T>. هذا الكود بحد ذاته لا يفعل أي شيء مفيد.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
}يتم تخزين الـ iterator في المتغير v1_iter. بمجرد إنشاء iterator، يمكننا استخدامه بطرق متنوعة. في القائمة 3-5، قمنا بالتكرار عبر مصفوفة (array) باستخدام حلقة for لتنفيذ بعض الكود على كل عنصر من عناصرها. خلف الكواليس، أدى هذا ضمناً إلى إنشاء iterator ثم استهلاكه، لكننا أغفلنا كيفية عمل ذلك بالضبط حتى الآن.
في المثال في القائمة 13-11، نفصل إنشاء الـ iterator عن استخدامه في حلقة for. عندما يتم استدعاء حلقة for باستخدام الـ iterator في v1_iter ، يتم استخدام كل عنصر في الـ iterator في دورة واحدة من الحلقة، والتي تطبع كل قيمة.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
for val in v1_iter {
println!("Got: {val}");
}
}في اللغات التي لا توفر iterators في مكتباتها القياسية، من المحتمل أن تكتب هذه الوظيفة نفسها عن طريق بدء متغير عند الفهرس (index) 0، واستخدام ذلك المتغير للفهرسة في الـ vector للحصول على قيمة، وزيادة قيمة المتغير في حلقة حتى يصل إلى العدد الإجمالي للعناصر في الـ vector.
تتعامل الـ iterators مع كل هذا المنطق نيابة عنك، مما يقلل من الكود المتكرر الذي قد تخطئ فيه. تمنحك الـ iterators مرونة أكبر لاستخدام نفس المنطق مع أنواع مختلفة من التسلسلات، وليس فقط هياكل البيانات التي يمكنك الفهرسة فيها، مثل vectors. دعونا نفحص كيف تفعل الـ iterators ذلك.
سمة المكرر وطريقة التالي (The Iterator Trait and the next Method)
تنفذ جميع الـ iterators سمة (trait) تسمى Iterator معرفة في المكتبة القياسية. يبدو تعريف الـ trait هكذا:
#![allow(unused)]
fn main() {
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// methods with default implementations elided
}
}لاحظ أن هذا التعريف يستخدم بعض الصيغ (syntax) الجديدة: type Item و Self::Item ، والتي تعرف نوعاً مرتبطاً (associated type) بهذا الـ trait. سنتحدث عن associated types بعمق في الفصل العشرين. في الوقت الحالي، كل ما تحتاج لمعرفته هو أن هذا الكود يقول إن تنفيذ Iterator trait يتطلب منك أيضاً تعريف نوع Item ، ويتم استخدام نوع Item هذا في نوع الإرجاع لطريقة next. بعبارة أخرى، سيكون نوع Item هو النوع الذي يتم إرجاعه من الـ iterator.
تتطلب Iterator trait من المنفذين تعريف طريقة واحدة فقط: طريقة next ، والتي تعيد عنصراً واحداً من الـ iterator في كل مرة، مغلفاً في Some ، وعندما ينتهي التكرار، تعيد None.
يمكننا استدعاء طريقة next على الـ iterators مباشرة؛ توضح القائمة 13-12 القيم التي يتم إرجاعها من الاستدعاءات المتكررة لـ next على الـ iterator المنشأ من الـ vector.
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}لاحظ أننا احتجنا إلى جعل v1_iter قابلاً للتغيير (mutable): استدعاء طريقة next على iterator يغير الحالة الداخلية التي يستخدمها الـ iterator لتتبع مكانه في التسلسل. بعبارة أخرى، هذا الكود يستهلك (consumes)، أو يستنفد، الـ iterator. كل استدعاء لـ next يأكل عنصراً من الـ iterator. لم نكن بحاجة إلى جعل v1_iter mutable عندما استخدمنا حلقة for ، لأن الحلقة أخذت ملكية (ownership) v1_iter وجعلته mutable خلف الكواليس.
لاحظ أيضاً أن القيم التي نحصل عليها من الاستدعاءات لـ next هي مراجع غير قابلة للتغيير (immutable references) للقيم الموجودة في الـ vector. تنتج طريقة iter مكرراً عبر immutable references. إذا أردنا إنشاء iterator يأخذ ownership لـ v1 ويعيد قيم مملوكة، يمكننا استدعاء into_iter بدلاً من iter. وبالمثل، إذا أردنا التكرار عبر مراجع قابلة للتغيير (mutable references)، يمكننا استدعاء iter_mut بدلاً من iter.
الطرق التي تستهلك المكرر (Methods That Consume the Iterator)
تمتلك Iterator trait عدداً من الطرق المختلفة مع تنفيذات افتراضية توفرها المكتبة القياسية؛ يمكنك التعرف على هذه الطرق من خلال النظر في توثيق API للمكتبة القياسية لـ Iterator trait. تستدعي بعض هذه الطرق طريقة next في تعريفها، وهذا هو السبب في أنك مطالب بتنفيذ طريقة next عند تنفيذ Iterator trait.
تسمى الطرق التي تستدعي next بـ محولات الاستهلاك (consuming adapters) لأن استدعاءها يستنفد الـ iterator. أحد الأمثلة هو طريقة sum ، التي تأخذ ownership للـ iterator وتكرر عبر العناصر من خلال استدعاء next بشكل متكرر، وبالتالي تستهلك الـ iterator. وبينما تكرر، تضيف كل عنصر إلى إجمالي جاري وتعيد الإجمالي عند اكتمال التكرار. تحتوي القائمة 13-13 على اختبار يوضح استخدام طريقة sum.
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}لا يُسمح لنا باستخدام v1_iter بعد استدعاء sum ، لأن sum تأخذ ownership للـ iterator الذي نستدعيها عليه.
الطرق التي تنتج مكررات أخرى (Methods That Produce Other Iterators)
محولات المكرر (Iterator adapters) هي طرق معرفة على Iterator trait لا تستهلك الـ iterator. بدلاً من ذلك، فإنها تنتج iterators مختلفة عن طريق تغيير بعض جوانب الـ iterator الأصلي.
توضح القائمة 13-14 مثالاً على استدعاء طريقة محول المكرر map ، والتي تأخذ إغلاقاً (closure) لاستدعائه على كل عنصر أثناء التكرار عبر العناصر. تعيد طريقة map مكرراً جديداً ينتج العناصر المعدلة. الـ closure هنا ينشئ iterator جديداً يتم فيه زيادة كل عنصر من الـ vector بمقدار 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
v1.iter().map(|x| x + 1);
}ومع ذلك، ينتج هذا الكود تحذيراً:
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
4 | let _ = v1.iter().map(|x| x + 1);
| +++++++
warning: `iterators` (bin "iterators") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
الكود في القائمة 13-14 لا يفعل أي شيء؛ الـ closure الذي حددناه لا يتم استدعاؤه أبداً. يذكرنا التحذير بالسبب: iterator adapters كسولة، ونحن بحاجة إلى استهلاك الـ iterator هنا.
لإصلاح هذا التحذير واستهلاك الـ iterator، سنستخدم طريقة collect ، التي استخدمناها مع env::args في القائمة 12-1. تستهلك هذه الطريقة الـ iterator وتجمع القيم الناتجة في نوع بيانات تجميعي (collection).
في القائمة 13-15، نجمع نتائج التكرار عبر الـ iterator الذي يتم إرجاعه من الاستدعاء لـ map في vector. سينتهي هذا الـ vector باحتواء كل عنصر من الـ vector الأصلي، مزيداً بمقدار 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
let v2: Vec<_> = v1.iter().map(|x| x + 1).collect();
assert_eq!(v2, vec![2, 3, 4]);
}لأن map تأخذ closure، يمكننا تحديد أي عملية نريد القيام بها على كل عنصر. هذا مثال رائع على كيفية سماح closures لك بتخصيص بعض السلوك مع إعادة استخدام سلوك التكرار الذي توفره Iterator trait.
يمكنك ربط استدعاءات متعددة لـ iterator adapters لأداء إجراءات معقدة بطريقة مقروءة. ولكن لأن جميع الـ iterators كسولة، يجب عليك استدعاء إحدى طرق consuming adapter للحصول على نتائج من الاستدعاءات لـ iterator adapters.
الإغلاقات التي تلتقط بيئتها (Closures That Capture Their Environment)
تأخذ العديد من iterator adapters إغلاقات كـ arguments، وعادة ما تكون الـ closures التي سنحددها كـ arguments لـ iterator adapters هي closures تلتقط بيئتها.
لهذا المثال، سنستخدم طريقة filter التي تأخذ closure. يحصل الـ closure على عنصر من الـ iterator ويعيد bool. إذا أعاد الـ closure القيمة true ، فسيتم تضمين القيمة في التكرار الناتج عن filter. إذا أعاد الـ closure القيمة false ، فلن يتم تضمين القيمة.
في القائمة 13-16، نستخدم filter مع closure يلتقط المتغير shoe_size من بيئته للتكرار عبر مجموعة من مثيلات (instances) هيكل Shoe. سيعيد فقط الأحذية التي هي بالحجم المحدد.
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filters_by_size() {
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"),
},
Shoe {
size: 13,
style: String::from("sandal"),
},
Shoe {
size: 10,
style: String::from("boot"),
},
];
let in_my_size = shoes_in_size(shoes, 10);
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}تأخذ دالة shoes_in_size ملكية vector من الأحذية وحجم حذاء كـ parameters. وتعيد vector يحتوي فقط على الأحذية بالحجم المحدد.
في جسم shoes_in_size ، نستدعي into_iter لإنشاء iterator يأخذ ownership للـ vector. ثم، نستدعي filter لتكييف ذلك الـ iterator إلى iterator جديد يحتوي فقط على العناصر التي يعيد الـ closure لها القيمة true.
يلتقط الـ closure الـ parameter shoe_size من البيئة ويقارن القيمة بحجم كل حذاء، محتفظاً فقط بالأحذية بالحجم المحدد. أخيراً، يؤدي استدعاء collect إلى جمع القيم التي أرجعها الـ iterator المكيف في vector يتم إرجاعه بواسطة الدالة.
يظهر الاختبار أنه عندما نستدعي shoes_in_size ، نحصل فقط على الأحذية التي لها نفس الحجم مثل القيمة التي حددناها.
تحسين مشروع الإدخال والإخراج الخاص بنا
تحسين مشروع الإدخال والإخراج الخاص بنا (Improving Our I/O Project)
باستخدام هذه المعرفة الجديدة حول المكررات (Iterators)، يمكننا تحسين مشروع الإدخال والإخراج (I/O) في الفصل 12 باستخدام Iterators لجعل أجزاء الكود (Code) أكثر وضوحاً وإيجازاً. دعنا نلقي نظرة على كيفية قيام Iterators بتحسين تنفيذنا لدالة (Function) Config::build ودالة search.
إزالة clone باستخدام مكرر (Iterator)
في القائمة (Listing) 12-6، أضفنا Code يأخذ شريحة (Slice) من قيم String وأنشأ مثيلاً (Instance) من هيكل (Struct) Config عن طريق الفهرسة (Indexing) في Slice واستنساخ (Cloning) القيم، مما يسمح لـ Struct Config بامتلاك تلك القيم. في Listing 13-17، أعدنا إنتاج تنفيذ Function Config::build كما كان في Listing 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}في ذلك الوقت، قلنا ألا تقلق بشأن استدعاءات clone غير الفعالة لأننا سنزيلها في المستقبل. حسناً، لقد حان ذلك الوقت الآن!
احتجنا إلى clone هنا لأن لدينا Slice بعناصر String في الوسيط (Parameter) args ، لكن Function build لا تمتلك args. لإعادة ملكية (Ownership) Instance Config ، كان علينا استنساخ القيم من حقول (Fields) query و file_path الخاصة بـ Config بحيث يمكن لـ Instance Config امتلاك قيمه الخاصة.
مع معرفتنا الجديدة حول Iterators، يمكننا تغيير Function build لتأخذ ملكية Iterator كـ Argument بدلاً من استعارة (Borrowing) Slice. سنستخدم وظائف Iterator بدلاً من Code الذي يتحقق من طول Slice ويقوم بـ Indexing في مواقع محددة. سيؤدي هذا إلى توضيح ما تفعله Function Config::build لأن Iterator سيصل إلى القيم.
بمجرد أن تأخذ Config::build ملكية Iterator وتتوقف عن استخدام عمليات Indexing التي تقوم بـ Borrow، يمكننا نقل (Move) قيم String من Iterator إلى Config بدلاً من استدعاء clone وإجراء تخصيص (Allocation) جديد.
استخدام المكرر المُعاد مباشرة
افتح ملف src/main.rs الخاص بمشروع I/O، والذي يجب أن يبدو كالتالي:
اسم الملف: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}سنقوم أولاً بتغيير بداية Function main التي كانت لدينا في Listing 12-24 إلى Code الموجود في Listing 13-18، والذي يستخدم هذه المرة Iterator. لن يتم تحويل هذا برمجياً (Compile) حتى نقوم بتحديث Config::build أيضاً.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}تعيد دالة env::args مكرراً (Iterator)! وبدلاً من تجميع قيم Iterator في متجه (Vector) ثم تمرير Slice إلى Config::build ، فإننا الآن نمرر ملكية Iterator المُعاد من env::args إلى Config::build مباشرة.
بعد ذلك، نحتاج إلى تحديث تعريف Config::build. دعنا نغير توقيع (Signature) Config::build ليبدو مثل Listing 13-19. هذا لا يزال لن يتم Compile ، لأننا بحاجة إلى تحديث جسم الدالة (Function Body).
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}توضح وثائق المكتبة القياسية (Standard Library Documentation) لدالة env::args أن نوع Iterator الذي تعيده هو std::env::Args ، وهذا النوع ينفذ سمة (Trait) الـ Iterator ويعيد قيم String.
لقد قمنا بتحديث Signature لـ Function Config::build بحيث يكون لـ Parameter args نوع عام (Generic Type) مع قيود السمة (Trait Bounds) impl Iterator<Item = String> بدلاً من &[String]. هذا الاستخدام لصيغة impl Trait التي ناقشناها في قسم “استخدام السمات كـ Parameters” من الفصل 10 يعني أن args يمكن أن يكون أي نوع ينفذ Trait Iterator ويعيد عناصر String.
لأننا نأخذ ملكية args وسنقوم بتعديل (Mutating) args عن طريق التكرار عليه، يمكننا إضافة الكلمة المفتاحية mut في مواصفات Parameter args لجعله قابلاً للتغير (Mutable).
استخدام طرق سمة Iterator
بعد ذلك، سنقوم بإصلاح Function Body لـ Config::build. نظراً لأن args ينفذ Trait Iterator ، فإننا نعلم أنه يمكننا استدعاء طريقة (Method) next عليه! يقوم Listing 13-20 بتحديث Code من Listing 12-23 لاستخدام Method next.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}تذكر أن القيمة الأولى في القيمة المعادة من env::args هي اسم البرنامج. نريد تجاهل ذلك والوصول إلى القيمة التالية، لذا نستدعي أولاً next ولا نفعل شيئاً بالقيمة المعادة. بعد ذلك، نستدعي next للحصول على القيمة التي نريد وضعها في Field query الخاص بـ Config. إذا أعاد next القيمة Some ، فإننا نستخدم match لاستخراج القيمة. وإذا أعاد None ، فهذا يعني أنه لم يتم توفير وسائط كافية، ونقوم بالإرجاع مبكراً مع قيمة Err. نفعل الشيء نفسه لقيمة file_path.
توضيح الكود باستخدام محولات المكرر (Iterator Adapters)
يمكننا أيضاً الاستفادة من Iterators في Function search في مشروع I/O الخاص بنا، والتي أُعيد إنتاجها هنا في Listing 13-21 كما كانت في Listing 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}يمكننا كتابة هذا Code بطريقة أكثر إيجازاً باستخدام طرق محولات المكرر (Iterator Adapter Methods). القيام بذلك يجنبنا أيضاً وجود Vector وسيط قابل للتغير لـ results. يفضل أسلوب البرمجة الوظيفية (Functional Programming) تقليل كمية الحالة القابلة للتغير (Mutable State) لجعل Code أكثر وضوحاً. قد تتيح إزالة Mutable State تحسيناً مستقبلياً لجعل البحث يحدث بالتوازي لأننا لن نضطر إلى إدارة الوصول المتزامن (Concurrent Access) إلى Vector الـ results. يوضح Listing 13-22 هذا التغيير.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}تذكر أن الغرض من Function search هو إرجاع جميع الأسطر في contents التي تحتوي على query. على غرار مثال الـ filter في Listing 13-16، يستخدم هذا Code محول filter للاحتفاظ فقط بالأسطر التي تعيد لها line.contains(query) القيمة true. ثم نقوم بتجميع (Collect) الأسطر المتطابقة في Vector آخر باستخدام collect. أبسط بكثير! لا تتردد في إجراء نفس التغيير لاستخدام طرق Iterator في Function search_case_insensitive أيضاً.
لمزيد من التحسين، قم بإرجاع Iterator من Function search عن طريق إزالة استدعاء collect وتغيير نوع الإرجاع إلى impl Iterator<Item = &'a str> بحيث تصبح Function عبارة عن Iterator Adapter. لاحظ أنك ستحتاج أيضاً إلى تحديث الاختبارات! ابحث في ملف كبير باستخدام أداة minigrep الخاصة بك قبل وبعد إجراء هذا التغيير لملاحظة الفرق في السلوك. قبل هذا التغيير، لن يطبع البرنامج أي نتائج حتى يجمع كل النتائج، ولكن بعد التغيير، ستُطبع النتائج فور العثور على كل سطر مطابق لأن حلقة (Loop) الـ for في Function run قادرة على الاستفادة من الكسل (Laziness) الخاص بـ Iterator.
الاختيار بين الحلقات أو المكررات (Loops or Iterators)
السؤال المنطقي التالي هو أي أسلوب يجب أن تختاره في Code الخاص بك ولماذا: التنفيذ الأصلي في Listing 13-21 أو الإصدار الذي يستخدم Iterators في Listing 13-22 (بافتراض أننا نجمع كل النتائج قبل إرجاعها بدلاً من إرجاع Iterator). يفضل معظم مبرمجي Rust استخدام أسلوب Iterator. من الصعب قليلاً التعود عليه في البداية، ولكن بمجرد أن تعتاد على مختلف Iterator Adapters وما تفعله، يمكن أن تكون Iterators أسهل في الفهم. بدلاً من العبث بأجزاء Loops المختلفة وبناء Vectors جديدة، يركز Code على الهدف عالي المستوى لـ Loop. هذا يجرد بعض Code الشائع بحيث يسهل رؤية المفاهيم الفريدة لهذا Code، مثل شرط التصفية (Filtering Condition) الذي يجب أن يمر به كل عنصر في Iterator.
ولكن هل التنفيذان متكافئان حقاً؟ قد يكون الافتراض البديهي هو أن Loop منخفض المستوى سيكون أسرع. دعنا نتحدث عن الأداء (Performance).
الأداء في الحلقات مقابل المكررات
الأداء في الحلقات مقابل المكررات (Performance in Loops vs. Iterators)
لتحديد ما إذا كان يجب استخدام حلقات (loops) أو مكررات (iterators)، عليك معرفة أي تنفيذ هو الأسرع: نسخة دالة search التي تستخدم حلقة for صريحة، أم النسخة التي تستخدم iterators.
لقد أجرينا اختبار أداء (benchmark) عن طريق تحميل المحتوى الكامل لرواية The Adventures of Sherlock Holmes للمؤلف Sir Arthur Conan Doyle في سلسلة نصية (String) والبحث عن كلمة the في المحتوى. إليك نتائج الـ benchmark لنسخة search التي تستخدم حلقة for والنسخة التي تستخدم iterators:
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
كلا التنفيذين لهما أداء متقارب! لن نشرح كود الـ benchmark هنا لأن الهدف ليس إثبات أن النسختين متكافئتان، بل الحصول على فكرة عامة عن كيفية مقارنة هذين التنفيذين من حيث الأداء.
للحصول على benchmark أكثر شمولاً، يجب عليك التحقق باستخدام نصوص متنوعة وبأحجام مختلفة كـ contents ، وكلمات مختلفة وبأطوال مختلفة كـ query ، وجميع أنواع الاختلافات الأخرى. النقطة المهمة هي: المكررات، على الرغم من كونها تجريد عالي المستوى (high-level abstraction)، يتم تجميعها (compiled) إلى نفس الكود تقريباً كما لو كنت قد كتبت الكود منخفض المستوى بنفسك. المكررات هي واحدة من التجريدات صفرية التكلفة (zero-cost abstractions) في Rust، ونعني بذلك أن استخدام التجريد لا يفرض أي عبء وقت تشغيل (runtime overhead) إضافي. هذا يشبه الطريقة التي يعرّف بها Bjarne Stroustrup، المصمم والمنفذ الأصلي للغة ++C، مفهوم “صفر عبء” (zero-overhead) في عرضه التقديمي ETAPS لعام 2012 بعنوان “أسس ++C”:
بشكل عام، تلتزم تنفيذا ++C بمبدأ صفر عبء: ما لا تستخدمه، لا تدفع ثمنه. وعلاوة على ذلك: ما تستخدمه، لا يمكنك كتابته يدوياً بشكل أفضل.
في كثير من الحالات، يتم تجميع كود Rust الذي يستخدم iterators إلى نفس لغة التجميع (assembly) التي قد تكتبها يدوياً. يتم تطبيق تحسينات (optimizations) مثل فك الحلقات (loop unrolling) وإلغاء فحص الحدود (bounds checking) عند الوصول إلى المصفوفات، مما يجعل الكود الناتج فعالاً للغاية. الآن بعد أن عرفت هذا، يمكنك استخدام iterators والإغلاقات (closures) دون خوف! فهي تجعل الكود يبدو وكأنه من مستوى أعلى ولكنها لا تفرض عقوبة على أداء وقت التشغيل للقيام بذلك.
ملخص (Summary)
الإغلاقات والمكررات هي ميزات في Rust مستوحاة من أفكار لغات البرمجة الوظيفية (functional programming). فهي تساهم في قدرة Rust على التعبير بوضوح عن الأفكار عالية المستوى بأداء منخفض المستوى. إن تنفيذ closures و iterators مصمم بحيث لا يتأثر أداء وقت التشغيل. هذا جزء من هدف Rust للسعي لتوفير zero-cost abstractions.
الآن بعد أن قمنا بتحسين القدرة التعبيرية لمشروع الإدخال والإخراج الخاص بنا، دعونا نلقي نظرة على بعض الميزات الإضافية لـ cargo التي ستساعدنا في مشاركة المشروع مع العالم.
المزيد حول Cargo و Crates.io
حتى الآن، استخدمنا فقط الميزات الأساسية لـ Cargo لبناء الكود وتشغيله واختباره، ولكن يمكنه القيام بأكثر من ذلك بكثير. في هذا الفصل، سنناقش بعض ميزاته الأخرى الأكثر تقدماً لنوضح لك كيفية القيام بما يلي:
- تخصيص عملية البناء (build) الخاصة بك من خلال ملفات تعريف الإصدار (release profiles).
- نشر المكتبات (libraries) على crates.io.
- تنظيم المشاريع الكبيرة باستخدام مساحات العمل (workspaces).
- تثبيت الملفات الثنائية (binaries) من crates.io.
- توسيع Cargo باستخدام أوامر مخصصة (custom commands).
يمكن لـ Cargo القيام بأكثر من الوظائف التي نغطيها في هذا الفصل، لذا للحصول على شرح كامل لجميع ميزاته، راجع توثيقاته.
تخصيص البناء باستخدام ملفات تعريف الإصدار (Release Profiles)
تخصيص عمليات البناء باستخدام ملفات تعريف الإصدار (Release Profiles)
في لغة Rust، تعتبر ملفات تعريف الإصدار (Release Profiles) ملفات تعريف محددة مسبقاً وقابلة للتخصيص مع إعدادات (Configurations) مختلفة تسمح للمبرمج بمزيد من التحكم في الخيارات المتنوعة لترجمة الشفرة البرمجية (Compiling Code). يتم تكوين كل ملف تعريف (Profile) بشكل مستقل عن الملفات الأخرى.
تمتلك أداة Cargo ملفي تعريف رئيسيين: ملف التعريف dev الذي تستخدمه Cargo عند تشغيل cargo build وملف التعريف release الذي تستخدمه Cargo عند تشغيل cargo build --release. يتم تعريف Profile dev بإعدادات افتراضية جيدة للتطوير (Development)، بينما يمتلك Profile release إعدادات افتراضية جيدة لإصدارات البناء (Release Builds).
قد تكون أسماء Profiles هذه مألوفة لك من مخرجات عمليات البناء (Builds) الخاصة بك:
$ cargo build
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
$ cargo build --release
Finished `release` profile [optimized] target(s) in 0.32s
إن dev و release هما ملفات تعريف مختلفة يستخدمها المترجم (Compiler).
تمتلك Cargo إعدادات افتراضية لكل من Profiles التي يتم تطبيقها عندما لا تكون قد أضفت صراحة أي أقسام [profile.*] في ملف Cargo.toml الخاص بالمشروع. من خلال إضافة أقسام [profile.*] لأي Profile تريد تخصيصه، فإنك تقوم بتجاوز (Override) أي مجموعة فرعية من الإعدادات الافتراضية. على سبيل المثال، إليك القيم الافتراضية لإعداد opt-level لملفي التعريف dev و release:
اسم الملف: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
يتحكم إعداد opt-level في عدد التحسينات (Optimizations) التي ستطبقها Rust على Code الخاص بك، بنطاق يتراوح من 0 إلى 3. يؤدي تطبيق المزيد من Optimizations إلى إطالة وقت الترجمة (Compiling Time)، لذا إذا كنت في مرحلة Development وتقوم بترجمة Code الخاص بك غالباً، فستحتاج إلى عدد أقل من Optimizations للترجمة بشكل أسرع حتى لو كان Code الناتج يعمل بشكل أبطأ. لذا فإن opt-level الافتراضي لـ dev هو 0. عندما تكون مستعداً لإصدار Code الخاص بك، فمن الأفضل قضاء وقت أطول في الترجمة. ستقوم بالترجمة في وضع الإصدار (Release Mode) مرة واحدة فقط، ولكنك ستشغل البرنامج المترجم عدة مرات، لذا فإن Release Mode يقايض وقت الترجمة الأطول بشفرة برمجية تعمل بشكل أسرع. وهذا هو السبب في أن opt-level الافتراضي لـ Profile release هو 3.
يمكنك تجاوز إعداد افتراضي عن طريق إضافة قيمة مختلفة له في Cargo.toml. على سبيل المثال، إذا أردنا استخدام مستوى التحسين 1 في Profile التطوير، يمكننا إضافة هذين السطرين إلى ملف Cargo.toml الخاص بمشروعنا:
اسم الملف: Cargo.toml
[profile.dev]
opt-level = 1
يتجاوز هذا Code الإعداد الافتراضي البالغ 0. الآن عند تشغيل cargo build ستستخدم Cargo الإعدادات الافتراضية لـ Profile dev بالإضافة إلى تخصيصنا لـ opt-level. ولأننا ضبطنا opt-level على 1 فستطبق Cargo المزيد من Optimizations أكثر من الافتراضي، ولكن ليس بقدر ما هو موجود في Release Build.
للحصول على القائمة الكاملة لخيارات التكوين والإعدادات الافتراضية لكل Profile، راجع وثائق Cargo.
نشر كرات (Crate) في Crates.io
نشر صندوق إلى Crates.io (Publishing a Crate to Crates.io)
لقد استخدمنا حزماً من crates.io كـ (تبعيات) dependencies لمشروعنا، ولكن يمكنك أيضاً مشاركة الكود الخاص بك مع أشخاص آخرين عن طريق نشر حزمك الخاصة. يقوم (سجل الصناديق) crate registry في crates.io بتوزيع الكود المصدري لحزمك، لذا فهو يستضيف بشكل أساسي الكود مفتوح المصدر.
تمتلك Rust و Cargo ميزات تجعل من السهل على الأشخاص العثور على حزمتك المنشورة واستخدامها. سنتحدث عن بعض هذه الميزات لاحقاً ثم نشرح كيفية نشر الحزمة.
كتابة تعليقات توثيقية مفيدة (Making Useful Documentation Comments)
سيساعد توثيق حزمك بدقة المستخدمين الآخرين على معرفة كيفية ووقت استخدامها، لذا يستحق الأمر استثمار الوقت في كتابة التوثيق. في الفصل الثالث، ناقشنا كيفية التعليق على كود Rust باستخدام شرطتين مائلتين، //. تمتلك Rust أيضاً نوعاً خاصاً من التعليقات للتوثيق، يُعرف بـ (تعليق التوثيق) documentation comment ، والذي سيقوم بإنشاء توثيق HTML. يعرض HTML محتويات تعليقات التوثيق لعناصر (واجهة برمجة التطبيقات العامة) public API المخصصة للمبرمجين المهتمين بمعرفة كيفية استخدام (الصندوق) crate الخاص بك بدلاً من كيفية تنفيذه.
تستخدم تعليقات التوثيق ثلاث شرطات مائلة، /// ، بدلاً من اثنتين وتدعم تنسيق Markdown لتنسيق النص. ضع تعليقات التوثيق مباشرة قبل العنصر الذي تقوم بتوثيقه. تعرض القائمة 14-1 تعليقات التوثيق لدالة add_one في صندوق يسمى my_crate.
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}هنا، نقدم وصفاً لما تفعله دالة add_one ، ونبدأ قسماً بالعنوان Examples ، ثم نقدم كوداً يوضح كيفية استخدام دالة add_one. يمكننا إنشاء توثيق HTML من تعليق التوثيق هذا عن طريق تشغيل cargo doc. يقوم هذا الأمر بتشغيل أداة rustdoc الموزعة مع Rust ويضع توثيق HTML المنشأ في دليل target/doc.
للراحة، سيؤدي تشغيل cargo doc --open إلى بناء HTML لتوثيق الصندوق الحالي (بالإضافة إلى توثيق جميع تبعيات الصندوق الخاص بك) وفتح النتيجة في متصفح الويب. انتقل إلى دالة add_one وسترى كيف يتم عرض النص في تعليقات التوثيق، كما هو موضح في الشكل 14-1.
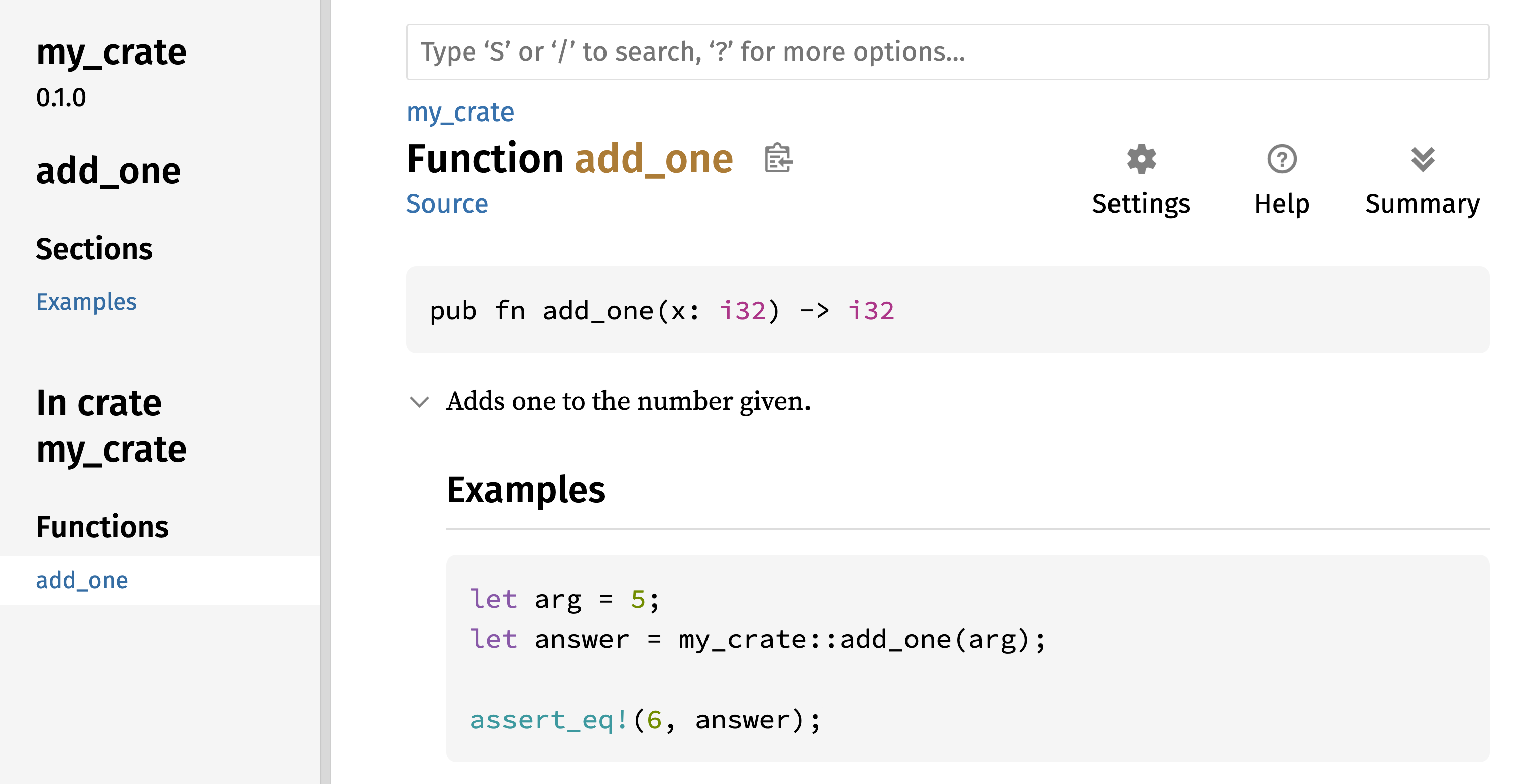
الشكل 14-1: توثيق HTML لدالة add_one
الأقسام شائعة الاستخدام (Commonly Used Sections)
استخدمنا عنوان Markdown باسم # Examples في القائمة 14-1 لإنشاء قسم في HTML بعنوان “Examples”. إليك بعض الأقسام الأخرى التي يشيع استخدامها من قبل مؤلفي الصناديق في توثيقاتهم:
- Panics: هذه هي السيناريوهات التي يمكن أن تؤدي فيها الدالة التي يتم توثيقها إلى (ذعر)
panic. يجب على مستدعي الدالة الذين لا يريدون لبرامجهم أن تصاب بالذعر التأكد من عدم استدعاء الدالة في هذه الحالات. - Errors: إذا كانت الدالة تعيد
Result، فإن وصف أنواع الأخطاء التي قد تحدث والظروف التي قد تتسبب في إعادة تلك الأخطاء يمكن أن يكون مفيداً للمستدعين حتى يتمكنوا من كتابة كود للتعامل مع أنواع الأخطاء المختلفة بطرق مختلفة. - Safety: إذا كانت الدالة (غير آمنة)
unsafeللاستدعاء (نناقش عدم الأمان في الفصل 20)، فيجب أن يكون هناك قسم يشرح سبب كون الدالة غير آمنة ويغطي (الثوابت)invariantsالتي تتوقع الدالة من المستدعين الحفاظ عليها.
لا تحتاج معظم تعليقات التوثيق إلى كل هذه الأقسام، ولكن هذه قائمة مرجعية جيدة لتذكيرك بجوانب الكود التي سيهتم المستخدمون بمعرفتها.
تعليقات التوثيق كاختبارات (Documentation Comments as Tests)
يمكن أن يساعد إضافة كتل كود برمجية كمثال في تعليقات التوثيق الخاصة بك في توضيح كيفية استخدام مكتبتك وله ميزة إضافية: سيؤدي تشغيل cargo test إلى تشغيل أمثلة الكود في توثيقك كاختبارات! لا شيء أفضل من التوثيق مع الأمثلة. ولكن لا شيء أسوأ من الأمثلة التي لا تعمل لأن الكود قد تغير منذ كتابة التوثيق. إذا قمنا بتشغيل cargo test مع توثيق دالة add_one من القائمة 14-1، فسنرى قسماً في نتائج الاختبار يبدو كالتالي:
Doc-tests my_crate
running 1 test
test src/lib.rs - add_one (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
الآن، إذا قمنا بتغيير الدالة أو المثال بحيث يؤدي assert_eq! في المثال إلى panic ، وقمنا بتشغيل cargo test مرة أخرى، فسنرى أن (اختبارات التوثيق) doc tests تكتشف أن المثال والكود غير متوافقين مع بعضهما البعض!
تعليقات العناصر المحتواة (Contained Item Comments)
يضيف نمط تعليق التوثيق //! توثيقاً للعنصر الذي يحتوي على التعليقات بدلاً من العناصر التي تلي التعليقات. نستخدم عادةً تعليقات التوثيق هذه داخل ملف جذر الصندوق (src/lib.rs حسب العرف) أو داخل (وحدة) module لتوثيق الصندوق أو الوحدة ككل.
على سبيل المثال، لإضافة توثيق يصف الغرض من الصندوق my_crate الذي يحتوي على دالة add_one ، نضيف تعليقات توثيق تبدأ بـ //! إلى بداية ملف src/lib.rs ، كما هو موضح في القائمة 14-2.
//! # My Crate
//!
//! `my_crate` is a collection of utilities to make performing certain
//! calculations more convenient.
/// Adds one to the number given.
// --snip--
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}لاحظ أنه لا يوجد أي كود بعد السطر الأخير الذي يبدأ بـ //!. لأننا بدأنا التعليقات بـ //! بدلاً من /// ، فإننا نوثق العنصر الذي يحتوي على هذا التعليق بدلاً من العنصر الذي يلي هذا التعليق. في هذه الحالة، هذا العنصر هو ملف src/lib.rs ، وهو جذر الصندوق. تصف هذه التعليقات الصندوق بأكمله.
عندما نشغل cargo doc --open ، ستظهر هذه التعليقات في الصفحة الأولى من التوثيق لـ my_crate فوق قائمة العناصر العامة في الصندوق، كما هو موضح في الشكل 14-2.
تعليقات التوثيق داخل العناصر مفيدة لوصف الصناديق والوحدات بشكل خاص. استخدمها لشرح الغرض العام للحاوية لمساعدة مستخدميك على فهم تنظيم الصندوق.
الشكل 14-2: التوثيق المعروض لـ my_crate ، بما في ذلك التعليق الذي يصف الصندوق ككل
تصدير واجهة برمجة تطبيقات عامة مريحة (Exporting a Convenient Public API)
يعد هيكل public API الخاص بك اعتباراً رئيسياً عند نشر صندوق. الأشخاص الذين يستخدمون صندوقك أقل دراية بالهيكل منك وقد يجدون صعوبة في العثور على الأجزاء التي يريدون استخدامها إذا كان لصندوقك (تسلسل هرمي للوحدات) module hierarchy كبير.
في الفصل السابع، غطينا كيفية جعل العناصر عامة باستخدام الكلمة المفتاحية pub ، وكيفية جلب العناصر إلى النطاق باستخدام الكلمة المفتاحية use. ومع ذلك، فإن الهيكل الذي يبدو منطقياً بالنسبة لك أثناء تطوير الصندوق قد لا يكون مريحاً جداً لمستخدميك. قد ترغب في تنظيم (هياكلك) structs في تسلسل هرمي يحتوي على مستويات متعددة، ولكن بعد ذلك قد يواجه الأشخاص الذين يريدون استخدام نوع قمت بتعريفه في عمق التسلسل الهرمي صعوبة في اكتشاف وجود هذا النوع. قد ينزعجون أيضاً من الاضطرار إلى كتابة use my_crate::some_module::another_module::UsefulType; بدلاً من use my_crate::UsefulType;.
الخبر السار هو أنه إذا كان الهيكل ليس مريحاً للآخرين لاستخدامه من مكتبة أخرى، فليس عليك إعادة ترتيب تنظيمك الداخلي: بدلاً من ذلك، يمكنك (إعادة تصدير) re-export العناصر لإنشاء هيكل عام يختلف عن هيكلك الخاص باستخدام pub use. تأخذ عملية إعادة التصدير عنصراً عاماً في مكان ما وتجعله عاماً في مكان آخر، كما لو كان قد تم تعريفه في المكان الآخر بدلاً من ذلك.
على سبيل المثال، لنفترض أننا صنعنا مكتبة باسم art لنمذجة المفاهيم الفنية. داخل هذه المكتبة توجد وحدتان: وحدة kinds تحتوي على (تعدادين) enums باسم PrimaryColor و SecondaryColor ووحدة utils تحتوي على دالة باسم mix ، كما هو موضح في القائمة 14-3.
//! # Art
//!
//! A library for modeling artistic concepts.
pub mod kinds {
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
// --snip--
unimplemented!();
}
}يوضح الشكل 14-3 كيف ستبدو الصفحة الأولى من التوثيق لهذا الصندوق المنشأ بواسطة cargo doc.
الشكل 14-3: الصفحة الأولى من التوثيق لـ art التي تسرد وحدات kinds و utils
لاحظ أن الأنواع PrimaryColor و SecondaryColor ليست مدرجة في الصفحة الأولى، ولا دالة mix. علينا النقر فوق kinds و utils لرؤيتها.
سيحتاج صندوق آخر يعتمد على هذه المكتبة إلى عبارات use تجلب العناصر من art إلى النطاق، مع تحديد هيكل الوحدة المعرف حالياً. تعرض القائمة 14-4 مثالاً لصندوق يستخدم العناصر PrimaryColor و mix من صندوق art.
use art::kinds::PrimaryColor;
use art::utils::mix;
fn main() {
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}كان على مؤلف الكود في القائمة 14-4، الذي يستخدم صندوق art ، أن يكتشف أن PrimaryColor موجود في وحدة kinds وأن mix موجود في وحدة utils. هيكل وحدة صندوق art أكثر صلة بالمطورين الذين يعملون على صندوق art منه لأولئك الذين يستخدمونه. لا يحتوي الهيكل الداخلي على أي معلومات مفيدة لشخص يحاول فهم كيفية استخدام صندوق art ، بل يسبب ارتباكاً لأن المطورين الذين يستخدمونه يضطرون إلى اكتشاف مكان البحث، ويجب عليهم تحديد أسماء الوحدات في عبارات use.
لإزالة التنظيم الداخلي من public API ، يمكننا تعديل كود صندوق art في القائمة 14-3 لإضافة عبارات pub use لإعادة تصدير العناصر في المستوى الأعلى، كما هو موضح في القائمة 14-5.
//! # Art
//!
//! A library for modeling artistic concepts.
pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;
pub mod kinds {
// --snip--
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
// --snip--
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
SecondaryColor::Orange
}
}سيقوم توثيق API الذي ينشئه cargo doc لهذا الصندوق الآن بإدراج وربط عمليات إعادة التصدير في الصفحة الأولى، كما هو موضح في الشكل 14-4، مما يجعل الأنواع PrimaryColor و SecondaryColor ودالة mix أسهل في العثور عليها.
الشكل 14-4: الصفحة الأولى من التوثيق لـ art التي تسرد عمليات إعادة التصدير
لا يزال بإمكان مستخدمي صندوق art رؤية واستخدام الهيكل الداخلي من القائمة 14-3 كما هو موضح في القائمة 14-4، أو يمكنهم استخدام الهيكل الأكثر راحة في القائمة 14-5، كما هو موضح في القائمة 14-6.
use art::PrimaryColor;
use art::mix;
fn main() {
// --snip--
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}في الحالات التي توجد فيها العديد من الوحدات المتداخلة، يمكن أن يؤدي إعادة تصدير الأنواع في المستوى الأعلى باستخدام pub use إلى إحداث فرق كبير في تجربة الأشخاص الذين يستخدمون الصندوق. استخدام شائع آخر لـ pub use هو إعادة تصدير تعريفات تبعية في الصندوق الحالي لجعل تعريفات ذلك الصندوق جزءاً من public API لصندوقك.
إن إنشاء هيكل public API مفيد هو فن أكثر منه علم، ويمكنك التكرار للعثور على API الذي يعمل بشكل أفضل لمستخدميك. يمنحك اختيار pub use مرونة في كيفية هيكلة صندوقك داخلياً ويفصل ذلك الهيكل الداخلي عما تقدمه لمستخدميك. انظر إلى بعض أكواد الصناديق التي قمت بتثبيتها لترى ما إذا كان هيكلها الداخلي يختلف عن public API الخاص بها.
إعداد حساب Crates.io (Setting Up a Crates.io Account)
قبل أن تتمكن من نشر أي صناديق، تحتاج إلى إنشاء حساب على crates.io والحصول على (رمز API) API token. للقيام بذلك، قم بزيارة الصفحة الرئيسية في crates.io وقم بتسجيل الدخول عبر حساب GitHub. (حساب GitHub هو مطلب حالي، ولكن قد يدعم الموقع طرقاً أخرى لإنشاء حساب في المستقبل.) بمجرد تسجيل الدخول، قم بزيارة إعدادات حسابك في https://crates.io/me/ واسترجع مفتاح API الخاص بك. بعد ذلك، قم بتشغيل أمر cargo login والصق مفتاح API الخاص بك عند مطالبتك بذلك، هكذا:
$ cargo login
abcdefghijklmnopqrstuvwxyz012345
سيقوم هذا الأمر بإبلاغ Cargo برمز API الخاص بك وتخزينه محلياً في ~/.cargo/credentials.toml. لاحظ أن هذا الرمز هو سر: لا تشاركه مع أي شخص آخر. إذا قمت بمشاركته مع أي شخص لأي سبب من الأسباب، فيجب عليك إلغاؤه وإنشاء رمز جديد على crates.io.
إضافة البيانات الوصفية إلى صندوق جديد (Adding Metadata to a New Crate)
لنفترض أن لديك صندوقاً تريد نشره. قبل النشر، ستحتاج إلى إضافة بعض (البيانات الوصفية) metadata في قسم [package] من ملف Cargo.toml الخاص بالصندوق.
سيحتاج صندوقك إلى اسم فريد. بينما تعمل على صندوق محلياً، يمكنك تسمية الصندوق بأي اسم تريده. ومع ذلك، يتم تخصيص أسماء الصناديق على crates.io على أساس الأسبقية. بمجرد أخذ اسم الصندوق، لا يمكن لأي شخص آخر نشر صندوق بهذا الاسم. قبل محاولة نشر صندوق، ابحث عن الاسم الذي تريد استخدامه. إذا كان الاسم مستخدماً، فستحتاج إلى العثور على اسم آخر وتعديل حقل name في ملف Cargo.toml تحت قسم [package] لاستخدام الاسم الجديد للنشر، هكذا:
اسم الملف: Cargo.toml
[package]
name = "guessing_game"
حتى لو اخترت اسماً فريداً، عندما تقوم بتشغيل cargo publish لنشر الصندوق في هذه المرحلة، ستحصل على تحذير ثم خطأ:
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error (status 400 Bad Request): missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for more information on configuring these fields
يؤدي هذا إلى حدوث خطأ لأنك تفتقد لبعض المعلومات المهمة: الوصف والترخيص مطلوبان حتى يعرف الناس ما يفعله صندوقك وتحت أي شروط يمكنهم استخدامه. في Cargo.toml ، أضف وصفاً يتكون من جملة أو جملتين فقط، لأنه سيظهر مع صندوقك في نتائج البحث. بالنسبة لحقل license ، تحتاج إلى تقديم (قيمة معرف الترخيص) license identifier value. يسرد تبادل بيانات حزمة البرامج (SPDX) التابع لمؤسسة Linux المعرفات التي يمكنك استخدامها لهذه القيمة. على سبيل المثال، لتحديد أنك قمت بترخيص صندوقك باستخدام ترخيص MIT، أضف معرف MIT:
اسم الملف: Cargo.toml
[package]
name = "guessing_game"
license = "MIT"
إذا كنت تريد استخدام ترخيص لا يظهر في SPDX، فأنت بحاجة إلى وضع نص ذلك الترخيص في ملف، وتضمين الملف في مشروعك، ثم استخدام license-file لتحديد اسم ذلك الملف بدلاً من استخدام مفتاح license.
الإرشاد بشأن الترخيص المناسب لمشروعك خارج نطاق هذا الكتاب. يقوم العديد من الأشخاص في مجتمع Rust بترخيص مشاريعهم بنفس طريقة Rust باستخدام ترخيص مزدوج من MIT OR Apache-2.0. توضح هذه الممارسة أنه يمكنك أيضاً تحديد معرفات ترخيص متعددة مفصولة بـ OR للحصول على تراخيص متعددة لمشروعك.
مع وجود اسم فريد، والإصدار، ووصفك، وإضافة ترخيص، قد يبدو ملف Cargo.toml لمشروع جاهز للنشر كالتالي:
اسم الملف: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
description = "A fun game where you guess what number the computer has chosen."
license = "MIT OR Apache-2.0"
[dependencies]
يصف توثيق Cargo البيانات الوصفية الأخرى التي يمكنك تحديدها لضمان تمكن الآخرين من اكتشاف واستخدام صندوقك بسهولة أكبر.
النشر إلى Crates.io (Publishing to Crates.io)
الآن بعد أن أنشأت حساباً، وحفظت رمز API الخاص بك، واخترت اسماً لصندوقك، وحددت البيانات الوصفية المطلوبة، فأنت جاهز للنشر! يؤدي نشر الصندوق إلى رفع إصدار محدد إلى crates.io ليستخدمه الآخرون.
كن حذراً، لأن النشر (دائم) permanent. لا يمكن أبداً الكتابة فوق الإصدار، ولا يمكن حذف الكود إلا في ظروف معينة. أحد الأهداف الرئيسية لـ Crates.io هو العمل كأرشيف دائم للكود بحيث تستمر عمليات بناء جميع المشاريع التي تعتمد على صناديق من crates.io في العمل. السماح بحذف الإصدارات سيجعل تحقيق هذا الهدف مستحيلاً. ومع ذلك، لا يوجد حد لعدد إصدارات الصناديق التي يمكنك نشرها.
قم بتشغيل أمر cargo publish مرة أخرى. يجب أن ينجح الآن:
$ cargo publish
Updating crates.io index
Packaging guessing_game v0.1.0 (file:///projects/guessing_game)
Packaged 6 files, 1.2KiB (895.0B compressed)
Verifying guessing_game v0.1.0 (file:///projects/guessing_game)
Compiling guessing_game v0.1.0
(file:///projects/guessing_game/target/package/guessing_game-0.1.0)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.19s
Uploading guessing_game v0.1.0 (file:///projects/guessing_game)
Uploaded guessing_game v0.1.0 to registry `crates-io`
note: waiting for `guessing_game v0.1.0` to be available at registry
`crates-io`.
You may press ctrl-c to skip waiting; the crate should be available shortly.
Published guessing_game v0.1.0 at registry `crates-io`
تهانينا! لقد شاركت الآن الكود الخاص بك مع مجتمع Rust، ويمكن لأي شخص بسهولة إضافة صندوقك كتبعية لمشروعه.
نشر إصدار جديد من صندوق موجود (Publishing a New Version of an Existing Crate)
عندما تجري تغييرات على صندوقك وتكون جاهزاً لإصدار نسخة جديدة، فإنك تقوم بتغيير قيمة version المحددة في ملف Cargo.toml الخاص بك وتعيد النشر. استخدم قواعد إصدارات البرمجيات الدلالية (Semantic Versioning) لتقرر ما هو رقم الإصدار التالي المناسب، بناءً على أنواع التغييرات التي أجريتها. ثم، قم بتشغيل cargo publish لرفع الإصدار الجديد.
إهمال الإصدارات من Crates.io (Deprecating Versions from Crates.io)
على الرغم من أنه لا يمكنك إزالة الإصدارات السابقة من الصندوق، إلا أنه يمكنك منع أي مشاريع مستقبلية من إضافتها كتبعية جديدة. هذا مفيد عندما يكون إصدار الصندوق معطلاً لسبب أو لآخر. في مثل هذه الحالات، يدعم Cargo (سحب) yanking إصدار الصندوق.
يؤدي سحب الإصدار إلى منع المشاريع الجديدة من الاعتماد على ذلك الإصدار مع السماح لجميع المشاريع الحالية التي تعتمد عليه بالاستمرار. أساساً، يعني السحب أن جميع المشاريع التي تحتوي على ملف Cargo.lock لن تتعطل، وأي ملفات Cargo.lock يتم إنشاؤها في المستقبل لن تستخدم الإصدار المسحوب.
لسحب إصدار من صندوق، في دليل الصندوق الذي قمت بنشره مسبقاً، قم بتشغيل cargo yank وحدد الإصدار الذي تريد سحبه. على سبيل المثال، إذا قمنا بنشر صندوق باسم guessing_game إصدار 1.0.1 وأردنا سحبه، فسنقوم بتشغيل ما يلي في دليل المشروع لـ guessing_game:
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank guessing_game@1.0.1
عن طريق إضافة --undo إلى الأمر، يمكنك أيضاً التراجع عن السحب والسماح للمشاريع بالبدء في الاعتماد على إصدار مرة أخرى:
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank guessing_game@1.0.1
عملية السحب لا تحذف أي كود. لا يمكنها، على سبيل المثال، حذف أسرار تم رفعها عن طريق الخطأ. إذا حدث ذلك، يجب عليك إعادة تعيين تلك الأسرار فوراً.
مساحات عمل كارغو (Cargo Workspaces)
مساحات عمل Cargo (Cargo Workspaces)
في الفصل الثاني عشر، قمنا ببناء حزمة (package) تضمنت صندوقاً ثنائياً (binary crate) وصندوق مكتبة (library crate). مع تطور مشروعك، قد تجد أن library crate يستمر في الكبر وترغب في تقسيم الـ package بشكل أكبر إلى عدة library crates. يوفر Cargo ميزة تسمى مساحات العمل (workspaces) يمكنها المساعدة في إدارة عدة packages مرتبطة يتم تطويرها جنباً إلى جنب.
إنشاء مساحة عمل (Creating a Workspace)
مساحة العمل (workspace) هي مجموعة من الـ packages التي تشترك في نفس ملف Cargo.lock ودليل المخرجات (output directory). دعونا ننشئ مشروعاً باستخدام workspace - سنستخدم كوداً بسيطاً حتى نتمكن من التركيز على هيكل الـ workspace. هناك طرق متعددة لهيكلة الـ workspace، لذا سنعرض طريقة واحدة شائعة. سيكون لدينا workspace يحتوي على binary واثنين من libraries. الـ binary، الذي سيوفر الوظيفة الرئيسية، سيعتمد على المكتبتين. ستوفر إحدى المكتبات دالة (function) باسم add_one والمكتبة الأخرى function باسم add_two. ستكون هذه الـ crates الثلاثة جزءاً من نفس الـ workspace. سنبدأ بإنشاء دليل جديد للـ workspace:
$ mkdir add
$ cd add
بعد ذلك، في دليل add ، ننشئ ملف Cargo.toml الذي سيقوم بتهيئة الـ workspace بالكامل. لن يحتوي هذا الملف على قسم [package]. بدلاً من ذلك، سيبدأ بقسم [workspace] الذي سيسمح لنا بإضافة أعضاء (members) إلى الـ workspace. نحرص أيضاً على استخدام أحدث وأفضل إصدار من خوارزمية الحل (resolver algorithm) الخاصة بـ Cargo في الـ workspace الخاص بنا عن طريق تعيين قيمة resolver إلى "3":
اسم الملف: Cargo.toml
[workspace]
resolver = "3"
بعد ذلك، سننشئ binary crate المسمى adder عن طريق تشغيل cargo new داخل دليل add:
$ cargo new adder
Created binary (application) `adder` package
Adding `adder` as member of workspace at `file:///projects/add`
يؤدي تشغيل cargo new داخل workspace أيضاً إلى إضافة الـ package المنشأ حديثاً تلقائياً إلى مفتاح members في تعريف [workspace] في ملف Cargo.toml الخاص بالـ workspace، هكذا:
[workspace]
resolver = "3"
members = ["adder"]
في هذه المرحلة، يمكننا بناء الـ workspace عن طريق تشغيل cargo build. يجب أن تبدو الملفات في دليل add الخاص بك هكذا:
├── Cargo.lock
├── Cargo.toml
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
يحتوي الـ workspace على دليل target واحد في المستوى الأعلى حيث سيتم وضع العناصر المنتجة (artifacts) المجمعة؛ لا يمتلك package الـ adder دليل target خاصاً به. حتى لو قمنا بتشغيل cargo build من داخل دليل adder ، فإن الـ artifacts المجمعة ستنتهي في add/target بدلاً من add/adder/target. يقوم Cargo بهيكلة دليل target في workspace هكذا لأن الـ crates في workspace من المفترض أن تعتمد على بعضها البعض. إذا كان لكل crate دليل target خاص به، فسيضطر كل crate إلى إعادة تجميع كل من الـ crates الأخرى في الـ workspace لوضع الـ artifacts في دليل target الخاص به. من خلال مشاركة دليل target واحد، يمكن للـ crates تجنب إعادة البناء غير الضرورية.
إنشاء الحزمة الثانية في مساحة العمل (Creating the Second Package in the Workspace)
بعد ذلك، دعونا ننشئ package عضواً آخر في الـ workspace ونسميه add_one. قم بتوليد library crate جديد باسم add_one:
$ cargo new add_one --lib
Created library `add_one` package
Adding `add_one` as member of workspace at `file:///projects/add`
سيشمل ملف Cargo.toml في المستوى الأعلى الآن مسار add_one في قائمة members:
اسم الملف: Cargo.toml
[workspace]
resolver = "3"
members = ["adder", "add_one"]
يجب أن يحتوي دليل add الخاص بك الآن على هذه الأدلة والملفات:
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
في ملف add_one/src/lib.rs ، دعونا نضيف function باسم add_one:
اسم الملف: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}الآن يمكننا جعل package الـ adder مع الـ binary الخاص بنا يعتمد على package الـ add_one الذي يحتوي على المكتبة الخاصة بنا. أولاً، سنحتاج إلى إضافة اعتماد مسار (path dependency) على add_one في ملف adder/Cargo.toml.
اسم الملف: adder/Cargo.toml
[dependencies]
add_one = { path = "../add_one" }
لا يفترض Cargo أن الـ crates في workspace ستعتمد على بعضها البعض، لذا نحتاج إلى أن نكون صريحين بشأن علاقات التبعية (dependency relationships).
بعد ذلك، دعونا نستخدم function الـ add_one (من crate الـ add_one) في crate الـ adder. افتح ملف adder/src/main.rs وغير function الـ main لاستدعاء function الـ add_one ، كما في القائمة 14-7.
fn main() {
let num = 10;
println!("Hello, world! {num} plus one is {}!", add_one::add_one(num));
}دعونا نبني الـ workspace عن طريق تشغيل cargo build في دليل add في المستوى الأعلى!
$ cargo build
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.22s
لتشغيل binary crate من دليل add ، يمكننا تحديد أي package في الـ workspace نريد تشغيله باستخدام وسيط (argument) الـ -p واسم الـ package مع cargo run:
$ cargo run -p adder
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/adder`
Hello, world! 10 plus one is 11!
هذا يشغل الكود في adder/src/main.rs ، والذي يعتمد على crate الـ add_one.
<a id="depending-on-an-external-package-in-a-workspace"></a>
### الاعتماد على حزمة خارجية (Depending on an External Package)
لاحظ أن الـ workspace يحتوي على ملف _Cargo.lock_ واحد فقط في المستوى الأعلى، بدلاً من وجود _Cargo.lock_ في دليل كل crate. يضمن ذلك أن جميع الـ crates تستخدم نفس الإصدار من جميع التبعيات (dependencies). إذا أضفنا حزمة (package) الـ `rand` إلى ملفات _adder/Cargo.toml_ و _add_one/Cargo.toml_ ، فسيقوم Cargo بحلهما (resolve) إلى إصدار واحد من `rand` وتسجيل ذلك في ملف _Cargo.lock_ الواحد. إن جعل جميع الـ crates في الـ workspace تستخدم نفس الـ dependencies يعني أن الـ crates ستكون دائماً متوافقة مع بعضها البعض. دعونا نضيف crate الـ `rand` إلى قسم `[dependencies]` في ملف _add_one/Cargo.toml_ حتى نتمكن من استخدام crate الـ `rand` في crate الـ `add_one`:
<span class="filename">اسم الملف: add_one/Cargo.toml</span>
```toml
[dependencies]
rand = "0.8.5"
يمكننا الآن إضافة use rand; إلى ملف add_one/src/lib.rs ، وبناء الـ workspace بالكامل عن طريق تشغيل cargo build في دليل add سيجلب ويجمع crate الـ rand. سنحصل على تحذير واحد لأننا لا نشير إلى الـ rand الذي جلبناه إلى النطاق (scope):
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling add_one v0.1.0 (file:///projects/add/add_one)
warning: unused import: `rand`
--> add_one/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `add_one` (lib) generated 1 warning (run `cargo fix --lib -p add_one` to apply 1 suggestion)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.95s
يحتوي ملف Cargo.lock في المستوى الأعلى الآن على معلومات حول تبعية add_one على rand. ومع ذلك، على الرغم من استخدام rand في مكان ما في الـ workspace، لا يمكننا استخدامه في crates أخرى في الـ workspace ما لم نضف rand إلى ملفات Cargo.toml الخاصة بها أيضاً. على سبيل المثال، إذا أضفنا use rand; إلى ملف adder/src/main.rs لـ package الـ adder ، فسنحصل على خطأ:
$ cargo build
--snip--
Compiling adder v0.1.0 (file:///projects/add/adder)
error[E0432]: unresolved import `rand`
--> adder/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
لإصلاح ذلك، قم بتحرير ملف Cargo.toml لـ package الـ adder وأشر إلى أن rand هو تبعية له أيضاً. سيؤدي بناء package الـ adder إلى إضافة rand إلى قائمة الـ dependencies لـ adder في Cargo.lock ، ولكن لن يتم تنزيل نسخ إضافية من rand. سيضمن Cargo أن كل crate في كل package في الـ workspace يستخدم package الـ rand سيستخدم نفس الإصدار طالما أنها تحدد إصدارات متوافقة من rand ، مما يوفر لنا المساحة ويضمن أن الـ crates في الـ workspace ستكون متوافقة مع بعضها البعض.
إذا حددت الـ crates في الـ workspace إصدارات غير متوافقة من نفس التبعية، فسيقوم Cargo بحل كل منها ولكنه سيظل يحاول حل أقل عدد ممكن من الإصدارات.
إضافة اختبار إلى مساحة عمل (Adding a Test to a Workspace)
لتحسين آخر، دعونا نضيف اختباراً (test) لـ function الـ add_one::add_one داخل crate الـ add_one:
اسم الملف: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}الآن قم بتشغيل cargo test في دليل add في المستوى الأعلى. سيؤدي تشغيل cargo test في workspace مهيكل مثل هذا إلى تشغيل الاختبارات لجميع الـ crates في الـ workspace:
$ cargo test
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.20s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/adder-3a47283c568d2b6a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
يوضح القسم الأول من المخرجات أن اختبار it_works في crate الـ add_one قد نجح. يوضح القسم التالي أنه لم يتم العثور على اختبارات في crate الـ adder ، ثم يوضح القسم الأخير أنه لم يتم العثور على اختبارات توثيق (documentation tests) في crate الـ add_one.
يمكننا أيضاً تشغيل الاختبارات لـ crate واحد معين في workspace من دليل المستوى الأعلى باستخدام علم (flag) الـ -p وتحديد اسم الـ crate الذي نريد اختباره:
$ cargo test -p add_one
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
توضح هذه المخرجات أن cargo test قام فقط بتشغيل الاختبارات لـ crate الـ add_one ولم يقم بتشغيل اختبارات crate الـ adder.
إذا قمت بنشر الـ crates في الـ workspace على crates.io ، فسيحتاج كل crate في الـ workspace إلى النشر بشكل منفصل. مثل cargo test ، يمكننا نشر crate معين في الـ workspace الخاص بنا باستخدام flag الـ -p وتحديد اسم الـ crate الذي نريد نشره.
لمزيد من التدريب، أضف crate باسم add_two إلى هذا الـ workspace بطريقة مماثلة لـ crate الـ add_one!
مع نمو مشروعك، فكر في استخدام workspace: فهو يتيح لك العمل مع مكونات أصغر وأسهل في الفهم من كتلة واحدة كبيرة من الكود. علاوة على ذلك، فإن الاحتفاظ بالـ crates في workspace يمكن أن يجعل التنسيق بين الـ crates أسهل إذا كانت تتغير غالباً في نفس الوقت.
تثبيت الملفات الثنائية باستخدام cargo install
تثبيت الملفات الثنائية (Installing Binaries) باستخدام cargo install
يسمح لك الأمر cargo install بتثبيت واستخدام الصناديق الثنائية (Binary Crates) محلياً. لا يهدف هذا الأمر إلى استبدال حزم النظام؛ بل يُقصد به أن يكون وسيلة مريحة لمطوري Rust لتثبيت الأدوات التي شاركها الآخرون على crates.io. لاحظ أنه يمكنك فقط تثبيت الحزم التي تحتوي على أهداف ثنائية (Binary Targets). يعتبر الهدف الثنائي (Binary Target) هو البرنامج القابل للتشغيل الذي يتم إنشاؤه إذا كان الصندوق (Crate) يحتوي على ملف src/main.rs أو ملف آخر محدد كملف ثنائي، على عكس هدف المكتبة (Library Target) الذي لا يكون قابلاً للتشغيل بمفرده ولكنه مناسب للتضمين داخل برامج أخرى. عادةً ما تحتوي Crates على معلومات في ملف README حول ما إذا كان Crate عبارة عن مكتبة، أو يحتوي على Binary Target، أو كليهما.
يتم تخزين جميع الملفات الثنائية (Binaries) المثبتة باستخدام cargo install في مجلد bin الخاص بجذر التثبيت. إذا قمت بتثبيت Rust باستخدام rustup.rs ولم يكن لديك أي تكوينات مخصصة، فسيكون هذا الدليل هو $HOME/.cargo/bin. تأكد من أن هذا الدليل موجود في متغير البيئة $PATH الخاص بك لتتمكن من تشغيل البرامج التي قمت بتثبيتها باستخدام cargo install.
على سبيل المثال، ذكرنا في الفصل 12 أن هناك تنفيذاً بلغة Rust لأداة grep يسمى ripgrep للبحث في الملفات. لتثبيت ripgrep يمكننا تشغيل ما يلي:
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v14.1.1
Downloaded 1 crate (213.6 KB) in 0.40s
Installing ripgrep v14.1.1
--snip--
Compiling grep v0.3.2
Finished `release` profile [optimized + debuginfo] target(s) in 6.73s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v14.1.1` (executable `rg`)
يُظهر السطر قبل الأخير من المخرجات موقع واسم Binary المثبت، والذي يكون في حالة ripgrep هو rg. طالما أن دليل التثبيت موجود في $PATH الخاص بك، كما ذكرنا سابقاً، يمكنك حينها تشغيل rg --help والبدء في استخدام أداة أسرع وأكثر ملاءمة لروح Rust للبحث في الملفات!
توسيع كارغو بأوامر مخصصة
توسيع Cargo باستخدام الأوامر المخصصة (Custom Commands)
تم تصميم Cargo بحيث يمكنك توسيعه بأوامر فرعية (subcommands) جديدة دون الحاجة إلى تعديله. إذا كان هناك ملف ثنائي (binary) في $PATH الخاص بك يسمى cargo-something، فيمكنك تشغيله كما لو كان subcommand لـ Cargo عن طريق تشغيل cargo something. يتم أيضًا سرد الـ custom commands مثل هذه عند تشغيل cargo --list. إن القدرة على استخدام cargo install لتثبيت الإضافات ثم تشغيلها تمامًا مثل أدوات Cargo المضمنة هي ميزة مريحة للغاية لتصميم Cargo!
ملخص
تعد مشاركة الكود باستخدام Cargo و crates.io جزءًا مما يجعل نظام Rust البيئي مفيدًا للعديد من المهام المختلفة. الـ standard library لـ Rust صغيرة ومستقرة، ولكن الـ crates سهلة المشاركة والاستخدام والتحسين في جدول زمني مختلف عن جدول اللغة. لا تخجل من مشاركة الكود المفيد لك على crates.io؛ فمن المحتمل أن يكون مفيدًا لشخص آخر أيضًا!
المؤشرات الذكية (Smart Pointers)
المؤشر (Pointer) هو مفهوم عام لمتغير يحتوي على عنوان في الذاكرة. يشير هذا العنوان إلى بيانات أخرى أو “يؤشر عليها”. النوع الأكثر شيوعاً للمؤشرات في لغة Rust هو المرجع (Reference)، والذي تعرفت عليه في الفصل الرابع. يُشار إلى References بالرمز & وهي تستعير (Borrow) القيمة التي تشير إليها. لا تمتلك References أي قدرات خاصة سوى الإشارة إلى البيانات، وليس لها أي أعباء إضافية (Overhead).
أما المؤشرات الذكية (Smart Pointers)، فهي من ناحية أخرى هياكل بيانات (Data Structures) تعمل مثل Pointer ولكنها تمتلك أيضاً بيانات وصفية (Metadata) وقدرات إضافية. مفهوم Smart Pointers ليس فريداً في Rust: فقد نشأت Smart Pointers في لغة ++C وهي موجودة في لغات أخرى أيضاً. تمتلك Rust مجموعة متنوعة من Smart Pointers المعرفة في المكتبة القياسية (Standard Library) والتي توفر وظائف تتجاوز تلك التي توفرها References. لاستكشاف المفهوم العام، سنلقي نظرة على زوجين من الأمثلة المختلفة لـ Smart Pointers، بما في ذلك نوع المؤشر الذكي بعدّ المراجع (Reference Counting). يتيح لك هذا Pointer السماح للبيانات بامتلاك مالكين متعددين من خلال تتبع عدد المالكين، وعندما لا يتبقى أي مالك، يتم تنظيف البيانات.
في Rust، ومع مفهوم الملكية (Ownership) والاستعارة (Borrowing) الخاص بها، هناك فرق إضافي بين References و Smart Pointers: فبينما تستعير References البيانات فقط، فإن Smart Pointers في كثير من الحالات تملك (Own) البيانات التي تشير إليها.
عادةً ما يتم تنفيذ Smart Pointers باستخدام الهياكل (Structs). وعلى عكس Struct العادي، تنفذ Smart Pointers سمات (Traits) Deref و Drop. تسمح Trait Deref لمثيل (Instance) من هيكل Smart Pointer بالتصرف مثل Reference بحيث يمكنك كتابة الشفرة البرمجية (Code) الخاصة بك لتعمل مع كل من References أو Smart Pointers. وتسمح لك Trait Drop بتخصيص Code الذي يتم تشغيله عندما يخرج Instance من Smart Pointer عن النطاق (Scope). في هذا الفصل، سنناقش كلتا السمتين ونوضح سبب أهميتهما لـ Smart Pointers.
بما أن نمط المؤشر الذكي (Smart Pointer Pattern) هو نمط تصميم عام يُستخدم بشكل متكرر في Rust، فإن هذا الفصل لن يغطي كل Smart Pointer موجود. تمتلك العديد من المكتبات (Libraries) مؤشرات ذكية خاصة بها، ويمكنك حتى كتابة المؤشرات الخاصة بك. سنغطي Smart Pointers الأكثر شيوعاً في Standard Library:
Box<T>، لتخصيص القيم في الذاكرة الكومة (Heap)Rc<T>، وهو نوع Reference Counting يتيح الملكية المتعددةRef<T>وRefMut<T>، اللذان يتم الوصول إليهما من خلالRefCell<T>، وهو نوع يفرض قواعد Borrowing في وقت التشغيل (Runtime) بدلاً من وقت الترجمة (Compile Time)
بالإضافة إلى ذلك، سنغطي نمط القابلية للتعديل الداخلية (Interior Mutability) حيث يكشف نوع غير قابل للتعديل (Immutable Type) عن واجهة برمجة تطبيقات (API) لتعديل قيمة داخلية. سنناقش أيضاً دورات المراجع (Reference Cycles): كيف يمكن أن تسرب الذاكرة (Memory Leak) وكيفية منع ذلك.
فلنبدأ!
استخدام Box للإشارة إلى البيانات في الكومة (Heap)
استخدام Box<T> للإشارة إلى البيانات في الكومة (Using Box<T> to Point to Data on the Heap)
أكثر (المؤشرات الذكية) smart pointers وضوحاً هو الصندوق، والذي يُكتب نوعه Box<T>. تسمح لك الصناديق بتخزين البيانات في (الكومة) heap بدلاً من (المكدس) stack. ما يتبقى في المكدس هو المؤشر إلى بيانات الكومة. ارجع إلى الفصل الرابع لمراجعة الفرق بين المكدس والكومة.
لا تمتلك الصناديق عبئاً إضافياً على الأداء، بخلاف تخزين بياناتها في الكومة بدلاً من المكدس. لكنها لا تمتلك الكثير من القدرات الإضافية أيضاً. ستستخدمها غالباً في هذه الحالات:
- عندما يكون لديك نوع لا يمكن معرفة حجمه في وقت التجميع، وتريد استخدام قيمة من ذلك النوع في سياق يتطلب حجماً دقيقاً.
- عندما يكون لديك كمية كبيرة من البيانات، وتريد نقل (الملكية)
ownershipولكن مع ضمان عدم نسخ البيانات عند القيام بذلك. - عندما تريد امتلاك قيمة، ويهتم كودك فقط بأنها نوع ينفذ (سمة)
traitمعينة بدلاً من كونها نوعاً محدداً.
سنوضح الحالة الأولى في “تمكين الأنواع العودية باستخدام الصناديق”. في الحالة الثانية، يمكن أن يستغرق نقل ملكية كمية كبيرة من البيانات وقتاً طويلاً لأن البيانات يتم نسخها في المكدس. لتحسين الأداء في هذه الحالة، يمكننا تخزين الكمية الكبيرة من البيانات في الكومة داخل صندوق. بعد ذلك، يتم نسخ كمية صغيرة فقط من بيانات المؤشر في المكدس، بينما تظل البيانات التي يشير إليها في مكان واحد في الكومة. تُعرف الحالة الثالثة باسم (كائن السمة) trait object ، وقد خُصص قسم “استخدام كائنات السمة للتجريد عبر السلوك المشترك” في الفصل 18 لهذا الموضوع. لذا، فإن ما تتعلمه هنا ستطبقه مرة أخرى في ذلك القسم!
تخزين البيانات في الكومة (Storing Data on the Heap)
قبل أن نناقش حالة استخدام تخزين الكومة لـ Box<T> ، سنغطي الصيغة وكيفية التفاعل مع القيم المخزنة داخل Box<T>.
تعرض القائمة 15-1 كيفية استخدام صندوق لتخزين قيمة i32 في الكومة.
fn main() {
let b = Box::new(5);
println!("b = {b}");
}نعرف المتغير b ليكون له قيمة Box يشير إلى القيمة 5 ، والتي يتم تخصيصها في الكومة. سيطبع هذا البرنامج b = 5 ؛ في هذه الحالة، يمكننا الوصول إلى البيانات الموجودة في الصندوق بشكل مشابه لكيفية وصولنا إليها إذا كانت هذه البيانات في المكدس. تماماً مثل أي قيمة مملوكة، عندما يخرج الصندوق عن النطاق، كما يفعل b في نهاية main ، سيتم إلغاء تخصيصه. يحدث إلغاء التخصيص لكل من الصندوق (المخزن في المكدس) والبيانات التي يشير إليها (المخزنة في الكومة).
وضع قيمة واحدة في الكومة ليس مفيداً جداً، لذا لن تستخدم الصناديق بمفردها بهذه الطريقة كثيراً. إن وجود قيم مثل i32 واحدة في المكدس، حيث يتم تخزينها افتراضياً، هو أمر أكثر ملاءمة في غالبية الحالات. دعنا ننظر في حالة تسمح لنا فيها الصناديق بتعريف أنواع لن يُسمح لنا بتعريفها إذا لم يكن لدينا صناديق.
تمكين الأنواع العودية باستخدام الصناديق (Enabling Recursive Types with Boxes)
يمكن أن تحتوي قيمة من (نوع عودي) recursive type على قيمة أخرى من نفس النوع كجزء من نفسها. تشكل الأنواع العودية مشكلة لأن Rust تحتاج إلى معرفة مقدار المساحة التي يشغلها النوع في وقت التجميع. ومع ذلك، فإن تداخل قيم الأنواع العودية يمكن نظرياً أن يستمر إلى ما لا نهاية، لذا لا يمكن لـ Rust معرفة مقدار المساحة التي تحتاجها القيمة. نظراً لأن الصناديق لها حجم معروف، يمكننا تمكين الأنواع العودية عن طريق إدخال صندوق في تعريف النوع العودي.
كمثال على نوع عودي، دعنا نستكشف (قائمة cons) cons list. هذا نوع بيانات يوجد عادة في لغات البرمجة الوظيفية. نوع قائمة cons الذي سنعرفه بسيط باستثناء العودية؛ لذلك، ستكون المفاهيم في المثال الذي سنعمل معه مفيدة في أي وقت تدخل فيه في مواقف أكثر تعقيداً تتضمن أنواعاً عودية.
فهم قائمة Cons (Understanding the Cons List)
قائمة cons هي هيكل بيانات يأتي من لغة البرمجة Lisp ولهجاتها، وهي مكونة من أزواج متداخلة، وهي نسخة Lisp من القائمة المرتبطة. يأتي اسمها من دالة cons (اختصار لـ construct function) في Lisp التي تنشئ زوجاً جديداً من وسيطتيها. من خلال استدعاء cons على زوج يتكون من قيمة وزوج آخر، يمكننا بناء قوائم cons مكونة من أزواج عودية.
على سبيل المثال، إليك تمثيل كود زائف لقائمة cons تحتوي على القائمة 1, 2, 3 مع وضع كل زوج بين قوسين:
(1, (2, (3, Nil)))
يحتوي كل عنصر في قائمة cons على عنصرين: قيمة العنصر الحالي وقيمة العنصر التالي. يحتوي العنصر الأخير في القائمة فقط على قيمة تسمى Nil بدون عنصر تالٍ. يتم إنتاج قائمة cons عن طريق استدعاء دالة cons بشكل عودي. الاسم المتعارف عليه للإشارة إلى الحالة الأساسية للعودية هو Nil. لاحظ أن هذا ليس نفس مفهوم “null” أو “nil” الذي نوقش في الفصل السادس، والذي يمثل قيمة غير صالحة أو غائبة.
ليست قائمة cons هيكل بيانات شائع الاستخدام في Rust. في معظم الأوقات عندما يكون لديك قائمة من العناصر في Rust، فإن Vec<T> هو خيار أفضل للاستخدام. أنواع البيانات العودية الأخرى الأكثر تعقيداً تعد مفيدة في مواقف مختلفة، ولكن من خلال البدء بقائمة cons في هذا الفصل، يمكننا استكشاف كيف تسمح لنا الصناديق بتعريف نوع بيانات عودي دون الكثير من التشتيت.
تحتوي القائمة 15-2 على تعريف (تعداد) enum لقائمة cons. لاحظ أن هذا الكود لن يتم تجميعه بعد، لأن نوع List ليس له حجم معروف، وهو ما سنوضحه.
enum List {
Cons(i32, List),
Nil,
}
fn main() {}ملاحظة: نحن نقوم بتنفيذ قائمة cons تحمل قيم
i32فقط لأغراض هذا المثال. كان بإمكاننا تنفيذها باستخدام (الأنواع العامة)generics، كما ناقشنا في الفصل العاشر، لتعريف نوع قائمة cons يمكنه تخزين قيم من أي نوع.
استخدام نوع List لتخزين القائمة 1, 2, 3 سيبدو مثل الكود في القائمة 15-3.
enum List {
Cons(i32, List),
Nil,
}
// --snip--
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}تحمل قيمة Cons الأولى 1 وقيمة List أخرى. قيمة List هذه هي قيمة Cons أخرى تحمل 2 وقيمة List أخرى. قيمة List هذه هي قيمة Cons واحدة أخرى تحمل 3 وقيمة List ، وهي أخيراً Nil ، وهو (المتغير) variant غير العودي الذي يشير إلى نهاية القائمة.
إذا حاولنا تجميع الكود في القائمة 15-3، فسنحصل على الخطأ الموضح في القائمة 15-4.
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
error[E0391]: cycle detected when computing when `List` needs drop
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which immediately requires computing when `List` needs drop again
= note: cycle used when computing whether `List` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` (bin "cons-list") due to 2 previous errors
يظهر الخطأ أن هذا النوع “له حجم لانهائي”. والسبب هو أننا عرفنا List بمتغير عودي: فهو يحمل قيمة أخرى من نفسه مباشرة. ونتيجة لذلك، لا تستطيع Rust معرفة مقدار المساحة التي تحتاجها لتخزين قيمة List. دعنا نحلل سبب حصولنا على هذا الخطأ. أولاً، سننظر في كيفية تقرير Rust لمقدار المساحة التي تحتاجها لتخزين قيمة من نوع غير عودي.
حساب حجم نوع غير عودي (Computing the Size of a Non-Recursive Type)
تذكر تعداد Message الذي عرفناه في القائمة 6-2 عندما ناقشنا تعريفات التعداد في الفصل السادس:
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {}لتحديد مقدار المساحة التي يجب تخصيصها لقيمة Message ، تمر Rust عبر كل متغير من المتغيرات لترى أي متغير يحتاج إلى أكبر مساحة. ترى Rust أن Message::Quit لا يحتاج إلى أي مساحة، و Message::Move يحتاج إلى مساحة كافية لتخزين قيمتي i32 ، وهكذا. نظراً لأنه سيتم استخدام متغير واحد فقط، فإن أكبر مساحة ستحتاجها قيمة Message هي المساحة التي سيستغرقها تخزين أكبر متغيراته.
قارن هذا بما يحدث عندما تحاول Rust تحديد مقدار المساحة التي يحتاجها نوع عودي مثل تعداد List في القائمة 15-2. يبدأ المترجم بالنظر في متغير Cons ، الذي يحمل قيمة من نوع i32 وقيمة من نوع List. لذلك، يحتاج Cons إلى مساحة تساوي حجم i32 بالإضافة إلى حجم List. لمعرفة مقدار الذاكرة التي يحتاجها نوع List ، ينظر المترجم في المتغيرات، بدءاً من متغير Cons. يحمل متغير Cons قيمة من نوع i32 وقيمة من نوع List ، وتستمر هذه العملية إلى ما لا نهاية، كما هو موضح في الشكل 15-1.

الشكل 15-1: قائمة List لانهائية تتكون من متغيرات Cons لانهائية
الحصول على نوع عودي بحجم معروف (Getting a Recursive Type with a Known Size)
نظراً لأن Rust لا تستطيع معرفة مقدار المساحة التي يجب تخصيصها للأنواع المعرفة عودياً، فإن المترجم يعطي خطأ مع هذا الاقتراح المفيد:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
في هذا الاقتراح، تعني (غير المباشرة) indirection أنه بدلاً من تخزين قيمة مباشرة، يجب علينا تغيير هيكل البيانات لتخزين القيمة بشكل غير مباشر عن طريق تخزين مؤشر إلى القيمة بدلاً من ذلك.
نظراً لأن Box<T> هو مؤشر، فإن Rust تعرف دائماً مقدار المساحة التي يحتاجها Box<T>: فحجم المؤشر لا يتغير بناءً على كمية البيانات التي يشير إليها. هذا يعني أنه يمكننا وضع Box<T> داخل متغير Cons بدلاً من قيمة List أخرى مباشرة. سيشير Box<T> إلى قيمة List التالية التي ستكون في الكومة بدلاً من داخل متغير Cons. من الناحية المفاهيمية، لا تزال لدينا قائمة، تم إنشاؤها بقوائم تحمل قوائم أخرى، ولكن هذا التنفيذ الآن يشبه وضع العناصر بجانب بعضها البعض بدلاً من داخل بعضها البعض.
يمكننا تغيير تعريف تعداد List في القائمة 15-2 واستخدام List في القائمة 15-3 إلى الكود في القائمة 15-5، والذي سيتم تجميعه.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));
}يحتاج متغير Cons إلى حجم i32 بالإضافة إلى المساحة اللازمة لتخزين بيانات مؤشر الصندوق. لا يخزن متغير Nil أي قيم، لذا فهو يحتاج إلى مساحة أقل في المكدس من متغير Cons. نحن نعلم الآن أن أي قيمة List ستشغل حجم i32 بالإضافة إلى حجم بيانات مؤشر الصندوق. باستخدام الصندوق، قمنا بكسر السلسلة العودية اللانهائية، بحيث يمكن للمترجم معرفة الحجم الذي يحتاجه لتخزين قيمة List. يوضح الشكل 15-2 كيف يبدو متغير Cons الآن.

الشكل 15-2: قائمة List ليست لانهائية الحجم، لأن Cons يحمل Box
توفر الصناديق فقط غير المباشرة وتخصيص الكومة؛ فهي لا تمتلك أي قدرات خاصة أخرى، مثل تلك التي سنراها مع أنواع المؤشرات الذكية الأخرى. كما أنها لا تمتلك عبء الأداء الذي تتكبده هذه القدرات الخاصة، لذا يمكن أن تكون مفيدة في حالات مثل قائمة cons حيث تكون غير المباشرة هي الميزة الوحيدة التي نحتاجها. سننظر في المزيد من حالات الاستخدام للصناديق في الفصل 18.
نوع Box<T> هو مؤشر ذكي لأنه ينفذ سمة Deref ، والتي تسمح بمعاملة قيم Box<T> مثل المراجع. عندما تخرج قيمة Box<T> عن النطاق، يتم تنظيف بيانات الكومة التي يشير إليها الصندوق أيضاً بسبب تنفيذ سمة Drop. ستكون هاتان السمتان أكثر أهمية للوظائف التي توفرها أنواع المؤشرات الذكية الأخرى التي سنناقشها في بقية هذا الفصل. دعنا نستكشف هاتين السمتين بمزيد من التفصيل.
معاملة المؤشرات الذكية مثل المراجع العادية
التعامل مع المؤشرات الذكية (Smart Pointers) كالمراجع العادية (Regular References)
يتيح لك تطبيق سمة Deref تخصيص سلوك عامل إلغاء الإشارة (dereference operator) * (لا يجب الخلط بينه وبين عامل الضرب أو عامل glob). من خلال تطبيق Deref بطريقة يمكن من خلالها التعامل مع smart pointer كـ regular reference، يمكنك كتابة كود يعمل على الـ references واستخدام هذا الكود مع الـ smart pointers أيضًا.
دعنا أولاً نلقي نظرة على كيفية عمل الـ dereference operator مع الـ regular references. بعد ذلك، سنحاول تعريف نوع مخصص يتصرف مثل Box<T> ونرى لماذا لا يعمل الـ dereference operator كـ reference على نوعنا المعرف حديثًا. سنستكشف كيف أن تطبيق سمة Deref يجعل من الممكن لـ smart pointers أن تعمل بطرق مماثلة لـ references. بعد ذلك، سننظر إلى ميزة الإكراه على إلغاء الإشارة (deref coercion) في Rust وكيف تتيح لنا العمل إما مع الـ references أو الـ smart pointers.
تتبع المرجع إلى القيمة
الـ regular reference هو نوع من المؤشرات (pointer)، وإحدى طرق التفكير في الـ pointer هي أنه سهم يشير إلى قيمة مخزنة في مكان آخر. في القائمة 15-6، ننشئ reference إلى قيمة i32 ثم نستخدم الـ dereference operator لتتبع الـ reference إلى القيمة.
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}يحتوي المتغير x على قيمة i32 وهي 5. نضبط y ليكون مساويًا لـ reference إلى x. يمكننا التأكيد على أن x يساوي 5. ومع ذلك، إذا أردنا إجراء تأكيد حول القيمة في y، يجب علينا استخدام *y لتتبع الـ reference إلى القيمة التي يشير إليها (وبالتالي، إلغاء الإشارة (dereference)) حتى يتمكن الـ compiler من مقارنة القيمة الفعلية. بمجرد أن نقوم بـ dereference لـ y، يمكننا الوصول إلى القيمة الصحيحة التي يشير إليها y والتي يمكننا مقارنتها بـ 5.
إذا حاولنا كتابة assert_eq!(5, y); بدلاً من ذلك، فسنحصل على خطأ الـ compilation هذا:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
لا يُسمح بمقارنة رقم و reference إلى رقم لأنهما نوعان مختلفان. يجب علينا استخدام الـ dereference operator لتتبع الـ reference إلى القيمة التي يشير إليها.
استخدام Box<T> كـ Reference
يمكننا إعادة كتابة الكود في القائمة 15-6 لاستخدام Box<T> بدلاً من reference؛ يعمل الـ dereference operator المستخدم على Box<T> في القائمة 15-7 بنفس طريقة عمل الـ dereference operator المستخدم على الـ reference في القائمة 15-6.
fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}الفرق الرئيسي بين القائمة 15-7 والقائمة 15-6 هو أننا هنا نضبط y ليكون مثيلًا لـ box يشير إلى قيمة منسوخة من x بدلاً من reference يشير إلى قيمة x. في التأكيد الأخير، يمكننا استخدام الـ dereference operator لتتبع مؤشر الـ box بنفس الطريقة التي فعلناها عندما كان y reference. بعد ذلك، سنستكشف ما هو خاص بـ Box<T> الذي يمكننا من استخدام الـ dereference operator عن طريق تعريف نوع الـ box الخاص بنا.
تعريف الـ Smart Pointer الخاص بنا
دعنا نبني نوع مغلف (wrapper type) مشابه لـ Box<T> الذي توفره الـ standard library لتجربة كيف تتصرف أنواع الـ smart pointer بشكل مختلف عن الـ references افتراضيًا. بعد ذلك، سننظر في كيفية إضافة القدرة على استخدام الـ dereference operator.
ملاحظة: هناك فرق كبير واحد بين نوع
MyBox<T>الذي سنبنيه الآن وBox<T>الحقيقي: لن يقوم إصدارنا بتخزين بياناته على الكومة (heap). نحن نركز هذا المثال علىDeref، لذا فإن مكان تخزين البيانات فعليًا أقل أهمية من سلوك الـ pointer.
يتم تعريف النوع Box<T> في النهاية على أنه struct tuple بعنصر واحد، لذا تحدد القائمة 15-8 نوع MyBox<T> بنفس الطريقة. سنقوم أيضًا بتعريف دالة new لتتناسب مع دالة new المعرفة على Box<T>.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {}نحدد struct يسمى MyBox ونعلن عن generic parameter T لأننا نريد أن يحتوي نوعنا على قيم من أي نوع. نوع MyBox هو tuple struct بعنصر واحد من النوع T. تأخذ الدالة MyBox::new parameter واحدًا من النوع T وتُرجع مثيل MyBox يحتوي على القيمة التي تم تمريرها.
دعنا نحاول إضافة الدالة main في القائمة 15-7 إلى القائمة 15-8 وتغييرها لاستخدام نوع MyBox<T> الذي عرفناه بدلاً من Box<T>. لن يتم تجميع الكود في القائمة 15-9، لأن Rust لا تعرف كيفية dereference لـ MyBox.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}إليك خطأ الـ compilation الناتج:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^ can't be dereferenced
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
لا يمكن إلغاء الإشارة إلى نوع MyBox<T> الخاص بنا لأننا لم نطبق هذه القدرة على نوعنا. لتمكين إلغاء الإشارة باستخدام الـ operator *، نقوم بتطبيق سمة Deref.
تطبيق سمة Deref
كما نوقش في “تطبيق سمة على نوع” في الفصل 10، لتطبيق سمة (trait) نحتاج إلى توفير تطبيقات لـ methods السمة المطلوبة. تتطلب سمة Deref، التي توفرها الـ standard library، منا تطبيق method واحد يسمى deref يقترض self ويُرجع reference إلى البيانات الداخلية. تحتوي القائمة 15-10 على تطبيق لـ Deref لإضافته إلى تعريف MyBox<T>.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}يحدد بناء الجملة type Target = T; نوعًا مرتبطًا (associated type) لـ سمة Deref لاستخدامه. الـ associated types هي طريقة مختلفة قليلاً للإعلان عن generic parameter، ولكن لا داعي للقلق بشأنها الآن؛ سنتناولها بمزيد من التفصيل في الفصل 20.
نملأ نص method deref بـ &self.0 بحيث يُرجع deref reference إلى القيمة التي نريد الوصول إليها باستخدام الـ operator *؛ تذكر من “إنشاء أنواع مختلفة باستخدام Structs Tuple” في الفصل 5 أن .0 يصل إلى القيمة الأولى في tuple struct. الآن يتم تجميع الدالة main في القائمة 15-9 التي تستدعي * على قيمة MyBox<T>، وتمر التأكيدات!
بدون سمة Deref، يمكن لـ compiler فقط dereference لـ references &. يمنح method deref الـ compiler القدرة على أخذ قيمة من أي نوع يطبق Deref واستدعاء method deref للحصول على reference يعرف كيفية dereference له.
عندما أدخلنا *y في القائمة 15-9، قامت Rust فعليًا بتشغيل هذا الكود خلف الكواليس:
*(y.deref())تستبدل Rust الـ operator * باستدعاء لـ method deref ثم dereference عادي حتى لا نضطر إلى التفكير فيما إذا كنا بحاجة إلى استدعاء method deref أم لا. تتيح لنا ميزة Rust هذه كتابة كود يعمل بشكل متطابق سواء كان لدينا regular reference أو نوع يطبق Deref.
يرجع سبب إرجاع method deref لـ reference إلى قيمة، وأن الـ dereference العادي خارج الأقواس في *(y.deref()) لا يزال ضروريًا، إلى نظام الملكية (ownership system). إذا كان method deref يُرجع القيمة مباشرة بدلاً من reference إلى القيمة، فسيتم نقل القيمة خارج self. لا نريد أن نأخذ ownership للقيمة الداخلية داخل MyBox<T> في هذه الحالة أو في معظم الحالات التي نستخدم فيها الـ dereference operator.
لاحظ أنه يتم استبدال الـ operator * باستدعاء لـ method deref ثم استدعاء لـ operator * مرة واحدة فقط، في كل مرة نستخدم فيها * في الكود الخاص بنا. نظرًا لأن استبدال الـ operator * لا يتكرر إلى ما لا نهاية، فإننا ننتهي ببيانات من النوع i32، والتي تتطابق مع 5 في assert_eq! في القائمة 15-9.
استخدام Deref Coercion في الدوال والـ Methods
الإكراه على إلغاء الإشارة (Deref coercion) يحول reference إلى نوع يطبق سمة Deref إلى reference إلى نوع آخر. على سبيل المثال، يمكن لـ deref coercion تحويل &String إلى &str لأن String تطبق سمة Deref بحيث تُرجع &str. الـ Deref coercion هي ميزة راحة تقوم بها Rust على الوسائط (arguments) لـ functions والـ methods، وتعمل فقط على الـ types التي تطبق سمة Deref. يحدث تلقائيًا عندما نمرر reference إلى قيمة نوع معين كوسيط لـ function أو method لا يتطابق مع نوع الـ parameter في تعريف الـ function أو method. تحول سلسلة من الاستدعاءات لـ method deref النوع الذي قدمناه إلى النوع الذي يحتاجه الـ parameter.
تمت إضافة الـ Deref coercion إلى Rust حتى لا يضطر المبرمجون الذين يكتبون استدعاءات الـ function والـ method إلى إضافة العديد من الـ references و dereferences الصريحة باستخدام & و *. تتيح لنا ميزة deref coercion أيضًا كتابة المزيد من الكود الذي يمكن أن يعمل إما لـ references أو لـ smart pointers.
لرؤية deref coercion أثناء العمل، دعنا نستخدم نوع MyBox<T> الذي عرفناه في القائمة 15-8 بالإضافة إلى تطبيق Deref الذي أضفناه في القائمة 15-10. تُظهر القائمة 15-11 تعريف function يحتوي على string slice parameter.
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {}يمكننا استدعاء الدالة hello باستخدام string slice كوسيط، مثل hello("Rust");، على سبيل المثال. تجعل الـ Deref coercion من الممكن استدعاء hello بـ reference إلى قيمة من النوع MyBox<String>، كما هو موضح في القائمة 15-12.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&m);
}هنا نستدعي الدالة hello بالوسيط &m، وهو reference إلى قيمة MyBox<String>. نظرًا لأننا طبقنا سمة Deref على MyBox<T> في القائمة 15-10، يمكن لـ Rust تحويل &MyBox<String> إلى &String عن طريق استدعاء deref. توفر الـ standard library تطبيقًا لـ Deref على String يُرجع string slice، وهذا موجود في وثائق API لـ Deref. تستدعي Rust deref مرة أخرى لتحويل &String إلى &str، والذي يتطابق مع تعريف الدالة hello.
إذا لم تطبق Rust الـ deref coercion، فسيتعين علينا كتابة الكود في القائمة 15-13 بدلاً من الكود في القائمة 15-12 لاستدعاء hello بقيمة من النوع &MyBox<String>.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&(*m)[..]);
}هذا الكود بدون deref coercions أصعب في القراءة والكتابة والفهم مع كل هذه الرموز المعنية. تسمح الـ Deref coercion لـ Rust بالتعامل مع هذه التحويلات تلقائيًا نيابة عنا.
عندما يتم تعريف سمة Deref للأنواع المعنية، ستحلل Rust الـ types وتستخدم Deref::deref عدة مرات حسب الضرورة للحصول على reference يتطابق مع نوع الـ parameter. يتم حل عدد المرات التي يجب فيها إدراج Deref::deref في الـ compile time، لذلك لا توجد عقوبة في وقت التشغيل للاستفادة من deref coercion!
التعامل مع Deref Coercion باستخدام المراجع القابلة للتغيير (Mutable References)
على غرار كيفية استخدامك لسمة Deref لتجاوز الـ operator * على الـ immutable references، يمكنك استخدام سمة DerefMut لتجاوز الـ operator * على الـ mutable references.
تقوم Rust بـ deref coercion عندما تجد الـ types وتطبيقات الـ trait في ثلاث حالات:
- من
&Tإلى&UعندماT: Deref<Target=U> - من
&mut Tإلى&mut UعندماT: DerefMut<Target=U> - من
&mut Tإلى&UعندماT: Deref<Target=U>
الحالتان الأوليان متماثلتان باستثناء أن الثانية تطبق القابلية للتغيير (mutability). تنص الحالة الأولى على أنه إذا كان لديك &T، وطبق T سمة Deref على نوع ما U، يمكنك الحصول على &U بشفافية. تنص الحالة الثانية على أن نفس الـ deref coercion يحدث لـ mutable references.
الحالة الثالثة أكثر تعقيدًا: ستقوم Rust أيضًا بـ coerce لـ mutable reference إلى immutable reference. لكن العكس غير ممكن: لن يتم أبدًا coerce لـ immutable references إلى mutable references. بسبب قواعد الاقتراض (borrowing rules)، إذا كان لديك mutable reference، فيجب أن يكون هذا الـ mutable reference هو الـ reference الوحيد لتلك البيانات (وإلا فلن يتم تجميع البرنامج). لن يؤدي تحويل mutable reference واحد إلى immutable reference واحد إلى كسر قواعد الاقتراض أبدًا. سيتطلب تحويل immutable reference إلى mutable reference أن يكون الـ immutable reference الأولي هو الـ immutable reference الوحيد لتلك البيانات، لكن قواعد الاقتراض لا تضمن ذلك. لذلك، لا يمكن لـ Rust افتراض أن تحويل immutable reference إلى mutable reference ممكن.
تشغيل الكود عند التنظيف باستخدام سمة Drop
تشغيل الشفرة البرمجية عند التنظيف باستخدام سمة Drop (Drop Trait)
السمة (Trait) الثانية المهمة لنمط المؤشر الذكي (Smart Pointer) هي Drop التي تسمح لك بتخصيص ما يحدث عندما يوشك متغير على الخروج من النطاق (Scope). يمكنك تقديم تنفيذ (Implementation) لـ Drop Trait على أي نوع (Type)، ويمكن استخدام تلك الشفرة البرمجية (Code) لتحرير الموارد (Resources) مثل الملفات أو اتصالات الشبكة.
نحن نقدم Drop في سياق Smart Pointers لأن وظائف Drop Trait تُستخدم دائماً تقريباً عند تنفيذ Smart Pointer. على سبيل المثال، عندما يتم إسقاط (Drop) Box<T> فإنه سيقوم بإلغاء تخصيص (Deallocate) المساحة في الذاكرة الكومة (Heap) التي يشير إليها الصندوق.
في بعض اللغات، وبالنسبة لبعض الأنواع، يجب على المبرمج استدعاء Code لتحرير الذاكرة أو Resources في كل مرة ينتهي فيها من استخدام مثيل (Instance) من تلك الأنواع. تشمل الأمثلة مقابض الملفات (File Handles) والمآخذ (Sockets) والأقفال (Locks). إذا نسي المبرمج ذلك، فقد يصبح النظام محملاً بشكل زائد وينهار. في Rust، يمكنك تحديد تشغيل جزء معين من Code كلما خرجت قيمة من Scope، وسيقوم المترجم (Compiler) بإدراج هذا Code تلقائياً. ونتيجة لذلك، لا تحتاج إلى توخي الحذر بشأن وضع Code التنظيف في كل مكان ينتهي فيه استخدام Instance من Type معين—ولن تسرب الموارد (Leak Resources) أبداً!
تحدد Code المراد تشغيله عندما تخرج قيمة من Scope من خلال تنفيذ Drop Trait. يتطلب منك Drop Trait تنفيذ تابع (Method) واحد يسمى drop يأخذ مرجعاً قابلاً للتعديل (Mutable Reference) لـ self. لرؤية متى تستدعي Rust تابع drop لنقم بتنفيذ drop مع عبارات println! في الوقت الحالي.
تظهر القائمة 15-14 هيكلاً (Struct) باسم CustomSmartPointer وظيفته المخصصة الوحيدة هي أنه سيطبع Dropping CustomSmartPointer! عندما يخرج Instance من Scope، لإظهار متى تقوم Rust بتشغيل Method drop.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("my stuff"),
};
let d = CustomSmartPointer {
data: String::from("other stuff"),
};
println!("CustomSmartPointers created");
}يتم تضمين Drop Trait في التمهيد (Prelude)، لذا لا نحتاج إلى جلبه إلى Scope. نقوم بتنفيذ Drop Trait على CustomSmartPointer ونوفر Implementation لـ Method drop الذي يستدعي println!. جسم (Body) Method drop هو المكان الذي تضع فيه أي منطق (Logic) تريد تشغيله عندما يخرج Instance من نوعك من Scope. نحن نطبع بعض النصوص هنا لتوضيح متى ستستدعي Rust تابع drop بصرياً.
في main ننشئ مثيلين (Instances) من CustomSmartPointer ثم نطبع CustomSmartPointers created. في نهاية main ستخرج Instances الخاصة بنا من CustomSmartPointer عن Scope، وستقوم Rust باستدعاء Code الذي وضعناه في Method drop وطباعة رسالتنا النهائية. لاحظ أننا لم نكن بحاجة لاستدعاء Method drop صراحة.
عند تشغيل هذا البرنامج، سنرى المخرجات (Output) التالية:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!
قامت Rust تلقائياً باستدعاء drop لنا عندما خرجت Instances الخاصة بنا من Scope، مستدعية Code الذي حددناه. يتم إسقاط المتغيرات (Variables) بترتيب عكسي لإنشائها، لذا تم إسقاط d قبل c. الغرض من هذا المثال هو إعطاؤك دليلاً مرئياً حول كيفية عمل Method drop؛ عادةً ما تحدد Code التنظيف الذي يحتاجه نوعك للتشغيل بدلاً من رسالة طباعة.
لسوء الحظ، ليس من السهل تعطيل وظيفة drop التلقائية. لا يكون تعطيل drop ضرورياً عادةً؛ فالمغزى الكامل من Drop Trait هو أنه يتم الاعتناء به تلقائياً. ومع ذلك، قد ترغب أحياناً في تنظيف قيمة مبكراً. أحد الأمثلة هو عند استخدام Smart Pointers التي تدير Locks: قد ترغب في فرض Method drop الذي يحرر القفل حتى يتمكن Code آخر في نفس Scope من الحصول على القفل. لا تسمح لك Rust باستدعاء Method drop الخاص بـ Drop Trait يدوياً؛ بدلاً من ذلك، يتعين عليك استدعاء Function std::mem::drop التي توفرها المكتبة القياسية (Standard Library) إذا كنت تريد فرض إسقاط قيمة قبل نهاية Scope الخاص بها.
محاولة استدعاء Method drop الخاص بـ Drop Trait يدوياً عن طريق تعديل Function main من القائمة 15-14 لن تنجح، كما هو موضح في القائمة 15-15.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
c.drop();
println!("CustomSmartPointer dropped before the end of main");
}عندما نحاول ترجمة (Compile) هذا Code، سنحصل على هذا الخطأ (Error):
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
16 - c.drop();
16 + drop(c);
|
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` (bin "drop-example") due to 1 previous error
تنص رسالة Error هذه على أنه لا يُسمح لنا باستدعاء drop صراحة. تستخدم رسالة الخطأ مصطلح المُهدم (Destructor)، وهو المصطلح البرمجي العام لـ Function تقوم بتنظيف Instance. يعتبر Destructor مناظراً لـ المُنشئ (Constructor) الذي ينشئ Instance. دالة drop في Rust هي Destructor واحد محدد.
لا تسمح لنا Rust باستدعاء drop صراحة، لأن Rust ستستمر في استدعاء drop تلقائياً على القيمة في نهاية main. سيؤدي هذا إلى خطأ التحرير المزدوج (Double Free Error) لأن Rust ستحاول تنظيف نفس القيمة مرتين.
لا يمكننا تعطيل الإدراج التلقائي لـ drop عندما تخرج قيمة من Scope، ولا يمكننا استدعاء Method drop صراحة. لذا، إذا كنا بحاجة إلى فرض تنظيف قيمة مبكراً، فإننا نستخدم Function std::mem::drop.
تختلف Function std::mem::drop عن Method drop في Drop Trait. نستدعيها عن طريق تمرير القيمة التي نريد فرض إسقاطها كوسيط (Argument). توجد Function في Prelude، لذا يمكننا تعديل main في القائمة 15-15 لاستدعاء Function drop كما هو موضح في القائمة 15-16.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
drop(c);
println!("CustomSmartPointer dropped before the end of main");
}سيؤدي تشغيل هذا Code إلى طباعة ما يلي:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main
تتم طباعة النص Dropping CustomSmartPointer with data `some data`! بين نص CustomSmartPointer created و CustomSmartPointer dropped before the end of main مما يوضح أنه يتم استدعاء Code الخاص بـ Method drop لإسقاط c عند تلك النقطة.
يمكنك استخدام Code المحدد في تنفيذ Drop Trait بعدة طرق لجعل التنظيف مريحاً وآمناً: على سبيل المثال، يمكنك استخدامه لإنشاء مخصص ذاكرة (Memory Allocator) خاص بك! مع Drop Trait ونظام الملكية (Ownership System) في Rust، لا يتعين عليك تذكر القيام بالتنظيف، لأن Rust تقوم بذلك تلقائياً.
كما لا داعي للقلق بشأن المشكلات الناتجة عن تنظيف القيم التي لا تزال قيد الاستخدام عن طريق الخطأ: فنظام الملكية الذي يضمن أن References صالحة دائماً يضمن أيضاً استدعاء drop مرة واحدة فقط عندما لا تعود القيمة قيد الاستخدام.
الآن بعد أن فحصنا Box<T> وبعض خصائص Smart Pointers، دعنا نلقي نظرة على عدد قليل من Smart Pointers الأخرى المعرفة في Standard Library.
Rc، المؤشر الذكي لعد المراجع
Rc<T>، المؤشر الذكي لعد المراجع (Rc<T>, the Reference-Counted Smart Pointer)
في أغلب الحالات، تكون الملكية (ownership) واضحة: أنت تعرف بالضبط أي متغير يمتلك قيمة معينة. ومع ذلك، هناك حالات قد يكون فيها للقيمة الواحدة عدة ملاك. على سبيل المثال، في هياكل بيانات الرسم البياني (graph data structures)، قد تشير عدة حواف (edges) إلى نفس العقدة (node)، وتكون تلك العقدة مملوكة مفاهيميًا لجميع الحواف التي تشير إليها. لا ينبغي تنظيف العقدة ما لم تكن هناك أي حواف تشير إليها وبالتالي ليس لها ملاك.
يجب عليك تمكين الملكية المتعددة (multiple ownership) صراحةً باستخدام نوع Rust المسمى Rc<T>، وهو اختصار لـ عد المراجع (reference counting). يتتبع النوع Rc<T> عدد المراجع لقيمة ما لتحديد ما إذا كانت القيمة لا تزال قيد الاستخدام أم لا. إذا كان هناك صفر من المراجع لقيمة ما، فيمكن تنظيف القيمة دون أن تصبح أي مراجع غير صالحة.
تخيل Rc<T> كجهاز تلفزيون في غرفة العائلة. عندما يدخل شخص واحد لمشاهدة التلفزيون، فإنه يقوم بتشغيله. يمكن للآخرين الدخول إلى الغرفة ومشاهدة التلفزيون. عندما يغادر آخر شخص الغرفة، فإنه يطفئ التلفزيون لأنه لم يعد قيد الاستخدام. إذا قام شخص ما بإطفاء التلفزيون بينما لا يزال الآخرون يشاهدونه، فستحدث ضجة من مشاهدي التلفزيون المتبقين!
نستخدم النوع Rc<T> عندما نريد تخصيص بعض البيانات على الكومة (heap) لأجزاء متعددة من برنامجنا لقراءتها ولا يمكننا تحديد وقت الترجمة (compile time) أي جزء سينتهي من استخدام البيانات آخراً. إذا كنا نعرف أي جزء سينتهي آخراً، فيمكننا ببساطة جعل هذا الجزء هو مالك البيانات، وستدخل قواعد الملكية العادية المفروضة في وقت الترجمة حيز التنفيذ.
لاحظ أن Rc<T> مخصص للاستخدام فقط في سيناريوهات الخيط الواحد (single-threaded). عندما نناقش التزامن (concurrency) في الفصل 16، سنغطي كيفية إجراء عد المراجع في البرامج متعددة الخيوط (multithreaded).
مشاركة البيانات (Sharing Data)
دعنا نعود إلى مثال قائمة cons في القائمة 15-5. تذكر أننا عرفناها باستخدام Box<T>. هذه المرة، سننشئ قائمتين تشتركان في ملكية قائمة ثالثة. مفاهيميًا، يبدو هذا مشابهًا للشكل 15-3.

الشكل 15-3: قائمتان، b و c تشتركان في ملكية قائمة ثالثة، a
سننشئ القائمة a التي تحتوي على 5 ثم 10. بعد ذلك، سننشئ قائمتين إضافيتين: b التي تبدأ بـ 3 و c التي تبدأ بـ 4. ستستمر كل من القائمتين b و c بعد ذلك إلى القائمة a الأولى التي تحتوي على 5 و 10. بمعنى آخر، ستشترك كلتا القائمتين في القائمة الأولى التي تحتوي على 5 و 10.
محاولة تنفيذ هذا السيناريو باستخدام تعريفنا لـ List مع Box<T> لن تنجح، كما هو موضح في القائمة 15-17.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}عندما نترجم هذا الكود، نحصل على هذا الخطأ:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
|
note: if `List` implemented `Clone`, you could clone the value
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^ consider implementing `Clone` for this type
...
10 | let b = Cons(3, Box::new(a));
| - you could clone this value
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` (bin "cons-list") due to 1 previous error
تمتلك متغيرات Cons البيانات التي تحملها، لذا عندما ننشئ القائمة b يتم نقل a إلى b وتمتلك b القائمة a. بعد ذلك، عندما نحاول استخدام a مرة أخرى عند إنشاء c لا يُسمح لنا بذلك لأن a قد تم نقلها.
يمكننا تغيير تعريف Cons ليحمل مراجع (references) بدلاً من ذلك، ولكن سيتعين علينا حينها تحديد معاملات مدة الحياة (lifetime parameters). من خلال تحديد معاملات مدة الحياة، سنحدد أن كل عنصر في القائمة سيعيش على الأقل طالما تعيش القائمة بأكملها. هذا هو الحال بالنسبة للعناصر والقوائم في القائمة 15-17، ولكن ليس في كل سيناريو.
بدلاً من ذلك، سنغير تعريفنا لـ List لاستخدام Rc<T> بدلاً من Box<T> كما هو موضح في القائمة 15-18. سيحمل كل متغير Cons الآن قيمة و Rc<T> يشير إلى List. عندما ننشئ b بدلاً من أخذ ملكية a سنقوم باستنساخ (clone) الـ Rc<List> الذي يحمله a وبذلك نزيد عدد المراجع من واحد إلى اثنين ونسمح لـ a و b بمشاركة ملكية البيانات في ذلك الـ Rc<List>. سنقوم أيضًا باستنساخ a عند إنشاء c مما يزيد عدد المراجع من اثنين إلى ثلاثة. في كل مرة نستدعي فيها Rc::clone سيزداد عدد المراجع للبيانات داخل Rc<List> ولن يتم تنظيف البيانات ما لم يكن هناك صفر من المراجع إليها.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
}نحتاج إلى إضافة عبارة use لجلب Rc<T> إلى النطاق (scope) لأنه ليس في التمهيد (prelude). في main ننشئ القائمة التي تحمل 5 و 10 ونخزنها في Rc<List> جديد في a. بعد ذلك، عندما ننشئ b و c نستدعي دالة Rc::clone ونمرر مرجعًا إلى Rc<List> في a كمعامل.
كان بإمكاننا استدعاء a.clone() بدلاً من Rc::clone(&a) ولكن عرف Rust هو استخدام Rc::clone في هذه الحالة. لا يقوم تنفيذ Rc::clone بعمل نسخة عميقة (deep copy) لجميع البيانات كما تفعل تنفيذات clone لمعظم الأنواع. استدعاء Rc::clone يزيد فقط من عداد المراجع، وهو ما لا يستغرق الكثير من الوقت. يمكن أن تستغرق النسخ العميقة للبيانات الكثير من الوقت. باستخدام Rc::clone لعد المراجع، يمكننا التمييز بصريًا بين أنواع النسخ العميقة من الاستنساخ وأنواع الاستنساخ التي تزيد من عداد المراجع. عند البحث عن مشاكل الأداء في الكود، نحتاج فقط إلى مراعاة استنساخ النسخ العميق ويمكننا تجاهل استدعاءات Rc::clone.
الاستنساخ لزيادة عداد المراجع (Cloning to Increase the Reference Count)
دعنا نغير مثالنا العملي في القائمة 15-18 حتى نتمكن من رؤية عدادات المراجع تتغير بينما ننشئ ونسقط المراجع إلى Rc<List> في a.
في القائمة 15-19، سنغير main بحيث يكون لها نطاق داخلي حول القائمة c؛ ثم يمكننا رؤية كيف يتغير عداد المراجع عندما تخرج c عن النطاق.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
// --snip--
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
println!("count after creating a = {}", Rc::strong_count(&a));
let b = Cons(3, Rc::clone(&a));
println!("count after creating b = {}", Rc::strong_count(&a));
{
let c = Cons(4, Rc::clone(&a));
println!("count after creating c = {}", Rc::strong_count(&a));
}
println!("count after c goes out of scope = {}", Rc::strong_count(&a));
}في كل نقطة في البرنامج حيث يتغير عداد المراجع، نقوم بطباعة عداد المراجع، والذي نحصل عليه من خلال استدعاء دالة Rc::strong_count. تمت تسمية هذه الدالة strong_count بدلاً من count لأن النوع Rc<T> يحتوي أيضًا على weak_count؛ سنرى فيمَ يُستخدم weak_count في “منع دورات المراجع باستخدام Weak<T>”.
يطبع هذا الكود ما يلي:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
يمكننا أن نرى أن Rc<List> في a له عداد مراجع أولي قدره 1؛ ثم في كل مرة نستدعي فيها clone يرتفع العداد بمقدار 1. عندما تخرج c عن النطاق، ينخفض العداد بمقدار 1. ليس علينا استدعاء دالة لتقليل عداد المراجع كما يتعين علينا استدعاء Rc::clone لزيادة عداد المراجع: يقوم تنفيذ سمة Drop (Drop trait) بتقليل عداد المراجع تلقائيًا عندما تخرج قيمة Rc<T> عن النطاق.
ما لا يمكننا رؤيته في هذا المثال هو أنه عندما تخرج b ثم a عن النطاق في نهاية main يكون العداد 0، ويتم تنظيف Rc<List> تمامًا. يسمح استخدام Rc<T> لقيمة واحدة بامتلاك عدة ملاك، ويضمن العداد بقاء القيمة صالحة طالما بقي أي من الملاك موجودًا.
عبر المراجع غير القابلة للتغيير (immutable references)، يسمح لك Rc<T> بمشاركة البيانات بين أجزاء متعددة من برنامجك للقراءة فقط. إذا كان Rc<T> يسمح لك بامتلاك مراجع متعددة قابلة للتغيير (mutable references) أيضًا، فقد تنتهك إحدى قواعد الاستعارة (borrowing rules) التي نوقشت في الفصل 4: يمكن أن تؤدي الاستعارات المتعددة القابلة للتغيير لنفس المكان إلى سباقات البيانات (data races) وعدم الاتساق. لكن القدرة على تغيير البيانات مفيدة جدًا! في القسم التالي، سنناقش نمط القابلية للتغيير الداخلية (interior mutability pattern) والنوع RefCell<T> الذي يمكنك استخدامه بالاقتران مع Rc<T> للعمل مع قيد عدم القابلية للتغيير هذا.
RefCell ونمط القابلية للتغيير الداخلي (Interior Mutability)
RefCell<T> ونمط القابلية للتغيير الداخلية (Interior Mutability Pattern)
“القابلية للتغيير الداخلية” (Interior Mutability) هي نمط تصميم في Rust يسمح لك بتغيير البيانات حتى عندما تكون هناك مراجع غير قابلة للتغيير (Immutable References) لتلك البيانات؛ عادةً ما يكون هذا الإجراء غير مسموح به بموجب قواعد الاستعارة (Borrowing Rules). لتغيير البيانات، يستخدم هذا النمط كوداً “غير آمن” (Unsafe Code) داخل هيكل البيانات لثني قواعد Rust المعتادة التي تحكم التغيير والاستعارة. يشير الكود الـ Unsafe للمترجم (Compiler) إلى أننا نتحقق من القواعد يدوياً بدلاً من الاعتماد على الـ Compiler للتحقق منها نيابة عنا؛ سنناقش الكود الـ Unsafe بشكل أكبر في الفصل 20.
يمكننا استخدام الأنواع التي تتبع نمط الـ Interior Mutability فقط عندما نتمكن من ضمان اتباع الـ Borrowing Rules في وقت التشغيل (Runtime)، على الرغم من أن الـ Compiler لا يمكنه ضمان ذلك. يتم بعد ذلك تغليف الكود الـ Unsafe المعني بواجهة برمجية (API) آمنة، ويظل النوع الخارجي غير قابل للتغيير (Immutable).
دعنا نستكشف هذا المفهوم من خلال النظر في النوع RefCell<T> الذي يتبع نمط الـ Interior Mutability.
فرض قواعد الاستعارة في وقت التشغيل (Runtime)
على عكس Rc<T>، يمثل النوع RefCell<T> ملكية فردية (Single Ownership) للبيانات التي يحملها. إذاً، ما الذي يجعل RefCell<T> مختلفاً عن نوع مثل Box<T>؟ تذكر الـ Borrowing Rules التي تعلمتها في الفصل 4:
- في أي وقت معين، يمكنك الحصول على مرجع واحد قابل للتغيير (Mutable Reference) أو أي عدد من الـ Immutable References (ولكن ليس كلاهما معاً).
- يجب أن تكون المراجع (References) صالحة دائماً.
مع الـ References و Box<T>، يتم فرض ثوابت الـ Borrowing Rules في وقت التجميع (Compile Time). أما مع RefCell<T>، فيتم فرض هذه الثوابت في وقت التشغيل (Runtime). مع الـ References، إذا خالفت هذه القواعد، فستحصل على خطأ من الـ Compiler. أما مع RefCell<T>، فإذا خالفت هذه القواعد، فسوف يهلع (Panic) برنامجك ويخرج.
تتمثل مزايا التحقق من الـ Borrowing Rules في الـ Compile Time في أنه سيتم اكتشاف الأخطاء في وقت مبكر من عملية التطوير، ولا يوجد أي تأثير على أداء الـ Runtime لأن كل التحليل يكتمل مسبقاً. لهذه الأسباب، يعد التحقق من الـ Borrowing Rules في الـ Compile Time هو الخيار الأفضل في غالبية الحالات، ولهذا السبب هو الخيار الافتراضي في Rust.
تتمثل ميزة التحقق من الـ Borrowing Rules في الـ Runtime بدلاً من ذلك في السماح ببعض سيناريوهات أمان الذاكرة (Memory-safe)، حيث كان سيتم رفضها بواسطة فحوصات الـ Compile Time. التحليل الساكن (Static Analysis)، مثل مترجم Rust، هو محافظ بطبيعته. بعض خصائص الكود مستحيلة الاكتشاف من خلال تحليل الكود: المثال الأكثر شهرة هو “مشكلة التوقف” (Halting Problem)، وهي خارج نطاق هذا الكتاب ولكنها موضوع مثير للبحث.
بسبب استحالة بعض التحليلات، إذا لم يتمكن مترجم Rust من التأكد من امتثال الكود لقواعد الملكية (Ownership Rules)، فقد يرفض برنامجاً صحيحاً؛ وبهذه الطريقة، يكون المترجم محافظاً. إذا قبلت Rust برنامجاً غير صحيح، فلن يتمكن المستخدمون من الوثوق بالضمانات التي تقدمها Rust. ومع ذلك، إذا رفضت Rust برنامجاً صحيحاً، فسوف ينزعج المبرمج، ولكن لن يحدث أي شيء كارثي. يكون النوع RefCell<T> مفيداً عندما تكون متأكداً من أن الكود الخاص بك يتبع الـ Borrowing Rules ولكن الـ Compiler غير قادر على فهم ذلك وضمانه.
على غرار Rc<T>، فإن RefCell<T> مخصص للاستخدام فقط في السيناريوهات أحادية المسار (Single-threaded) وسيعطيك خطأ في الـ Compile Time إذا حاولت استخدامه في سياق متعدد المسارات (Multithreaded). سنتحدث عن كيفية الحصول على وظائف RefCell<T> في برنامج Multithreaded في الفصل 16.
إليك ملخص لأسباب اختيار Box<T> أو Rc<T> أو RefCell<T>:
- يسمح
Rc<T>بوجود مالكين متعددين لنفس البيانات؛ بينما يمتلكBox<T>وRefCell<T>مالكاً واحداً فقط. - يسمح
Box<T>باستعارات غير قابلة للتغيير أو قابلة للتغيير يتم فحصها في الـ Compile Time؛ ويسمحRc<T>فقط بالاستعارات غير القابلة للتغيير التي يتم فحصها في الـ Compile Time؛ بينما يسمحRefCell<T>باستعارات غير قابلة للتغيير أو قابلة للتغيير يتم فحصها في الـ Runtime. - لأن
RefCell<T>يسمح باستعارات قابلة للتغيير (Mutable Borrows) يتم فحصها في الـ Runtime، يمكنك تغيير القيمة داخلRefCell<T>حتى عندما يكون الـRefCell<T>نفسه غير قابل للتغيير.
تغيير القيمة داخل قيمة غير قابلة للتغيير هو نمط الـ Interior Mutability. دعنا ننظر في موقف تكون فيه الـ Interior Mutability مفيدة ونفحص كيف يكون ذلك ممكناً.
استخدام القابلية للتغيير الداخلية (Interior Mutability)
من نتائج الـ Borrowing Rules أنه عندما يكون لديك قيمة غير قابلة للتغيير، لا يمكنك استعارتها بشكل قابل للتغيير. على سبيل المثال، لن يتم تجميع هذا الكود:
fn main() {
let x = 5;
let y = &mut x;
}إذا حاولت تجميع هذا الكود، فستحصل على الخطأ التالي:
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` (bin "borrowing") due to 1 previous error
ومع ذلك، هناك مواقف يكون من المفيد فيها أن تقوم القيمة بتغيير نفسها في دوالها المرتبطة (Methods) ولكنها تظهر غير قابلة للتغيير للكود الآخر. لن يتمكن الكود الموجود خارج الـ Methods الخاصة بالقيمة من تغيير القيمة. استخدام RefCell<T> هو إحدى الطرق للحصول على القدرة على امتلاك Interior Mutability، ولكن RefCell<T> لا يلتف على الـ Borrowing Rules تماماً: يسمح الـ Borrow Checker في الـ Compiler بهذه الـ Interior Mutability، ويتم التحقق من الـ Borrowing Rules في الـ Runtime بدلاً من ذلك. إذا انتهكت القواعد، فستحصل على panic! بدلاً من خطأ الـ Compiler.
دعنا نمر بمثال عملي حيث يمكننا استخدام RefCell<T> لتغيير قيمة غير قابلة للتغيير ونرى لماذا يعد ذلك مفيداً.
الاختبار باستخدام الكائنات الوهمية (Mock Objects)
أحياناً أثناء الاختبار، يستخدم المبرمج نوعاً بدلاً من نوع آخر، من أجل مراقبة سلوك معين والتأكد من تنفيذه بشكل صحيح. يسمى هذا النوع البديل “بديل الاختبار” (Test Double). فكر في الأمر بمعنى “البديل السينمائي” (Stunt Double) في صناعة الأفلام، حيث يحل شخص محل الممثل للقيام بمشهد صعب بشكل خاص. تحل الـ Test Doubles محل الأنواع الأخرى عندما نقوم بتشغيل الاختبارات. “الكائنات الوهمية” (Mock Objects) هي أنواع محددة من الـ Test Doubles التي تسجل ما يحدث أثناء الاختبار حتى تتمكن من التأكد من حدوث الإجراءات الصحيحة.
لا تمتلك Rust كائنات (Objects) بنفس المعنى الموجود في اللغات الأخرى، ولا تمتلك Rust وظائف Mock Object مدمجة في المكتبة القياسية (Standard Library) كما تفعل بعض اللغات الأخرى. ومع ذلك، يمكنك بالتأكيد إنشاء هيكل (Struct) يخدم نفس أغراض الـ Mock Object.
إليك السيناريو الذي سنختبره: سننشئ مكتبة تتبع قيمة مقابل قيمة قصوى وترسل رسائل بناءً على مدى قرب القيمة الحالية من القيمة القصوى. يمكن استخدام هذه المكتبة لتتبع حصة (Quota) المستخدم لعدد استدعاءات الـ API المسموح له بإجرائها، على سبيل المثال.
ستوفر مكتبتنا فقط وظيفة تتبع مدى قرب القيمة من الحد الأقصى وما هي الرسائل التي يجب أن تكون في أي أوقات. من المتوقع أن توفر التطبيقات التي تستخدم مكتبتنا آلية إرسال الرسائل: يمكن للتطبيق إظهار الرسالة للمستخدم مباشرة، أو إرسال بريد إلكتروني، أو إرسال رسالة نصية، أو القيام بشيء آخر. لا تحتاج المكتبة إلى معرفة هذا التفصيل. كل ما تحتاجه هو شيء ينفذ سمة (Trait) سنوفرها، تسمى Messenger. توضح القائمة 15-20 كود المكتبة.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}أحد الأجزاء المهمة في هذا الكود هو أن الـ Messenger Trait يحتوي على Method واحدة تسمى send تأخذ Immutable Reference لـ self ونص الرسالة. هذا الـ Trait هو الواجهة التي يحتاج الـ Mock Object الخاص بنا إلى تنفيذها بحيث يمكن استخدام الـ Mock بنفس الطريقة التي يستخدم بها الكائن الحقيقي. الجزء المهم الآخر هو أننا نريد اختبار سلوك الـ set_value Method في الـ LimitTracker. يمكننا تغيير ما نمرره لمعامل value ولكن set_value لا تعيد أي شيء لكي نقوم بإجراء تأكيدات (Assertions) عليه. نريد أن نكون قادرين على القول إنه إذا أنشأنا LimitTracker بشيء ينفذ الـ Messenger Trait وقيمة معينة لـ max فسيتم إخبار الـ Messenger بإرسال الرسائل المناسبة عندما نمرر أرقاماً مختلفة لـ value.
نحتاج إلى Mock Object يقوم، بدلاً من إرسال بريد إلكتروني أو رسالة نصية عندما نستدعي send بتتبع الرسائل التي طُلب منه إرسالها فقط. يمكننا إنشاء نسخة جديدة من الـ Mock Object، وإنشاء LimitTracker يستخدم الـ Mock Object، واستدعاء الـ set_value Method في LimitTracker ثم التحقق من أن الـ Mock Object يحتوي على الرسائل التي نتوقعها. توضح القائمة 15-21 محاولة لتنفيذ Mock Object للقيام بذلك، لكن الـ Borrow Checker لن يسمح بذلك.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}يعرف كود الاختبار هذا Struct باسم MockMessenger يحتوي على حقل sent_messages مع Vec من قيم String لتتبع الرسائل التي طُلب منه إرسالها. كما نعرف دالة مرتبطة new لجعل إنشاء قيم MockMessenger جديدة تبدأ بقائمة فارغة من الرسائل أمراً مريحاً. ثم نقوم بتنفيذ الـ Messenger Trait لـ MockMessenger حتى نتمكن من إعطاء MockMessenger لـ LimitTracker. في تعريف الـ send Method، نأخذ الرسالة الممررة كمعامل ونخزنها في قائمة sent_messages الخاصة بالـ MockMessenger.
في الاختبار، نختبر ما يحدث عندما يُطلب من الـ LimitTracker تعيين value لشيء يمثل أكثر من 75 بالمائة من قيمة max. أولاً، ننشئ MockMessenger جديداً، والذي سيبدأ بقائمة فارغة من الرسائل. ثم ننشئ LimitTracker جديداً ونعطيه مرجعاً للـ MockMessenger الجديد وقيمة max قدرها 100. نستدعي الـ set_value Method في الـ LimitTracker بقيمة 80 وهي أكثر من 75 بالمائة من 100. ثم نؤكد أن قائمة الرسائل التي يتتبعها الـ MockMessenger يجب أن تحتوي الآن على رسالة واحدة.
ومع ذلك، هناك مشكلة واحدة في هذا الاختبار، كما هو موضح هنا:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference in the `impl` method and the `trait` definition
|
2 ~ fn send(&mut self, msg: &str);
3 | }
...
56 | impl Messenger for MockMessenger {
57 ~ fn send(&mut self, message: &str) {
|
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` (lib test) due to 1 previous error
لا يمكننا تعديل الـ MockMessenger لتتبع الرسائل، لأن الـ send Method تأخذ Immutable Reference لـ self. لا يمكننا أيضاً أخذ الاقتراح من نص الخطأ باستخدام &mut self في كل من الـ impl Method وتعريف الـ Trait. نحن لا نريد تغيير الـ Messenger Trait لمجرد مصلحة الاختبار. بدلاً من ذلك، نحتاج إلى إيجاد طريقة لجعل كود الاختبار الخاص بنا يعمل بشكل صحيح مع تصميمنا الحالي.
هذا موقف يمكن أن تساعد فيه الـ Interior Mutability! سنقوم بتخزين الـ sent_messages داخل RefCell<T> وبعد ذلك ستتمكن الـ send Method من تعديل sent_messages لتخزين الرسائل التي رأيناها. توضح القائمة 15-22 كيف يبدو ذلك.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}أصبح حقل sent_messages الآن من النوع RefCell<Vec<String>> بدلاً من Vec<String>. في دالة new ننشئ نسخة RefCell<Vec<String>> جديدة حول الـ Vector الفارغ.
بالنسبة لتنفيذ الـ send Method، لا يزال المعامل الأول عبارة عن استعارة غير قابلة للتغيير (Immutable Borrow) لـ self وهو ما يطابق تعريف الـ Trait. نستدعي borrow_mut على الـ RefCell<Vec<String>> في self.sent_messages للحصول على مرجع قابل للتغيير (Mutable Reference) للقيمة الموجودة داخل الـ RefCell<Vec<String>> وهي الـ Vector. بعد ذلك، يمكننا استدعاء push على الـ Mutable Reference للـ Vector لتتبع الرسائل المرسلة أثناء الاختبار.
التغيير الأخير الذي يتعين علينا إجراؤه هو في الـ Assertion: لمعرفة عدد العناصر الموجودة في الـ Vector الداخلي، نستدعي borrow على الـ RefCell<Vec<String>> للحصول على Immutable Reference للـ Vector.
الآن بعد أن رأيت كيفية استخدام RefCell<T> دعنا نتعمق في كيفية عمله!
تتبع الاستعارات في وقت التشغيل (Runtime)
عند إنشاء Immutable References و Mutable References، نستخدم صيغة & و &mut على التوالي. مع RefCell<T> نستخدم دالتي borrow و borrow_mut وهما جزء من الـ API الآمن الذي ينتمي لـ RefCell<T>. تعيد دالة borrow نوع المؤشر الذكي (Smart Pointer) المسمى Ref<T> وتعيد borrow_mut نوع الـ Smart Pointer المسمى RefMut<T>. ينفذ كلا النوعين سمة Deref لذا يمكننا معاملتهما مثل الـ References العادية.
يتتبع RefCell<T> عدد الـ Smart Pointers من نوع Ref<T> و RefMut<T> النشطة حالياً. في كل مرة نستدعي فيها borrow يزيد RefCell<T> من عداد الاستعارات غير القابلة للتغيير النشطة. عندما تخرج قيمة Ref<T> عن الـ Scope، ينخفض عداد الـ Immutable Borrows بمقدار 1. تماماً مثل الـ Borrowing Rules في الـ Compile Time، يسمح لنا RefCell<T> بامتلاك العديد من الـ Immutable Borrows أو Mutable Borrow واحد في أي نقطة زمنية.
إذا حاولنا انتهاك هذه القواعد، فبدلاً من الحصول على خطأ من الـ Compiler كما هو الحال مع الـ References، فإن تنفيذ RefCell<T> سوف يهلع (Panic) في الـ Runtime. توضح القائمة 15-23 تعديلاً لتنفيذ send في القائمة 15-22. نحن نحاول عمداً إنشاء استعارتين قابلتين للتغيير نشطتين لنفس الـ Scope لتوضيح أن RefCell<T> يمنعنا من القيام بذلك في الـ Runtime.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}ننشئ متغيراً one_borrow للـ RefMut<T> Smart Pointer المرتجع من borrow_mut. ثم ننشئ Mutable Borrow آخر بنفس الطريقة في المتغير two_borrow. هذا يؤدي لإنشاء مرجعين قابلين للتغيير في نفس الـ Scope، وهو أمر غير مسموح به. عندما نقوم بتشغيل الاختبارات لمكتبتنا، سيتم تجميع الكود في القائمة 15-23 دون أي أخطاء، لكن الاختبار سيفشل:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at src/lib.rs:60:53:
RefCell already borrowed
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
لاحظ أن الكود هلع مع الرسالة already borrowed: BorrowMutError. هذه هي الطريقة التي يتعامل بها RefCell<T> مع انتهاكات الـ Borrowing Rules في الـ Runtime.
إن اختيار اكتشاف أخطاء الاستعارة في الـ Runtime بدلاً من الـ Compile Time، كما فعلنا هنا، يعني أنك قد تجد أخطاء في الكود الخاص بك في وقت لاحق من عملية التطوير: ربما ليس حتى يتم نشر الكود الخاص بك في بيئة الإنتاج (Production). أيضاً، سيتحمل الكود الخاص بك عقوبة أداء بسيطة في الـ Runtime نتيجة لتتبع الاستعارات في الـ Runtime بدلاً من الـ Compile Time. ومع ذلك، فإن استخدام RefCell<T> يجعل من الممكن كتابة Mock Object يمكنه تعديل نفسه لتتبع الرسائل التي رآها أثناء استخدامه في سياق لا يُسمح فيه إلا بالقيم غير القابلة للتغيير. يمكنك استخدام RefCell<T> على الرغم من مقايضاته للحصول على وظائف أكثر مما توفره الـ References العادية.
السماح بمالكين متعددين للبيانات القابلة للتغيير
الطريقة الشائعة لاستخدام RefCell<T> هي بالاشتراك مع Rc<T>. تذكر أن Rc<T> يسمح لك بامتلاك مالكين متعددين لبعض البيانات، ولكنه يمنح فقط وصولاً غير قابل للتغيير لتلك البيانات. إذا كان لديك Rc<T> يحمل RefCell<T> فيمكنك الحصول على قيمة يمكن أن يكون لها مالكون متعددون و يمكنك تغييرها!
على سبيل المثال، تذكر مثال قائمة الـ Cons في القائمة 15-18 حيث استخدمنا Rc<T> للسماح لقوائم متعددة بمشاركة ملكية قائمة أخرى. لأن Rc<T> يحمل فقط قيماً غير قابلة للتغيير، لا يمكننا تغيير أي من القيم في القائمة بمجرد إنشائها. دعنا نضيف RefCell<T> لقدرته على تغيير القيم في القوائم. توضح القائمة 15-24 أنه باستخدام RefCell<T> في تعريف الـ Cons يمكننا تعديل القيمة المخزنة في جميع القوائم.
#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a));
*value.borrow_mut() += 10;
println!("a after = {a:?}");
println!("b after = {b:?}");
println!("c after = {c:?}");
}ننشئ قيمة هي نسخة من Rc<RefCell<i32>> ونخزنها في متغير باسم value حتى نتمكن من الوصول إليها مباشرة لاحقاً. ثم ننشئ List في a مع تنويعة Cons تحمل value. نحتاج إلى استنساخ (Clone) لـ value بحيث يمتلك كل من a و value ملكية القيمة الداخلية 5 بدلاً من نقل الملكية من value إلى a أو جعل a يستعير من value.
نغلف القائمة a في Rc<T> بحيث عندما ننشئ القائمتين b و c يمكنهما الإشارة إلى a وهو ما فعلناه في القائمة 15-18.
بعد أن أنشأنا القوائم في a و b و c نريد إضافة 10 إلى القيمة الموجودة في value. نقوم بذلك عن طريق استدعاء borrow_mut على value والذي يستخدم ميزة إلغاء الإسناد التلقائي (Automatic Dereferencing) التي ناقشناها في قسم “أين هو عامل ->؟” في الفصل 5 لإلغاء إسناد الـ Rc<T> إلى قيمة الـ RefCell<T> الداخلية. تعيد دالة borrow_mut مؤشراً ذكياً من نوع RefMut<T> ونستخدم عامل إلغاء الإسناد (Dereference Operator) عليه ونغير القيمة الداخلية.
عندما نطبع a و b و c يمكننا أن نرى أنها جميعاً تحتوي على القيمة المعدلة 15 بدلاً من 5:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
هذه التقنية رائعة جداً! باستخدام RefCell<T> لدينا قيمة List تبدو من الخارج غير قابلة للتغيير. ولكن يمكننا استخدام الـ Methods في RefCell<T> التي توفر وصولاً إلى الـ Interior Mutability الخاصة بها حتى نتمكن من تعديل بياناتنا عندما نحتاج إلى ذلك. تحمينا فحوصات الـ Runtime للـ Borrowing Rules من “تسابق البيانات” (Data Races)، وأحياناً يستحق الأمر التضحية ببعض السرعة مقابل هذه المرونة في هياكل بياناتنا. لاحظ أن RefCell<T> لا يعمل مع الكود متعدد المسارات (Multithreaded)! الـ Mutex<T> هو النسخة الآمنة للمسارات (Thread-safe) من RefCell<T> وسنناقش Mutex<T> في الفصل 16.
دورات المراجع يمكن أن تسرب الذاكرة (Memory Leak)
دورات المراجع يمكن أن تسرب الذاكرة (Reference Cycles Can Leak Memory)
تجعل ضمانات سلامة الذاكرة في Rust من الصعب، ولكن ليس من المستحيل، إنشاء ذاكرة لا يتم تنظيفها أبداً عن طريق الخطأ (ما يعرف باسم تسرب الذاكرة (memory leak)). إن منع تسرب الذاكرة تماماً ليس أحد ضمانات Rust، مما يعني أن تسرب الذاكرة يعتبر آمناً من حيث الذاكرة (memory safe) في Rust. يمكننا أن نرى أن Rust يسمح بتسرب الذاكرة باستخدام Rc<T> و RefCell<T>: من الممكن إنشاء مراجع حيث تشير العناصر إلى بعضها البعض في دورة (cycle). يؤدي هذا إلى حدوث memory leaks لأن عدد المراجع (reference count) لكل عنصر في الدورة لن يصل أبداً إلى 0، ولن يتم إسقاط (drop) القيم أبداً.
إنشاء دورة مراجع (Creating a Reference Cycle)
دعونا نلقي نظرة على كيفية حدوث دورة مراجع وكيفية منعها، بدءاً من تعريف التعداد List ودالة tail في القائمة 15-25.
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {}نحن نستخدم تنويعاً آخر لتعريف List من القائمة 15-5. العنصر الثاني في متغير Cons هو الآن RefCell<Rc<List>> ، مما يعني أنه بدلاً من امتلاك القدرة على تعديل قيمة i32 كما فعلنا في القائمة 15-24، نريد تعديل قيمة List التي يشير إليها متغير Cons. نضيف أيضاً دالة tail لتسهيل الوصول إلى العنصر الثاني إذا كان لدينا متغير Cons.
في القائمة 15-26، نضيف دالة main تستخدم التعريفات الموجودة في القائمة 15-25. ينشئ هذا الكود قائمة في a وقائمة في b تشير إلى القائمة في a. ثم يقوم بتعديل القائمة في a لتشير إلى b ، مما يؤدي إلى إنشاء دورة مراجع (reference cycle). توجد عبارات println! على طول الطريق لتوضيح عدد المراجع في نقاط مختلفة من هذه العملية.
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {
let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil))));
println!("a initial rc count = {}", Rc::strong_count(&a));
println!("a next item = {:?}", a.tail());
let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a))));
println!("a rc count after b creation = {}", Rc::strong_count(&a));
println!("b initial rc count = {}", Rc::strong_count(&b));
println!("b next item = {:?}", b.tail());
if let Some(link) = a.tail() {
*link.borrow_mut() = Rc::clone(&b);
}
println!("b rc count after changing a = {}", Rc::strong_count(&b));
println!("a rc count after changing a = {}", Rc::strong_count(&a));
// Uncomment the next line to see that we have a cycle;
// it will overflow the stack.
// println!("a next item = {:?}", a.tail());
}ننشئ مثيلاً (instance) من Rc<List> يحمل قيمة List في المتغير a مع قائمة أولية هي 5, Nil. ثم ننشئ instance من Rc<List> يحمل قيمة List أخرى في المتغير b تحتوي على القيمة 10 وتشير إلى القائمة في a.
نقوم بتعديل a بحيث تشير إلى b بدلاً من Nil ، مما يؤدي إلى إنشاء cycle. نفعل ذلك باستخدام دالة tail للحصول على مرجع لـ RefCell<Rc<List>> في a ، والذي نضعه في المتغير link. ثم نستخدم دالة borrow_mut على RefCell<Rc<List>> لتغيير القيمة بالداخل من Rc<List> يحمل قيمة Nil إلى Rc<List> الموجود في b.
عندما نشغل هذا الكود، مع ترك آخر println! كتعليق في الوقت الحالي، سنحصل على هذه المخرجات:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
يصبح reference count لمثيلات Rc<List> في كل من a و b هو 2 بعد تغيير القائمة في a لتشير إلى b. في نهاية main ، يقوم Rust بإسقاط المتغير b ، مما يقلل reference count لمثيل b من نوع Rc<List> من 2 إلى 1. لن يتم إسقاط الذاكرة التي يمتلكها Rc<List> في الكومة (heap) في هذه المرحلة لأن reference count الخاص به هو 1 وليس 0. ثم يقوم Rust بإسقاط a ، مما يقلل reference count لمثيل a من نوع Rc<List> من 2 إلى 1 أيضاً. لا يمكن إسقاط ذاكرة هذا المثيل أيضاً، لأن مثيل Rc<List> الآخر لا يزال يشير إليه. ستبقى الذاكرة المخصصة للقائمة غير مجمعة للأبد. لتصور دورة المراجع هذه، أنشأنا الرسم التخطيطي في الشكل 15-4.

الشكل 15-4: دورة مراجع للقائمتين a و b تشيران إلى بعضهما البعض
إذا قمت بإلغاء التعليق عن آخر println! وشغلت البرنامج، فسيحاول Rust طباعة هذه الدورة مع إشارة a إلى b وإشارة b إلى a وهكذا دواليك حتى يحدث فيض في المكدس (stack overflow).
بالمقارنة مع برنامج حقيقي، فإن عواقب إنشاء reference cycle في هذا المثال ليست وخيمة للغاية: فمباشرة بعد إنشاء دورة المراجع، ينتهي البرنامج. ومع ذلك، إذا قام برنامج أكثر تعقيداً بتخصيص الكثير من الذاكرة في دورة واحتفظ بها لفترة طويلة، فسيستخدم البرنامج ذاكرة أكثر مما يحتاج وقد يرهق النظام، مما يتسبب في نفاد الذاكرة المتاحة.
إن إنشاء دورات المراجع ليس بالأمر السهل، ولكنه ليس مستحيلاً أيضاً. إذا كان لديك قيم RefCell<T> تحتوي على قيم Rc<T> أو تركيبات متداخلة مماثلة من الأنواع ذات القابلية للتغيير الداخلية (interior mutability) وعد المراجع (reference counting)، فيجب عليك التأكد من عدم إنشاء دورات؛ لا يمكنك الاعتماد على Rust لاكتشافها. سيكون إنشاء reference cycle بمثابة خطأ منطقي (logic bug) في برنامجك يجب عليك استخدام الاختبارات المؤتمتة ومراجعات الكود وممارسات تطوير البرمجيات الأخرى لتقليله.
حل آخر لتجنب دورات المراجع هو إعادة تنظيم هياكل البيانات الخاصة بك بحيث تعبر بعض المراجع عن الملكية (ownership) وبعض المراجع لا تفعل ذلك. ونتيجة لذلك، يمكن أن يكون لديك دورات تتكون من بعض علاقات الملكية وبعض العلاقات غير المملوكة، وفقط علاقات الملكية هي التي تؤثر على ما إذا كان يمكن إسقاط القيمة أم لا. في القائمة 15-25، نريد دائماً أن تمتلك متغيرات Cons قائمتها، لذا فإن إعادة تنظيم هيكل البيانات غير ممكنة. دعونا نلقي نظرة على مثال يستخدم الرسوم البيانية (graphs) المكونة من عقد أب (parent nodes) وعقد أبناء (child nodes) لنرى متى تكون العلاقات غير المملوكة وسيلة مناسبة لمنع دورات المراجع.
منع دورات المراجع باستخدام Weak<T> (Preventing Reference Cycles Using Weak)
حتى الآن، أوضحنا أن استدعاء Rc::clone يزيد من العدد القوي (strong_count) لمثيل Rc<T> ، ولا يتم تنظيف مثيل Rc<T> إلا إذا كان strong_count الخاص به هو 0. يمكنك أيضاً إنشاء مرجع ضعيف (weak reference) للقيمة داخل مثيل Rc<T> عن طريق استدعاء Rc::downgrade وتمرير مرجع إلى Rc<T>. المراجع القوية (Strong references) هي الطريقة التي يمكنك من خلالها مشاركة ملكية مثيل Rc<T>. المراجع الضعيفة (Weak references) لا تعبر عن علاقة ملكية، ولا يؤثر عددها على وقت تنظيف مثيل Rc<T>. لن تتسبب في حدوث reference cycle، لأن أي دورة تتضمن بعض المراجع الضعيفة سيتم كسرها بمجرد أن يصبح strong_count للقيم المعنية 0.
عندما تستدعي Rc::downgrade ، تحصل على مؤشر ذكي (smart pointer) من نوع Weak<T>. بدلاً من زيادة strong_count في مثيل Rc<T> بمقدار 1، فإن استدعاء Rc::downgrade يزيد العدد الضعيف (weak_count) بمقدار 1. يستخدم النوع Rc<T> الـ weak_count لتتبع عدد مراجع Weak<T> الموجودة، بشكل مشابه لـ strong_count. الفرق هو أن weak_count لا يحتاج إلى أن يكون 0 حتى يتم تنظيف مثيل Rc<T>.
نظراً لأن القيمة التي يشير إليها Weak<T> قد تكون قد أُسقطت، فلكي تفعل أي شيء بالقيمة التي يشير إليها Weak<T> ، يجب عليك التأكد من أن القيمة لا تزال موجودة. افعل ذلك عن طريق استدعاء دالة upgrade على مثيل Weak<T> ، والتي ستعيد Option<Rc<T>>. ستحصل على نتيجة Some إذا لم تكن قيمة Rc<T> قد أُسقطت بعد، ونتيجة None إذا كانت قيمة Rc<T> قد أُسقطت. نظراً لأن upgrade تعيد Option<Rc<T>> ، فإن Rust سيضمن التعامل مع حالة Some وحالة None ، ولن يكون هناك مؤشر غير صالح (invalid pointer).
كمثال، بدلاً من استخدام قائمة تعرف عناصرها فقط عن العنصر التالي، سننشئ شجرة (tree) تعرف عناصرها عن عناصرها الأبناء وعناصرها الآباء أيضاً.
إنشاء هيكل بيانات الشجرة (Creating a Tree Data Structure)
للبدء، سنبني شجرة تحتوي على عقد (nodes) تعرف عن عقدها الأبناء. سننشئ struct يسمى Node يحمل قيمة i32 الخاصة به بالإضافة إلى مراجع لقيم Node الأبناء الخاصة به:
اسم الملف: src/main.rs
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}نريد أن تمتلك Node أبناءها، ونريد مشاركة تلك الملكية مع المتغيرات حتى نتمكن من الوصول إلى كل Node في الشجرة مباشرة. للقيام بذلك، نعرف عناصر Vec<T> لتكون قيماً من نوع Rc<Node>. نريد أيضاً تعديل العقد التي تعتبر أبناء لعقدة أخرى، لذا لدينا RefCell<T> في children حول Vec<Rc<Node>>.
بعد ذلك، سنستخدم تعريف struct الخاص بنا وننشئ مثيل Node واحداً يسمى leaf بالقيمة 3 وبدون أبناء، ومثيلاً آخر يسمى branch بالقيمة 5 و leaf كأحد أبنائه، كما هو موضح في القائمة 15-27.
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}نقوم بعمل clone لـ Rc<Node> في leaf ونخزن ذلك في branch ، مما يعني أن Node في leaf أصبح لها الآن مالكان: leaf و branch. يمكننا الانتقال من branch إلى leaf عبر branch.children ، ولكن لا توجد طريقة للانتقال من leaf إلى branch. والسبب هو أن leaf ليس لديها مرجع لـ branch ولا تعرف أنهما مرتبطان. نريد أن تعرف leaf أن branch هو والدها. سنفعل ذلك بعد ذلك.
إضافة مرجع من الابن إلى والده
لجعل العقدة الابنة مدركة لوالدها، نحتاج إلى إضافة حقل parent إلى تعريف struct الخاص بـ Node. تكمن المشكلة في تحديد نوع parent. نحن نعلم أنه لا يمكن أن يحتوي على Rc<T> ، لأن ذلك سيؤدي إلى إنشاء دورة مراجع مع إشارة leaf.parent إلى branch وإشارة branch.children إلى leaf ، مما قد يتسبب في ألا تصبح قيم strong_count الخاصة بهما 0 أبداً.
بالتفكير في العلاقات بطريقة أخرى، يجب أن تمتلك العقدة الأب أبناءها: إذا تم إسقاط عقدة أب، فيجب إسقاط عقدها الأبناء أيضاً. ومع ذلك، لا ينبغي للابن أن يمتلك والده: إذا أسقطنا عقدة ابنة، فيجب أن يظل الأب موجوداً. هذه حالة للمراجع الضعيفة!
لذا، بدلاً من Rc<T> ، سنجعل نوع parent يستخدم Weak<T> ، وتحديداً RefCell<Weak<Node>>. الآن يبدو تعريف struct الخاص بـ Node كما يلي:
اسم الملف: src/main.rs
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}ستتمكن العقدة من الرجوع إلى عقدتها الأب ولكنها لا تمتلك والدها. في القائمة 15-28، نقوم بتحديث main لاستخدام هذا التعريف الجديد بحيث يكون لدى عقدة leaf طريقة للرجوع إلى والدها، branch.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}يبدو إنشاء عقدة leaf مشابهاً للقائمة 15-27 باستثناء حقل parent: تبدأ leaf بدون أب، لذا ننشئ مثيل مرجع Weak<Node> جديداً وفارغاً.
في هذه المرحلة، عندما نحاول الحصول على مرجع لوالد leaf باستخدام دالة upgrade ، نحصل على قيمة None. نرى هذا في المخرجات من أول عبارة println!:
leaf parent = None
عندما ننشئ عقدة branch ، سيكون لها أيضاً مرجع Weak<Node> جديد في حقل parent لأن branch ليس لها عقدة أب. لا نزال نملك leaf كأحد أبناء branch. بمجرد حصولنا على مثيل Node في branch ، يمكننا تعديل leaf لمنحها مرجع Weak<Node> لوالدها. نستخدم دالة borrow_mut على RefCell<Weak<Node>> في
leaf ، ونستخدم دالة Rc::downgrade من Rc<Node> في branch لإنشاء مرجع Weak<Node> لـ branch.
عندما نطبع والد leaf مرة أخرى، سنحصل هذه المرة على متغير Some يحمل branch: الآن يمكن لـ leaf الوصول إلى والدها! عندما نطبع leaf ، نتجنب أيضاً الدورة التي انتهت في النهاية بفيض في المكدس كما حدث في القائمة 15-26؛ حيث تتم طباعة مراجع Weak<Node> كـ (Weak):
leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
يشير عدم وجود مخرجات لانهائية إلى أن هذا الكود لم ينشئ دورة مراجع. يمكننا أيضاً معرفة ذلك من خلال النظر في القيم التي نحصل عليها من استدعاء Rc::strong_count و Rc::weak_count.
تصور التغييرات في strong_count و weak_count
دعونا نلقي نظرة على كيفية تغير قيم strong_count و weak_count لمثيلات Rc<Node> من خلال إنشاء نطاق داخلي جديد ونقل عملية إنشاء branch إلى ذلك النطاق. من خلال القيام بذلك، يمكننا رؤية ما يحدث عند إنشاء branch ثم إسقاطها عندما تخرج عن النطاق (scope). تظهر التعديلات في القائمة 15-29.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
{
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!(
"branch strong = {}, weak = {}",
Rc::strong_count(&branch),
Rc::weak_count(&branch),
);
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}بعد إنشاء leaf ، يكون لـ Rc<Node> الخاص بها عدد قوي (strong count) قدره 1 وعدد ضعيف (weak count) قدره 0. في النطاق الداخلي، ننشئ branch ونربطها بـ leaf ، وعند هذه النقطة عندما نطبع الأعداد، سيكون لـ Rc<Node> في branch عدد قوي قدره 1 وعدد ضعيف قدره 1 (لأن leaf.parent تشير إلى branch باستخدام Weak<Node>). عندما نطبع الأعداد في leaf ، سنرى أن لها عدداً قوياً قدره 2 لأن branch لديها الآن نسخة (clone) من Rc<Node> الخاص بـ leaf مخزنة في branch.children ولكن سيظل لها عدد ضعيف قدره 0.
عندما ينتهي النطاق الداخلي، تخرج branch عن النطاق وينخفض العدد القوي لـ Rc<Node> إلى 0، لذا يتم إسقاط Node الخاصة بها. العدد الضعيف 1 من leaf.parent ليس له أي تأثير على ما إذا كان سيتم إسقاط Node أم لا، لذا لا نحصل على أي تسرب للذاكرة!
إذا حاولنا الوصول إلى والد leaf بعد نهاية النطاق، فسنحصل على None مرة أخرى. في نهاية البرنامج، يكون لـ Rc<Node> في leaf عدد قوي قدره 1 وعدد ضعيف قدره 0 لأن المتغير leaf هو الآن المرجع الوحيد لـ Rc<Node> مرة أخرى.
كل المنطق الذي يدير الأعداد وإسقاط القيم مدمج في Rc<T> و Weak<T> وتنفيذاتهما لسمة Drop. من خلال تحديد أن العلاقة من الابن إلى والده يجب أن تكون مرجع Weak<T> في تعريف Node ، يمكنك جعل عقد الآباء تشير إلى عقد الأبناء والعكس صحيح دون إنشاء دورة مراجع وتسرب للذاكرة.
ملخص (Summary)
غطى هذا الفصل كيفية استخدام المؤشرات الذكية (smart pointers) لتقديم ضمانات ومقايضات مختلفة عن تلك التي يقدمها Rust افتراضياً مع المراجع العادية. النوع Box<T> له حجم معروف ويشير إلى بيانات مخصصة في الكومة (heap). النوع Rc<T> يتتبع عدد المراجع للبيانات في الكومة بحيث يمكن أن يكون للبيانات مالكون متعددون. النوع RefCell<T> مع قابليته للتغيير الداخلية يمنحنا نوعاً يمكننا استخدامه عندما نحتاج إلى نوع غير قابل للتغيير ولكننا نحتاج إلى تغيير قيمة داخلية لذلك النوع؛ كما أنه يفرض قواعد الاستعارة (borrowing rules) في وقت التشغيل بدلاً من وقت التصريف.
تمت أيضاً مناقشة سمات Deref و Drop ، والتي تتيح الكثير من وظائف المؤشرات الذكية. استكشفنا دورات المراجع التي يمكن أن تسبب تسرباً للذاكرة وكيفية منعها باستخدام Weak<T>.
إذا كان هذا الفصل قد أثار اهتمامك وتريد تنفيذ مؤشراتك الذكية الخاصة، فراجع كتاب “The Rustonomicon” لمزيد من المعلومات المفيدة.
بعد ذلك، سنتحدث عن التزامن (concurrency) في Rust. ستتعلم حتى عن بعض المؤشرات الذكية الجديدة.
التزامن بلا خوف (Fearless Concurrency)
يعد التعامل مع البرمجة المتزامنة (Concurrent Programming) بأمان وكفاءة أحد أهداف لغة Rust الرئيسية الأخرى. تزداد أهمية البرمجة المتزامنة، التي يتم فيها تنفيذ أجزاء مختلفة من البرنامج بشكل مستقل، والبرمجة المتوازية (Parallel Programming)، التي يتم فيها تنفيذ أجزاء مختلفة من البرنامج في نفس الوقت، مع استفادة المزيد من أجهزة الكمبيوتر من معالجاتها المتعددة. تاريخياً، كانت البرمجة في هذه السياقات صعبة وعرضة للأخطاء، وتأمل Rust في تغيير ذلك.
في البداية، اعتقد فريق Rust أن ضمان سلامة الذاكرة (Memory Safety) ومنع مشاكل التزامن (Concurrency) كانا تحديين منفصلين يجب حلهما بطرق مختلفة. ومع مرور الوقت، اكتشف الفريق أن أنظمة الملكية (Ownership) والأنواع (Type Systems) هي مجموعة قوية من الأدوات للمساعدة في إدارة سلامة الذاكرة ومشاكل Concurrency معاً! من خلال الاستفادة من Ownership والتحقق من الأنواع (Type Checking)، تصبح العديد من أخطاء Concurrency أخطاء في وقت الترجمة (Compile-time Errors) في Rust بدلاً من أخطاء وقت التشغيل (Runtime Errors). لذلك، بدلاً من جعلك تقضي الكثير من الوقت في محاولة إعادة إنتاج الظروف الدقيقة التي يحدث فيها خطأ Concurrency في وقت التشغيل، سيرفض الكود غير الصحيح الترجمة (Compile) وسيقدم خطأ يوضح المشكلة. ونتيجة لذلك، يمكنك إصلاح الكود الخاص بك أثناء العمل عليه بدلاً من إصلاحه بعد شحنه إلى بيئة الإنتاج (Production). لقد أطلقنا على هذا الجانب من Rust اسم التزامن بلا خوف (Fearless Concurrency). يسمح لك Fearless Concurrency بكتابة كود خالٍ من الأخطاء الدقيقة ويسهل إعادة هيكلته (Refactor) دون إدخال أخطاء جديدة.
ملاحظة: من أجل التبسيط، سنشير إلى العديد من المشكلات على أنها متزامنة (Concurrent) بدلاً من أن نكون أكثر دقة بقولنا متزامنة و/أو متوازية (Concurrent and/or Parallel). في هذا الفصل، يرجى استبدال كلمة متزامنة و/أو متوازية ذهنياً كلما استخدمنا كلمة متزامنة. في الفصل التالي، حيث يهم التمييز أكثر، سنكون أكثر تحديداً.
تتسم العديد من اللغات بالتمسك الشديد بالحلول التي تقدمها للتعامل مع المشكلات المتزامنة. على سبيل المثال، تمتلك لغة Erlang وظائف أنيقة للتزامن عبر تمرير الرسائل (Message-passing Concurrency)، ولكن لديها طرق غامضة فقط لمشاركة الحالة (Shared State) بين الخيوط (Threads). يعد دعم مجموعة فرعية فقط من الحلول الممكنة استراتيجية معقولة للغات عالية المستوى لأن اللغة عالية المستوى تعد بفوائد ناتجة عن التخلي عن بعض التحكم مقابل الحصول على تجريدات (Abstractions). ومع ذلك، يُتوقع من اللغات منخفضة المستوى تقديم الحل بأفضل أداء في أي موقف معين وأن يكون لديها تجريدات أقل فوق الأجهزة (Hardware). لذلك، تقدم Rust مجموعة متنوعة من الأدوات لنمذجة المشكلات بأي طريقة مناسبة لموقفك ومتطلباتك.
إليك الموضوعات التي سنغطيها في هذا الفصل:
- كيفية إنشاء خيوط (Threads) لتشغيل قطع متعددة من الكود في نفس الوقت.
- التزامن عبر تمرير الرسائل (Message-passing Concurrency)، حيث ترسل القنوات (Channels) رسائل بين Threads.
- التزامن عبر الحالة المشتركة (Shared-state Concurrency)، حيث تمتلك Threads متعددة إمكانية الوصول إلى قطعة معينة من البيانات.
- سمات (Traits)
SyncوSendالتي توسع ضمانات Concurrency في Rust لتشمل الأنواع المعرفة من قبل المستخدم بالإضافة إلى الأنواع التي توفرها المكتبة القياسية (Standard Library).
استخدام الخيوط لتشغيل الكود في وقت واحد (Threads)
استخدام الخيوط لتشغيل الكود في وقت واحد (Using Threads to Run Code Simultaneously)
في معظم أنظمة التشغيل الحالية، يتم تشغيل كود البرنامج المنفذ في عملية (process)، وسيقوم نظام التشغيل بإدارة عدة processes في وقت واحد. داخل البرنامج، يمكنك أيضاً الحصول على أجزاء مستقلة تعمل في وقت واحد. تسمى الميزات التي تشغل هذه الأجزاء المستقلة خيوطاً (threads). على سبيل المثال، يمكن أن يحتوي خادم الويب على عدة threads بحيث يمكنه الاستجابة لأكثر من طلب واحد في نفس الوقت.
يمكن أن يؤدي تقسيم الحساب في برنامجك إلى عدة threads لتشغيل مهام متعددة في نفس الوقت إلى تحسين الأداء، ولكنه يضيف أيضاً تعقيداً. ولأن threads يمكن أن تعمل في وقت واحد، فلا يوجد ضمان متأصل حول الترتيب الذي ستعمل به أجزاء الكود الخاصة بك على threads مختلفة. يمكن أن يؤدي هذا إلى مشاكل، مثل:
- حالات السباق (Race conditions)، حيث تصل threads إلى البيانات أو الموارد بترتيب غير متسق.
- حالات الجمود (Deadlocks)، حيث ينتظر خيطان بعضهما البعض، مما يمنع كلا الـ threads من الاستمرار.
- الأخطاء (Bugs) التي تحدث فقط في مواقف معينة ويصعب إعادة إنتاجها وإصلاحها بشكل موثوق.
تحاول Rust التخفيف من الآثار السلبية لاستخدام threads، لكن البرمجة في سياق متعدد الخيوط (multithreaded) لا تزال تتطلب تفكيراً دقيقاً وتتطلب بنية كود تختلف عن تلك الموجودة في البرامج التي تعمل في خيط واحد (single thread).
تنفذ لغات البرمجة threads بعدة طرق مختلفة، وتوفر العديد من أنظمة التشغيل واجهة برمجة تطبيقات (API) يمكن للغة البرمجة استدعاؤها لإنشاء threads جديدة. تستخدم مكتبة Rust القياسية نموذج 1:1 لتنفيذ الخيوط، حيث يستخدم البرنامج خيط نظام تشغيل واحداً لكل خيط لغة واحد. هناك صناديق (crates) تنفذ نماذج أخرى من threading تقدم مقايضات مختلفة لنموذج 1:1. (يوفر نظام async في Rust، والذي سنراه في الفصل القادم، نهجاً آخر للتزامن (concurrency) أيضاً.)
إنشاء خيط جديد باستخدام spawn (Creating a New Thread with spawn)
لإنشاء خيط جديد، نستدعي دالة thread::spawn ونمرر لها إغلاقاً (closure) (تحدثنا عن closures في الفصل الثالث عشر) يحتوي على الكود الذي نريد تشغيله في الخيط الجديد. يطبع المثال في القائمة 16-1 بعض النصوص من خيط رئيسي (main thread) ونصوصاً أخرى من خيط جديد.
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
}لاحظ أنه عندما يكتمل main thread لبرنامج Rust، يتم إغلاق جميع الـ spawned threads، سواء انتهت من العمل أم لا. قد يكون المخرجات من هذا البرنامج مختلفة قليلاً في كل مرة، لكنها ستشبه ما يلي:
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the main thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
تجبر استدعاءات thread::sleep الخيط على إيقاف تنفيذه لفترة قصيرة، مما يسمح لخيط مختلف بالعمل. من المحتمل أن تتبادل الـ threads الأدوار، لكن هذا ليس مضموناً: فهو يعتمد على كيفية جدولة نظام التشغيل الخاص بك للـ threads. في هذا التشغيل، طبع main thread أولاً، على الرغم من أن جملة الطباعة من spawned thread تظهر أولاً في الكود. وحتى بالرغم من أننا أخبرنا spawned thread بالطباعة حتى تصل i إلى 9 ، إلا أنه وصل فقط إلى 5 قبل أن يتوقف main thread.
إذا قمت بتشغيل هذا الكود ورأيت فقط مخرجات من main thread، أو لم ترَ أي تداخل، فحاول زيادة الأرقام في النطاقات لإنشاء المزيد من الفرص لنظام التشغيل للتبديل بين الـ threads.
انتظار انتهاء جميع الخيوط (Waiting for All Threads to Finish)
الكود في القائمة 16-1 لا يوقف spawned thread قبل الأوان في معظم الأوقات بسبب انتهاء main thread فحسب، بل لأنه لا يوجد ضمان على الترتيب الذي تعمل به الـ threads، لا يمكننا أيضاً ضمان أن spawned thread سيعمل على الإطلاق!
يمكننا إصلاح مشكلة عدم عمل spawned thread أو انتهائه قبل الأوان عن طريق حفظ قيمة الإرجاع لـ thread::spawn في متغير. نوع الإرجاع لـ thread::spawn هو JoinHandle<T>. الـ JoinHandle<T> هو قيمة مملوكة، عندما نستدعي طريقة (method) الـ join عليها، ستنتظر خيطها حتى ينتهي. توضح القائمة 16-2 كيفية استخدام JoinHandle<T> للخيط الذي أنشأناه في القائمة 16-1 وكيفية استدعاء join للتأكد من انتهاء spawned thread قبل خروج main.
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
handle.join().unwrap();
}يؤدي استدعاء join على المقبض (handle) إلى حظر (block) الخيط الذي يعمل حالياً حتى ينتهي الخيط الذي يمثله الـ handle. حظر (Blocking) الخيط يعني منع ذلك الخيط من أداء العمل أو الخروج. ولأننا وضعنا استدعاء join بعد حلقة for الخاصة بـ main thread، فإن تشغيل القائمة 16-2 يجب أن ينتج مخرجات مشابهة لهذا:
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 1 from the spawned thread!
hi number 3 from the main thread!
hi number 2 from the spawned thread!
hi number 4 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
يستمر الخيطان في التناوب، لكن main thread ينتظر بسبب استدعاء handle.join() ولا ينتهي حتى ينتهي spawned thread.
ولكن دعونا نرى ما يحدث عندما نقوم بدلاً من ذلك بنقل handle.join() قبل حلقة for في main ، هكذا:
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
handle.join().unwrap();
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
}سينتظر main thread انتهاء spawned thread ثم يشغل حلقة for الخاصة به، لذا لن تكون المخرجات متداخلة بعد الآن، كما هو موضح هنا:
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
يمكن للتفاصيل الصغيرة، مثل مكان استدعاء join ، أن تؤثر على ما إذا كانت الـ threads تعمل في نفس الوقت أم لا.
استخدام إغلاقات move مع الخيوط (Using move Closures with Threads)
سنستخدم غالباً الكلمة المفتاحية move مع closures الممررة إلى thread::spawn لأن الـ closure سيأخذ حينها ملكية (ownership) القيم التي يستخدمها من البيئة، وبالتالي ينقل ملكية تلك القيم من خيط إلى آخر. في قسم “التقاط المراجع أو نقل الملكية” في الفصل الثالث عشر، ناقشنا move في سياق closures. الآن سنركز أكثر على التفاعل بين move و thread::spawn.
لاحظ في القائمة 16-1 أن الـ closure الذي نمرره إلى thread::spawn لا يأخذ أي arguments: نحن لا نستخدم أي بيانات من main thread في كود spawned thread. لاستخدام بيانات من main thread في spawned thread، يجب على closure الخاص بـ spawned thread التقاط (capture) القيم التي يحتاجها. توضح القائمة 16-3 محاولة لإنشاء متجه (vector) في main thread واستخدامه في spawned thread. ومع ذلك، لن يعمل هذا بعد، كما سترى في لحظة.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}يستخدم الـ closure المتغير v ، لذا سيقوم بـ capture لـ v ويجعله جزءاً من بيئة الـ closure. ولأن thread::spawn يشغل هذا الـ closure في خيط جديد، يجب أن نكون قادرين على الوصول إلى v داخل ذلك الخيط الجديد. ولكن عندما نقوم بتجميع هذا المثال، نحصل على الخطأ التالي:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {v:?}");
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {v:?}");
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` (bin "threads") due to 1 previous error
تستنتج (infers) Rust كيفية التقاط v ، ولأن println! تحتاج فقط إلى مرجع (reference) لـ v ، يحاول الـ closure استعارة (borrow) المتغير v. ومع ذلك، هناك مشكلة: لا تستطيع Rust معرفة مدة تشغيل spawned thread، لذا فهي لا تعرف ما إذا كان الـ reference لـ v سيكون صالحاً دائماً.
تقدم القائمة 16-4 سيناريو من المرجح أن يحتوي على reference لـ v لن يكون صالحاً.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
drop(v); // oh no!
handle.join().unwrap();
}إذا سمحت لنا Rust بتشغيل هذا الكود، فهناك احتمال أن يتم وضع spawned thread فوراً في الخلفية دون أن يعمل على الإطلاق. يحتوي spawned thread على reference لـ v بالداخل، لكن main thread يقوم فوراً بإسقاط (drop) المتغير v ، باستخدام دالة drop التي ناقشناها في الفصل الخامس عشر. ثم، عندما يبدأ spawned thread في التنفيذ، لن يكون v صالحاً بعد الآن، لذا فإن الـ reference له يكون أيضاً غير صالح. أوه لا!
لإصلاح خطأ المترجم (compiler) في القائمة 16-3، يمكننا استخدام نصيحة رسالة الخطأ:
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
بإضافة الكلمة المفتاحية move قبل الـ closure، نجبر الـ closure على أخذ ownership للقيم التي يستخدمها بدلاً من السماح لـ Rust باستنتاج أنه يجب عليه borrow للقيم. التعديل على القائمة 16-3 الموضح في القائمة 16-5 سيتم تجميعه وتشغيله كما ننوي.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(move || {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}قد نميل إلى تجربة نفس الشيء لإصلاح الكود في القائمة 16-4 حيث استدعى main thread الدالة drop باستخدام move closure. ومع ذلك، فإن هذا الإصلاح لن يعمل لأن ما تحاول القائمة 16-4 القيام به غير مسموح به لسبب مختلف. إذا أضفنا move إلى الـ closure، فسننقل v إلى بيئة الـ closure، ولن نتمكن بعد الآن من استدعاء drop عليه في main thread. سنحصل على خطأ compiler هذا بدلاً من ذلك:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Here's a vector: {v:?}");
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
|
help: consider cloning the value before moving it into the closure
|
6 ~ let value = v.clone();
7 ~ let handle = thread::spawn(move || {
8 ~ println!("Here's a vector: {value:?}");
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` (bin "threads") due to 1 previous error
لقد أنقذتنا قواعد الملكية (ownership rules) في Rust مرة أخرى! حصلنا على خطأ من الكود في القائمة 16-3 لأن Rust كانت متحفظة وتقوم فقط بـ borrow لـ v للخيط، مما يعني أن main thread يمكنه نظرياً إبطال reference الخاص بـ spawned thread. من خلال إخبار Rust بنقل ownership لـ v إلى spawned thread، فإننا نضمن لـ Rust أن main thread لن يستخدم v بعد الآن. إذا قمنا بتغيير القائمة 16-4 بنفس الطريقة، فإننا ننتهك ownership rules عندما نحاول استخدام v في main thread. الكلمة المفتاحية move تتجاوز افتراض Rust المتحفظ بالاستعارة؛ فهي لا تسمح لنا بانتهاك ownership rules.
الآن بعد أن غطينا ماهية الـ threads والطرق التي توفرها thread API، دعونا نلقي نظرة على بعض المواقف التي يمكننا فيها استخدام threads.
نقل البيانات بين الخيوط باستخدام تمرير الرسائل (Message Passing)
نقل البيانات بين الخيوط (Threads) باستخدام تمرير الرسائل (Message Passing)
أحد الأساليب الشائعة بشكل متزايد لضمان التزامن (concurrency) الآمن هو تمرير الرسائل (message passing)، حيث تتواصل الـ threads أو الـ actors عن طريق إرسال رسائل تحتوي على بيانات لبعضها البعض. إليك الفكرة في شعار من وثائق لغة Go:
“لا تتواصل عن طريق مشاركة الذاكرة (sharing memory)؛ بدلاً من ذلك، شارك الذاكرة عن طريق التواصل.”
لتحقيق تزامن إرسال الرسائل، توفر الـ standard library في Rust تطبيقًا لـ القنوات (channels). الـ channel هو مفهوم برمجي عام يتم من خلاله إرسال البيانات من thread إلى آخر.
يمكنك تخيل الـ channel في البرمجة على أنه يشبه قناة مائية اتجاهية، مثل جدول أو نهر. إذا وضعت شيئًا مثل بطة مطاطية في نهر، فسوف تنتقل إلى أسفل النهر حتى نهاية المجرى المائي.
يحتوي الـ channel على نصفين: مرسل (transmitter) و مستقبل (receiver). نصف الـ transmitter هو الموقع العلوي حيث تضع البطة المطاطية في النهر، ونصف الـ receiver هو المكان الذي تنتهي فيه البطة المطاطية في المصب. يستدعي جزء واحد من الكود الخاص بك methods على الـ transmitter بالبيانات التي تريد إرسالها، ويتحقق جزء آخر من طرف الـ receiving بحثًا عن الرسائل الواردة. يقال إن الـ channel مغلق (closed) إذا تم إسقاط (dropped) أي من نصفي الـ transmitter أو الـ receiver.
هنا، سنعمل على برنامج يحتوي على thread واحد لإنشاء قيم وإرسالها عبر channel، و thread آخر سيستقبل القيم ويطبعها. سنرسل قيمًا بسيطة بين الـ threads باستخدام channel لتوضيح الميزة. بمجرد أن تكون على دراية بالتقنية، يمكنك استخدام الـ channels لأي threads تحتاج إلى التواصل مع بعضها البعض، مثل نظام دردشة أو نظام تقوم فيه threads متعددة بأداء أجزاء من عملية حسابية وإرسال الأجزاء إلى thread واحد يجمع النتائج.
أولاً، في القائمة 16-6، سننشئ channel ولكن لن نفعل به أي شيء. لاحظ أن هذا لن يتم تجميعه بعد لأن Rust لا يمكنها معرفة نوع القيم التي نريد إرسالها عبر الـ channel.
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}ننشئ channel جديدًا باستخدام دالة mpsc::channel؛ يشير mpsc إلى منتج متعدد، مستهلك واحد (multiple producer, single consumer). باختصار، الطريقة التي تطبق بها الـ standard library في Rust الـ channels تعني أن الـ channel يمكن أن يحتوي على أطراف إرسال (sending) متعددة تنتج قيمًا ولكن طرف استقبال (receiving) واحد فقط يستهلك تلك القيم. تخيل جداول متعددة تتدفق معًا في نهر واحد كبير: كل ما يتم إرساله عبر أي من الجداول سينتهي به المطاف في نهر واحد في النهاية. سنبدأ بـ single producer في الوقت الحالي، ولكننا سنضيف multiple producers عندما نجعل هذا المثال يعمل.
تُرجع دالة mpsc::channel tuple، العنصر الأول منها هو طرف الـ sending - الـ transmitter - والعنصر الثاني هو طرف الـ receiving - الـ receiver. تُستخدم الاختصارات tx و rx تقليديًا في العديد من المجالات لـ transmitter و receiver، على التوالي، لذلك نسمي متغيراتنا على هذا النحو للإشارة إلى كل طرف. نحن نستخدم عبارة let بنمط (pattern) يفكك الـ tuples؛ سنناقش استخدام الـ patterns في عبارات let والـ destructuring في الفصل 19. في الوقت الحالي، اعلم أن استخدام عبارة let بهذه الطريقة هو أسلوب مناسب لاستخراج أجزاء الـ tuple التي تُرجعها mpsc::channel.
دعنا ننقل طرف الـ transmitting إلى thread تم إنشاؤه حديثًا ونجعله يرسل string واحدًا بحيث يتواصل الـ thread الذي تم إنشاؤه مع الـ main thread، كما هو موضح في القائمة 16-7. هذا يشبه وضع بطة مطاطية في النهر في المنبع أو إرسال رسالة دردشة من thread إلى آخر.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
}مرة أخرى، نستخدم thread::spawn لإنشاء thread جديد ثم نستخدم move لنقل tx إلى الـ closure بحيث يمتلك الـ thread الذي تم إنشاؤه الـ tx. يحتاج الـ thread الذي تم إنشاؤه إلى امتلاك الـ transmitter ليتمكن من إرسال الرسائل عبر الـ channel.
يحتوي الـ transmitter على method send الذي يأخذ القيمة التي نريد إرسالها. يُرجع method send نوع Result<T, E>، لذلك إذا تم إسقاط الـ receiver بالفعل ولم يكن هناك مكان لإرسال قيمة، فستُرجع عملية الـ send خطأ. في هذا المثال، نستدعي unwrap للإصابة بالذعر في حالة حدوث خطأ. ولكن في تطبيق حقيقي، سنتعامل معه بشكل صحيح: ارجع إلى الفصل 9 لمراجعة استراتيجيات معالجة الأخطاء المناسبة.
في القائمة 16-8، سنحصل على القيمة من الـ receiver في الـ main thread. هذا يشبه استرداد البطة المطاطية من الماء في نهاية النهر أو تلقي رسالة دردشة.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}يحتوي الـ receiver على methodين مفيدين: recv و try_recv. نحن نستخدم recv، وهو اختصار لـ receive (استقبال)، والذي سيحظر تنفيذ الـ main thread وينتظر حتى يتم إرسال قيمة عبر الـ channel. بمجرد إرسال قيمة، ستُرجعها recv في Result<T, E>. عندما يغلق الـ transmitter، ستُرجع recv خطأ للإشارة إلى أنه لن تأتي المزيد من القيم.
لا يحظر method try_recv، ولكنه بدلاً من ذلك سيُرجع Result<T, E> على الفور: قيمة Ok تحتوي على رسالة إذا كانت متوفرة وقيمة Err إذا لم تكن هناك أي رسائل هذه المرة. يعد استخدام try_recv مفيدًا إذا كان هذا الـ thread لديه عمل آخر للقيام به أثناء انتظار الرسائل: يمكننا كتابة حلقة تستدعي try_recv كل فترة، وتتعامل مع رسالة إذا كانت متوفرة، وإلا فإنها تقوم بعمل آخر لفترة قصيرة حتى تتحقق مرة أخرى.
لقد استخدمنا recv في هذا المثال للتبسيط؛ ليس لدينا أي عمل آخر لـ main thread للقيام به بخلاف انتظار الرسائل، لذا فإن حظر الـ main thread مناسب.
عندما نقوم بتشغيل الكود في القائمة 16-8، سنرى القيمة المطبوعة من الـ main thread:
Got: hi
ممتاز!
نقل الملكية (Ownership) عبر القنوات
تلعب قواعد الـ ownership دورًا حيويًا في message sending لأنها تساعدك على كتابة كود تزامن آمن. يعد منع الأخطاء في البرمجة المتزامنة ميزة التفكير في الـ ownership في جميع برامج Rust الخاصة بك. دعنا نجري تجربة لإظهار كيف يعمل الـ channels والـ ownership معًا لمنع المشاكل: سنحاول استخدام قيمة val في الـ thread الذي تم إنشاؤه بعد أن أرسلناها عبر الـ channel. حاول تجميع الكود في القائمة 16-9 لترى لماذا لا يُسمح بهذا الكود.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
println!("val is {val}");
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}هنا، نحاول طباعة val بعد أن أرسلناها عبر الـ channel عبر tx.send. السماح بذلك سيكون فكرة سيئة: بمجرد إرسال القيمة إلى thread آخر، يمكن لهذا الـ thread تعديلها أو إسقاطها قبل أن نحاول استخدام القيمة مرة أخرى. من المحتمل أن تتسبب تعديلات الـ thread الآخر في حدوث أخطاء أو نتائج غير متوقعة بسبب بيانات غير متسقة أو غير موجودة. ومع ذلك، تعطينا Rust خطأ إذا حاولنا تجميع الكود في القائمة 16-9:
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:27
|
8 | let val = String::from("hi");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val is {val}");
| ^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` (bin "message-passing") due to 1 previous error
لقد تسبب خطأ التزامن الخاص بنا في حدوث خطأ في وقت التجميع (compile-time error). تأخذ دالة send الـ ownership لـ parameter الخاص بها، وعندما يتم نقل القيمة، يأخذ الـ receiver الـ ownership لها. هذا يمنعنا من استخدام القيمة مرة أخرى عن طريق الخطأ بعد إرسالها؛ يتحقق نظام الـ ownership من أن كل شيء على ما يرام.
إرسال قيم متعددة
تم تجميع وتشغيل الكود في القائمة 16-8، ولكنه لم يوضح لنا بوضوح أن threadين منفصلين كانا يتحدثان مع بعضهما البعض عبر الـ channel.
في القائمة 16-10، أجرينا بعض التعديلات التي ستثبت أن الكود في القائمة 16-8 يعمل بشكل متزامن (concurrently): سيرسل الـ thread الذي تم إنشاؤه الآن رسائل متعددة ويتوقف مؤقتًا لمدة ثانية بين كل رسالة.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
}هذه المرة، يحتوي الـ thread الذي تم إنشاؤه على vector من الـ strings التي نريد إرسالها إلى الـ main thread. نكرر عليها، ونرسل كل واحدة على حدة، ونتوقف مؤقتًا بين كل واحدة عن طريق استدعاء دالة thread::sleep بقيمة Duration تبلغ ثانية واحدة.
في الـ main thread، لم نعد نستدعي دالة recv بشكل صريح: بدلاً من ذلك، نتعامل مع rx كـ مكرر (iterator). لكل قيمة يتم استقبالها، نقوم بطباعتها. عندما يتم إغلاق الـ channel، سينتهي التكرار.
عند تشغيل الكود في القائمة 16-10، يجب أن ترى الإخراج التالي مع توقف لمدة ثانية واحدة بين كل سطر:
Got: hi
Got: from
Got: the
Got: thread
نظرًا لعدم وجود أي كود يتوقف مؤقتًا أو يتأخر في حلقة for في الـ main thread، يمكننا أن نقول إن الـ main thread ينتظر استقبال القيم من الـ thread الذي تم إنشاؤه.
إنشاء منتجين متعددين (Multiple Producers)
في وقت سابق ذكرنا أن mpsc هو اختصار لـ multiple producer, single consumer. دعنا نستخدم mpsc ونوسع الكود في القائمة 16-10 لإنشاء threads متعددة ترسل جميعها قيمًا إلى نفس الـ receiver. يمكننا القيام بذلك عن طريق استنساخ (cloning) الـ transmitter، كما هو موضح في القائمة 16-11.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
// --snip--
}هذه المرة، قبل أن ننشئ الـ thread الأول، نستدعي clone على الـ transmitter. سيعطينا هذا transmitter جديدًا يمكننا تمريره إلى الـ thread الأول الذي تم إنشاؤه. نمرر الـ transmitter الأصلي إلى thread ثانٍ تم إنشاؤه. هذا يعطينا threadين، يرسل كل منهما رسائل مختلفة إلى الـ receiver الواحد.
عند تشغيل الكود، يجب أن يبدو الإخراج الخاص بك شيئًا كهذا:
Got: hi
Got: more
Got: from
Got: messages
Got: for
Got: the
Got: thread
Got: you
قد ترى القيم بترتيب آخر، اعتمادًا على نظامك. هذا ما يجعل الـ concurrency مثيرًا للاهتمام وصعبًا أيضًا. إذا قمت بالتجربة باستخدام thread::sleep، وإعطائه قيمًا مختلفة في الـ threads المختلفة، فسيكون كل تشغيل غير حتمي (nondeterministic) بشكل أكبر وينتج إخراجًا مختلفًا في كل مرة.
الآن بعد أن نظرنا في كيفية عمل الـ channels، دعنا نلقي نظرة على طريقة مختلفة لـ concurrency.
تزامن الحالة المشتركة (Shared-State Concurrency)
تزامن الحالة المشتركة (Shared-State Concurrency)
يُعد تمرير الرسائل (Message passing) طريقة جيدة للتعامل مع التزامن (concurrency)، ولكنه ليس الطريقة الوحيدة. هناك طريقة أخرى تتمثل في وصول خيوط (threads) متعددة إلى نفس البيانات المشتركة (shared data). تذكر هذا الجزء من شعار وثائق لغة Go مرة أخرى: “لا تتواصل عن طريق مشاركة الذاكرة (sharing memory).”
كيف سيبدو التواصل عن طريق memory sharing؟ بالإضافة إلى ذلك، لماذا يحذر المتحمسون لـ message-passing من عدم استخدام memory sharing؟
بطريقة ما، تشبه القنوات (channels) في أي لغة برمجة الـ ملكية فردية (single ownership) لأنه بمجرد نقل قيمة عبر channel، لا يجب عليك استخدام تلك القيمة بعد الآن. يشبه تزامن الذاكرة المشتركة (Shared-memory concurrency) الـ ملكية متعددة (multiple ownership): يمكن لـ threads متعددة الوصول إلى نفس موقع الذاكرة في نفس الوقت. كما رأيت في الفصل 15، حيث جعلت الـ مؤشرات الذكية (smart pointers) الـ multiple ownership ممكنة، يمكن أن تضيف الـ multiple ownership تعقيدًا لأن هؤلاء المالكين المختلفين يحتاجون إلى إدارة. يساعد نظام الأنواع (type system) وقواعد الـ ownership في Rust بشكل كبير في جعل هذه الإدارة صحيحة. كمثال، دعنا ننظر إلى الـ mutexes، وهي إحدى بدائيات التزامن (concurrency primitives) الأكثر شيوعًا للـ shared memory.
التحكم في الوصول باستخدام المزاليج (Mutexes)
الـ Mutex هو اختصار لـ الاستبعاد المتبادل (mutual exclusion)، بمعنى أن الـ mutex يسمح لـ thread واحد فقط بالوصول إلى بعض الـ data في أي وقت معين. للوصول إلى الـ data في mutex، يجب على الـ thread أولاً الإشارة إلى أنه يريد الوصول عن طريق طلب الحصول على قفل (lock) الـ mutex. الـ lock هو بنية بيانات (data structure) تعد جزءًا من الـ mutex وتتتبع من لديه حاليًا وصول حصري إلى الـ data. لذلك، يوصف الـ mutex بأنه يحمي (guarding) الـ data التي يحملها عبر نظام الـ locking.
تشتهر الـ mutexes بصعوبة استخدامها لأنه يجب عليك تذكر قاعدتين:
- يجب أن تحاول الحصول على الـ lock قبل استخدام الـ data.
- عندما تنتهي من الـ data التي يحميها الـ mutex، يجب عليك إلغاء قفل (unlock) الـ data حتى تتمكن الـ threads الأخرى من الحصول على الـ lock.
بالنسبة لاستعارة من العالم الحقيقي لـ mutex، تخيل حلقة نقاش في مؤتمر بها ميكروفون واحد فقط. قبل أن يتمكن أحد أعضاء اللجنة من التحدث، يجب عليه أن يطلب أو يشير إلى أنه يريد استخدام الميكروفون. عندما يحصل على الميكروفون، يمكنه التحدث للمدة التي يريدها ثم يسلم الميكروفون إلى عضو اللجنة التالي الذي يطلب التحدث. إذا نسي أحد أعضاء اللجنة تسليم الميكروفون عند الانتهاء منه، فلن يتمكن أي شخص آخر من التحدث. إذا ساءت إدارة الميكروفون المشترك، فلن تعمل حلقة النقاش كما هو مخطط لها!
قد تكون إدارة الـ mutexes صعبة للغاية، ولهذا السبب فإن الكثير من الناس متحمسون لـ channels. ومع ذلك، بفضل الـ type system وقواعد الـ ownership في Rust، لا يمكنك أن تخطئ في الـ locking والـ unlocking.
واجهة برمجة التطبيقات لـ Mutex<T>
كمثال على كيفية استخدام mutex، دعنا نبدأ باستخدام mutex في سياق thread واحد، كما هو موضح في القائمة 16-12.
use std::sync::Mutex;
fn main() {
let m = Mutex::new(5);
{
let mut num = m.lock().unwrap();
*num = 6;
}
println!("m = {m:?}");
}كما هو الحال مع العديد من الـ types، ننشئ Mutex<T> باستخدام الدالة المرتبطة (associated function) new. للوصول إلى الـ data داخل الـ mutex، نستخدم method lock للحصول على الـ lock. سيؤدي هذا الاستدعاء إلى حظر الـ thread الحالي بحيث لا يمكنه القيام بأي عمل حتى يحين دورنا للحصول على الـ lock.
سيفشل استدعاء lock إذا أصيب thread آخر يحمل الـ lock بالذعر (panicked). في هذه الحالة، لن يتمكن أحد من الحصول على الـ lock، لذلك اخترنا unwrap وجعل هذا الـ thread يصاب بالذعر إذا كنا في هذا الموقف.
بعد أن حصلنا على الـ lock، يمكننا التعامل مع القيمة المرجعة، المسماة num في هذه الحالة، كـ mutable reference للـ data الداخلية. يضمن الـ type system أننا نحصل على lock قبل استخدام القيمة في m. نوع m هو Mutex<i32>، وليس i32، لذلك يجب علينا استدعاء lock لنتمكن من استخدام قيمة i32. لا يمكننا أن ننسى؛ لن يسمح لنا الـ type system بالوصول إلى الـ i32 الداخلي بخلاف ذلك.
يعيد استدعاء lock نوعًا يسمى MutexGuard، ملفوفًا في LockResult الذي تعاملنا معه باستدعاء unwrap. يطبق نوع MutexGuard سمة Deref للإشارة إلى الـ data الداخلية الخاصة بنا؛ يحتوي الـ type أيضًا على تطبيق الإسقاط (Drop implementation) الذي يحرر الـ lock تلقائيًا عندما يخرج MutexGuard من النطاق (scope)، وهو ما يحدث في نهاية الـ scope الداخلي. نتيجة لذلك، لا نخاطر بنسيان تحرير الـ lock وحظر الـ mutex من استخدامه بواسطة threads أخرى لأن تحرير الـ lock يحدث تلقائيًا.
بعد إسقاط الـ lock، يمكننا طباعة قيمة الـ mutex ونرى أننا تمكنا من تغيير الـ i32 الداخلي إلى 6.
الوصول المشترك إلى Mutex<T>
الآن دعنا نحاول مشاركة قيمة بين threads متعددة باستخدام Mutex<T>. سنقوم بتشغيل 10 threads ونجعل كل واحد منها يزيد قيمة عداد (counter) بمقدار 1، بحيث ينتقل الـ counter من 0 إلى 10. سيحتوي المثال في القائمة 16-13 على خطأ compiler، وسنستخدم هذا الخطأ لمعرفة المزيد حول استخدام Mutex<T> وكيف تساعدنا Rust في استخدامه بشكل صحيح.
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}ننشئ متغير counter لاحتواء i32 داخل Mutex<T>، كما فعلنا في القائمة 16-12. بعد ذلك، ننشئ 10 threads عن طريق التكرار على نطاق من الأرقام. نستخدم thread::spawn ونعطي جميع الـ threads نفس الـ closure: واحد ينقل الـ counter إلى الـ thread، ويحصل على lock على Mutex<T> عن طريق استدعاء method lock، ثم يضيف 1 إلى القيمة في الـ mutex. عندما ينتهي الـ thread من تشغيل الـ closure الخاص به، سيخرج num من الـ scope ويحرر الـ lock حتى يتمكن thread آخر من الحصول عليه.
في الـ main thread، نجمع جميع مقابض الانضمام (join handles). بعد ذلك، كما فعلنا في القائمة 16-2، نستدعي join على كل handle للتأكد من انتهاء جميع الـ threads. عند هذه النقطة، سيحصل الـ main thread على الـ lock ويطبع نتيجة هذا البرنامج.
لقد أشرنا إلى أن هذا المثال لن يتم تجميعه. الآن دعنا نكتشف السبب!
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: borrow of moved value: `counter`
--> src/main.rs:21:29
|
5 | let counter = Mutex::new(0);
| ------- move occurs because `counter` has type `std::sync::Mutex<i32>`, which does not implement the `Copy` trait
...
8 | for _ in 0..10 {
| -------------- inside of this loop
9 | let handle = thread::spawn(move || {
| ------- value moved into closure here, in previous iteration of loop
...
21 | println!("Result: {}", *counter.lock().unwrap());
| ^^^^^^^ value borrowed here after move
|
help: consider moving the expression out of the loop so it is only moved once
|
8 ~ let mut value = counter.lock();
9 ~ for _ in 0..10 {
10 | let handle = thread::spawn(move || {
11 ~ let mut num = value.unwrap();
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
تنص رسالة الخطأ على أن قيمة counter قد تم نقلها (moved) في التكرار السابق للـ loop. تخبرنا Rust أنه لا يمكننا نقل الـ ownership لـ lock counter إلى threads متعددة. دعنا نصلح خطأ الـ compiler باستخدام طريقة الـ multiple-ownership التي ناقشناها في الفصل 15.
الـ Multiple Ownership مع الـ Threads المتعددة
في الفصل 15، أعطينا قيمة لـ owners متعددين باستخدام الـ smart pointer Rc<T> لإنشاء قيمة مرجعية العد (reference-counted). دعنا نفعل الشيء نفسه هنا ونرى ما سيحدث. سنقوم بلف Mutex<T> في Rc<T> في القائمة 16-14 واستنساخ (clone) الـ Rc<T> قبل نقل الـ ownership إلى الـ thread.
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}مرة أخرى، نقوم بالـ compile ونحصل على… أخطاء مختلفة! الـ compiler يعلمنا الكثير:
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `{closure@src/main.rs:11:36: 11:43}`
| | |
| | required by a bound introduced by this call
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:11:36: 11:43}`, the trait `Send` is not implemented for `Rc<std::sync::Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:723:1
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
يا إلهي، رسالة الخطأ مطولة جدًا! إليك الجزء المهم الذي يجب التركيز عليه: `Rc<Mutex<i32>>` cannot be sent between threads safely. يخبرنا الـ compiler أيضًا بالسبب: the trait `Send` is not implemented for `Rc<Mutex<i32>>`. سنتحدث عن Send في القسم التالي: إنها إحدى الـ traits التي تضمن أن الـ types التي نستخدمها مع الـ threads مخصصة للاستخدام في مواقف التزامن (concurrent situations).
لسوء الحظ، Rc<T> ليس آمنًا للمشاركة عبر الـ threads. عندما يدير Rc<T> عداد الـ reference، فإنه يضيف إلى العداد لكل استدعاء لـ clone ويطرح من العداد عندما يتم إسقاط كل clone. لكنه لا يستخدم أي concurrency primitives للتأكد من أن التغييرات على العداد لا يمكن أن يقاطعها thread آخر. قد يؤدي هذا إلى أعداد خاطئة - أخطاء خفية يمكن أن تؤدي بدورها إلى تسرب الذاكرة (memory leaks) أو إسقاط قيمة قبل الانتهاء منها. ما نحتاجه هو نوع يشبه تمامًا Rc<T>، ولكنه يجري تغييرات على عداد الـ reference بطريقة آمنة للـ thread.
عد مرجعي ذري (Atomic Reference Counting) باستخدام Arc<T>
لحسن الحظ، Arc<T> هو نوع مثل Rc<T> آمن للاستخدام في مواقف التزامن. يشير الحرف a إلى ذري (atomic)، مما يعني أنه نوع مرجعي العد ذريًا (atomically reference-counted). الـ Atomics هي نوع إضافي من concurrency primitive لن نغطيه بالتفصيل هنا: راجع وثائق الـ standard library لـ std::sync::atomic لمزيد من التفاصيل. في هذه المرحلة، تحتاج فقط إلى معرفة أن الـ atomics تعمل مثل الـ primitive types ولكنها آمنة للمشاركة عبر الـ threads.
قد تتساءل إذن لماذا ليست جميع الـ primitive types ذرية ولماذا لم يتم تطبيق الـ standard library types لاستخدام Arc<T> افتراضيًا. السبب هو أن أمان الـ thread يأتي مع عقوبة في الأداء لا تريد دفعها إلا عندما تحتاج إليها حقًا. إذا كنت تجري عمليات على قيم داخل thread واحد فقط، يمكن أن يعمل الكود الخاص بك بشكل أسرع إذا لم يكن مضطرًا لفرض الضمانات التي توفرها الـ atomics.
دعنا نعود إلى مثالنا: يحتوي Arc<T> و Rc<T> على نفس واجهة برمجة التطبيقات (API)، لذلك نصلح برنامجنا عن طريق تغيير سطر use، واستدعاء new، واستدعاء clone. سيتم تجميع وتشغيل الكود في القائمة 16-15 أخيرًا.
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}سيقوم هذا الكود بطباعة ما يلي:
Result: 10
لقد فعلناها! لقد قمنا بالعد من 0 إلى 10، وهو ما قد لا يبدو مثيرًا للإعجاب، ولكنه علمنا الكثير عن Mutex<T> وأمان الـ thread. يمكنك أيضًا استخدام بنية هذا البرنامج لإجراء عمليات أكثر تعقيدًا من مجرد زيادة عداد. باستخدام هذه الاستراتيجية، يمكنك تقسيم عملية حسابية إلى أجزاء مستقلة، وتقسيم هذه الأجزاء عبر الـ threads، ثم استخدام Mutex<T> لجعل كل thread يقوم بتحديث النتيجة النهائية بجزئه.
لاحظ أنه إذا كنت تجري عمليات رقمية بسيطة، فهناك أنواع أبسط من أنواع Mutex<T> التي توفرها وحدة std::sync::atomic في الـ standard library. توفر هذه الـ types وصولًا آمنًا ومتزامنًا وذريًا إلى الـ primitive types. اخترنا استخدام Mutex<T> مع primitive type لهذا المثال حتى نتمكن من التركيز على كيفية عمل Mutex<T>.
مقارنة RefCell<T>/Rc<T> و Mutex<T>/Arc<T>
ربما لاحظت أن counter غير قابل للتغيير (immutable) ولكن يمكننا الحصول على mutable reference للقيمة بداخله؛ هذا يعني أن Mutex<T> يوفر قابلية التغيير الداخلية (interior mutability)، كما تفعل عائلة Cell. بنفس الطريقة التي استخدمنا بها RefCell<T> في الفصل 15 للسماح لنا بتغيير المحتويات داخل Rc<T>، نستخدم Mutex<T> لتغيير المحتويات داخل Arc<T>.
هناك تفصيل آخر يجب ملاحظته وهو أن Rust لا يمكنها حمايتك من جميع أنواع أخطاء المنطق (logic errors) عند استخدام Mutex<T>. تذكر من الفصل 15 أن استخدام Rc<T> جاء مع خطر إنشاء دورات مرجعية (reference cycles)، حيث يشير قيمتا Rc<T> إلى بعضهما البعض، مما يتسبب في memory leaks. وبالمثل، يأتي Mutex<T> مع خطر إنشاء جمود (deadlocks). تحدث هذه عندما تحتاج عملية ما إلى قفل موردين (resources) ويكون كل من threadين قد حصل على أحد الـ locks، مما يجعلهما ينتظران بعضهما البعض إلى الأبد. إذا كنت مهتمًا بالـ deadlocks، فحاول إنشاء برنامج Rust يحتوي على deadlock؛ ثم ابحث عن استراتيجيات التخفيف من الـ deadlock لـ mutexes في أي لغة وحاول تطبيقها في Rust. توفر وثائق API لـ Mutex<T> و MutexGuard في الـ standard library معلومات مفيدة.
سنختتم هذا الفصل بالحديث عن سمات الإرسال والمزامنة (Send and Sync traits) وكيف يمكننا استخدامها مع الـ custom types.
التزامن القابل للتوسع مع Send و Sync
التزامن القابل للتوسع باستخدام Send و Sync (Extensible Concurrency with Send and Sync)
من المثير للاهتمام أن كل ميزة من ميزات التزامن (concurrency) التي تحدثنا عنها حتى الآن في هذا الفصل كانت جزءاً من المكتبة القياسية (standard library)، وليست جزءاً من اللغة نفسها. خياراتك للتعامل مع التزامن لا تقتصر على اللغة أو المكتبة القياسية؛ يمكنك كتابة ميزات التزامن الخاصة بك أو استخدام تلك التي كتبها الآخرون.
ومع ذلك، من بين مفاهيم التزامن الرئيسية المضمنة في اللغة بدلاً من المكتبة القياسية هي سمات (traits) الواسمات (marker traits) الموجودة في std::marker وهما Send و Sync.
نقل الملكية بين الخيوط (Transferring Ownership Between Threads)
تشير سمة الواسم Send إلى أن ملكية (ownership) القيم من النوع الذي ينفذ Send يمكن نقلها بين الخيوط (threads). ينفذ كل نوع في Rust تقريباً سمة Send ، ولكن هناك بعض الاستثناءات، بما في ذلك Rc<T>: لا يمكن لهذا النوع تنفيذ Send لأنه إذا قمت بنسخ (cloned) قيمة Rc<T> وحاولت نقل ملكية النسخة إلى خيط آخر، فقد يقوم كلا الخيطين بتحديث عداد المراجع (reference count) في نفس الوقت. لهذا السبب، تم تنفيذ Rc<T> للاستخدام في حالات الخيط الواحد (single-threaded) حيث لا تريد دفع ضريبة أداء الأمان بين الخيوط.
لذلك، يضمن نظام الأنواع (type system) في Rust وقيود السمات (trait bounds) أنك لن ترسل أبداً قيمة Rc<T> عبر threads بشكل غير آمن عن طريق الخطأ. عندما حاولنا القيام بذلك في القائمة 16-14، حصلنا على الخطأ the trait `Send` is not implemented for `Rc<Mutex<i32>>`. عندما انتقلنا إلى Arc<T> ، الذي ينفذ Send ، تم تجميع (compiled) الكود.
أي نوع يتكون بالكامل من أنواع تنفذ Send يتم وسمه تلقائياً كـ Send أيضاً. جميع الأنواع الأولية (primitive types) هي Send تقريباً، باستثناء المؤشرات الخام (raw pointers)، والتي سنناقشها في الفصل العشرين.
الوصول من خيوط متعددة (Accessing from Multiple Threads)
تشير سمة الواسم Sync إلى أنه من الآمن للنوع الذي ينفذ Sync أن يتم الرجوع إليه من threads متعددة. بعبارة أخرى، أي نوع T ينفذ Sync إذا كان &T (مرجع غير قابل للتغيير لـ T) ينفذ Send ، مما يعني أنه يمكن إرسال المرجع (reference) بأمان إلى خيط آخر. على غرار Send ، تنفذ جميع primitive types سمة Sync ، والأنواع المكونة بالكامل من أنواع تنفذ Sync تنفذ أيضاً Sync.
المؤشر الذكي (smart pointer) من نوع Rc<T> لا ينفذ أيضاً Sync لنفس الأسباب التي تجعله لا ينفذ Send. النوع RefCell<T> (الذي تحدثنا عنه في الفصل الخامس عشر) وعائلة الأنواع المرتبطة Cell<T> لا تنفذ Sync. إن تنفيذ فحص الاستعارة (borrow checking) الذي يقوم به RefCell<T> في وقت التشغيل (runtime) ليس آمناً بين الخيوط. ينفذ smart pointer من نوع Mutex<T> سمة Sync ويمكن استخدامه لمشاركة الوصول مع threads متعددة، كما رأيت في قسم “الوصول المشترك إلى Mutex<T>”.
تنفيذ Send و Sync يدوياً غير آمن (Implementing Send and Sync Manually Is Unsafe)
بما أن الأنواع المكونة بالكامل من أنواع أخرى تنفذ سمات Send و Sync تنفذ أيضاً Send و Sync تلقائياً، فلا يتعين علينا تنفيذ تلك traits يدوياً. وبصفتها marker traits، فهي لا تحتوي حتى على أي دوال (methods) لتنفيذها. إنها مفيدة فقط لفرض الثوابت (invariants) المتعلقة بـ concurrency.
يتضمن تنفيذ هذه السمات يدوياً كتابة كود Rust غير آمن (unsafe Rust code). سنتحدث عن استخدام unsafe Rust code في الفصل العشرين؛ في الوقت الحالي، المعلومات المهمة هي أن بناء أنواع متزامنة جديدة لا تتكون من أجزاء تنفذ Send و Sync يتطلب تفكيراً دقيقاً للحفاظ على ضمانات الأمان. يحتوي كتاب “The Rustonomicon” على مزيد من المعلومات حول هذه الضمانات وكيفية الحفاظ عليها.
ملخص (Summary)
ليست هذه هي المرة الأخيرة التي سترى فيها التزامن في هذا الكتاب: الفصل القادم يركز على البرمجة غير المتزامنة (async programming)، وسوف يستخدم المشروع في الفصل الحادي والعشرين المفاهيم الواردة في هذا الفصل في موقف أكثر واقعية من الأمثلة الصغيرة التي نوقشت هنا.
كما ذكرنا سابقاً، ولأن القليل جداً من كيفية تعامل Rust مع concurrency هو جزء من اللغة، فإن العديد من حلول التزامن يتم تنفيذها كـ حزم (crates). هذه تتطور بسرعة أكبر من المكتبة القياسية، لذا تأكد من البحث عبر الإنترنت عن أحدث crates لاستخدامها في حالات الخيوط المتعددة (multithreaded).
توفر مكتبة Rust القياسية قنوات (channels) لتمرير الرسائل (message passing) وأنواع المؤشرات الذكية، مثل Mutex<T> و Arc<T> ، والتي تعد آمنة للاستخدام في سياقات التزامن. يضمن نظام الأنواع وفاحص الاستعارة (borrow checker) أن الكود الذي يستخدم هذه الحلول لن ينتهي به الأمر بسباقات البيانات (data races) أو مراجع غير صالحة. بمجرد أن يتم تجميع الكود الخاص بك، يمكنك أن تطمئن إلى أنه سيعمل بسعادة على threads متعددة دون أنواع الأخطاء التي يصعب تتبعها والشائعة في اللغات الأخرى. لم تعد البرمجة المتزامنة مفهوماً يدعو للخوف: انطلق واجعل برامجك متزامنة، بلا خوف!
أساسيات البرمجة غير المتزامنة (Asynchronous Programming): Async، وAwait، وFutures، وStreams
تستغرق العديد من العمليات التي نطلب من الحاسوب القيام بها وقتاً طويلاً للانتهاء. سيكون من الجيد لو تمكنا من القيام بشيء آخر بينما ننتظر اكتمال تلك العمليات الطويلة الأمد. توفر الحواسيب الحديثة تقنيتين للعمل على أكثر من عملية في وقت واحد: التوازي (Parallelism) والتزامن (Concurrency). ومع ذلك، فإن منطق برامجنا مكتوب بطريقة خطية غالباً. نود أن نكون قادرين على تحديد العمليات التي يجب أن يؤديها البرنامج والنقاط التي يمكن للدالة (Function) عندها أن تتوقف مؤقتاً ويمكن لجزء آخر من البرنامج أن يعمل بدلاً منها، دون الحاجة إلى تحديد الترتيب والطريقة التي يجب أن يعمل بها كل جزء من الكود (Code) مسبقاً وبدقة. البرمجة غير المتزامنة (Asynchronous Programming) هي تجريد (Abstraction) يسمح لنا بالتعبير عن الكود الخاص بنا من حيث نقاط التوقف المحتملة والنتائج النهائية التي تتولى تفاصيل التنسيق نيابة عنا.
يبني هذا الفصل على استخدام الفصل 16 للخيوط (Threads) من أجل Parallelism وConcurrency من خلال تقديم نهج بديل لكتابة Code: العقود (Futures) في Rust، والمجاري (Streams)، وصيغة async وawait التي تتيح لنا التعبير عن كيفية جعل العمليات غير متزامنة، والحزم (Crates) الخارجية التي تنفذ بيئات التشغيل غير المتزامنة (Asynchronous Runtimes): Code الذي يدير وينسق تنفيذ العمليات غير المتزامنة.
لنلقِ نظرة على مثال. لنفترض أنك تقوم بتصدير مقطع فيديو أنشأته لاحتفال عائلي، وهي عملية قد تستغرق من دقائق إلى ساعات. سيستخدم تصدير الفيديو أكبر قدر ممكن من قوة وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU). إذا كان لديك قلب CPU واحد فقط ولم يقم نظام التشغيل (Operating System) الخاص بك بإيقاف هذا التصدير مؤقتاً حتى يكتمل - أي إذا قام بتنفيذ التصدير بشكل متزامن (Synchronously) - فلن تتمكن من القيام بأي شيء آخر على حاسوبك أثناء تشغيل تلك المهمة. ستكون تلك تجربة محبطة للغاية. لحسن الحظ، يمكن لـ Operating System الخاص بحاسوبك، وهو يفعل ذلك بالفعل، مقاطعة التصدير بشكل غير مرئي بما يكفي للسماح لك بإنجاز أعمال أخرى في نفس الوقت.
لنفترض الآن أنك تقوم بتنزيل مقطع فيديو شاركه شخص آخر، وهو ما قد يستغرق وقتاً طويلاً أيضاً ولكنه لا يستهلك الكثير من وقت CPU. في هذه الحالة، يتعين على CPU انتظار وصول البيانات من الشبكة (Network). وبينما يمكنك البدء في قراءة البيانات بمجرد بدء وصولها، فقد يستغرق الأمر بعض الوقت حتى تظهر كلها. وحتى بمجرد توفر البيانات بالكامل، إذا كان الفيديو كبيراً جداً، فقد يستغرق تحميله بالكامل ثانية أو ثانيتين على الأقل. قد لا يبدو هذا وقتاً طويلاً، ولكنه وقت طويل جداً بالنسبة للمعالج (Processor) الحديث، الذي يمكنه أداء مليارات العمليات كل ثانية. مرة أخرى، سيقوم Operating System الخاص بك بمقاطعة برنامجك بشكل غير مرئي للسماح لـ CPU بأداء أعمال أخرى أثناء انتظار انتهاء استدعاء Network.
تصدير الفيديو هو مثال على عملية مقيدة بـ CPU (CPU-bound) أو مقيدة بالحوسبة (Compute-bound). فهي محدودة بسرعات معالجة البيانات المحتملة للحاسوب داخل CPU أو GPU، ومقدار تلك السرعة التي يمكن تخصيصها للعملية. تنزيل الفيديو هو مثال على عملية مقيدة بالإدخال والإخراج (I/O-bound)، لأنها محدودة بسرعة الإدخال والإخراج (Input and Output) للحاسوب؛ حيث لا يمكنها السير إلا بالسرعة التي يمكن بها إرسال البيانات عبر Network.
في كلا المثالين، توفر المقاطعات غير المرئية لنظام التشغيل شكلاً من أشكال Concurrency. ومع ذلك، فإن هذا Concurrency يحدث فقط على مستوى البرنامج بأكمله: يقاطع Operating System برنامجاً واحداً للسماح للبرامج الأخرى بإنجاز عملها. في كثير من الحالات، ولأننا نفهم برامجنا بمستوى أكثر تفصيلاً مما يفعله Operating System، يمكننا اكتشاف فرص لـ Concurrency لا يستطيع Operating System رؤيتها.
على سبيل المثال، إذا كنا نبني أداة لإدارة تنزيلات الملفات، فيجب أن نكون قادرين على كتابة برنامجنا بحيث لا يؤدي بدء تنزيل واحد إلى قفل واجهة المستخدم (UI)، ويجب أن يتمكن المستخدمون من بدء تنزيلات متعددة في نفس الوقت. ومع ذلك، فإن العديد من واجهات برمجة تطبيقات (APIs) نظام التشغيل للتفاعل مع Network هي واجهات حاجبة (Blocking)؛ أي أنها تحجب تقدم البرنامج حتى تصبح البيانات التي تعالجها جاهزة تماماً.
ملاحظة: هذه هي الطريقة التي تعمل بها معظم استدعاءات Functions، إذا فكرت في الأمر. ومع ذلك، فإن مصطلح Blocking عادة ما يكون محجوزاً لاستدعاءات Functions التي تتفاعل مع الملفات، أو Network، أو الموارد الأخرى على الحاسوب، لأن هذه هي الحالات التي يستفيد فيها البرنامج الفردي من كون العملية غير حاجبة (Non-blocking).
يمكننا تجنب حجب الخيط الرئيسي (Main Thread) الخاص بنا عن طريق إنشاء Thread مخصص لتنزيل كل ملف. ومع ذلك، فإن العبء الإضافي لموارد النظام التي تستخدمها تلك Threads سيصبح مشكلة في النهاية. سيكون من الأفضل إذا لم يكن الاستدعاء Blocking في المقام الأول، وبدلاً من ذلك يمكننا تحديد عدد من المهام التي نود أن يكملها برنامجنا والسماح لـ Runtime باختيار أفضل ترتيب وطريقة لتشغيلها.
هذا هو بالضبط ما يوفره لنا تجريب Async (اختصار لـ Asynchronous) في Rust. في هذا الفصل، ستتعلم كل شيء عن Async حيث نغطي المواضيع التالية:
- كيفية استخدام صيغة
asyncوawaitفي Rust وتنفيذ الدوال غير المتزامنة (Asynchronous Functions) باستخدام Runtime. - كيفية استخدام نموذج Async لحل بعض التحديات نفسها التي اطلعنا عليها في الفصل 16.
- كيف يوفر تعدد الخيوط (Multithreading) وAsync حلولاً متكاملة يمكنك دمجها في كثير من الحالات.
قبل أن نرى كيف يعمل Async في الممارسة العملية، نحتاج إلى أخذ جولة قصيرة لمناقشة الاختلافات بين Parallelism وConcurrency.
التوازي والتزامن (Parallelism and Concurrency)
لقد تعاملنا مع Parallelism وConcurrency كأنهما قابلان للتبادل غالباً حتى الآن. الآن نحتاج إلى التمييز بينهما بدقة أكبر، لأن الاختلافات ستظهر بمجرد أن نبدأ العمل.
فكر في الطرق المختلفة التي يمكن للفريق من خلالها تقسيم العمل في مشروع برمجي. يمكنك تكليف عضو واحد بمهام متعددة، أو تكليف كل عضو بمهمة واحدة، أو استخدام مزيج من النهجين.
عندما يعمل فرد على عدة مهام مختلفة قبل اكتمال أي منها، فإن هذا يسمى تزامناً (Concurrency). إحدى طرق تنفيذ Concurrency تشبه وجود مشروعين مختلفين مفتوحين على حاسوبك، وعندما تشعر بالملل أو تتعثر في مشروع واحد، تنتقل إلى الآخر. أنت شخص واحد فقط، لذا لا يمكنك إحراز تقدم في كلتا المهمتين في نفس الوقت تماماً، ولكن يمكنك القيام بمهام متعددة (Multitask)، وإحراز تقدم في مهمة واحدة تلو الأخرى عن طريق التبديل بينهما (انظر الشكل 17-1).

عندما يقوم الفريق بتقسيم مجموعة من المهام من خلال قيام كل عضو بأخذ مهمة واحدة والعمل عليها بمفرده، فإن هذا يسمى توازياً (Parallelism). يمكن لكل شخص في الفريق إحراز تقدم في نفس الوقت تماماً (انظر الشكل 17-2).

في كلا سيري العمل هذين، قد تضطر إلى التنسيق بين المهام المختلفة. ربما اعتقدت أن المهمة المسندة لشخص واحد كانت مستقلة تماماً عن عمل أي شخص آخر، ولكنها تتطلب في الواقع أن ينهي شخص آخر في الفريق مهمته أولاً. يمكن القيام ببعض العمل بشكل متوازٍ، ولكن بعضه كان في الواقع تسلسلياً (Serial): لا يمكن أن يحدث إلا في سلسلة، مهمة تلو الأخرى، كما في الشكل 17-3.

وبالمثل، قد تدرك أن إحدى مهامك تعتمد على مهمة أخرى من مهامك. الآن أصبح عملك المتزامن تسلسلياً أيضاً.
يمكن أن يتقاطع Parallelism وConcurrency مع بعضهما البعض أيضاً. إذا علمت أن زميلاً لك متعثر حتى تنهي إحدى مهامك، فمن المحتمل أن تركز كل جهودك على تلك المهمة لـ “فك حجب” (Unblock) زميلك. لم تعد أنت وزميلك قادرين على العمل بشكل متوازٍ، ولم تعد قادراً أيضاً على العمل بشكل متزامن على مهامك الخاصة.
نفس الديناميكيات الأساسية تلعب دوراً في البرمجيات والأجهزة. في آلة ذات قلب CPU واحد، يمكن لـ CPU أداء عملية واحدة فقط في كل مرة، ولكن لا يزال بإمكانه العمل بشكل متزامن. باستخدام أدوات مثل Threads، والعمليات (Processes)، وAsync، يمكن للحاسوب إيقاف نشاط واحد مؤقتاً والانتقال إلى أنشطة أخرى قبل العودة في النهاية إلى ذلك النشاط الأول مرة أخرى. في آلة ذات قلوب CPU متعددة، يمكنه أيضاً القيام بالعمل بشكل متوازٍ. يمكن لقلب واحد أن يؤدي مهمة واحدة بينما يؤدي قلب آخر مهمة غير مرتبطة تماماً، وتحدث تلك العمليات في نفس الوقت فعلياً.
تشغيل Code غير متزامن في Rust يحدث عادةً بشكل متزامن. اعتماداً على الأجهزة، ونظام التشغيل، وAsynchronous Runtime الذي نستخدمه (المزيد عن Asynchronous Runtimes قريباً)، قد يستخدم هذا Concurrency أيضاً Parallelism في الخفاء.
الآن، دعونا نتعمق في كيفية عمل البرمجة غير المتزامنة في Rust فعلياً.
الفيوتشرز (Futures) وبناء جملة Async
العقود الآجلة وبناء جملة Async (Futures and the Async Syntax)
العناصر الأساسية للبرمجة غير المتزامنة (asynchronous programming) في Rust هي العقود الآجلة (futures) والكلمات المفتاحية async و await الخاصة بـ Rust.
الـ Future هو قيمة قد لا تكون جاهزة الآن ولكنها ستصبح جاهزة في مرحلة ما في المستقبل. (يظهر هذا المفهوم نفسه في العديد من اللغات، أحيانًا تحت أسماء أخرى مثل المهمة (task) أو الوعد (promise)). توفر Rust سمة (trait) تسمى Future كبنة بناء بحيث يمكن تنفيذ عمليات async مختلفة بهياكل بيانات مختلفة ولكن بواجهة مشتركة. في Rust، الـ futures هي أنواع تنفذ الـ Future trait. يحتفظ كل future بمعلوماته الخاصة حول التقدم الذي تم إحرازه وماذا يعني أن يكون “جاهزًا”.
يمكنك تطبيق الكلمة المفتاحية async على الكتل (blocks) والدوال (functions) لتحديد إمكانية مقاطعتها واستئنافها. داخل كتلة async أو دالة async، يمكنك استخدام الكلمة المفتاحية await لانتظار future (أي انتظار أن يصبح جاهزًا). أي نقطة تقوم فيها بانتظار future باستخدام await داخل كتلة أو دالة async هي نقطة محتملة لتوقف تلك الكتلة أو الدالة مؤقتًا واستئنافها. تسمى عملية التحقق من الـ future لمعرفة ما إذا كانت قيمته متاحة بعد بـ الاستطلاع (polling).
تستخدم بعض اللغات الأخرى، مثل C# و JavaScript، أيضًا الكلمات المفتاحية async و await للبرمجة غير المتزامنة. إذا كنت معتادًا على تلك اللغات، فقد تلاحظ بعض الاختلافات الجوهرية في كيفية تعامل Rust مع بناء الجملة. وهذا لسبب وجيه، كما سنرى!
عند كتابة async Rust، نستخدم الكلمات المفتاحية async و await معظم الوقت. يقوم Rust بترجمتها إلى كود مكافئ باستخدام الـ Future trait، تمامًا كما يترجم حلقات for إلى كود مكافئ باستخدام الـ Iterator trait. نظرًا لأن Rust يوفر الـ Future trait، يمكنك أيضًا تنفيذه لأنواع البيانات الخاصة بك عند الحاجة. العديد من الدوال التي سنراها في هذا الفصل تعيد أنواعًا لها تنفيذاتها الخاصة لـ Future. سنعود إلى تعريف الـ trait في نهاية الفصل ونتعمق في كيفية عمله، لكن هذا القدر من التفاصيل كافٍ لمواصلة المضي قدمًا.
قد يبدو كل هذا مجردًا بعض الشيء، لذا دعنا نكتب أول برنامج async لنا: أداة بسيطة لكشط الويب (web scraper). سنمرر عنواني URL من سطر الأوامر، ونجلبهما معًا بالتزامن (concurrently)، ونعيد نتيجة أيهما ينتهي أولاً. سيحتوي هذا المثال على قدر لا بأس به من بناء الجملة الجديد، لكن لا تقلق - سنشرح كل ما تحتاج إلى معرفته أثناء المضي قدمًا.
أول برنامج Async لنا
للحفاظ على تركيز هذا الفصل على تعلم async بدلاً من التعامل مع أجزاء النظام البيئي (ecosystem)، قمنا بإنشاء حزمة (crate) تسمى trpl (وهي اختصار لـ “The Rust Programming Language”). تقوم بإعادة تصدير (re-export) جميع الأنواع والـ traits والدوال التي ستحتاجها، بشكل أساسي من حزم futures و tokio. حزمة futures هي الموطن الرسمي لتجارب Rust لأكواد async، وهي في الواقع المكان الذي تم فيه تصميم الـ Future trait في الأصل. Tokio هو وقت التشغيل غير المتزامن (async runtime) الأكثر استخدامًا في Rust اليوم، خاصة لتطبيقات الويب. هناك أوقات تشغيل رائعة أخرى، وقد تكون أكثر ملاءمة لأغراضك. نحن نستخدم حزمة tokio داخليًا لـ trpl لأنها مختبرة جيدًا ومستخدمة على نطاق واسع.
في بعض الحالات، تقوم trpl أيضًا بإعادة تسمية أو تغليف واجهات برمجة التطبيقات (APIs) الأصلية لإبقائك مركزًا على التفاصيل ذات الصلة بهذا الفصل. إذا كنت تريد فهم ما تفعله الحزمة، فنحن نشجعك على مراجعة كود المصدر الخاص بها. ستتمكن من رؤية الحزمة التي يأتي منها كل re-export، وقد تركنا تعليقات مكثفة تشرح ما تفعله الحزمة.
أنشئ مشروعًا ثنائيًا (binary project) جديدًا باسم hello-async وأضف حزمة trpl كاعتمادية (dependency):
$ cargo new hello-async
$ cd hello-async
$ cargo add trpl
الآن يمكننا استخدام الأجزاء المختلفة التي توفرها trpl لكتابة أول برنامج async لنا. سنقوم ببناء أداة سطر أوامر بسيطة تجلب صفحتين ويب، وتسحب عنصر <title> من كل منهما، وتطبع عنوان الصفحة التي تنهي تلك العملية بالكامل أولاً.
تعريف دالة page_title
لنبدأ بكتابة دالة تأخذ عنوان URL لصفحة كـ parameter، وتقوم بإنشاء طلب (request) إليها، وتعيد نص عنصر <title> (انظر القائمة 17-1).
extern crate trpl; // required for mdbook test
fn main() {
// TODO: we'll add this next!
}
use trpl::Html;
async fn page_title(url: &str) -> Option<String> {
let response = trpl::get(url).await;
let response_text = response.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}أولاً، نعرّف دالة باسم page_title ونميزها بالكلمة المفتاحية async. ثم نستخدم الدالة trpl::get لجلب أي عنوان URL يتم تمريره ونضيف الكلمة المفتاحية await لانتظار الاستجابة (response). للحصول على نص الـ response نطلب دالة text الخاصة بها وننتظرها مرة أخرى باستخدام الكلمة المفتاحية await. كلتا الخطوتين غير متزامنتين. بالنسبة لدالة get يتعين علينا انتظار الخادم لإرسال الجزء الأول من استجابته، والذي سيتضمن ترويسات HTTP (HTTP headers) وملفات تعريف الارتباط (cookies) وما إلى ذلك ويمكن تسليمها بشكل منفصل عن جسم الاستجابة (response body). خاصة إذا كان الجسم كبيرًا جدًا، فقد يستغرق وصوله بالكامل بعض الوقت. نظرًا لأنه يتعين علينا انتظار وصول الاستجابة بالكامل، فإن دالة text هي أيضًا async.
يتعين علينا انتظار كلا الـ futures صراحةً، لأن الـ futures في Rust كسولة (lazy): فهي لا تفعل أي شيء حتى تطلب منها ذلك باستخدام الكلمة المفتاحية await. (في الواقع، سيعرض Rust تحذيرًا من المترجم إذا لم تستخدم future). قد يذكرك هذا بمناقشة المكررات (iterators) في قسم “معالجة سلسلة من العناصر باستخدام المكررات” في الفصل 13. لا تفعل الـ iterators شيئًا ما لم تستدعِ دالة next الخاصة بها - سواء بشكل مباشر أو باستخدام حلقات for أو دوال مثل map التي تستخدم next داخليًا. وبالمثل، لا تفعل الـ futures شيئًا ما لم تطلب منها ذلك صراحةً. يسمح هذا الكسل لـ Rust بتجنب تشغيل كود async حتى تبرز الحاجة إليه فعليًا.
ملاحظة: هذا يختلف عن السلوك الذي رأيناه عند استخدام
thread::spawnفي قسم “إنشاء خيط جديد باستخدام spawn” في الفصل 16، حيث بدأت الـ closure التي مررناها إلى خيط (thread) آخر في العمل على الفور. كما أنه يختلف عن كيفية تعامل العديد من اللغات الأخرى مع async. ولكنه مهم لـ Rust لتكون قادرة على تقديم ضمانات الأداء الخاصة بها، تمامًا كما هو الحال مع الـ iterators.
بمجرد حصولنا على response_text يمكننا تحليلها إلى مثيل من نوع Html باستخدام Html::parse. بدلاً من سلسلة نصية خام (raw string)، أصبح لدينا الآن نوع بيانات يمكننا استخدامه للتعامل مع HTML كهيكل بيانات أغنى. على وجه الخصوص، يمكننا استخدام دالة select_first للعثور على أول مثيل لمحدد CSS (CSS selector) معين. من خلال تمرير السلسلة النصية "title" سنحصل على أول عنصر <title> في المستند، إذا وجد. نظرًا لأنه قد لا يكون هناك أي عنصر مطابق، فإن select_first تعيد Option<ElementRef>. أخيرًا، نستخدم دالة Option::map التي تتيح لنا التعامل مع العنصر الموجود في الـ Option إذا كان حاضرًا، وعدم فعل شيء إذا لم يكن كذلك. (يمكننا أيضًا استخدام تعبير match هنا، لكن map أكثر تعبيرًا (idiomatic)). في جسم الدالة التي نوفرها لـ map نستدعي inner_html على الـ title للحصول على محتواه، وهو String. عندما ينتهي كل شيء، يكون لدينا Option<String>.
لاحظ أن الكلمة المفتاحية await في Rust تأتي بعد التعبير الذي تنتظره، وليس قبله. أي أنها كلمة مفتاحية لاحقة (postfix). قد يختلف هذا عما اعتدت عليه إذا كنت قد استخدمت async في لغات أخرى، ولكن في Rust يجعل ذلك سلاسل الدوال (chains of methods) أجمل بكثير في التعامل معها. ونتيجة لذلك، يمكننا تغيير جسم page_title لربط استدعاءات دالتي trpl::get و text معًا مع وجود await بينهما، كما هو موضح في القائمة 17-2.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
// TODO: we'll add this next!
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}بهذا، نكون قد كتبنا بنجاح أول دالة async لنا! قبل أن نضيف بعض الكود في main لاستدعائها، دعنا نتحدث قليلاً عن ما كتبناه وما يعنيه.
عندما يرى Rust كتلة (block) مميزة بالكلمة المفتاحية async فإنه يترجمها إلى نوع بيانات فريد ومجهول ينفذ الـ Future trait. وعندما يرى Rust دالة (function) مميزة بـ async فإنه يترجمها إلى دالة غير متزامنة (non-async function) يكون جسمها عبارة عن كتلة async. نوع الإرجاع لدالة async هو نوع البيانات المجهول الذي ينشئه المترجم لتلك الكتلة async.
وبالتالي، فإن كتابة async fn تعادل كتابة دالة تعيد future لنوع الإرجاع. بالنسبة للمترجم، فإن تعريف دالة مثل async fn page_title في القائمة 17-1 يعادل تقريبًا دالة غير متزامنة معرفة بهذا الشكل:
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
use std::future::Future;
use trpl::Html;
fn page_title(url: &str) -> impl Future<Output = Option<String>> {
async move {
let text = trpl::get(url).await.text().await;
Html::parse(&text)
.select_first("title")
.map(|title| title.inner_html())
}
}
}دعنا نمر عبر كل جزء من النسخة المحولة:
- تستخدم بناء جملة
impl Traitالذي ناقشناه سابقًا في الفصل 10 في قسم “السمات كمعاملات”. - القيمة المعادة تنفذ الـ
Futuretrait مع نوع مرتبط (associated type) يسمىOutput. لاحظ أن نوع الـOutputهوOption<String>وهو نفس نوع الإرجاع الأصلي من نسخةasync fnلدالةpage_title. - يتم تغليف كل الكود المستدعى في جسم الدالة الأصلية في كتلة
async move. تذكر أن الكتل هي تعبيرات (expressions). هذه الكتلة بالكامل هي التعبير المعاد من الدالة. - تنتج كتلة async هذه قيمة من نوع
Option<String>كما تم وصفه للتو. وتلك القيمة تطابق نوع الـOutputفي نوع الإرجاع. هذا تمامًا مثل الكتل الأخرى التي رأيتها. - جسم الدالة الجديد هو كتلة
async moveبسبب كيفية استخدامه لـ parameter الـurl. (سنتحدث أكثر عن الفرق بينasyncوasync moveلاحقًا في الفصل).
الآن يمكننا استدعاء page_title في main.
تنفيذ دالة Async باستخدام وقت تشغيل (Executing an Async Function with a Runtime)
للبدء، سنحصل على العنوان لصفحة واحدة، كما هو موضح في القائمة 17-3. لسوء الحظ، هذا الكود لا يترجم (compile) بعد.
extern crate trpl; // required for mdbook test
use trpl::Html;
async fn main() {
let args: Vec<String> = std::env::args().collect();
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}نحن نتبع نفس النمط الذي استخدمناه للحصول على وسائط سطر الأوامر في قسم “قبول وسائط سطر الأوامر” في الفصل 12. ثم نمرر وسيط URL إلى page_title وننتظر النتيجة باستخدام await. نظرًا لأن القيمة التي ينتجها الـ future هي Option<String> فإننا نستخدم تعبير match لطباعة رسائل مختلفة بناءً على ما إذا كانت الصفحة تحتوي على <title>.
المكان الوحيد الذي يمكننا فيه استخدام الكلمة المفتاحية await هو داخل دوال أو كتل async، ولن يسمح لنا Rust بتمييز دالة main الخاصة بـ async.
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:6:1
|
6 | async fn main() {
السبب في عدم إمكانية تمييز main بـ async هو أن كود async يحتاج إلى وقت تشغيل (runtime): حزمة Rust تدير تفاصيل تنفيذ الكود غير المتزامن. يمكن لدالة main في البرنامج أن تهيئ (initialize) وقت تشغيل، لكنها ليست وقت تشغيل بحد ذاتها. (سنرى المزيد حول سبب ذلك بعد قليل). كل برنامج Rust ينفذ كود async لديه مكان واحد على الأقل يقوم فيه بإعداد وقت تشغيل ينفذ الـ futures.
معظم اللغات التي تدعم async ترفق وقت تشغيل معها، لكن Rust لا تفعل ذلك. بدلاً من ذلك، هناك العديد من أوقات التشغيل غير المتزامنة المتاحة، كل منها يقدم مقايضات مختلفة مناسبة لحالة الاستخدام التي يستهدفها. على سبيل المثال، خادم ويب عالي الإنتاجية مع العديد من نوى المعالج (CPU cores) وكمية كبيرة من ذاكرة الوصول العشوائي (RAM) لديه احتياجات مختلفة تمامًا عن متحكم دقيق (microcontroller) بنواة واحدة وكمية صغيرة من RAM ولا توجد قدرة على تخصيص الذاكرة في الكومة (heap allocation). الحزم التي توفر أوقات التشغيل تلك غالبًا ما توفر أيضًا نسخ async من الوظائف الشائعة مثل إدخال/إخراج الملفات أو الشبكة (I/O).
هنا، وطوال بقية هذا الفصل، سنستخدم دالة block_on من حزمة trpl والتي تأخذ future كـ parameter وتحظر (blocks) الخيط الحالي حتى يكتمل تشغيل هذا الـ future. خلف الكواليس، يؤدي استدعاء block_on إلى إعداد وقت تشغيل باستخدام حزمة tokio المستخدمة لتشغيل الـ future الممرر (سلوك block_on في حزمة trpl مشابه لدوال block_on في حزم أوقات التشغيل الأخرى). بمجرد اكتمال الـ future، تعيد block_on أي قيمة أنتجها الـ future.
يمكننا تمرير الـ future المعاد من page_title مباشرة إلى block_on وبمجرد اكتماله، يمكننا إجراء مطابقة (match) على الـ Option<String> الناتج كما حاولنا أن نفعل في القائمة 17-3. ومع ذلك، بالنسبة لمعظم الأمثلة في الفصل (ومعظم أكواد async في العالم الحقيقي)، سنقوم بأكثر من مجرد استدعاء دالة async واحدة، لذا بدلاً من ذلك سنمرر كتلة async وننتظر صراحةً نتيجة استدعاء page_title كما في القائمة 17-4.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
})
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}عندما نشغل هذا الكود، نحصل على السلوك الذي توقعناه في البداية:
$ cargo run -- "https://www.rust-lang.org"
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/async_await 'https://www.rust-lang.org'`
The title for https://www.rust-lang.org was
Rust Programming Language
أخيرًا - أصبح لدينا كود async يعمل! ولكن قبل أن نضيف الكود للتسابق بين موقعين، دعنا نوجه انتباهنا لفترة وجيزة إلى كيفية عمل الـ futures.
كل نقطة انتظار (await point) - أي كل مكان يستخدم فيه الكود الكلمة المفتاحية await - تمثل مكانًا يتم فيه إعادة التحكم إلى وقت التشغيل. لكي يعمل ذلك، يحتاج Rust إلى تتبع الحالة (state) المتضمنة في كتلة async بحيث يمكن لوقت التشغيل بدء عمل آخر ثم العودة عندما يكون جاهزًا لمحاولة دفع العمل الأول للأمام مرة أخرى. هذه آلة حالة (state machine) غير مرئية، كما لو كنت قد كتبت enum مثل هذا لحفظ الحالة الحالية عند كل نقطة انتظار:
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
enum PageTitleFuture<'a> {
Initial { url: &'a str },
GetAwaitPoint { url: &'a str },
TextAwaitPoint { response: trpl::Response },
}
}ومع ذلك، فإن كتابة الكود للانتقال بين كل حالة يدويًا سيكون مملاً وعرضة للخطأ، خاصة عندما تحتاج إلى إضافة المزيد من الوظائف والمزيد من الحالات إلى الكود لاحقًا. لحسن الحظ، يقوم مترجم Rust بإنشاء وإدارة هياكل بيانات آلة الحالة لأكواد async تلقائيًا. لا تزال جميع قواعد الاقتراض والملكية العادية حول هياكل البيانات تنطبق، ومن حسن الحظ أن المترجم يتعامل أيضًا مع التحقق منها ويوفر رسائل خطأ مفيدة. سنعمل على بعض من هذه الحالات لاحقًا في الفصل.
في النهاية، يجب على شيء ما تنفيذ آلة الحالة هذه، وهذا الشيء هو وقت التشغيل. (هذا هو السبب في أنك قد تصادف ذكر المنفذين (executors) عند البحث في أوقات التشغيل: المنفذ هو جزء من وقت التشغيل المسؤول عن تنفيذ كود async).
الآن يمكنك أن ترى لماذا منعنا المترجم من جعل main نفسها دالة async في القائمة 17-3. إذا كانت main دالة async، فسيحتاج شيء آخر إلى إدارة آلة الحالة لأي future تعيده main ولكن main هي نقطة البداية للبرنامج! بدلاً من ذلك، استدعينا دالة trpl::block_on في main لإعداد وقت تشغيل وتشغيل الـ future المعاد من كتلة async حتى ينتهي.
ملاحظة: توفر بعض أوقات التشغيل وحدات ماكرو (macros) بحيث يمكنك كتابة دالة
mainبصيغة async. تقوم تلك الـ macros بإعادة كتابةasync fn main() { ... }لتكونfn mainعادية، والتي تفعل نفس الشيء الذي فعلناه يدويًا في القائمة 17-4: استدعاء دالة تشغل future حتى الاكتمال بالطريقة التي تفعلهاtrpl::block_on.
الآن دعنا نضع هذه الأجزاء معًا ونرى كيف يمكننا كتابة كود متزامن (concurrent code).
التسابق بين عنواني URL بالتزامن (Racing Two URLs Against Each Other Concurrently)
في القائمة 17-5، نستدعي page_title مع عنواني URL مختلفين يتم تمريرهما من سطر الأوامر ونسابق بينهما عن طريق اختيار أي future ينتهي أولاً.
extern crate trpl; // required for mdbook test
use trpl::{Either, Html};
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let title_fut_1 = page_title(&args[1]);
let title_fut_2 = page_title(&args[2]);
let (url, maybe_title) =
match trpl::select(title_fut_1, title_fut_2).await {
Either::Left(left) => left,
Either::Right(right) => right,
};
println!("{url} returned first");
match maybe_title {
Some(title) => println!("Its page title was: '{title}'"),
None => println!("It had no title."),
}
})
}
async fn page_title(url: &str) -> (&str, Option<String>) {
let response_text = trpl::get(url).await.text().await;
let title = Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html());
(url, title)
}نبدأ باستدعاء page_title لكل من عناوين URL التي قدمها المستخدم. نحفظ الـ futures الناتجة كـ title_fut_1 و title_fut_2. تذكر أن هذه لا تفعل أي شيء بعد، لأن الـ futures كسولة ولم ننتظرها بعد. ثم نمرر الـ futures إلى trpl::select التي تعيد قيمة تشير إلى أي من الـ futures الممررة إليها ينتهي أولاً.
ملاحظة: داخليًا، تم بناء
trpl::selectعلى دالةselectأكثر عمومية معرفة في حزمةfutures. يمكن لدالةselectفي حزمةfuturesالقيام بالكثير من الأشياء التي لا تستطيع دالةtrpl::selectالقيام بها، ولكنها تحتوي أيضًا على بعض التعقيدات الإضافية التي يمكننا تخطيها في الوقت الحالي.
يمكن لأي من الـ futures أن “يفوز” بشكل مشروع، لذا ليس من المنطقي إعادة Result. بدلاً من ذلك، تعيد trpl::select نوعًا لم نره من قبل، وهو trpl::Either. نوع Either يشبه إلى حد ما الـ Result في أن له حالتين. ولكن على عكس Result لا يوجد مفهوم للنجاح أو الفشل مدمج في Either. بدلاً من ذلك، يستخدم Left و Right للإشارة إلى “واحد أو الآخر”:
#![allow(unused)]
fn main() {
enum Either<A, B> {
Left(A),
Right(B),
}
}تعيد دالة select القيمة Left مع مخرجات ذلك الـ future إذا فاز الوسيط الأول، و Right مع مخرجات الـ future الثاني إذا فاز ذلك الـ future. هذا يطابق الترتيب الذي تظهر به الوسائط عند استدعاء الدالة: الوسيط الأول يقع على يسار الوسيط الثاني.
نقوم أيضًا بتحديث page_title لتعيد نفس عنوان URL الممرر إليها. بهذه الطريقة، إذا كانت الصفحة التي تعود أولاً لا تحتوي على <title> يمكننا حله، فلا يزال بإمكاننا طباعة رسالة ذات معنى. مع توفر هذه المعلومات، نختتم بتحديث مخرجات println! للإشارة إلى عنوان URL الذي انتهى أولاً وما هو الـ <title> - إن وجد - لصفحة الويب عند عنوان URL هذا.
لقد قمت ببناء أداة كشط ويب صغيرة تعمل الآن! اختر عنواني URL وقم بتشغيل أداة سطر الأوامر. قد تكتشف أن بعض المواقع أسرع باستمرار من غيرها، بينما في حالات أخرى يختلف الموقع الأسرع من تشغيل لآخر. والأهم من ذلك، أنك تعلمت أساسيات التعامل مع الـ futures، لذا يمكننا الآن التعمق أكثر في ما يمكننا فعله باستخدام async.
تطبيق التزامن مع Async
تطبيق التزامن باستخدام Async (Applying Concurrency with Async)
في هذا القسم، سنقوم بتطبيق async على بعض تحديات التزامن (concurrency) نفسها التي واجهناها مع الخيوط (threads) في الفصل 16. نظرًا لأننا تحدثنا بالفعل عن الكثير من الأفكار الرئيسية هناك، سنركز في هذا القسم على الاختلافات بين الـ threads والعقود الآجلة (futures).
في كثير من الحالات، تكون واجهات برمجة التطبيقات (APIs) للعمل مع التزامن باستخدام async مشابهة جدًا لتلك المستخدمة مع الـ threads. وفي حالات أخرى، ينتهي بها الأمر لتكون مختلفة تمامًا. وحتى عندما تبدو الـ APIs متشابهة بين الـ threads و async، فغالبًا ما يكون لها سلوك مختلف - ودائمًا ما يكون لها خصائص أداء مختلفة.
إنشاء مهمة جديدة باستخدام spawn_task (Creating a New Task with spawn_task)
كانت العملية الأولى التي تناولناها في قسم “إنشاء خيط جديد باستخدام spawn” في الفصل 16 هي العد التصاعدي في خيطين منفصلين. لنفعل الشيء نفسه باستخدام async. توفر حزمة trpl دالة spawn_task التي تبدو مشابهة جدًا لـ API thread::spawn ودالة sleep التي تعد نسخة async من API thread::sleep. يمكننا استخدامهما معًا لتنفيذ مثال العد، كما هو موضح في القائمة 17-6.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
}كنقطة بداية، نقوم بإعداد دالة main الخاصة بنا باستخدام trpl::block_on بحيث يمكن أن تكون دالتنا ذات المستوى الأعلى async.
ملاحظة: من هذه النقطة فصاعدًا في الفصل، سيتضمن كل مثال نفس كود التغليف هذا مع
trpl::block_onفيmainلذا سنقوم غالبًا بتخطيه تمامًا كما نفعل معmain. تذكر تضمينه في كودك!
ثم نكتب حلقتين (loops) داخل تلك الكتلة (block)، تحتوي كل منهما على استدعاء trpl::sleep الذي ينتظر لمدة نصف ثانية (500 مللي ثانية) قبل إرسال الرسالة التالية. نضع حلقة واحدة في جسم trpl::spawn_task والأخرى في حلقة for ذات مستوى أعلى. نضيف أيضًا await بعد استدعاءات sleep.
يتصرف هذا الكود بشكل مشابه للتنفيذ القائم على الـ threads - بما في ذلك حقيقة أنك قد ترى الرسائل تظهر بترتيب مختلف في جهازك الطرفي (terminal) عند تشغيله:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
تتوقف هذه النسخة بمجرد انتهاء حلقة for في جسم كتلة async الرئيسية، لأن المهمة (task) التي تم إنشاؤها بواسطة spawn_task يتم إغلاقها عند انتهاء دالة main. إذا كنت تريد تشغيلها حتى اكتمال المهمة، فستحتاج إلى استخدام مقبض انضمام (join handle) لانتظار اكتمال المهمة الأولى. مع الـ threads، استخدمنا دالة join لـ “حظر” (block) الخيط حتى ينتهي من العمل. في القائمة 17-7، يمكننا استخدام await لفعل الشيء نفسه، لأن مقبض المهمة (task handle) نفسه هو future. نوع مخرجاته (Output type) هو Result لذا نقوم أيضًا بفك تغليفه (unwrap) بعد انتظاره بـ await.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let handle = trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
handle.await.unwrap();
});
}هذه النسخة المحدثة تعمل حتى تنتهي كلتا الحلقتين:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
حتى الآن، يبدو أن async والـ threads يعطياننا نتائج مماثلة، فقط ببناء جملة مختلف: استخدام await بدلاً من استدعاء join على الـ join handle، وانتظار استدعاءات sleep بـ await.
الاختلاف الأكبر هو أننا لم نكن بحاجة إلى إنشاء خيط نظام تشغيل (operating system thread) آخر للقيام بذلك. في الواقع، لا نحتاج حتى إلى إنشاء مهمة (task) هنا. نظرًا لأن كتل async تترجم إلى futures مجهولة، يمكننا وضع كل حلقة في كتلة async وجعل وقت التشغيل (runtime) يشغلهما معًا حتى الاكتمال باستخدام دالة trpl::join.
في قسم “انتظار انتهاء جميع الخيوط” في الفصل 16، أظهرنا كيفية استخدام دالة join على نوع JoinHandle المعاد عند استدعاء std::thread::spawn. دالة trpl::join مشابهة، ولكن للـ futures. عندما تعطيها اثنين من الـ futures، فإنها تنتج future جديدًا واحدًا يكون مخرجه عبارة عن صف (tuple) يحتوي على مخرجات كل future مررته بمجرد اكتمالهما معًا. وبالتالي، في القائمة 17-8، نستخدم trpl::join لانتظار انتهاء كل من fut1 و fut2. نحن لا ننتظر fut1 و fut2 بـ await ولكن بدلاً من ذلك ننتظر الـ future الجديد الناتج عن trpl::join. نتجاهل المخرجات لأنها مجرد tuple يحتوي على قيمتين فارغتين (unit values).
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let fut1 = async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
let fut2 = async {
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
trpl::join(fut1, fut2).await;
});
}عندما نشغل هذا، نرى كلا الـ futures يعملان حتى الاكتمال:
hi number 1 from the first task!
hi number 1 from the second task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
الآن، سترى نفس الترتيب تمامًا في كل مرة، وهو أمر مختلف تمامًا عما رأيناه مع الـ threads ومع trpl::spawn_task في القائمة 17-7. ذلك لأن دالة trpl::join هي دالة عادلة (fair)، مما يعني أنها تتحقق من كل future بشكل متساوٍ، بالتناوب بينهما، ولا تسمح أبدًا لأحدهما بالسباق إذا كان الآخر جاهزًا. مع الـ threads، يقرر نظام التشغيل أي خيط يتحقق منه ومدة تركه يعمل. مع async Rust، يقرر الـ runtime أي مهمة يتحقق منها. (في الممارسة العملية، تصبح التفاصيل معقدة لأن الـ async runtime قد يستخدم threads نظام التشغيل داخليًا كجزء من كيفية إدارته للتزامن، لذا فإن ضمان العدالة يمكن أن يكون عملاً إضافيًا للـ runtime - ولكنه لا يزال ممكنًا!) لا يتعين على الـ runtimes ضمان العدالة لأي عملية معينة، وغالبًا ما يقدمون APIs مختلفة لتتيح لك اختيار ما إذا كنت تريد العدالة أم لا.
جرب بعض هذه الاختلافات في انتظار الـ futures وشاهد ما تفعله:
- قم بإزالة كتلة async من حول إحدى الحلقتين أو كلتيهما.
- انتظر كل كتلة async بـ
awaitفور تعريفها. - قم بتغليف الحلقة الأولى فقط في كتلة async، وانتظر الـ future الناتج بعد جسم الحلقة الثانية.
لتحدي إضافي، انظر ما إذا كان بإمكانك معرفة المخرجات في كل حالة قبل تشغيل الكود!
إرسال البيانات بين مهمتين باستخدام تمرير الرسائل (Sending Data Between Two Tasks Using Message Passing)
ستكون مشاركة البيانات بين الـ futures مألوفة أيضًا: سنستخدم تمرير الرسائل (message passing) مرة أخرى، ولكن هذه المرة مع نسخ async من الأنواع والدوال. سنسلك مسارًا مختلفًا قليلاً عما فعلناه في قسم “نقل البيانات بين الخيوط باستخدام تمرير الرسائل” في الفصل 16 لتوضيح بعض الاختلافات الرئيسية بين التزامن القائم على الـ threads والقائم على الـ futures. في القائمة 17-9، سنبدأ بكتلة async واحدة فقط - بدون إنشاء مهمة منفصلة كما أنشأنا خيطًا منفصلاً.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let val = String::from("hi");
tx.send(val).unwrap();
let received = rx.recv().await.unwrap();
println!("received '{received}'");
});
}هنا، نستخدم trpl::channel وهي نسخة async من API القناة متعددة المنتجين ووحيدة المستهلك (multiple-producer, single-consumer channel) التي استخدمناها مع الـ threads في الفصل 16. نسخة الـ async من الـ API تختلف قليلاً فقط عن النسخة القائمة على الـ threads: فهي تستخدم مستقبل (receiver) rx قابل للتغيير (mutable) بدلاً من غير قابل للتغيير، ودالة recv الخاصة بها تنتج future نحتاج لانتظاره بـ await بدلاً من إنتاج القيمة مباشرة. الآن يمكننا إرسال رسائل من المرسل (sender) إلى المستقبل. لاحظ أننا لا نحتاج لإنشاء thread منفصل أو حتى task؛ نحن نحتاج فقط لانتظار استدعاء rx.recv بـ await.
دالة Receiver::recv المتزامنة في std::mpsc::channel تحظر (blocks) حتى تستقبل رسالة. دالة trpl::Receiver::recv لا تفعل ذلك، لأنها async. بدلاً من الحظر، فإنها تعيد التحكم إلى الـ runtime حتى يتم استقبال رسالة أو يغلق جانب الإرسال من القناة. في المقابل، نحن لا ننتظر استدعاء send بـ await لأنه لا يحظر. لا يحتاج لذلك لأن القناة التي نرسل إليها غير محدودة (unbounded).
ملاحظة: لأن كل كود الـ async هذا يعمل في كتلة async في استدعاء
trpl::block_onفإن كل شيء داخله يمكنه تجنب الحظر. ومع ذلك، فإن الكود خارجه سيحظر عند انتظار عودة دالةblock_on. هذا هو الهدف الكامل من دالةtrpl::block_on: فهي تتيح لك اختيار مكان الحظر على مجموعة من أكواد async، وبالتالي مكان الانتقال بين الكود المتزامن (sync) وغير المتزامن (async).
لاحظ شيئين حول هذا المثال. أولاً، ستصل الرسالة على الفور. ثانياً، على الرغم من أننا نستخدم future هنا، لا يوجد تزامن بعد. كل شيء في القائمة يحدث بالتسلسل، تمامًا كما لو لم تكن هناك futures متضمنة.
دعنا نعالج الجزء الأول عن طريق إرسال سلسلة من الرسائل والنوم بينها، كما هو موضح في القائمة 17-10.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
}بالإضافة إلى إرسال الرسائل، نحتاج لاستقبالها. في هذه الحالة، لأننا نعرف عدد الرسائل القادمة، يمكننا فعل ذلك يدويًا عن طريق استدعاء rx.recv().await أربع مرات. في العالم الحقيقي، سنستخدم عمومًا حلقة معالجة.
في القائمة 16-10، استخدمنا حلقة for لمعالجة جميع العناصر المستلمة من قناة متزامنة. ومع ذلك، لا يملك Rust بعد طريقة لاستخدام حلقة for مع سلسلة من العناصر المنتجة بشكل غير متزامن، لذا نحتاج لاستخدام حلقة لم نرها من قبل: حلقة while let الشرطية. هذه هي نسخة الحلقة من بنية if let التي رأيناها في قسم “التحكم في التدفق الموجز باستخدام if let و let...else” في الفصل 6. ستستمر الحلقة في التنفيذ طالما استمر النمط الذي تحدده في مطابقة القيمة.
استدعاء rx.recv ينتج future ننتظره بـ await. سيقوم الـ runtime بإيقاف الـ future مؤقتًا حتى يصبح جاهزًا. بمجرد وصول رسالة، سيتحول الـ future إلى Some(message) لعدد المرات التي تصل فيها رسالة. عندما تغلق القناة، وبغض النظر عما إذا كانت أي رسائل قد وصلت، سيتحول الـ future بدلاً من ذلك إلى None للإشارة إلى عدم وجود المزيد من القيم وبالتالي يجب أن نتوقف عن الاستطلاع (polling) - أي نتوقف عن الانتظار بـ await.
حلقة while let تجمع كل هذا معًا. إذا كانت نتيجة استدعاء rx.recv().await هي Some(message) فنحن نحصل على الوصول للرسالة ويمكننا استخدامها في جسم الحلقة، تمامًا كما نفعل مع if let. إذا كانت النتيجة None تنتهي الحلقة. في كل مرة تكتمل فيها الحلقة، تصل لنقطة الـ await مرة أخرى، لذا يقوم الـ runtime بإيقافها مؤقتًا مرة أخرى حتى تصل رسالة أخرى.
الكود الآن يرسل ويستقبل جميع الرسائل بنجاح. لسوء الحظ، لا تزال هناك بضع مشاكل. أولاً، الرسائل لا تصل بفواصل زمنية مدتها نصف ثانية. إنها تصل جميعها دفعة واحدة، بعد ثانيتين (2000 مللي ثانية) من بدء البرنامج. ثانياً، هذا البرنامج لا ينتهي أبداً! بدلاً من ذلك، ينتظر للأبد رسائل جديدة. ستحتاج لإغلاقه باستخدام ctrl-C.
الكود داخل كتلة Async واحدة ينفذ خطياً (Code Within One Async Block Executes Linearly)
لنبدأ بفحص سبب وصول الرسائل دفعة واحدة بعد التأخير الكامل، بدلاً من وصولها مع تأخيرات بين كل واحدة. داخل كتلة async معينة، يكون الترتيب الذي تظهر به الكلمات المفتاحية await في الكود هو أيضاً الترتيب الذي يتم تنفيذها به عند تشغيل البرنامج.
توجد كتلة async واحدة فقط في القائمة 17-10، لذا كل شيء فيها يعمل خطياً. لا يزال لا يوجد تزامن. تحدث جميع استدعاءات tx.send متخللة بجميع استدعاءات trpl::sleep ونقاط الـ await المرتبطة بها. عندها فقط تصل حلقة while let لأي من نقاط الـ await في استدعاءات recv.
للحصول على السلوك الذي نريده، حيث يحدث تأخير النوم بين كل رسالة، نحتاج لوضع عمليات tx و rx في كتل async الخاصة بها، كما هو موضح في القائمة 17-11. عندها يمكن للـ runtime تنفيذ كل منها بشكل منفصل باستخدام trpl::join تمامًا كما في القائمة 17-8. مرة أخرى، ننتظر نتيجة استدعاء trpl::join بـ await وليس الـ futures الفردية. إذا انتظرنا الـ futures الفردية بالتسلسل، فسينتهي بنا الأمر مرة أخرى في تدفق تسلسلي - وهو بالضبط ما نحاول عدم فعله.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}مع الكود المحدث في القائمة 17-11، يتم طباعة الرسائل بفواصل زمنية مدتها 500 مللي ثانية، بدلاً من وصولها جميعاً دفعة واحدة بعد ثانيتين.
نقل الملكية إلى كتلة Async (Moving Ownership Into an Async Block)
البرنامج لا يزال لا ينتهي أبداً، بسبب الطريقة التي تتفاعل بها حلقة while let مع trpl::join:
- الـ future المعاد من
trpl::joinيكتمل فقط بمجرد اكتمال كلا الـ futures الممررة إليه. - الـ future المسمى
tx_futيكتمل بمجرد انتهائه من النوم بعد إرسال آخر رسالة فيvals. - الـ future المسمى
rx_futلن يكتمل حتى تنتهي حلقةwhile let. - حلقة
while letلن تنتهي حتى ينتج انتظارrx.recvالقيمةNone. - انتظار
rx.recvسيعيدNoneفقط بمجرد إغلاق الطرف الآخر من القناة. - ستغلق القناة فقط إذا استدعينا
rx.closeأو عندما يتم إسقاط (drop) جانب المرسلtx. - نحن لا نستدعي
rx.closeفي أي مكان، ولن يتم إسقاطtxحتى تنتهي كتلة async الخارجية الممررة لـtrpl::block_on. - لا يمكن للكتلة أن تنتهي لأنها محظورة بانتظار اكتمال
trpl::joinمما يعيدنا لأعلى هذه القائمة.
في الوقت الحالي، كتلة async حيث نرسل الرسائل تقوم فقط بـ اقتراض tx لأن إرسال رسالة لا يتطلب ملكية (ownership)، ولكن إذا استطعنا نقل (move) tx إلى كتلة async تلك، فسيتم إسقاطها بمجرد انتهاء تلك الكتلة. في قسم “التقاط المراجع أو نقل الملكية” في الفصل 13، تعلمت كيفية استخدام الكلمة المفتاحية move مع الـ closures، وكما نوقش في قسم “استخدام move closures مع الـ Threads” في الفصل 16، غالباً ما نحتاج لنقل البيانات إلى الـ closures عند العمل مع الـ threads. تنطبق نفس الديناميكيات الأساسية على كتل async، لذا تعمل الكلمة المفتاحية move مع كتل async تماماً كما تعمل مع الـ closures.
في القائمة 17-12، نقوم بتغيير الكتلة المستخدمة لإرسال الرسائل من async إلى async move.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async move {
// --snip--
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}عندما نشغل هذه النسخة من الكود، فإنها تغلق برشاقة بعد إرسال واستقبال آخر رسالة. بعد ذلك، لنرى ما الذي سيحتاج للتغيير لإرسال البيانات من أكثر من future واحد.
ربط عدد من الـ Futures باستخدام ماكرو join! (Joining a Number of Futures with the join! Macro)
قناة الـ async هذه هي أيضاً قناة متعددة المنتجين، لذا يمكننا استدعاء clone على tx إذا أردنا إرسال رسائل من عدة futures، كما هو موضح في القائمة 17-13.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(1500)).await;
}
};
trpl::join!(tx1_fut, tx_fut, rx_fut);
});
}أولاً، نقوم باستنساخ (clone) لـ tx لننشئ tx1 خارج كتلة async الأولى. ننقل tx1 إلى تلك الكتلة تماماً كما فعلنا سابقاً مع tx. ثم لاحقاً، ننقل tx الأصلي إلى كتلة async جديدة، حيث نرسل المزيد من الرسائل بتأخير أبطأ قليلاً. لقد وضعنا كتلة async الجديدة هذه بعد كتلة async الخاصة باستقبال الرسائل، ولكن كان يمكن وضعها قبلها أيضاً. المفتاح هو الترتيب الذي يتم به انتظار الـ futures بـ await وليس الترتيب الذي تم إنشاؤها به.
كلتا كتلتي async لإرسال الرسائل تحتاجان لتكونا كتل async move بحيث يتم إسقاط كل من tx و tx1 عند انتهاء تلك الكتل. وإلا، فسينتهي بنا الأمر مرة أخرى في نفس الحلقة اللانهائية التي بدأنا بها.
أخيراً، ننتقل من trpl::join إلى trpl::join! للتعامل مع الـ future الإضافي: ماكرو join! ينتظر عدداً عشوائياً من الـ futures بـ await حيث نعرف عدد الـ futures في وقت الترجمة (compile time). سنناقش انتظار مجموعة من عدد غير معروف من الـ futures لاحقاً في هذا الفصل.
الآن نرى جميع الرسائل من كلا الـ futures المرسلين، ولأن الـ futures المرسلين يستخدمون تأخيرات مختلفة قليلاً بعد الإرسال، يتم استقبال الرسائل أيضاً بتلك الفواصل الزمنية المختلفة:
received 'hi'
received 'more'
received 'from'
received 'the'
received 'messages'
received 'future'
received 'for'
received 'you'
لقد استكشفنا كيفية استخدام تمرير الرسائل لإرسال البيانات بين الـ futures، وكيف يعمل الكود داخل كتلة async بشكل تسلسلي، وكيفية نقل الملكية إلى كتلة async، وكيفية ربط عدة futures. بعد ذلك، دعنا نناقش كيف ولماذا نخبر الـ runtime أنه يمكنه الانتقال لمهمة أخرى.
العمل مع أي عدد من Futures
التنازل عن التحكم لوقت التشغيل (Yielding Control to the Runtime)
تذكر من قسم “أول برنامج غير متزامن لنا” أنه عند كل نقطة انتظار (await point)، تمنح Rust وقت التشغيل (runtime) فرصة لإيقاف المهمة (task) مؤقتاً والتبديل إلى مهمة أخرى إذا لم يكن الـ future الذي يتم انتظاره جاهزاً. والعكس صحيح أيضاً: Rust تقوم فقط بإيقاف الكتل غير المتزامنة (async blocks) مؤقتاً وتسليم التحكم مرة أخرى إلى الـ runtime عند await point. كل شيء بين await points يكون متزامناً (synchronous).
هذا يعني أنه إذا قمت بالكثير من العمل في async block بدون await point، فإن ذلك الـ future سيمنع أي futures أخرى من إحراز تقدم. قد تسمع أحياناً إشارة إلى هذا على أنه future واحد يقوم بـ تجويع (starving) الـ futures الأخرى. في بعض الحالات، قد لا يكون ذلك أمراً كبيراً. ومع ذلك، إذا كنت تقوم بنوع من الإعداد المكلف أو عمل يستغرق وقتاً طويلاً، أو إذا كان لديك future سيستمر في القيام بمهمة معينة إلى أجل غير مسمى، فستحتاج إلى التفكير في متى وأين تسلم التحكم مرة أخرى إلى الـ runtime.
دعونا نحاكي عملية تستغرق وقتاً طويلاً لتوضيح مشكلة الـ starvation، ثم نستكشف كيفية حلها. تقدم القائمة 17-14 دالة slow.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
// We will call `slow` here later
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}يستخدم هذا الكود std::thread::sleep بدلاً من trpl::sleep بحيث يؤدي استدعاء slow إلى حظر (block) الخيط (thread) الحالي لعدد من المللي ثانية. يمكننا استخدام slow لتمثيل العمليات الواقعية التي تستغرق وقتاً طويلاً وتكون حظراً (blocking).
في القائمة 17-15، نستخدم slow لمحاكاة القيام بهذا النوع من العمل المرتبط بالمعالج (CPU-bound work) في زوج من الـ futures.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
slow("a", 10);
slow("a", 20);
trpl::sleep(Duration::from_millis(50)).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
slow("b", 10);
slow("b", 15);
slow("b", 350);
trpl::sleep(Duration::from_millis(50)).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}يسلم كل future التحكم مرة أخرى إلى الـ runtime فقط بعد تنفيذ مجموعة من العمليات البطيئة. إذا قمت بتشغيل هذا الكود، فسترى هذا المخرج:
'a' started.
'a' ran for 30ms
'a' ran for 10ms
'a' ran for 20ms
'b' started.
'b' ran for 75ms
'b' ran for 10ms
'b' ran for 15ms
'b' ran for 350ms
'a' finished.
كما هو الحال مع القائمة 17-5 حيث استخدمنا trpl::select للتسابق بين futures تجلب عنواني URL، لا يزال select ينتهي بمجرد انتهاء a. ومع ذلك، لا يوجد تداخل (interleaving) بين استدعاءات slow في الـ futures الاثنين. يقوم الـ future a بكل عمله حتى يتم انتظار استدعاء trpl::sleep ، ثم يقوم الـ future b بكل عمله حتى يتم انتظار استدعاء trpl::sleep الخاص به، وأخيراً يكتمل الـ future a. للسماح لكلا الـ futures بإحراز تقدم بين مهامهما البطيئة، نحتاج إلى await points حتى نتمكن من تسليم التحكم مرة أخرى إلى الـ runtime. وهذا يعني أننا بحاجة إلى شيء يمكننا انتظاره!
يمكننا بالفعل رؤية هذا النوع من التسليم يحدث في القائمة 17-15: إذا قمنا بإزالة trpl::sleep في نهاية الـ future a ، فإنه سيكتمل دون تشغيل الـ future b على الإطلاق. دعونا نحاول استخدام دالة trpl::sleep كنقطة انطلاق للسماح للعمليات بتبادل إحراز التقدم، كما هو موضح في القائمة 17-16.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let one_ms = Duration::from_millis(1);
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::sleep(one_ms).await;
slow("a", 10);
trpl::sleep(one_ms).await;
slow("a", 20);
trpl::sleep(one_ms).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::sleep(one_ms).await;
slow("b", 10);
trpl::sleep(one_ms).await;
slow("b", 15);
trpl::sleep(one_ms).await;
slow("b", 350);
trpl::sleep(one_ms).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}لقد أضفنا استدعاءات trpl::sleep مع await points بين كل استدعاء لـ slow. الآن أصبح عمل الـ futures الاثنين متداخلاً:
'a' started.
'a' ran for 30ms
'b' started.
'b' ran for 75ms
'a' ran for 10ms
'b' ran for 10ms
'a' ran for 20ms
'b' ran for 15ms
'a' finished.
لا يزال الـ future a يعمل لفترة قبل تسليم التحكم إلى b ، لأنه يستدعي slow قبل استدعاء trpl::sleep على الإطلاق، ولكن بعد ذلك يتبادل الـ futures الأدوار في كل مرة يصل فيها أحدهما إلى await point. في هذه الحالة، قمنا بذلك بعد كل استدعاء لـ slow ، ولكن يمكننا تقسيم العمل بأي طريقة نراها منطقية بالنسبة لنا.
نحن لا نريد حقاً أن ننام (sleep) هنا: نريد إحراز تقدم بأسرع ما يمكن. نحتاج فقط إلى إعادة التحكم إلى الـ runtime. يمكننا القيام بذلك مباشرة، باستخدام دالة trpl::yield_now. في القائمة 17-17، نستبدل كل استدعاءات trpl::sleep تلك بـ trpl::yield_now.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::yield_now().await;
slow("a", 10);
trpl::yield_now().await;
slow("a", 20);
trpl::yield_now().await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::yield_now().await;
slow("b", 10);
trpl::yield_now().await;
slow("b", 15);
trpl::yield_now().await;
slow("b", 350);
trpl::yield_now().await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}هذا الكود أكثر وضوحاً بشأن النية الفعلية ويمكن أن يكون أسرع بكثير من استخدام sleep ، لأن المؤقتات (timers) مثل تلك المستخدمة بواسطة sleep غالباً ما يكون لها حدود لمدى دقتها. نسخة sleep التي نستخدمها، على سبيل المثال، ستنام دائماً لمدة مللي ثانية واحدة على الأقل، حتى لو مررنا لها مدة (Duration) تبلغ نانو ثانية واحدة. مرة أخرى، أجهزة الكمبيوتر الحديثة سريعة: يمكنها القيام بالكثير في مللي ثانية واحدة!
هذا يعني أن async يمكن أن يكون مفيداً حتى للمهام المرتبطة بالحساب (compute-bound tasks)، اعتماداً على ما يفعله برنامجك أيضاً، لأنه يوفر أداة مفيدة لهيكلة العلاقات بين أجزاء مختلفة من البرنامج (ولكن بتكلفة العبء الإضافي لآلة الحالة غير المتزامنة (async state machine)). هذا شكل من أشكال تعدد المهام التعاوني (cooperative multitasking)، حيث يمتلك كل future القدرة على تحديد متى يسلم التحكم عبر await points. لذلك يتحمل كل future أيضاً مسؤولية تجنب الحظر لفترة طويلة جداً. في بعض أنظمة التشغيل المدمجة (embedded operating systems) القائمة على Rust، هذا هو النوع الوحيد من تعدد المهام!
في الكود الواقعي، لن تقوم عادةً بتبديل استدعاءات الدوال مع await points في كل سطر بالطبع. في حين أن التنازل عن التحكم بهذه الطريقة غير مكلف نسبياً، إلا أنه ليس مجانياً. في كثير من الحالات، قد يؤدي محاولة تقسيم مهمة مرتبطة بالحساب إلى جعلها أبطأ بشكل ملحوظ، لذا أحياناً يكون من الأفضل للأداء العام السماح لعملية ما بالحظر لفترة وجيزة. قم دائماً بالقياس لمعرفة ماهية اختناقات الأداء الفعلية في كودك. ومع ذلك، من المهم إبقاء الديناميكية الأساسية في الاعتبار إذا كنت ترى الكثير من العمل يحدث بشكل تسلسلي وكنت تتوقع حدوثه بشكل متزامن (concurrently)!
بناء تجريداتنا غير المتزامنة الخاصة (Building Our Own Async Abstractions)
يمكننا أيضاً تركيب الـ futures معاً لإنشاء أنماط جديدة. على سبيل المثال، يمكننا بناء دالة timeout باستخدام لبنات بناء غير متزامنة لدينا بالفعل. عندما ننتهي، ستكون النتيجة لبنة بناء أخرى يمكننا استخدامها لإنشاء المزيد من التجريدات غير المتزامنة (async abstractions).
توضح القائمة 17-18 كيف نتوقع أن يعمل timeout هذا مع future بطيء.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}دعونا ننفذ هذا! للبدء، دعونا نفكر في واجهة برمجة التطبيقات (API) لـ timeout:
- يجب أن تكون دالة غير متزامنة (async function) نفسها حتى نتمكن من انتظارها.
- يجب أن يكون معاملها (parameter) الأول هو future للتشغيل. يمكننا جعله عاماً (generic) للسماح له بالعمل مع أي future.
- سيكون parameter الثاني هو أقصى وقت للانتظار. إذا استخدمنا
Duration، فسيجعل ذلك من السهل تمريره إلىtrpl::sleep. - يجب أن تعيد
Result. إذا اكتمل الـ future بنجاح، فسيكون الـResultهوOkمع القيمة التي أنتجها الـ future. إذا انقضت مهلة الانتظار أولاً، فسيكون الـResultهوErrمع المدة التي انتظرها الـ timeout.
توضح القائمة 17-19 هذا التصريح.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
// Here is where our implementation will go!
}هذا يلبي أهدافنا بالنسبة للأنواع. الآن دعونا نفكر في السلوك الذي نحتاجه: نريد تسابق الـ future الممرر مقابل المدة. يمكننا استخدام trpl::sleep لإنشاء future مؤقت (timer future) من المدة، واستخدام trpl::select لتشغيل ذلك الـ timer مع الـ future الذي يمرره المستدعي.
في القائمة 17-20، ننفذ timeout عن طريق المطابقة (matching) على نتيجة انتظار trpl::select.
extern crate trpl; // required for mdbook test
use std::time::Duration;
use trpl::Either;
// --snip--
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
match trpl::select(future_to_try, trpl::sleep(max_time)).await {
Either::Left(output) => Ok(output),
Either::Right(_) => Err(max_time),
}
}تنفيذ trpl::select ليس عادلاً: فهو يقوم دائماً بـ polling للمعاملات بالترتيب الذي تم تمريرها به (تنفيذات select الأخرى ستختار عشوائياً أي معامل ستقوم بـ polling له أولاً). وبالتالي، نمرر future_to_try إلى select أولاً حتى يحصل على فرصة للاكتمال حتى لو كان max_time مدة قصيرة جداً. إذا انتهى future_to_try أولاً، فسيعيد select القيمة Left مع مخرجات future_to_try. إذا انتهى الـ timer أولاً، فسيعيد select القيمة Right مع مخرجات الـ timer وهي ().
إذا نجح future_to_try وحصلنا على Left(output) ، فإننا نعيد Ok(output). إذا انقضى مؤقت النوم بدلاً من ذلك وحصلنا على Right(()) ، فإننا نتجاهل الـ () باستخدام _ ونعيد Err(max_time) بدلاً من ذلك.
بذلك، لدينا timeout يعمل مبني من مساعدين غير متزامنين آخرين. إذا قمنا بتشغيل الكود الخاص بنا، فسيطبع وضع الفشل بعد المهلة:
Failed after 2 seconds
لأن الـ futures تتركب مع futures أخرى، يمكنك بناء أدوات قوية حقاً باستخدام لبنات بناء غير متزامنة أصغر. على سبيل المثال، يمكنك استخدام نفس هذا النهج لدمج المهلات (timeouts) مع عمليات إعادة المحاولة (retries)، واستخدامها بدورها مع عمليات مثل استدعاءات الشبكة (مثل تلك الموجودة في القائمة 17-5).
في الممارسة العملية، ستعمل عادةً مباشرة مع async و await ، وبشكل ثانوي مع دوال مثل select وماكروهات مثل ماكرو join! للتحكم في كيفية تنفيذ الـ futures الخارجية.
لقد رأينا الآن عدداً من الطرق للعمل مع عدة futures في نفس الوقت. بعد ذلك، سنلقي نظرة على كيفية العمل مع عدة futures في تسلسل عبر الزمن باستخدام التدفقات (streams).
الجداول: Futures في تسلسل (Streams)
التدفقات: المستقبلات في تسلسل (Streams: Futures in Sequence)
تذكر كيف استخدمنا المستلم (receiver) لقناتنا غير المتزامنة (async channel) في وقت سابق من هذا الفصل في قسم “تمرير الرسائل”. تنتج دالة recv غير المتزامنة تسلسلاً (sequence) من العناصر بمرور الوقت. هذا مثال على نمط (pattern) أكثر عمومية يعرف باسم التدفق (stream). يتم تمثيل العديد من المفاهيم بشكل طبيعي كـ تدفقات (streams): العناصر التي تصبح متاحة في طابور (queue)، أو قطع (chunks) البيانات التي يتم سحبها تدريجياً من نظام الملفات (filesystem) عندما تكون مجموعة البيانات الكاملة كبيرة جداً بالنسبة لـ ذاكرة (memory) الكمبيوتر، أو البيانات التي تصل عبر الشبكة (network) بمرور الوقت. ولأن الـ streams هي مستقبلات (futures)، يمكننا استخدامها مع أي نوع آخر من الـ future ودمجها بطرق مثيرة للاهتمام. على سبيل المثال، يمكننا تجميع (batch up) الأحداث (events) لتجنب إطلاق الكثير من استدعاءات الشبكة (network calls)، أو تعيين مهلات زمنية (timeouts) على تسلسلات من العمليات (operations) طويلة الأمد، أو تقييد (throttle) أحداث واجهة المستخدم (user interface) لتجنب القيام بعمل غير ضروري.
لقد رأينا sequence من العناصر في الفصل الثالث عشر، عندما نظرنا إلى سمة (trait) المكرر (iterator) في قسم “سمة Iterator ودالة next”، ولكن هناك فرقان بين الـ iterators ومستلم الـ async channel. الفرق الأول هو الوقت: الـ iterators متزامنة (synchronous)، بينما مستلم الـ channel غير متزامن (asynchronous). الفرق الثاني هو واجهة برمجة التطبيقات (API). عند العمل مباشرة مع Iterator ، فإننا نستدعي دالة next الـ synchronous الخاصة به. أما مع stream الـ trpl::Receiver بشكل خاص، فقد استدعينا دالة recv الـ asynchronous بدلاً من ذلك. بخلاف ذلك، تبدو هذه الـ APIs متشابهة جداً، وهذا التشابه ليس صدفة. الـ stream يشبه شكلاً asynchronous من التكرار (iteration). وبينما ينتظر trpl::Receiver تحديداً لاستلام الرسائل، فإن الـ API العام للـ stream أوسع بكثير: فهو يوفر العنصر التالي بالطريقة التي يفعلها Iterator ، ولكن بشكل asynchronous.
يعني التشابه بين الـ iterators والـ streams في Rust أنه يمكننا بالفعل إنشاء stream من أي iterator. كما هو الحال مع iterator، يمكننا العمل مع stream من خلال استدعاء دالة next الخاصة به ثم انتظار (awaiting) المخرجات، كما في القائمة 17-21، والتي لن يتم تجميعها (compile) بعد.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}نبدأ بـ مصفوفة (array) من الأرقام، والتي نحولها إلى مكرر (iterator) ثم نستدعي map عليه لمضاعفة جميع القيم. ثم نحول الـ iterator إلى stream باستخدام دالة trpl::stream_from_iter. بعد ذلك، نقوم بعمل حلقة (loop) على العناصر في الـ stream أثناء وصولها باستخدام حلقة while let.
للأسف، عندما نحاول تشغيل الكود، فإنه لا يتم تجميعه بل يبلغ بدلاً من ذلك عن عدم وجود دالة next متاحة:
error[E0599]: no method named `next` found for struct `tokio_stream::iter::Iter` in the current scope
--> src/main.rs:10:40
|
10 | while let Some(value) = stream.next().await {
| ^^^^
|
= help: items from traits can only be used if the trait is in scope
help: the following traits which provide `next` are implemented but not in scope; perhaps you want to import one of them
|
1 + use crate::trpl::StreamExt;
|
1 + use futures_util::stream::stream::StreamExt;
|
1 + use std::iter::Iterator;
|
1 + use std::str::pattern::Searcher;
|
help: there is a method `try_next` with a similar name
|
10 | while let Some(value) = stream.try_next().await {
| ~~~~~~~~
كما يوضح هذا المخرج، فإن سبب خطأ المترجم (compiler) هو أننا بحاجة إلى الـ trait الصحيح في النطاق (scope) لنتمكن من استخدام دالة next. بالنظر إلى نقاشنا حتى الآن، قد تتوقع بشكل معقول أن يكون هذا الـ trait هو Stream ، ولكنه في الواقع StreamExt. وهو اختصار لـ امتداد (extension)، و Ext هو نمط شائع في مجتمع Rust لتوسيع trait بآخر.
تحدد سمة Stream واجهة (interface) منخفضة المستوى تجمع بشكل فعال بين سمات Iterator و Future. توفر StreamExt مجموعة من الـ APIs عالية المستوى فوق Stream ، بما في ذلك دالة next بالإضافة إلى دوال مساعدة (utility methods) أخرى مشابهة لتلك التي توفرها سمة Iterator. لم تصبح Stream و StreamExt بعد جزءاً من المكتبة القياسية (standard library) لـ Rust، ولكن معظم حزم النظام البيئي (ecosystem crates) تستخدم تعريفات مماثلة.
إصلاح خطأ الـ compiler هو إضافة عبارة use لـ trpl::StreamExt ، كما في القائمة 17-22.
extern crate trpl; // required for mdbook test
use trpl::StreamExt;
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// --snip--
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}مع وضع كل تلك القطع معاً، يعمل هذا الكود بالطريقة التي نريدها! علاوة على ذلك، الآن بعد أن أصبح لدينا StreamExt في الـ scope، يمكننا استخدام جميع الـ utility methods الخاصة به، تماماً كما هو الحال مع الـ iterators.
نظرة فاحصة على سمات Async
نظرة فاحصة على سمات البرمجة غير المتزامنة (Traits for Async)
خلال هذا الفصل، استخدمنا سمات (traits) مثل Future و Stream و StreamExt بطرق متنوعة. ومع ذلك، فقد تجنبنا حتى الآن الخوض في تفاصيل كيفية عملها أو كيفية ترابطها معاً، وهو أمر جيد في معظم الأوقات لعملك اليومي بلغة Rust. لكن في بعض الأحيان، ستواجه مواقف تحتاج فيها إلى فهم المزيد من تفاصيل هذه الـ traits، جنباً إلى جنب مع نوع Pin وسمة Unpin. في هذا القسم، سنتعمق بما يكفي للمساعدة في تلك السيناريوهات، مع ترك التعمق الحقيقي للتوثيقات الأخرى.
سمة Future
لنبدأ بإلقاء نظرة فاحصة على كيفية عمل سمة Future. إليك كيف تعرفها لغة Rust:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}يتضمن تعريف الـ trait هذا مجموعة من الأنواع الجديدة وأيضاً بعض الصيغ (syntax) التي لم نرها من قبل، لذا دعونا نستعرض التعريف جزءاً بجزء.
أولاً، يحدد النوع المرتبط (associated type) لـ Future وهو Output ما ستؤول إليه الـ future عند اكتمالها. هذا مشابه للنوع المرتبط Item في سمة Iterator.
ثانياً، تمتلك Future طريقة (method) تسمى poll ، والتي تأخذ مرجع (reference) خاصاً من نوع Pin لمعامل self الخاص بها، ومرجعاً قابلاً للتغيير (mutable reference) لنوع Context ، وتعيد Poll<Self::Output>. سنتحدث أكثر عن Pin و Context بعد قليل. في الوقت الحالي، دعونا نركز على ما تعيده الـ method، وهو نوع Poll:
#![allow(unused)]
fn main() {
pub enum Poll<T> {
Ready(T),
Pending,
}
}نوع Poll هذا مشابه لـ Option. لديه متغير (variant) واحد يحتوي على قيمة، وهو Ready(T) ، وآخر لا يحتوي على قيمة، وهو Pending. ومع ذلك، فإن Poll يعني شيئاً مختلفاً تماماً عن Option! يشير الـ variant المسمى Pending إلى أن الـ future لا تزال لديها أعمال للقيام بها، لذا سيحتاج المستدعي (caller) إلى التحقق مرة أخرى لاحقاً. بينما يشير الـ variant المسمى Ready إلى أن الـ Future قد أنهت عملها وأن القيمة T أصبحت متاحة.
ملاحظة: من النادر أن تحتاج إلى استدعاء
pollمباشرة، ولكن إذا اضطررت لذلك، فضع في اعتبارك أنه مع معظم الـ futures، لا ينبغي للمستدعي استدعاءpollمرة أخرى بعد أن تعيد الـ future القيمةReady. العديد من الـ futures ستصاب بالذعر (panic) إذا تم استدعاءpollعليها مرة أخرى بعد أن تصبح جاهزة. الـ futures التي يكون من الآمن استدعاءpollعليها مرة أخرى ستذكر ذلك صراحة في توثيقها. هذا مشابه لكيفية سلوكIterator::next.
عندما ترى كوداً يستخدم await ، تقوم Rust بتجميعه (compile) خلف الكواليس إلى كود يستدعي poll. إذا نظرت إلى القائمة 17-4، حيث قمنا بطباعة عنوان الصفحة لعنوان URL واحد بمجرد اكتماله، فإن Rust تقوم بتجميعه إلى شيء يشبه (وإن لم يكن مطابقاً تماماً) هذا:
match page_title(url).poll() {
Ready(page_title) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
},
Pending => {
// ولكن ماذا نضع هنا؟
}
}ماذا يجب أن نفعل عندما لا تزال الـ future في حالة Pending؟ نحتاج إلى طريقة ما للمحاولة مراراً وتكراراً حتى تصبح الـ future جاهزة أخيراً. بعبارة أخرى، نحتاج إلى حلقة تكرار (loop):
let mut page_title_fut = page_title(url);
loop {
match page_title_fut.poll() {
Ready(value) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
},
Pending => {
// استمرار
}
}
}ومع ذلك، إذا قامت Rust بتجميعه إلى ذلك الكود بالضبط، فإن كل await ستكون حاجزة (blocking) - وهو عكس ما كنا نسعى إليه تماماً! بدلاً من ذلك، تضمن Rust أن الـ loop يمكنها تسليم التحكم إلى شيء يمكنه إيقاف العمل مؤقتاً على هذه الـ future للعمل على futures أخرى ثم التحقق من هذه الـ future مرة أخرى لاحقاً. كما رأينا، هذا الشيء هو وقت تشغيل غير متزامن (async runtime)، وعمل الجدولة (scheduling) والتنسيق هذا هو أحد وظائفه الرئيسية.
في قسم “إرسال البيانات بين مهمتين باستخدام تمرير الرسائل”، وصفنا الانتظار على rx.recv. استدعاء recv يعيد future، وانتظار الـ future يستدعي poll عليها. لاحظنا أن الـ runtime سيوقف الـ future مؤقتاً حتى تصبح جاهزة إما بـ Some(message) أو None عند إغلاق القناة (channel). مع فهمنا الأعمق لسمة Future ، وتحديداً Future::poll ، يمكننا رؤية كيفية عمل ذلك. يعرف الـ runtime أن الـ future ليست جاهزة عندما تعيد Poll::Pending. وعلى العكس من ذلك، يعرف الـ runtime أن الـ future جاهزة ويقوم بتقديمها عندما تعيد poll القيمة Poll::Ready(Some(message)) أو Poll::Ready(None).
التفاصيل الدقيقة لكيفية قيام الـ runtime بذلك تقع خارج نطاق هذا الكتاب، ولكن المفتاح هو رؤية الآليات الأساسية للـ futures: يقوم الـ runtime باستدعاء poll لكل future هو مسؤول عنها، ويعيد الـ future إلى وضع السكون عندما لا تكون جاهزة بعد.
نوع Pin وسمة Unpin
بالعودة إلى القائمة 17-13، استخدمنا ماكرو (macro) trpl::join! لانتظار ثلاث futures. ومع ذلك، فمن الشائع أن يكون لديك مجموعة (collection) مثل متجه (vector) يحتوي على عدد من الـ futures التي لن تُعرف حتى وقت التشغيل (runtime). لنقم بتغيير القائمة 17-13 إلى الكود الموجود في القائمة 17-23 الذي يضع الـ futures الثلاثة في vector ويستدعي دالة trpl::join_all بدلاً من ذلك، وهو ما لن يتم تجميعه بعد.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
// --snip--
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let futures: Vec<Box<dyn Future<Output = ()>>> =
vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
trpl::join_all(futures).await;
});
}لقد وضعنا كل future داخل Box لتحويلها إلى كائنات سمات (trait objects)، تماماً كما فعلنا في قسم “إرجاع الأخطاء من run” في الفصل 12. (سنغطي trait objects بالتفصيل في الفصل 18). يتيح لنا استخدام trait objects معاملة كل من الـ futures المجهولة الناتجة عن هذه الأنواع كأنها من نفس النوع، لأن جميعها تطبق سمة Future.
قد يكون هذا مفاجئاً. ففي النهاية، لا تعيد أي من الكتل غير المتزامنة (async blocks) أي شيء، لذا ينتج عن كل منها Future<Output = ()>. تذكر أن Future هي trait، وأن المترجم (compiler) ينشئ تعداداً (enum) فريداً لكل async block، حتى عندما يكون لها أنواع مخرجات متطابقة. تماماً كما لا يمكنك وضع هيكلين (structs) مختلفين مكتوبين يدوياً في Vec ، لا يمكنك خلط الـ enums التي أنشأها الـ compiler.
ثم نقوم بتمرير الـ collection الخاصة بالـ futures إلى دالة trpl::join_all وننتظر النتيجة. ومع ذلك، لا يتم تجميع هذا؛ إليك الجزء ذو الصلة من رسائل الخطأ.
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
--> src/main.rs:48:33
|
48 | trpl::join_all(futures).await;
| ^^^^^ the trait `Unpin` is not implemented for `dyn Future<Output = ()>`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<dyn Future<Output = ()>>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
تخبرنا الملاحظة في رسالة الخطأ هذه أنه يجب علينا استخدام macro pin! لـ “تثبيت” (pin) القيم، مما يعني وضعها داخل نوع Pin الذي يضمن عدم نقل القيم في الذاكرة (memory). تقول رسالة الخطأ أن التثبيت (pinning) مطلوب لأن dyn Future<Output = ()> تحتاج إلى تطبيق سمة Unpin وهي لا تفعل ذلك حالياً.
تعيد دالة trpl::join_all هيكلاً يسمى JoinAll. هذا الـ struct عام (generic) على نوع F ، وهو مقيد بتطبيق سمة Future. انتظار future مباشرة باستخدام await يثبت الـ future ضمنياً. لهذا السبب لا نحتاج إلى استخدام pin! في كل مكان نريد فيه انتظار futures.
ومع ذلك، نحن لا ننتظر future مباشرة هنا. بدلاً من ذلك، نقوم بإنشاء future جديدة، JoinAll ، عن طريق تمرير collection من الـ futures إلى دالة join_all. يتطلب توقيع (signature) دالة join_all أن تطبق جميع أنواع العناصر في الـ collection سمة Future ، ويطبق Box<T> سمة Future فقط إذا كان الـ T الذي يغلفه هو future تطبق سمة Unpin.
هذا الكثير لاستيعابه! لفهمه حقاً، دعونا نتعمق قليلاً في كيفية عمل سمة Future فعلياً، لا سيما فيما يتعلق بـ pinning. انظر مرة أخرى إلى تعريف سمة Future:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
// Required method
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}المعامل cx ونوعه Context هما المفتاح لكيفية معرفة الـ runtime فعلياً متى يجب التحقق من أي future معينة مع بقائها كسولة (lazy). مرة أخرى، تفاصيل كيفية عمل ذلك تقع خارج نطاق هذا الفصل، وعادة ما تحتاج فقط إلى التفكير في هذا عند كتابة تطبيق Future مخصص. سنركز بدلاً من ذلك على نوع self ، حيث أن هذه هي المرة الأولى التي نرى فيها method حيث يكون لـ self تعليق توضيحي للنوع (type annotation). يعمل الـ type annotation لـ self مثل الـ type annotations لمعاملات الدوال الأخرى ولكن مع اختلافين رئيسيين:
- يخبر Rust بنوع
selfالذي يجب أن يكون عليه لاستدعاء الـ method. - لا يمكن أن يكون أي نوع فحسب. فهو مقتصر على النوع الذي تم تطبيق الـ method عليه، أو مرجع أو مؤشر ذكي (smart pointer) لهذا النوع، أو
Pinيغلف مرجعاً لهذا النوع.
سنرى المزيد عن هذا الـ syntax في الفصل 18. في الوقت الحالي، يكفي أن نعرف أنه إذا أردنا استدعاء poll على future للتحقق مما إذا كانت Pending أو Ready(Output) ، فنحن بحاجة إلى مرجع قابل للتغيير مغلف بـ Pin للنوع.
Pin هو غلاف لأنواع تشبه المؤشرات (pointer-like types) مثل & و &mut و Box و Rc. (من الناحية الفنية، يعمل Pin مع الأنواع التي تطبق سمات Deref أو DerefMut ، ولكن هذا يعادل فعلياً العمل فقط مع الـ references والـ smart pointers). الـ Pin ليس مؤشراً بحد ذاته وليس له أي سلوك خاص به مثل Rc و Arc مع عد المراجع (reference counting)؛ إنه مجرد أداة يستخدمها الـ
لماذا يحتاج `self` إلى أن يكون في نوع `Pin` لاستدعاء `poll`؟
تذكر مما سبق في هذا الفصل أن سلسلة من نقاط الانتظار (await points) في الـ future يتم تجميعها في آلة حالة (state machine)، ويتأكد المترجم من أن هذه الـ state machine تتبع جميع قواعد Rust المعتادة حول السلامة، بما في ذلك الاستعارة (borrowing) والملكية (ownership). لإنجاح ذلك، تنظر Rust إلى البيانات المطلوبة بين await point واحدة والـ await point التالية أو نهاية الكتلة غير المتزامنة (async block). ثم تنشئ متغيراً (variant) مقابلاً في الـ state machine المجمعة. يحصل كل variant على الوصول الذي يحتاجه للبيانات التي سيتم استخدامها في ذلك القسم من الكود المصدري، سواء عن طريق أخذ ملكية تلك البيانات أو الحصول على مرجع قابل للتغيير (mutable reference) أو غير قابل للتغيير (immutable reference) لها.
حتى الآن، كل شيء يسير على ما يرام: إذا أخطأنا في أي شيء يتعلق بالملكية أو المراجع في async block معينة، فسيخبرنا مدقق الاستعارة (borrow checker). ولكن عندما نريد نقل الـ future المقابلة لتلك الكتلة - مثل نقلها إلى `Vec` لتمريرها إلى `join_all` - تصبح الأمور أكثر تعقيداً.
عندما ننقل future - سواء عن طريق دفعها إلى هيكل بيانات لاستخدامها كمكرر (iterator) مع `join_all` أو عن طريق إعادتها من دالة - فإن ذلك يعني فعلياً نقل الـ state machine التي تنشئها Rust لنا. وعلى عكس معظم الأنواع الأخرى في Rust، يمكن للـ futures التي تنشئها Rust لـ async blocks أن تنتهي بمراجع لنفسها في حقول أي variant معين، كما هو موضح في الرسم التوضيحي المبسط في الشكل 17-4.
<figure>
<img alt="A single-column, three-row table representing a future, fut1, which has data values 0 and 1 in the first two rows and an arrow pointing from the third row back to the second row, representing an internal reference within the future." src="img/trpl17-04.svg" class="center" />
<figcaption>الشكل 17-4: نوع بيانات مرجعي ذاتي (self-referential data type)</figcaption>
</figure>
بشكل افتراضي، يكون أي كائن له مرجع لنفسه غير آمن للنقل، لأن المراجع تشير دائماً إلى عنوان الذاكرة (memory address) الفعلي لأي شيء تشير إليه (انظر الشكل 17-5). إذا قمت بنقل هيكل البيانات نفسه، فستبقى تلك المراجع الداخلية تشير إلى الموقع القديم. ومع ذلك، أصبح موقع الذاكرة هذا الآن غير صالح. لسبب واحد، لن يتم تحديث قيمته عندما تجري تغييرات على هيكل البيانات. ولسبب آخر - وهو الأكثر أهمية - أصبح الكمبيوتر الآن حراً في إعادة استخدام تلك الذاكرة لأغراض أخرى! قد ينتهي بك الأمر بقراءة بيانات غير ذات صلة تماماً لاحقاً.
<figure>
<img alt="Two tables, depicting two futures, fut1 and fut2, each of which has one column and three rows, representing the result of having moved a future out of fut1 into fut2. The first, fut1, is grayed out, with a question mark in each index, representing unknown memory. The second, fut2, has 0 and 1 in the first and second rows and an arrow pointing from its third row back to the second row of fut1, representing a pointer that is referencing the old location in memory of the future before it was moved." src="img/trpl17-05.svg" class="center" />
<figcaption>الشكل 17-5: النتيجة غير الآمنة لنقل نوع بيانات مرجعي ذاتي</figcaption>
</figure>
نظرياً، يمكن لمترجم Rust محاولة تحديث كل مرجع لكائن كلما تم نقله، ولكن هذا قد يضيف الكثير من العبء على الأداء، خاصة إذا كانت هناك شبكة كاملة من المراجع تحتاج إلى تحديث. إذا تمكنا بدلاً من ذلك من التأكد من أن هيكل البيانات المعني _لا يتحرك في الذاكرة_، فلن نضطر إلى تحديث أي مراجع. هذا هو بالضبط الغرض من borrow checker في Rust: في الكود الآمن، يمنعك من نقل أي عنصر له مرجع نشط يشير إليه.
يعتمد `Pin` على ذلك ليعطينا الضمان الدقيق الذي نحتاجه. عندما نقوم بـ "تثبيت" (pin) قيمة عن طريق تغليف مؤشر لتلك القيمة في `Pin` ، فإنها لا تعود قادرة على الحركة. وبالتالي، إذا كان لديك `Pin<Box<SomeType>>` ، فأنت في الواقع تثبت قيمة `SomeType` ، _وليس_ مؤشر `Box`. يوضح الشكل 17-6 هذه العملية.
<figure>
<img alt="Three boxes laid out side by side. The first is labeled “Pin”, the second “b1”, and the third “pinned”. Within “pinned” is a table labeled “fut”, with a single column; it represents a future with cells for each part of the data structure. Its first cell has the value “0”, its second cell has an arrow coming out of it and pointing to the fourth and final cell, which has the value “1” in it, and the third cell has dashed lines and an ellipsis to indicate there may be other parts to the data structure. All together, the “fut” table represents a future which is self-referential. An arrow leaves the box labeled “Pin”, goes through the box labeled “b1” and terminates inside the “pinned” box at the “fut” table." src="img/trpl17-06.svg" class="center" />
<figcaption>الشكل 17-6: تثبيت `Box` يشير إلى نوع future مرجعي ذاتي</figcaption>
</figure>
في الواقع، لا يزال بإمكان مؤشر `Box` التحرك بحرية. تذكر: نحن نهتم بالتأكد من أن البيانات التي يتم الرجوع إليها في النهاية تبقى في مكانها. إذا تحرك المؤشر، _ولكن البيانات التي يشير إليها_ بقيت في نفس المكان، كما في الشكل 17-7، فلا توجد مشكلة محتملة. (كتمرين مستقل، انظر إلى توثيقات الأنواع بالإضافة إلى وحدة `std::pin` وحاول معرفة كيف يمكنك القيام بذلك باستخدام `Pin` يغلف `Box`). المفتاح هو أن النوع المرجعي الذاتي نفسه لا يمكنه التحرك، لأنه لا يزال مثبتاً.
<figure>
<img alt="Four boxes laid out in three rough columns, identical to the previous diagram with a change to the second column. Now there are two boxes in the second column, labeled “b1” and “b2”, “b1” is grayed out, and the arrow from “Pin” goes through “b2” instead of “b1”, indicating that the pointer has moved from “b1” to “b2”, but the data in “pinned” has not moved." src="img/trpl17-07.svg" class="center" />
<figcaption>الشكل 17-7: نقل `Box` يشير إلى نوع future مرجعي ذاتي</figcaption>
</figure>
ومع ذلك، فإن معظم الأنواع آمنة تماماً للنقل، حتى لو كانت خلف مؤشر `Pin`. نحتاج فقط إلى التفكير في التثبيت عندما تحتوي العناصر على مراجع داخلية. القيم البدائية (primitive values) مثل الأرقام والقيم المنطقية (Booleans) آمنة لأنها بوضوح لا تحتوي على أي مراجع داخلية.
وكذلك معظم الأنواع التي تتعامل معها عادةً في Rust. يمكنك نقل `Vec` ، على سبيل المثال، دون قلق. بالنظر إلى ما رأيناه حتى الآن، إذا كان لديك `Pin<Vec<String>>` ، فسيتعين عليك القيام بكل شيء عبر واجهات برمجة التطبيقات (APIs) الآمنة ولكن المقيدة التي يوفرها `Pin` ، على الرغم من أن `Vec<String>` آمن دائماً للنقل إذا لم تكن هناك مراجع أخرى له. نحتاج إلى طريقة لإخبار المترجم أنه من الجيد نقل العناصر في حالات مثل هذه - وهنا يأتي دور سمة التمييز (marker trait) المسماة `Unpin`.
الـ `Unpin` هي marker trait، مشابهة لسمات `Send` و `Sync` التي رأيناها في الفصل 16، وبالتالي ليس لها وظائف خاصة بها. توجد سمات التمييز فقط لإخبار المترجم أنه من الآمن استخدام النوع الذي يطبق سمة معينة في سياق معين. تخبر `Unpin` المترجم أن نوعاً معيناً _لا_ يحتاج إلى الالتزام بأي ضمانات حول ما إذا كان يمكن نقل القيمة المعنية بأمان.
<!--
The inline `<code>` in the next block is to allow the inline `<em>` inside it,
matching what NoStarch does style-wise, and emphasizing within the text here
that it is something distinct from a normal type.
-->
تماماً كما هو الحال مع `Send` و `Sync` ، يطبق المترجم `Unpin` تلقائياً لجميع الأنواع التي يمكنه إثبات أنها آمنة. وهناك حالة خاصة، مشابهة أيضاً لـ `Send` و `Sync` ، وهي عندما _لا_ يتم تطبيق `Unpin` لنوع ما. الصيغة لهذا هي <code>impl !Unpin for <em>SomeType</em></code>، حيث <code><em>SomeType</em></code> هو اسم النوع الذي _يحتاج_ إلى الالتزام بتلك الضمانات ليكون آمناً كلما تم استخدام مؤشر لهذا النوع في `Pin`.
بمعنى آخر، هناك شيئان يجب وضعهما في الاعتبار حول العلاقة بين `Pin` و `Unpin`. أولاً، `Unpin` هي الحالة "العادية"، و `!Unpin` هي الحالة الخاصة. ثانياً، ما إذا كان النوع يطبق `Unpin` أو `!Unpin` يهم _فقط_ عندما تستخدم مؤشراً مثبتاً لهذا النوع مثل <code>Pin<&mut <em>SomeType</em>></code>.
لجعل ذلك ملموساً، فكر في `String`: لها طول وحروف Unicode التي تشكلها. يمكننا تغليف `String` في `Pin` ، كما هو موضح في الشكل 17-8. ومع ذلك، تطبق `String` تلقائياً `Unpin` ، كما تفعل معظم الأنواع الأخرى في Rust.
<figure>
<img alt="A box labeled “Pin” on the left with an arrow going from it to a box labeled “String” on the right. The “String” box contains the data 5usize, representing the length of the string, and the letters “h”, “e”, “l”, “l”, and “o” representing the characters of the string “hello” stored in this String instance. A dotted rectangle surrounds the “String” box and its label, but not the “Pin” box." src="img/trpl17-08.svg" class="center" />
<figcaption>الشكل 17-8: تثبيت `String`؛ يشير الخط المنقط إلى أن الـ `String` تطبق سمة `Unpin` وبالتالي فهي ليست مثبتة</figcaption>
</figure>
ونتيجة لذلك، يمكننا القيام بأشياء قد تكون غير قانونية إذا كانت `String` تطبق `!Unpin` بدلاً من ذلك، مثل استبدال سلسلة نصية بأخرى في نفس موقع الذاكرة تماماً كما في الشكل 17-9. هذا لا ينتهك عقد `Pin` ، لأن `String` ليس لها مراجع داخلية تجعل من غير الآمن نقلها. وهذا هو بالضبط سبب تطبيقها لـ `Unpin` بدلاً من `!Unpin`.
<figure>
<img alt="The same “hello” string data from the previous example, now labeled “s1” and grayed out. The “Pin” box from the previous example now points to a different String instance, one that is labeled “s2”, is valid, has a length of 7usize, and contains the characters of the string “goodbye”. s2 is surrounded by a dotted rectangle because it, too, implements the Unpin trait." src="img/trpl17-09.svg" class="center" />
<figcaption>الشكل 17-9: استبدال الـ `String` بـ `String` مختلفة تماماً في الذاكرة</figcaption>
</figure>
الآن نعرف ما يكفي لفهم الأخطاء المبلغ عنها لاستدعاء `join_all` من القائمة 17-23. حاولنا في الأصل نقل الـ futures الناتجة عن async blocks إلى `Vec<Box<dyn Future<Output = ()>>>` ، ولكن كما رأينا، قد تحتوي تلك الـ futures على مراجع داخلية، لذا فهي لا تطبق `Unpin` تلقائياً. بمجرد تثبيتها، يمكننا تمرير نوع `Pin` الناتج إلى الـ `Vec` ، ونحن واثقون من أن البيانات الأساسية في الـ futures _لن_ يتم نقلها. توضح القائمة 17-24 كيفية إصلاح الكود عن طريق استدعاء macro `pin!` حيث يتم تعريف كل من الـ futures الثلاثة وتعديل نوع trait object.
<Listing number="17-24" caption="تثبيت الـ futures لتمكين نقلها إلى المتجه">
```rust
# extern crate trpl; // required for mdbook test
#
use std::pin::{Pin, pin};
// --snip--
# use std::time::Duration;
#
# fn main() {
# trpl::block_on(async {
# let (tx, mut rx) = trpl::channel();
#
# let tx1 = tx.clone();
let tx1_fut = pin!(async move {
// --snip--
# let vals = vec![
# String::from("hi"),
# String::from("from"),
# String::from("the"),
# String::from("future"),
# ];
#
# for val in vals {
# tx1.send(val).unwrap();
# trpl::sleep(Duration::from_secs(1)).await;
# }
});
let rx_fut = pin!(async {
// --snip--
# while let Some(value) = rx.recv().await {
# println!("received '{value}'");
# }
});
let tx_fut = pin!(async move {
// --snip--
# let vals = vec![
# String::from("more"),
# String::from("messages"),
# String::from("for"),
# String::from("you"),
# ];
#
# for val in vals {
# tx.send(val).unwrap();
# trpl::sleep(Duration::from_secs(1)).await;
# }
});
let futures: Vec<Pin<&mut dyn Future<Output = ()>>> =
vec![tx1_fut, rx_fut, tx_fut];
#
# trpl::join_all(futures).await;
# });
# }
هذا المثال الآن يتم تجميعه وتشغيله، ويمكننا إضافة أو إزالة futures من الـ vector في وقت التشغيل وضمها جميعاً.
تعتبر Pin و Unpin مهمة في الغالب لبناء مكتبات منخفضة المستوى، أو عندما تبني runtime بنفسك، بدلاً من كود Rust اليومي. ولكن عندما ترى هذه السمات في رسائل الخطأ، سيكون لديك الآن فكرة أفضل عن كيفية إصلاح الكود الخاص بك!
ملاحظة: هذا المزيج من
PinوUnpinيجعل من الممكن تطبيق فئة كاملة من الأنواع المعقدة في Rust بأمان والتي قد تكون صعبة لولا ذلك لأنها مرجعية ذاتية. تظهر الأنواع التي تتطلبPinبشكل شائع في Rust غير المتزامن اليوم، ولكن بين الحين والآخر، قد تراها في سياقات أخرى أيضاً.تفاصيل كيفية عمل
PinوUnpin، والقواعد التي يتعين عليهما الالتزام بها، مغطاة على نطاق واسع في توثيق API لـstd::pin، لذا إذا كنت مهتماً بمعرفة المزيد، فهذا مكان رائع للبدء.إذا كنت تريد فهم كيفية عمل الأشياء تحت الغطاء بمزيد من التفصيل، فراجع الفصلين 2 و 4 من كتاب البرمجة غير المتزامنة في Rust.
سمة Stream
الآن بعد أن أصبح لديك فهم أعمق لسمات Future و Pin و Unpin ، يمكننا توجيه انتباهنا إلى سمة Stream. كما تعلمت سابقاً في هذا الفصل، فإن الـ streams تشبه المكررات غير المتزامنة (asynchronous iterators). ومع ذلك، على عكس Iterator و Future ، لا يوجد تعريف لـ Stream في المكتبة القياسية (standard library) حتى وقت كتابة هذا التقرير، ولكن يوجد تعريف شائع جداً من حزمة (crate) تسمى futures يُستخدم في جميع أنحاء النظام البيئي.
دعونا نراجع تعريفات سمات Iterator و Future قبل النظر في كيفية قيام سمة Stream بدمجهما معاً. من Iterator ، لدينا فكرة التسلسل: توفر طريقة next الخاصة بها Option<Self::Item>. ومن Future ، لدينا فكرة الجاهزية بمرور الوقت: توفر طريقة poll الخاصة بها Poll<Self::Output>. لتمثيل تسلسل من العناصر التي تصبح جاهزة بمرور الوقت، نحدد سمة Stream التي تجمع تلك الميزات معاً:
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
}ملاحظة: التعريف الفعلي الذي استخدمناه سابقاً في هذا الفصل يبدو مختلفاً قليلاً عن هذا، لأنه يدعم إصدارات Rust التي لم تكن تدعم بعد استخدام الدوال غير المتزامنة (async functions) في السمات (traits). ونتيجة لذلك، يبدو كالتالي:
fn next(&mut self) -> Next<'_, Self> where Self: Unpin;نوع
Nextهذا هو هيكل (struct) يطبقFutureويسمح لنا بتسمية عمر (lifetime) المرجع لـselfبـNext<'_, Self>، بحيث يمكن لـawaitالعمل مع هذه الطريقة (method).
سمة StreamExt هي أيضاً موطن لجميع الـ methods المثيرة للاهتمام المتاحة للاستخدام مع الـ streams. يتم تطبيق StreamExt تلقائياً لكل نوع يطبق Stream ، ولكن يتم تعريف هذه الـ traits بشكل منفصل لتمكين المجتمع من تطوير واجهات برمجة تطبيقات (APIs) مريحة دون التأثير على الـ trait الأساسية.
في إصدار StreamExt المستخدم في حزمة trpl ، لا يحدد الـ trait طريقة next فحسب، بل يوفر أيضاً تطبيقاً افتراضياً لـ next يتعامل بشكل صحيح مع تفاصيل استدعاء Stream::poll_next. هذا يعني أنه حتى عندما تحتاج إلى كتابة نوع بيانات تدفقي (streaming data type) خاص بك، فإنك فقط تضطر إلى تطبيق Stream ، ومن ثم يمكن لأي شخص يستخدم نوع البيانات الخاص بك استخدام StreamExt وطرقها معه تلقائياً.
هذا كل ما سنغطيه فيما يتعلق بالتفاصيل منخفضة المستوى حول هذه الـ traits. وللختام، دعونا نفكر في كيفية ترابط الـ futures (بما في ذلك الـ streams) والمهام (tasks) والخيوط (threads) معاً!
الفيوتشرز والمهام والخيوط (Tasks)
تجميع كل شيء معاً: العقود الآجلة والمهام والخيوط (Futures, Tasks, and Threads)
كما رأينا في الفصل 16، توفر الخيوط (Threads) نهجاً واحداً للتزامن (Concurrency). لقد رأينا نهجاً آخر في هذا الفصل: استخدام البرمجة غير المتزامنة (Async) مع العقود الآجلة (Futures) والتدفقات (Streams). إذا كنت تتساءل متى تختار طريقة على الأخرى، فالإجابة هي: يعتمد ذلك على الحالة! وفي كثير من الحالات، لا يكون الاختيار بين Threads أو Async، بل بالأحرى Threads و Async معاً.
وفرت العديد من أنظمة التشغيل نماذج Concurrency تعتمد على الخيوط لعقود من الزمن، ونتيجة لذلك تدعمها العديد من لغات البرمجة. ومع ذلك، فإن هذه النماذج لا تخلو من المقايضات. ففي العديد من أنظمة التشغيل، تستهلك Threads قدراً لا بأس به من الذاكرة لكل Thread. كما أن Threads لا تكون خياراً متاحاً إلا عندما يدعمها نظام التشغيل والأجهزة الخاصة بك. وعلى عكس أجهزة الكمبيوتر المكتبية والمحمولة السائدة، فإن بعض الأنظمة المضمنة (Embedded Systems) لا تحتوي على نظام تشغيل على الإطلاق، وبالتالي لا تحتوي أيضاً على Threads.
يوفر نموذج Async مجموعة مختلفة—ومكملة في النهاية—من المقايضات. في نموذج Async، لا تتطلب العمليات المتزامنة Threads خاصة بها. بدلاً من ذلك، يمكن تشغيلها على مهام (Tasks)، كما هو الحال عندما استخدمنا trpl::spawn_task لبدء العمل من دالة متزامنة (Synchronous Function) في قسم Streams. تشبه Task الخيط (Thread)، ولكن بدلاً من إدارتها بواسطة نظام التشغيل، يتم إدارتها بواسطة شفرة برمجية (Code) على مستوى المكتبة: وقت التشغيل (Runtime).
هناك سبب يجعل واجهات برمجة التطبيقات (APIs) لإنشاء (Spawning) الخيوط وإنشاء المهام متشابهة جداً. تعمل Threads كحدود لمجموعات من العمليات المتزامنة؛ حيث يكون Concurrency ممكناً بين Threads. وتعمل Tasks كحدود لمجموعات من العمليات غير المتزامنة؛ حيث يكون Concurrency ممكناً بين و داخل Tasks، لأن Task يمكنها التبديل بين Futures في جسمها (Body). أخيراً، تعتبر Futures هي الوحدة الأكثر دقة لـ Concurrency في Rust، وقد يمثل كل Future شجرة من Futures الأخرى. يدير Runtime—وتحديداً المنفذ (Executor) الخاص به—المهام (Tasks)، وتدير Tasks العقود الآجلة (Futures). وفي هذا الصدد، تشبه Tasks خيوطاً خفيفة الوزن يديرها Runtime مع قدرات إضافية تأتي من كونها تدار بواسطة Runtime بدلاً من نظام التشغيل.
هذا لا يعني أن Async Tasks دائماً أفضل من Threads (أو العكس). يعتبر Concurrency باستخدام Threads نموذجاً برمجياً أبسط في بعض النواحي من Concurrency باستخدام async. يمكن أن يكون ذلك نقطة قوة أو نقطة ضعف. تعتبر Threads نوعاً ما “أطلق وانسَ” (Fire and forget)؛ فليس لها مكافئ أصلي لـ Future، لذا فهي تعمل ببساطة حتى الاكتمال دون مقاطعة إلا من قبل نظام التشغيل نفسه.
واتضح أن Threads و Tasks غالباً ما يعملان معاً بشكل جيد جداً، لأن Tasks يمكن (على الأقل في بعض Runtimes) نقلها بين Threads. في الواقع، تحت الغطاء، فإن Runtime الذي كنا نستخدمه—بما في ذلك دالتي spawn_blocking و spawn_task—هو متعدد الخيوط (Multithreaded) بشكل افتراضي! تستخدم العديد من Runtimes نهجاً يسمى سرقة العمل (Work stealing) لنقل Tasks بشكل شفاف بين Threads، بناءً على كيفية استخدام Threads حالياً، لتحسين الأداء العام للنظام. يتطلب هذا النهج فعلياً وجود Threads و Tasks، وبالتالي Futures.
عند التفكير في الطريقة التي يجب استخدامها ومتى، ضع في اعتبارك هذه القواعد العامة:
- إذا كان العمل قابلاً للتوازي بشكل كبير (أي مرتبط بالمعالج CPU-bound)، مثل معالجة مجموعة من البيانات حيث يمكن معالجة كل جزء بشكل منفصل، فإن Threads هي الخيار الأفضل.
- إذا كان العمل متزامناً بشكل كبير (أي مرتبط بالإدخال والإخراج I/O-bound)، مثل التعامل مع الرسائل من مجموعة من المصادر المختلفة التي قد تأتي على فترات مختلفة أو بمعدلات مختلفة، فإن Async هو الخيار الأفضل.
وإذا كنت بحاجة إلى كل من التوازي (Parallelism) والتزامن (Concurrency)، فلا يتعين عليك الاختيار بين Threads و Async. يمكنك استخدامهما معاً بحرية، مما يسمح لكل منهما بلعب الدور الذي يبرع فيه. على سبيل المثال، تعرض القائمة 17-25 مثالاً شائعاً جداً لهذا النوع من المزيج في Code لغة Rust الواقعي.
extern crate trpl; // for mdbook test
use std::{thread, time::Duration};
fn main() {
let (tx, mut rx) = trpl::channel();
thread::spawn(move || {
for i in 1..11 {
tx.send(i).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
trpl::block_on(async {
while let Some(message) = rx.recv().await {
println!("{message}");
}
});
}نبدأ بإنشاء قناة غير متزامنة (Async Channel)، ثم إنشاء Thread يأخذ ملكية جانب المرسل من القناة باستخدام الكلمة المفتاحية (Keyword) move. داخل Thread، نرسل الأرقام من 1 إلى 10، مع النوم لمدة ثانية بين كل رقم. أخيراً، نقوم بتشغيل Future تم إنشاؤه باستخدام كتلة Async ممررة إلى trpl::block_on تماماً كما فعلنا طوال الفصل. في ذلك Future، ننتظر (Await) تلك الرسائل، تماماً كما في أمثلة تمرير الرسائل (Message-passing) الأخرى التي رأيناها.
للعودة إلى السيناريو الذي افتتحنا به الفصل، تخيل تشغيل مجموعة من مهام ترميز الفيديو (Video encoding tasks) باستخدام Thread مخصص (لأن ترميز الفيديو مرتبط بالحوسبة Compute-bound) ولكن مع إخطار واجهة المستخدم (UI) بأن تلك العمليات قد اكتملت باستخدام Async Channel. هناك أمثلة لا حصر لها لهذه الأنواع من التوليفات في حالات الاستخدام الواقعية.
ملخص
هذه ليست المرة الأخيرة التي سترى فيها Concurrency في هذا الكتاب. سيطبق المشروع في الفصل 21 هذه المفاهيم في موقف أكثر واقعية من الأمثلة البسيطة التي تمت مناقشتها هنا، وسيقارن بين حل المشكلات باستخدام Threads مقابل Tasks و Futures بشكل مباشر أكثر.
بغض النظر عن أي من هذه الأساليب تختار، تمنحك Rust الأدوات التي تحتاجها لكتابة Code آمن وسريع ومتزامن—سواء كان ذلك لخادم ويب عالي الإنتاجية أو لنظام تشغيل مضمن.
بعد ذلك، سنتحدث عن الطرق الاصطلاحية (Idiomatic ways) لنمذجة المشكلات وهيكلة الحلول مع زيادة حجم برامج Rust الخاصة بك. بالإضافة إلى ذلك، سنناقش كيف ترتبط اصطلاحات Rust بتلك التي قد تكون مألوفاً بها من البرمجة كائنية التوجه (Object-oriented programming).
خصائص البرمجة كائنية التوجه (Object-Oriented Programming Features)
البرمجة كائنية التوجه (Object-Oriented Programming - OOP) هي وسيلة لنمذجة البرامج. ظهرت الكائنات (Objects) كمفهوم برمجي لأول مرة في لغة البرمجة Simula في الستينيات. أثرت تلك الـ Objects على المعمارية البرمجية لآلان كاي (Alan Kay) التي تتبادل فيها الـ Objects الرسائل فيما بينها. لوصف هذه المعمارية، صاغ مصطلح البرمجة كائنية التوجه (Object-Oriented Programming) في عام 1967. تصف العديد من التعريفات المتنافسة ماهية OOP، وبناءً على بعض هذه التعريفات، تُعتبر لغة Rust كائنية التوجه، بينما وفقاً لتعريفات أخرى لا تُعتبر كذلك. في هذا الفصل، سنستكشف خصائص معينة تُعتبر عادةً كائنية التوجه وكيف تترجم تلك الخصائص إلى لغة Rust الاصطلاحية (Idiomatic Rust). سنوضح لك بعد ذلك كيفية تنفيذ نمط تصميم (Design Pattern) كائني التوجه في Rust ونناقش المقايضات الناتجة عن القيام بذلك مقابل تنفيذ حل باستخدام بعض نقاط قوة Rust بدلاً من ذلك.
خصائص اللغات كائنية التوجه
خصائص اللغات كائنية التوجه (Object-Oriented Languages)
لا يوجد إجماع في مجتمع البرمجة حول الميزات التي يجب أن تتوفر في اللغة لكي تُعتبر كائنية التوجه. تتأثر لغة Rust بالعديد من النماذج البرمجية (Programming Paradigms)، بما في ذلك البرمجة كائنية التوجه (OOP)؛ على سبيل المثال، استكشفنا الميزات التي جاءت من البرمجة الوظيفية (Functional Programming) في الفصل 13. يمكن القول إن لغات OOP تشترك في خصائص معينة—وهي الكائنات، والتغليف، والوراثة. دعنا نلقي نظرة على معنى كل من هذه الخصائص وما إذا كانت Rust تدعمها.
الكائنات تحتوي على بيانات وسلوك (Objects Contain Data and Behavior)
كتاب أنماط التصميم: عناصر البرمجيات كائنية التوجه القابلة لإعادة الاستخدام (Design Patterns: Elements of Reusable Object-Oriented Software) لمؤلفيه إريك جاما، وريتشارد هيلم، ورالف جونسون، وجون فليسيدس (Addison-Wesley، 1994)، والمعروف عامياً بكتاب عصابة الأربعة (The Gang of Four)، هو فهرس لأنماط التصميم كائنية التوجه. يعرّف الكتاب OOP بهذه الطريقة:
تتكون البرامج كائنية التوجه من كائنات. يقوم الكائن (Object) بتغليف كل من البيانات والإجراءات التي تعمل على تلك البيانات. وعادة ما تسمى هذه الإجراءات توابع (Methods) أو عمليات (Operations).
باستخدام هذا التعريف، فإن Rust كائنية التوجه: فالهياكل (Structs) والتعدادات (Enums) تحتوي على بيانات، وتوفر كتل impl توابع (Methods) عليها. وبالرغم من أن Structs و Enums التي تحتوي على Methods لا تُسمى كائنات (Objects)، إلا أنها توفر نفس الوظائف، وفقاً لتعريف عصابة الأربعة للكائنات.
التغليف الذي يخفي تفاصيل التنفيذ (Encapsulation That Hides Implementation Details)
جانب آخر يرتبط عادة بـ OOP هو فكرة التغليف (Encapsulation)، والتي تعني أن تفاصيل تنفيذ (Implementation) الكائن لا يمكن الوصول إليها من قبل الشفرة البرمجية (Code) التي تستخدم ذلك الكائن. لذلك، فإن الطريقة الوحيدة للتفاعل مع الكائن هي من خلال واجهة برمجة التطبيقات (API) العامة الخاصة به؛ ولا ينبغي لـ Code الذي يستخدم الكائن أن يكون قادراً على الوصول إلى الأجزاء الداخلية للكائن وتغيير البيانات أو السلوك مباشرة. وهذا يمكن المبرمج من تغيير وإعادة هيكلة (Refactor) الأجزاء الداخلية للكائن دون الحاجة إلى تغيير Code الذي يستخدم الكائن.
ناقشنا كيفية التحكم في Encapsulation في الفصل 7: يمكننا استخدام الكلمة المفتاحية pub لتحديد أي الوحدات (Modules)، والأنواع (Types)، والدوال (Functions)، و Methods في Code الخاص بنا يجب أن تكون عامة (Public)، وبشكل افتراضي يكون كل شيء آخر خاصاً (Private). على سبيل المثال، يمكننا تعريف هيكل (Struct) باسم AveragedCollection يحتوي على حقل (Field) يضم متجهاً (Vector) من قيم i32. يمكن أن يحتوي Struct أيضاً على Field يضم متوسط القيم في Vector، مما يعني أنه لا يلزم حساب المتوسط عند الطلب في كل مرة يحتاجه فيها شخص ما. بمعنى آخر، سيقوم AveragedCollection بتخزين المتوسط المحسوب (Cache) لنا. تحتوي القائمة 18-1 على تعريف Struct AveragedCollection.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}تم وضع علامة pub على Struct لكي يتمكن Code الآخر من استخدامه، ولكن الحقول (Fields) داخل Struct تظل Private. هذا مهم في هذه الحالة لأننا نريد التأكد من أنه كلما تمت إضافة قيمة إلى القائمة أو إزالتها منها، يتم تحديث المتوسط أيضاً. نقوم بذلك من خلال تنفيذ Methods add و remove و average على Struct، كما هو موضح في القائمة 18-2.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average();
Some(value)
}
None => None,
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}تعتبر Methods العامة add و remove و average هي الطرق الوحيدة للوصول إلى البيانات أو تعديلها في مثيل (Instance) من AveragedCollection. عندما يتم إضافة عنصر إلى list باستخدام Method add أو إزالته باستخدام Method remove فإن تنفيذ كل منهما يستدعي Method الخاص update_average الذي يتولى تحديث Field average أيضاً.
نترك Fields list و average خاصة (Private) بحيث لا توجد طريقة لـ Code الخارجي لإضافة عناصر إلى Field list أو إزالتها منه مباشرة؛ وإلا فقد يصبح Field average غير متزامن عند تغير list. يعيد Method average القيمة الموجودة في Field average مما يسمح لـ Code الخارجي بقراءة المتوسط ولكن دون تعديله.
بما أننا قمنا بتغليف تفاصيل Implementation الخاصة بـ Struct AveragedCollection فيمكننا بسهولة تغيير جوانب معينة، مثل هيكل البيانات (Data Structure)، في المستقبل. على سبيل المثال، يمكننا استخدام HashSet<i32> بدلاً من Vec<i32> لـ Field list. وطالما ظلت تواقيع (Signatures) التوابع العامة add و remove و average كما هي، فلن يحتاج Code الذي يستخدم AveragedCollection إلى التغيير. إذا جعلنا list عاماً (Public) بدلاً من ذلك، فلن يكون هذا هو الحال بالضرورة: فـ HashSet<i32> و Vec<i32> لديهما Methods مختلفة لإضافة العناصر وإزالتها، لذا من المحتمل أن يضطر Code الخارجي للتغيير إذا كان يعدل list مباشرة.
إذا كان Encapsulation جانباً مطلوباً لكي تُعتبر اللغة كائنية التوجه، فإن Rust تلبي هذا المتطلب. فخيار استخدام pub أو عدم استخدامه لأجزاء مختلفة من Code يتيح تغليف تفاصيل Implementation.
الوراثة كنظام أنواع وكمشاركة للشفرة (Inheritance as a Type System and as Code Sharing)
الوراثة (Inheritance) هي آلية يمكن من خلالها للكائن أن يرث عناصر من تعريف كائن آخر، وبذلك يكتسب بيانات وسلوك الكائن الأب دون أن تضطر لتعريفها مرة أخرى.
إذا كان يجب أن تتوفر الوراثة في اللغة لكي تكون كائنية التوجه، فإن Rust ليست كذلك. فلا توجد طريقة لتعريف Struct يرث Fields وتنفيذ Methods لـ Struct الأب دون استخدام ماكرو (Macro).
ومع ذلك، إذا كنت معتاداً على وجود Inheritance في حقيبة أدواتك البرمجية، فيمكنك استخدام حلول أخرى في Rust، اعتماداً على سبب لجوئك إلى Inheritance في المقام الأول.
قد تختار Inheritance لسببين رئيسيين. أحدهما هو إعادة استخدام Code: يمكنك تنفيذ سلوك معين لنوع (Type) واحد، وتتيح لك Inheritance إعادة استخدام هذا Implementation لنوع مختلف. يمكنك القيام بذلك بطريقة محدودة في Code لغة Rust باستخدام تنفيذات سمة التابع الافتراضية (Default Trait Method Implementations)، والتي رأيتها في القائمة 10-14 عندما أضفنا تنفيذاً افتراضياً لـ Method summarize على سمة (Trait) Summary. أي Type ينفذ Trait Summary سيكون لديه Method summarize متاحاً عليه دون أي Code إضافي. وهذا يشبه وجود تنفيذ لـ Method في فئة أب (Parent Class) وامتلاك فئة ابن (Child Class) وارثة لنفس التنفيذ أيضاً. يمكننا أيضاً تجاوز (Override) التنفيذ الافتراضي لـ Method summarize عندما ننفذ Trait Summary وهو ما يشبه قيام Child Class بتجاوز تنفيذ Method موروث من Parent Class.
السبب الآخر لاستخدام Inheritance يتعلق بنظام الأنواع (Type System): للسماح باستخدام نوع ابن (Child Type) في نفس الأماكن التي يُستخدم فيها النوع الأب (Parent Type). يسمى هذا أيضاً تعدد الأشكال (Polymorphism)، وهو ما يعني أنه يمكنك استبدال كائنات متعددة ببعضها البعض في وقت التشغيل (Runtime) إذا كانت تشترك في خصائص معينة.
تعدد الأشكال (Polymorphism)
بالنسبة للكثيرين، يعتبر Polymorphism مرادفاً لـ Inheritance. لكنه في الواقع مفهوم أكثر عمومية يشير إلى Code يمكنه العمل مع بيانات من أنواع (Types) متعددة. وبالنسبة لـ Inheritance، تكون تلك Types عموماً فئات فرعية (Subclasses).
بدلاً من ذلك، تستخدم Rust الأنواع العامة (Generics) للتجريد (Abstract) عبر Types محتملة مختلفة، وحدود السمات (Trait Bounds) لفرض قيود على ما يجب أن توفره تلك Types. يسمى هذا أحياناً تعدد الأشكال البارامتري المحدود (Bounded Parametric Polymorphism).
اختارت Rust مجموعة مختلفة من المقايضات بعدم تقديمها لـ Inheritance. فغالباً ما تخاطر Inheritance بمشاركة Code أكثر من اللازم. لا ينبغي لـ Subclasses أن تشترك دائماً في جميع خصائص Parent Class الخاصة بها، ولكنها ستفعل ذلك مع Inheritance. وهذا يمكن أن يجعل تصميم البرنامج أقل مرونة. كما أنه يفتح المجال لاستدعاء Methods على Subclasses لا معنى لها أو تسبب أخطاء لأن Methods لا تنطبق على Subclass. بالإضافة إلى ذلك، تسمح بعض اللغات فقط بـ الوراثة الفردية (Single Inheritance) (مما يعني أن Subclass يمكنه الوراثة من فئة واحدة فقط)، مما يحد بشكل أكبر من مرونة تصميم البرنامج.
لهذه الأسباب، تتخذ Rust نهجاً مختلفاً باستخدام كائنات السمات (Trait Objects) بدلاً من Inheritance لتحقيق Polymorphism في Runtime. دعنا نلقي نظرة على كيفية عمل Trait Objects.
استخدام كائنات السمات للتجريد فوق السلوك المشترك (Trait Objects)
استخدام كائنات السمات للتجريد فوق السلوك المشترك (Using Trait Objects to Abstract over Shared Behavior)
في الفصل 8، ذكرنا أن أحد قيود المتجهات (vectors) هو أنها يمكن أن تخزن عناصر من نوع واحد فقط. لقد أنشأنا حلاً بديلاً في القائمة 8-9 حيث عرفنا تعداد SpreadsheetCell (enum) يحتوي على متغيرات (variants) لحمل الأعداد الصحيحة، والأعداد العشرية، والنصوص. كان هذا يعني أنه يمكننا تخزين أنواع مختلفة من البيانات في كل خلية مع استمرار وجود vector يمثل صفًا من الخلايا. هذا حل ممتاز عندما تكون العناصر القابلة للتبديل لدينا هي مجموعة ثابتة من الأنواع التي نعرفها عند ترجمة الكود الخاص بنا.
ومع ذلك، في بعض الأحيان نريد لمستخدم المكتبة الخاصة بنا أن يكون قادرًا على توسيع مجموعة الأنواع الصالحة في موقف معين. لتوضيح كيف يمكننا تحقيق ذلك، سننشئ مثالاً لأداة واجهة مستخدم رسومية (GUI) تمر عبر قائمة من العناصر، وتستدعي دالة draw على كل منها لرسمها على الشاشة - وهو أسلوب شائع لأدوات الـ GUI. سننشئ حزمة مكتبة (library crate) تسمى gui تحتوي على هيكلية مكتبة GUI. قد تتضمن هذه الـ crate بعض الأنواع ليستخدمها الأشخاص، مثل Button أو TextField. بالإضافة إلى ذلك، سيرغب مستخدمو gui في إنشاء أنواعهم الخاصة التي يمكن رسمها: على سبيل المثال، قد يضيف أحد المبرمجين Image وقد يضيف مبرمج آخر SelectBox.
في وقت كتابة المكتبة، لا يمكننا معرفة وتعريف جميع الأنواع التي قد يرغب المبرمجون الآخرون في إنشائها. لكننا نعلم أن gui بحاجة إلى تتبع العديد من القيم ذات الأنواع المختلفة، وهي بحاجة إلى استدعاء دالة draw على كل من هذه القيم ذات الأنواع المختلفة. لا تحتاج المكتبة إلى معرفة ما سيحدث بالضبط عندما نستدعي دالة draw بل تحتاج فقط إلى معرفة أن القيمة ستمتلك تلك الدالة متاحة لنا لاستدعائها.
للقيام بذلك في لغة تدعم الوراثة (inheritance)، قد نعرف فئة (class) تسمى Component تمتلك دالة تسمى draw. الفئات الأخرى، مثل Button و Image و SelectBox سترث من Component وبالتالي ترث دالة draw. يمكن لكل منها تجاوز (override) دالة draw لتعريف سلوكها المخصص، ولكن يمكن للإطار البرمجي (framework) التعامل مع جميع الأنواع كما لو كانت مثيلات (instances) من Component واستدعاء draw عليها. ولكن نظرًا لأن Rust لا تمتلك inheritance، فنحن بحاجة إلى طريقة أخرى لهيكلة مكتبة gui للسماح للمستخدمين بإنشاء أنواع جديدة متوافقة مع المكتبة.
تعريف سمة للسلوك المشترك (Defining a Trait for Common Behavior)
لتنفيذ السلوك الذي نريده لـ gui سنعرف سمة (trait) تسمى Draw ستمتلك دالة واحدة تسمى draw. بعد ذلك، يمكننا تعريف vector يأخذ كائن سمة (trait object). يشير الـ trait object إلى كل من مثيل لنوع ينفذ الـ trait المحدد وجدول يستخدم للبحث عن دوال (methods) الـ trait على ذلك النوع في وقت التشغيل (runtime). ننشئ trait object عن طريق تحديد نوع من المؤشرات (pointers)، مثل مرجع (reference) أو مؤشر ذكي من نوع Box<T> ثم الكلمة المفتاحية dyn ثم تحديد الـ trait ذي الصلة. (سنتحدث عن سبب وجوب استخدام trait objects لمؤشر في قسم “الأنواع ذات الحجم الديناميكي وسمة Sized” في الفصل 20). يمكننا استخدام trait objects بدلاً من نوع عام (generic) أو نوع ملموس (concrete type). أينما نستخدم trait object، سيضمن نظام الأنواع في Rust في وقت الترجمة (compile time) أن أي قيمة مستخدمة في ذلك السياق ستنفذ الـ trait الخاص بـ trait object. وبالتالي، لا نحتاج إلى معرفة جميع الأنواع الممكنة في وقت الترجمة.
لقد ذكرنا أننا في Rust نمتنع عن تسمية الهياكل (structs) والتعدادات (enums) بـ “كائنات” (objects) لتمييزها عن كائنات اللغات الأخرى. في الـ struct أو الـ enum، تكون البيانات في حقول الـ struct والسلوك في كتل impl منفصلة، بينما في اللغات الأخرى، غالبًا ما يطلق على البيانات والسلوك المدمجين في مفهوم واحد اسم كائن. تختلف الـ trait objects عن الكائنات في اللغات الأخرى في أننا لا نستطيع إضافة بيانات إلى trait object. الـ trait objects ليست مفيدة بشكل عام مثل الكائنات في اللغات الأخرى: غرضها المحدد هو السماح بالتجريد (abstraction) عبر السلوك المشترك.
توضح القائمة 18-3 كيفية تعريف trait يسمى Draw مع دالة واحدة تسمى draw.
pub trait Draw {
fn draw(&self);
}يجب أن يبدو بناء الجملة (syntax) هذا مألوفًا من نقاشاتنا حول كيفية تعريف الـ traits في الفصل 10. بعد ذلك يأتي بعض الـ syntax الجديد: توضح القائمة 18-4 تعريف struct يسمى Screen يحمل vector يسمى components. هذا الـ vector هو من نوع Box<dyn Draw> وهو trait object؛ إنه بديل لأي نوع داخل Box ينفذ الـ Draw trait.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}على هيكل Screen سنعرف دالة تسمى run ستستدعي دالة draw على كل من الـ components الخاصة بها، كما هو موضح في القائمة 18-5.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}يعمل هذا بشكل مختلف عن تعريف struct يستخدم معامل نوع عام (generic type parameter) مع قيود السمات (trait bounds). يمكن استبدال generic type parameter بنوع ملموس واحد فقط في كل مرة، بينما تسمح الـ trait objects لعدة أنواع ملموسة بملء مكان الـ trait object في وقت التشغيل. على سبيل المثال، كان بإمكاننا تعريف هيكل Screen باستخدام نوع عام و trait bound، كما في القائمة 18-6.
pub trait Draw {
fn draw(&self);
}
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}هذا يقيدنا بمثيل من Screen يمتلك قائمة من المكونات كلها من نوع Button أو كلها من نوع TextField. إذا كنت ستمتلك دائمًا مجموعات متجانسة (homogeneous collections)، فإن استخدام الـ generics والـ trait bounds يفضل لأن التعريفات سيتم توحيد شكلها (monomorphized) في وقت الترجمة لاستخدام الأنواع الملموسة.
من ناحية أخرى، مع الدالة التي تستخدم trait objects، يمكن لمثيل واحد من Screen أن يحمل Vec<T> يحتوي على Box<Button> بالإضافة إلى Box<TextField>. دعنا ننظر في كيفية عمل ذلك، ثم سنتحدث عن الآثار المترتبة على أداء وقت التشغيل.
تنفيذ السمة (Implementing the Trait)
الآن سنضيف بعض الأنواع التي تنفذ الـ Draw trait. سنوفر نوع Button. مرة أخرى، تنفيذ مكتبة GUI فعليًا هو خارج نطاق هذا الكتاب، لذا لن تمتلك دالة draw أي تنفيذ مفيد في جسمها. لتخيل كيف قد يبدو التنفيذ، قد يمتلك هيكل Button حقولاً لـ width و height و label كما هو موضح في القائمة 18-7.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
// code to actually draw a button
}
}ستختلف حقول width و height و label في Button عن الحقول في المكونات الأخرى؛ على سبيل المثال، قد يمتلك نوع TextField نفس تلك الحقول بالإضافة إلى حقل placeholder. كل نوع من الأنواع التي نريد رسمها على الشاشة سينفذ الـ Draw trait ولكنه سيستخدم كودًا مختلفًا في دالة draw لتعريف كيفية رسم ذلك النوع المعين، كما فعل Button هنا (بدون كود الـ GUI الفعلي، كما ذكرنا). قد يمتلك نوع Button على سبيل المثال كتلة impl إضافية تحتوي على methods متعلقة بما يحدث عندما ينقر المستخدم على الزر. هذه الأنواع من الـ methods لن تنطبق على أنواع مثل TextField.
إذا قرر شخص يستخدم مكتبتنا تنفيذ هيكل SelectBox يمتلك حقول width و height و options فإنه سينفذ الـ Draw trait على نوع SelectBox أيضًا، كما هو موضح في القائمة 18-8.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
fn main() {}يمكن لمستخدم مكتبتنا الآن كتابة دالة main الخاصة به لإنشاء مثيل من Screen. إلى مثيل Screen يمكنه إضافة SelectBox و Button عن طريق وضع كل منهما في Box<T> ليصبح trait object. يمكنه بعد ذلك استدعاء دالة run على مثيل Screen والتي ستستدعي draw على كل من المكونات. توضح القائمة 18-9 هذا التنفيذ.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
use gui::{Button, Screen};
fn main() {
let screen = Screen {
components: vec![
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
screen.run();
}عندما كتبنا المكتبة، لم نكن نعلم أن شخصًا ما قد يضيف نوع SelectBox ولكن تنفيذنا لـ Screen كان قادرًا على العمل على النوع الجديد ورسمه لأن SelectBox ينفذ الـ Draw trait، مما يعني أنه ينفذ دالة draw.
هذا المفهوم - المتمثل في الاهتمام فقط بالرسائل التي تستجيب لها القيمة بدلاً من النوع الملموس للقيمة - يشبه مفهوم كتابة البطة (duck typing) في اللغات ذات الأنواع الديناميكية: إذا كان يمشي مثل البطة ويصيح مثل البطة، فلا بد أنه بطة! في تنفيذ run على Screen في القائمة 18-5، لا تحتاج run إلى معرفة النوع الملموس لكل مكون. إنها لا تتحقق مما إذا كان المكون مثيلاً لـ Button أو SelectBox بل تستدعي فقط دالة draw على المكون. من خلال تحديد Box<dyn Draw> كنوع للقيم في vector الـ components فقد عرفنا Screen بحيث يحتاج إلى قيم يمكننا استدعاء دالة draw عليها.
ميزة استخدام trait objects ونظام الأنواع في Rust لكتابة كود مشابه للكود الذي يستخدم duck typing هي أننا لا نضطر أبدًا للتحقق مما إذا كانت القيمة تنفذ دالة معينة في وقت التشغيل أو القلق بشأن الحصول على أخطاء إذا كانت القيمة لا تنفذ دالة ولكننا استدعيناها على أي حال. لن يترجم Rust الكود الخاص بنا إذا كانت القيم لا تنفذ الـ traits التي تحتاجها الـ trait objects.
على سبيل المثال، توضح القائمة 18-10 ما يحدث إذا حاولنا إنشاء Screen مع String كمكون.
use gui::Screen;
fn main() {
let screen = Screen {
components: vec![Box::new(String::from("Hi"))],
};
screen.run();
}سنحصل على هذا الخطأ لأن String لا ينفذ الـ Draw trait:
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast from `Box<String>` to `Box<dyn Draw>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` (bin "gui") due to 1 previous error
يخبرنا هذا الخطأ أننا إما نمرر شيئًا إلى Screen لم نكن نقصد تمريره وبالتالي يجب تمرير نوع مختلف، أو يجب علينا تنفيذ Draw على String بحيث يتمكن Screen من استدعاء draw عليه.
إجراء الإرسال الديناميكي (Performing Dynamic Dispatch)
تذكر في قسم “أداء الكود الذي يستخدم الأنواع العامة” في الفصل 10 نقاشنا حول عملية الـ monomorphization التي يجريها المترجم على الـ generics: ينشئ المترجم تنفيذات غير عامة للدوال والـ methods لكل نوع ملموس نستخدمه بدلاً من generic type parameter. الكود الناتج عن monomorphization يقوم بـ إرسال ثابت (static dispatch)، وهو عندما يعرف المترجم الدالة التي تستدعيها في وقت الترجمة. هذا على عكس الإرسال الديناميكي (dynamic dispatch)، وهو عندما لا يستطيع المترجم معرفة الدالة التي تستدعيها في وقت الترجمة. في حالات الـ dynamic dispatch، يصدر المترجم كودًا سيعرف في وقت التشغيل الدالة التي يجب استدعاؤها.
عندما نستخدم trait objects، يجب على Rust استخدام dynamic dispatch. لا يعرف المترجم جميع الأنواع التي قد تستخدم مع الكود الذي يستخدم trait objects، لذا فهو لا يعرف أي دالة منفذة على أي نوع يجب استدعاؤها. بدلاً من ذلك، في وقت التشغيل، يستخدم Rust المؤشرات داخل trait object لمعرفة الدالة التي يجب استدعاؤها. هذا البحث يتطلب تكلفة في وقت التشغيل لا تحدث مع الـ static dispatch. يمنع الـ dynamic dispatch المترجم أيضًا من اختيار تضمين (inline) كود الدالة، مما يمنع بدوره بعض التحسينات (optimizations)، ولدى Rust بعض القواعد حول أين يمكنك وأين لا يمكنك استخدام dynamic dispatch، تسمى توافق dyn (dyn compatibility). تلك القواعد خارج نطاق هذا النقاش، ولكن يمكنك قراءة المزيد عنها في المرجع. ومع ذلك، فقد حصلنا على مرونة إضافية في الكود الذي كتبناه في القائمة 18-5 وتمكنا من دعمه في القائمة 18-9، لذا فهي مقايضة يجب أخذها في الاعتبار.
تنفيذ نمط تصميم كائني التوجه (Design Pattern)
تنفيذ نمط تصميم كائني التوجه (Implementing an Object-Oriented Design Pattern)
يُعد نمط الحالة (state pattern) أحد أنماط التصميم كائنية التوجه (object-oriented design patterns). جوهر هذا النمط هو أننا نعرف مجموعة من الحالات التي يمكن أن تتخذها قيمة ما داخلياً. يتم تمثيل هذه الحالات بواسطة مجموعة من كائنات الحالة (state objects)، ويتغير سلوك القيمة بناءً على حالتها. سنعمل من خلال مثال على هيكل (struct) لمنشور مدونة يحتوي على حقل للاحتفاظ بحالته، والتي ستكون state object من المجموعة “مسودة” (draft)، أو “مراجعة” (review)، أو “منشور” (published).
تتشارك state objects في الوظائف: في لغة رست (Rust)، بالطبع، نستخدم structs والسمات (traits) بدلاً من الكائنات (objects) والوراثة (inheritance). كل state object مسؤول عن سلوكه الخاص وعن تحديد متى يجب أن ينتقل إلى حالة أخرى. القيمة التي تحمل state object لا تعرف شيئاً عن السلوك المختلف للحالات أو متى يتم الانتقال بين الحالات.
ميزة استخدام state pattern هي أنه عندما تتغير متطلبات العمل (business requirements) للبرنامج، فلن نحتاج إلى تغيير كود القيمة التي تحمل الحالة أو الكود الذي يستخدم تلك القيمة. سنحتاج فقط إلى تحديث الكود داخل أحد state objects لتغيير قواعده أو ربما إضافة المزيد من state objects.
أولاً، سنقوم بتنفيذ state pattern بطريقة كائنية التوجه (object-oriented) تقليدية. بعد ذلك، سنستخدم نهجاً أكثر طبيعية في Rust. دعونا نبدأ في تنفيذ سير عمل (workflow) لمنشور مدونة تدريجياً باستخدام state pattern.
ستبدو الوظيفة النهائية كما يلي:
- يبدأ منشور المدونة كمسودة فارغة.
- عند الانتهاء من المسودة، يتم طلب مراجعة للمنشور.
- عند الموافقة على المنشور، يتم نشره.
- تعيد منشورات المدونة المنشورة فقط محتوى لطباعته بحيث لا يمكن نشر المنشورات غير المعتمدة عن طريق الخطأ.
أي تغييرات أخرى يتم محاولتها على المنشور يجب ألا يكون لها أي تأثير. على سبيل المثال، إذا حاولنا الموافقة على منشور مدونة في حالة draft قبل طلب review، فيجب أن يظل المنشور مسودة غير منشورة.
محاولة النمط كائني التوجه التقليدي (Attempting Traditional Object-Oriented Style)
هناك طرق لا حصر لها لهيكلة الكود لحل نفس المشكلة، ولكل منها مقايضات (trade-offs) مختلفة. تنفيذ هذا القسم يتبع أسلوباً كائني التوجه تقليدياً، وهو أمر ممكن كتابته في Rust، ولكنه لا يستفيد من بعض نقاط قوة Rust. لاحقاً، سنعرض حلاً مختلفاً لا يزال يستخدم object-oriented design pattern ولكنه مهيكل بطريقة قد تبدو أقل مألوفة للمبرمجين ذوي الخبرة في object-oriented. سنقارن بين الحلين لتجربة trade-offs لتصميم كود Rust بشكل مختلف عن الكود في اللغات الأخرى.
توضح القائمة 18-11 سير العمل هذا في شكل كود: هذا مثال لاستخدام واجهة برمجة التطبيقات (API) التي سننفذها في حزمة مكتبة (library crate) تسمى blog. لن يتم تصريف هذا الكود بعد لأننا لم نقم بتنفيذ crate المسمى blog.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}نريد السماح للمستخدم بإنشاء منشور مدونة جديد كمسودة باستخدام Post::new. ونريد السماح بإضافة نص إلى منشور المدونة. إذا حاولنا الحصول على محتوى المنشور فوراً، قبل الموافقة، فلا يجب أن نحصل على أي نص لأن المنشور لا يزال draft. لقد أضفنا assert_eq! في الكود لأغراض التوضيح. سيكون اختبار الوحدة (unit test) الممتاز لهذا هو التأكد من أن منشور المدونة في حالة draft يعيد سلسلة نصية فارغة من دالة الكائن (method) المسمى content ، لكننا لن نكتب اختبارات لهذا المثال.
بعد ذلك، نريد تمكين طلب مراجعة للمنشور، ونريد من content أن تعيد سلسلة نصية فارغة أثناء انتظار review. عندما يتلقى المنشور الموافقة، يجب أن يتم نشره، مما يعني أن نص المنشور سيتم إعادته عند استدعاء content.
لاحظ أن النوع الوحيد الذي نتفاعل معه من crate هو النوع Post. سيستخدم هذا النوع state pattern وسيحمل قيمة ستكون واحدة من ثلاثة state objects تمثل الحالات المختلفة التي يمكن أن يكون عليها المنشور—draft، أو review، أو published. سيتم إدارة التغيير من حالة إلى أخرى داخلياً ضمن النوع Post. تتغير الحالات استجابة لـ methods التي يستدعيها مستخدمو مكتبتنا على مثيل (instance) من Post ، لكن ليس عليهم إدارة تغييرات الحالة مباشرة. أيضاً، لا يمكن للمستخدمين ارتكاب خطأ في الحالات، مثل نشر منشور قبل مراجعته.
تعريف Post وإنشاء مثيل جديد (Defining Post and Creating a New Instance)
دعونا نبدأ في تنفيذ المكتبة! نحن نعلم أننا بحاجة إلى struct عام يسمى Post يحمل بعض المحتوى، لذا سنبدأ بتعريف struct ودالة عامة مرتبطة (associated function) تسمى new لإنشاء instance من Post ، كما هو موضح في القائمة 18-12. سنقوم أيضاً بإنشاء trait خاص يسمى State يحدد السلوك الذي يجب أن تمتلكه جميع state objects لـ Post.
بعد ذلك، سيحمل Post كائن سمة (trait object) من نوع Box<dyn State> داخل Option<T> في حقل خاص يسمى state للاحتفاظ بـ state object. سترى سبب ضرورة Option<T> بعد قليل.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
}
trait State {}
struct Draft {}
impl State for Draft {}تحدد trait المسمى State السلوك المشترك بين حالات المنشور المختلفة. كائنات الحالة هي Draft و PendingReview و Published ، وجميعها ستنفذ State trait. في الوقت الحالي، لا تحتوي trait على أي methods، وسنبدأ بتعريف حالة Draft فقط لأن هذه هي الحالة التي نريد أن يبدأ بها المنشور.
عندما ننشئ Post جديداً، نضبط حقل state الخاص به على قيمة Some تحمل Box. يشير هذا Box إلى instance جديد من struct المسمى Draft. يضمن هذا أنه كلما أنشأنا instance جديداً من Post ، فإنه سيبدأ كمسودة. نظرًا لأن حقل state في Post خاص، فلا توجد طريقة لإنشاء Post في أي حالة أخرى! في دالة Post::new ، نضبط حقل content على String جديد وفارغ.
تخزين نص محتوى المنشور (Storing the Text of the Post Content)
رأينا في القائمة 18-11 أننا نريد أن نكون قادرين على استدعاء method يسمى add_text وتمرير &str إليه ليتم إضافته كمحتوى نصي لمنشور المدونة. نقوم بتنفيذ هذا كـ method، بدلاً من كشف حقل content كـ pub ، حتى نتمكن لاحقاً من تنفيذ method يتحكم في كيفية قراءة بيانات حقل content. دالة add_text بسيطة للغاية، لذا دعونا نضيف التنفيذ في القائمة 18-13 إلى كتلة impl Post.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
trait State {}
struct Draft {}
impl State for Draft {}تأخذ add_text مرجعاً قابلاً للتغيير (mutable reference) لـ self لأننا نغير instance الخاص بـ Post الذي نستدعي add_text عليه. ثم نستدعي push_str على String في content ونمرر معامل (argument) النص لإضافته إلى content المحفوظ. هذا السلوك لا يعتمد على الحالة التي يمر بها المنشور، لذا فهو ليس جزءاً من state pattern. لا تتفاعل دالة add_text مع حقل state على الإطلاق، ولكنها جزء من السلوك الذي نريد دعمه.
التأكد من أن محتوى المنشور المسودة فارغ (Ensuring That the Content of a Draft Post Is Empty)
حتى بعد استدعاء add_text وإضافة بعض المحتوى إلى منشورنا، لا نزال نريد أن تعيد دالة content شريحة نصية (string slice) فارغة لأن المنشور لا يزال في حالة draft، كما هو موضح في أول assert_eq! في القائمة 18-11. في الوقت الحالي، دعونا ننفذ دالة content بأبسط شيء يحقق هذا المتطلب: إعادة string slice فارغة دائماً. سنغير هذا لاحقاً بمجرد تنفيذ القدرة على تغيير حالة المنشور بحيث يمكن نشره. حتى الآن، يمكن أن تكون المنشورات في حالة draft فقط، لذا يجب أن يكون محتوى المنشور فارغاً دائماً. توضح القائمة 18-14 هذا التنفيذ المؤقت (placeholder).
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
}
trait State {}
struct Draft {}
impl State for Draft {}مع إضافة دالة content هذه، يعمل كل شيء في القائمة 18-11 حتى أول assert_eq! كما هو مطلوب.
طلب مراجعة، مما يغير حالة المنشور (Requesting a Review, Which Changes the Post’s State)
بعد ذلك، نحتاج إلى إضافة وظيفة لطلب مراجعة للمنشور، والتي يجب أن تغير حالته من Draft إلى PendingReview. توضح القائمة 18-15 هذا الكود.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
}نعطي Post دالة عامة تسمى request_review تأخذ mutable reference لـ self. ثم نستدعي دالة request_review داخلية على الحالة الحالية لـ Post ، وهذه الدالة الثانية تستهلك الحالة الحالية وتعيد حالة جديدة.
نضيف دالة request_review إلى State trait؛ ستحتاج جميع الأنواع التي تنفذ trait الآن إلى تنفيذ دالة request_review. لاحظ أنه بدلاً من وجود self أو &self أو &mut self كأول معامل للدالة، لدينا self: Box<Self>. تعني هذه الصيغة أن الدالة صالحة فقط عند استدعائها على Box يحمل النوع. تأخذ هذه الصيغة ملكية (ownership) لـ Box<Self> ، مما يؤدي إلى إبطال الحالة القديمة بحيث يمكن لقيمة الحالة في Post أن تتحول إلى حالة جديدة.
لاستهلاك الحالة القديمة، تحتاج دالة request_review إلى أخذ ملكية قيمة الحالة. وهنا يأتي دور Option في حقل state الخاص بـ Post: نستدعي دالة take لإخراج قيمة Some من حقل state وترك None في مكانها لأن Rust لا تسمح لنا بامتلاك حقول غير ممتلئة في structs. يتيح لنا ذلك نقل قيمة state خارج Post بدلاً من استعارتها. بعد ذلك، سنضبط قيمة state للمنشور على نتيجة هذه العملية.
نحتاج إلى ضبط state على None مؤقتاً بدلاً من ضبطها مباشرة
بعد أن قمنا بتحويلها إلى حالة جديدة.
تعيد دالة request_review في Draft مثيلاً جديداً ومغلفاً (boxed instance) من struct جديد يسمى PendingReview ، والذي يمثل الحالة عندما ينتظر المنشور المراجعة. ينفذ struct المسمى PendingReview أيضاً دالة request_review ولكنه لا يقوم بأي تحويلات. بدلاً من ذلك، يعيد نفسه لأنه عندما نطلب مراجعة لمنشور موجود بالفعل في حالة PendingReview ، يجب أن يظل في حالة PendingReview.
الآن يمكننا البدء في رؤية مزايا state pattern: دالة request_review في Post هي نفسها بغض النظر عن قيمة state الخاصة بها. كل حالة مسؤولة عن قواعدها الخاصة.
سنترك دالة content في Post كما هي، تعيد string slice فارغة. يمكننا الآن الحصول على Post في حالة PendingReview وكذلك في حالة Draft ، لكننا نريد نفس السلوك في حالة PendingReview. القائمة 18-11 تعمل الآن حتى استدعاء assert_eq! الثاني!
إضافة approve لتغيير سلوك content (Adding approve to Change content’s Behavior)
ستكون دالة approve مشابهة لدالة request_review: ستقوم بضبط state على القيمة التي تقول الحالة الحالية إنها يجب أن تمتلكها عند الموافقة على تلك الحالة، كما هو موضح في القائمة 18-16.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}نضيف دالة approve إلى State trait ونضيف struct جديداً ينفذ State ، وهو حالة Published.
بشكل مشابه للطريقة التي تعمل بها request_review في PendingReview ، إذا استدعينا دالة approve على Draft ، فلن يكون لها أي تأثير لأن approve ستعيد self. عندما نستدعي approve على PendingReview ، فإنها تعيد boxed instance جديداً من struct المسمى Published. ينفذ struct المسمى Published السمة State ، وبالنسبة لكل من دالة request_review ودالة approve ، فإنه يعيد نفسه لأن المنشور يجب أن يظل في حالة Published في تلك الحالات.
الآن نحتاج إلى تحديث دالة content في Post. نريد أن تعتمد القيمة المعادة من content على الحالة الحالية لـ Post ، لذا سنجعل Post يفوض (delegate) المهمة لدالة content معرفة في state الخاصة به، كما هو موضح في القائمة 18-17.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
// --snip--
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}بما أن الهدف هو إبقاء كل هذه القواعد داخل structs التي تنفذ State ، فإننا نستدعي دالة content على القيمة الموجودة في state ونمرر instance المنشور (أي self) كمعامل. ثم نعيد القيمة التي يتم إرجاعها من استخدام دالة content على قيمة state.
نستدعي دالة as_ref على Option لأننا نريد مرجعاً (reference) للقيمة الموجودة داخل Option بدلاً من ملكية القيمة. نظرًا لأن state هي من نوع Option<Box<dyn State>> ، فعندما نستدعي as_ref ، يتم إرجاع Option<&Box<dyn State>>. إذا لم نستدعِ as_ref ، فسنحصل على خطأ لأننا لا نستطيع نقل state خارج &self المستعار لمعامل الدالة.
ثم نستدعي دالة unwrap ، والتي نعلم أنها لن تتسبب أبداً في توقف طارئ (panic) لأننا نعلم أن methods في Post تضمن أن state ستحتوي دائماً على قيمة Some عند انتهاء تلك methods. هذه واحدة من الحالات التي تحدثنا عنها في قسم “عندما تمتلك معلومات أكثر من المصرّف” في الفصل التاسع عندما نعلم أن قيمة None غير ممكنة أبداً، على الرغم من أن compiler غير قادر على فهم ذلك.
عند هذه النقطة، عندما نستدعي content على &Box<dyn State> ، سيبدأ مفعول إكراه فك المرجع (deref coercion) على & و Box بحيث يتم استدعاء دالة content في النهاية على النوع الذي ينفذ State trait. وهذا يعني أننا بحاجة إلى إضافة content إلى تعريف State trait، وهنا سنضع المنطق الخاص بالمحتوى الذي سيتم إرجاعه بناءً على الحالة التي لدينا، كما هو موضح في القائمة 18-18.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// --snip--
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}نضيف تنفيذاً افتراضياً (default implementation) لدالة content يعيد string slice فارغة. وهذا يعني أننا لسنا بحاجة لتنفيذ content في structs المسمى Draft و PendingReview. سيقوم struct المسمى Published بتجاوز (override) دالة content وإعادة القيمة الموجودة في post.content. على الرغم من كونه ملائماً، إلا أن جعل دالة content في State تحدد محتوى Post يؤدي إلى تداخل الحدود بين مسؤولية State ومسؤولية Post.
لاحظ أننا بحاجة إلى تعليقات توضيحية للعمر (lifetime annotations) في هذه الدالة، كما ناقشنا في الفصل العاشر. نحن نأخذ reference لـ post كمعامل ونعيد reference لجزء من ذلك post ، لذا فإن عمر المرجع المعاد مرتبط بعمر معامل post.
لقد انتهينا—كل ما في القائمة 18-11 يعمل الآن! لقد قمنا بتنفيذ state pattern مع قواعد سير عمل منشور المدونة. المنطق المتعلق بالقواعد يعيش في state objects بدلاً من أن يكون مشتتاً في جميع أنحاء Post.
لماذا لا نستخدم التعداد (Enum)؟
ربما كنت تتساءل لماذا لم نستخدم تعداداً (enum) مع حالات المنشور المختلفة كمتغيرات (variants). هذا بالتأكيد حل ممكن؛ جربه وقارن النتائج النهائية لترى أيهما تفضل! أحد عيوب استخدام enum هو أن كل مكان يتحقق من قيمة enum سيحتاج إلى تعبير مطابقة (match expression) أو ما شابه للتعامل مع كل variant ممكن. قد يصبح هذا أكثر تكراراً من حل trait object هذا.
تقييم نمط الحالة (Evaluating the State Pattern)
لقد أظهرنا أن Rust قادرة على تنفيذ object-oriented state pattern لتغليف (encapsulate) الأنواع المختلفة من السلوك التي يجب أن يتمتع بها المنشور في كل حالة. لا تعرف methods في Post شيئاً عن السلوكيات المختلفة. وبسبب الطريقة التي نظمنا بها الكود، علينا النظر في مكان واحد فقط لمعرفة الطرق المختلفة التي يمكن أن يتصرف بها المنشور المنشور: تنفيذ State trait على struct المسمى Published.
إذا أردنا إنشاء تنفيذ بديل لا يستخدم state pattern، فقد نستخدم بدلاً من ذلك match expressions في methods الخاصة بـ Post أو حتى في كود main الذي يتحقق من حالة المنشور ويغير السلوك في تلك الأماكن. وهذا يعني أننا سنضطر إلى النظر في عدة أماكن لفهم جميع تداعيات كون المنشور في حالة published.
مع state pattern، لا تحتاج methods في Post والأماكن التي نستخدم فيها Post إلى match expressions، ولإضافة حالة جديدة، سنحتاج فقط إلى إضافة struct جديد وتنفيذ trait methods على ذلك struct في مكان واحد.
التنفيذ باستخدام state pattern سهل التوسيع لإضافة المزيد من الوظائف. لرؤية بساطة صيانة الكود الذي يستخدم state pattern، جرب بعض هذه الاقتراحات:
- أضف دالة
rejectتغير حالة المنشور منPendingReviewمرة أخرى إلىDraft. - اشترط استدعاءين لـ
approveقبل أن يتم تغيير الحالة إلىPublished. - اسمح للمستخدمين بإضافة محتوى نصي فقط عندما يكون المنشور في حالة
Draft. تلميح: اجعل state object مسؤولاً عما قد يتغير في المحتوى ولكنه غير مسؤول عن تعديلPost.
أحد عيوب state pattern هو أنه نظراً لأن الحالات تنفذ الانتقالات بين الحالات، فإن بعض الحالات مرتبطة (coupled) ببعضها البعض. إذا أضفنا حالة أخرى بين PendingReview و Published ، مثل Scheduled ، فسنضطر إلى تغيير الكود في PendingReview للانتقال إلى Scheduled بدلاً من ذلك. سيكون العمل أقل إذا لم تكن PendingReview بحاجة إلى التغيير مع إضافة حالة جديدة، ولكن هذا يعني الانتقال إلى نمط تصميم آخر.
عيب آخر هو أننا قمنا بتكرار بعض المنطق. للتخلص من بعض التكرار، قد نحاول عمل default implementations لدوال request_review و approve في State trait تعيد self. ومع ذلك، لن يعمل هذا: عند استخدام State كـ trait object، لا تعرف trait ما سيكون عليه self الملموس (concrete) بالضبط، لذا فإن نوع الإرجاع غير معروف في وقت التصريف. (هذه واحدة من قواعد توافق dyn المذكورة سابقاً.)
يتضمن التكرار الآخر التنفيذات المتشابهة لدوال request_review و approve في Post. تستخدم كلتا الدالتين Option::take مع حقل state في Post ، وإذا كانت state هي Some ، فإنهما تفوضان المهمة لتنفيذ القيمة المغلفة لنفس الدالة وتضبطان القيمة الجديدة لحقل state على النتيجة. إذا كان لدينا الكثير من methods في Post تتبع هذا النمط، فقد نفكر في تعريف ماكرو (macro) للتخلص من التكرار (انظر قسم “الماكرو” في الفصل 20).
من خلال تنفيذ state pattern تماماً كما هو محدد للغات كائنية التوجه، فإننا لا نستفيد بشكل كامل من نقاط قوة Rust كما يمكننا. دعونا نلقي نظرة على بعض التغييرات التي يمكننا إجراؤها على crate المسمى blog والتي يمكن أن تجعل الحالات والانتقالات غير الصالحة أخطاء في وقت التصريف (compile-time errors).
ترميز الحالات والسلوك كأنواع (Encoding States and Behavior as Types)
سنوضح لك كيفية إعادة التفكير في state pattern للحصول على مجموعة مختلفة من trade-offs. بدلاً من تغليف الحالات والانتقالات تماماً بحيث لا يكون للكود الخارجي أي معرفة بها، سنقوم بترميز (encode) الحالات في أنواع مختلفة. وبالتالي، سيمنع نظام فحص الأنواع (type-checking system) في Rust محاولات استخدام منشورات draft حيث يُسمح فقط بمنشورات published عن طريق إصدار خطأ من compiler.
دعونا نفكر في الجزء الأول من main في القائمة 18-11:
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}لا نزال نمكن من إنشاء منشورات جديدة في حالة draft باستخدام Post::new والقدرة على إضافة نص إلى محتوى المنشور. ولكن بدلاً من وجود دالة content في منشور draft تعيد سلسلة نصية فارغة، سنجعل الأمر بحيث لا تمتلك منشورات draft دالة content على الإطلاق. بهذه الطريقة، إذا حاولنا الحصول على محتوى منشور draft، فسنحصل على خطأ من compiler يخبرنا أن الدالة غير موجودة. ونتيجة لذلك، سيكون من المستحيل بالنسبة لنا عرض محتوى منشور draft عن طريق الخطأ في الإنتاج لأن ذلك الكود لن يتم تصريفه أصلاً. توضح القائمة 18-19 تعريف struct المسمى Post و struct المسمى DraftPost ، بالإضافة إلى methods في كل منهما.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}يمتلك كل من structs المسمى Post و DraftPost حقل content خاصاً يخزن نص منشور المدونة. لم تعد structs تمتلك حقل state لأننا ننقل ترميز الحالة إلى أنواع structs. سيمثل struct المسمى Post منشوراً منشوراً، ولديه دالة content تعيد content.
لا يزال لدينا دالة Post::new ، ولكن بدلاً من إرجاع instance من Post ، فإنها تعيد instance من DraftPost. نظرًا لأن content خاص ولا توجد أي functions تعيد Post ، فليس من الممكن إنشاء instance من Post في الوقت الحالي.
يمتلك struct المسمى DraftPost دالة add_text ، لذا يمكننا إضافة نص إلى content كما كان من قبل، ولكن لاحظ أن DraftPost لا يمتلك دالة content معرفة! لذا الآن يضمن البرنامج أن جميع المنشورات تبدأ كمنشورات draft، ومنشورات draft ليس محتواها متاحاً للعرض. أي محاولة للحصول على
محتوى هذه القيود سيؤدي إلى خطأ من compiler.
إذن، كيف نحصل على منشور منشور؟ نريد فرض القاعدة التي تنص على أن منشور draft يجب مراجعته والموافقة عليه قبل أن يتم نشره. يجب ألا يعرض المنشور في حالة pending review أي محتوى أيضاً. دعونا ننفذ هذه القيود عن طريق إضافة struct آخر يسمى PendingReviewPost ، وتعريف دالة request_review في DraftPost لتعيد PendingReviewPost وتعريف دالة approve في PendingReviewPost لتعيد Post ، كما هو موضح في القائمة 18-20.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
// --snip--
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(self) -> PendingReviewPost {
PendingReviewPost {
content: self.content,
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
}تأخذ دالتا request_review و approve ملكية self ، وبالتالي تستهلكان مثيلات DraftPost و PendingReviewPost وتحولانهما إلى PendingReviewPost و Post منشور، على التوالي. بهذه الطريقة، لن يكون لدينا أي مثيلات DraftPost متبقية بعد استدعاء request_review عليها، وهكذا دواليك. لا يمتلك struct المسمى PendingReviewPost دالة content معرفة فيه، لذا فإن محاولة قراءة محتواه تؤدي إلى خطأ من compiler، كما هو الحال مع DraftPost. ولأن الطريقة الوحيدة للحصول على instance من Post منشور يمتلك دالة content معرفة هي استدعاء دالة approve على PendingReviewPost ، والطريقة الوحيدة للحصول على PendingReviewPost هي استدعاء دالة request_review على DraftPost ، فقد قمنا الآن بترميز سير عمل منشور المدونة في نظام الأنواع (type system).
ولكن علينا أيضاً إجراء بعض التغييرات الصغيرة في main. تعيد دالتا request_review و approve مثيلات جديدة بدلاً من تعديل struct الذي يتم استدعاؤهما عليه، لذا نحتاج إلى إضافة المزيد من تعيينات التظليل (shadowing assignments) باستخدام let post = لحفظ المثيلات المعادة. كما لا يمكننا إجراء التأكيدات (assertions) حول كون محتويات منشورات draft و pending review سلاسل نصية فارغة، ولسنا بحاجة إليها: لا يمكننا تصريف الكود الذي يحاول استخدام محتوى المنشورات في تلك الحالات بعد الآن. يظهر الكود المحدث في main في القائمة 18-21.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
let post = post.request_review();
let post = post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}التغييرات التي احتجنا لإجرائها في main لإعادة تعيين post تعني أن هذا التنفيذ لا يتبع تماماً object-oriented state pattern بعد الآن: التحويلات بين الحالات لم تعد مغلفة بالكامل داخل تنفيذ Post. ومع ذلك، فإن مكسبنا هو أن الحالات غير الصالحة أصبحت الآن مستحيلة بسبب نظام الأنواع وفحص الأنواع الذي يحدث في وقت التصريف! يضمن هذا اكتشاف بعض الأخطاء، مثل عرض محتوى منشور غير منشور، قبل وصولها إلى الإنتاج.
جرب المهام المقترحة في بداية هذا القسم على crate المسمى blog كما هو بعد القائمة 18-21 لترى رأيك في تصميم هذا الإصدار من الكود. لاحظ أن بعض المهام قد تكون مكتملة بالفعل في هذا التصميم.
لقد رأينا أنه على الرغم من أن Rust قادرة على تنفيذ أنماط التصميم كائنية التوجه، إلا أن أنماطاً أخرى، مثل ترميز الحالة في نظام الأنواع، متاحة أيضاً في Rust. هذه الأنماط لها trade-offs مختلفة. على الرغم من أنك قد تكون على دراية كبيرة بالأنماط كائنية التوجه، إلا أن إعادة التفكير في المشكلة للاستفادة من ميزات Rust يمكن أن توفر فوائد، مثل منع بعض الأخطاء في وقت التصريف. لن تكون الأنماط كائنية التوجه دائماً هي الحل الأفضل في Rust بسبب ميزات معينة، مثل الملكية (ownership)، التي لا تمتلكها اللغات كائنية التوجه.
ملخص (Summary)
بغض النظر عما إذا كنت تعتقد أن Rust لغة كائنية التوجه بعد قراءة هذا الفصل، فأنت تعلم الآن أنه يمكنك استخدام trait objects للحصول على بعض الميزات كائنية التوجه في Rust. يمكن أن يمنح الإرسال الديناميكي (dynamic dispatch) كودك بعض المرونة مقابل القليل من أداء وقت التشغيل. يمكنك استخدام هذه المرونة لتنفيذ أنماط كائنية التوجه يمكن أن تساعد في قابلية صيانة كودك. تمتلك Rust أيضاً ميزات أخرى، مثل ownership، لا تمتلكها اللغات كائنية التوجه. لن يكون النمط كائني التوجه دائماً هو أفضل طريقة للاستفادة من نقاط قوة Rust، ولكنه خيار متاح.
بعد ذلك، سننظر في الأنماط (patterns)، وهي ميزة أخرى من ميزات Rust التي تتيح الكثير من المرونة. لقد نظرنا إليها باختصار طوال الكتاب ولكننا لم نرَ كامل قدراتها بعد. لننطلق!
الأنماط والمطابقة (Patterns and Matching)
الأنماط (Patterns) هي صيغة خاصة في لغة Rust للمطابقة مع بنية الأنواع (Types)، سواء كانت معقدة أم بسيطة. يمنحك استخدام Patterns بالاقتران مع تعبيرات match والبنى الأخرى تحكماً أكبر في تدفق التحكم (Control Flow) للبرنامج. يتكون Pattern من مزيج من العناصر التالية:
- القيم المكتوبة مباشرة (Literals)
- المصفوفات (Arrays)، أو التعدادات (Enums)، أو الهياكل (Structs)، أو الصفوف (Tuples) المفككة (Destructured)
- المتغيرات (Variables)
- الرموز الشاملة (Wildcards)
- العناصر النائبة (Placeholders)
تشمل بعض أمثلة Patterns كلاً من x و (a, 3) و Some(Color::Red). في السياقات التي تكون فيها Patterns صالحة، تصف هذه المكونات شكل البيانات. يقوم برنامجنا بعد ذلك بمطابقة القيم مع Patterns لتحديد ما إذا كانت تمتلك شكل البيانات الصحيح لمواصلة تشغيل جزء معين من الكود (Code).
لاستخدام Pattern، نقوم بمقارنته بقيمة ما. إذا تطابق Pattern مع القيمة، فإننا نستخدم أجزاء القيمة في Code الخاص بنا. تذكر تعبيرات match في الفصل 6 التي استخدمت Patterns، مثل مثال آلة فرز العملات المعدنية. إذا كانت القيمة تناسب شكل Pattern، فيمكننا استخدام الأجزاء المسماة. وإذا لم تكن كذلك، فلن يعمل Code المرتبط بـ Pattern.
هذا الفصل هو مرجع لكل ما يتعلق بـ Patterns. سنغطي الأماكن الصالحة لاستخدام Patterns، والفرق بين الأنماط القابلة للنقض (Refutable Patterns) وغير القابلة للنقض (Irrefutable Patterns)، والأنواع المختلفة لصيغ Patterns التي قد تراها. بنهاية الفصل، ستعرف كيفية استخدام Patterns للتعبير عن العديد من المفاهيم بطريقة واضحة.
جميع الأماكن التي يمكن استخدام الأنماط فيها
جميع الأماكن التي يمكن استخدام الأنماط (Patterns) فيها
تظهر الأنماط (Patterns) في عدد من الأماكن في Rust، وكنت تستخدمها كثيرًا دون أن تدرك ذلك! يناقش هذا القسم جميع الأماكن التي تكون فيها Patterns صالحة.
أذرع match (match arms)
كما نوقش في الفصل 6، نستخدم Patterns في أذرع match (match arms) لتعبيرات match (match expressions). رسميًا، يتم تعريف تعبيرات match على أنها الكلمة المفتاحية match، وقيمة للمطابقة عليها، وواحد أو أكثر من match arms التي تتكون من نمط (pattern) وتعبير (expression) يتم تشغيله إذا كانت القيمة تطابق pattern لهذا الذراع، مثل هذا:
match VALUE {
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
}على سبيل المثال، إليك تعبير match من القائمة 6-5 الذي يطابق قيمة Option<i32> في المتغير (variable) x:
match x {
None => None,
Some(i) => Some(i + 1),
}الـ Patterns في تعبير match هذا هي None و Some(i) على يسار كل سهم.
أحد متطلبات تعبيرات match هو أنها يجب أن تكون شاملة (exhaustive) بمعنى أنه يجب أخذ جميع الاحتمالات للقيمة في تعبير match في الاعتبار. إحدى الطرق لضمان تغطية كل الاحتمالات هي أن يكون لديك نمط شامل (catch-all pattern) للذراع الأخير: على سبيل المثال، اسم variable يطابق أي قيمة لا يمكن أن يفشل أبدًا وبالتالي يغطي كل حالة متبقية.
الـ pattern المحدد _ سيطابق أي شيء، ولكنه لا يرتبط أبدًا بـ variable، لذلك غالبًا ما يستخدم في ذراع match الأخير. يمكن أن يكون pattern _ مفيدًا عندما تريد تجاهل أي قيمة غير محددة، على سبيل المثال. سنغطي pattern _ بمزيد من التفصيل في “Ignoring Values in a Pattern” لاحقًا في هذا الفصل.
عبارات let (let statements)
قبل هذا الفصل، لم نناقش صراحةً استخدام Patterns إلا مع match و if let، ولكن في الواقع، استخدمنا Patterns في أماكن أخرى أيضًا، بما في ذلك في let statements. على سبيل المثال، ضع في اعتبارك تعيين متغير (variable assignment) المباشر هذا باستخدام let:
#![allow(unused)]
fn main() {
let x = 5;
}في كل مرة استخدمت فيها let statement كهذا، كنت تستخدم Patterns، على الرغم من أنك ربما لم تدرك ذلك! بشكل أكثر رسمية، تبدو let statement كما يلي:
let PATTERN = EXPRESSION;
في عبارات مثل let x = 5; مع اسم variable في خانة PATTERN، فإن اسم variable هو مجرد شكل بسيط بشكل خاص من pattern. يقارن Rust الـ expression بـ pattern ويعين أي أسماء يجدها. لذلك، في مثال let x = 5;، فإن x هو pattern يعني “اربط ما يطابق هنا بـ variable x.” نظرًا لأن اسم x هو pattern بأكمله، فإن هذا pattern يعني فعليًا “اربط كل شيء بـ variable x، مهما كانت القيمة.”
لرؤية جانب مطابقة الـ pattern لـ let بشكل أكثر وضوحًا، ضع في اعتبارك القائمة 19-1، التي تستخدم pattern مع let لـ تفكيك (destructure) صف (tuple).
fn main() {
let (x, y, z) = (1, 2, 3);
}هنا، نطابق tuple بـ pattern. يقارن Rust القيمة (1, 2, 3) بـ pattern (x, y, z) ويرى أن القيمة تطابق pattern - أي أنه يرى أن عدد العناصر هو نفسه في كليهما - لذلك يربط Rust 1 بـ x، و 2 بـ y، و 3 بـ z. يمكنك التفكير في pattern tuple هذا على أنه يتداخل فيه ثلاثة Patterns variable فردية.
إذا كان عدد العناصر في pattern لا يطابق عدد العناصر في tuple، فلن يتطابق النوع الكلي وسنحصل على خطأ المترجم (compiler error). على سبيل المثال، توضح القائمة 19-2 محاولة لـ destructure tuple بثلاثة عناصر إلى اثنين variables، وهو ما لن ينجح.
fn main() {
let (x, y) = (1, 2, 3);
}تؤدي محاولة تجميع هذا الكود إلى خطأ النوع هذا:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
لإصلاح الـ error، يمكننا تجاهل واحد أو أكثر من القيم في tuple باستخدام _ أو ..، كما سترى في قسم “Ignoring Values in a Pattern”. إذا كانت المشكلة هي أن لدينا عددًا كبيرًا جدًا من variables في pattern، فإن الحل هو جعل الأنواع متطابقة عن طريق إزالة variables بحيث يساوي عدد variables عدد العناصر في tuple.
تعبيرات if let الشرطية (if let expressions)
في الفصل 6، ناقشنا كيفية استخدام if let expressions بشكل أساسي كطريقة أقصر لكتابة ما يعادل match الذي يطابق حالة واحدة فقط. اختياريًا، يمكن أن تحتوي if let على else مطابق يحتوي على كود يتم تشغيله إذا لم يطابق pattern في if let.
توضح القائمة 19-3 أنه من الممكن أيضًا مزج ومطابقة تعبيرات if let و وإلا إذا (else if) و وإلا إذا كان (else if let). يمنحنا القيام بذلك مرونة أكبر من تعبير match الذي يمكننا فيه التعبير عن قيمة واحدة فقط للمقارنة مع Patterns. أيضًا، لا يتطلب Rust أن تكون الشروط في سلسلة من أذرع if let و else if و else if let مرتبطة ببعضها البعض.
يحدد الكود في القائمة 19-3 اللون الذي يجب أن يكون عليه الخلفية بناءً على سلسلة من عمليات التحقق لعدة شروط. لهذا المثال، أنشأنا variables بقيم مبرمجة (hardcoded) قد يتلقاها برنامج حقيقي من إدخال المستخدم.
fn main() {
let favorite_color: Option<&str> = None;
let is_tuesday = false;
let age: Result<u8, _> = "34".parse();
if let Some(color) = favorite_color {
println!("Using your favorite color, {color}, as the background");
} else if is_tuesday {
println!("Tuesday is green day!");
} else if let Ok(age) = age {
if age > 30 {
println!("Using purple as the background color");
} else {
println!("Using orange as the background color");
}
} else {
println!("Using blue as the background color");
}
}إذا حدد المستخدم لونًا مفضلاً، فسيتم استخدام هذا اللون كخلفية. إذا لم يتم تحديد لون مفضل وكان اليوم هو الثلاثاء، فسيكون لون الخلفية أخضر. بخلاف ذلك، إذا حدد المستخدم عمره كسلسلة نصية وتمكنا من تحليلها كرقم بنجاح، فسيكون اللون إما أرجوانيًا أو برتقاليًا اعتمادًا على قيمة الرقم. إذا لم تنطبق أي من هذه الشروط، فسيكون لون الخلفية أزرق.
تسمح لنا هذه البنية الشرطية بدعم المتطلبات المعقدة. مع القيم المبرمجة التي لدينا هنا، سيطبع هذا المثال Using purple as the background color.
يمكنك أن ترى أن if let يمكن أن يقدم أيضًا variables جديدة تقوم بـ التظليل (shadowing) لـ variables الموجودة بنفس الطريقة التي يمكن أن تفعلها match arms: السطر if let Ok(age) = age يقدم variable age جديدًا يحتوي على القيمة داخل متغير Ok، مما يقوم بـ shadowing لـ variable age الموجود. هذا يعني أننا بحاجة إلى وضع الشرط if age > 30 داخل تلك الكتلة: لا يمكننا دمج هذين الشرطين في if let Ok(age) = age && age > 30. الـ age الجديد الذي نريد مقارنته بـ 30 ليس صالحًا حتى يبدأ النطاق (scope) الجديد بالقوس المعقوف.
الجانب السلبي لاستخدام if let expressions هو أن الـ compiler لا يتحقق من الشمولية (exhaustiveness)، بينما يتحقق منها مع تعبيرات match. إذا حذفنا كتلة else الأخيرة وبالتالي فاتنا التعامل مع بعض الحالات، فلن ينبهنا الـ compiler إلى خطأ المنطق المحتمل.
حلقة شرطية while let (while let conditional loop)
تسمح حلقة شرطية while let، المشابهة في البناء لـ if let، لحلقة while بالاستمرار في العمل طالما استمر pattern في المطابقة. في القائمة 19-4، نعرض حلقة while let تنتظر الرسائل المرسلة بين الخيوط (threads)، ولكن في هذه الحالة تتحقق من نتيجة (Result) بدلاً من خيار (Option).
fn main() {
let (tx, rx) = std::sync::mpsc::channel();
std::thread::spawn(move || {
for val in [1, 2, 3] {
tx.send(val).unwrap();
}
});
while let Ok(value) = rx.recv() {
println!("{value}");
}
}يطبع هذا المثال 1 و 2 ثم 3. دالة recv (recv method) تأخذ الرسالة الأولى من جانب المستقبل للقناة وتُرجع موافق (Ok(value)). عندما رأينا recv لأول مرة في الفصل 16، قمنا بفك خطأ (error) مباشرة، أو تفاعلنا معه كمكرر (iterator) باستخدام حلقة for (for loop). كما توضح القائمة 19-4، يمكننا أيضًا استخدام while let، لأن دالة recv تُرجع Ok في كل مرة تصل فيها رسالة، طالما أن المرسل موجود، ثم تنتج خطأ (Err) بمجرد قطع اتصال جانب المرسل.
حلقة for (for loop)
في for loop، القيمة التي تتبع الكلمة المفتاحية for مباشرة هي pattern. على سبيل المثال، في for x in y، فإن x هو pattern. توضح القائمة 19-5 كيفية استخدام pattern في for loop لـ destructure، أو تفكيك، tuple كجزء من for loop.
fn main() {
let v = vec!['a', 'b', 'c'];
for (index, value) in v.iter().enumerate() {
println!("{value} is at index {index}");
}
}سيطبع الكود في القائمة 19-5 ما يلي:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a is at index 0
b is at index 1
c is at index 2
نقوم بتكييف iterator باستخدام دالة enumerate (enumerate method) بحيث تنتج قيمة وفهرسًا لتلك القيمة، موضوعة في tuple. القيمة الأولى المنتجة هي tuple (0, 'a'). عندما تتم مطابقة هذه القيمة مع pattern (index, value)، سيكون index هو 0 و value هو 'a'، مما يطبع السطر الأول من الإخراج.
معاملات الدالة (Function Parameters)
يمكن أن تكون معاملات الدالة (Function Parameters) أيضًا Patterns. يجب أن يبدو الكود في القائمة 19-6، الذي يعلن عن دالة تسمى foo تأخذ معاملًا واحدًا يسمى x من النوع i32، مألوفًا الآن.
fn foo(x: i32) {
// code goes here
}
fn main() {}الجزء x هو pattern! كما فعلنا مع let، يمكننا مطابقة tuple في وسائط الدالة بـ pattern. تقسم القائمة 19-7 القيم في tuple أثناء تمريرها إلى دالة.
fn print_coordinates(&(x, y): &(i32, i32)) {
println!("Current location: ({x}, {y})");
}
fn main() {
let point = (3, 5);
print_coordinates(&point);
}يطبع هذا الكود Current location: (3, 5). القيم &(3, 5) تطابق pattern &(x, y)، لذا فإن x هي القيمة 3 و y هي القيمة 5.
يمكننا أيضًا استخدام Patterns في قوائم معاملات الإغلاق (closure) بنفس طريقة قوائم Function Parameters لأن closures تشبه الدوال، كما نوقش في الفصل 13.
في هذه المرحلة، رأيت عدة طرق لاستخدام Patterns، ولكن Patterns لا تعمل بنفس الطريقة في كل مكان يمكننا استخدامها فيه. في بعض الأماكن، يجب أن تكون Patterns غير قابلة للدحض (irrefutable)؛ في ظروف أخرى، يمكن أن تكون قابلة للدحض (refutable). سنناقش هذين المفهومين لاحقًا.
القابلية للدحض: ما إذا كان النمط قد يفشل في المطابقة (Refutability)
قابلية النقض: عندما قد يفشل النمط في المطابقة (Refutability: Whether a Pattern Might Fail to Match)
تأتي الأنماط (Patterns) في شكلين: قابلة للنقض (Refutable) وغير قابلة للنقض (Irrefutable). الأنماط التي ستطابق أي قيمة محتملة يتم تمريرها هي أنماط Irrefutable. مثال على ذلك سيكون x في العبارة let x = 5; لأن x يطابق أي شيء وبالتالي لا يمكن أن يفشل في المطابقة. أما الأنماط التي يمكن أن تفشل في المطابقة لبعض القيم المحتملة فهي أنماط Refutable. مثال على ذلك سيكون Some(x) في التعبير if let Some(x) = a_value لأنه إذا كانت القيمة في المتغير (Variable) a_value هي None بدلاً من Some ، فإن نمط Some(x) لن يطابق.
يمكن لوسائط الدوال (Function Parameters)، وعبارات let ، وحلقات (Loops) الـ for أن تقبل فقط Patterns من نوع Irrefutable لأن البرنامج لا يمكنه فعل أي شيء ذي معنى عندما لا تتطابق القيم. تقبل تعبيرات if let و while let وعبارة let...else كلاً من Patterns الـ Refutable والـ Irrefutable، لكن المترجم (Compiler) يحذر من استخدام Irrefutable Patterns لأنها، بحكم تعريفها، مخصصة للتعامل مع الفشل المحتمل: تكمن وظيفة الشرط في قدرته على الأداء بشكل مختلف اعتماداً على النجاح أو الفشل.
بشكل عام، لا ينبغي أن تقلق بشأن التمييز بين Refutable Patterns و Irrefutable Patterns؛ ومع ذلك، فأنت بحاجة إلى التعرف على مفهوم قابلية النقض (Refutability) حتى تتمكن من الاستجابة عندما تراها في رسالة خطأ. في تلك الحالات، ستحتاج إلى تغيير إما Pattern أو البنية التي تستخدم Pattern معها، اعتماداً على السلوك المقصود من الكود (Code).
دعونا نلقي نظرة على مثال لما يحدث عندما نحاول استخدام Refutable Pattern حيث تتطلب لغة Rust استخدام Irrefutable Pattern والعكس صحيح. توضح القائمة (Listing) 19-8 عبارة let ، ولكن بالنسبة لـ Pattern ، فقد حددنا Some(x) ، وهو Refutable Pattern. وكما قد تتوقع، لن يتم تحويل هذا الكود برمجياً (Compile).
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value;
}إذا كانت some_option_value قيمة None ، فستفشل في مطابقة Pattern Some(x) ، مما يعني أن Pattern هو Refutable. ومع ذلك، يمكن لعبارة let أن تقبل فقط Irrefutable Pattern لأنه لا يوجد شيء صالح يمكن لـ Code القيام به مع قيمة None. في وقت التحويل البرمجي (Compile Time)، ستشتكي Rust من أننا حاولنا استخدام Refutable Pattern حيث يلزم استخدام Irrefutable Pattern:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch19-02-refutability.html
= note: the matched value is of type `Option<i32>`
help: you might want to use `let else` to handle the variant that isn't matched
|
3 | let Some(x) = some_option_value else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
لأننا لم نغطِ (ولم نتمكن من تغطية!) كل قيمة صالحة باستخدام Pattern Some(x) ، فإن Rust تنتج بشكل محق خطأ في Compiler.
إذا كان لدينا Refutable Pattern حيث يلزم وجود Irrefutable Pattern ، فيمكننا إصلاح ذلك عن طريق تغيير Code الذي يستخدم Pattern: بدلاً من استخدام let ، يمكننا استخدام let...else. بعد ذلك، إذا لم يتطابق Pattern ، فسيقوم Code الموجود بين الأقواس المتعرجة بالتعامل مع القيمة. توضح Listing 19-9 كيفية إصلاح Code في Listing 19-8.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value else {
return;
};
}لقد أعطينا لـ Code مخرجاً! هذا الكود صالح تماماً، على الرغم من أنه يعني أننا لا نستطيع استخدام Irrefutable Pattern دون تلقي تحذير. إذا أعطينا let...else نمطاً سيطابق دائماً، مثل x ، كما هو موضح في Listing 19-10، فسيقوم Compiler بإعطاء تحذير.
fn main() {
let x = 5 else {
return;
};
}تشتكي Rust من أنه ليس من المنطقي استخدام let...else مع Irrefutable Pattern:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `let...else` pattern
--> src/main.rs:2:5
|
2 | let x = 5 else {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `else` clause is useless
= help: consider removing the `else` clause
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
لهذا السبب، يجب أن تستخدم أذرع المطابقة (Match Arms) أنماطاً من نوع Refutable ، باستثناء الذراع الأخير، الذي يجب أن يطابق أي قيم متبقية باستخدام Irrefutable Pattern. تسمح لنا Rust باستخدام Irrefutable Pattern في match بذراع واحد فقط، لكن هذه الصيغة ليست مفيدة بشكل خاص ويمكن استبدالها بعبارة let أبسط.
الآن بعد أن عرفت أين تستخدم Patterns والفرق بين Refutable Patterns و Irrefutable Patterns ، فلنغطِ كل الصيغ التي يمكننا استخدامها لإنشاء Patterns.
بناء جملة الأنماط (Pattern Syntax)
بناء جملة الأنماط (Pattern Syntax)
في هذا القسم، نجمع كل بناء الجملة (syntax) الصالح في الأنماط (patterns) ونناقش سبب وموعد رغبتك في استخدام كل منها.
مطابقة القيم الحرفية (Matching Literals)
كما رأيت في الفصل السادس، يمكنك مطابقة الأنماط مع القيم الحرفية (literals) مباشرة. يوفر الكود التالي بعض الأمثلة:
fn main() {
let x = 1;
match x {
1 => println!("one"),
2 => println!("two"),
3 => println!("three"),
_ => println!("anything"),
}
}يطبع هذا الكود one لأن القيمة في x هي 1. هذا syntax مفيد عندما تريد أن يتخذ الكود الخاص بك إجراءً إذا حصل على قيمة ملموسة (concrete value) معينة.
مطابقة المتغيرات المسماة (Matching Named Variables)
المتغيرات المسماة (Named variables) هي أنماط غير قابلة للدحض (irrefutable patterns) تطابق أي قيمة، وقد استخدمناها عدة مرات في هذا الكتاب. ومع ذلك، هناك تعقيد عند استخدام المتغيرات المسماة في تعبيرات match أو if let أو while let. نظرًا لأن كل نوع من هذه التعبيرات يبدأ نطاقاً (scope) جديداً، فإن المتغيرات المعلن عنها كجزء من نمط داخل هذه التعبيرات ستظلل (shadow) تلك التي لها نفس الاسم خارج هذه البنيات، كما هو الحال مع جميع المتغيرات. في القائمة 19-11، نعلن عن متغير باسم x بقيمة Some(5) ومتغير y بقيمة 10. ثم ننشئ تعبير match على القيمة x. انظر إلى الأنماط في أذرع المطابقة (match arms) و println! في النهاية، وحاول معرفة ما سيطبعه الكود قبل تشغيل هذا الكود أو القراءة أكثر.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(y) => println!("Matched, y = {y}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}دعونا نستعرض ما يحدث عند تشغيل تعبير match. النمط في ذراع المطابقة الأول لا يطابق القيمة المحددة لـ x ، لذا يستمر الكود.
يقدم النمط في ذراع المطابقة الثاني متغيراً جديداً باسم y سيطابق أي قيمة داخل قيمة Some. نظرًا لأننا في scope جديد داخل تعبير match ، فهذا متغير y جديد، وليس y الذي أعلنا عنه في البداية بالقيمة 10. سيطابق ربط (binding) y الجديد هذا أي قيمة داخل Some ، وهو ما لدينا في x. لذلك، يرتبط y الجديد هذا بالقيمة الداخلية لـ Some في x. تلك القيمة هي 5 ، لذا يتم تنفيذ التعبير لهذا الذراع ويطبع Matched, y = 5.
إذا كانت x قيمة None بدلاً من Some(5) ، فلن تتطابق الأنماط في أول ذراعين، لذا كانت القيمة ستتطابق مع الشرطة السفلية (underscore). لم نقدم المتغير x في نمط ذراع underscore، لذا فإن x في التعبير لا يزال هو x الخارجي الذي لم يتم تظليله. في هذه الحالة الافتراضية، سيطبع match عبارة Default case, x = None.
عندما ينتهي تعبير match ، ينتهي نطاقه، وكذلك ينتهي نطاق y الداخلي. ينتج println! الأخير at the end: x = Some(5), y = 10.
لإنشاء تعبير match يقارن قيم x و y الخارجية، بدلاً من تقديم متغير جديد يظلل متغير y الموجود، سنحتاج إلى استخدام حارس مطابقة (match guard) شرطي بدلاً من ذلك. سنتحدث عن match guards لاحقاً في قسم “إضافة شروط باستخدام حراس المطابقة”.
مطابقة أنماط متعددة (Matching Multiple Patterns)
في تعبيرات match ، يمكنك مطابقة أنماط متعددة باستخدام syntax المسمى | ، وهو عامل “أو” (or operator) للأنماط. على سبيل المثال، في الكود التالي، نطابق قيمة x مع match arms، أولها يحتوي على خيار أو ، مما يعني أنه إذا كانت قيمة x تطابق أيًا من القيمتين في ذلك الذراع، فسيتم تشغيل كود ذلك الذراع:
fn main() {
let x = 1;
match x {
1 | 2 => println!("one or two"),
3 => println!("three"),
_ => println!("anything"),
}
}يطبع هذا الكود one or two.
مطابقة نطاقات من القيم باستخدام ..= (Matching Ranges of Values with ..=)
يسمح لنا syntax المسمى ..= بالمطابقة مع نطاق شامل (inclusive range) من القيم. في الكود التالي، عندما يطابق نمط أيًا من القيم ضمن النطاق المحدد، سيتم تنفيذ ذلك الذراع:
fn main() {
let x = 5;
match x {
1..=5 => println!("one through five"),
_ => println!("something else"),
}
}إذا كانت x هي 1 أو 2 أو 3 أو 4 أو 5 ، فسيتم مطابقة الذراع الأول. هذا syntax أكثر ملاءمة لقيم مطابقة متعددة من استخدام عامل | للتعبير عن نفس الفكرة؛ إذا أردنا استخدام | ، فسنضطر إلى تحديد 1 | 2 | 3 | 4 | 5. تحديد النطاق (range) أقصر بكثير، خاصة إذا أردنا مطابقة، على سبيل المثال، أي رقم بين 1 و 1000!
يتحقق compiler من أن النطاق ليس فارغاً في وقت التصريف (compile time)، ولأن الأنواع الوحيدة التي يمكن لـ Rust معرفة ما إذا كان النطاق فارغاً أم لا هي char والقيم الرقمية، فإن النطاقات مسموح بها فقط مع القيم الرقمية أو char.
إليك مثال باستخدام نطاقات من قيم char:
fn main() {
let x = 'c';
match x {
'a'..='j' => println!("early ASCII letter"),
'k'..='z' => println!("late ASCII letter"),
_ => println!("something else"),
}
}يمكن لـ Rust معرفة أن 'c' تقع ضمن نطاق النمط الأول وتطبع early ASCII letter.
التفكيك لتقسيم القيم (Destructuring to Break Apart Values)
يمكننا أيضاً استخدام الأنماط لتفكيك (destructure) الهياكل (structs) والتعدادات (enums) والصفوف (tuples) لاستخدام أجزاء مختلفة من هذه القيم. دعونا نستعرض كل قيمة.
الهياكل (Structs)
توضح القائمة 19-12 هيكلاً يسمى Point مع حقلين، x و y ، يمكننا تفكيكهما باستخدام نمط مع عبارة let.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x: a, y: b } = p;
assert_eq!(0, a);
assert_eq!(7, b);
}ينشئ هذا الكود المتغيرين a و b اللذين يطابقان قيم الحقلين x و y للهيكل p. يوضح هذا المثال أن أسماء المتغيرات في النمط لا يجب أن تطابق أسماء الحقول في struct. ومع ذلك، فمن الشائع مطابقة أسماء المتغيرات مع أسماء الحقول لتسهيل تذكر المتغيرات التي جاءت من أي حقول. وبسبب هذا الاستخدام الشائع، ولأن كتابة let Point { x: x, y: y } = p; تحتوي على الكثير من التكرار، فإن Rust لديها اختصار للأنماط التي تطابق حقول struct: ما عليك سوى إدراج اسم حقل struct، وستكون للمتغيرات التي تم إنشاؤها من النمط نفس الأسماء. تتصرف القائمة 19-13 بنفس طريقة الكود في القائمة 19-12، ولكن المتغيرات التي تم إنشاؤها في نمط let هي x و y بدلاً من a و b.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x, y } = p;
assert_eq!(0, x);
assert_eq!(7, y);
}ينشئ هذا الكود المتغيرين x و y اللذين يطابقان الحقلين x و y للمتغير p. والنتيجة هي أن المتغيرين x و y يحتويان على القيم من الهيكل p.
يمكننا أيضاً التفكيك باستخدام قيم حرفية كجزء من نمط struct بدلاً من إنشاء متغيرات لجميع الحقول. القيام بذلك يسمح لنا باختبار بعض الحقول لقيم معينة مع إنشاء متغيرات لتفكيك الحقول الأخرى.
في القائمة 19-14، لدينا تعبير match يفصل قيم Point إلى ثلاث حالات: النقاط التي تقع مباشرة على محور x (وهو ما يكون صحيحاً عندما يكون y = 0) ، أو على محور y (x = 0) ، أو لا تقع على أي من المحورين.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
match p {
Point { x, y: 0 } => println!("On the x axis at {x}"),
Point { x: 0, y } => println!("On the y axis at {y}"),
Point { x, y } => {
println!("On neither axis: ({x}, {y})");
}
}
}سيطابق الذراع الأول أي نقطة تقع على محور x من خلال تحديد أن حقل y يطابق إذا كانت قيمته تطابق القيمة الحرفية 0. لا يزال النمط ينشئ متغيراً x يمكننا استخدامه في الكود لهذا الذراع.
وبالمثل، يطابق الذراع الثاني أي نقطة على محور y من خلال تحديد أن حقل x يطابق إذا كانت قيمته 0 وينشئ متغيراً y لقيمة حقل y. لا يحدد الذراع الثالث أي قيم حرفية، لذا فهو يطابق أي Point أخرى وينشئ متغيرات لكل من الحقلين x و y.
في هذا المثال، تطابق القيمة p الذراع الثاني بحكم احتواء x على 0 ، لذا سيطبع هذا الكود On the y axis at 7.
تذكر أن تعبير match يتوقف عن فحص الأذرع بمجرد العثور على أول نمط مطابق، لذا على الرغم من أن Point { x: 0, y: 0 } تقع على محور x ومحور y ، فإن هذا الكود سيطبع فقط On the x axis at 0.
التعدادات (Enums)
لقد قمنا بتفكيك التعدادات (enums) في هذا الكتاب (على سبيل المثال، القائمة 6-5 في الفصل السادس)، لكننا لم نناقش صراحة بعد أن النمط لتفكيك enum يتوافق مع الطريقة التي يتم بها تعريف البيانات المخزنة داخل enum. كمثال، في القائمة 19-15، نستخدم التعداد Message من القائمة 6-2 ونكتب match مع أنماط تفكك كل قيمة داخلية.
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let msg = Message::ChangeColor(0, 160, 255);
match msg {
Message::Quit => {
println!("The Quit variant has no data to destructure.");
}
Message::Move { x, y } => {
println!("Move in the x direction {x} and in the y direction {y}");
}
Message::Write(text) => {
println!("Text message: {text}");
}
Message::ChangeColor(r, g, b) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
}
}سيطبع هذا الكود Change color to red 0, green 160, and blue 255. حاول تغيير قيمة msg لرؤية الكود من الأذرع الأخرى يعمل.
بالنسبة لمتغيرات التعداد (enum variants) التي لا تحتوي على أي بيانات، مثل Message::Quit ، لا يمكننا تفكيك القيمة أكثر من ذلك. يمكننا فقط المطابقة على قيمة Message::Quit الحرفية، ولا توجد متغيرات في ذلك النمط.
بالنسبة لمتغيرات التعداد الشبيهة بالهياكل (struct-like enum variants)، مثل Message::Move ، يمكننا استخدام نمط مشابه للنمط الذي نحدده لمطابقة structs. بعد اسم variant، نضع أقواساً متعرجة ثم ندرج الحقول مع المتغيرات بحيث نقسم الأجزاء لاستخدامها في الكود لهذا الذراع. هنا نستخدم الصيغة المختصرة كما فعلنا في القائمة 19-13.
بالنسبة لمتغيرات التعداد الشبيهة بالصفوف (tuple-like enum variants)، مثل Message::Write التي تحمل صفاً (tuple) بعنصر واحد و Message::ChangeColor التي تحمل tuple بثلاثة عناصر، فإن النمط مشابه للنمط الذي نحدده لمطابقة tuples. يجب أن يتطابق عدد المتغيرات في النمط مع عدد العناصر في variant الذي نطابقه.
الهياكل والتعدادات المتداخلة (Nested Structs and Enums)
حتى الآن، كانت جميع أمثلتنا تطابق structs أو enums بعمق مستوى واحد، ولكن المطابقة يمكن أن تعمل على العناصر المتداخلة (nested items) أيضاً! على سبيل المثال، يمكننا إعادة بناء الرسالة، كما هو موضح في القائمة 19-16.
enum Color {
Rgb(i32, i32, i32),
Hsv(i32, i32, i32),
}
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(Color),
}
fn main() {
let msg = Message::ChangeColor(Color::Hsv(0, 160, 255));
match msg {
Message::ChangeColor(Color::Rgb(r, g, b)) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
Message::ChangeColor(Color::Hsv(h, s, v)) => {
println!("Change color to hue {h}, saturation {s}, value {v}");
}
_ => (),
}
}يطابق نمط الذراع الأول في تعبير match متغير التعداد Message::ChangeColor الذي يحتوي على متغير Color::Rgb ؛ ثم يرتبط النمط بقيم i32 الثلاث الداخلية. يطابق نمط الذراع الثاني أيضاً متغير التعداد Message::ChangeColor ، لكن التعداد الداخلي يطابق Color::Hsv بدلاً من ذلك. يمكننا تحديد هذه الشروط المعقدة في تعبير match واحد، على الرغم من مشاركة تعدادين.
الهياكل والصفوف (Structs and Tuples)
يمكننا خلط ومطابقة وتداخل أنماط التفكيك بطرق أكثر تعقيداً. يوضح المثال التالي تفكيكاً معقداً حيث نقوم بتداخل structs و tuples داخل tuple ونقوم بتفكيك جميع القيم الأولية (primitive values) منها:
fn main() {
struct Point {
x: i32,
y: i32,
}
let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 });
}يتيح لنا هذا الكود تقسيم الأنواع المعقدة إلى أجزائها المكونة حتى نتمكن من استخدام القيم التي نهتم بها بشكل منفصل.
التفكيك باستخدام الأنماط هو وسيلة مريحة لاستخدام أجزاء من القيم، مثل القيمة من كل حقل في struct، بشكل منفصل عن بعضها البعض.
تجاهل القيم في النمط (Ignoring Values in a Pattern)
لقد رأيت أنه من المفيد أحياناً تجاهل القيم في النمط، كما هو الحال في الذراع الأخير من match ، للحصول على حالة شاملة (catch-all) لا تفعل شيئاً في الواقع ولكنها تأخذ في الاعتبار جميع القيم الممكنة المتبقية. هناك عدة طرق لتجاهل قيم كاملة أو أجزاء من القيم في النمط: استخدام نمط _ (الذي رأيته)، أو استخدام نمط _ داخل نمط آخر، أو استخدام اسم يبدأ بشرطة سفلية، أو استخدام .. لتجاهل الأجزاء المتبقية من القيمة. دعونا نستكشف كيفية وسبب استخدام كل من هذه الأنماط.
قيمة كاملة باستخدام _ (An Entire Value with _)
لقد استخدمنا underscore كنمط بدل (wildcard pattern) يطابق أي قيمة ولكنه لا يرتبط بالقيمة. هذا مفيد بشكل خاص كذراع أخير في تعبير match ، ولكن يمكننا أيضاً استخدامه في أي نمط، بما في ذلك معاملات الدوال (function parameters)، كما هو موضح في القائمة 19-17.
fn foo(_: i32, y: i32) {
println!("This code only uses the y parameter: {y}");
}
fn main() {
foo(3, 4);
}سيتجاهل هذا الكود تماماً القيمة 3 الممرة كمعامل أول، وسيطبع This code only uses the y parameter: 4.
في معظم الحالات عندما لا تعود بحاجة إلى معامل دالة معين، فإنك ستقوم بتغيير التوقيع (signature) بحيث لا يتضمن المعامل غير المستخدم. يمكن أن يكون تجاهل معامل الدالة مفيداً بشكل خاص في حالات مثل تنفيذ trait عندما تحتاج إلى signature معين ولكن جسم الدالة في تنفيذك لا يحتاج إلى أحد المعاملات. عندها تتجنب الحصول على تحذير من compiler حول معاملات الدوال غير المستخدمة، كما سيحدث إذا استخدمت اسماً بدلاً من ذلك.
أجزاء من القيمة باستخدام _ المتداخلة (Parts of a Value with a Nested _)
يمكننا أيضاً استخدام _ داخل نمط آخر لتجاهل جزء فقط من القيمة، على سبيل المثال، عندما نريد اختبار جزء فقط من القيمة ولكن ليس لدينا استخدام للأجزاء الأخرى في الكود المقابل الذي نريد تشغيله. توضح القائمة 19-18 كوداً مسؤولاً عن إدارة قيمة إعداد ما. متطلبات العمل هي أنه لا ينبغي السماح للمستخدم بإلغاء تخصيص موجود لإعداد ما، ولكن يمكنه إلغاء ضبط الإعداد وإعطاؤه قيمة إذا كان غير مضبوط حالياً.
fn main() {
let mut setting_value = Some(5);
let new_setting_value = Some(10);
match (setting_value, new_setting_value) {
(Some(_), Some(_)) => {
println!("Can't overwrite an existing customized value");
}
_ => {
setting_value = new_setting_value;
}
}
println!("setting is {setting_value:?}");
}سيطبع هذا الكود Can't overwrite an existing customized value ثم setting is Some(5). في ذراع المطابقة الأول، لا نحتاج إلى المطابقة على القيم داخل أي من متغيري Some أو استخدامها، ولكننا نحتاج إلى اختبار الحالة عندما يكون setting_value و new_setting_value هما متغير Some. في هذه الحالة، نطبع سبب عدم تغيير setting_value ، ولا يتم تغييرها.
في جميع الحالات الأخرى (إذا كان أي من setting_value أو new_setting_value هو None) المعبر عنها بنمط _ في الذراع الثاني، نريد السماح لـ new_setting_value بأن تصبح setting_value.
يمكننا أيضاً استخدام underscores في أماكن متعددة داخل نمط واحد لتجاهل قيم معينة. توضح القائمة 19-19 مثالاً لتجاهل القيمتين الثانية والرابعة في tuple مكون من خمسة عناصر.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, _, third, _, fifth) => {
println!("Some numbers: {first}, {third}, {fifth}");
}
}
}سيطبع هذا الكود Some numbers: 2, 8, 32 ، وسيتم تجاهل القيمتين 4 و 16.
متغير غير مستخدم ببدء اسمه بـ _ (An Unused Variable by Starting Its Name with _)
إذا أنشأت متغيراً ولكنك لم تستخدمه في أي مكان، فسيصدر Rust عادةً تحذيراً لأن المتغير غير المستخدم قد يكون خطأً برمجياً (bug). ومع ذلك، أحياناً يكون من المفيد أن تكون قادراً على إنشاء متغير لن تستخدمه بعد، كما هو الحال عند عمل نموذج أولي (prototyping) أو مجرد بدء مشروع. في هذه الحالة، يمكنك إخبار Rust بعدم تحذيرك بشأن المتغير غير المستخدم عن طريق بدء اسم المتغير بشرطة سفلية. في القائمة 19-20، ننشئ متغيرين غير مستخدمين، ولكن عندما نقوم بتصريف هذا الكود، يجب أن نحصل فقط على تحذير بشأن أحدهما.
fn main() {
let _x = 5;
let y = 10;
}هنا، نحصل على تحذير بشأن عدم استخدام المتغير y ، لكننا لا نحصل على تحذير بشأن عدم استخدام _x.
لاحظ أن هناك فرقاً دقيقاً بين استخدام _ فقط واستخدام اسم يبدأ بشرطة سفلية. syntax المسمى _x لا يزال يربط القيمة بالمتغير، بينما _ لا يربط على الإطلاق. لإظهار حالة يكون فيها هذا التمييز مهماً، ستوفر لنا القائمة 19-21 خطأً.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{s:?}");
}سنتلقى خطأً لأن قيمة s ستظل تُنقل إلى _s ، مما يمنعنا من استخدام s مرة أخرى. ومع ذلك، فإن استخدام underscore بمفرده لا يرتبط أبداً بالقيمة. سيتم تصريف القائمة 19-22 دون أي أخطاء لأن s لا يتم نقلها إلى _.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_) = s {
println!("found a string");
}
println!("{s:?}");
}يعمل هذا الكود بشكل جيد لأننا لا نربط s بأي شيء؛ فهي لا تُنقل.
الأجزاء المتبقية من القيمة باستخدام .. (Remaining Parts of a Value with ..)
مع القيم التي تحتوي على أجزاء كثيرة، يمكننا استخدام syntax المسمى .. لاستخدام أجزاء محددة وتجاهل الباقي، وتجنب الحاجة إلى إدراج underscores لكل قيمة متجاهلة. يتجاهل النمط .. أي أجزاء من القيمة لم نقم بمطابقتها صراحة في بقية النمط. في القائمة 19-23، لدينا struct يسمى Point يحمل إحداثيات في فضاء ثلاثي الأبعاد. في تعبير match ، نريد العمل فقط على إحداثي x وتجاهل القيم في الحقلين y و z.
fn main() {
struct Point {
x: i32,
y: i32,
z: i32,
}
let origin = Point { x: 0, y: 0, z: 0 };
match origin {
Point { x, .. } => println!("x is {x}"),
}
}ندرج قيمة x ثم نضمن فقط النمط ... هذا أسرع من الاضطرار إلى إدراج y: _ و z: _ ، خاصة عندما نعمل مع structs تحتوي على الكثير من الحقول في المواقف التي يكون فيها حقل واحد أو حقلان فقط هما المهمان.
سيتوسع syntax المسمى .. إلى أكبر عدد يحتاجه من القيم. توضح القائمة 19-24 كيفية استخدام .. مع tuple.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, .., last) => {
println!("Some numbers: {first}, {last}");
}
}
}في هذا الكود، يتم مطابقة القيمتين الأولى والأخيرة مع first و last. سيطابق .. ويتجاهل كل شيء في المنتصف.
ومع ذلك، يجب أن يكون استخدام .. غير غامض (unambiguous). إذا كان من غير الواضح أي القيم مخصصة للمطابقة وأيها يجب تجاهلها، فسيقوم Rust بإعطائنا خطأً. توضح القائمة 19-25 مثالاً لاستخدام .. بشكل غامض، لذا لن يتم تصريفه.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {second}")
},
}
}عندما نقوم بتصريف هذا المثال، نحصل على هذا الخطأ:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` (bin "patterns") due to 1 previous error
من المستحيل على Rust تحديد عدد القيم في tuple التي يجب تجاهلها قبل مطابقة قيمة مع second ثم عدد القيم الإضافية التي يجب تجاهلها بعد ذلك. قد يعني هذا الكود أننا نريد تجاهل 2 ، وربط second بـ 4 ، ثم تجاهل 8 و 16 و 32 ؛ أو أننا نريد تجاهل 2 و 4 ، وربط second بـ 8 ، ثم تجاهل 16 و 32 ؛ وهكذا دواليك. اسم المتغير second لا يعني أي شيء خاص لـ Rust، لذا نحصل على خطأ من compiler لأن استخدام .. في مكانين مثل هذا أمر غامض.
إضافة شروط إضافية باستخدام حراس المطابقة (Adding Conditionals with Match Guards)
حارس المطابقة (match guard) هو شرط if إضافي، يتم تحديده بعد النمط في ذراع match ، والذي يجب أن يتطابق أيضاً ليتم اختيار ذلك الذراع. تعد match guards مفيدة للتعبير عن أفكار أكثر تعقيداً مما يسمح به النمط وحده. لاحظ، مع ذلك، أنها متاحة فقط في تعبيرات match ، وليس في تعبيرات if let أو while let.
يمكن للشرط استخدام المتغيرات التي تم إنشاؤها في النمط. توضح القائمة 19-26 تعبير match حيث يحتوي الذراع الأول على النمط Some(x) ويحتوي أيضاً على match guard وهو if x % 2 == 0 (والذي سيكون true إذا كان الرقم زوجياً).
fn main() {
let num = Some(4);
match num {
Some(x) if x % 2 == 0 => println!("The number {x} is even"),
Some(x) => println!("The number {x} is odd"),
None => (),
}
}سيطبع هذا المثال The number 4 is even. عندما تتم مقارنة num بالنمط في الذراع الأول، فإنه يتطابق لأن Some(4) تطابق Some(x). ثم
لأنها كذلك، يتم اختيار الذراع الأول.
إذا كانت num هي Some(5) بدلاً من ذلك، فسيكون match guard في الذراع الأول false لأن باقي قسمة 5 على 2 هو 1، وهو لا يساوي 0. سينتقل Rust بعد ذلك إلى الذراع الثاني، والذي سيطابق لأن الذراع الثاني لا يحتوي على match guard وبالتالي يطابق أي متغير Some.
لا توجد طريقة للتعبير عن شرط if x % 2 == 0 داخل نمط، لذا فإن match guard يمنحنا القدرة على التعبير عن هذا المنطق. الجانب السلبي لهذه القدرة التعبيرية الإضافية هو أن compiler لا يحاول التحقق من الشمولية (exhaustiveness) عند استخدام تعبيرات match guard.
عند مناقشة القائمة 19-11، ذكرنا أنه يمكننا استخدام match guards لحل مشكلة تظليل الأنماط (pattern-shadowing). تذكر أننا أنشأنا متغيراً جديداً داخل النمط في تعبير match بدلاً من استخدام المتغير خارج match. كان ذلك المتغير الجديد يعني أننا لا نستطيع الاختبار مقابل قيمة المتغير الخارجي. توضح القائمة 19-27 كيف يمكننا استخدام match guard لإصلاح هذه المشكلة.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(n) if n == y => println!("Matched, n = {n}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}سيطبع هذا الكود الآن Default case, x = Some(5). النمط في ذراع المطابقة الثاني لا يقدم متغيراً جديداً y من شأنه أن يظلل y الخارجي، مما يعني أنه يمكننا استخدام y الخارجي في match guard. بدلاً من تحديد النمط كـ Some(y) ، والذي كان سيظلل y الخارجي، نحدد Some(n). يؤدي هذا إلى إنشاء متغير جديد n لا يظلل أي شيء لأنه لا يوجد متغير n خارج match.
حارس المطابقة if n == y ليس نمطاً وبالتالي لا يقدم متغيرات جديدة. هذا الـ y هو y الخارجي بدلاً من y جديد يظلله، ويمكننا البحث عن قيمة لها نفس قيمة y الخارجي من خلال مقارنة n بـ y.
يمكنك أيضاً استخدام عامل أو | في match guard لتحديد أنماط متعددة؛ سيتم تطبيق شرط match guard على جميع الأنماط. توضح القائمة 19-28 الأسبقية (precedence) عند الجمع بين نمط يستخدم | مع match guard. الجزء المهم من هذا المثال هو أن match guard المسمى if y ينطبق على 4 و 5 و 6 ، على الرغم من أنه قد يبدو أن if y ينطبق فقط على 6.
fn main() {
let x = 4;
let y = false;
match x {
4 | 5 | 6 if y => println!("yes"),
_ => println!("no"),
}
}ينص شرط المطابقة على أن الذراع يطابق فقط إذا كانت قيمة x تساوي 4 أو 5 أو 6 و إذا كانت y هي true. عندما يتم تشغيل هذا الكود، يطابق نمط الذراع الأول لأن x هي 4 ، ولكن match guard المسمى if y هو false ، لذا لا يتم اختيار الذراع الأول. ينتقل الكود إلى الذراع الثاني، الذي يطابق، ويطبع هذا البرنامج no. والسبب هو أن شرط if ينطبق على النمط بالكامل 4 | 5 | 6 ، وليس فقط على القيمة الأخيرة 6. بعبارة أخرى، تتصرف أسبقية match guard فيما يتعلق بالنمط على النحو التالي:
(4 | 5 | 6) if y => ...
بدلاً من هذا:
4 | 5 | (6 if y) => ...
بعد تشغيل الكود، يظهر سلوك الأسبقية بوضوح: إذا تم تطبيق match guard فقط على القيمة النهائية في قائمة القيم المحددة باستخدام عامل | ، لكان الذراع قد تطابق، ولكان البرنامج قد طبع yes.
استخدام روابط @ (Using @ Bindings)
يسمح لنا عامل “عند” (at operator) المسمى @ بإنشاء متغير يحمل قيمة في نفس الوقت الذي نختبر فيه تلك القيمة لمطابقة نمط ما. في القائمة 19-29، نريد اختبار أن حقل id في Message::Hello يقع ضمن النطاق 3..=7. نريد أيضاً ربط القيمة بالمتغير id حتى نتمكن من استخدامها في الكود المرتبط بالذراع.
fn main() {
enum Message {
Hello { id: i32 },
}
let msg = Message::Hello { id: 5 };
match msg {
Message::Hello { id: id @ 3..=7 } => {
println!("Found an id in range: {id}")
}
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
}
Message::Hello { id } => println!("Found some other id: {id}"),
}
}سيطبع هذا المثال Found an id in range: 5. من خلال تحديد id @ قبل النطاق 3..=7 ، فإننا نلتقط أي قيمة طابقت النطاق في متغير باسم id مع اختبار أن القيمة طابقت نمط النطاق أيضاً.
في الذراع الثاني، حيث لدينا نطاق محدد فقط في النمط، لا يحتوي الكود المرتبط بالذراع على متغير يحتوي على القيمة الفعلية لحقل id. كان من الممكن أن تكون قيمة حقل id هي 10 أو 11 أو 12، لكن الكود الذي يتماشى مع هذا النمط لا يعرف أياً منها. كود النمط غير قادر على استخدام القيمة من حقل id لأننا لم نحفظ قيمة id في متغير.
في الذراع الأخير، حيث حددنا متغيراً بدون نطاق، تتوفر لدينا القيمة لاستخدامها في كود الذراع في متغير باسم id. والسبب هو أننا استخدمنا syntax المختصر لحقل struct. لكننا لم نطبق أي اختبار على القيمة في حقل id في هذا الذراع، كما فعلنا مع أول ذراعين: أي قيمة ستطابق هذا النمط.
يسمح لنا استخدام @ باختبار قيمة وحفظها في متغير داخل نمط واحد.
ملخص (Summary)
تعد أنماط Rust مفيدة جداً في التمييز بين أنواع البيانات المختلفة. عند استخدامها في تعبيرات match ، يضمن Rust أن أنماطك تغطي كل قيمة ممكنة، وإلا فلن يتم تصريف برنامجك. تجعل الأنماط في عبارات let ومعاملات الدوال تلك البنيات أكثر فائدة، مما يتيح تفكيك القيم إلى أجزاء أصغر وتعيين تلك الأجزاء لمتغيرات. يمكننا إنشاء أنماط بسيطة أو معقدة لتناسب احتياجاتنا.
بعد ذلك، وفي الفصل قبل الأخير من الكتاب، سننظر في بعض الجوانب المتقدمة لمجموعة متنوعة من ميزات Rust.
الميزات المتقدمة (Advanced Features)
بحلول الآن، تعلمت الأجزاء الأكثر استخدامًا في لغة برمجة Rust. قبل أن نقوم بمشروع آخر في الفصل 21، سنلقي نظرة على بعض جوانب اللغة التي قد تصادفها بين الحين والآخر ولكن قد لا تستخدمها كل يوم. يمكنك استخدام هذا الفصل كمرجع عندما تواجه أي مجهول. الميزات المشمولة هنا مفيدة في مواقف محددة للغاية. على الرغم من أنك قد لا تحتاج إليها كثيرًا، إلا أننا نريد التأكد من أن لديك إلمامًا بجميع الميزات التي تقدمها Rust.
في هذا الفصل، سنغطي:
- لغة Rust غير الآمنة (Unsafe Rust): كيفية إلغاء الاشتراك في بعض ضمانات Rust وتحمل المسؤولية عن الحفاظ على تلك الضمانات يدويًا.
- السمات المتقدمة (Advanced traits): الأنواع المرتبطة (Associated types)، ومعاملات النوع الافتراضية (default type parameters)، وبناء الجملة المؤهل بالكامل (fully qualified syntax)، والسمات الفائقة (supertraits)، ونمط النوع الجديد (newtype pattern) فيما يتعلق بالسمات.
- الأنواع المتقدمة (Advanced types): المزيد عن نمط النوع الجديد (newtype pattern)، وأسماء مستعارة للأنواع (type aliases)، ونوع “أبداً” (never type)، والأنواع ذات الحجم الديناميكي (dynamically sized types).
- الدوال والإغلاقات المتقدمة (Advanced functions and closures): مؤشرات الدوال (Function pointers) وإرجاع الإغلاقات (closures).
- الماكرو (Macros): طرق لتعريف كود يحدد المزيد من الكود في وقت الترجمة (compile time).
إنها مجموعة واسعة من ميزات Rust مع شيء للجميع! دعنا نبدأ!
رست غير الآمنة (Unsafe Rust)
لغة رست غير الآمنة (Unsafe Rust)
جميع الأكواد التي ناقشناها حتى الآن كانت تخضع لضمانات سلامة الذاكرة (memory safety guarantees) الخاصة بلغة رست (Rust) والتي يتم فرضها في وقت التصريف (compile time). ومع ذلك، تمتلك رست لغة ثانية مخفية بداخلها لا تفرض ضمانات سلامة الذاكرة هذه: تُسمى رست غير الآمنة (unsafe Rust) وهي تعمل تماماً مثل رست العادية ولكنها تمنحنا “قوى خارقة” إضافية.
توجد Unsafe Rust لأن التحليل الساكن (static analysis)، بطبيعته، يكون متحفظاً. فعندما يحاول المصرّف (compiler) تحديد ما إذا كان الكود يلتزم بالضمانات أم لا، فمن الأفضل له رفض بعض البرامج الصالحة بدلاً من قبول بعض البرامج غير الصالحة. على الرغم من أن الكود قد يكون سليماً، إلا أنه إذا لم يمتلك compiler معلومات كافية ليكون واثقاً، فإنه سيرفض الكود. في هذه الحالات، يمكنك استخدام كود غير آمن (unsafe code) لإخبار compiler: “ثق بي، أنا أعرف ما أفعله”. ومع ذلك، كن حذراً، فأنت تستخدم Unsafe Rust على مسؤوليتك الخاصة: إذا استخدمت unsafe code بشكل غير صحيح، فقد تحدث مشكلات بسبب عدم سلامة الذاكرة، مثل فك مرجع مؤشر فارغ (null pointer dereferencing).
سبب آخر لامتلاك رست وجهاً آخر غير آمن هو أن عتاد الحاسوب (computer hardware) الأساسي غير آمن بطبيعته. إذا لم تسمح لك رست بإجراء عمليات غير آمنة (unsafe operations)، فلن تتمكن من أداء مهام معينة. تحتاج رست للسماح لك بالقيام ببرمجة الأنظمة منخفضة المستوى (low-level systems programming)، مثل التفاعل المباشر مع نظام التشغيل (operating system) أو حتى كتابة نظام التشغيل الخاص بك. العمل مع low-level systems programming هو أحد أهداف اللغة. دعونا نستكشف ما يمكننا فعله باستخدام Unsafe Rust وكيفية القيام بذلك.
ممارسة القوى الخارقة غير الآمنة (Performing Unsafe Superpowers)
للتحول إلى Unsafe Rust، استخدم الكلمة المفتاحية (keyword) unsafe ثم ابدأ كتلة (block) جديدة تحتوي على unsafe code. يمكنك اتخاذ خمسة إجراءات في Unsafe Rust لا يمكنك القيام بها في رست الآمنة (safe Rust)، والتي نسميها القوى الخارقة غير الآمنة (unsafe superpowers). تشمل هذه القوى القدرة على:
- فك مرجع مؤشر خام (Dereference a raw pointer).
- استدعاء دالة (function) أو دالة كائن (method) غير آمنة.
- الوصول إلى متغير ساكن قابل للتغيير (mutable static variable) أو تعديله.
- تنفيذ سمة (trait) غير آمنة.
- الوصول إلى حقول الاتحادات (union).
من المهم فهم أن unsafe لا توقف عمل فاحص الاستعارة (borrow checker) أو تعطّل أي من فحوصات السلامة الأخرى في رست: إذا استخدمت مرجعاً (reference) في unsafe code، فسيظل خاضعاً للفحص. تمنحك keyword unsafe فقط إمكانية الوصول إلى هذه الميزات الخمس التي لا يتم فحصها بواسطة compiler من حيث سلامة الذاكرة. ستظل تحصل على درجة معينة من السلامة داخل unsafe block.
بالإضافة إلى ذلك، لا تعني unsafe أن الكود داخل block هو بالضرورة خطير أو أنه سيواجه بالتأكيد مشكلات في سلامة الذاكرة: القصد هو أنك كمبرمج ستضمن أن الكود داخل unsafe block سيصل إلى الذاكرة بطريقة صالحة.
البشر معرضون للخطأ وستحدث الأخطاء، ولكن من خلال اشتراط أن تكون هذه العمليات الخمس غير الآمنة داخل blocks مميزة بـ unsafe ، ستعرف أن أي أخطاء تتعلق بسلامة الذاكرة يجب أن تكون داخل unsafe block. اجعل unsafe blocks صغيرة؛ ستكون ممتناً لذلك لاحقاً عندما تحقق في أخطاء الذاكرة (memory bugs).
لعزل unsafe code قدر الإمكان، من الأفضل إحاطة هذا الكود داخل تجريد آمن (safe abstraction) وتوفير واجهة برمجة تطبيقات (API) آمنة، وهو ما سنناقشه لاحقاً في هذا الفصل عندما نفحص unsafe functions و methods. يتم تنفيذ أجزاء من المكتبة القياسية (standard library) كتجريدات آمنة فوق unsafe code تم تدقيقه. إن تغليف unsafe code في safe abstraction يمنع استخدامات unsafe من التسرب إلى جميع الأماكن التي قد ترغب أنت أو مستخدموك في استخدام الوظيفة المنفذة باستخدام unsafe code، لأن استخدام safe abstraction هو أمر آمن.
دعونا نلقي نظرة على كل من القوى الخارقة الخمس غير الآمنة بالترتيب. سننظر أيضاً في بعض التجريدات التي توفر واجهة آمنة لـ unsafe code.
فك مرجع مؤشر خام (Dereferencing a Raw Pointer)
في الفصل الرابع، في قسم “المراجع المعلقة” (Dangling References)، ذكرنا أن compiler يضمن أن المراجع صالحة دائماً. تمتلك Unsafe Rust نوعين جديدين يسمى كل منهما مؤشر خام (raw pointer) يشبهان المراجع. كما هو الحال مع المراجع، يمكن أن تكون raw pointers غير قابلة للتغيير (immutable) أو قابلة للتغيير (mutable) وتُكتب كـ *const T و *mut T على التوالي. النجمة ليست عامل فك المرجع (dereference operator)؛ بل هي جزء من اسم النوع. في سياق raw pointers، تعني immutable أنه لا يمكن التعيين للمؤشر مباشرة بعد فك مرجعه.
على عكس المراجع والمؤشرات الذكية (smart pointers)، فإن raw pointers:
- يُسمح لها بتجاهل قواعد الاستعارة (borrowing rules) من خلال امتلاك مؤشرات immutable و mutable معاً أو عدة مؤشرات mutable لنفس الموقع.
- لا تضمن الإشارة إلى ذاكرة صالحة.
- يُسمح لها بأن تكون فارغة (null).
- لا تنفذ أي تنظيف تلقائي (automatic cleanup).
من خلال اختيار عدم فرض رست لهذه الضمانات، يمكنك التخلي عن السلامة المضمونة مقابل أداء أفضل أو القدرة على التفاعل مع لغة أخرى أو عتاد لا تنطبق عليه ضمانات رست.
توضح القائمة 20-1 كيفية إنشاء raw pointer غير قابل للتغيير وآخر قابل للتغيير.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
}لاحظ أننا لا ندرج keyword unsafe في هذا الكود. يمكننا إنشاء raw pointers في safe code؛ لكننا لا نستطيع فك مرجع raw pointers خارج unsafe block، كما سترى بعد قليل.
لقد أنشأنا raw pointers باستخدام عوامل الاستعارة الخام (raw borrow operators): &raw const num ينشئ مؤشر خام *const i32 غير قابل للتغيير، و &raw mut num ينشئ مؤشر خام *mut i32 قابل للتغيير. ولأننا أنشأناها مباشرة من متغير محلي، فنحن نعلم أن هذه الـ raw pointers المحددة صالحة، لكن لا يمكننا وضع هذا الافتراض حول أي raw pointer.
لإثبات ذلك، سنقوم بعد ذلك بإنشاء raw pointer لا يمكننا التأكد من صلاحيته، باستخدام keyword as لتحويل (cast) قيمة بدلاً من استخدام raw borrow operator. توضح القائمة 20-2 كيفية إنشاء raw pointer لموقع عشوائي في الذاكرة. محاولة استخدام ذاكرة عشوائية هو أمر غير محدد (undefined): قد تكون هناك بيانات في ذلك العنوان وقد لا تكون، وقد يقوم compiler بتحسين الكود بحيث لا يكون هناك وصول للذاكرة، أو قد ينتهي البرنامج بخطأ في التجزئة (segmentation fault). عادةً، لا يوجد سبب وجيه لكتابة كود كهذا، خاصة في الحالات التي يمكنك فيها استخدام raw borrow operator بدلاً من ذلك، ولكن الأمر ممكن.
fn main() {
let address = 0x012345usize;
let r = address as *const i32;
}تذكر أنه يمكننا إنشاء raw pointers في safe code، لكن لا يمكننا فك مرجع raw pointers وقراءة البيانات التي تشير إليها. في القائمة 20-3، نستخدم dereference operator * على raw pointer مما يتطلب unsafe block.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
unsafe {
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
}
}إنشاء مؤشر لا يسبب ضرراً؛ فقط عندما نحاول الوصول إلى القيمة التي يشير إليها قد ينتهي بنا الأمر بالتعامل مع قيمة غير صالحة.
لاحظ أيضاً أنه في القائمتين 20-1 و 20-3، أنشأنا raw pointers من نوع *const i32 و *mut i32 يشيران كلاهما إلى نفس موقع الذاكرة حيث يتم تخزين num. إذا حاولنا بدلاً من ذلك إنشاء reference غير قابل للتغيير وآخر قابل للتغيير لـ num ، فلن يتم تصريف الكود لأن قواعد الملكية (ownership rules) في رست لا تسمح بمرجع mutable في نفس وقت وجود أي مراجع immutable. باستخدام raw pointers، يمكننا إنشاء مؤشر mutable ومؤشر immutable لنفس الموقع وتغيير البيانات من خلال المؤشر mutable، مما قد يؤدي إلى حدوث سباق بيانات (data race). كن حذراً!
مع كل هذه المخاطر، لماذا قد تستخدم raw pointers؟ أحد حالات الاستخدام الرئيسية هو عند التفاعل مع كود لغة C، كما سترى في القسم التالي. حالة أخرى هي عند بناء safe abstractions لا يفهمها borrow checker. سنقدم unsafe functions ثم ننظر في مثال لـ safe abstraction يستخدم unsafe code.
استدعاء دالة أو دالة كائن غير آمنة (Calling an Unsafe Function or Method)
النوع الثاني من العمليات التي يمكنك القيام بها في unsafe block هو استدعاء unsafe functions. تبدو unsafe functions و methods تماماً مثل functions و methods العادية، لكنها تحتوي على unsafe إضافية قبل بقية التعريف. تشير keyword unsafe في هذا السياق إلى أن function لها متطلبات نحتاج إلى الالتزام بها عند استدعائها، لأن رست لا تستطيع ضمان وفائنا بهذه المتطلبات. من خلال استدعاء unsafe function داخل unsafe block، فإننا نقول إننا قرأنا توثيق هذه function ونتحمل مسؤولية الالتزام بعقودها.
إليك unsafe function تسمى dangerous لا تفعل شيئاً في جسمها:
fn main() {
unsafe fn dangerous() {}
unsafe {
dangerous();
}
}يجب علينا استدعاء function dangerous داخل unsafe block منفصل. إذا حاولنا استدعاء dangerous بدون unsafe block، فسنحصل على خطأ:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function `dangerous` is unsafe and requires unsafe block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
باستخدام unsafe block، نحن نؤكد لرست أننا قرأنا توثيق function، ونفهم كيفية استخدامها بشكل صحيح، وتحققنا من أننا نفي بعقد function.
للقيام بعمليات غير آمنة في جسم unsafe function، لا تزال بحاجة إلى استخدام unsafe block، تماماً كما هو الحال داخل function عادية، وسيقوم compiler بتنبيهك إذا نسيت. يساعدنا هذا في إبقاء unsafe blocks صغيرة قدر الإمكان، حيث قد لا تكون العمليات غير آمنة مطلوبة عبر جسم function بالكامل.
إنشاء تجريد آمن فوق كود غير آمن (Creating a Safe Abstraction over Unsafe Code)
مجرد احتواء function على unsafe code لا يعني أننا بحاجة إلى تمييز function بأكملها كغير آمنة. في الواقع، يعد تغليف unsafe code في safe function تجريداً شائعاً. كمثال، دعونا ندرس function split_at_mut من standard library، والتي تتطلب بعض unsafe code. سنستكشف كيف يمكننا تنفيذها. يتم تعريف هذه method الآمنة على الشرائح القابلة للتغيير (mutable slices): فهي تأخذ شريحة (slice) واحدة وتجعلها شريحتين عن طريق تقسيم slice عند الفهرس (index) المعطى كمعامل (argument). توضح القائمة 20-4 كيفية استخدام split_at_mut.
fn main() {
let mut v = vec![1, 2, 3, 4, 5, 6];
let r = &mut v[..];
let (a, b) = r.split_at_mut(3);
assert_eq!(a, &mut [1, 2, 3]);
assert_eq!(b, &mut [4, 5, 6]);
}لا يمكننا تنفيذ هذه function باستخدام safe Rust فقط. قد تبدو المحاولة شيئاً مثل القائمة 20-5، والتي لن يتم تصريفها. للتبسيط، سنقوم بتنفيذ split_at_mut كـ function بدلاً من method وفقط لـ slices من قيم i32 بدلاً من النوع العام (generic type) T.
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}تقوم هذه function أولاً بالحصول على الطول الإجمالي لـ slice. بعد ذلك، تتحقق (assert) من أن index المعطى كمعامل يقع ضمن slice من خلال التأكد مما إذا كان أقل من أو يساوي الطول. يعني هذا التحقق أنه إذا مررنا index أكبر من الطول لتقسيم slice عنده، فإن function ستتوقف بشكل طارئ (panic) قبل أن تحاول استخدام ذلك index.
بعد ذلك، نعيد شريحتين قابلتين للتغيير في صف (tuple): واحدة من بداية slice الأصلية إلى index المسمى mid والأخرى من mid إلى نهاية slice.
عندما نحاول تصريف الكود في القائمة 20-5، سنحصل على خطأ:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
|
= help: use `.split_at_mut(position)` to obtain two mutable non-overlapping sub-slices
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
لا يستطيع borrow checker في رست فهم أننا نستعير أجزاء مختلفة من slice؛ فهو يعرف فقط أننا نستعير من نفس slice مرتين. استعارة أجزاء مختلفة من slice هو أمر سليم جوهرياً لأن الشريحتين لا تتداخلان، لكن رست ليست ذكية بما يكفي لمعرفة ذلك. عندما نعلم أن الكود سليم، ولكن رست لا تعلم ذلك، يحين الوقت للاستعانة بـ unsafe code.
توضح القائمة 20-6 كيفية استخدام unsafe block، و raw pointer، وبعض الاستدعاءات لـ unsafe functions لجعل تنفيذ split_at_mut يعمل.
use std::slice;
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
let ptr = values.as_mut_ptr();
assert!(mid <= len);
unsafe {
(
slice::from_raw_parts_mut(ptr, mid),
slice::from_raw_parts_mut(ptr.add(mid), len - mid),
)
}
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}تذكر من قسم “نوع الشريحة” (The Slice Type) في الفصل الرابع أن slice هي مؤشر لبعض البيانات وطول slice. نحن نستخدم method المسمى len للحصول على طول slice و method المسمى as_mut_ptr للوصول إلى raw pointer الخاص بـ slice. في هذه الحالة، ولأن لدينا mutable slice لقيم i32 ، فإن as_mut_ptr تعيد raw pointer من نوع *mut i32 ، والذي قمنا بتخزينه في المتغير ptr.
نحتفظ بالتحقق من أن index المسمى mid يقع ضمن slice. بعد ذلك، نصل إلى unsafe code: تأخذ function المسمى slice::from_raw_parts_mut مؤشراً خاماً وطولاً، وتنشئ slice. نستخدم هذه function لإنشاء slice تبدأ من ptr وطولها mid من العناصر. بعد ذلك، نستدعي method المسمى add على ptr مع تمرير mid كمعامل للحصول على raw pointer يبدأ عند mid ، وننشئ slice باستخدام ذلك المؤشر وعدد العناصر المتبقية بعد mid كطول.
تعتبر function المسمى slice::from_raw_parts_mut غير آمنة لأنها تأخذ raw pointer ويجب أن تثق في أن هذا المؤشر صالح. كما أن method المسمى add على raw pointers هو أيضاً غير آمن لأنه يجب أن يثق في أن موقع الإزاحة (offset) هو أيضاً مؤشر صالح. لذلك، كان علينا وضع unsafe block حول استدعاءاتنا لـ slice::from_raw_parts_mut و add حتى نتمكن من استدعائهما. من خلال النظر في الكود وإضافة التحقق من أن mid يجب أن يكون أقل من أو يساوي len ، يمكننا القول إن جميع raw pointers المستخدمة داخل unsafe block ستكون مؤشرات صالحة لبيانات داخل slice. هذا استخدام مقبول ومناسب لـ unsafe.
لاحظ أننا لسنا بحاجة لتمييز function الناتجة split_at_mut كـ unsafe ، ويمكننا استدعاء هذه function من safe Rust. لقد أنشأنا safe abstraction لكود غير آمن مع تنفيذ لـ function يستخدم unsafe code بطريقة آمنة، لأنه ينشئ فقط مؤشرات صالحة من البيانات التي تملك هذه function صلاحية الوصول إليها.
في المقابل، فإن استخدام slice::from_raw_parts_mut في القائمة 20-7 سيؤدي على الأرجح إلى انهيار البرنامج عند استخدام slice. يأخذ هذا الكود موقعاً عشوائياً في الذاكرة وينشئ slice بطول 10,000 عنصر.
fn main() {
use std::slice;
let address = 0x01234usize;
let r = address as *mut i32;
let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
}نحن لا نملك الذاكرة في هذا الموقع العشوائي، ولا يوجد ضمان بأن slice التي ينشئها هذا الكود تحتوي على قيم i32 صالحة. محاولة استخدام values كما لو كانت slice صالحة تؤدي إلى سلوك غير محدد (undefined behavior).
استخدام دوال خارجية (extern) لاستدعاء كود خارجي (Using extern Functions to Call External Code)
أحياناً قد يحتاج كود رست الخاص بك إلى التفاعل مع كود مكتوب بلغة أخرى. لهذا الغرض، تمتلك رست keyword extern التي تسهل إنشاء واستخدام واجهة الدوال الأجنبية (Foreign Function Interface - FFI)، وهي طريقة للغة برمجة لتعريف functions وتمكين لغة برمجة مختلفة (أجنبية) من استدعاء تلك functions.
توضح القائمة 20-8 كيفية إعداد تكامل مع function المسمى abs من مكتبة C القياسية. الدوال المعلن عنها داخل blocks من نوع extern هي بشكل عام غير آمنة للاستدعاء من كود رست، لذا يجب أيضاً تمييز extern blocks بـ unsafe. والسبب هو أن اللغات الأخرى لا تفرض قواعد وضمانات رست، ولا تستطيع رست التحقق منها، لذا تقع المسؤولية على عاتق المبرمج لضمان السلامة.
unsafe extern "C" {
fn abs(input: i32) -> i32;
}
fn main() {
unsafe {
println!("Absolute value of -3 according to C: {}", abs(-3));
}
}داخل block من نوع unsafe extern "C" ، ندرج أسماء وتواقيع (signatures) الدوال الخارجية من لغة أخرى نريد استدعاءها. يحدد جزء "C" أي واجهة ثنائية للتطبيق (Application Binary Interface - ABI) تستخدمها function الخارجية: تحدد ABI كيفية استدعاء function على مستوى لغة التجميع (assembly). تعتبر ABI الخاصة بـ "C" هي الأكثر شيوعاً وتتبع ABI الخاصة بلغة البرمجة C. تتوفر معلومات حول جميع واجهات ABI التي تدعمها رست في مرجع رست (Rust Reference).
كل عنصر يتم الإعلان عنه داخل unsafe extern block هو غير آمن ضمنياً. ومع ذلك، فإن بعض functions الخاصة بـ FFI آمنة للاستدعاء. على سبيل المثال، function المسمى abs من مكتبة C القياسية ليس لديها أي اعتبارات تتعلق بسلامة الذاكرة، ونحن نعلم أنه يمكن استدعاؤها مع أي i32. في حالات كهذه، يمكننا استخدام keyword safe للقول إن هذه function المحددة آمنة للاستدعاء على الرغم من وجودها في unsafe extern block. بمجرد إجراء هذا التغيير، لن يتطلب استدعاؤها وجود unsafe block، كما هو موضح في القائمة 20-9.
unsafe extern "C" {
safe fn abs(input: i32) -> i32;
}
fn main() {
println!("Absolute value of -3 according to C: {}", abs(-3));
}تمييز function كـ safe لا يجعلها آمنة بطبيعتها! بدلاً من ذلك، هو بمثابة وعد تقطعه لرست بأنها آمنة. تظل مسؤوليتك هي التأكد من الوفاء بهذا الوعد!
استدعاء دوال رست من لغات أخرى (Calling Rust Functions from Other Languages)
يمكننا أيضاً استخدام extern لإنشاء واجهة تسمح للغات أخرى باستدعاء functions الخاصة برست. بدلاً من إنشاء extern block كامل، نضيف keyword extern ونحدد ABI المراد استخدامها قبل keyword fn لـ function المعنية مباشرة. نحتاج أيضاً إلى إضافة تعليق توضيحي (annotation) من نوع #[unsafe(no_mangle)] لإخبار compiler رست بعدم تشويه (mangle) اسم هذه function. التشويه (Mangling) هو عندما يقوم compiler بتغيير الاسم الذي أعطيناه لـ function إلى اسم مختلف يحتوي على مزيد من المعلومات لتستهلكها أجزاء أخرى من عملية التصريف ولكنه أقل قابلية للقراءة من قبل البشر. يقوم كل compiler لغة برمجة بتشويه الأسماء بشكل مختلف قليلاً، لذا لكي تكون function رست قابلة للتسمية من قبل لغات أخرى، يجب علينا تعطيل تشويه الأسماء الخاص بـ compiler رست. هذا أمر غير آمن لأنه قد تحدث تصادمات في الأسماء عبر المكتبات بدون mangling المدمج، لذا تقع على عاتقنا مسؤولية التأكد من أن الاسم الذي نختاره آمن للتصدير بدون mangling.
في المثال التالي، نجعل function المسمى call_from_c قابلة للوصول من كود C، بعد تصريفها إلى مكتبة مشتركة (shared library) وربطها من C:
#[unsafe(no_mangle)]
pub extern "C" fn call_from_c() {
println!("Just called a Rust function from C!");
}
هذا الاستخدام لـ extern يتطلب unsafe فقط في السمة (attribute)، وليس على extern block.
الوصول إلى متغير ساكن قابل للتغيير أو تعديله (Accessing or Modifying a Mutable Static Variable)
في هذا الكتاب، لم نتحدث بعد عن المتغيرات العامة (global variables)، والتي تدعمها رست ولكنها قد تكون إشكالية مع قواعد الملكية في رست. إذا كان هناك خيطان (threads) يصلان إلى نفس المتغير العام القابل للتغيير، فقد يتسبب ذلك في data race.
في رست، تسمى global variables بالمتغيرات الساكنة (static variables). توضح القائمة 20-10 مثالاً للإعلان عن static variable واستخدامه مع شريحة نصية (string slice) كقيمة.
static HELLO_WORLD: &str = "Hello, world!";
fn main() {
println!("value is: {HELLO_WORLD}");
}تشبه static variables الثوابت (constants)، التي ناقشناها في قسم “الإعلان عن الثوابت” (Declaring Constants) في الفصل الثالث. تكون أسماء static variables بصيغة SCREAMING_SNAKE_CASE حسب العرف. يمكن لـ static variables فقط تخزين مراجع ذات عمر 'static (static lifetime)، مما يعني أن compiler رست يمكنه معرفة العمر (lifetime) ولسنا مطالبين بتمييزه صراحة. الوصول إلى static variable غير قابل للتغيير هو أمر آمن.
هناك فرق دقيق بين constants و static variables غير القابلة للتغيير وهو أن القيم في static variable لها عنوان ثابت في الذاكرة. استخدام القيمة سيصل دائماً إلى نفس البيانات. من ناحية أخرى، يُسمح لـ constants بتكرار بياناتها كلما تم استخدامها. فرق آخر هو أن static variables يمكن أن تكون قابلة للتغيير (mutable). الوصول إلى static variables القابلة للتغيير وتعديلها هو أمر غير آمن (unsafe). توضح القائمة 20-11 كيفية الإعلان عن static variable قابل للتغيير يسمى COUNTER والوصول إليه وتعديله.
static mut COUNTER: u32 = 0;
/// SAFETY: Calling this from more than a single thread at a time is undefined
/// behavior, so you *must* guarantee you only call it from a single thread at
/// a time.
unsafe fn add_to_count(inc: u32) {
unsafe {
COUNTER += inc;
}
}
fn main() {
unsafe {
// SAFETY: This is only called from a single thread in `main`.
add_to_count(3);
println!("COUNTER: {}", *(&raw const COUNTER));
}
}كما هو الحال مع المتغيرات العادية، نحدد القابلية للتغيير باستخدام keyword mut. أي كود يقرأ من COUNTER أو يكتب فيه يجب أن يكون داخل unsafe block. الكود في القائمة 20-11 يتم تصريفه ويطبع COUNTER: 3 كما نتوقع لأنه يعمل بخيط واحد (single threaded). من المحتمل أن يؤدي وصول عدة threads إلى COUNTER إلى حدوث data races، لذا فهو undefined behavior. لذلك، نحتاج إلى تمييز function بأكملها كـ unsafe وتوثيق قيود السلامة بحيث يعرف أي شخص يستدعي function ما هو مسموح له وما هو غير مسموح له بفعله بأمان.
كلما كتبنا unsafe function، فمن المعتاد (idiomatic) كتابة تعليق يبدأ بـ SAFETY ويشرح ما يحتاج المستدعي فعله لاستدعاء function بأمان. وبالمثل، كلما قمنا بعملية غير آمنة، فمن المعتاد كتابة تعليق يبدأ بـ SAFETY لشرح كيفية الالتزام بقواعد السلامة.
بالإضافة إلى ذلك، سيرفض compiler افتراضياً أي محاولة لإنشاء مراجع لـ static variable قابل للتغيير من خلال قاعدة تحقق (lint) في compiler. يجب عليك إما إلغاء الاشتراك صراحة في حماية lint هذه عن طريق إضافة annotation من نوع #[allow(static_mut_refs)] أو الوصول إلى static variable القابل للتغيير عبر raw pointer تم إنشاؤه باستخدام أحد raw borrow operators. يتضمن ذلك الحالات التي يتم فيها إنشاء reference بشكل غير مرئي، كما هو الحال عند استخدامه في println! في هذه القائمة. يساعد اشتراط إنشاء مراجع لـ static mutable variables عبر raw pointers في جعل متطلبات السلامة لاستخدامها أكثر وضوحاً.
مع البيانات القابلة للتغيير التي يمكن الوصول إليها عالمياً، من الصعب ضمان عدم وجود data races، ولهذا السبب تعتبر رست أن static variables القابلة للتغيير غير آمنة. حيثما أمكن، يفضل استخدام تقنيات التزامن (concurrency) والمؤشرات الذكية الآمنة للخيوط (thread-safe smart pointers) التي ناقشناها في الفصل 16 بحيث يتحقق compiler من أن الوصول إلى البيانات من threads مختلفة يتم بأمان.
تنفيذ سمة غير آمنة (Implementing an Unsafe Trait)
يمكننا استخدام unsafe لتنفيذ سمة غير آمنة (unsafe trait). تكون trait غير آمنة عندما يكون لواحد على الأقل من methods الخاصة بها بعض الثوابت (invariants) التي لا يستطيع compiler التحقق منها. نعلن أن trait هي unsafe عن طريق إضافة keyword unsafe قبل trait وتمييز تنفيذ trait كـ unsafe أيضاً، كما هو موضح في القائمة 20-12.
unsafe trait Foo {
// methods go here
}
unsafe impl Foo for i32 {
// method implementations go here
}
fn main() {}باستخدام unsafe impl ، نحن نعد بأننا سنلتزم بـ invariants التي لا يستطيع compiler التحقق منها.
كمثال، تذكر سمات العلامات (marker traits) المسمى Send و Sync التي ناقشناها في قسم “التزامن القابل للتوسع مع Send و Sync” في الفصل 16: يقوم compiler بتنفيذ هذه traits تلقائياً إذا كانت أنواعنا تتكون بالكامل من أنواع أخرى تنفذ Send و Sync. إذا قمنا بتنفيذ نوع يحتوي على نوع لا ينفذ Send أو Sync ، مثل raw pointers، وأردنا تمييز هذا النوع كـ Send أو Sync ، فيجب علينا استخدام unsafe. لا تستطيع رست التحقق من أن نوعنا يلتزم بالضمانات التي تسمح بإرساله بأمان عبر threads أو الوصول إليه من عدة threads؛ لذلك، نحتاج إلى إجراء تلك الفحوصات يدوياً والإشارة إلى ذلك باستخدام unsafe.
الوصول إلى حقول الاتحاد (Accessing Fields of a Union)
الإجراء الأخير الذي يعمل فقط مع unsafe هو الوصول إلى حقول الاتحاد (union). يشبه union الهيكل (struct)، ولكن يتم استخدام حقل واحد فقط معلن عنه في مثيل (instance) معين في وقت واحد. تُستخدم unions بشكل أساسي للتفاعل مع unions في كود لغة C. الوصول إلى حقول union غير آمن لأن رست لا تستطيع ضمان نوع البيانات المخزنة حالياً في instance الخاص بـ union. يمكنك معرفة المزيد عن unions في مرجع رست (Rust Reference).
استخدام Miri للتحقق من الكود غير الآمن (Using Miri to Check Unsafe Code)
عند كتابة unsafe code، قد ترغب في التحقق من أن ما كتبته هو بالفعل آمن وصحيح. أحد أفضل الطرق للقيام بذلك هو استخدام Miri، وهي أداة رسمية من رست لاكتشاف undefined behavior. بينما يعتبر borrow checker أداة ساكنة (static tool) تعمل في وقت التصريف، فإن Miri هي أداة ديناميكية (dynamic tool) تعمل في وقت التشغيل (runtime). تقوم بفحص الكود الخاص بك عن طريق تشغيل برنامجك، أو مجموعة الاختبارات الخاصة به، واكتشاف متى تنتهك القواعد التي تفهمها حول كيفية عمل رست.
يتطلب استخدام Miri نسخة ليلية (nightly build) من رست (والتي نتحدث عنها أكثر في الملحق G: كيف تُصنع رست و “رست الليلية”). يمكنك تثبيت كل من نسخة nightly من رست وأداة Miri عن طريق كتابة rustup +nightly component add miri. هذا لا يغير إصدار رست الذي يستخدمه مشروعك؛ بل يضيف الأداة فقط إلى نظامك حتى تتمكن من استخدامها عندما تريد. يمكنك تشغيل Miri على مشروع عن طريق كتابة cargo +nightly miri run أو cargo +nightly miri test.
كمثال على مدى فائدة ذلك، انظر ماذا يحدث عندما نقوم بتشغيلها ضد القائمة 20-7.
$ cargo +nightly miri run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.01s
Running `file:///home/.rustup/toolchains/nightly/bin/cargo-miri runner target/miri/debug/unsafe-example`
warning: integer-to-pointer cast
--> src/main.rs:5:13
|
5 | let r = address as *mut i32;
| ^^^^^^^^^^^^^^^^^^^ integer-to-pointer cast
|
= help: this program is using integer-to-pointer casts or (equivalently) `ptr::with_exposed_provenance`, which means that Miri might miss pointer bugs in this program
= help: see https://doc.rust-lang.org/nightly/std/ptr/fn.with_exposed_provenance.html for more details on that operation
= help: to ensure that Miri does not miss bugs in your program, use Strict Provenance APIs (https://doc.rust-lang.org/nightly/std/ptr/index.html#strict-provenance, https://crates.io/crates/sptr) instead
= help: you can then set `MIRIFLAGS=-Zmiri-strict-provenance` to ensure you are not relying on `with_exposed_provenance` semantics
= help: alternatively, `MIRIFLAGS=-Zmiri-permissive-provenance` disables this warning
= note: BACKTRACE:
= note: inside `main` at src/main.rs:5:13: 5:32
error: Undefined Behavior: pointer not dereferenceable: pointer must be dereferenceable for 40000 bytes, but got 0x1234[noalloc] which is a dangling pointer (it has no provenance)
--> src/main.rs:7:35
|
7 | let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ Undefined Behavior occurred here
|
= help: this indicates a bug in the program: it performed an invalid operation, and caused Undefined Behavior
= help: see https://doc.rust-lang.org/nightly/reference/behavior-considered-undefined.html for further information
= note: BACKTRACE:
= note: inside `main` at src/main.rs:7:35: 7:70
note: some details are omitted, run with `MIRIFLAGS=-Zmiri-backtrace=full` for a verbose backtrace
error: aborting due to 1 previous error; 1 warning emitted
تحذرنا Miri بشكل صحيح من أننا نقوم بتحويل (casting) عدد صحيح إلى مؤشر، وهو ما قد يمثل مشكلة، لكن Miri لا تستطيع تحديد ما إذا كانت هناك مشكلة لأنها لا تعرف مصدر المؤشر. بعد ذلك، تعيد Miri خطأً حيث يوجد في القائمة 20-7 سلوك غير محدد لأن لدينا مؤشر معلق (dangling pointer). بفضل Miri، نعلم الآن أن هناك خطراً من حدوث undefined behavior، ويمكننا التفكير في كيفية جعل الكود آمناً. في بعض الحالات، يمكن لـ Miri تقديم توصيات حول كيفية إصلاح الأخطاء.
لا تلتقط Miri كل ما قد تخطئ فيه عند كتابة unsafe code. Miri هي أداة تحليل ديناميكي، لذا فهي تلتقط فقط المشكلات في الكود الذي يتم تشغيله بالفعل. هذا يعني أنك ستحتاج إلى استخدامها جنباً إلى جنب مع تقنيات اختبار جيدة لزيادة ثقتك في unsafe code الذي كتبته. كما أن Miri لا تغطي كل طريقة ممكنة يمكن أن يكون بها كودك غير سليم (unsound).
بمعنى آخر: إذا التقطت Miri مشكلة، فأنت تعلم أن هناك خطأ (bug)، ولكن مجرد عدم التقاط Miri لخطأ لا يعني عدم وجود مشكلة. ومع ذلك، يمكنها التقاط الكثير. جرب تشغيلها على الأمثلة الأخرى لـ unsafe code في هذا الفصل وانظر ماذا ستقول!
يمكنك معرفة المزيد عن Miri في مستودع GitHub الخاص بها.
استخدام الكود غير الآمن بشكل صحيح (Using Unsafe Code Correctly)
استخدام unsafe لممارسة إحدى القوى الخارقة الخمس التي ناقشناها للتو ليس خطأً أو حتى أمراً غير مرغوب فيه، ولكن من الأصعب كتابة unsafe code بشكل صحيح لأن compiler لا يستطيع المساعدة في الحفاظ على سلامة الذاكرة. عندما يكون لديك سبب لاستخدام unsafe code، يمكنك القيام بذلك، ووجود التمييز الصريح بـ unsafe يجعل من السهل تتبع مصدر المشكلات عند حدوثها. كلما كتبت unsafe code، يمكنك استخدام Miri لمساعدتك على أن تكون أكثر ثقة في أن الكود الذي كتبته يلتزم بقواعد رست.
لاستكشاف أعمق بكثير حول كيفية العمل بفعالية مع Unsafe Rust، اقرأ دليل رست الرسمي لـ unsafe ، The Rustonomicon.
السمات المتقدمة (Advanced Traits)
(السمات المتقدمة) Advanced Traits
لقد غطينا Traits لأول مرة في قسم “تعريف السلوك المشترك باستخدام السمات” في الفصل العاشر، لكننا لم نناقش التفاصيل الأكثر تقدماً. الآن بعد أن عرفت المزيد عن Rust، يمكننا الدخول في التفاصيل الدقيقة.
تعريف السمات باستخدام الأنواع المرتبطة (Defining Traits with Associated Types)
تربط (الأنواع المرتبطة) Associated types بين (نائب نوع) type placeholder و (سمة) trait بحيث يمكن لتعريفات (دوال السمة) trait methods استخدام هذه الأنواع النائبة في (تواقيعها) signatures. سيقوم (منفذ السمة) implementor بتحديد (النوع الملموس) concrete type الذي سيتم استخدامه بدلاً من النوع النائب لتنفيذ معين. بهذه الطريقة، يمكننا تعريف trait يستخدم بعض الأنواع دون الحاجة إلى معرفة ماهية تلك الأنواع بالضبط حتى يتم تنفيذ trait.
لقد وصفنا معظم الميزات المتقدمة في هذا الفصل بأنها نادراً ما تكون مطلوبة. تقع Associated types في مكان ما في المنتصف: فهي تُستخدم بشكل أقل تكراراً من الميزات الموضحة في بقية الكتاب ولكن بشكل أكثر شيوعاً من العديد من الميزات الأخرى التي تمت مناقشتها في هذا الفصل.
أحد الأمثلة على trait مع associated type هو Iterator الذي توفره المكتبة القياسية. يسمى associated type بـ Item ويمثل نوع القيم التي يتنقل عبرها النوع الذي ينفذ Iterator. تعريف Iterator هو كما هو موضح في القائمة 20-13.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}النوع Item هو placeholder (نائب)، ويوضح تعريف دالة next أنها ستعيد قيمًا من النوع Option<Self::Item>. سيقوم منفذو Iterator بتحديد concrete type لـ Item ، وستعيد دالة next نوع Option يحتوي على قيمة من ذلك concrete type.
قد تبدو Associated types مفهوماً مشابهاً لـ (الأنواع العامة) generics ، حيث تسمح لنا الأخيرة بتعريف دالة دون تحديد الأنواع التي يمكنها التعامل معها. لفحص الفرق بين المفهومين، سننظر في تنفيذ Iterator على نوع يسمى Counter يحدد أن نوع Item هو u32:
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}تبدو هذه الصيغة قابلة للمقارنة مع generics. لذا، لماذا لا نعرف Iterator باستخدام generics فقط، كما هو موضح في القائمة 20-14؟
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}الفرق هو أنه عند استخدام generics ، كما في القائمة 20-14، يجب علينا (توضيح) annotate الأنواع في كل تنفيذ؛ ولأننا نستطيع أيضاً تنفيذ Iterator<String> for Counter أو أي نوع آخر، فقد يكون لدينا تطبيقات متعددة لـ Iterator لـ Counter. بعبارة أخرى، عندما يحتوي trait على (معلمة عامة) generic parameter ، يمكن تنفيذه لنوع ما عدة مرات، مع تغيير concrete types لـ generic type parameters في كل مرة. عندما نستخدم دالة next على Counter ، سيتعين علينا تقديم (توضيحات النوع) type annotations للإشارة إلى أي تنفيذ لـ Iterator نريد استخدامه.
مع Associated types ، لا نحتاج إلى annotate الأنواع، لأننا لا نستطيع تنفيذ trait على نوع ما عدة مرات. في القائمة 20-13 مع التعريف الذي يستخدم associated types ، يمكننا اختيار نوع Item مرة واحدة فقط لأنه لا يمكن أن يكون هناك سوى impl Iterator for Counter واحد. ليس علينا تحديد أننا نريد (مكررًا) iterator لقيم u32 في كل مكان نستدعي فيه next على Counter.
تصبح Associated types أيضاً جزءاً من (عقد السمة) trait’s contract: يجب على منفذي trait توفير نوع ليحل محل associated type placeholder. غالباً ما يكون لـ Associated types اسم يصف كيفية استخدام النوع، ويعد توثيق associated type في توثيق (واجهة برمجة التطبيقات) API ممارسة جيدة.
استخدام المعلمات العامة الافتراضية والتحميل الزائد للمعاملات (Using Default Generic Parameters and Operator Overloading)
عندما نستخدم generic type parameters ، يمكننا تحديد concrete type افتراضي للنوع العام. هذا يلغي حاجة منفذي trait لتحديد concrete type إذا كان النوع الافتراضي يعمل. يمكنك تحديد نوع افتراضي عند التصريح عن نوع عام باستخدام صيغة <PlaceholderType=ConcreteType>.
مثال رائع على موقف تكون فيه هذه التقنية مفيدة هو (التحميل الزائد للمعاملات) operator overloading ، حيث تقوم بتخصيص سلوك (معامل) operator (مثل +) في مواقف معينة.
لا تسمح لك Rust بإنشاء operators خاصة بك أو تحميل operators عشوائية بشكل زائد. ولكن يمكنك تحميل العمليات والسمات المقابلة المدرجة في std::ops عن طريق تنفيذ traits المرتبطة بـ operator. على سبيل المثال، في القائمة 20-15، نقوم بتحميل المعامل + بشكل زائد لجمع مثيلين من Point معاً. نقوم بذلك عن طريق تنفيذ سمة Add على (هيكل) struct باسم Point.
use std::ops::Add;
#[derive(Debug, Copy, Clone, PartialEq)]
struct Point {
x: i32,
y: i32,
}
impl Add for Point {
type Output = Point;
fn add(self, other: Point) -> Point {
Point {
x: self.x + other.x,
y: self.y + other.y,
}
}
}
fn main() {
assert_eq!(
Point { x: 1, y: 0 } + Point { x: 2, y: 3 },
Point { x: 3, y: 3 }
);
}تقوم دالة add بجمع قيم x لمثيلين من Point وقيم y لمثيلين من Point لإنشاء Point جديد. تحتوي سمة Add على associated type يسمى Output يحدد النوع الذي تعيده دالة add.
generic type الافتراضي في هذا الكود موجود داخل سمة Add. إليك تعريفها:
#![allow(unused)]
fn main() {
trait Add<Rhs=Self> {
type Output;
fn add(self, rhs: Rhs) -> Self::Output;
}
}يجب أن يبدو هذا الكود مألوفاً بشكل عام: trait مع دالة واحدة و associated type. الجزء الجديد هو Rhs=Self: تسمى هذه الصيغة (معلمات النوع الافتراضية) default type parameters. تحدد معلمة النوع العام Rhs (اختصار لـ “الجانب الأيمن” right-hand side) نوع معلمة rhs في دالة add. إذا لم نحدد concrete type لـ Rhs عندما ننفذ سمة Add ، فسيتم تعيين نوع Rhs افتراضياً إلى Self ، والذي سيكون النوع الذي ننفذ Add عليه.
عندما نفذنا Add لـ Point ، استخدمنا الافتراضي لـ Rhs لأننا أردنا جمع مثيلين من Point. دعنا ننظر في مثال لتنفيذ سمة Add حيث نريد تخصيص نوع Rhs بدلاً من استخدام الافتراضي.
لدينا هيكلان، Millimeters و Meters ، يحملان قيمًا بوحدات مختلفة. يُعرف هذا التغليف الرقيق لنوع موجود في struct آخر باسم (نمط النوع الجديد) newtype pattern ، والذي نصفه بمزيد من التفصيل في قسم “تنفيذ السمات الخارجية باستخدام نمط النوع الجديد”. نريد جمع قيم بالمليمترات إلى قيم بالأمتار وجعل تنفيذ Add يقوم بالتحويل بشكل صحيح. يمكننا تنفيذ Add لـ Millimeters مع Meters كـ Rhs ، كما هو موضح في القائمة 20-16.
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}لجمع Millimeters و Meters ، نحدد impl Add<Meters> لتعيين قيمة معلمة النوع Rhs بدلاً من استخدام الافتراضي Self.
ستستخدم default type parameters بطريقتين رئيسيتين:
- لتوسيع نوع دون كسر الكود الموجود.
- للسماح بالتخصيص في حالات محددة لن يحتاجها معظم المستخدمين.
سمة Add في المكتبة القياسية هي مثال على الغرض الثاني: عادةً، ستجمع نوعين متشابهين، لكن سمة Add توفر القدرة على التخصيص بما يتجاوز ذلك. استخدام default type parameter في تعريف سمة Add يعني أنك لست مضطراً لتحديد المعلمة الإضافية معظم الوقت. بعبارة أخرى، لا توجد حاجة لبعض (الأكواد المتكررة) boilerplate للتنفيذ، مما يسهل استخدام trait.
الغرض الأول مشابه للثاني ولكن بالعكس: إذا كنت تريد إضافة معلمة نوع إلى trait موجود، يمكنك إعطاؤها قيمة افتراضية للسماح بتوسيع وظائف trait دون كسر كود التنفيذ الحالي.
إزالة الغموض بين الدوال ذات الأسماء المتطابقة (Disambiguating Between Identically Named Methods)
لا يوجد شيء في Rust يمنع trait من امتلاك دالة بنفس اسم دالة trait آخر، ولا تمنعك Rust من تنفيذ كلا السمتين على نوع واحد. من الممكن أيضاً تنفيذ دالة مباشرة على النوع بنفس اسم الدوال من traits.
عند استدعاء دوال بنفس الاسم، ستحتاج إلى إخبار Rust بأيها تريد استخدامه. ضع في اعتبارك الكود في القائمة 20-17 حيث عرفنا سمتين، Pilot و Wizard ، كلاهما يمتلك دالة تسمى fly. ثم ننفذ كلا السمتين على نوع Human الذي يمتلك بالفعل دالة تسمى fly منفذة عليه. كل دالة fly تفعل شيئاً مختلفاً.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {}عندما نستدعي fly على مثيل من Human ، يقوم (المترجم) compiler افتراضياً باستدعاء الدالة المنفذة مباشرة على النوع، كما هو موضح في القائمة 20-18.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
person.fly();
}سيؤدي تشغيل هذا الكود إلى طباعة *waving arms furiously* ، مما يظهر أن Rust استدعت دالة fly المنفذة على Human مباشرة.
لاستدعاء دوال fly من سمة Pilot أو سمة Wizard ، نحتاج إلى استخدام صيغة أكثر صراحة لتحديد أي دالة fly نعنيها. توضح القائمة 20-19 هذه الصيغة.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
Pilot::fly(&person);
Wizard::fly(&person);
person.fly();
}تحديد اسم trait قبل اسم الدالة يوضح لـ Rust أي تنفيذ لـ fly نريد استدعاءه. يمكننا أيضاً الكتابة (لإزالة الغموض) disambiguate.
يؤدي تشغيل هذا الكود إلى طباعة ما يلي:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
لأن دالة fly تأخذ معلمة self ، إذا كان لدينا نوعان كلاهما ينفذ trait واحداً، فيمكن لـ Rust معرفة أي تنفيذ لـ trait يجب استخدامه بناءً على نوع self.
ومع ذلك، فإن (الدوال المرتبطة) associated functions التي ليست methods لا تحتوي على معلمة self. عندما يكون هناك عدة أنواع أو traits تعرف دوالاً ليست methods بنفس اسم الدالة، لا تعرف Rust دائماً النوع الذي تقصده ما لم تستخدم (الصيغة المؤهلة بالكامل) fully qualified syntax. على سبيل المثال، في القائمة 20-20، ننشئ trait لملجأ حيوانات يريد تسمية جميع الجراء Spot. نصنع سمة Animal مع دالة مرتبطة ليست method تسمى baby_name. يتم تنفيذ سمة Animal للهيكل Dog ، والذي نوفر عليه أيضاً دالة مرتبطة ليست method تسمى baby_name مباشرة.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Dog::baby_name());
}ننفذ الكود لتسمية جميع الجراء Spot في دالة baby_name المرتبطة المعرفة على Dog مباشرة. ينفذ نوع Dog أيضاً سمة Animal ، التي تصف الخصائص التي تمتلكها جميع الحيوانات. تسمى صغار الكلاب جراء (puppies)، ويتم التعبير عن ذلك في تنفيذ سمة Animal على Dog في دالة baby_name المرتبطة بسمة Animal.
في main ، نستدعي دالة Dog::baby_name ، التي تستدعي الدالة المرتبطة المعرفة على Dog مباشرة. يطبع هذا الكود ما يلي:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
هذا المخرج ليس ما أردناه. نريد استدعاء دالة baby_name التي هي جزء من سمة Animal التي نفذناها على Dog بحيث يطبع الكود A baby dog is called a puppy. تقنية تحديد اسم trait التي استخدمناها في القائمة 20-19 لا تساعد هنا؛ إذا قمنا بتغيير main إلى الكود في القائمة 20-21، فسنحصل على خطأ في الترجمة.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Animal::baby_name());
}لأن Animal::baby_name لا تحتوي على معلمة self ، وقد تكون هناك أنواع أخرى تنفذ سمة Animal ، لا تستطيع Rust معرفة أي تنفيذ لـ Animal::baby_name نريد. سنحصل على خطأ المترجم هذا:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:20:43
|
2 | fn baby_name() -> String;
| ------------------------- `Animal::baby_name` defined here
...
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
20 | println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
| +++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `traits-example` (bin "traits-example") due to 1 previous error
لإزالة الغموض وإخبار Rust أننا نريد استخدام تنفيذ Animal لـ Dog بدلاً من تنفيذ Animal لنوع آخر، نحتاج إلى استخدام fully qualified syntax. توضح القائمة 20-22 كيفية استخدام fully qualified syntax.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
}نحن نزود Rust بـ type annotation داخل الأقواس الزاوية، مما يشير إلى أننا نريد استدعاء دالة baby_name من سمة Animal كما هي منفذة على Dog من خلال القول بأننا نريد معاملة نوع Dog كـ Animal لاستدعاء هذه الدالة. سيطبع هذا الكود الآن ما نريد:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
بشكل عام، يتم تعريف fully qualified syntax كما يلي:
<Type as Trait>::function(receiver_if_method, next_arg, ...);بالنسبة للدوال المرتبطة التي ليست methods ، لن يكون هناك (مستقبل) receiver: سيكون هناك فقط قائمة الوسائط الأخرى. يمكنك استخدام fully qualified syntax في كل مكان تستدعي فيه دوالاً أو methods. ومع ذلك، يُسمح لك بحذف أي جزء من هذه الصيغة يمكن لـ Rust استنتاجه من معلومات أخرى في البرنامج. تحتاج فقط إلى استخدام هذه الصيغة الأكثر تفصيلاً في الحالات التي توجد فيها تطبيقات متعددة تستخدم نفس الاسم وتحتاج Rust إلى مساعدة لتحديد التطبيق الذي تريد استدعاءه.
استخدام السمات الفائقة (Using Supertraits)
أحياناً قد تكتب تعريف trait يعتمد على trait آخر: لكي ينفذ نوع ما السمة الأولى، تريد أن تطلب من ذلك النوع أيضاً تنفيذ السمة الثانية. ستفعل ذلك حتى يتمكن تعريف trait الخاص بك من الاستفادة من (العناصر المرتبطة) associated items للسمة الثانية. يسمى trait الذي يعتمد عليه تعريف trait الخاص بك بـ (السمة الفائقة) supertrait لسمتك.
على سبيل المثال، لنقل إننا نريد صنع سمة OutlinePrint مع دالة outline_print التي ستطبع قيمة معينة منسقة بحيث تكون مؤطرة بالنجوم. أي، بالنظر إلى هيكل Point الذي ينفذ سمة المكتبة القياسية Display لتكون النتيجة (x, y) ، عندما نستدعي outline_print على مثيل Point يحتوي على 1 لـ x و 3 لـ y ، يجب أن يطبع ما يلي:
**********
* *
* (1, 3) *
* *
**********
في تنفيذ دالة outline_print ، نريد استخدام وظائف سمة Display. لذلك، نحتاج إلى تحديد أن سمة OutlinePrint ستعمل فقط للأنواع التي تنفذ أيضاً Display وتوفر الوظائف التي تحتاجها OutlinePrint. يمكننا القيام بذلك في تعريف trait من خلال تحديد OutlinePrint: Display. هذه التقنية تشبه إضافة trait bound إلى trait. تعرض القائمة 20-23 تنفيذاً لسمة OutlinePrint.
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
fn main() {}لأننا حددنا أن OutlinePrint تتطلب سمة Display ، يمكننا استخدام دالة to_string التي يتم تنفيذها تلقائياً لأي نوع ينفذ Display. إذا حاولنا استخدام to_string دون إضافة نقطتين وتحديد سمة Display بعد اسم trait ، فسنحصل على خطأ يقول إنه لم يتم العثور على دالة باسم to_string للنوع &Self في النطاق الحالي.
دعنا نرى ما يحدث عندما نحاول تنفيذ OutlinePrint على نوع لا ينفذ Display ، مثل هيكل Point:
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}نحصل على خطأ يقول إن Display مطلوب ولكنه غير منفذ:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:23
|
20 | impl OutlinePrint for Point {}
| ^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:24:7
|
24 | p.outline_print();
| ^^^^^^^^^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint::outline_print`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint::outline_print`
4 | fn outline_print(&self) {
| ------------- required by a bound in this associated function
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` (bin "traits-example") due to 2 previous errors
لإصلاح ذلك، ننفذ Display على Point ونلبي القيد الذي تتطلبه OutlinePrint ، هكذا:
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
use std::fmt;
impl fmt::Display for Point {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "({}, {})", self.x, self.y)
}
}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}بعد ذلك، سيتم تجميع تنفيذ سمة OutlinePrint على Point بنجاح، ويمكننا استدعاء outline_print على مثيل Point لعرضه داخل إطار من النجوم.
تنفيذ السمات الخارجية باستخدام نمط النوع الجديد (Implementing External Traits with the Newtype Pattern)
في قسم “تنفيذ سمة على نوع” في الفصل العاشر، ذكرنا (قاعدة اليتيم) orphan rule التي تنص على أنه لا يُسمح لنا بتنفيذ trait على نوع إلا إذا كان trait أو النوع، أو كلاهما، محليين لـ (صندوقنا) crate. من الممكن التغلب على هذا القيد باستخدام newtype pattern ، والذي يتضمن إنشاء نوع جديد في (هيكل مجموعة) tuple struct. (غطينا tuple structs في قسم “إنشاء أنواع مختلفة باستخدام هياكل المجموعات” في الفصل الخامس). سيمتلك tuple struct حقلاً واحداً ويكون تغليفاً رقيقاً حول النوع الذي نريد تنفيذ trait له. بعد ذلك، يكون نوع التغليف محلياً لـ crate الخاص بنا، ويمكننا تنفيذ trait على التغليف. Newtype هو مصطلح ينبع من لغة البرمجة Haskell. لا توجد عقوبة على أداء وقت التشغيل لاستخدام هذا النمط، ويتم حذف نوع التغليف في وقت الترجمة.
كمثال، لنقل إننا نريد تنفيذ Display على Vec<T> ، وهو ما تمنعنا orphan rule من القيام به مباشرة لأن سمة Display ونوع Vec<T> معرفان خارج crate الخاص بنا. يمكننا صنع هيكل Wrapper يحمل مثيلاً من Vec<T> ؛ ثم يمكننا تنفيذ Display على Wrapper واستخدام قيمة Vec<T> ، كما هو موضح في القائمة 20-24.
use std::fmt;
struct Wrapper(Vec<String>);
impl fmt::Display for Wrapper {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "[{}]", self.0.join(", "))
}
}
fn main() {
let w = Wrapper(vec![String::from("hello"), String::from("world")]);
println!("w = {w}");
}يستخدم تنفيذ Display القيمة self.0 للوصول إلى Vec<T> الداخلي لأن Wrapper هو tuple struct و Vec<T> هو العنصر في الفهرس 0 في المجموعة. بعد ذلك، يمكننا استخدام وظائف سمة Display على Wrapper.
الجانب السلبي لاستخدام هذه التقنية هو أن Wrapper هو نوع جديد، لذا فهو لا يمتلك دوال القيمة التي يحملها. سيتعين علينا تنفيذ جميع دوال Vec<T> مباشرة على Wrapper بحيث تقوم الدوال بـ (التفويض) delegate إلى self.0 ، مما سيسمح لنا بمعاملة Wrapper تماماً مثل Vec<T>. إذا أردنا أن يمتلك النوع الجديد كل دالة يمتلكها النوع الداخلي، فإن تنفيذ سمة Deref على Wrapper لإعادة النوع الداخلي سيكون حلاً (ناقشنا تنفيذ سمة Deref في قسم “معاملة المؤشرات الذكية مثل المراجع العادية” في الفصل الخامس عشر). إذا لم نكن نريد أن يمتلك نوع Wrapper جميع دوال النوع الداخلي - على سبيل المثال، لتقييد سلوك نوع Wrapper - سيتعين علينا تنفيذ الدوال التي نريدها فقط يدوياً.
يعد newtype pattern مفيداً أيضاً حتى عندما لا تكون traits متضمنة. دعنا نغير التركيز وننظر في بعض الطرق المتقدمة للتفاعل مع نظام أنواع Rust.
الأنواع المتقدمة (Advanced Types)
أنواع متقدمة (Advanced Types)
يحتوي نظام الأنواع (type system) في Rust على بعض الميزات التي ذكرناها سابقاً ولكن لم نناقشها بعد. سنبدأ بمناقشة الأنواع الجديدة (newtypes) بشكل عام بينما نفحص سبب فائدتها كأنواع. بعد ذلك، سننتقل إلى الأسماء المستعارة للأنواع (type aliases)، وهي ميزة مشابهة لـ newtypes ولكن بدلالات (semantics) مختلفة قليلاً. سنناقش أيضاً نوع الـ ! والأنواع ذات الحجم الديناميكي (dynamically sized types).
سلامة الأنواع والتجريد باستخدام نمط الـ Newtype (Type Safety and Abstraction with the Newtype Pattern)
يفترض هذا القسم أنك قرأت القسم السابق “تطبيق السمات الخارجية باستخدام نمط الـ Newtype”. نمط الـ newtype مفيد أيضاً لمهام تتجاوز تلك التي ناقشناها حتى الآن، بما في ذلك فرض أن القيم لا يتم الخلط بينها أبداً بشكل ثابت (statically) والإشارة إلى وحدات القيمة. لقد رأيت مثالاً على استخدام newtypes للإشارة إلى الوحدات في القائمة 20-16: تذكر أن هياكل (structs) الـ Millimeters و Meters غلفت قيم u32 في newtype. إذا كتبنا دالة (function) بمعامل (parameter) من نوع Millimeters ، فلن نتمكن من تجميع برنامج حاول بالخطأ استدعاء تلك الـ function بقيمة من نوع Meters أو u32 عادي.
يمكننا أيضاً استخدام نمط الـ newtype لتجريد (abstract away) بعض تفاصيل التطبيق (implementation details) لنوع ما: يمكن للنوع الجديد كشف واجهة برمجة تطبيقات عامة (public API) تختلف عن الـ API للنوع الداخلي الخاص (private inner type).
يمكن لـ newtypes أيضاً إخفاء التطبيق الداخلي. على سبيل المثال، يمكننا توفير نوع People لتغليف HashMap<i32, String> يخزن معرف (ID) الشخص المرتبط باسمه. الكود الذي يستخدم People سيتفاعل فقط مع الـ public API الذي نوفره، مثل method لإضافة سلسلة نصية للاسم إلى مجموعة People ؛ لن يحتاج هذا الكود إلى معرفة أننا نخصص ID من نوع i32 للأسماء داخلياً. نمط الـ newtype هو طريقة خفيفة لتحقيق التغليف (encapsulation) لإخفاء implementation details ، والتي ناقشناها في قسم “التغليف الذي يخفي تفاصيل التطبيق” في الفصل الثامن عشر.
مرادفات الأنواع والأسماء المستعارة للأنواع (Type Synonyms and Type Aliases)
توفر Rust القدرة على التصريح عن اسم مستعار للنوع (type alias) لإعطاء نوع موجود اسماً آخر. لهذا نستخدم الكلمة المفتاحية type. على سبيل المثال، يمكننا إنشاء الـ alias المسمى Kilometers للنوع i32 هكذا:
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}الآن الـ alias المسمى Kilometers هو مرادف (synonym) لـ i32 ؛ على عكس نوعي Millimeters و Meters اللذين أنشأناهما في القائمة 20-16، فإن Kilometers ليس نوعاً جديداً ومنفصلاً. سيتم التعامل مع القيم التي لها النوع Kilometers بنفس طريقة التعامل مع قيم النوع i32:
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}لأن Kilometers و i32 هما نفس النوع، يمكننا إضافة قيم من كلا النوعين ويمكننا تمرير قيم Kilometers إلى functions تأخذ parameters من نوع i32. ومع ذلك، باستخدام هذه الطريقة، لا نحصل على فوائد فحص الأنواع (type-checking) التي نحصل عليها من نمط الـ newtype الذي ناقشناه سابقاً. بمعنى آخر، إذا خلطنا بين قيم Kilometers و i32 في مكان ما، فلن يعطينا المترجم (compiler) خطأً.
حالة الاستخدام الرئيسية لـ type synonyms هي تقليل التكرار. على سبيل المثال، قد يكون لدينا نوع طويل مثل هذا:
Box<dyn Fn() + Send + 'static>كتابة هذا النوع الطويل في تواقيع الدوال (function signatures) وكـ annotations للأنواع في كل مكان في الكود يمكن أن يكون متعباً وعرضة للخطأ. تخيل وجود مشروع مليء بكود مثل ذلك الموجود في القائمة 20-25.
fn main() {
let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi"));
fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) {
// --snip--
}
fn returns_long_type() -> Box<dyn Fn() + Send + 'static> {
// --snip--
Box::new(|| ())
}
}يجعل الـ type alias هذا الكود أكثر قابلية للإدارة عن طريق تقليل التكرار. في القائمة 20-26، قدمنا alias باسم Thunk للنوع المطول ويمكننا استبدال جميع استخدامات النوع بالـ alias الأقصر Thunk.
fn main() {
type Thunk = Box<dyn Fn() + Send + 'static>;
let f: Thunk = Box::new(|| println!("hi"));
fn takes_long_type(f: Thunk) {
// --snip--
}
fn returns_long_type() -> Thunk {
// --snip--
Box::new(|| ())
}
}هذا الكود أسهل بكثير في القراءة والكتابة! اختيار اسم ذو معنى لـ type alias يمكن أن يساعد في إيصال نيتك (intent) أيضاً (thunk هي كلمة لكود سيتم تقييمه في وقت لاحق، لذا فهو اسم مناسب لـ closure يتم تخزينه).
تُستخدم type aliases أيضاً بشكل شائع مع نوع Result<T, E> لتقليل التكرار. فكر في وحدة (module) الـ std::io في المكتبة القياسية (standard library). غالباً ما تعيد عمليات الإدخال/الإخراج (I/O) قيمة Result<T, E> للتعامل مع المواقف التي تفشل فيها العمليات. تحتوي هذه المكتبة على struct باسم std::io::Error يمثل جميع أخطاء I/O الممكنة. العديد من الـ functions في std::io ستعيد Result<T, E> حيث الـ E هي std::io::Error ، مثل هذه الـ functions في سمة (trait) الـ Write:
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}يتكرر Result<..., Error> كثيراً. على هذا النحو، لدى std::io هذا التصريح عن type alias:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}لأن هذا التصريح موجود في module الـ std::io ، يمكننا استخدام الـ alias المؤهل بالكامل std::io::Result<T> ؛ أي Result<T, E> مع ملء E كـ std::io::Error. تنتهي function signatures لـ trait الـ Write لتبدو هكذا:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}يساعد الـ type alias بطريقتين: يجعل الكود أسهل في الكتابة و يعطينا واجهة (interface) متسقة عبر كل std::io. ولأنه alias، فهو مجرد Result<T, E> آخر، مما يعني أنه يمكننا استخدام أي methods تعمل على Result<T, E> معه، بالإضافة إلى syntax خاص مثل عامل الـ ?.
نوع الـ Never الذي لا يعود أبداً (The Never Type That Never Returns)
لدى Rust نوع خاص باسم ! يُعرف في لغة نظرية الأنواع بـ النوع الفارغ (empty type) لأنه لا يحتوي على قيم. نحن نفضل تسميته نوع الـ never (never type) لأنه يقف في مكان نوع الإرجاع عندما لا تعود الـ function أبداً. إليك مثال:
fn bar() -> ! {
// --snip--
panic!();
}يُقرأ هذا الكود على أن “الـ function المسمى bar لا تعود أبداً”. الـ functions التي لا تعود أبداً تسمى دوال متباعدة (diverging functions). لا يمكننا إنشاء قيم من النوع ! ، لذا لا يمكن لـ bar أن تعود أبداً.
ولكن ما فائدة نوع لا يمكنك أبداً إنشاء قيم له؟ تذكر الكود من القائمة 2-5، وهو جزء من لعبة تخمين الأرقام؛ لقد أعدنا إنتاج جزء منه هنا في القائمة 20-27.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}في ذلك الوقت، تخطينا بعض التفاصيل في هذا الكود. في قسم “بنية التحكم في التدفق match” في الفصل السادس، ناقشنا أن أذرع (arms) الـ match يجب أن تعيد جميعها نفس النوع. لذا، على سبيل المثال، الكود التالي لا يعمل:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "hello",
};
}يجب أن يكون نوع guess في هذا الكود integer و string، وتتطلب Rust أن يكون لـ guess نوع واحد فقط. لذا، ماذا يعيد continue ؟ كيف سُمح لنا بإرجاع u32 من ذراع واحد وامتلاك ذراع آخر ينتهي بـ continue في القائمة 20-27؟
كما قد خمنت، لـ continue قيمة ! . أي عندما تحسب Rust نوع guess ، فإنها تنظر في كلا ذراعي match، الأول بقيمة u32 والثاني بقيمة ! . ولأن ! لا يمكن أن يكون له قيمة أبداً، تقرر Rust أن نوع guess هو u32.
الطريقة الرسمية لوصف هذا السلوك هي أن التعبيرات من النوع `!` يمكن إجبارها (coerced) على أي نوع آخر. يُسمح لنا بإنهاء ذراع الـ `match` هذا بـ `continue` لأن `continue` لا يعيد قيمة؛ بدلاً من ذلك، فإنه ينقل التحكم مرة أخرى إلى أعلى الحلقة (loop)، لذا في حالة الـ `Err` ، لا نقوم أبداً بتعيين قيمة لـ `guess`.
نوع الـ never مفيد مع ماكرو (macro) الـ `panic!` أيضاً. تذكر دالة الـ `unwrap` التي نستدعيها على قيم `Option<T>` لإنتاج قيمة أو الذعر (panic) بهذا التعريف:
```rust,ignore
# enum Option<T> {
# Some(T),
# None,
# }
#
# use crate::Option::*;
#
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}
في هذا الكود، يحدث نفس الشيء كما في الـ match في القائمة 20-27: ترى Rust أن val لها النوع T و panic! لها النوع ! ، لذا فإن نتيجة تعبير الـ match الإجمالي هي T. يعمل هذا الكود لأن panic! لا ينتج قيمة؛ بل ينهي البرنامج. في حالة الـ None ، لن نعيد قيمة من unwrap ، لذا فإن هذا الكود صالح.
تعبير أخير له النوع ! هو الحلقة (loop):
fn main() {
print!("forever ");
loop {
print!("and ever ");
}
}هنا، الـ loop لا تنتهي أبداً، لذا ! هي قيمة التعبير. ومع ذلك، لن يكون هذا صحيحاً إذا قمنا بتضمين break ، لأن الـ loop ستنتهي عندما تصل إلى الـ break.
الأنواع ذات الحجم الديناميكي وسمة الـ Sized (Dynamically Sized Types and the Sized Trait)
تحتاج Rust إلى معرفة تفاصيل معينة حول أنواعها، مثل مقدار المساحة التي يجب تخصيصها لقيمة من نوع معين. هذا يترك جانباً واحداً من نظام الأنواع الخاص بها مربكاً قليلاً في البداية: مفهوم الأنواع ذات الحجم الديناميكي (dynamically sized types). يُشار إليها أحياناً باسم DSTs أو الأنواع غير محددة الحجم (unsized types)، وتسمح لنا هذه الأنواع بكتابة كود باستخدام قيم لا يمكننا معرفة حجمها إلا في وقت التشغيل (runtime).
دعونا نتعمق في تفاصيل نوع ذو حجم ديناميكي يسمى str ، والذي كنا نستخدمه طوال الكتاب. هذا صحيح، ليس &str ، بل str بمفرده هو DST. في كثير من الحالات، مثل عند تخزين نص أدخله مستخدم، لا يمكننا معرفة طول السلسلة النصية حتى runtime. هذا يعني أنه لا يمكننا إنشاء متغير من نوع str ، ولا يمكننا أخذ وسيط (argument) من نوع str. فكر في الكود التالي، الذي لا يعمل:
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
}تحتاج Rust إلى معرفة مقدار الذاكرة التي يجب تخصيصها لأي قيمة من نوع معين، ويجب أن تستخدم جميع قيم النوع نفس مقدار الذاكرة. إذا سمحت لنا Rust بكتابة هذا الكود، فستحتاج قيمتا str هاتان إلى شغل نفس مقدار المساحة. لكن لهما أطوال مختلفة: s1 يحتاج إلى 12 بايت من التخزين و s2 يحتاج إلى 15. وهذا هو السبب في أنه ليس من الممكن إنشاء متغير يحمل نوعاً ذا حجم ديناميكي.
لذا، ماذا نفعل؟ في هذه الحالة، أنت تعرف الإجابة بالفعل: نجعل نوع s1 و s2 شريحة سلسلة نصية (string slice) (&str) بدلاً من str. تذكر من قسم “شرائح السلسلة النصية” في الفصل الرابع أن هيكل بيانات الشريحة (slice data structure) يخزن فقط موضع البداية وطول الشريحة. لذا، على الرغم من أن &T هي قيمة واحدة تخزن عنوان الذاكرة حيث يوجد T ، فإن string slice هي قيمتان: عنوان الـ str وطوله. على هذا النحو، يمكننا معرفة حجم قيمة string slice في وقت التجميع (compile time): إنه ضعف طول usize. أي أننا نعرف دائماً حجم string slice، بغض النظر عن طول السلسلة النصية التي يشير إليها. بشكل عام، هذه هي الطريقة التي تُستخدم بها dynamically sized types في Rust: لديها قدر إضافي من البيانات الوصفية (metadata) التي تخزن حجم المعلومات الديناميكية. القاعدة الذهبية للأنواع ذات الحجم الديناميكي هي أنه يجب علينا دائماً وضع قيم DSTs خلف مؤشر (pointer) من نوع ما.
يمكننا دمج str مع جميع أنواع الـ pointers: على سبيل المثال، Box<str> أو Rc<str>. في الواقع، لقد رأيت هذا من قبل ولكن مع نوع مختلف ذو حجم ديناميكي: السمات (traits). كل trait هو DST يمكننا الرجوع إليه باستخدام اسم الـ trait. في قسم “استخدام كائنات السمات للتجريد فوق السلوك المشترك” في الفصل الثامن عشر، ذكرنا أنه لاستخدام traits ككائنات سمات (trait objects)، يجب وضعها خلف pointer، مثل &dyn Trait أو Box<dyn Trait> (و Rc<dyn Trait> سيعمل أيضاً).
للعمل مع DSTs، توفر Rust سمة الـ Sized لتحديد ما إذا كان حجم النوع معروفاً في compile time أم لا. يتم تطبيق هذه الـ trait تلقائياً لكل شيء يُعرف حجمه في compile time. بالإضافة إلى ذلك، تضيف Rust ضمناً قيداً (bound) على Sized لكل دالة عامة (generic function). أي أن تعريف generic function مثل هذا:
fn generic<T>(t: T) {
// --snip--
}يتم التعامل معه فعلياً كما لو كنا قد كتبنا هذا:
fn generic<T: Sized>(t: T) {
// --snip--
}بشكل افتراضي، ستعمل generic functions فقط على الأنواع التي لها حجم معروف في compile time. ومع ذلك، يمكنك استخدام الـ syntax الخاص التالي لتخفيف هذا القيد:
fn generic<T: ?Sized>(t: &T) {
// --snip--
}قيد الـ trait على ?Sized يعني “T قد يكون أو لا يكون Sized “، وهذا الترميز يتجاوز الافتراضي بأن الأنواع العامة يجب أن يكون لها حجم معروف في compile time. الـ syntax الخاص بـ ?Trait بهذا المعنى متاح فقط لـ Sized ، وليس لأي traits أخرى.
لاحظ أيضاً أننا قمنا بتغيير نوع المعامل t من T إلى &T. ولأن النوع قد لا يكون Sized ، نحتاج إلى استخدامه خلف نوع من الـ pointers. في هذه الحالة، اخترنا مرجعاً (reference).
بعد ذلك، سنتحدث عن الدوال والإغلاقات (closures)!
الدوال والإغلاقات المتقدمة
الدوال والإغلاقات المتقدمة (Advanced Functions and Closures)
يستكشف هذا القسم بعض الميزات المتقدمة المتعلقة بالدوال والإغلاقات (closures)، بما في ذلك مؤشرات الدوال (function pointers) وإرجاع الإغلاقات.
مؤشرات الدوال (Function Pointers)
لقد تحدثنا عن كيفية تمرير الإغلاقات (closures) إلى الدوال؛ يمكنك أيضًا تمرير الدوال العادية إلى الدوال! هذه التقنية مفيدة عندما تريد تمرير دالة قمت بتعريفها بالفعل بدلاً من تعريف إغلاق جديد. تتحول الدوال تلقائيًا إلى النوع fn (بحرف f صغير)، ولا ينبغي الخلط بينه وبين سمة الإغلاق Fn. يسمى النوع fn بـ مؤشر الدالة (function pointer). سيسمح لك تمرير الدوال باستخدام مؤشرات الدوال باستخدام الدوال كمعاملات (arguments) لدوال أخرى.
إن بناء الجملة (syntax) لتحديد أن المعامل هو مؤشر دالة يشبه بناء جملة الإغلاقات، كما هو موضح في القائمة 20-28، حيث قمنا بتعريف دالة add_one تضيف 1 إلى معاملها. تأخذ الدالة do_twice معاملين: مؤشر دالة لأي دالة تأخذ معامل i32 وترجع i32 وقيمة i32 واحدة. تستدعي الدالة do_twice الدالة f مرتين، وتمرر لها قيمة arg ثم تجمع نتيجتي استدعاء الدالة معًا. تستدعي الدالة main الدالة do_twice بالمعاملات add_one و 5.
fn add_one(x: i32) -> i32 {
x + 1
}
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {
f(arg) + f(arg)
}
fn main() {
let answer = do_twice(add_one, 5);
println!("The answer is: {answer}");
}يطبع هذا الكود The answer is: 12. نحدد أن المعامل f في do_twice هو fn يأخذ معاملًا واحدًا من النوع i32 ويرجع i32. يمكننا بعد ذلك استدعاء f في جسم do_twice. في main يمكننا تمرير اسم الدالة add_one كمعامل أول لـ do_twice.
على عكس الإغلاقات، فإن fn هو نوع (type) وليس سمة (trait)، لذا نحدد fn كنوع المعامل مباشرةً بدلاً من التصريح عن معامل نوع عام (generic type parameter) مع إحدى سمات Fn كقيد سمة (trait bound).
تنفذ مؤشرات الدوال جميع سمات الإغلاق الثلاث (Fn و FnMut و FnOnce) مما يعني أنه يمكنك دائمًا تمرير مؤشر دالة كمعامل لدالة تتوقع إغلاقًا. من الأفضل كتابة الدوال باستخدام نوع عام وإحدى سمات الإغلاق حتى تتمكن دوالك من قبول إما دوال أو إغلاقات.
ومع ذلك، فإن أحد الأمثلة على الحالات التي قد ترغب فيها في قبول fn فقط وليس الإغلاقات هو عند التعامل مع كود خارجي لا يحتوي على إغلاقات: يمكن لدوال C قبول الدوال كمعاملات، لكن لغة C لا تحتوي على إغلاقات.
كمثال على المكان الذي يمكنك فيه استخدام إغلاق محدد في السطر (inline closure) أو دالة مسماة، دعنا ننظر إلى استخدام طريقة map التي توفرها سمة Iterator في المكتبة القياسية (standard library). لاستخدام طريقة map لتحويل متجه (vector) من الأرقام إلى متجه من السلاسل النصية (strings)، يمكننا استخدام إغلاق، كما في القائمة 20-29.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(|i| i.to_string()).collect();
}أو يمكننا تسمية دالة كمعامل لـ map بدلاً من الإغلاق. توضح القائمة 20-30 كيف سيبدو هذا.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(ToString::to_string).collect();
}لاحظ أنه يجب علينا استخدام بناء الجملة المؤهل بالكامل (fully qualified syntax) الذي تحدثنا عنه في قسم “السمات المتقدمة” لأن هناك دوال متعددة متاحة باسم to_string.
هنا، نستخدم دالة to_string المعرفة في سمة ToString والتي نفذتها المكتبة القياسية لأي نوع ينفذ Display.
تذكر من قسم “قيم التعداد” في الفصل 6 أن اسم كل متغير تعداد (enum variant) نقوم بتعريفه يصبح أيضًا دالة تهيئة (initializer function). يمكننا استخدام دوال التهيئة هذه كمؤشرات دوال تنفذ سمات الإغلاق، مما يعني أنه يمكننا تحديد دوال التهيئة كمعاملات للطرق التي تأخذ إغلاقات، كما هو موضح في القائمة 20-31.
fn main() {
enum Status {
Value(u32),
Stop,
}
let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect();
}هنا، نقوم بإنشاء مثيلات Status::Value باستخدام كل قيمة u32 في النطاق الذي يتم استدعاء map عليه باستخدام دالة التهيئة لـ Status::Value. يفضل بعض الأشخاص هذا الأسلوب ويفضل البعض الآخر استخدام الإغلاقات. يتم ترجمتها (compile) إلى نفس الكود، لذا استخدم الأسلوب الأوضح بالنسبة لك.
إرجاع الإغلاقات (Returning Closures)
يتم تمثيل الإغلاقات بواسطة السمات، مما يعني أنه لا يمكنك إرجاع الإغلاقات مباشرةً. في معظم الحالات التي قد ترغب فيها في إرجاع سمة، يمكنك بدلاً من ذلك استخدام النوع الملموس (concrete type) الذي ينفذ السمة كقيمة إرجاع للدالة. ومع ذلك، لا يمكنك عادةً القيام بذلك مع الإغلاقات لأنها لا تملك نوعًا ملموسًا يمكن إرجاعه؛ لا يُسمح لك باستخدام مؤشر الدالة fn كنوع إرجاع إذا كان الإغلاق يلتقط أي قيم من نطاقه (scope)، على سبيل المثال.
بدلاً من ذلك، ستستخدم عادةً بناء جملة impl Trait الذي تعلمناه في الفصل 10. يمكنك إرجاع أي نوع دالة باستخدام Fn و FnOnce و FnMut. على سبيل المثال، سيتم ترجمة الكود الموجود في القائمة 20-32 بشكل جيد تمامًا.
#![allow(unused)]
fn main() {
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
}ومع ذلك، كما لاحظنا في قسم “استنتاج وتحديد أنواع الإغلاق” في الفصل 13، فإن كل إغلاق هو أيضًا نوعه المتميز الخاص. إذا كنت بحاجة إلى العمل مع دوال متعددة لها نفس التوقيع (signature) ولكن بتنفيذات مختلفة، فستحتاج إلى استخدام كائن سمة (trait object) لها. فكر فيما يحدث إذا كتبت كودًا مثل الموضح في القائمة 20-33.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
move |x| x + init
}هنا لدينا دالتان، returns_closure و returns_initialized_closure وكلاهما يرجعان impl Fn(i32) -> i32. لاحظ أن الإغلاقات التي يرجعانها مختلفة، على الرغم من أنها تنفذ نفس النوع. إذا حاولنا ترجمة هذا، فإن Rust تخبرنا أنه لن يعمل:
$ cargo build
Compiling functions-example v0.1.0 (file:///projects/functions-example)
error[E0308]: mismatched types
--> src/main.rs:2:44
|
2 | let handlers = vec![returns_closure(), returns_initialized_closure(123)];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected opaque type, found a different opaque type
...
9 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ------------------- the expected opaque type
...
13 | fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
| ------------------- the found opaque type
|
= note: expected opaque type `impl Fn(i32) -> i32`
found opaque type `impl Fn(i32) -> i32`
= note: distinct uses of `impl Trait` result in different opaque types
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions-example` (bin "functions-example") due to 1 previous error
تخبرنا رسالة الخطأ أنه كلما أرجعنا impl Trait فإن Rust تنشئ نوعًا معتمًا (opaque type) فريدًا، وهو نوع لا يمكننا رؤية تفاصيل ما تبنيه Rust لنا فيه، ولا يمكننا تخمين النوع الذي ستنشئه Rust لنكتبه بأنفسنا. لذا، على الرغم من أن هذه الدوال ترجع إغلاقات تنفذ نفس السمة Fn(i32) -> i32 إلا أن الأنواع المعتمة التي تنشئها Rust لكل منها متميزة. (هذا مشابه لكيفية إنتاج Rust لأنواع ملموسة مختلفة لكتل async المتميزة حتى عندما يكون لها نفس نوع الإخراج، كما رأينا في “النوع Pin وسمة Unpin” في الفصل 17). لقد رأينا حلاً لهذه المشكلة عدة مرات الآن: يمكننا استخدام كائن سمة، كما في القائمة 20-34.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
fn returns_initialized_closure(init: i32) -> Box<dyn Fn(i32) -> i32> {
Box::new(move |x| x + init)
}سيتم ترجمة هذا الكود بشكل جيد تمامًا. لمزيد من المعلومات حول كائنات السمات، ارجع إلى قسم “استخدام كائنات السمات للتجريد من السلوك المشترك” في الفصل 18.
بعد ذلك، دعنا ننظر إلى الماكرو (macros)!
الماكرو (Macros)
الماكرو (Macros)
لقد استخدمنا macros مثل println! في جميع أنحاء هذا الكتاب، لكننا لم نستكشف بالكامل ما هو الـ macro وكيف يعمل. يشير مصطلح macro إلى مجموعة من الميزات في Rust - الـ macros التصريحية (declarative macros) باستخدام macro_rules! وثلاثة أنواع من الـ macros الإجرائية (procedural macros):
- الـ custom
#[derive]macros التي تحدد الكود المضاف باستخدام السمة (attribute)deriveالمستخدمة على الـ structs والـ enums. - الـ attribute-like macros التي تحدد attributes مخصصة قابلة للاستخدام على أي عنصر.
- الـ function-like macros التي تبدو وكأنها استدعاءات دالة ولكنها تعمل على الرموز (tokens) المحددة كوسيطة لها.
سنتحدث عن كل من هذه الأنواع بالتتابع، ولكن أولاً، دعنا ننظر إلى سبب حاجتنا إلى الـ macros بينما لدينا بالفعل دوال (functions).
الفرق بين الـ Macros والدوال
بشكل أساسي، الـ macros هي طريقة لكتابة كود يكتب كودًا آخر، وهو ما يُعرف باسم البرمجة الوصفية (metaprogramming). في الملحق ج، نناقش الـ attribute derive، الذي يولد تطبيقًا (implementation) لسمات (traits) مختلفة لك. لقد استخدمنا أيضًا الـ macros println! و vec! في جميع أنحاء الكتاب. كل هذه الـ macros تتوسع (expand) لإنتاج كود أكثر من الكود الذي كتبته يدويًا.
الـ metaprogramming مفيدة لتقليل كمية الكود الذي يتعين عليك كتابته وصيانته، وهو أيضًا أحد أدوار الـ functions. ومع ذلك، تتمتع الـ macros ببعض الصلاحيات الإضافية التي لا تتمتع بها الـ functions.
يجب أن يحدد توقيع الـ function عدد ونوع المعلمات (parameters) التي تحتوي عليها الـ function. من ناحية أخرى، يمكن أن تأخذ الـ macros عددًا متغيرًا من الـ parameters: يمكننا استدعاء println!("hello") بوسيطة واحدة أو println!("hello {}", name) بوسيطتين. أيضًا، يتم توسيع الـ macros قبل أن يفسر المترجم (compiler) معنى الكود، لذلك يمكن للـ macro، على سبيل المثال، تطبيق trait على نوع معين. لا يمكن للـ function ذلك، لأنه يتم استدعاؤها في وقت التشغيل (runtime) ويجب تطبيق الـ trait في وقت التجميع (compile time).
الجانب السلبي لتطبيق macro بدلاً من function هو أن تعريفات الـ macro أكثر تعقيدًا من تعريفات الـ function لأنك تكتب كود Rust يكتب كود Rust. بسبب هذا التوسط (indirection)، تكون تعريفات الـ macro بشكل عام أكثر صعوبة في القراءة والفهم والصيانة من تعريفات الـ function.
هناك فرق مهم آخر بين الـ macros والـ functions وهو أنه يجب عليك تعريف الـ macros أو إحضارها إلى النطاق (scope) قبل استدعائها في ملف، على عكس الـ functions التي يمكنك تعريفها في أي مكان واستدعائها في أي مكان.
الـ Declarative Macros للـ Metaprogramming العام
الشكل الأكثر استخدامًا للـ macros في Rust هو الـ declarative macro. يشار إليها أحيانًا باسم “macros by example” أو “macro_rules! macros” أو ببساطة “macros”. في جوهرها، تسمح لك الـ declarative macros بكتابة شيء مشابه لتعبير match في Rust. كما نوقش في الفصل 6، تعبيرات match هي هياكل تحكم تأخذ تعبيرًا، وتقارن القيمة الناتجة للتعبير بالأنماط (patterns)، ثم تقوم بتشغيل الكود المرتبط بالـ pattern المطابق. تقارن الـ macros أيضًا قيمة بالـ patterns المرتبطة بكود معين: في هذا الموقف، القيمة هي كود مصدر Rust الحرفي الذي تم تمريره إلى الـ macro؛ تتم مقارنة الـ patterns بهيكل كود المصدر هذا؛ والكود المرتبط بكل pattern، عند مطابقته، يحل محل الكود الذي تم تمريره إلى الـ macro. يحدث كل هذا أثناء الـ compilation.
لتعريف macro، تستخدم البنية macro_rules!. دعنا نستكشف كيفية استخدام macro_rules! من خلال النظر في كيفية تعريف الـ macro vec!. غطى الفصل 8 كيف يمكننا استخدام الـ macro vec! لإنشاء متجه (vector) جديد بقيم معينة. على سبيل المثال، ينشئ الـ macro التالي vector جديدًا يحتوي على ثلاثة أعداد صحيحة:
#![allow(unused)]
fn main() {
let v: Vec<u32> = vec![1, 2, 3];
}يمكننا أيضًا استخدام الـ macro vec! لإنشاء vector من عددين صحيحين أو vector من خمس شرائح string (string slices). لن نتمكن من استخدام function للقيام بنفس الشيء لأننا لن نعرف عدد أو نوع القيم مقدمًا.
تُظهر القائمة 20-35 تعريفًا مبسطًا قليلاً للـ macro vec!.
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}ملاحظة: يتضمن التعريف الفعلي للـ macro
vec!في المكتبة القياسية كودًا لتخصيص الكمية الصحيحة من الذاكرة مقدمًا. هذا الكود هو تحسين (optimization) لا ندرجه هنا، لجعل المثال أبسط.
يشير التعليق التوضيحي #[macro_export] إلى أنه يجب إتاحة هذا الـ macro كلما تم إحضار الصندوق (crate) الذي تم تعريف الـ macro فيه إلى الـ scope. بدون هذا التعليق التوضيحي، لا يمكن إحضار الـ macro إلى الـ scope.
نبدأ بعد ذلك تعريف الـ macro بـ macro_rules! واسم الـ macro الذي نقوم بتعريفه بدون علامة التعجب. يتبع الاسم، في هذه الحالة vec، بأقواس متعرجة تشير إلى نص تعريف الـ macro.
الهيكل في نص vec! مشابه لهيكل تعبير match. لدينا هنا ذراع (arm) واحد مع الـ pattern ( $( $x:expr ),* )، متبوعًا بـ => وكتلة الكود المرتبطة بهذا الـ pattern. إذا تطابق الـ pattern، فسيتم إصدار كتلة الكود المرتبطة. نظرًا لأن هذا هو الـ pattern الوحيد في هذا الـ macro، فهناك طريقة واحدة صالحة فقط للمطابقة؛ سيؤدي أي pattern آخر إلى حدوث خطأ. سيكون للـ macros الأكثر تعقيدًا أكثر من ذراع واحد.
يختلف بناء جملة الـ pattern الصالح في تعريفات الـ macro عن بناء جملة الـ pattern الذي تم تناوله في الفصل 19 لأن الـ macro patterns تتم مطابقتها مع هيكل كود Rust بدلاً من القيم. دعنا نطلع على ما تعنيه أجزاء الـ pattern في القائمة 20-29؛ للحصول على بناء جملة الـ macro pattern الكامل، راجع مرجع Rust.
أولاً، نستخدم مجموعة من الأقواس لاحتواء الـ pattern بالكامل. نستخدم علامة الدولار ($) للإعلان عن متغير في نظام الـ macro سيحتوي على كود Rust الذي يطابق الـ pattern. تجعل علامة الدولار من الواضح أن هذا متغير macro بدلاً من متغير Rust عادي. بعد ذلك تأتي مجموعة من الأقواس التي تلتقط القيم التي تطابق الـ pattern داخل الأقواس لاستخدامها في كود الاستبدال. داخل $() يوجد $x:expr، الذي يطابق أي تعبير Rust ويعطي التعبير الاسم $x.
تشير الفاصلة التي تلي $() إلى أنه يجب أن تظهر فاصلة حرفية فاصلة بين كل مثيل للكود الذي يطابق الكود في $(). يحدد الرمز * أن الـ pattern يطابق صفرًا أو أكثر مما يسبق الرمز *.
عندما نستدعي هذا الـ macro بـ vec![1, 2, 3];، يطابق الـ pattern $x ثلاث مرات مع التعبيرات الثلاثة 1 و 2 و 3.
الآن دعنا ننظر إلى الـ pattern في نص الكود المرتبط بهذا الـ arm: يتم إنشاء temp_vec.push() داخل $()* لكل جزء يطابق $() في الـ pattern صفرًا أو أكثر من المرات اعتمادًا على عدد المرات التي يطابق فيها الـ pattern. يتم استبدال $x بكل تعبير مطابق. عندما نستدعي هذا الـ macro بـ vec![1, 2, 3];، سيكون الكود الذي تم إنشاؤه والذي يحل محل استدعاء الـ macro هذا هو التالي:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}لقد قمنا بتعريف macro يمكنه أخذ أي عدد من الوسائط من أي نوع ويمكنه إنشاء كود لإنشاء vector يحتوي على العناصر المحددة.
لمعرفة المزيد حول كيفية كتابة الـ macros، راجع الوثائق عبر الإنترنت أو الموارد الأخرى، مثل “The Little Book of Rust Macros” الذي بدأه Daniel Keep وواصله Lukas Wirth.
الـ Procedural Macros لإنشاء الكود من الـ Attributes
الشكل الثاني من الـ macros هو الـ procedural macro، الذي يعمل أشبه بـ function (وهو نوع من الإجراءات). تقبل الـ procedural macros بعض الكود كمدخل، وتعمل على هذا الكود، وتنتج بعض الكود كمخرج بدلاً من المطابقة مع الـ patterns واستبدال الكود بكود آخر كما تفعل الـ declarative macros. الأنواع الثلاثة من الـ procedural macros هي derive المخصص، والـ attribute-like، والـ function-like، وجميعها تعمل بطريقة مماثلة.
عند إنشاء الـ procedural macros، يجب أن توجد التعريفات في صندوقها الخاص بنوع صندوق خاص. هذا لأسباب تقنية معقدة نأمل في التخلص منها في المستقبل. في القائمة 20-36، نوضح كيفية تعريف procedural macro، حيث some_attribute هو عنصر نائب لاستخدام نوع macro معين.
use proc_macro::TokenStream;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}تأخذ الـ function التي تحدد procedural macro TokenStream كمدخل وتنتج TokenStream كمخرج. يتم تعريف النوع TokenStream بواسطة الـ crate proc_macro المضمن مع Rust ويمثل تسلسلًا من الـ tokens. هذا هو جوهر الـ macro: الكود المصدري الذي يعمل عليه الـ macro يشكل الـ input TokenStream، والكود الذي ينتجه الـ macro هو الـ output TokenStream. تحتوي الـ function أيضًا على attribute مرفق بها يحدد نوع الـ procedural macro الذي نقوم بإنشائه. يمكن أن يكون لدينا أنواع متعددة من الـ procedural macros في نفس الـ crate.
دعنا ننظر إلى الأنواع المختلفة من الـ procedural macros. سنبدأ بـ custom derive macro ثم نشرح الاختلافات الصغيرة التي تجعل الأشكال الأخرى مختلفة.
الـ Custom derive Macros
دعنا ننشئ crate يسمى hello_macro يحدد trait يسمى HelloMacro مع function واحدة مرتبطة تسمى hello_macro. بدلاً من جعل مستخدمينا يطبقون الـ trait HelloMacro لكل نوع من أنواعهم، سنوفر procedural macro بحيث يمكن للمستخدمين إضافة تعليق توضيحي لنوعهم بـ #[derive(HelloMacro)] للحصول على تطبيق افتراضي لـ function hello_macro. سيطبع التطبيق الافتراضي Hello, Macro! My name is TypeName! حيث TypeName هو اسم النوع الذي تم تعريف هذا الـ trait عليه. بعبارة أخرى، سنكتب crate يمكّن مبرمجًا آخر من كتابة كود مثل القائمة 20-37 باستخدام الـ crate الخاص بنا.
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}سيقوم هذا الكود بطباعة Hello, Macro! My name is Pancakes! عندما ننتهي. الخطوة الأولى هي إنشاء library crate جديد، مثل هذا:
$ cargo new hello_macro --lib
pub trait HelloMacro {
fn hello_macro();
}لدينا trait و function خاص به. في هذه المرحلة، يمكن لمستخدم الـ crate الخاص بنا تطبيق الـ trait لتحقيق الوظيفة المطلوبة، كما في القائمة 20-39.
use hello_macro::HelloMacro;
struct Pancakes;
impl HelloMacro for Pancakes {
fn hello_macro() {
println!("Hello, Macro! My name is Pancakes!");
}
}
fn main() {
Pancakes::hello_macro();
}ومع ذلك، سيحتاجون إلى كتابة كتلة التطبيق لكل نوع يريدون استخدامه مع hello_macro؛ نريد أن نوفر عليهم القيام بهذا العمل.
بالإضافة إلى ذلك، لا يمكننا حتى الآن توفير function hello_macro بتطبيق افتراضي سيطبع اسم النوع الذي تم تطبيق الـ trait عليه: لا تمتلك Rust إمكانيات الانعكاس (reflection)، لذلك لا يمكنها البحث عن اسم النوع في الـ runtime. نحتاج إلى macro لإنشاء كود في الـ compile time.
الخطوة التالية هي تعريف الـ procedural macro. في وقت كتابة هذا التقرير، يجب أن تكون الـ procedural macros في الـ crate الخاص بها. في النهاية، قد يتم رفع هذا القيد. الاصطلاح لهيكلة الـ crates والـ macro crates هو كما يلي: بالنسبة لـ crate يسمى foo، يسمى الـ custom derive procedural macro crate بـ foo_derive. دعنا نبدأ crate جديدًا يسمى hello_macro_derive داخل مشروع hello_macro الخاص بنا:
$ cargo new hello_macro_derive --lib
الـ crates الخاصان بنا مرتبطان ارتباطًا وثيقًا، لذلك نقوم بإنشاء الـ procedural macro crate داخل دليل الـ crate hello_macro الخاص بنا. إذا قمنا بتغيير تعريف الـ trait في hello_macro، فسيتعين علينا تغيير تطبيق الـ procedural macro في hello_macro_derive أيضًا. سيحتاج الـ crates إلى النشر بشكل منفصل، وسيحتاج المبرمجون الذين يستخدمون هذه الـ crates إلى إضافتها كـ dependencies وإحضار كليهما إلى الـ scope. يمكننا بدلاً من ذلك أن نجعل الـ crate hello_macro يستخدم hello_macro_derive كـ dependency ويعيد تصدير كود الـ procedural macro. ومع ذلك، فإن الطريقة التي قمنا بها بهيكلة المشروع تجعل من الممكن للمبرمجين استخدام hello_macro حتى لو لم يرغبوا في وظيفة derive.
نحتاج إلى الإعلان عن الـ crate hello_macro_derive كـ procedural macro crate. سنحتاج أيضًا إلى وظيفة من الـ crates syn و quote، كما سترى بعد قليل، لذلك نحتاج إلى إضافتها كـ dependencies. أضف ما يلي إلى ملف Cargo.toml لـ hello_macro_derive:
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
لبدء تعريف الـ procedural macro، ضع الكود في القائمة 20-40 في ملف src/lib.rs الخاص بك لـ crate hello_macro_derive. لاحظ أن هذا الكود لن يتم تجميعه حتى نضيف تعريفًا لـ function impl_hello_macro.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate.
let ast = syn::parse(input).unwrap();
// Build the trait implementation.
impl_hello_macro(&ast)
}لاحظ أننا قسمنا الكود إلى function hello_macro_derive، وهي المسؤولة عن parse الـ TokenStream، و function impl_hello_macro، وهي المسؤولة عن تحويل شجرة بناء الجملة (syntax tree): هذا يجعل كتابة procedural macro أكثر ملاءمة. سيكون الكود في الـ function الخارجية (hello_macro_derive في هذه الحالة) هو نفسه تقريبًا لكل procedural macro crate تراه أو تنشئه. سيكون الكود الذي تحدده في نص الـ function الداخلية (impl_hello_macro في هذه الحالة) مختلفًا اعتمادًا على الغرض من الـ procedural macro الخاص بك.
لقد قدمنا ثلاثة crates جديدة: proc_macro، و syn، و quote. يأتي الـ crate proc_macro مع Rust، لذلك لم نكن بحاجة إلى إضافته إلى الـ dependencies في Cargo.toml. الـ crate proc_macro هو واجهة برمجة تطبيقات (API) المترجم التي تسمح لنا بقراءة ومعالجة كود Rust من الكود الخاص بنا.
يقوم الـ crate syn بـ parse كود Rust من string إلى هيكل بيانات يمكننا إجراء عمليات عليه. يقوم الـ crate quote بتحويل هياكل بيانات syn مرة أخرى إلى كود Rust. تجعل هذه الـ crates من السهل جدًا parse أي نوع من كود Rust قد نرغب في التعامل معه: كتابة parser كامل لكود Rust ليست مهمة بسيطة.
سيتم استدعاء function hello_macro_derive عندما يحدد مستخدم مكتبتنا #[derive(HelloMacro)] على نوع. هذا ممكن لأننا أضفنا تعليقًا توضيحيًا لـ function hello_macro_derive هنا بـ proc_macro_derive وحددنا الاسم HelloMacro، الذي يطابق اسم الـ trait الخاص بنا؛ هذا هو الاصطلاح الذي تتبعه معظم الـ procedural macros.
تقوم function hello_macro_derive أولاً بتحويل الـ input من TokenStream إلى هيكل بيانات يمكننا بعد ذلك تفسيره وإجراء عمليات عليه. هذا هو المكان الذي يأتي فيه دور syn. تأخذ function parse في syn TokenStream وتُرجع struct DeriveInput يمثل كود Rust الذي تم عمل parse له. تُظهر القائمة 20-41 الأجزاء ذات الصلة من struct DeriveInput التي نحصل عليها من parse الـ string struct Pancakes;.
DeriveInput {
// --snip--
ident: Ident {
ident: "Pancakes",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}تُظهر fields هذا الـ struct أن كود Rust الذي قمنا بـ parse له هو unit struct مع الـ ident (المعرف، بمعنى الاسم) لـ Pancakes. هناك المزيد من الـ fields على هذا الـ struct لوصف جميع أنواع كود Rust؛ تحقق من وثائق syn لـ DeriveInput لمزيد من المعلومات.
قريبًا سنقوم بتعريف function impl_hello_macro، وهو المكان الذي سنقوم فيه ببناء كود Rust الجديد الذي نريد تضمينه. ولكن قبل أن نفعل ذلك، لاحظ أن الخرج لـ derive macro الخاص بنا هو أيضًا TokenStream. تتم إضافة الـ TokenStream المُرجع إلى الكود الذي يكتبه مستخدمو الـ crate الخاص بنا، لذلك عندما يقومون بـ compile الـ crate الخاص بهم، سيحصلون على الوظيفة الإضافية التي نوفرها في الـ TokenStream المعدل.
ربما لاحظت أننا نستدعي unwrap لجعل function hello_macro_derive يحدث لها panic! إذا فشل استدعاء function syn::parse هنا. من الضروري أن يحدث panic! لـ procedural macro الخاص بنا عند حدوث أخطاء لأن functions proc_macro_derive يجب أن تُرجع TokenStream بدلاً من Result لتتوافق مع API الـ procedural macro. لقد قمنا بتبسيط هذا المثال باستخدام unwrap؛ في كود الإنتاج، يجب عليك توفير رسائل خطأ أكثر تحديدًا حول ما حدث بشكل خاطئ باستخدام panic! أو expect.
الآن بعد أن أصبح لدينا الكود لتحويل كود Rust المشروح من TokenStream إلى مثيل DeriveInput، دعنا ننشئ الكود الذي يطبق الـ trait HelloMacro على النوع المشروح، كما هو موضح في القائمة 20-42.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let generated = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
generated.into()
}نحصل على مثيل struct Ident يحتوي على اسم (المعرف) النوع المشروح باستخدام ast.ident. يُظهر الـ struct في القائمة 20-41 أنه عندما نقوم بتشغيل function impl_hello_macro على الكود في القائمة 20-37، فإن الـ ident الذي نحصل عليه سيكون له الـ field ident بقيمة "Pancakes". وبالتالي، سيحتوي المتغير name في القائمة 20-42 على مثيل struct Ident، والذي عند طباعته، سيكون الـ string "Pancakes"، وهو اسم الـ struct في القائمة 20-37.
يسمح لنا الـ macro quote! بتعريف كود Rust الذي نريد إرجاعه. يتوقع المترجم شيئًا مختلفًا عن النتيجة المباشرة لتنفيذ الـ macro quote!، لذلك نحتاج إلى تحويله إلى TokenStream. نقوم بذلك عن طريق استدعاء الـ method into، الذي يستهلك هذا التمثيل الوسيط ويُرجع قيمة من النوع TokenStream المطلوب.
يوفر الـ macro quote! أيضًا بعض آليات القوالب الرائعة: يمكننا إدخال #name، وسيحل محله quote! بالقيمة الموجودة في المتغير name. يمكنك حتى القيام ببعض التكرار المشابه للطريقة التي تعمل بها الـ macros العادية. تحقق من وثائق الـ crate quote للحصول على مقدمة شاملة.
نريد أن يقوم الـ procedural macro الخاص بنا بإنشاء تطبيق لـ trait HelloMacro الخاص بنا للنوع الذي قام المستخدم بشرحه، والذي يمكننا الحصول عليه باستخدام #name. يحتوي تطبيق الـ trait على function واحدة hello_macro، التي يحتوي نصها على الوظيفة التي نريد توفيرها: طباعة Hello, Macro! My name is ثم اسم النوع المشروح.
الـ macro stringify! المستخدم هنا مدمج في Rust. يأخذ تعبير Rust، مثل 1 + 2، وفي الـ compile time يحول التعبير إلى string literal، مثل "1 + 2". هذا يختلف عن format! أو println!، وهما macros يقومان بتقييم التعبير ثم تحويل النتيجة إلى String. هناك احتمال أن يكون الـ input #name تعبيرًا للطباعة حرفيًا، لذلك نستخدم stringify!. يوفر استخدام stringify! أيضًا تخصيصًا عن طريق تحويل #name إلى string literal في الـ compile time.
في هذه المرحلة، يجب أن يكتمل cargo build بنجاح في كل من hello_macro و hello_macro_derive. دعنا نربط هذه الـ crates بالكود في القائمة 20-37 لرؤية الـ procedural macro في العمل! قم بإنشاء مشروع ثنائي جديد في دليل projects الخاص بك باستخدام cargo new pancakes. نحتاج إلى إضافة hello_macro و hello_macro_derive كـ dependencies في Cargo.toml الخاص بـ crate pancakes. إذا كنت تنشر إصداراتك من hello_macro و hello_macro_derive على crates.io، فستكون dependencies عادية؛ إذا لم يكن كذلك، يمكنك تحديدها كـ dependencies path على النحو التالي:
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
ضع الكود في القائمة 20-37 في src/main.rs، وقم بتشغيل cargo run: يجب أن يطبع Hello, Macro! My name is Pancakes!. تم تضمين تطبيق الـ trait HelloMacro من الـ procedural macro دون أن يحتاج الـ crate pancakes إلى تطبيقه؛ أضاف #[derive(HelloMacro)] تطبيق الـ trait.
بعد ذلك، دعنا نستكشف كيف تختلف الأنواع الأخرى من الـ procedural macros عن الـ custom derive macros.
الـ Attribute-Like Macros
الـ attribute-like macros مشابهة لـ custom derive macros، ولكن بدلاً من إنشاء كود لـ attribute derive، فإنها تسمح لك بإنشاء attributes جديدة. إنها أيضًا أكثر مرونة: يعمل derive فقط مع الـ structs والـ enums؛ يمكن تطبيق الـ attributes على عناصر أخرى أيضًا، مثل الـ functions. إليك مثال على استخدام attribute-like macro. لنفترض أن لديك attribute يسمى route يشرح الـ functions عند استخدام إطار عمل لتطبيق ويب:
#[route(GET, "/")]
fn index() {سيتم تعريف attribute #[route] هذا بواسطة إطار العمل كـ procedural macro. سيبدو توقيع function تعريف الـ macro كما يلي:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {هنا، لدينا معلمات من النوع TokenStream. الأول هو لمحتويات الـ attribute: الجزء GET, "/". والثاني هو نص العنصر المرفق به الـ attribute: في هذه الحالة، fn index() {} وبقية نص الـ function.
بخلاف ذلك، تعمل الـ attribute-like macros بنفس طريقة عمل الـ custom derive macros: تقوم بإنشاء crate بنوع الـ crate proc-macro وتطبيق function ينشئ الكود الذي تريده!
الـ Function-Like Macros
الـ function-like macros هي الشكل الثالث من الـ procedural macros. على عكس الـ declarative macros، التي تعمل عن طريق المطابقة مع الـ patterns، تعمل الـ function-like macros عن طريق أخذ TokenStream كمدخل وإرجاع TokenStream كخرج. على سبيل المثال، يمكن أن يكون لديك macro يسمى sql! يقوم بـ parse محتويات string ويتحقق من صحة بناء جملة SQL داخله.
let sql = sql!(SELECT * FROM posts WHERE id=1);سيبدو توقيع function تعريف الـ macro كما يلي:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {هذا مشابه لـ custom derive macros، ولكن بدلاً من أن يكون له attribute يحدد نوع الـ macro، فإن function تعريف الـ macro لها attribute #[proc_macro]، وتأخذ TokenStream واحدًا كمدخل.
المشروع النهائي: بناء خادم ويب متعدد الخيوط (Multithreaded)
لقد كانت رحلة طويلة، ولكننا وصلنا إلى نهاية الكتاب. في هذا الفصل، سنقوم ببناء مشروع إضافي معًا لعرض بعض المفاهيم التي تناولناها في الفصول الأخيرة، بالإضافة إلى استعراض بعض الدروس السابقة.
في مشروعنا النهائي، سننشئ خادم ويب يعرض رسالة “مرحبًا!” ويبدو كما هو موضح في الشكل 21-1 في متصفح الويب.
إليك خطتنا لبناء خادم الويب:
- التعرف على بروتوكولات TCP و HTTP.
- الاستماع إلى اتصالات TCP على الـ socket.
- تحليل عدد صغير من طلبات HTTP.
- إنشاء استجابة HTTP صحيحة.
- تحسين معدل النقل/الإنتاجية (Throughput) لخادمنا بواسطة تجمع الخيوط (Thread Pool).
الشكل 21-1: مشروعنا النهائي المشترك
قبل أن نبدأ، يجب أن نذكر نقطتين. أولاً، الطريقة التي سنستخدمها لن تكون أفضل طريقة لبناء خادم ويب باستخدام Rust. فقد نشر أعضاء المجتمع عددًا من الحزم (crates) الجاهزة للاستخدام الإنتاجي والمتوفرة على crates.io والتي تقدم تنفيذات أكثر شمولاً لخوادم الويب وتجمعات الخيوط من تلك التي سنبنيها. ولكن هدفنا في هذا الفصل هو مساعدتك على التعلم، وليس اتباع الطريق الأسهل. وبما أن Rust هي لغة برمجة أنظمة (Systems Programming Language)، يمكننا اختيار مستوى التجريد الذي نريد العمل به ويمكننا النزول إلى مستوى أدنى مما هو ممكن أو عملي في لغات أخرى.
ثانيًا، لن نستخدم هنا مفاهيمي async و await. بناء تجمع الخيوط (Thread Pool) هو تحدٍ كبير بذاته، بدون أن نضيف بناء بيئة تشغيل غير متزامنة (async runtime)! ومع ذلك، سنشير إلى كيف يمكن أن يكون async و await ذا تطبيق لبعض نفس المشاكل التي سنراها في هذا الفصل. في النهاية، كما ذكرنا في الفصل 17، كثير من بيئات التشغيل غير المتزامنة تستخدم تجمعات الخيوط لإدارة أعمالها.
لذلك، سنقوم بكتابة خادم HTTP الأساسي وتجمع الخيوط يدويًا بحيث تتمكن من التعرف على الأفكار والتقنيات العامة وراء الحزم التي قد تستخدمها في المستقبل.
بناء خادم ويب أحادي الخيط
بناء خادم ويب أحادي المسار (Building a Single-Threaded Web Server)
سنبدأ بتشغيل (خادم ويب أحادي المسار) single-threaded web server. قبل أن نبدأ، دعنا نلقي نظرة سريعة على (البروتوكولات) protocols المتضمنة في بناء خوادم الويب. تفاصيل هذه البروتوكولات خارج نطاق هذا الكتاب، لكن نظرة عامة موجزة ستعطيك المعلومات التي تحتاجها.
البروتوكولان الرئيسيان المتضمنان في خوادم الويب هما (بروتوكول نقل النص التشعبي) Hypertext Transfer Protocol (HTTP) و (بروتوكول التحكم في الإرسال) Transmission Control Protocol (TCP). كلا البروتوكولين هما بروتوكولات (طلب-استجابة) request-response ، مما يعني أن (العميل) client يبدأ الطلبات و (الخادم) server يستمع إلى الطلبات ويقدم استجابة للعميل. يتم تحديد محتويات تلك الطلبات والاستجابات بواسطة البروتوكولات.
TCP هو البروتوكول من المستوى الأدنى الذي يصف تفاصيل كيفية انتقال المعلومات من خادم إلى آخر ولكنه لا يحدد ماهية تلك المعلومات. يبني HTTP فوق TCP من خلال تحديد محتويات الطلبات والاستجابات. من الممكن تقنياً استخدام HTTP مع بروتوكولات أخرى، ولكن في الغالبية العظمى من الحالات، يرسل HTTP بياناته عبر TCP. سنعمل مع (البايتات الخام) raw bytes لطلبات واستجابات TCP و HTTP.
الاستماع إلى اتصال TCP (Listening to the TCP Connection)
يحتاج خادم الويب الخاص بنا إلى الاستماع إلى (اتصال TCP) TCP connection ، لذا فهذا هو الجزء الأول الذي سنعمل عليه. توفر المكتبة القياسية وحدة std::net التي تتيح لنا القيام بذلك. لننشئ مشروعاً جديداً بالطريقة المعتادة:
$ cargo new hello
Created binary (application) `hello` project
$ cd hello
الآن أدخل الكود الموجود في القائمة 21-1 في src/main.rs للبدء. سيستمع هذا الكود عند العنوان المحلي 127.0.0.1:7878 لـ (تدفقات TCP) TCP streams القادمة. عندما يتلقى تدفقاً قادماً، سيطبع Connection established!.
use std::net::TcpListener;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
println!("Connection established!");
}
}باستخدام TcpListener ، يمكننا الاستماع لاتصالات TCP عند العنوان 127.0.0.1:7878. في العنوان، الجزء الذي يسبق النقطتين هو (عنوان IP) IP address يمثل جهاز الكمبيوتر الخاص بك (هذا هو نفسه على كل جهاز كمبيوتر ولا يمثل جهاز المؤلفين تحديداً)، و 7878 هو (المنفذ) port. لقد اخترنا هذا المنفذ لسببين: لا يتم قبول HTTP عادةً على هذا المنفذ، لذا فمن غير المرجح أن يتعارض خادمنا مع أي خادم ويب آخر قد يكون قيد التشغيل على جهازك، و 7878 هي كلمة rust المكتوبة على الهاتف.
تعمل دالة bind في هذا السيناريو مثل دالة new حيث ستعيد مثيلاً جديداً من TcpListener. تسمى الدالة bind لأنه في الشبكات، يُعرف الاتصال بمنفذ للاستماع إليه باسم “(الربط بمنفذ) binding to a port”.
تعيد دالة bind نوع Result<T, E> ، مما يشير إلى أنه من الممكن أن يفشل الربط، على سبيل المثال، إذا قمنا بتشغيل مثيلين من برنامجنا وبالتالي كان هناك برنامجان يستمعان إلى نفس المنفذ. لأننا نكتب خادماً أساسياً لأغراض التعلم فقط، فلن نقلق بشأن التعامل مع هذه الأنواع من الأخطاء؛ بدلاً من ذلك، نستخدم unwrap لإيقاف البرنامج في حالة حدوث أخطاء.
تعيد دالة incoming على TcpListener (مكرراً) iterator يعطينا سلسلة من التدفقات (بشكل أكثر تحديداً، تدفقات من النوع TcpStream). يمثل (التدفق) stream الواحد اتصالاً مفتوحاً بين العميل والخادم. (الاتصال) Connection هو الاسم لعملية الطلب والاستجابة الكاملة التي يتصل فيها العميل بالخادم، ويقوم الخادم بإنشاء استجابة، ويغلق الخادم الاتصال. على هذا النحو، سنقرأ من TcpStream لنرى ما أرسله العميل ثم نكتب استجابتنا إلى التدفق لإرسال البيانات مرة أخرى إلى العميل. بشكل عام، ستقوم حلقة for هذه بمعالجة كل اتصال بدوره وإنتاج سلسلة من التدفقات لنتعامل معها.
في الوقت الحالي، تتكون معالجتنا للتدفق من استدعاء unwrap لإنهاء برنامجنا إذا كان التدفق يحتوي على أي أخطاء؛ إذا لم تكن هناك أخطاء، يطبع البرنامج رسالة. سنضيف المزيد من الوظائف لحالة النجاح في القائمة التالية. السبب في أننا قد نتلقى أخطاء من دالة incoming عندما يتصل عميل بالخادم هو أننا لا نتنقل فعلياً عبر الاتصالات. بدلاً من ذلك، نحن نتنقل عبر (محاولات الاتصال) connection attempts. قد لا يكون الاتصال ناجحاً لعدد من الأسباب، وكثير منها خاص بنظام التشغيل. على سبيل المثال، تمتلك العديد من أنظمة التشغيل حداً لعدد الاتصالات المفتوحة المتزامنة التي يمكنها دعمها؛ ستؤدي محاولات الاتصال الجديدة التي تتجاوز هذا العدد إلى حدوث خطأ حتى يتم إغلاق بعض الاتصالات المفتوحة.
دعنا نحاول تشغيل هذا الكود! استدعِ cargo run في (الطرفية) terminal ثم قم بتحميل 127.0.0.1:7878 في متصفح الويب. يجب أن يظهر المتصفح رسالة خطأ مثل “Connection reset” لأن الخادم لا يرسل حالياً أي بيانات. ولكن عندما تنظر إلى الطرفية الخاصة بك، يجب أن ترى عدة رسائل تمت طباعتها عندما اتصل المتصفح بالخادم!
Running `target/debug/hello`
Connection established!
Connection established!
Connection established!
أحياناً سترى رسائل متعددة مطبوعة لطلب متصفح واحد؛ قد يكون السبب هو أن المتصفح يقدم طلباً للصفحة بالإضافة إلى طلب لموارد أخرى، مثل أيقونة favicon.ico التي تظهر في علامة تبويب المتصفح.
قد يكون السبب أيضاً هو أن المتصفح يحاول الاتصال بالخادم عدة مرات لأن الخادم لا يستجيب بأي بيانات. عندما يخرج stream عن النطاق ويتم (إسقاطه) dropped في نهاية الحلقة، يتم إغلاق الاتصال كجزء من تنفيذ drop. تتعامل المتصفحات أحياناً مع الاتصالات المغلقة عن طريق إعادة المحاولة، لأن المشكلة قد تكون مؤقتة.
تفتح المتصفحات أيضاً أحياناً اتصالات متعددة بالخادم دون إرسال أي طلبات بحيث إذا أرسلت طلبات لاحقاً، يمكن أن تتم تلك الطلبات بسرعة أكبر. عندما يحدث هذا، سيرى خادمنا كل اتصال، بغض النظر عما إذا كانت هناك أي طلبات عبر ذلك الاتصال. تقوم العديد من إصدارات المتصفحات المستندة إلى Chrome بذلك، على سبيل المثال؛ يمكنك تعطيل هذا (التحسين) optimization باستخدام وضع التصفح الخاص أو استخدام متصفح مختلف.
العامل المهم هو أننا حصلنا بنجاح على (مقبض) handle لاتصال TCP!
تذكر إيقاف البرنامج بالضغط على ctrl-C عندما تنتهي من تشغيل إصدار معين من الكود. ثم أعد تشغيل البرنامج باستدعاء أمر cargo run بعد إجراء كل مجموعة من تغييرات الكود للتأكد من أنك تقوم بتشغيل أحدث كود.
قراءة الطلب (Reading the Request)
لننفذ الوظيفة لقراءة الطلب من المتصفح! لفصل (الاهتمامات) concerns بين الحصول على اتصال أولاً ثم اتخاذ إجراء ما مع الاتصال، سنبدأ دالة جديدة لمعالجة الاتصالات. في دالة handle_connection الجديدة هذه، سنقرأ البيانات من تدفق TCP ونطبعها حتى نتمكن من رؤية البيانات التي يتم إرسالها من المتصفح. قم بتغيير الكود ليبدو مثل القائمة 21-2.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
println!("Request: {http_request:#?}");
}نقوم بجلب std::io::BufReader و std::io::prelude إلى النطاق للوصول إلى traits والأنواع التي تتيح لنا القراءة من التدفق والكتابة إليه. في حلقة for في دالة main ، بدلاً من طباعة رسالة تقول إننا أجرينا اتصالاً، نستدعي الآن دالة handle_connection الجديدة ونمرر stream إليها.
في دالة handle_connection ، ننشئ مثيلاً جديداً من BufReader يغلف (مرجعاً) reference للتدفق. يضيف BufReader (تخزيناً مؤقتاً) buffering عن طريق إدارة الاستدعاءات لطرق std::io::Read trait من أجلنا.
ننشئ متغيراً باسم http_request لجمع أسطر الطلب الذي يرسله المتصفح إلى خادمنا. نشير إلى أننا نريد جمع هذه الأسطر في (متجه) vector عن طريق إضافة توضيح النوع Vec<_>.
ينفذ BufReader السمة std::io::BufRead ، التي توفر دالة lines. تعيد دالة lines مكرراً من Result<String, std::io::Error> عن طريق تقسيم تدفق البيانات كلما رأت بايت (سطر جديد) newline. للحصول على كل String ، نقوم بـ map و unwrap لكل Result. قد يكون Result خطأ إذا لم تكن البيانات (ترميز UTF-8) UTF-8 صالحاً أو إذا كانت هناك مشكلة في القراءة من التدفق. مرة أخرى، يجب أن يتعامل برنامج الإنتاج مع هذه الأخطاء بشكل أكثر لباقة، لكننا نختار إيقاف البرنامج في حالة الخطأ للتبسيط.
يشير المتصفح إلى نهاية طلب HTTP عن طريق إرسال حرفي سطر جديد متتاليين، لذا للحصول على طلب واحد من التدفق، نأخذ الأسطر حتى نحصل على سطر عبارة عن سلسلة فارغة. بمجرد جمع الأسطر في المتجه، نقوم بطباعتها باستخدام (تنسيق التصحيح الجميل) pretty debug formatting حتى نتمكن من إلقاء نظرة على التعليمات التي يرسلها متصفح الويب إلى خادمنا.
دعنا نجرب هذا الكود! ابدأ البرنامج وقدم طلباً في متصفح الويب مرة أخرى. لاحظ أننا سنظل نحصل على صفحة خطأ في المتصفح، لكن مخرج برنامجنا في الطرفية سيبدو الآن مشابهاً لهذا:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
اعتماداً على متصفحك، قد تحصل على مخرج مختلف قليلاً. الآن بعد أن قمنا بطباعة بيانات الطلب، يمكننا أن نرى لماذا نحصل على اتصالات متعددة من طلب متصفح واحد من خلال النظر في المسار بعد GET في السطر الأول من الطلب. إذا كانت الاتصالات المتكررة تطلب جميعها / ، فنحن نعلم أن المتصفح يحاول جلب / بشكل متكرر لأنه لا يتلقى استجابة من برنامجنا.
دعنا نحلل بيانات الطلب هذه لفهم ما يطلبه المتصفح من برنامجنا.
نظرة فاحصة على طلب HTTP (Looking More Closely at an HTTP Request)
HTTP هو بروتوكول يعتمد على النص، ويأخذ الطلب هذا التنسيق:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
السطر الأول هو (سطر الطلب) request line الذي يحتوي على معلومات حول ما يطلبه العميل. الجزء الأول من سطر الطلب هو (الطريقة) method المستخدمة، مثل GET أو POST ، والتي تصف كيفية تقديم العميل لهذا الطلب. استخدم عميلنا طلب GET ، مما يعني أنه يطلب معلومات.
الجزء التالي من سطر الطلب هو / ، والذي يشير إلى (معرف المورد الموحد) uniform resource identifier (URI) الذي يطلبه العميل: URI هو تقريباً، ولكن ليس تماماً، نفس (محدد موقع الموارد الموحد) uniform resource locator (URL). الفرق بين URIs و URLs ليس مهماً لأغراضنا في هذا الفصل، لكن مواصفات HTTP تستخدم المصطلح URI ، لذا يمكننا فقط استبدال URL بـ URI ذهنياً هنا.
الجزء الأخير هو إصدار HTTP الذي يستخدمه العميل، ثم ينتهي سطر الطلب بتسلسل CRLF. (يرمز CRLF إلى carriage return و line feed (رجوع العربة وتغذية السطر)، وهي مصطلحات من أيام الآلة الكاتبة!) يمكن أيضاً كتابة تسلسل CRLF كـ \r\n ، حيث \r هو رجوع العربة و \n هو تغذية السطر. يفصل (تسلسل CRLF) CRLF sequence سطر الطلب عن بقية بيانات الطلب. لاحظ أنه عند طباعة CRLF ، نرى بداية سطر جديد بدلاً من \r\n.
بالنظر إلى بيانات سطر الطلب التي تلقيناها من تشغيل برنامجنا حتى الآن، نرى أن GET هي الطريقة، و / هو request URI ، و HTTP/1.1 هو الإصدار.
بعد سطر الطلب، الأسطر المتبقية بدءاً من Host: فصاعداً هي (رؤوس) headers. طلبات GET ليس لها (جسم) body.
حاول تقديم طلب من متصفح مختلف أو طلب عنوان مختلف، مثل 127.0.0.1:7878/test ، لترى كيف تتغير بيانات الطلب.
الآن بعد أن عرفنا ما يطلبه المتصفح، دعنا نرسل بعض البيانات!
كتابة استجابة (Writing a Response)
سنقوم بتنفيذ إرسال البيانات استجابة لطلب العميل. تأخذ الاستجابات التنسيق التالي:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
السطر الأول هو (سطر الحالة) status line الذي يحتوي على إصدار HTTP المستخدم في الاستجابة، و (رمز حالة) status code رقمي يلخص نتيجة الطلب، و (عبارة سبب) reason phrase تقدم وصفاً نصياً لرمز الحالة. بعد تسلسل CRLF توجد أي رؤوس، وتسلسل CRLF آخر، وجسم الاستجابة.
إليك مثال على استجابة تستخدم إصدار HTTP 1.1 ولديها رمز حالة 200، وعبارة سبب OK ، ولا توجد رؤوس، ولا يوجد جسم:
HTTP/1.1 200 OK\r\n\r\n
رمز الحالة 200 هو استجابة النجاح القياسية. النص هو استجابة HTTP ناجحة صغيرة جداً. لنكتب هذا في التدفق كاستجابتنا لطلب ناجح! من دالة handle_connection ، قم بإزالة println! التي كانت تطبع بيانات الطلب واستبدلها بالكود الموجود في القائمة 21-3.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let response = "HTTP/1.1 200 OK\r\n\r\n";
stream.write_all(response.as_bytes()).unwrap();
}يحدد السطر الجديد الأول متغير response الذي يحمل بيانات رسالة النجاح. بعد ذلك، نستدعي as_bytes على استجابتنا لتحويل بيانات السلسلة النصية إلى بايتات. تأخذ دالة write_all على stream نوع &[u8] وترسل تلك البايتات مباشرة عبر الاتصال. لأن عملية write_all قد تفشل، نستخدم unwrap على أي نتيجة خطأ كما فعلنا سابقاً. مرة أخرى، في تطبيق حقيقي، ستضيف معالجة الأخطاء هنا.
مع هذه التغييرات، دعنا نشغل الكود الخاص بنا ونقدم طلباً. لم نعد نطبع أي بيانات في الطرفية، لذا لن نرى أي مخرج بخلاف المخرج من Cargo. عندما تقوم بتحميل 127.0.0.1:7878 في متصفح الويب، يجب أن تحصل على صفحة فارغة بدلاً من خطأ. لقد قمت للتو ببرمجة استلام طلب HTTP وإرسال استجابة يدوياً!
إرجاع HTML حقيقي (Returning Real HTML)
لننفذ الوظيفة لإرجاع أكثر من صفحة فارغة. أنشئ الملف الجديد hello.html في جذر دليل مشروعك، وليس في دليل src. يمكنك إدخال أي HTML تريده؛ تعرض القائمة 21-4 أحد الاحتمالات.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
هذا مستند HTML5 بسيط مع عنوان وبعض النص. لإرجاع هذا من الخادم عند استلام طلب، سنقوم بتعديل handle_connection كما هو موضح في القائمة 21-5 لقراءة ملف HTML ، وإضافته إلى الاستجابة كجسم، وإرساله.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
// --snip--
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}لقد أضفنا fs إلى عبارة use لجلب وحدة نظام الملفات في المكتبة القياسية إلى النطاق. يجب أن يبدو كود قراءة محتويات ملف إلى سلسلة نصية مألوفاً؛ استخدمناه عندما قرأنا محتويات ملف لمشروع الإدخال/الإخراج الخاص بنا في القائمة 12-4.
بعد ذلك، نستخدم format! لإضافة محتويات الملف كجسم لاستجابة النجاح. لضمان استجابة HTTP صالحة، نضيف رأس Content-Length ، والذي يتم ضبطه على حجم جسم الاستجابة الخاص بنا - في هذه الحالة، حجم hello.html.
شغل هذا الكود باستخدام cargo run وقم بتحميل 127.0.0.1:7878 في متصفحك؛ يجب أن ترى HTML الخاص بك معروضاً!
حالياً، نحن نتجاهل بيانات الطلب في http_request ونرسل فقط محتويات ملف HTML دون قيد أو شرط. هذا يعني أنه إذا حاولت طلب 127.0.0.1:7878/something-else في متصفحك، فستظل تحصل على نفس استجابة HTML هذه. في الوقت الحالي، خادمنا محدود للغاية ولا يفعل ما تفعله معظم خوادم الويب. نريد تخصيص استجاباتنا اعتماداً على الطلب وإرسال ملف HTML فقط لطلب جيد التنسيق إلى /.
التحقق من الطلب والاستجابة بشكل انتقائي (Validating the Request and Selectively Responding)
في الوقت الحالي، سيعيد خادم الويب الخاص بنا HTML الموجود في الملف بغض النظر عما طلبه العميل. لنضف وظيفة للتحقق من أن المتصفح يطلب / قبل إرجاع ملف HTML وإرجاع خطأ إذا طلب المتصفح أي شيء آخر. لهذا نحتاج إلى تعديل handle_connection ، كما هو موضح في القائمة 21-6. يتحقق هذا الكود الجديد من محتوى الطلب المستلم مقابل ما نعرف أن طلباً لـ / يبدو عليه ويضيف كتل if و else لمعالجة الطلبات بشكل مختلف.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// --snip--
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
} else {
// some other request
}
}سننظر فقط في السطر الأول من طلب HTTP ، لذا بدلاً من قراءة الطلب بالكامل في متجه، نستدعي next للحصول على العنصر الأول من المكرر. يتولى unwrap الأول التعامل مع Option ويوقف البرنامج إذا لم يكن المكرر يحتوي على عناصر. يتعامل unwrap الثاني مع Result وله نفس تأثير unwrap الذي كان في map المضاف في القائمة 21-2.
بعد ذلك، نتحقق من request_line لنرى ما إذا كان يساوي سطر طلب لطلب GET إلى مسار /. إذا كان الأمر كذلك، فإن كتلة if تعيد محتويات ملف HTML الخاص بنا.
إذا كان request_line لا يساوي طلب GET إلى مسار / ، فهذا يعني أننا تلقينا طلباً آخر. سنضيف كوداً إلى كتلة else بعد قليل للاستجابة لجميع الطلبات الأخرى.
شغل هذا الكود الآن واطلب 127.0.0.1:7878 ؛ يجب أن تحصل على HTML في hello.html. إذا قمت بإجراء أي طلب آخر، مثل 127.0.0.1:7878/something-else ، فستحصل على خطأ في الاتصال مثل تلك التي رأيتها عند تشغيل الكود في القائمة 21-1 والقائمة 21-2.
الآن لنضف الكود الموجود في القائمة 21-7 إلى كتلة else لإرجاع استجابة برمز الحالة 404، والذي يشير إلى أن المحتوى المطلوب لم يتم العثور عليه. سنعيد أيضاً بعض HTML لصفحة يتم عرضها في المتصفح تشير إلى الاستجابة للمستخدم النهائي.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
// --snip--
} else {
let status_line = "HTTP/1.1 404 NOT FOUND";
let contents = fs::read_to_string("404.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
}
}هنا، استجابتنا لها سطر حالة برمز الحالة 404 وعبارة السبب NOT FOUND. سيكون جسم الاستجابة هو HTML الموجود في الملف 404.html. ستحتاج إلى إنشاء ملف 404.html بجوار hello.html لصفحة الخطأ؛ مرة أخرى، لا تتردد في استخدام أي HTML تريده، أو استخدم عينة HTML في القائمة 21-8.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
مع هذه التغييرات، شغل خادمك مرة أخرى. يجب أن يؤدي طلب 127.0.0.1:7878 إلى إرجاع محتويات hello.html ، وأي طلب آخر، مثل 127.0.0.1:7878/foo ، يجب أن يعيد خطأ HTML من 404.html.
إعادة الهيكلة (Refactoring)
في الوقت الحالي، تحتوي كتل if و else على الكثير من التكرار: كلاهما يقرأ الملفات ويكتب محتويات الملفات في التدفق. الاختلافات الوحيدة هي سطر الحالة واسم الملف. لنحول الكود ليكون أكثر إيجازاً عن طريق استخراج تلك الاختلافات في أسطر if و else منفصلة ستقوم بتعيين قيم سطر الحالة واسم الملف إلى متغيرات؛ يمكننا بعد ذلك استخدام تلك المتغيرات دون قيد أو شرط في الكود لقراءة الملف وكتابة الاستجابة. تعرض القائمة 21-9 الكود الناتج بعد استبدال كتل if و else الكبيرة.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// --snip--
fn handle_connection(mut stream: TcpStream) {
// --snip--
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = if request_line == "GET / HTTP/1.1" {
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}الآن تعيد كتل if و else فقط القيم المناسبة لسطر الحالة واسم الملف في (مجموعة) tuple ؛ ثم نستخدم (تفكيك البنية) destructuring لتعيين هاتين القيمتين لـ status_line و filename باستخدام نمط في عبارة let ، كما تمت مناقشته في الفصل 19.
أصبح الكود الذي كان مكرراً سابقاً الآن خارج كتل if و else ويستخدم متغيرات status_line و filename. هذا يسهل رؤية الفرق بين الحالتين، ويعني أن لدينا مكاناً واحداً فقط لتحديث الكود إذا أردنا تغيير كيفية عمل قراءة الملف وكتابة الاستجابة. سيكون سلوك الكود في القائمة 21-9 هو نفسه الموجود في القائمة 21-7.
رائع! لدينا الآن خادم ويب بسيط في حوالي 40 سطراً من كود Rust يستجيب لطلب واحد بصفحة من المحتوى ويستجيب لجميع الطلبات الأخرى باستجابة 404.
حالياً، يعمل خادمنا في مسار واحد، مما يعني أنه يمكنه فقط خدمة طلب واحد في كل مرة. دعنا نفحص كيف يمكن أن يكون ذلك مشكلة من خلال محاكاة بعض الطلبات البطيئة. بعد ذلك، سنقوم بإصلاحها بحيث يمكن لخادمنا التعامل مع طلبات متعددة في وقت واحد.
من خادم أحادي الخيط إلى خادم متعدد الخيوط
من خادم أحادي المسار إلى خادم متعدد المسارات (Multithreaded)
في الوقت الحالي، يقوم الخادم بمعالجة كل طلب بالترتيب، مما يعني أنه لن يعالج اتصالاً ثانياً حتى ينتهي من معالجة الاتصال الأول. إذا تلقى الخادم المزيد والمزيد من الطلبات، فسيكون هذا التنفيذ التسلسلي أقل كفاءة بشكل متزايد. إذا تلقى الخادم طلباً يستغرق وقتاً طويلاً للمعالجة، فستضطر الطلبات اللاحقة إلى الانتظار حتى ينتهي الطلب الطويل، حتى لو كان من الممكن معالجة الطلبات الجديدة بسرعة. سنحتاج إلى إصلاح ذلك، ولكن أولاً سنلقي نظرة على المشكلة بشكل عملي.
محاكاة طلب بطيء
سنلقي نظرة على كيفية تأثير طلب بطيء المعالجة على الطلبات الأخرى المقدمة إلى تنفيذ الخادم الحالي لدينا. تنفذ القائمة 21-10 معالجة طلب إلى المسار /sleep مع استجابة بطيئة محاكاة ستجعل الخادم ينام لمدة خمس ثوانٍ قبل الاستجابة.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
// --snip--
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
// --snip--
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
// --snip--
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}لقد انتقلنا من استخدام if إلى match الآن بعد أن أصبح لدينا ثلاث حالات. نحتاج إلى المطابقة صراحةً على شريحة (slice) من request_line لمطابقة النمط مع قيم السلسلة النصية الثابتة؛ حيث لا يقوم match بعملية الإسناد المرجعي وإلغاء الإسناد (referencing and dereferencing) تلقائياً كما تفعل دالة المساواة.
الذراع الأول هو نفسه كتلة if من القائمة 21-9. الذراع الثاني يطابق طلباً إلى /sleep. عند استلام هذا الطلب، سينام الخادم لمدة خمس ثوانٍ قبل عرض صفحة HTML الناجحة. الذراع الثالث هو نفسه كتلة else من القائمة 21-9.
يمكنك أن ترى مدى بساطة خادمنا: المكتبات الحقيقية ستتعامل مع التعرف على الطلبات المتعددة بطريقة أقل إسهاباً بكثير!
ابدأ تشغيل الخادم باستخدام cargo run. ثم افتح نافذتين في المتصفح: واحدة لـ http://127.0.0.1:7878 والأخرى لـ http://127.0.0.1:7878/sleep. إذا قمت بإدخال عنوان / عدة مرات، كما فعلت سابقاً، فسترى أنه يستجيب بسرعة. ولكن إذا أدخلت /sleep ثم قمت بتحميل /، فسترى أن / ينتظر حتى ينتهي sleep من نومه لمدة خمس ثوانٍ كاملة قبل التحميل.
هناك تقنيات متعددة يمكننا استخدامها لتجنب تراكم الطلبات خلف طلب بطيء، بما في ذلك استخدام البرمجة غير المتزامنة (async) كما فعلنا في الفصل 17؛ والتقنية التي سنقوم بتنفيذها هي “حوض المسارات” (thread pool).
تحسين معدل النقل باستخدام حوض المسارات (Thread Pool)
“حوض المسارات” (thread pool) هو مجموعة من المسارات (threads) التي تم إنشاؤها وهي جاهزة وتنتظر معالجة مهمة ما. عندما يتلقى البرنامج مهمة جديدة، فإنه يعين أحد المسارات في الحوض للمهمة، وسيقوم هذا المسار بمعالجة المهمة. تظل المسارات المتبقية في الحوض متاحة للتعامل مع أي مهام أخرى تأتي أثناء معالجة المسار الأول. عندما ينتهي المسار الأول من معالجة مهمته، يتم إعادته إلى حوض المسارات الخاملة، ليكون جاهزاً للتعامل مع مهمة جديدة. يسمح لك حوض المسارات بمعالجة الاتصالات بشكل متزامن (concurrently)، مما يزيد من معدل نقل البيانات (throughput) في خادمك.
سنحدد عدد المسارات في الحوض برقم صغير لحمايتنا من هجمات الحرمان من الخدمة (DoS)؛ فلو جعلنا برنامجنا ينشئ مساراً جديداً لكل طلب يأتي، لتمكن شخص يقوم بتقديم 10 ملايين طلب إلى خادمنا من إحداث فوضى عارمة عن طريق استهلاك جميع موارد خادمنا وإيقاف معالجة الطلبات تماماً.
بدلاً من إنشاء مسارات غير محدودة، سيكون لدينا عدد ثابت من المسارات التي تنتظر في الحوض. يتم إرسال الطلبات الواردة إلى الحوض للمعالجة. سيحتفظ الحوض بطابور (queue) من الطلبات الواردة. سيقوم كل مسار من المسارات في الحوض بسحب طلب من هذا الطابور، ومعالجة الطلب، ثم يطلب من الطابور طلباً آخر. بهذا التصميم، يمكننا معالجة ما يصل إلى N من الطلبات بشكل متزامن، حيث N هو عدد المسارات. إذا كان كل مسار يستجيب لطلب يستغرق وقتاً طويلاً، فلا يزال بإمكان الطلبات اللاحقة التراكم في الطابور، لكننا زدنا عدد الطلبات طويلة الأمد التي يمكننا التعامل معها قبل الوصول إلى تلك النقطة.
هذه التقنية هي مجرد واحدة من طرق عديدة لتحسين معدل نقل خادم الويب. الخيارات الأخرى التي قد تستكشفها هي نموذج fork/join، ونموذج الإدخال/الإخراج غير المتزامن أحادي المسار، ونموذج الإدخال/الإخراج غير المتزامن متعدد المسارات. إذا كنت مهتماً بهذا الموضوع، يمكنك قراءة المزيد عن الحلول الأخرى ومحاولة تنفيذها؛ فمع لغة منخفضة المستوى مثل Rust، كل هذه الخيارات ممكنة.
قبل أن نبدأ في تنفيذ حوض المسارات، دعونا نتحدث عن الشكل الذي يجب أن يكون عليه استخدام الحوض. عندما تحاول تصميم كود، فإن كتابة واجهة العميل أولاً يمكن أن تساعد في توجيه تصميمك. اكتب الواجهة البرمجية (API) للكود بحيث تكون منظمة بالطريقة التي تريد استدعاءها بها؛ ثم قم بتنفيذ الوظائف داخل هذا الهيكل بدلاً من تنفيذ الوظائف ثم تصميم الواجهة البرمجية العامة.
على غرار كيفية استخدامنا للتطوير المدفوع بالاختبار (TDD) في مشروع الفصل 12، سنستخدم هنا التطوير المدفوع بالمترجم (compiler-driven development). سنكتب الكود الذي يستدعي الدوال التي نريدها، ثم سننظر في الأخطاء الواردة من المترجم لتحديد ما يجب تغييره تالياً لجعل الكود يعمل. قبل القيام بذلك، سنستكشف التقنية التي لن نستخدمها كنقطة انطلاق.
إنشاء مسار لكل طلب
أولاً، دعونا نستكشف كيف قد يبدو الكود الخاص بنا إذا قام بإنشاء مسار جديد لكل اتصال. كما ذكرنا سابقاً، هذه ليست خطتنا النهائية بسبب مشاكل احتمال إنشاء عدد غير محدود من المسارات، ولكنها نقطة انطلاق للحصول على خادم متعدد المسارات يعمل أولاً. بعد ذلك، سنضيف حوض المسارات كتحسين، وسيكون التباين بين الحلين أسهل.
توضح القائمة 21-11 التغييرات التي يجب إجراؤها على main لإنشاء مسار جديد للتعامل مع كل تدفق (stream) داخل حلقة for.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
thread::spawn(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}كما تعلمت في الفصل 16، سيقوم thread::spawn بإنشاء مسار جديد ثم تشغيل الكود الموجود في الإغلاق (closure) في المسار الجديد. إذا قمت بتشغيل هذا الكود وتحميل /sleep في متصفحك، ثم / في علامتي تبويب إضافيتين، فسترى بالفعل أن الطلبات إلى / لا تضطر إلى انتظار انتهاء /sleep. ومع ذلك، كما ذكرنا، سيؤدي هذا في النهاية إلى إرهاق النظام لأنك ستنشئ مسارات جديدة دون أي حدود.
قد تتذكر أيضاً من الفصل 17 أن هذا هو بالضبط نوع الموقف الذي تتألق فيه البرمجة غير المتزامنة (async) و (await)! ضع ذلك في اعتبارك بينما نبني حوض المسارات وفكر في كيف ستكون الأمور مختلفة أو متشابهة مع async.
إنشاء عدد محدود من المسارات
نريد أن يعمل حوض المسارات الخاص بنا بطريقة مماثلة ومألوفة بحيث لا يتطلب الانتقال من المسارات إلى حوض المسارات تغييرات كبيرة في الكود الذي يستخدم واجهتنا البرمجية. توضح القائمة 21-12 الواجهة الافتراضية لهيكل ThreadPool الذي نريد استخدامه بدلاً من thread::spawn.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}نستخدم ThreadPool::new لإنشاء حوض مسارات جديد بعدد قابل للتكوين من المسارات، في هذه الحالة أربعة. ثم، في حلقة for تمتلك pool.execute واجهة مماثلة لـ thread::spawn من حيث أنها تأخذ إغلاقاً يجب أن يشغله الحوض لكل تدفق. نحتاج إلى تنفيذ pool.execute بحيث تأخذ الإغلاق وتعطيه لمسار في الحوض لتشغيله. لن يتم تجميع هذا الكود بعد، لكننا سنحاول حتى يتمكن المترجم من توجيهنا في كيفية إصلاحه.
بناء ThreadPool باستخدام التطوير المدفوع بالمترجم
قم بإجراء التغييرات في القائمة 21-12 على ملف src/main.rs، ثم دعنا نستخدم أخطاء المترجم من cargo check لتوجيه تطويرنا. إليك الخطأ الأول الذي نحصل عليه:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` (bin "hello") due to 1 previous error
رائع! يخبرنا هذا الخطأ أننا بحاجة إلى نوع أو وحدة ThreadPool لذا سنقوم ببناء واحدة الآن. سيكون تنفيذ ThreadPool الخاص بنا مستقلاً عن نوع العمل الذي يقوم به خادم الويب الخاص بنا. لذا، دعونا نحول صندوق hello من صندوق ثنائي إلى صندوق مكتبة (library crate) ليحتوي على تنفيذ ThreadPool الخاص بنا. بعد التغيير إلى صندوق مكتبة، يمكننا أيضاً استخدام مكتبة حوض المسارات المنفصلة لأي عمل نريد القيام به باستخدام حوض مسارات، وليس فقط لخدمة طلبات الويب.
أنشئ ملف src/lib.rs يحتوي على ما يلي، وهو أبسط تعريف لهيكل ThreadPool يمكننا الحصول عليه في الوقت الحالي:
pub struct ThreadPool;ثم، قم بتحرير ملف main.rs لجلب ThreadPool إلى النطاق من صندوق المكتبة عن طريق إضافة الكود التالي إلى أعلى ملف src/main.rs:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}لا يزال هذا الكود لا يعمل، ولكن دعنا نتحقق منه مرة أخرى للحصول على الخطأ التالي الذي نحتاج إلى معالجته:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
يشير هذا الخطأ إلى أننا نحتاج تالياً إلى إنشاء دالة مرتبطة تسمى new لـ ThreadPool. نعلم أيضاً أن new تحتاج إلى معامل واحد يمكنه قبول 4 كمعامل ويجب أن تعيد نسخة من ThreadPool. دعونا ننفذ أبسط دالة new تمتلك تلك الخصائص:
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}اخترنا usize كنوع لمعامل size لأننا نعلم أن عدداً سالباً من المسارات لا معنى له. نعلم أيضاً أننا سنستخدم هذا… (تم اختصار المحتوى بسبب حدود الحجم)
…
لنبدأ بإنشاء قناة (channel) في ThreadPool::new والاحتفاظ بالمرسل (sender) في نسخة ThreadPool كما هو موضح في القائمة 21-16. هيكل Job لا يحمل أي شيء في الوقت الحالي ولكنه سيكون نوع العنصر الذي نرسله عبر القناة.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}في ThreadPool::new ننشئ قناتنا الجديدة ونجعل الحوض يحتفظ بالمرسل. سيتم تجميع هذا بنجاح.
دعونا نحاول تمرير مستقبل (receiver) القناة إلى كل Worker بينما يقوم حوض المسارات بإنشاء القناة. نعلم أننا نريد استخدام المستقبل في المسار الذي تنشئه نسخ Worker لذا سنشير إلى معامل receiver في الإغلاق. الكود في القائمة 21-17 لن يتم تجميعه تماماً بعد.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, receiver));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}لقد أجرينا بعض التغييرات الصغيرة والمباشرة: نمرر المستقبل إلى Worker::new ثم نستخدمه داخل الإغلاق.
عندما نحاول التحقق من هذا الكود، نحصل على هذا الخطأ:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
25 | for id in 0..size {
| ----------------- inside of this loop
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
|
note: consider changing this parameter type in method `new` to borrow instead if owning the value isn't necessary
--> src/lib.rs:47:33
|
47 | fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
| --- in this method ^^^^^^^^^^^^^^^^^^^ this parameter takes ownership of the value
help: consider moving the expression out of the loop so it is only moved once
|
25 ~ let mut value = Worker::new(id, receiver);
26 ~ for id in 0..size {
27 ~ workers.push(value);
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` (lib) due to 1 previous error
يحاول الكود تمرير receiver إلى نسخ Worker متعددة. هذا لن يعمل، كما ستتذكر من الفصل 16: تنفيذ القناة الذي توفره Rust هو “منتجون متعددون، مستهلك واحد” (multiple producer, single consumer). هذا يعني أنه لا يمكننا ببساطة استنساخ طرف الاستهلاك في القناة لإصلاح هذا الكود. كما أننا لا نريد إرسال رسالة عدة مرات إلى مستهلكين متعددين؛ نريد قائمة واحدة من الرسائل مع نسخ Worker متعددة بحيث تتم معالجة كل رسالة مرة واحدة.
بالإضافة إلى ذلك، فإن سحب مهمة من طابور القناة يتضمن تعديل الـ receiver لذا تحتاج المسارات إلى طريقة آمنة لمشاركة وتعديل receiver؛ وإلا فقد نحصل على حالات تسابق (race conditions) (كما تمت تغطيتها في الفصل 16).
تذكر المؤشرات الذكية الآمنة للمسارات التي نوقشت في الفصل 16: لمشاركة الملكية عبر مسارات متعددة والسماح للمسارات بتعديل القيمة، نحتاج إلى استخدام Arc<Mutex<T>>. سيسمح نوع Arc لنسخ Worker متعددة بامتلاك المستقبل، وسيضمن Mutex أن عاملاً واحداً فقط يحصل على مهمة من المستقبل في كل مرة. توضح القائمة 21-18 التغييرات التي نحتاج إلى إجرائها.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
// --snip--
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}في ThreadPool::new نضع المستقبل في Arc و Mutex. لكل Worker جديد، نقوم باستنساخ الـ Arc لزيادة عدد المراجع بحيث يمكن لنسخ Worker مشاركة ملكية المستقبل.
مع هذه التغييرات، يتم تجميع الكود! نحن نقترب!
تنفيذ دالة execute
دعونا أخيراً ننفذ دالة execute على ThreadPool. سنقوم أيضاً بتغيير Job من هيكل إلى اسم مستعار للنوع (type alias) لكائن سمة (trait object) يحمل نوع الإغلاق الذي تستقبله execute. كما نوقش في قسم “مرادفات الأنواع وأسماء الأنواع المستعارة” في الفصل 20، تسمح لنا أسماء الأنواع المستعارة بجعل الأنواع الطويلة أقصر لسهولة الاستخدام. انظر إلى القائمة 21-19.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}بعد إنشاء نسخة Job جديدة باستخدام الإغلاق الذي نحصل عليه في execute نرسل تلك المهمة عبر طرف الإرسال في القناة. نحن نستدعي unwrap على send للحالة التي يفشل فيها الإرسال. قد يحدث هذا إذا قمنا، على سبيل المثال، بإيقاف جميع مساراتنا عن التنفيذ، مما يعني أن طرف الاستقبال قد توقف عن استقبال رسائل جديدة. في الوقت الحالي، لا يمكننا إيقاف مساراتنا عن التنفيذ: تستمر مساراتنا في التنفيذ طالما أن الحوض موجود. السبب في استخدامنا لـ unwrap هو أننا نعلم أن حالة الفشل لن تحدث، لكن المترجم لا يعرف ذلك.
لكننا لم ننتهِ تماماً بعد! في الـ Worker لا يزال الإغلاق الذي يتم تمريره إلى thread::spawn يشير فقط إلى طرف الاستقبال في القناة. بدلاً من ذلك، نحتاج إلى أن يدخل الإغلاق في حلقة تكرار للأبد، يطلب من طرف الاستقبال في القناة مهمة ويقوم بتشغيل المهمة عندما يحصل على واحدة. دعونا نجري التغيير الموضح في القائمة 21-20 على Worker::new.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}هنا، نستدعي أولاً lock على الـ receiver للحصول على الـ mutex، ثم نستدعي unwrap للهلع (panic) عند حدوث أي أخطاء. قد يفشل الحصول على القفل إذا كان الـ mutex في حالة مسمومة (poisoned)، والتي يمكن أن تحدث إذا هلع مسار آخر أثناء امتلاك القفل بدلاً من تحريره. في هذه الحالة، استدعاء unwrap لجعل هذا المسار يهلع هو الإجراء الصحيح الذي يجب اتخاذه. لا تتردد في تغيير unwrap هذه إلى expect مع رسالة خطأ ذات معنى بالنسبة لك.
إذا حصلنا على القفل في الـ mutex، فنحن نستدعي recv لاستقبال Job من القناة. استدعاء unwrap نهائي يتجاوز أي أخطاء هنا أيضاً، والتي قد تحدث إذا تم إغلاق المسار الذي يحمل المرسل، على غرار كيفية إرجاع دالة send لـ Err إذا تم إغلاق المستقبل.
استدعاء recv يحجب التنفيذ (blocks)، لذا إذا لم تكن هناك مهمة بعد، فسوف ينتظر المسار الحالي حتى تصبح المهمة متاحة. يضمن Mutex<T> أن مسار Worker واحداً فقط في كل مرة يحاول طلب مهمة.
حوض المسارات الخاص بنا الآن في حالة عمل! جربه باستخدام cargo run وقم بإجراء بعض الطلبات:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
warning: field `workers` is never read
--> src/lib.rs:7:5
|
6 | pub struct ThreadPool {
| ---------- field in this struct
7 | workers: Vec<Worker>,
| ^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: fields `id` and `thread` are never read
--> src/lib.rs:48:5
|
47 | struct Worker {
| ------ fields in this struct
48 | id: usize,
| ^^
49 | thread: thread::JoinHandle<()>,
| ^^^^^^
warning: `hello` (lib) generated 2 warnings
Finished `dev` profile [unoptimized + debuginfo] target(s) in 4.91s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
نجاح! لدينا الآن حوض مسارات ينفذ الاتصالات بشكل غير متزامن. لا يتم إنشاء أكثر من أربعة مسارات أبداً، لذا لن يتعرض نظامنا للحمل الزائد إذا تلقى الخادم الكثير من الطلبات. إذا قدمنا طلباً إلى /sleep، فسيكون الخادم قادراً على خدمة الطلبات الأخرى عن طريق جعل مسار آخر يقوم بتشغيلها.
ملاحظة: إذا فتحت /sleep في نوافذ متصفح متعددة في وقت واحد، فقد يتم تحميلها واحدة تلو الأخرى في فترات زمنية مدتها خمس ثوانٍ. تقوم بعض متصفحات الويب بتنفيذ نسخ متعددة من نفس الطلب بشكل تسلسلي لأسباب تتعلق بالتخزين المؤقت (caching). هذا القيد لا يسببه خادم الويب الخاص بنا.
هذا وقت جيد للتوقف والتفكير في كيف سيكون الكود في القوائم 21-18 و 21-19 و 21-20 مختلفاً إذا كنا نستخدم الـ futures بدلاً من الإغلاق للعمل الذي يتعين القيام به. ما هي الأنواع التي ستتغير؟ كيف ستكون تواقيع الدوال مختلفة، إن وجدت؟ ما هي أجزاء الكود التي ستبقى كما هي؟
بعد التعرف على حلقة while let في الفصل 17 والفصل 19، قد تتساءل لماذا لم نكتب كود مسار Worker كما هو موضح في القائمة 21-21.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}هذا الكود يتم تجميعه وتشغيله ولكنه لا يؤدي إلى سلوك المسارات المطلوب: سيظل الطلب البطيء يتسبب في انتظار الطلبات الأخرى للمعالجة. السبب دقيق نوعاً ما: هيكل Mutex لا يحتوي على دالة unlock عامة لأن ملكية القفل تعتمد على عمر MutexGuard<T> داخل LockResult<MutexGuard<T>> الذي تعيده دالة lock. في وقت التجميع، يمكن لمدقق الاستعارة (borrow checker) بعد ذلك فرض القاعدة التي تنص على أنه لا يمكن الوصول إلى مورد يحميه Mutex ما لم نكن نمتلك القفل. ومع ذلك، يمكن أن يؤدي هذا التنفيذ أيضاً إلى الاحتفاظ بالقفل لفترة أطول من المقصود إذا لم نكن منتبهين لعمر MutexGuard<T>.
الكود في القائمة 21-20 الذي يستخدم let job = receiver.lock().unwrap().recv().unwrap(); يعمل لأنه مع let يتم إسقاط أي قيم مؤقتة مستخدمة في التعبير على الجانب الأيمن من علامة التساوي فور انتهاء عبارة let. ومع ذلك، فإن while let (و if let و match) لا تسقط القيم المؤقتة حتى نهاية الكتلة المرتبطة. في القائمة 21-21، يظل القفل ممسوكاً طوال مدة استدعاء job()، مما يعني أن نسخ Worker الأخرى لا يمكنها استقبال المهام.
الإغلاق اللطيف والتنظيف (Graceful Shutdown)
الإغلاق الآمن (Graceful Shutdown) والتنظيف (Cleanup)
يستجيب الكود في القائمة 21-20 للطلبات بشكل غير متزامن (asynchronously) من خلال استخدام مجمع خيوط المعالجة (thread pool)، كما خططنا. تظهر لنا بعض التحذيرات حول حقول (fields) workers و id و thread التي لا نستخدمها بطريقة مباشرة، مما يذكرنا بأننا لا نقوم بأي عملية تنظيف. عندما نستخدم الطريقة الأقل أناقة بالضغط على ctrl-C لإيقاف خيط المعالجة الرئيسي (main thread)، يتم إيقاف جميع خيوط المعالجة الأخرى فوراً أيضاً، حتى لو كانت في منتصف خدمة طلب ما.
بعد ذلك، سنقوم بتنفيذ سمة (trait) Drop لاستدعاء join على كل خيط من خيوط المعالجة في pool للتأكد من إنهاء الطلبات التي تعمل عليها قبل الإغلاق. ثم سنقوم بتنفيذ طريقة لإخبار خيوط المعالجة بوجوب التوقف عن قبول طلبات جديدة والإغلاق. لرؤية هذا الكود قيد التشغيل، سنقوم بتعديل الخادم الخاص بنا ليقبل طلبين فقط قبل إغلاق thread pool الخاص به بشكل آمن.
شيء واحد يجب ملاحظته أثناء المضي قدماً: لا يؤثر أي من هذا على أجزاء الكود التي تتعامل مع تنفيذ الإغلاقات (closures)، لذا سيكون كل شيء هنا هو نفسه إذا كنا نستخدم thread pool لـ وقت تشغيل غير متزامن (async runtime).
تنفيذ سمة Drop على ThreadPool
لنبدأ بتنفيذ Drop على thread pool الخاص بنا. عندما يتم حذف (dropped) pool، يجب أن تنضم (join) جميع خيوط المعالجة الخاصة بنا للتأكد من إنهاء عملها. تعرض القائمة 21-22 محاولة أولى لتنفيذ Drop ؛ هذا الكود لن يعمل تماماً بعد.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}أولاً، نقوم بالمرور عبر كل من workers في thread pool. نستخدم &mut لهذا لأن self هو مرجع قابل للتغيير، ونحتاج أيضاً إلى القدرة على تغيير worker. لكل worker ، نقوم بطباعة رسالة تفيد بأن مثيل (instance) Worker هذا قيد الإغلاق، ثم نستدعي join على خيط ذلك instance. إذا فشل استدعاء join ، نستخدم unwrap لجعل Rust تدخل في حالة هلع (panic) وتنتقل إلى إغلاق غير آمن.
إليك الخطأ الذي نحصل عليه عند تصريف (compile) هذا الكود:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: `JoinHandle::<T>::join` takes ownership of the receiver `self`, which moves `worker.thread`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:1921:17
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` (lib) due to 1 previous error
يخبرنا الخطأ أنه لا يمكننا استدعاء join لأننا نملك فقط استعارة قابلة للتغيير (mutable borrow) لكل worker ، بينما تأخذ join ملكية (ownership) وسيطها. لحل هذه المشكلة، نحتاج إلى نقل الخيط خارج instance Worker الذي يملك thread حتى تتمكن join من استهلاك الخيط. إحدى الطرق للقيام بذلك هي اتباع نفس النهج الذي اتبعناه في القائمة 18-15. إذا كان Worker يحتفظ بـ Option<thread::JoinHandle<()>> ، فيمكننا استدعاء دالة take على Option لنقل القيمة خارج متغير (variant) Some وترك variant None في مكانه. بعبارة أخرى، فإن Worker الذي يعمل سيكون لديه variant Some في thread ، وعندما نريد تنظيف Worker ، سنستبدل Some بـ None حتى لا يكون لدى Worker خيط لتشغيله.
ومع ذلك، فإن المرة الوحيدة التي سيظهر فيها هذا هي عند حذف Worker. في المقابل، سيتعين علينا التعامل مع Option<thread::JoinHandle<()>> في أي مكان نصل فيه إلى worker.thread. يستخدم أسلوب رست الاصطلاحي (Idiomatic Rust) نوع Option كثيراً، ولكن عندما تجد نفسك تغلف شيئاً تعرف أنه سيكون موجوداً دائماً في Option كحل بديل مثل هذا، فمن الجيد البحث عن طرق بديلة لجعل الكود الخاص بك أنظف وأقل عرضة للخطأ.
في هذه الحالة، يوجد بديل أفضل: دالة Vec::drain. وهي تقبل معلمة نطاق (range parameter) لتحديد العناصر التي سيتم إزالتها من المتجه (vector) وتُرجع مكرراً (iterator) لتلك العناصر. سيؤدي تمرير بناء جملة النطاق .. إلى إزالة كل قيمة من vector.
لذا، نحتاج إلى تحديث تنفيذ drop لـ ThreadPool كالتالي:
#![allow(unused)]
fn main() {
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}
}يحل هذا خطأ compiler ولا يتطلب أي تغييرات أخرى في الكود الخاص بنا. لاحظ أنه نظراً لأنه يمكن استدعاء drop عند حدوث panic، فإن unwrap يمكن أن تسبب أيضاً panic وتؤدي إلى هلع مزدوج (double panic)، مما يؤدي فوراً إلى تعطل البرنامج وإنهاء أي عملية تنظيف قيد التنفيذ. هذا أمر مقبول لبرنامج تجريبي، ولكنه غير مستحسن لكود الإنتاج.
إرسال إشارة إلى خيوط المعالجة للتوقف عن انتظار المهام
مع كل التغييرات التي أجريناها، يتم تصريف الكود الخاص بنا دون أي تحذيرات. ومع ذلك، فإن الخبر السيئ هو أن هذا الكود لا يعمل بالطريقة التي نريدها بعد. المفتاح هو المنطق في closures التي يتم تشغيلها بواسطة خيوط المعالجة لـ instances Worker: في الوقت الحالي، نستدعي join ، لكن ذلك لن يوقف خيوط المعالجة، لأنها في حلقة (loop) للأبد تبحث عن مهام (jobs). إذا حاولنا حذف ThreadPool مع تنفيذنا الحالي لـ drop ، فسيتم حظر (block) main thread للأبد، بانتظار انتهاء الخيط الأول.
لإصلاح هذه المشكلة، سنحتاج إلى تغيير في تنفيذ drop لـ ThreadPool ثم تغيير في loop الخاص بـ Worker.
أولاً، سنقوم بتغيير تنفيذ drop لـ ThreadPool لحذف المرسل (sender) صراحةً قبل انتظار انتهاء خيوط المعالجة. تعرض القائمة 21-23 التغييرات على ThreadPool لحذف sender صراحةً. على عكس الخيط، نحتاج هنا بالفعل إلى استخدام Option لنتمكن من نقل sender خارج ThreadPool باستخدام Option::take.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
// --snip--
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}يؤدي حذف sender إلى إغلاق القناة (channel)، مما يشير إلى أنه لن يتم إرسال المزيد من الرسائل. عندما يحدث ذلك، فإن جميع استدعاءات recv التي تقوم بها instances Worker في الحلقة اللانهائية ستُرجع خطأً. في القائمة 21-24، نقوم بتغيير loop الخاص بـ Worker للخروج من الحلقة بشكل آمن في هذه الحالة، مما يعني أن خيوط المعالجة ستنتهي عندما يستدعي تنفيذ drop لـ ThreadPool دالة join عليها.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker { id, thread }
}
}لرؤية هذا الكود قيد التشغيل، دعونا نعدل main لقبول طلبين فقط قبل إغلاق الخادم بشكل آمن، كما هو موضح في القائمة 21-25.
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}لن ترغب في إغلاق خادم ويب حقيقي بعد خدمة طلبين فقط. يوضح هذا الكود فقط أن Graceful Shutdown و Cleanup يعملان بشكل صحيح.
دالة take معرفة في trait Iterator وتحد من التكرار إلى أول عنصرين على الأكثر. سيخرج ThreadPool عن النطاق في نهاية main ، وسيتم تشغيل تنفيذ drop.
ابدأ الخادم باستخدام cargo run وقم بإجراء ثلاثة طلبات. يجب أن يفشل الطلب الثالث، وفي terminal الخاص بك، يجب أن ترى مخرجات مشابهة لهذا:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
قد ترى ترتيباً مختلفاً لمعرفات Worker والرسائل المطبوعة. يمكننا أن نرى كيف يعمل هذا الكود من الرسائل: حصلت instances Worker رقم 0 و 3 على أول طلبين. توقف الخادم عن قبول الاتصالات بعد الاتصال الثاني، ويبدأ تنفيذ Drop على ThreadPool قبل أن يبدأ Worker 3 مهمته. يؤدي حذف sender إلى فصل جميع instances Worker وإخبارها بالإغلاق. تطبع instances Worker رسالة عند فصلها، ثم يستدعي thread pool دالة join لانتظار انتهاء كل خيط Worker.
لاحظ جانباً مثيراً للاهتمام في هذا التنفيذ المحدد: قام ThreadPool بحذف sender ، وقبل أن يتلقى أي Worker خطأً، حاولنا الانضمام إلى Worker 0. لم يكن Worker 0 قد تلقى خطأً بعد من recv ، لذا تم حظر main thread، بانتظار انتهاء Worker 0. في هذه الأثناء، تلقى Worker 3 مهمة ثم تلقت جميع خيوط المعالجة خطأً. عندما انتهى Worker 0 ، انتظر main thread انتهاء بقية instances Worker. عند تلك النقطة، كانت جميعها قد خرجت من حلقاتها وتوقفت.
تهانينا! لقد أكملنا مشروعنا الآن؛ لدينا خادم ويب أساسي يستخدم thread pool للاستجابة بشكل غير متزامن. نحن قادرون على إجراء Graceful Shutdown للخادم، مما ينظف جميع خيوط المعالجة في pool.
إليك الكود الكامل للمرجع:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}يمكننا القيام بالمزيد هنا! إذا كنت ترغب في الاستمرار في تحسين هذا المشروع، فإليك بعض الأفكار:
- إضافة المزيد من التوثيق (documentation) لـ
ThreadPoolودوالها العامة. - إضافة اختبارات (tests) لوظائف المكتبة.
- تغيير استدعاءات
unwrapإلى معالجة أخطاء أكثر قوة. - استخدام
ThreadPoolلأداء مهام أخرى غير خدمة طلبات الويب. - العثور على حزمة (crate) لـ thread pool على crates.io وتنفيذ خادم ويب مماثل باستخدام crate بدلاً من ذلك. ثم قارن واجهة برمجة التطبيقات (API) الخاصة بها وقوتها بـ thread pool الذي قمنا بتنفيذه.
ملخص (Summary)
أحسنت! لقد وصلت إلى نهاية الكتاب! نود أن نشكرك على انضمامك إلينا في هذه الجولة في Rust. أنت الآن جاهز لتنفيذ مشاريع Rust الخاصة بك والمساعدة في مشاريع الآخرين. ضع في اعتبارك أن هناك مجتمعاً مضيافاً من الـ Rustaceans الآخرين الذين يسعدهم مساعدتك في أي تحديات تواجهها في رحلتك مع Rust.
Appendix
تحتوي الأقسام التالية على مواد مرجعية قد تجدها مفيدة في رحلتك مع لغة Rust.
أ - الكلمات المفتاحية (Keywords)
الملحق أ: الكلمات المفتاحية (Keywords)
تحتوي القوائم التالية على “الكلمات المفتاحية” (Keywords) المحجوزة للاستخدام الحالي أو المستقبلي بواسطة لغة Rust. وبناءً على ذلك، لا يمكن استخدامها كـ “معرفات” (Identifiers) (باستثناء استخدامها كـ “معرفات خام” - Raw Identifiers، كما سنناقش في قسم المعرفات الخام). الـ Identifiers هي أسماء الدوال، والمتغيرات، والمعاملات، وحقول الهياكل (Struct Fields)، والوحدات (Modules)، والحزم (Crates)، والثوابت، والماكرو (Macros)، والقيم الساكنة، والسمات (Attributes)، والأنواع، والسمات (Traits)، أو فترات الحياة (Lifetimes).
الكلمات المفتاحية المستخدمة حالياً
فيما يلي قائمة بالـ Keywords المستخدمة حالياً، مع وصف لوظائفها.
as: إجراء “تحويل أولي” (Primitive Casting)، أو إزالة الغموض عن Trait معين يحتوي على عنصر، أو إعادة تسمية العناصر في عباراتuse.async: إرجاعFutureبدلاً من حظر المسار (Thread) الحالي.await: تعليق التنفيذ حتى تصبح نتيجة الـFutureجاهزة.break: الخروج من حلقة تكرار (Loop) فوراً.const: تعريف عناصر ثابتة أو مؤشرات خام (Raw Pointers) ثابتة.continue: الاستمرار إلى التكرار التالي للحلقة.crate: في مسار الوحدة، يشير إلى جذر الـ Crate.dyn: “إرسال ديناميكي” (Dynamic Dispatch) إلى كائن سمة (Trait Object).else: خيار احتياطي لهياكل تدفق التحكمifوif let.enum: تعريف “تعداد” (Enumeration).extern: ربط دالة أو متغير خارجي.false: القيمة المنطقية “خطأ”.fn: تعريف دالة أو نوع مؤشر دالة.for: التكرار عبر عناصر من مكرر (Iterator)، أو تنفيذ Trait، أو تحديد Lifetime ذات رتبة أعلى.if: التفرع بناءً على نتيجة تعبير شرطي.impl: تنفيذ وظائف ذاتية أو وظائف Trait.in: جزء من صيغة حلقةfor.let: ربط متغير.loop: التكرار دون قيد أو شرط.match: مطابقة قيمة مع أنماط (Patterns).mod: تعريف Module.move: جعل “الإغلاق” (Closure) يأخذ ملكية جميع ما يلتقطه.mut: الإشارة إلى “القابلية للتغيير” (Mutability) في المراجع، أو الـ Raw Pointers، أو روابط الأنماط.pub: الإشارة إلى الرؤية العامة في Struct Fields، أو كتلimplأو الـ Modules.ref: الربط عن طريق المرجع.return: الإرجاع من الدالة.Self: اسم مستعار للنوع الذي نقوم بتعريفه أو تنفيذه.self: موضوع الدالة المرتبطة (Method) أو الـ Module الحالي.static: متغير عام أو Lifetime تستمر طوال فترة تنفيذ البرنامج.struct: تعريف هيكل (Structure).super: الـ Module الأب للـ Module الحالي.trait: تعريف Trait.true: القيمة المنطقية “صواب”.type: تعريف اسم مستعار للنوع (Type Alias) أو نوع مرتبط (Associated Type).union: تعريف اتحاد؛ وتعتبر Keyword فقط عند استخدامها في إعلان الاتحاد.unsafe: الإشارة إلى كود، أو دوال، أو Traits، أو عمليات تنفيذ غير آمنة.use: جلب الرموز إلى النطاق (Scope).where: الإشارة إلى البنود التي تقيد النوع.while: التكرار المشروط بناءً على نتيجة تعبير.
الكلمات المفتاحية المحجوزة للاستخدام المستقبلي
الـ Keywords التالية لا تمتلك أي وظيفة بعد ولكنها محجوزة بواسطة Rust للاستخدام المستقبلي المحتمل:
abstractbecomeboxdofinalgenmacrooverrideprivtrytypeofunsizedvirtualyield
المعرفات الخام (Raw Identifiers)
“المعرفات الخام” (Raw Identifiers) هي الصيغة التي تسمح لك باستخدام الـ Keywords في الأماكن التي لا يُسمح فيها عادةً باستخدامها. تستخدم الـ Raw Identifier عن طريق إضافة البادئة r# قبل الـ Keyword.
على سبيل المثال، match هي Keyword. إذا حاولت تجميع الدالة التالية التي تستخدم match كاسم لها:
اسم الملف: src/main.rs
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}ستحصل على هذا الخطأ:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
يوضح الخطأ أنه لا يمكنك استخدام الـ Keyword match كـ Identifier للدالة. لاستخدام match كاسم دالة، تحتاج إلى استخدام صيغة الـ Raw Identifier، هكذا:
اسم الملف: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}
fn main() {
assert!(r#match("foo", "foobar"));
}سيتم تجميع هذا الكود دون أي أخطاء. لاحظ البادئة r# في اسم الدالة في تعريفها وكذلك في مكان استدعاء الدالة في main.
تسمح لك الـ Raw Identifiers باستخدام أي كلمة تختارها كـ Identifier، حتى لو كانت تلك الكلمة Keyword محجوزة. يمنحنا هذا مزيداً من الحرية في اختيار أسماء الـ Identifiers، كما يسمح لنا بالتكامل مع البرامج المكتوبة بلغة لا تعتبر هذه الكلمات Keywords فيها. بالإضافة إلى ذلك، تسمح لك الـ Raw Identifiers باستخدام مكتبات مكتوبة بإصدار (Edition) مختلف من Rust عن الذي تستخدمه الـ Crate الخاصة بك. على سبيل المثال، try ليست Keyword في إصدار 2015 ولكنها كذلك في إصدارات 2018 و2021 و2024. إذا كنت تعتمد على مكتبة مكتوبة باستخدام إصدار 2015 وبها دالة try فستحتاج إلى استخدام صيغة الـ Raw Identifier، وهي r#try في هذه الحالة، لاستدعاء تلك الدالة من الكود الخاص بك في الإصدارات اللاحقة. راجع الملحق هـ لمزيد من المعلومات حول الإصدارات.
ب - العوامل والرموز (Operators and Symbols)
الملحق ب: (المعاملات) Operators و (الرموز) Symbols
يحتوي هذا الملحق على مسرد لـ (الصيغة) Syntax الخاصة بلغة Rust، بما في ذلك (المعاملات) Operators و (الرموز) Symbols الأخرى التي تظهر بمفردها أو في سياق (المسارات) Paths، و (الأنواع العامة) Generics، و (قيود السمات) Trait bounds، و (الماكروهات) Macros، و (السمات) Attributes، و (التعليقات) Comments، و (المجموعات) Tuples، و (الأقواس) Brackets.
Operators
يحتوي الجدول B-1 على Operators في Rust، ومثال على كيفية ظهور Operator في السياق، وشرح موجز، وما إذا كان Operator (قابل للتحميل الزائد) Overloadable. إذا كان Operator Overloadable، يتم إدراج Trait ذي الصلة الذي يجب استخدامه لتحميل هذا Operator الزائد.
الجدول B-1: Operators
| Operator | مثال | الشرح | Overloadable؟ |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | (توسيع الماكرو) Macro expansion | |
! | !expr | (المكمل المنطقي أو على مستوى البت) Bitwise or logical complement | Not |
!= | expr != expr | (مقارنة عدم التساوي) Nonequality comparison | PartialEq |
% | expr % expr | (باقي القسمة الحسابي) Arithmetic remainder | Rem |
%= | var %= expr | (باقي القسمة الحسابي والإسناد) Arithmetic remainder and assignment | RemAssign |
& | &expr, &mut expr | (الاستعارة) Borrow | |
& | &type, &mut type, &'a type, &'a mut type | (نوع المؤشر المستعار) Borrowed pointer type | |
& | expr & expr | (البتي AND) Bitwise AND | BitAnd |
&= | var &= expr | (البتي AND والإسناد) Bitwise AND and assignment | BitAndAssign |
&& | expr && expr | (المنطقي AND ذو الدائرة القصيرة) Short-circuiting logical AND | |
* | expr * expr | (الضرب الحسابي) Arithmetic multiplication | Mul |
*= | var *= expr | (الضرب الحسابي والإسناد) Arithmetic multiplication and assignment | MulAssign |
* | *expr | (إلغاء الإشارة) Dereference | Deref |
* | *const type, *mut type | (المؤشر الخام) Raw pointer | |
+ | trait + trait, 'a + trait | (قيد النوع المركب) Compound type constraint | |
+ | expr + expr | (الجمع الحسابي) Arithmetic addition | Add |
+= | var += expr | (الجمع الحسابي والإسناد) Arithmetic addition and assignment | AddAssign |
, | expr, expr | (فاصل الوسائط والعناصر) Argument and element separator | |
- | - expr | (النفي الحسابي) Arithmetic negation | Neg |
- | expr - expr | (الطرح الحسابي) Arithmetic subtraction | Sub |
-= | var -= expr | (الطرح الحسابي والإسناد) Arithmetic subtraction and assignment | SubAssign |
-> | fn(...) -> type, |…| -> type | (نوع الإرجاع للدالة والإغلاق) Function and closure return type | |
. | expr.ident | (الوصول إلى الحقل) Field access | |
. | expr.ident(expr, ...) | (استدعاء الدالة) Method call | |
. | expr.0, expr.1, and so on | (فهرسة المجموعة) Tuple indexing | |
.. | .., expr.., ..expr, expr..expr | (حرفي النطاق غير الشامل للطرف الأيمن) Right-exclusive range literal | PartialOrd |
..= | ..=expr, expr..=expr | (حرفي النطاق الشامل للطرف الأيمن) Right-inclusive range literal | PartialOrd |
.. | ..expr | (صيغة تحديث حرفي الهيكل) Struct literal update syntax | |
.. | variant(x, ..), struct_type { x, .. } | (ربط النمط “والباقي”) "And the rest" pattern binding | |
... | expr...expr | (مهمل، استخدم ..= بدلاً منه) في نمط: (نمط النطاق الشامل) inclusive range pattern | |
/ | expr / expr | (القسمة الحسابية) Arithmetic division | Div |
/= | var /= expr | (القسمة الحسابية والإسناد) Arithmetic division and assignment | DivAssign |
: | pat: type, ident: type | (القيود) Constraints | |
: | ident: expr | (مهيئ حقل الهيكل) Struct field initializer | |
: | 'a: loop {...} | (تسمية الحلقة) Loop label | |
; | expr; | (مُنهي العبارة والعنصر) Statement and item terminator | |
; | [...; len] | جزء من (صيغة المصفوفة ذات الحجم الثابت) fixed-size array syntax | |
<< | expr << expr | (الإزاحة لليسار) Left-shift | Shl |
<<= | var <<= expr | (الإزاحة لليسار والإسناد) Left-shift and assignment | ShlAssign |
< | expr < expr | (مقارنة أقل من) Less than comparison | PartialOrd |
<= | expr <= expr | (مقارنة أقل من أو يساوي) Less than or equal to comparison | PartialOrd |
= | var = expr, ident = type | (الإسناد/التكافؤ) Assignment/equivalence | |
== | expr == expr | (مقارنة التساوي) Equality comparison | PartialEq |
=> | pat => expr | جزء من (صيغة ذراع المطابقة) match arm syntax | |
> | expr > expr | (مقارنة أكبر من) Greater than comparison | PartialOrd |
>= | expr >= expr | (مقارنة أكبر من أو يساوي) Greater than or equal to comparison | PartialOrd |
>> | expr >> expr | (الإزاحة لليمين) Right-shift | Shr |
>>= | var >>= expr | (الإزاحة لليمين والإسناد) Right-shift and assignment | ShrAssign |
@ | ident @ pat | (ربط النمط) Pattern binding | |
^ | expr ^ expr | (البتي OR الحصري) Bitwise exclusive OR | BitXor |
^= | var ^= expr | (البتي OR الحصري والإسناد) Bitwise exclusive OR and assignment | BitXorAssign |
| | pat | pat | (بدائل النمط) Pattern alternatives | |
| | expr | expr | (البتي OR) Bitwise OR | BitOr |
|= | var |= expr | (البتي OR والإسناد) Bitwise OR and assignment | BitOrAssign |
|| | expr || expr | (المنطقي OR ذو الدائرة القصيرة) Short-circuiting logical OR | |
? | expr? | (نشر الخطأ) Error propagation |
Non-operator Symbols
تحتوي الجداول التالية على جميع Symbols التي لا تعمل كـ Operators؛ أي أنها لا تتصرف مثل استدعاء دالة أو Method call.
يعرض الجدول B-2 Symbols التي تظهر بمفردها وتكون صالحة في مجموعة متنوعة من المواقع.
الجدول B-2: Stand-alone Syntax
| Symbol | الشرح |
|---|---|
'ident | (عمر مسمى أو تسمية حلقة) Named lifetime or loop label |
Digits immediately followed by u8, i32, f64, usize, and so on | (حرفي رقمي من نوع محدد) Numeric literal of specific type |
"..." | (حرفي سلسلة نصية) String literal |
r"...", r#"..."#, r##"..."##, and so on | (حرفي سلسلة نصية خام) Raw string literal؛ لا تتم معالجة (أحرف الهروب) escape characters |
b"..." | (حرفي سلسلة بايت) Byte string literal؛ ينشئ (مصفوفة من البايتات) array of bytes بدلاً من String |
br"...", br#"..."#, br##"..."##, and so on | (حرفي سلسلة بايت خام) Raw byte string literal؛ مزيج من Raw و Byte string literal |
'...' | (حرفي محرف) Character literal |
b'...' | (حرفي بايت ASCII) ASCII byte literal |
|…| expr | (الإغلاق) Closure |
! | (النوع السفلي الفارغ دائمًا للدوال المتباينة) Always-empty bottom type for diverging functions |
_ | (ربط النمط “المتجاهل”) "Ignored" pattern binding؛ يستخدم أيضًا لجعل (الحرفيات الصحيحة) integer literals قابلة للقراءة |
يعرض الجدول B-3 Symbols التي تظهر في سياق Path عبر (التسلسل الهرمي للوحدة) module hierarchy إلى (عنصر) item.
الجدول B-3: Path-Related Syntax
| Symbol | الشرح |
|---|---|
ident::ident | (مسار مساحة الاسم) Namespace path |
super::path | Path بالنسبة إلى (الوالد) parent للوحدة الحالية |
type::ident, <type as trait>::ident | (الثوابت والدوال والأنواع المرتبطة) Associated constants, functions, and types |
<type>::... | (العنصر المرتبط) Associated item لـ type لا يمكن تسميته مباشرة (على سبيل المثال، <&T>::...، <[T]>::...، وهكذا) |
trait::method(...) | (إزالة الغموض) Disambiguating عن Method call عن طريق تسمية Trait الذي يحدده |
type::method(...) | Disambiguating عن Method call عن طريق تسمية type الذي تم تعريفه من أجله |
<type as trait>::method(...) | Disambiguating عن Method call عن طريق تسمية Trait و type |
يعرض الجدول B-4 Symbols التي تظهر في سياق استخدام (معلمات النوع العامة) generic type parameters.
الجدول B-4: Generics
| Symbol | الشرح |
|---|---|
path<...> | يحدد (المعلمات) parameters لـ generic type في type (على سبيل المثال، Vec<u8>) |
path::<...>, method::<...> | يحدد parameters لـ generic type، function، أو method في (تعبير) expression؛ يشار إليه غالبًا باسم turbofish (على سبيل المثال، "42".parse::<i32>()) |
fn ident<...> ... | تعريف generic function |
struct ident<...> ... | تعريف (هيكل عام) generic structure |
enum ident<...> ... | تعريف (تعداد عام) generic enumeration |
impl<...> ... | تعريف (تنفيذ عام) generic implementation |
for<...> type | (قيود العمر ذات الرتبة الأعلى) Higher ranked lifetime bounds |
type<ident=type> | Generic type حيث تحتوي واحدة أو أكثر من associated types على (تعيينات محددة) specific assignments (على سبيل المثال، Iterator<Item=T>) |
يعرض الجدول B-5 Symbols التي تظهر في سياق تقييد generic type parameters باستخدام trait bounds.
الجدول B-5: Trait Bound Constraints
| Symbol | الشرح |
|---|---|
T: U | Generic parameter T مقيد بـ types التي تنفذ U |
T: 'a | Generic type T يجب أن يعيش أطول من lifetime 'a (مما يعني أن type لا يمكن أن يحتوي بشكل متعدٍ على أي (مراجع) references ذات lifetimes أقصر من 'a) |
T: 'static | Generic type T لا يحتوي على borrowed references بخلاف static |
'b: 'a | Generic lifetime 'b يجب أن يعيش أطول من lifetime 'a |
T: ?Sized | يسمح لـ generic type parameter بأن يكون (نوعًا بحجم ديناميكي) dynamically sized type |
'a + trait, trait + trait | Compound type constraint |
يعرض الجدول B-6 Symbols التي تظهر في سياق استدعاء أو تعريف Macros وتحديد Attributes على item.
الجدول B-6: Macros and Attributes
| Symbol | الشرح |
|---|---|
#[meta] | (سمة خارجية) Outer attribute |
#![meta] | (سمة داخلية) Inner attribute |
$ident | (استبدال الماكرو) Macro substitution |
$ident:kind | (متغير الماكرو الوصفي) Macro metavariable |
$(...)... | (تكرار الماكرو) Macro repetition |
ident!(...), ident!{...}, ident![...] | (استدعاء الماكرو) Macro invocation |
يعرض الجدول B-7 Symbols التي تنشئ Comments.
الجدول B-7: Comments
| Symbol | الشرح |
|---|---|
// | (تعليق سطر) Line comment |
//! | (تعليق توثيق سطر داخلي) Inner line doc comment |
/// | (تعليق توثيق سطر خارجي) Outer line doc comment |
/*...*/ | (تعليق كتلة) Block comment |
/*!...*/ | (تعليق توثيق كتلة داخلي) Inner block doc comment |
/**...*/ | (تعليق توثيق كتلة خارجي) Outer block doc comment |
يعرض الجدول B-8 السياقات التي تُستخدم فيها Parentheses.
الجدول B-8: Parentheses
| Symbol | الشرح |
|---|---|
() | (مجموعة فارغة) Empty tuple (تُعرف أيضًا باسم unit)، حرفي ونوع |
(expr) | (تعبير بين قوسين) Parenthesized expression |
(expr,) | (تعبير مجموعة بعنصر واحد) Single-element tuple expression |
(type,) | (نوع مجموعة بعنصر واحد) Single-element tuple type |
(expr, ...) | (تعبير مجموعة) Tuple expression |
(type, ...) | (نوع مجموعة) Tuple type |
expr(expr, ...) | (تعبير استدعاء دالة) Function call expression؛ يستخدم أيضًا لتهيئة tuple struct و tuple enum |
يعرض الجدول B-9 السياقات التي تُستخدم فيها (الأقواس المعقوفة) Curly Brackets.
الجدول B-9: Curly Brackets
| السياق | الشرح |
|---|---|
{...} | (تعبير كتلة) Block expression |
Type {...} | (حرفي الهيكل) Struct literal |
يعرض الجدول B-10 السياقات التي تُستخدم فيها (الأقواس المربعة) Square Brackets.
الجدول B-10: Square Brackets
| السياق | الشرح |
|---|---|
[...] | (حرفي المصفوفة) Array literal |
[expr; len] | Array literal يحتوي على len نسخة من expr |
[type; len] | (نوع المصفوفة) Array type يحتوي على len من type |
expr[expr] | (فهرسة المجموعة) Collection indexing؛ Overloadable (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | Collection indexing يتظاهر بأنه (تقطيع المجموعة) collection slicing، باستخدام Range، RangeFrom، RangeTo، أو RangeFull كـ “index” |
ج - السمات القابلة للاشتقاق (Derivable Traits)
الملحق ج: السمات القابلة للاشتقاق (Appendix C: Derivable Traits)
في أماكن مختلفة من الكتاب، ناقشنا سمة derive ، والتي يمكنك تطبيقها على تعريف هيكل (struct) أو تعداد (enum). تولد سمة derive كوداً يقوم بتنفيذ سمة (trait) مع تنفيذها الافتراضي الخاص على النوع الذي قمت بتمييزه بصيغة derive.
في هذا الملحق، نقدم مرجعاً لجميع الـ traits في المكتبة القياسية التي يمكنك استخدامها مع derive. يغطي كل قسم ما يلي:
- ما هي المعاملات (operators) والطرق (methods) التي سيمكنها اشتقاق هذه الـ trait.
- ماذا يفعل تنفيذ الـ trait الذي توفره
derive. - ماذا يعني تنفيذ الـ trait بالنسبة للنوع.
- الشروط التي يسمح لك فيها أو لا يسمح لك بتنفيذ الـ trait.
- أمثلة على العمليات التي تتطلب الـ trait.
إذا كنت تريد سلوكاً مختلفاً عن ذلك الذي توفره سمة derive ، فراجع توثيق المكتبة القياسية لكل trait للحصول على تفاصيل حول كيفية تنفيذها يدوياً.
الـ traits المدرجة هنا هي الوحيدة المعرفة بواسطة المكتبة القياسية التي يمكن تنفيذها على أنواعك باستخدام derive. الـ traits الأخرى المعرفة في المكتبة القياسية ليس لها سلوك افتراضي منطقي، لذا فالأمر متروك لك لتنفيذها بالطريقة التي تناسب ما تحاول تحقيقه.
مثال على trait لا يمكن اشتقاقها هو Display ، والتي تتعامل مع التنسيق للمستخدمين النهائيين. يجب عليك دائماً التفكير في الطريقة المناسبة لعرض نوع ما للمستخدم النهائي. ما هي أجزاء النوع التي يجب السماح للمستخدم النهائي برؤيتها؟ ما هي الأجزاء التي سيجدونها ذات صلة؟ ما هو تنسيق البيانات الذي سيكون أكثر صلة بهم؟ لا يمتلك مترجم (compiler) Rust هذه الرؤية، لذا لا يمكنه توفير سلوك افتراضي مناسب لك.
قائمة الـ derivable traits المقدمة في هذا الملحق ليست شاملة: يمكن للمكتبات تنفيذ derive لـ traits الخاصة بها، مما يجعل قائمة الـ traits التي يمكنك استخدام derive معها مفتوحة تماماً. يتضمن تنفيذ derive استخدام ماكرو إجرائي (procedural macro)، والذي تمت تغطيته في قسم “ماكروهات derive المخصصة” في الفصل العشرين.
Debug لمخرجات المبرمج (Debug for Programmer Output)
تمكن سمة Debug تنسيق التصحيح (debug formatting) في سلاسل التنسيق، والتي تشير إليها بإضافة :? داخل العناصر النائبة {}.
تسمح لك سمة Debug بطباعة مثيلات (instances) من نوع ما لأغراض التصحيح، بحيث يمكنك أنت والمبرمجون الآخرون الذين يستخدمون نوعك فحص instance في نقطة معينة من تنفيذ البرنامج.
سمة Debug مطلوبة، على سبيل المثال، في استخدام ماكرو assert_eq!. يطبع هذا الماكرو قيم الـ instances المعطاة كـ arguments إذا فشل تأكيد المساواة حتى يتمكن المبرمجون من رؤية سبب عدم تساوي الـ instances الاثنين.
PartialEq و Eq لمقارنات المساواة (PartialEq and Eq for Equality Comparisons)
تسمح لك سمة PartialEq بمقارنة instances من نوع ما للتحقق من المساواة وتمكن من استخدام المعاملات == و !=.
يؤدي اشتقاق PartialEq إلى تنفيذ طريقة eq. عند اشتقاق PartialEq على الـ structs، يكون الـ instances متساويين فقط إذا كانت جميع الحقول (fields) متساوية، ولا يكون الـ instances متساويين إذا كان أي من الـ fields غير متساوٍ. عند الاشتقاق على الـ enums، يكون كل متغير (variant) مساوياً لنفسه وغير مساوٍ للـ variants الأخرى.
سمة PartialEq مطلوبة، على سبيل المثال، مع استخدام ماكرو assert_eq! ، الذي يحتاج إلى القدرة على مقارنة اثنين من instances لنوع ما من أجل المساواة.
سمة Eq ليس لها طرق. الغرض منها هو الإشارة إلى أنه لكل قيمة من النوع المميز، تكون القيمة مساوية لنفسها. لا يمكن تطبيق سمة Eq إلا على الأنواع التي تنفذ أيضاً PartialEq ، على الرغم من أنه لا يمكن لجميع الأنواع التي تنفذ PartialEq تنفيذ Eq. أحد الأمثلة على ذلك هو أنواع الأرقام ذات الفاصلة العائمة (floating-point number types): ينص تنفيذ أرقام الفاصلة العائمة على أن اثنين من instances لقيمة “ليس رقماً” (NaN) غير متساويين مع بعضهما البعض.
مثال على متى تكون Eq مطلوبة هو للمفاتيح (keys) في HashMap<K, V> بحيث يمكن للـ HashMap<K, V> معرفة ما إذا كان مفتاحان هما نفس الشيء.
PartialOrd و Ord لمقارنات الترتيب (PartialOrd and Ord for Ordering Comparisons)
تسمح لك سمة PartialOrd بمقارنة instances من نوع ما لأغراض الفرز (sorting). يمكن استخدام النوع الذي ينفذ PartialOrd مع المعاملات < و > و <= و >=. يمكنك فقط تطبيق سمة PartialOrd على الأنواع التي تنفذ أيضاً PartialEq.
يؤدي اشتقاق PartialOrd إلى تنفيذ طريقة partial_cmp ، والتي تعيد Option<Ordering> الذي سيكون None عندما لا تنتج القيم المعطاة ترتيباً. مثال على قيمة لا تنتج ترتيباً، على الرغم من إمكانية مقارنة معظم قيم ذلك النوع، هو قيمة NaN للفاصلة العائمة. استدعاء partial_cmp مع أي رقم فاصلة عائمة وقيمة NaN للفاصلة العائمة سيعيد None.
عند الاشتقاق على الـ structs، تقارن PartialOrd بين اثنين من instances من خلال مقارنة القيمة في كل field بالترتيب الذي تظهر به الـ fields في تعريف الـ struct. عند الاشتقاق على الـ enums، تعتبر الـ variants الخاصة بالـ enum المصرح عنها سابقاً في تعريف الـ enum أقل من الـ variants المدرجة لاحقاً.
سمة PartialOrd مطلوبة، على سبيل المثال، لطريقة gen_range من صندوق (crate) الـ rand التي تولد قيمة عشوائية في النطاق المحدد بواسطة تعبير النطاق (range expression).
تسمح لك سمة Ord بمعرفة أنه لأي قيمتين من النوع المميز، سيوجد ترتيب صالح. تنفذ سمة Ord طريقة cmp ، والتي تعيد Ordering بدلاً من Option<Ordering> لأن الترتيب الصالح سيكون ممكناً دائماً. يمكنك فقط تطبيق سمة Ord على الأنواع التي تنفذ أيضاً PartialOrd و Eq (و Eq تتطلب PartialEq). عند الاشتقاق على الـ structs والـ enums، تتصرف cmp بنفس الطريقة التي يتصرف بها التنفيذ المشتق لـ partial_cmp مع PartialOrd.
مثال على متى تكون Ord مطلوبة هو عند تخزين القيم في BTreeSet<T> ، وهو هيكل بيانات يخزن البيانات بناءً على ترتيب فرز القيم.
Clone و Copy لمضاعفة القيم (Clone and Copy for Duplicating Values)
تسمح لك سمة Clone بإنشاء نسخة عميقة (deep copy) من قيمة بشكل صريح، وقد تتضمن عملية المضاعفة تشغيل كود عشوائي ونسخ بيانات الكومة (heap data). راجع قسم “تفاعل المتغيرات والبيانات مع Clone” في الفصل الرابع لمزيد من المعلومات حول Clone.
يؤدي اشتقاق Clone إلى تنفيذ طريقة clone ، والتي عند تنفيذها للنوع بالكامل، تستدعي clone على كل جزء من أجزاء النوع. هذا يعني أن جميع الـ fields أو القيم في النوع يجب أن تنفذ أيضاً Clone لاشتقاق Clone.
مثال على متى تكون Clone مطلوبة هو عند استدعاء طريقة to_vec على شريحة (slice). الـ slice لا يمتلك instances النوع التي يحتوي عليها، ولكن الـ vector المعاد من to_vec سيحتاج إلى امتلاك instances الخاصة به، لذا تستدعي to_vec الطريقة clone على كل عنصر. وبالتالي، يجب أن ينفذ النوع المخزن في الـ slice سمة Clone.
تسمح لك سمة Copy بمضاعفة قيمة عن طريق نسخ البتات (bits) المخزنة على المكدس (stack) فقط؛ لا يلزم وجود كود عشوائي. راجع قسم “بيانات المكدس فقط: Copy” في الفصل الرابع لمزيد من المعلومات حول Copy.
لا تعرف سمة Copy أي طرق لمنع المبرمجين من تحميل تلك الطرق بشكل زائد وانتهاك افتراض عدم تشغيل كود عشوائي. بهذه الطريقة، يمكن لجميع المبرمجين افتراض أن نسخ قيمة سيكون سريعاً جداً.
يمكنك اشتقاق Copy على أي نوع تنفذ جميع أجزائه Copy. يجب أن ينفذ النوع الذي ينفذ Copy أيضاً Clone لأن النوع الذي ينفذ Copy لديه تنفيذ بسيط لـ Clone يؤدي نفس المهمة مثل Copy.
نادراً ما تكون سمة Copy مطلوبة؛ الأنواع التي تنفذ Copy لديها تحسينات متاحة، مما يعني أنك لست مضطراً لاستدعاء clone ، مما يجعل الكود أكثر إيجازاً.
كل شيء ممكن مع Copy يمكنك أيضاً تحقيقه باستخدام Clone ، ولكن الكود قد يكون أبطأ أو يضطر لاستخدام clone في بعض الأماكن.
Hash لربط قيمة بقيمة ذات حجم ثابت (Hash for Mapping a Value to a Value of Fixed Size)
تسمح لك سمة Hash بأخذ instance من نوع ذو حجم عشوائي وربط ذلك الـ instance بقيمة ذات حجم ثابت باستخدام دالة تجزئة (hash function). يؤدي اشتقاق Hash إلى تنفيذ طريقة hash. يجمع التنفيذ المشتق لطريقة hash نتيجة استدعاء hash على كل جزء من أجزاء النوع، مما يعني أن جميع الـ fields أو القيم يجب أن تنفذ أيضاً Hash لاشتقاق Hash.
مثال على متى تكون Hash مطلوبة هو في تخزين الـ keys في HashMap<K, V> لتخزين البيانات بكفاءة.
Default للقيم الافتراضية (Default for Default Values)
تسمح لك سمة Default بإنشاء قيمة افتراضية لنوع ما. يؤدي اشتقاق Default إلى تنفيذ دالة default. يستدعي التنفيذ المشتق لدالة default دالة default على كل جزء من النوع، مما يعني أن جميع الـ fields أو القيم في النوع يجب أن تنفذ أيضاً Default لاشتقاق Default.
تُستخدم دالة Default::default بشكل شائع بالاشتراك مع صيغة تحديث الهيكل (struct update syntax) التي تمت مناقشتها في قسم “إنشاء مثيلات من مثيلات أخرى باستخدام صيغة تحديث الهيكل” في الفصل الخامس. يمكنك تخصيص عدد قليل من fields الهيكل ثم تعيين واستخدام قيمة افتراضية لبقية الـ fields باستخدام ..Default::default().
سمة Default مطلوبة عندما تستخدم الطريقة unwrap_or_default على instances الـ Option<T> ، على سبيل المثال. إذا كان الـ Option<T> هو None ، فستعيد الطريقة unwrap_or_default نتيجة Default::default للنوع T المخزن في الـ Option<T>.
د - أدوات تطوير مفيدة
الملحق د: أدوات التطوير المفيدة (Useful Development Tools)
في هذا الملحق، نتحدث عن بعض أدوات التطوير المفيدة التي يوفرها مشروع Rust. سننظر في التنسيق التلقائي (Automatic Formatting)، والطرق السريعة لتطبيق إصلاحات تحذيرات المترجم (compiler warnings)، وأداة التحقق من الكود (linter)، والتكامل مع بيئات التطوير المتكاملة (IDEs).
التنسيق التلقائي باستخدام rustfmt
أداة تنسيق الكود (rustfmt) تعيد تنسيق الكود الخاص بك وفقًا لنمط الكود (code style) الخاص بالمجتمع. تستخدم العديد من المشاريع التعاونية rustfmt لمنع الجدال حول النمط الذي يجب استخدامه عند كتابة Rust: يقوم الجميع بتنسيق الكود الخاص بهم باستخدام الأداة.
تتضمن تثبيتات Rust أداة rustfmt بشكل افتراضي، لذلك يجب أن تكون لديك بالفعل البرنامجان rustfmt وأمر تنسيق الكود (cargo-fmt) على نظامك. هذان الأمران يشبهان مترجم لغة رست (rustc) ومدير الحزم (cargo) من حيث أن rustfmt يسمح بتحكم أدق، بينما cargo-fmt يفهم اتفاقيات المشروع الذي يستخدم cargo. لتنسيق أي مشروع cargo، أدخل ما يلي:
$ cargo fmt
تشغيل هذا الأمر يعيد تنسيق كل كود Rust في الحزمة (crate) الحالية. يجب أن يغير هذا فقط نمط الكود، وليس دلالات الكود (code semantics). لمزيد من المعلومات حول rustfmt، راجع وثائقه.
إصلاح الكود الخاص بك باستخدام rustfix
أداة إصلاح الكود (rustfix) مُضمنة مع تثبيتات Rust ويمكنها تلقائيًا إصلاح تحذيرات المترجم (compiler warnings) التي لديها طريقة واضحة لتصحيح المشكلة، والتي من المحتمل أن تكون ما تريده. ربما تكون قد رأيت compiler warnings من قبل. على سبيل المثال، لننظر إلى هذا الكود:
اسم الملف: src/main.rs
fn main() {
let mut x = 42;
println!("{x}");
}هنا، نقوم بتعريف المتغير x على أنه قابل للتغيير (mutable)، لكننا لا نغيره أبدًا. تحذرنا Rust من ذلك:
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: variable does not need to be mutable
--> src/main.rs:2:9
|
52 | let mut x = 0;
| ----^
| |
| help: remove this `mut`
|
= note: `#[warn(unused_mut)]` on by default
يقترح التحذير أن نزيل الكلمة المفتاحية mut. يمكننا تطبيق هذا الاقتراح تلقائيًا باستخدام أداة rustfix عن طريق تشغيل الأمر cargo fix:
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
عندما ننظر إلى src/main.rs مرة أخرى، سنرى أن cargo fix قد غير الكود:
اسم الملف: src/main.rs
fn main() {
let x = 42;
println!("{x}");
}المتغير x أصبح الآن غير قابل للتغيير (immutable)، ولم يعد التحذير يظهر.
يمكنك أيضًا استخدام الأمر cargo fix لنقل الكود الخاص بك بين إصدارات لغة رست (Rust editions) المختلفة. يتم تناول Rust editions في الملحق هـ.
المزيد من قواعد التحقق (Lints) باستخدام Clippy
أداة Clippy (Clippy) هي مجموعة من Lints لتحليل الكود الخاص بك حتى تتمكن من اكتشاف الأخطاء الشائعة وتحسين كود Rust الخاص بك. Clippy مُضمنة مع تثبيتات Rust القياسية.
لتشغيل Lints الخاصة بـ Clippy على أي مشروع cargo، أدخل ما يلي:
$ cargo clippy
على سبيل المثال، لنفترض أنك كتبت برنامجًا يستخدم تقريبًا لثابت رياضي، مثل باي (pi)، كما يفعل هذا البرنامج:
fn main() {
let x = 3.1415;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}تشغيل cargo clippy على هذا المشروع ينتج عنه هذا الخطأ:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
يخبرك هذا الخطأ أن Rust لديها بالفعل ثابت PI أكثر دقة مُعرَّف، وأن برنامجك سيكون أكثر صحة إذا استخدمت الثابت بدلاً من ذلك. ستقوم بعد ذلك بتغيير الكود الخاص بك لاستخدام الثابت PI.
الكود التالي لا ينتج عنه أي أخطاء أو تحذيرات من Clippy:
fn main() {
let x = std::f64::consts::PI;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}لمزيد من المعلومات حول Clippy، راجع وثائقه.
تكامل بيئة التطوير المتكاملة (IDE Integration) باستخدام rust-analyzer
للمساعدة في IDE Integration، يوصي مجتمع Rust باستخدام محلل لغة رست (rust-analyzer). هذه الأداة هي مجموعة من الأدوات المساعدة التي تركز على المترجم (compiler-centric utilities) وتتحدث بروتوكول خادم اللغة (Language Server Protocol)، وهو مواصفات لـ IDEs ولغات البرمجة للتواصل مع بعضها البعض. يمكن لعملاء مختلفين استخدام rust-analyzer، مثل المكون الإضافي (plug-in) لـ rust-analyzer لـ Visual Studio Code.
قم بزيارة الصفحة الرئيسية لمشروع rust-analyzer للحصول على تعليمات التثبيت، ثم قم بتثبيت دعم خادم اللغة (language server support) في IDE الخاص بك. سيكتسب IDE الخاص بك قدرات مثل الإكمال التلقائي (autocompletion)، والانتقال إلى التعريف (jump to definition)، والأخطاء المضمنة (inline errors).
هـ - الإصدارات (Editions)
الملحق هـ: الإصدارات (Editions)
في الفصل الأول، رأيت أن الأمر cargo new يضيف بعض البيانات الوصفية (metadata) إلى ملف _Cargo.toml_ الخاص بك حول إصدار (edition). يتحدث هذا الملحق عما يعنيه ذلك!
تتمتع لغة Rust والمُصرِّف (compiler) بدورة إصدار مدتها ستة أسابيع، مما يعني أن المستخدمين يحصلون على تدفق مستمر من الميزات الجديدة. تطلق لغات البرمجة الأخرى تغييرات أكبر بوتيرة أقل؛ بينما تطلق Rust تحديثات أصغر بشكل متكرر. بعد فترة من الزمن، تتراكم كل هذه التغييرات الصغيرة. ولكن من إصدار إلى إصدار، قد يكون من الصعب النظر إلى الوراء والقول: “واو، بين Rust 1.10 و Rust 1.31، تغيرت Rust كثيرًا!”
كل ثلاث سنوات تقريبًا، ينتج فريق Rust إصدار (edition) جديدًا للغة Rust. يجمع كل edition الميزات التي تم إطلاقها في حزمة واضحة مع توثيق وأدوات (tooling) محدثة بالكامل. يتم شحن الإصدارات الجديدة كجزء من عملية الإصدار المعتادة التي تستغرق ستة أسابيع.
تخدم editions أغراضًا مختلفة لأشخاص مختلفين:
- بالنسبة لمستخدمي Rust النشطين، يجمع edition جديد التغييرات التدريجية في حزمة سهلة الفهم.
- بالنسبة لغير المستخدمين، يشير edition جديد إلى أن بعض التطورات الرئيسية قد تحققت، مما قد يجعل Rust تستحق نظرة أخرى.
- بالنسبة لأولئك الذين يطورون Rust، يوفر edition جديد نقطة تجمع للمشروع ككل.
في وقت كتابة هذا الكتاب، تتوفر أربعة Rust editions: Rust 2015، Rust 2018، Rust 2021، و Rust 2024. كُتب هذا الكتاب باستخدام مصطلحات (idioms) edition Rust 2024.
يشير مفتاح edition في _Cargo.toml_ إلى أي edition يجب أن يستخدمه compiler لـ code الخاص بك. إذا لم يكن المفتاح موجودًا، تستخدم Rust القيمة 2015 كقيمة edition لأسباب تتعلق بالتوافق مع الإصدارات السابقة (backward compatibility).
يمكن لكل مشروع اختيار edition بخلاف edition 2015 الافتراضي. يمكن أن تحتوي editions على تغييرات غير متوافقة، مثل تضمين كلمة مفتاحية (keyword) جديدة تتعارض مع المعرفات (identifiers) في code. ومع ذلك، ما لم تختر هذه التغييرات، سيستمر code الخاص بك في أن يُصرَّف (compile) حتى مع ترقية إصدار compiler الذي تستخدمه.
تدعم جميع إصدارات compiler الخاصة بـ Rust أي edition كان موجودًا قبل إصدار ذلك compiler، ويمكنها ربط الحزم (crates) من أي editions مدعومة معًا. تؤثر تغييرات edition فقط على طريقة قيام compiler بتحليل الشفرة (code) في البداية. لذلك، إذا كنت تستخدم Rust 2015 وتستخدم إحدى التبعيات (dependency) الخاصة بك Rust 2018، فسيتم compile مشروعك وستتمكن من استخدام تلك dependency. يعمل الوضع المعاكس أيضًا، حيث يستخدم مشروعك Rust 2018 وتستخدم dependency إصدار Rust 2015.
لتوضيح الأمر: ستكون معظم الميزات متاحة في جميع editions. سيستمر المطورون الذين يستخدمون أي Rust edition في رؤية التحسينات مع إصدار نسخ مستقرة جديدة. ومع ذلك، في بعض الحالات، خاصة عند إضافة keywords جديدة، قد تكون بعض الميزات الجديدة متاحة فقط في editions اللاحقة. ستحتاج إلى تبديل editions إذا كنت ترغب في الاستفادة من هذه الميزات.
لمزيد من التفاصيل، راجع دليل إصدار Rust. هذا كتاب كامل يسرد الاختلافات بين editions ويوضح كيفية ترقية code الخاص بك تلقائيًا إلى edition جديد عبر الأمر cargo fix.
و - ترجمات الكتاب
الملحق و: ترجمات الكتاب (Translations of the Book)
للموارد بلغات أخرى غير الإنجليزية. معظمها لا يزال قيد التقدم؛ انظر وسم Translations للمساعدة أو لإخبارنا عن ترجمة جديدة!
- Português (BR)
- Português (PT)
- 简体中文: KaiserY/trpl-zh-cn, gnu4cn/rust-lang-Zh_CN
- 正體中文
- Українська
- Español, alternate, Español por RustLangES
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi, Persian (FA)
- Deutsch
- हिंदी
- ไทย
- Danske
- O’zbek
- Tiếng Việt
- Italiano
- বাংলা
ز - كيف تُصنع رست و "رست الليلية" (Nightly Rust)
الملحق ز - كيف تُصنع Rust و “نسخة نايتلي” (Appendix G - How Rust is Made and “Nightly Rust”)
يدور هذا الملحق حول كيفية صنع لغة Rust وكيف يؤثر ذلك عليك كمطور Rust.
الاستقرار بدون ركود (Stability Without Stagnation)
كلغة برمجة، تهتم Rust كثيرًا باستقرار الكود الخاص بك. نريد أن تكون Rust أساسًا صلبًا يمكنك البناء عليه، وإذا كانت الأشياء تتغير باستمرار، فسيكون ذلك مستحيلاً. في الوقت نفسه، إذا لم نتمكن من تجربة ميزات جديدة، فقد لا نكتشف العيوب المهمة إلا بعد إصدارها، عندما لا نعود قادرين على تغيير الأشياء.
حلنا لهذه المشكلة هو ما نسميه “الاستقرار بدون ركود” (stability without stagnation)، ومبدأنا التوجيهي هو التالي: يجب ألا تضطر أبدًا إلى الخوف من الترقية إلى إصدار جديد من Rust المستقر (stable). يجب أن تكون كل ترقية غير مؤلمة، ولكن يجب أيضًا أن تجلب لك ميزات جديدة، وأخطاء أقل، وأوقات ترجمة (compile times) أسرع.
تشو، تشو! قنوات الإصدار وركوب القطارات (Choo, Choo! Release Channels and Riding the Trains)
يعمل تطوير Rust وفقًا لـ جدول قطار (train schedule). أي أن كل التطوير يتم في الفرع الرئيسي (main branch) لمستودع Rust. تتبع الإصدارات نموذج قطار إصدار البرمجيات (software release train model)، والذي تم استخدامه بواسطة Cisco IOS ومشاريع برمجية أخرى. هناك ثلاث قنوات إصدار (release channels) لـ Rust:
- نايتلي (Nightly)
- بيتا (Beta)
- مستقر (Stable)
يستخدم معظم مطوري Rust قناة Stable بشكل أساسي، ولكن أولئك الذين يرغبون في تجربة ميزات جديدة تجريبية قد يستخدمون Nightly أو Beta.
إليك مثال على كيفية عمل عملية التطوير والإصدار: لنفترض أن فريق Rust يعمل على إصدار Rust 1.5. حدث ذلك الإصدار في ديسمبر من عام 2015، ولكنه سيوفر لنا أرقام إصدارات واقعية. تمت إضافة ميزة جديدة إلى Rust: وصل التزام (commit) جديد إلى الفرع الرئيسي. في كل ليلة، يتم إنتاج نسخة Nightly جديدة من Rust. كل يوم هو يوم إصدار، ويتم إنشاء هذه الإصدارات بواسطة بنية الإصدار التحتية (release infrastructure) الخاصة بنا تلقائيًا. لذا مع مرور الوقت، تبدو إصداراتنا هكذا، مرة واحدة كل ليلة:
nightly: * - - * - - *
كل ستة أسابيع، يحين وقت إعداد إصدار جديد! يتفرع فرع beta لمستودع Rust من الفرع الرئيسي المستخدم بواسطة Nightly. الآن، هناك إصداران:
nightly: * - - * - - *
|
beta: *
لا يستخدم معظم مستخدمي Rust إصدارات Beta بنشاط، ولكنهم يختبرون مقابل Beta في نظام التكامل المستمر (CI system) الخاص بهم لمساعدة Rust في اكتشاف التراجعات (regressions) المحتملة. في هذه الأثناء، لا يزال هناك إصدار Nightly كل ليلة:
nightly: * - - * - - * - - * - - *
|
beta: *
لنفترض أنه تم العثور على تراجع (regression). من الجيد أننا حصلنا على بعض الوقت لاختبار إصدار Beta قبل أن يتسلل التراجع إلى إصدار Stable! يتم تطبيق الإصلاح على الفرع الرئيسي، بحيث يتم إصلاح Nightly، ثم يتم نقل الإصلاح (backported) إلى فرع beta ويتم إنتاج إصدار جديد من Beta:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
بعد ستة أسابيع من إنشاء أول نسخة Beta، يحين وقت إصدار Stable! يتم إنتاج فرع stable من فرع beta:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
هيا! لقد انتهى Rust 1.5! ومع ذلك، فقد نسينا شيئًا واحدًا: نظرًا لمرور الأسابيع الستة، نحتاج أيضًا إلى نسخة Beta جديدة من الإصدار التالي من Rust، وهو 1.6. لذا بعد أن يتفرع stable من beta يتفرع الإصدار التالي من beta من nightly مرة أخرى:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
يسمى هذا “نموذج القطار” (train model) لأنه كل ستة أسابيع، يغادر إصدار “المحطة”، ولكن لا يزال يتعين عليه القيام برحلة عبر قناة Beta قبل أن يصل كإصدار Stable.
تصدر Rust إصدارات كل ستة أسابيع، مثل الساعة. إذا كنت تعرف تاريخ إصدار واحد لـ Rust، فيمكنك معرفة تاريخ الإصدار التالي: إنه بعد ستة أسابيع. الجانب الجيد في وجود إصدارات مجدولة كل ستة أسابيع هو أن القطار التالي قادم قريبًا. إذا حدث أن فاتت ميزة معينة إصدارًا معينًا، فلا داعي للقلق: فهناك إصدار آخر سيحدث في وقت قصير! يساعد هذا في تقليل الضغط للتسلل بميزات قد لا تكون مصقولة بالقرب من الموعد النهائي للإصدار.
بفضل هذه العملية، يمكنك دائمًا التحقق من البناء التالي لـ Rust والتحقق بنفسك من سهولة الترقية إليه: إذا لم يعمل إصدار Beta كما هو متوقع، يمكنك إبلاغ الفريق به وإصلاحه قبل حدوث إصدار Stable التالي! الكسر (Breakage) في إصدار Beta نادر نسبيًا، ولكن rustc لا يزال قطعة من البرمجيات، والأخطاء موجودة.
وقت الصيانة (Maintenance time)
يدعم مشروع Rust أحدث إصدار مستقر. عندما يتم إصدار نسخة مستقرة جديدة، يصل الإصدار القديم إلى نهاية عمره (EOL). هذا يعني أن كل إصدار يتم دعمه لمدة ستة أسابيع.
الميزات غير المستقرة (Unstable Features)
هناك عقبة أخرى في نموذج الإصدار هذا: الميزات غير المستقرة (unstable features). تستخدم Rust تقنية تسمى “أعلام الميزات” (feature flags) لتحديد الميزات التي يتم تمكينها في إصدار معين. إذا كانت ميزة جديدة قيد التطوير النشط، فإنها تصل إلى الفرع الرئيسي، وبالتالي في Nightly، ولكن خلف علم ميزة (feature flag). إذا كنت ترغب، كمستخدم، في تجربة الميزة التي لا تزال قيد العمل، يمكنك ذلك، ولكن يجب أن تستخدم إصدار Nightly من Rust وتضع علامة على كود المصدر الخاص بك بالعلم المناسب للاشتراك.
إذا كنت تستخدم إصدار Beta أو Stable من Rust، فلا يمكنك استخدام أي أعلام ميزات. هذا هو المفتاح الذي يسمح لنا بالحصول على استخدام عملي للميزات الجديدة قبل أن نعلن استقرارها للأبد. أولئك الذين يرغبون في الاشتراك في أحدث التقنيات (bleeding edge) يمكنهم فعل ذلك، وأولئك الذين يريدون تجربة صلبة كالصخر يمكنهم الالتزام بـ Stable ومعرفة أن كودهم لن ينكسر. الاستقرار بدون ركود.
يحتوي هذا الكتاب فقط على معلومات حول الميزات المستقرة، حيث أن الميزات قيد العمل لا تزال تتغير، وبالتأكيد ستكون مختلفة بين وقت كتابة هذا الكتاب ووقت تمكينها في البناءات المستقرة. يمكنك العثور على وثائق للميزات الخاصة بـ Nightly فقط عبر الإنترنت.
Rustup ودور نسخة نايتلي (Rustup and the Role of Rust Nightly)
يجعل Rustup من السهل التغيير بين قنوات الإصدار المختلفة لـ Rust، على أساس عالمي أو لكل مشروع. بشكل افتراضي، سيكون لديك Rust المستقر مثبتًا. لتثبيت Nightly، على سبيل المثال:
$ rustup toolchain install nightly
يمكنك رؤية جميع سلاسل الأدوات (toolchains) (إصدارات Rust والمكونات المرتبطة بها) التي قمت بتثبيتها باستخدام rustup أيضًا. إليك مثال على كمبيوتر يعمل بنظام Windows لأحد المؤلفين:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
كما ترى، فإن سلسلة أدوات Stable هي الافتراضية. يستخدم معظم مستخدمي Rust نسخة Stable معظم الوقت. قد ترغب في استخدام Stable معظم الوقت، ولكن تستخدم Nightly في مشروع معين، لأنك تهتم بميزة متطورة. للقيام بذلك، يمكنك استخدام rustup override في دليل ذلك المشروع لتعيين سلسلة أدوات Nightly لتكون هي التي يجب أن يستخدمها rustup عندما تكون في ذلك الدليل:
$ cd ~/projects/needs-nightly
$ rustup override set nightly
الآن، في كل مرة تستدعي فيها rustc أو cargo داخل دليل ~/projects/needs-nightly، سيتأكد rustup من أنك تستخدم Nightly Rust، بدلاً من Rust المستقر الافتراضي لديك. هذا مفيد جدًا عندما يكون لديك الكثير من مشاريع Rust!
عملية RFC والفرق (The RFC Process and Teams)
إذًا كيف تتعلم عن هذه الميزات الجديدة؟ يتبع نموذج تطوير Rust عملية طلب التعليقات (RFC) (Request For Comments process). إذا كنت ترغب في تحسين في Rust، يمكنك كتابة اقتراح يسمى RFC.
يمكن لأي شخص كتابة RFCs لتحسين Rust، ويتم مراجعة الاقتراحات ومناقشتها من قبل فريق Rust، الذي يتكون من العديد من الفرق الفرعية للموضوعات. هناك قائمة كاملة بالفرق على موقع Rust الإلكتروني، والتي تتضمن فرقًا لكل منطقة من مناطق المشروع: تصميم اللغة، تنفيذ المترجم، البنية التحتية، التوثيق، والمزيد. يقرأ الفريق المناسب الاقتراح والتعليقات، ويكتب بعض التعليقات الخاصة به، وفي النهاية، يكون هناك إجماع على قبول الميزة أو رفضها.
إذا تم قبول الميزة، يتم فتح مشكلة (issue) في مستودع Rust، ويمكن لشخص ما تنفيذها. الشخص الذي ينفذها قد لا يكون هو الشخص الذي اقترح الميزة في المقام الأول! عندما يكون التنفيذ جاهزًا، فإنه يصل إلى الفرع الرئيسي خلف بوابة ميزة (feature gate)، كما ناقشنا في قسم “الميزات غير المستقرة”.
بعد مرور بعض الوقت، وبمجرد أن يتمكن مطورو Rust الذين يستخدمون إصدارات Nightly من تجربة الميزة الجديدة، سيناقش أعضاء الفريق الميزة، وكيف سارت الأمور في Nightly، ويقررون ما إذا كان ينبغي أن تصل إلى Rust المستقر أم لا. إذا كان القرار هو المضي قدمًا، يتم إزالة بوابة الميزة، وتعتبر الميزة الآن مستقرة! تركب القطارات إلى إصدار مستقر جديد من Rust.